
热门标签
热门文章
- 1ZooKeeper集群安装后显示ZooKeeper JMX enabled by defaultUsing config: /opt/app/zookeeper-3.4.13/bin/../conf
- 2经验 - github中的watch、star、fork、following的作用_gitee个人主页下的following是什么意思
- 3MySQL中三种表的删除方式_mysql8 删除表格
- 4合肥中科深谷嵌入式项目实战——人工智能与机械臂(六)
- 52021-09-13RC4 加密问题漏洞CVE-2015-2808_rc4 加密问题漏洞(cve-2015-2808)
- 6IDEA中没有Web Application的问题_idea社区版不支持web开发
- 7ICCV 2023 | APE: 高效的 CLIP 图像分类适配算法,比 Tip-Adapter 参数少30倍
- 8mysql 创建学生表、课程表、学生选课表_学生表选课表课程表
- 9Git下载安装及基本配置_git下载地址
- 10镜像容器 gitlab pull 代码到本地 教程
当前位置: article > 正文
DATA AI Summit 2022提及到的对 aggregate 的优化_objecthashaggregate
作者:我家自动化 | 2024-04-18 01:26:42
赞
踩
objecthashaggregate
背景
本文基于SPARK 3.3.0
HashAggregate的优化
该优化是FaceBook(Meta) 内部的优化,还有合并到spark社区。
该优化的主要是partialaggregate的部分:对于类似求count,sum,Avg的聚合操作,会存在现在mapper进行部分聚合的操作,之后在reduce端,再进行FinalAggregate操作。