
- 1Redis 可视化客户端工具、fastgithub 加速器_redis客户端工具
- 2Yolov5如何训练自定义的数据集,以及使用GPU训练,涵盖报错解决_yolov5指定使用gpu训练
- 3【正点原子Linux连载】 第二十五章HDMI屏幕驱动实验摘自【正点原子】ATK-DLRK3568嵌入式Linux驱动开发指南_正点原子的高清口
- 4Android弧形SeekBar的设计与实现_seekbar自定义弧形
- 5编译原理作业小结_save = false; state = incomment;
- 6Vue--style绑定样式--点击按钮切换样式_vue点击div按钮设置style
- 7android 线程执行方法吗,Android:等待线程完成执行方法
- 8Java 面向对象三大特性之三——接口(面试、学习、工作必备技能)_java面试实现接口
- 9neo4j的Cypher的语法记录
- 10MPU6050传感器—姿态检测_mpu6050如何检测角度
目标检测(1)—— 基础知识和常用数据集_目标检测数据集
赞
踩
一、什么是目标检测
一张图片,经过网络后得到输出,检测出感兴趣目标的一个位置,比如下图的车在什么地方,狗在什么地方;还要输出相应位置的目标是什么类别的。
目标检测:位置+类别
- 矩形框:位置
- 矩形框:类别
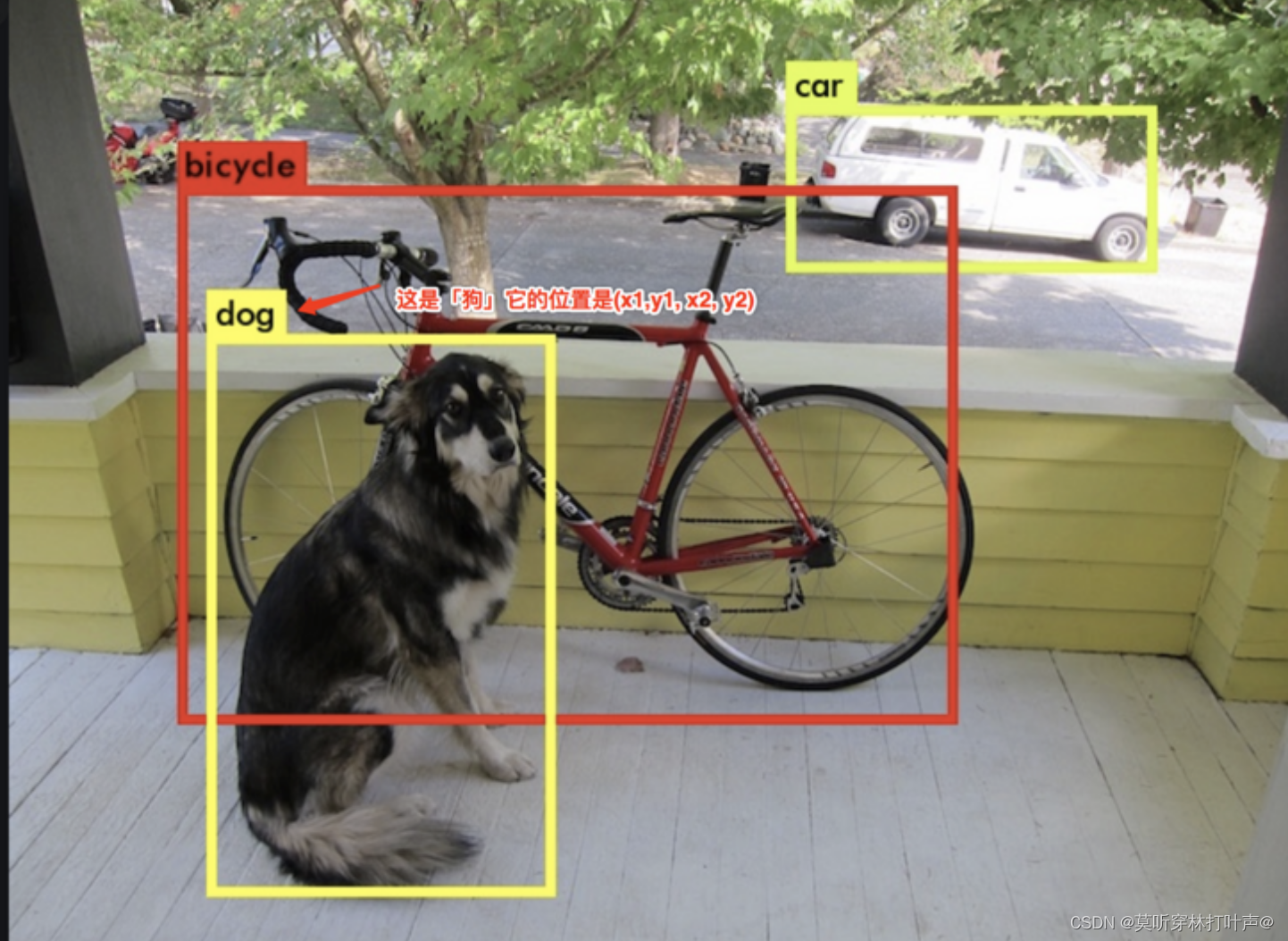
eg:人脸检测
把人脸作为目标,就把人脸框起来。

eg:文字检测
把文字当作目标,就把文字框起来。

重点在于:要学会判断你要做的东西的目标是什么?
主流的目标检测,都是以矩形框的形式进行输出的。一般精度不高。
更高精度的:叫做语义分割。
语义分割:用不同的颜色区分开。矩形框会包含背景,所以精度没有那么高。语义分割的训练要求更高。

- 总结:目标检测能满足大多数场景,如果需要更高的精度,选择语义分割。
二、目标检测数据集
