
- 1机器学习之网格搜索(GridSearch)及参数说明,实例演示_gridsearchfit的参数
- 2英飞凌旋变软解码学习
- 3怎样生成全局唯一流水号?UUID、自增主键,你已经Out啦,快来学习定制化雪花算法。_若依 主键uuid
- 4CESS 测试网上线!首个提供多元应用场景的去中心化存储网络_cess区块浏览其
- 5如何用python进行数据分析_如何用python做数据分析
- 6深入理解大语言模型微调技术_微调大语言模型应用于
- 7上手OpenMMLab——深度学习预训练与MMPretrain
- 8MPU6050 6轴姿态传感器的分析与使用(一)
- 9使用labelme打标签,详细教程_labelme使用教程
- 10【MySql】Mysql之备份与恢复_mysql数据库备份与还原
YOLOv5~TRT~JetsonNX部署_trtexec.exe yolov5s.onnx
赞
踩
针对不同的平台,如何使深度学习算法的推理速度更快,无疑可以影响用户的体验,甚至可以影响一个算法的有效性,这是深度学习模型部署所要研究的问题。目前模型部署框架则有NVIDIA推出的TensorRT,谷歌的Tensorflow和用于ARM平台的tflite,开源的caffe,百度的飞桨等。
在AIOT、移动设备以及自动驾驶等领域,出于成本和性能方面的考虑,可能无法使用高性能的GPU服务器,因此NVIDIA推出了Jetson NX,可以广泛地应用于嵌入式设备和边缘计算等场景。同时,Nvidia所开发的TensorRT可以对深度学习模型的推理过程进行加速,使得Jetson NX也可以使用一些深度学习算法从而拥有更广泛的应用价值。Triton是NVIDIA于2018年开源的服务框架,可以对TensorRT生成的推理引擎进行更好的调度以及处理推理请求。
本文主要介绍了基于Jetson NX使用TensorRT和Triton对深度学习算法模型进行部署的流程,并以yolov5和ResNet两种视觉领域常用的算法为例进行了评测。
这次都是py代码哦
▌模型部署流程
Jetson上的模型部署因为是基于arm的,与传统基于x86的主机或服务器的部署略有差别,但基本类似,主要分为三步:
-
模型转换为onnx
-
生成基于TensorRT的推理引擎
-
使用Triton完成部署
1.模型转换为onnx
首先可以将pytorch或其他框架训练好的模型转换为onnx格式用于后续的部署。pytorch中提供了将模型文件导出为onnx格式的函数。以yolov5为例:

可以将原模型导出为onnx格式,其中model是我们要进行导出的模型文件,f为导出的onnx模型文件。
2.基于TensorRT的推理引擎生成
TensorRT主要用于优化模型推理速度,是硬件相关的。主要有两种将torch生成的模型转化为TensorRT的engine的方式:
-
将模型的.pth权重文件转化为.wts文件。之后编写c++程序对.wts进行编译,生成推理引擎,通过调用推理引擎来进行TensorRT的推理。
-
将网络结构保存为onnx格式,然后利用ONNX-TensorRT工具将onnx模型文件转换为TensorRT推理引擎即可即可。
注:两种方法生成的推理引擎无法直接互换使用,需要进行一定的转换。
在本文中,我们使用第二种方法生成推理引擎。即使用上一步中转化好的onnx模型文件,使用ONNX-TensorRT工具trtexec将onnx模型文件转化为推理引擎。
在Jetson上安装arm版的TensorRT后可以使用trtexec将onnx模型文件生成推理引擎,使用方法如下:
--onnx代表输入的模型文件, --fp16代表使用半精度浮点类型数据,--saveEngine代表保存的推理引擎名称。使用trtexec -h可以查看更多参数说明。执行结束后可以得到类似如下的性能结果报告:

如果最后显示为PASSED则代表推理引擎生成成功,2-9为用伪数据进行的性能测试结果。
3.使用Triton完成部署
在上一步中使用TensorRT得到推理引擎后,可以使用Triton进行进一步的部署。
Jetson版的Triton Server安装可以参考 [Triton Inference Server Support for Jetson and JetPack][1]。安装完成后,配置模型即可完成部署,更多信息可参考[ Triton Model Configuration Documentation][2]。
在本文以如下配置过程为例: 配置文件的目录格式如下:
配置文件的目录格式如下:

即构建好模型文件的目录和配置文件,并将上一步中得到的推理引擎复制到相应目录下作为model.plan,一个简单的配置文件config.pbtxt可以设置如下:

完成以上配置后,即可使用tritonserver进行部署: whaosoft aiot http://143ai.com
 部署成功后结果如上图所示,可以使用pytritonclient将需要预测的数据进行预处理后访问8001端口进行推理调用。
部署成功后结果如上图所示,可以使用pytritonclient将需要预测的数据进行预处理后访问8001端口进行推理调用。
▌性能评测
本文分别对视觉领域常用的两种算法Yolov5和ResNet进行了评测,对TensorRT的加速进行了量化的评估。
ResNet 图1 ResNet加速性能评价
图1 ResNet加速性能评价
本文对ResNet常见的两种网络结构ResNet18和ResNet50分别进行了测试,实验结果如图1所示,加速版本与未加速版本所使用的设置均一致,测量的指标为query per second(qps),batchsize均为1,加速比约为6.02。
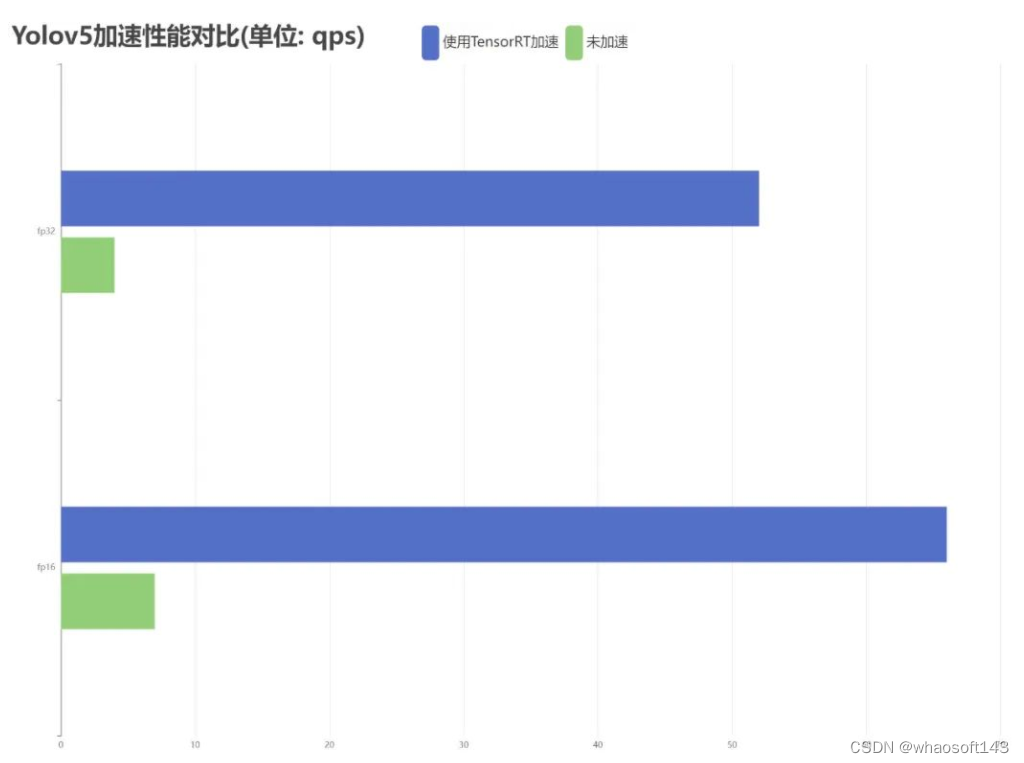 图2 Yolov5加速性能评价
图2 Yolov5加速性能评价
Yolo是视觉领域常用的目标检测算法,本文对Yolov5的加速性能进行了测试,分别对半精度浮点类型和全精度浮点类型的加速性能进行了实验。实验结果如图2所示,加速版本与未加速版本所使用的实验设置均一致,图像输入尺寸为320×320,测量的性能指标为qps。可以看出,目标识别算法只有在加速后可以实现实时的目标检测,加速比约为10.96。
▌总结
本文主要介绍了基于Jetson NX使用TensorRT和Triton对深度学习算法模型进行部署方法和整体流程,并以yolov5和ResNet两种视觉领域常用的算法为例进行了评测。在基本不损失精度的情况下,TensorRT可以对常见的深度学习算法模型进行很好的加速并部署在Jetson上。
利用这项技术,使Jetson不再依赖服务器,可以在本地实时常见的深度学习任务。在边缘计算、移动端设备计算等场景中有非常广阔的应用价值。
▌参考资料
[1]https://github.com/triton-inference-server/server/blob/r22.10/docs/user_guide/jetson.md
[2]https://github.com/triton-inference-server/server/blob/main/docs/model_configuration.md#model-configuration
[封面]https://developer.nvidia.com/tensorrt