这看起来是没有问题的(能够很好的减少网络IO),但是我们知道对于聚合操作,我们会进行数据的spill的操作,如果在mapper阶段合并的数据很少,以至于抵消不了网络IO带来的消耗的话,这无疑会给任务带来损耗。
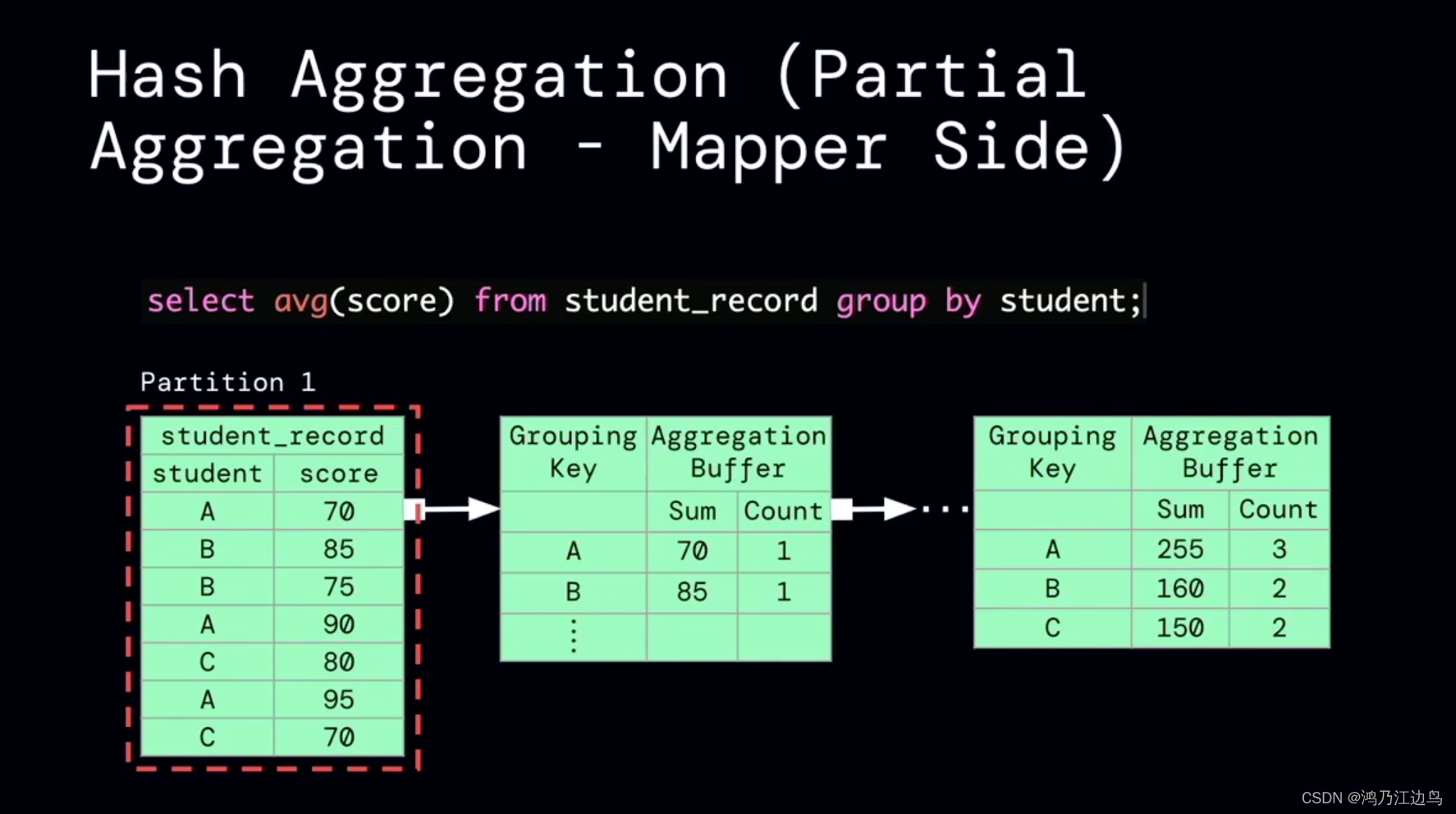
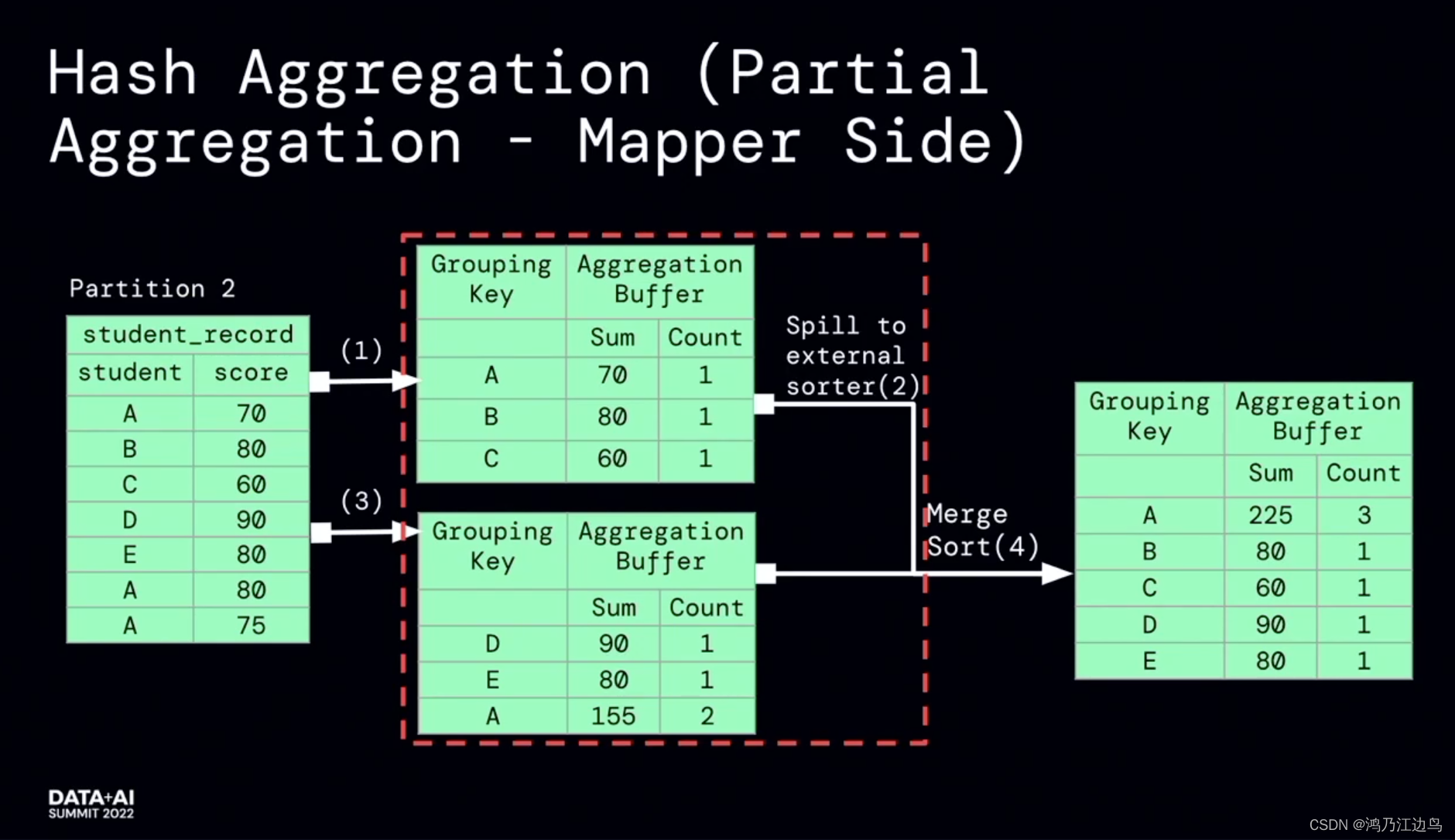
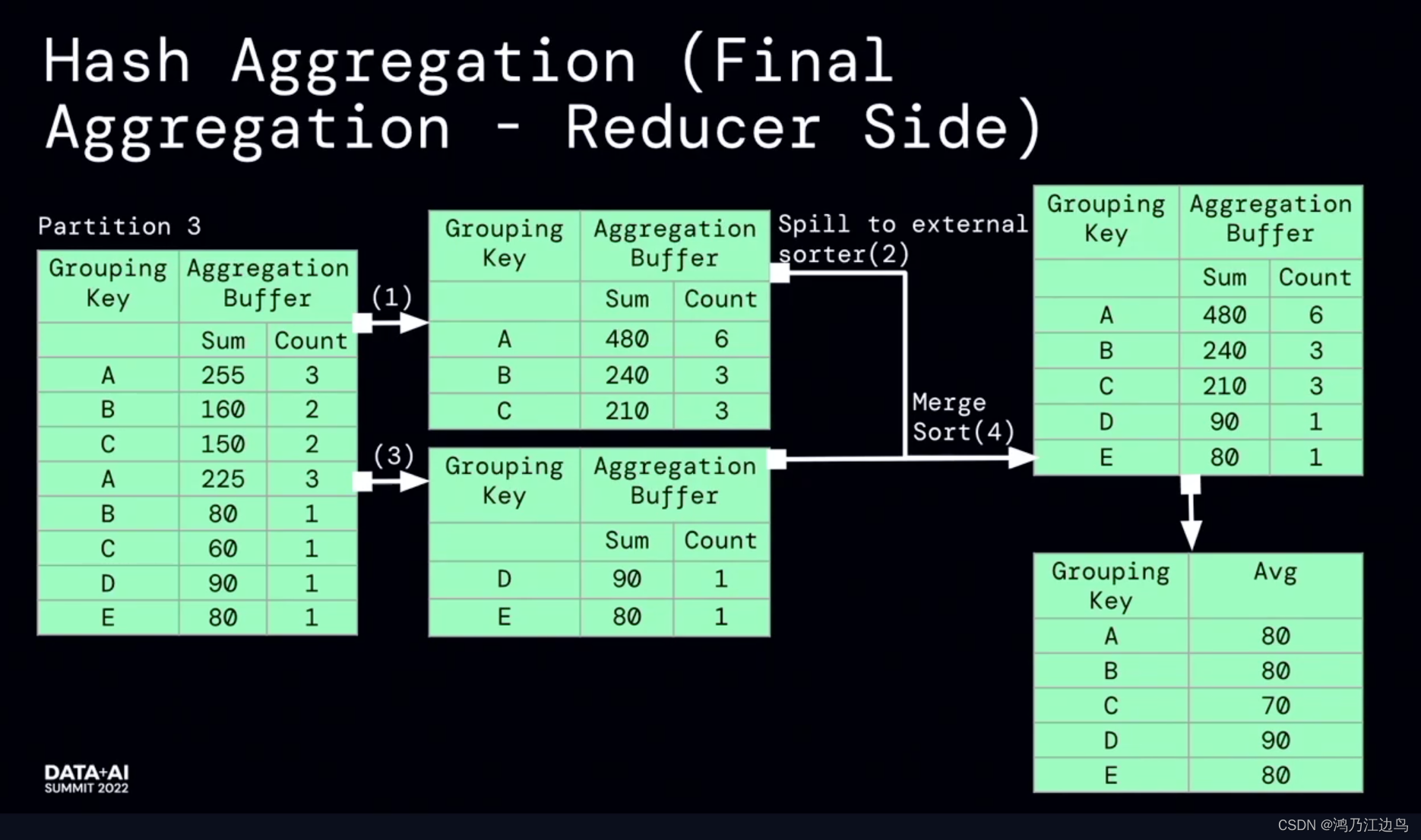
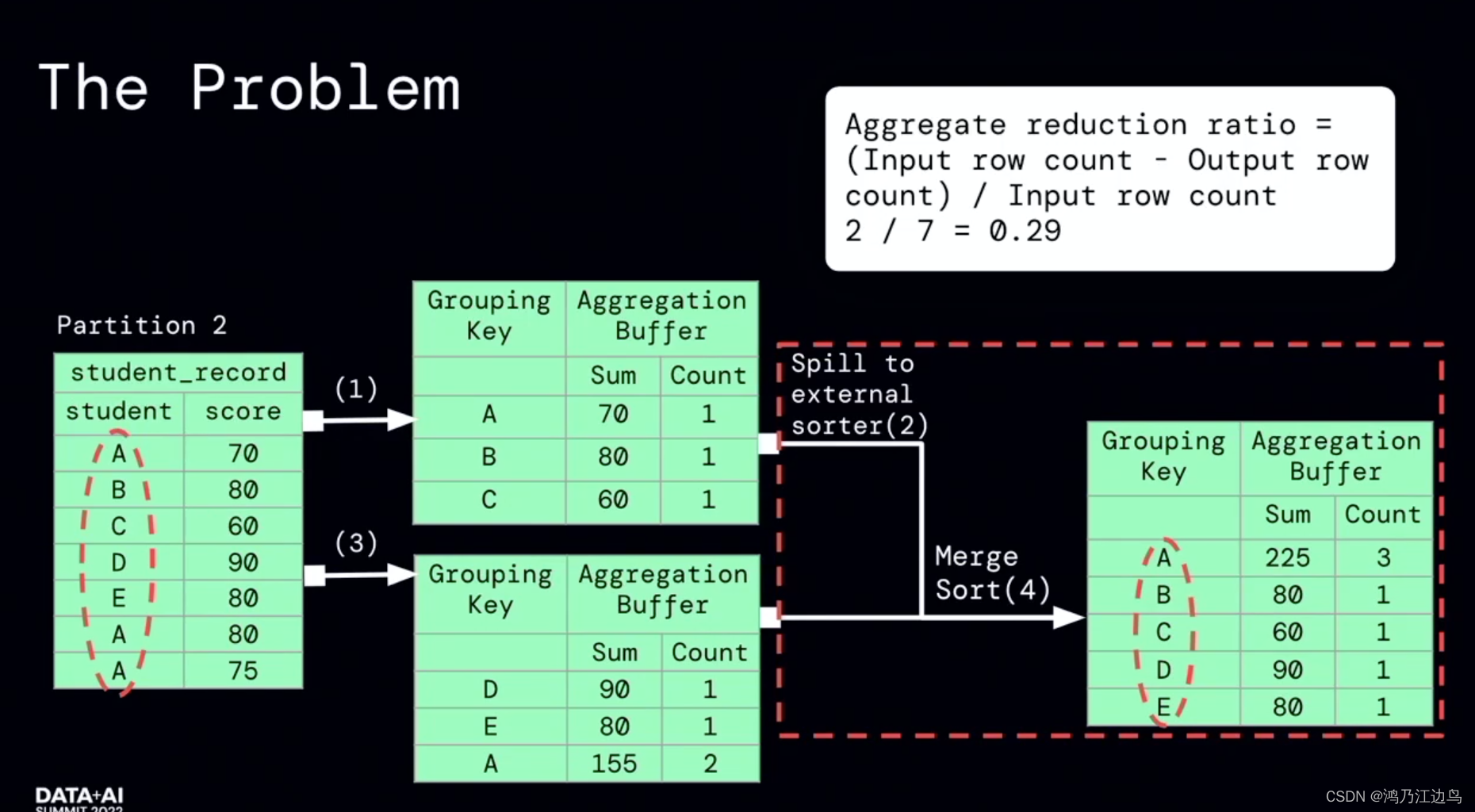
利用运行时的指标信息,能够达到比较好的加速效果。
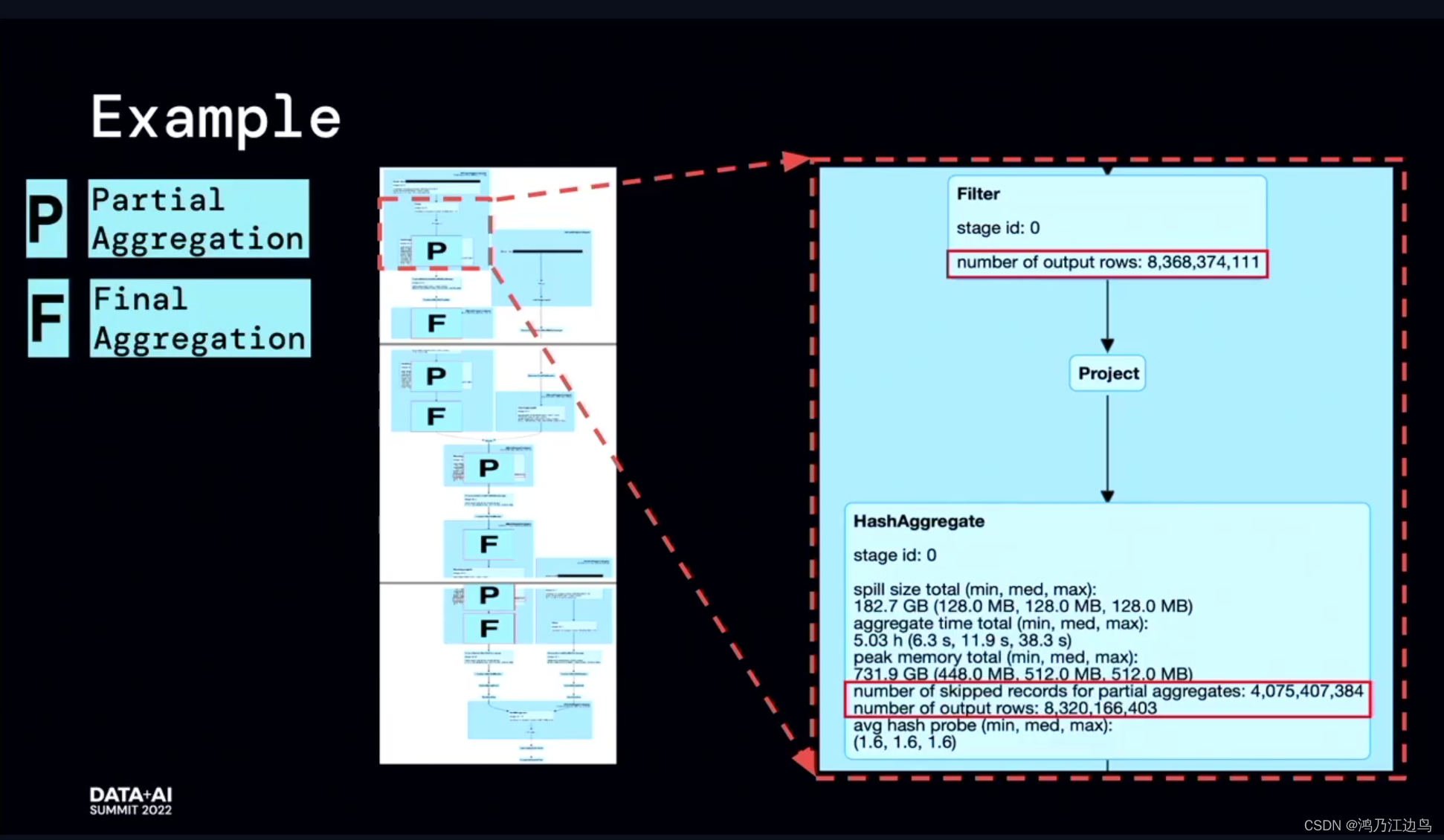
ObjectHashAggregate的优化