1、常见的数据集
VOC数据集
VOC2007、VOC2012
训练集-图片:人工对训练集进行标注,需要标注想要的目标在那个位置,对应的是哪个目标。
测试集-图片:测试集也有一些标注。
具体如下:(这里省略验证集)
共四种类型的图片,竞赛给参赛者前三种图片,参赛者用自己的网络模型对训练集的图片和标注进行训练,然后用训练好的模型,在测试集的图片上跑一遍,得到测试集的标注。参赛者把测试集的标注提交给比赛方,比赛方把自己的标注和参赛者的标注进行比较后排名。

为什么用VOC2007、VOC2012?
05-07一个阶段,08-12一个阶段。选择数据集比较大的。
数据集的下载
第一种下载方式:在VOC官网下载。
http://host.robots.ox.ac.uk/pascal/VOC/
第二种下载方式:PyTorch自带。
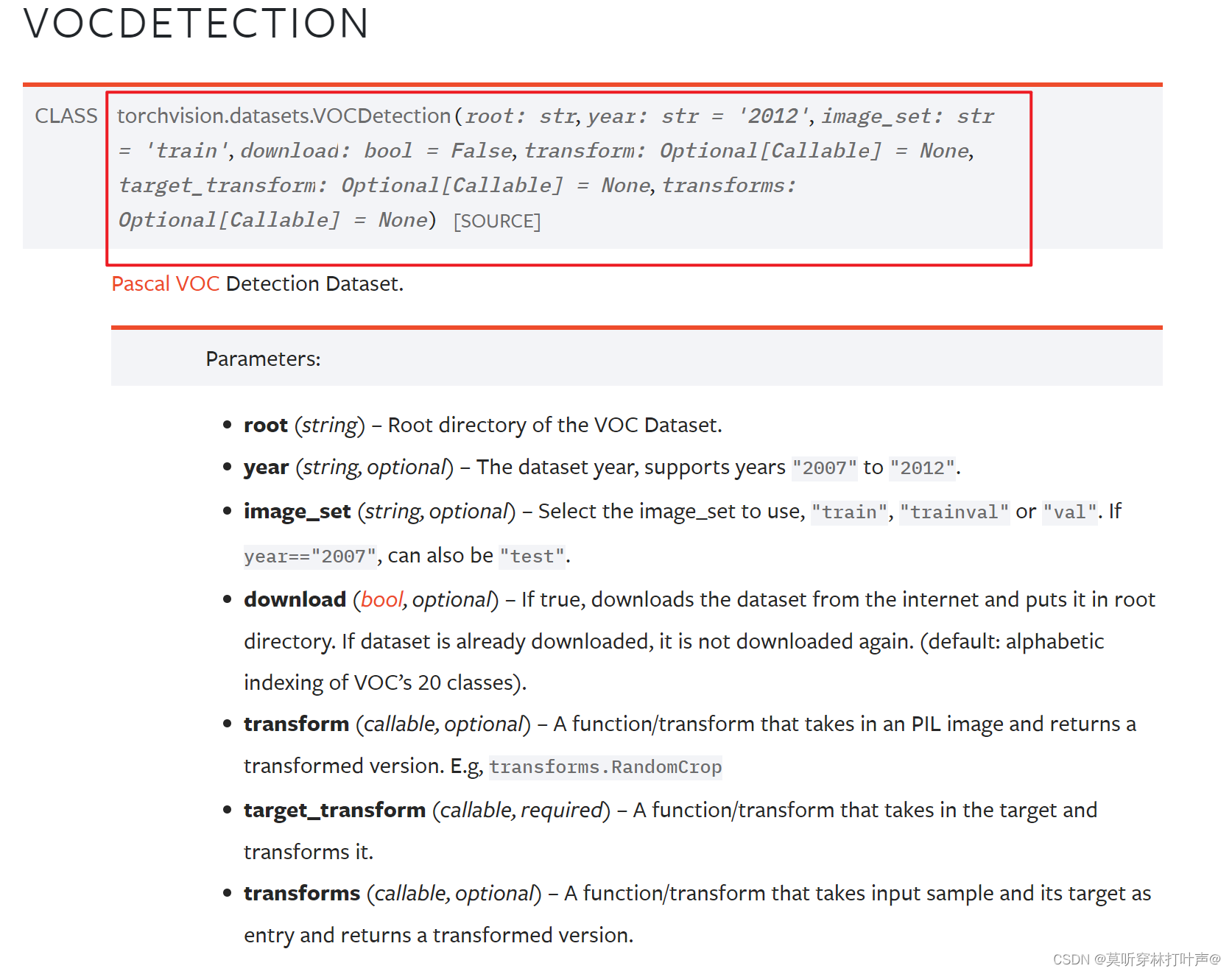
数据集的标注
VOC2007:

- Annotations:包含了xml文件,描述了图片的各种信息,特别是目标的位置坐标。
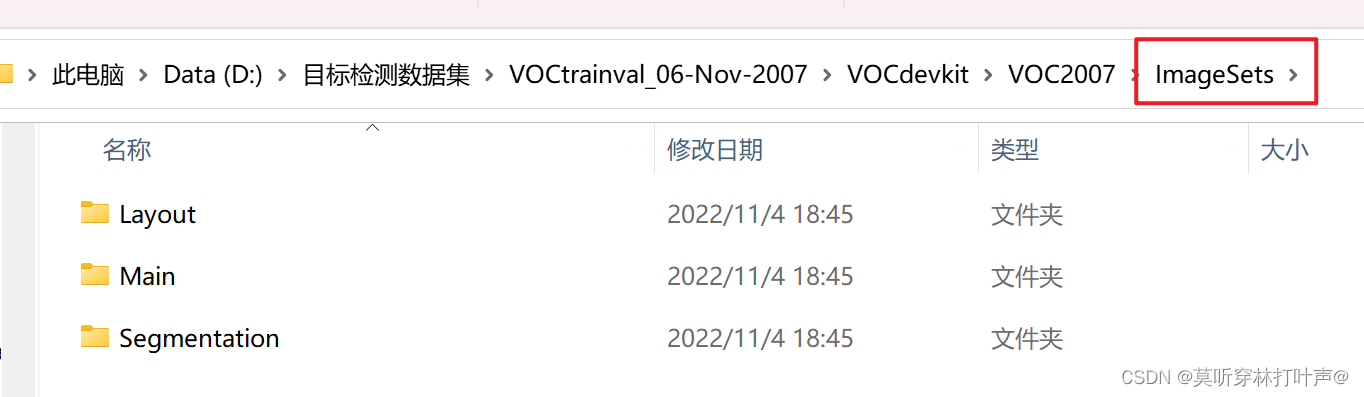
- ImageSets:主要关注Main文件夹,里面的文件包含了不同类别目标的训练/验证数据集图片名称
- JPEGImages:原图片。
- SegmentationClass/Object:用于语义分割,不关注。
Annotations:标注
xml是一种规定的格式。
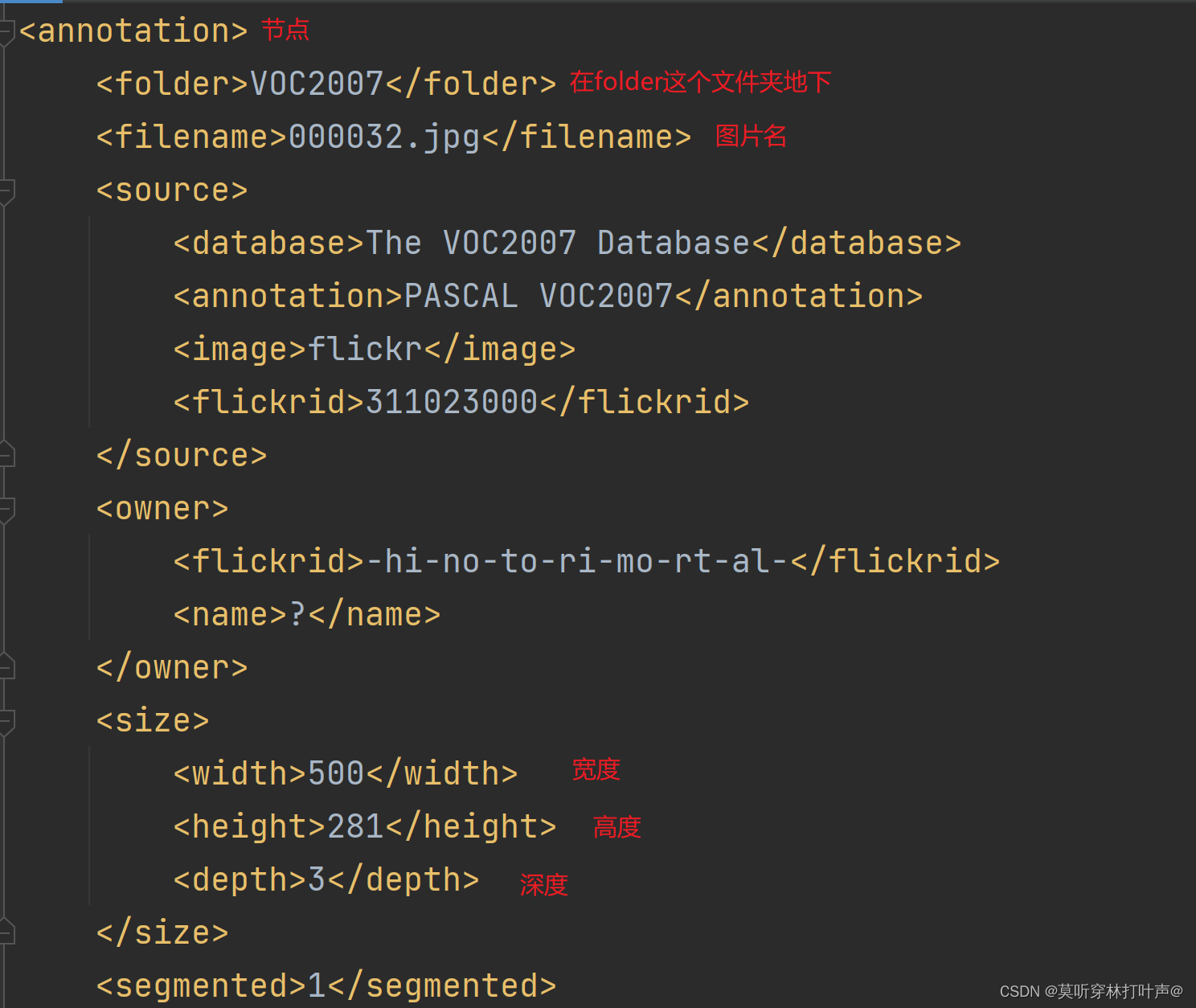
打开000032.xml,xml里面包括了图片的信息。

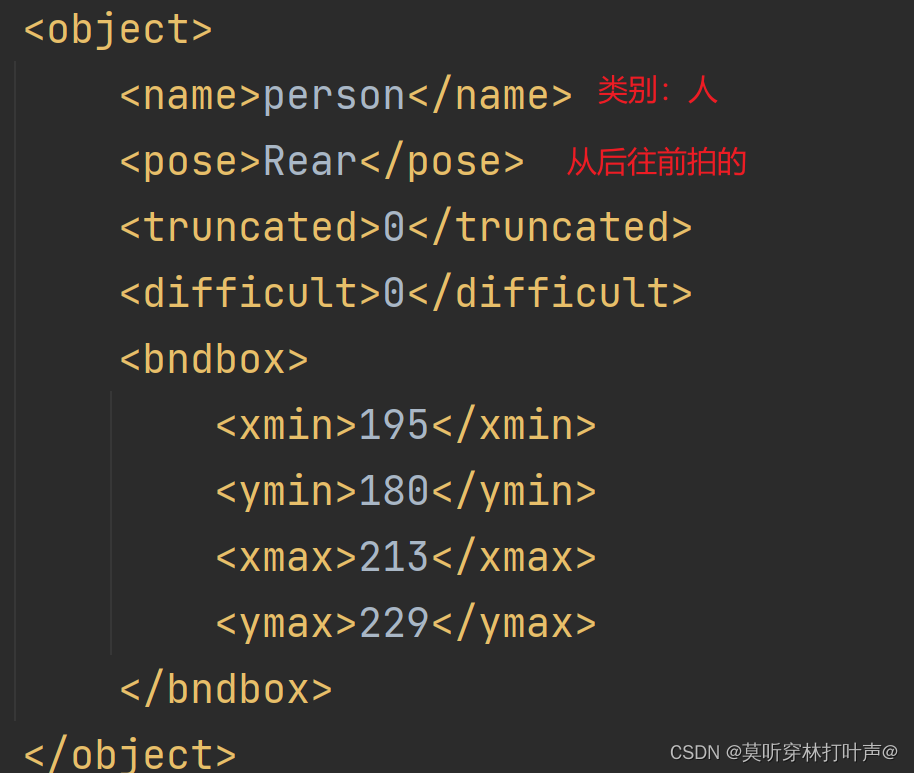
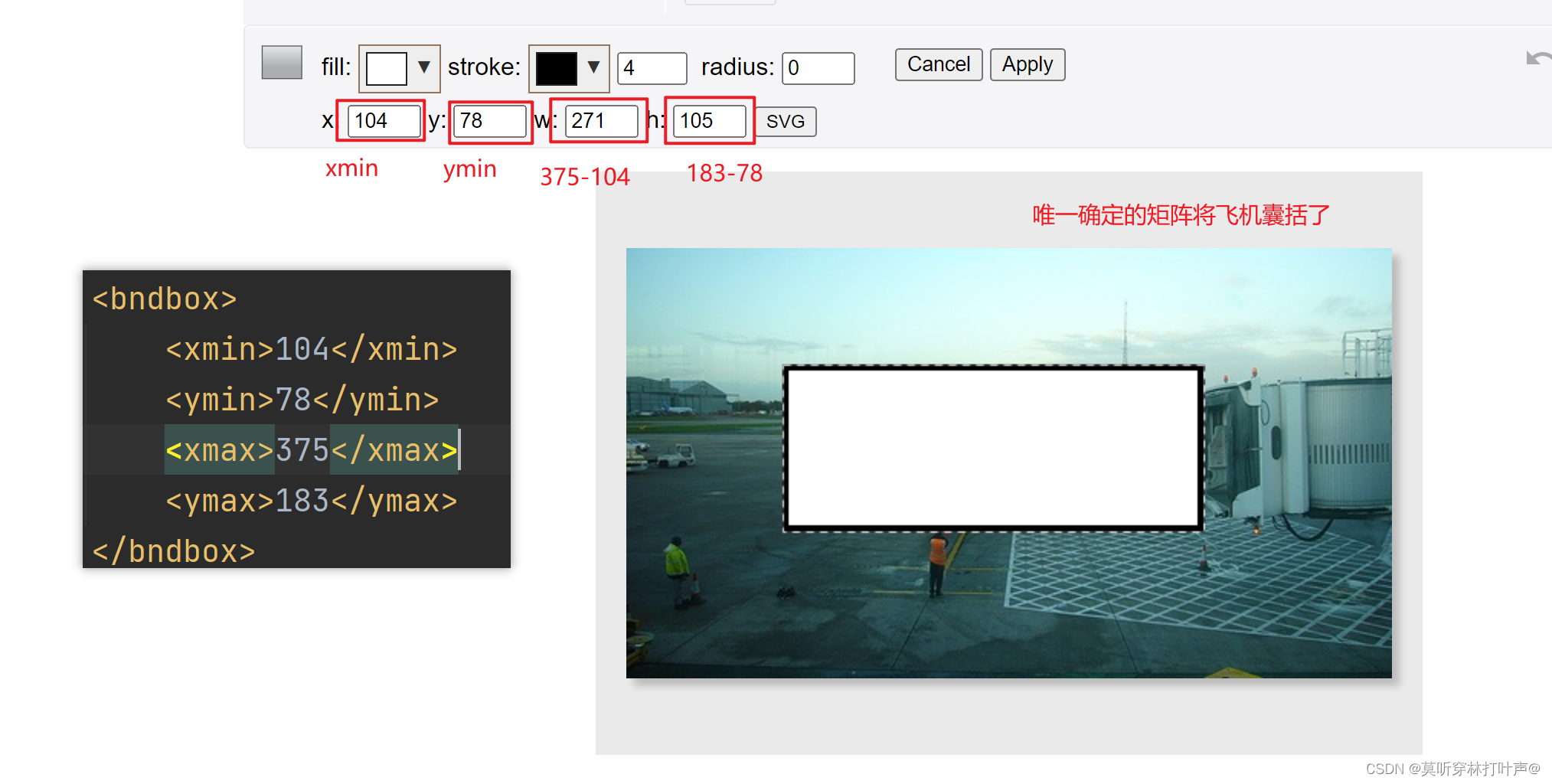
bndbox是核心,打开网站:图片在线查看工具