对于ObjectHashAggreate的原理,可以参考深入理解SPARK SQL 中HashAggregateExec和ObjectHashAggregateExec以及UnsafeRow,该文可以比较清楚的解释ObjectHashAggregate和HashAggregate的区别:
- ObjectHashAggregate能够弥补HashAggregate 不能支持collect_set等这种表达式,从而不会转变为SortAggregate
- ObjectHashAggregate利用的是java Array对象(SpecificInternalRow)保存聚合的中间缓冲区,这对jvm gc是不太友好的
- ObjectHashAggregate根据hashMap的size(默认是128),而不是输入的行数来进行spill,这会导致提前spill,内存利用率不高。
- 由于提前的spill,ObjectHashAggregate会对剩下的所有数据做额外的一次排序操作(如果没有spill,就不需要额外的sort操作),而HashAggregate则是会对每次需要spill的数据做排序
使用jvm heap的内存使用情况以及处理的行数来指导什么时候开始spill。
但是这种在数据倾斜的情况下,会增加OOM的风险。
SortAggregate优化
目前SortAggreaget的现状是:
- 每个任务在sort Aggreate前需要按照key进行排序
- 根据排序的结果,在相邻的行之间进行聚合操作
不同于Hash Aggregate: - 不需要hashTable,也就不存在内存溢写和回退到sortAggregate
- 优化器更喜欢选择hashAggregate
- 没有codegen的实现.
目前在spark 3.3.0增加的功能:
- 如果数据是有序的话,会选择用sortAggragate替代HashAggregate
通过物理计划RuleReplaceHashWithSortAgg来做替换,当然通过spark.sql.execution.replaceHashWithSortAgg来开启(默认是关闭的),因为对于任何新特性,在release版本默认都是关闭的,在master分支才是开启的 - 支持sortAggretate(without keys)的codegen代码生成
其他
对于Aggregate更多的细节了解可以参考sparksql源码系列 | 一文搞懂with one count distinct 执行原理
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/443289
推荐阅读
- [详细] -->
赞
踩
相关标签