https://www.gifgit.com/image/rectangle-tool
验证xml中矩形框:
ImageSets:重点关注Main
aeroplane_train:aeroplane代表是飞机这一类,train代表是训练集,剩下的同。
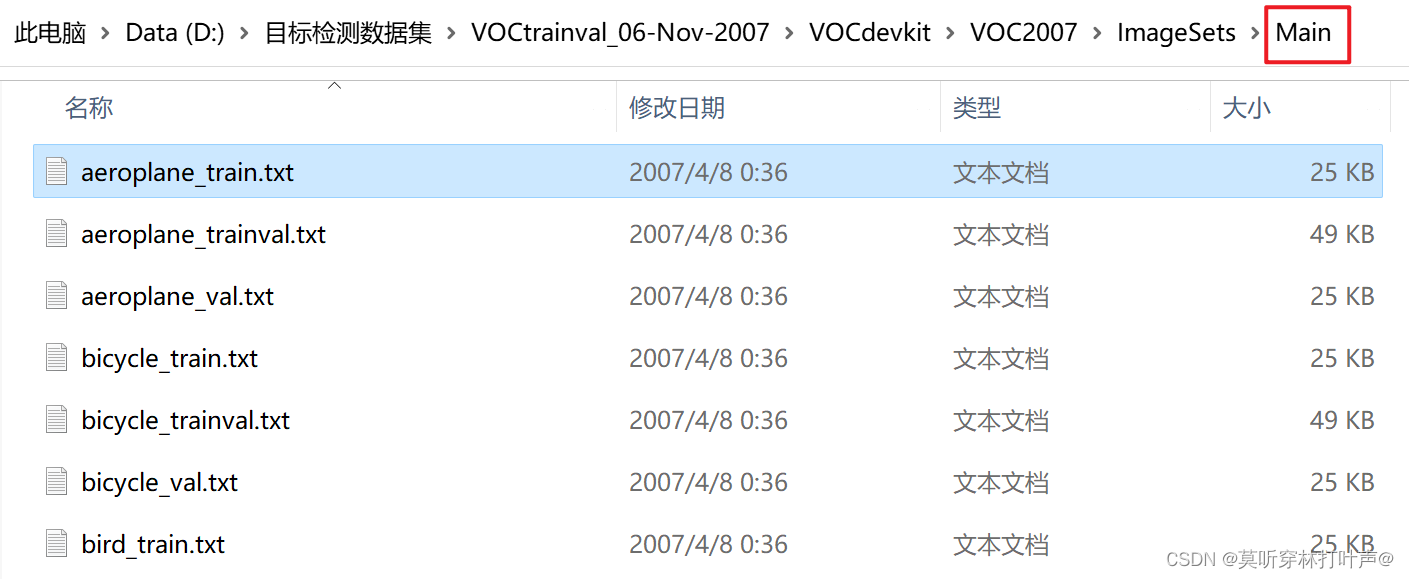
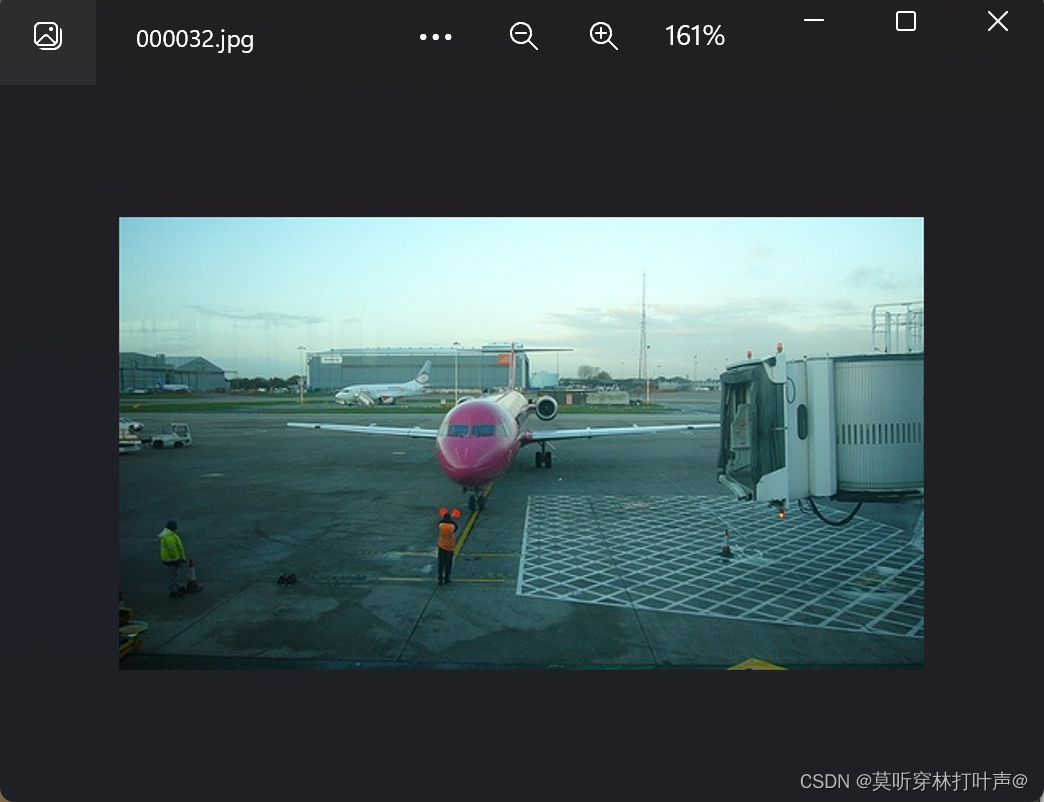
000032.jpg是飞机,打开aeroplane_train.txt
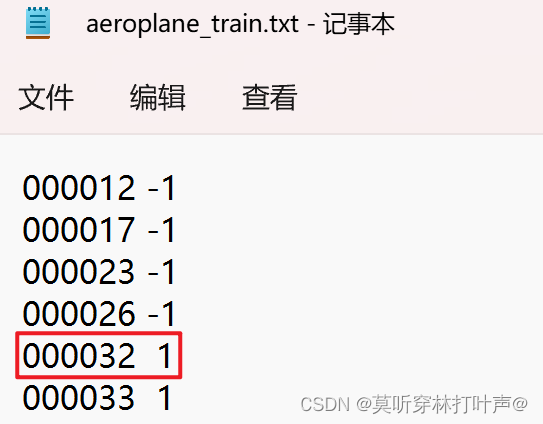
该图片在飞机这一类。只要图片中有飞机(不是有一个飞机),就是1,为正样本;-1代表图片中没有飞机。
JPEGImages:原图。

例如:000031.jpg
针对目标检测,2012没有包含2007,从2008开头的;针对图像分割,就包含了2007。
COCO数据集
官网:https://cocodataset.org/#home

常用COCO2017,下载2017的val和它的标注,看一下是怎么标注的。(所以就下个小的,和18G的目录一样)
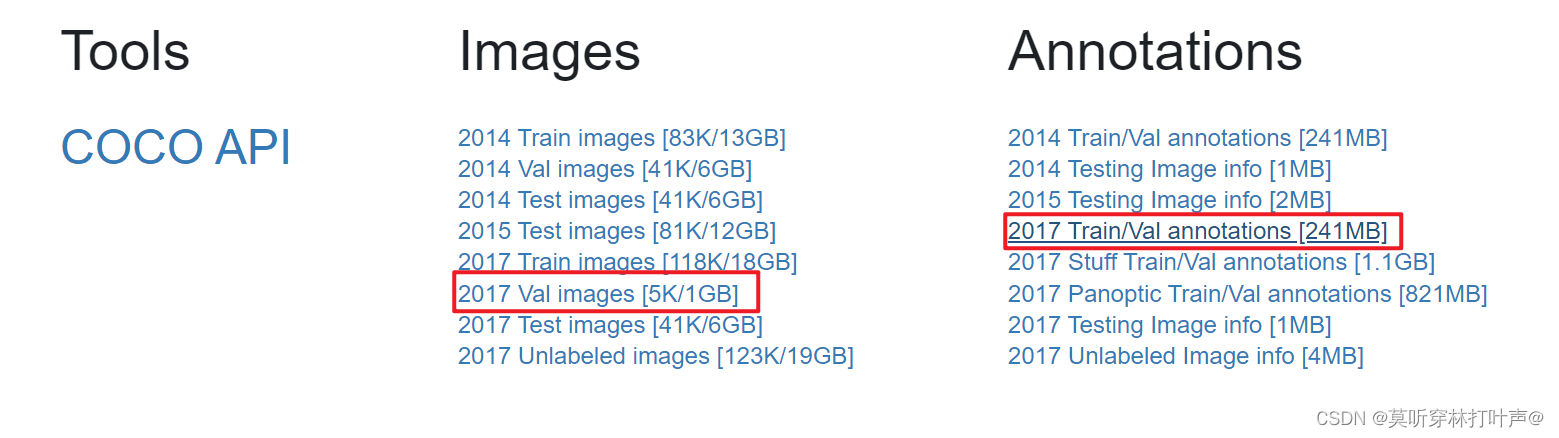
val2017:里面是图片。
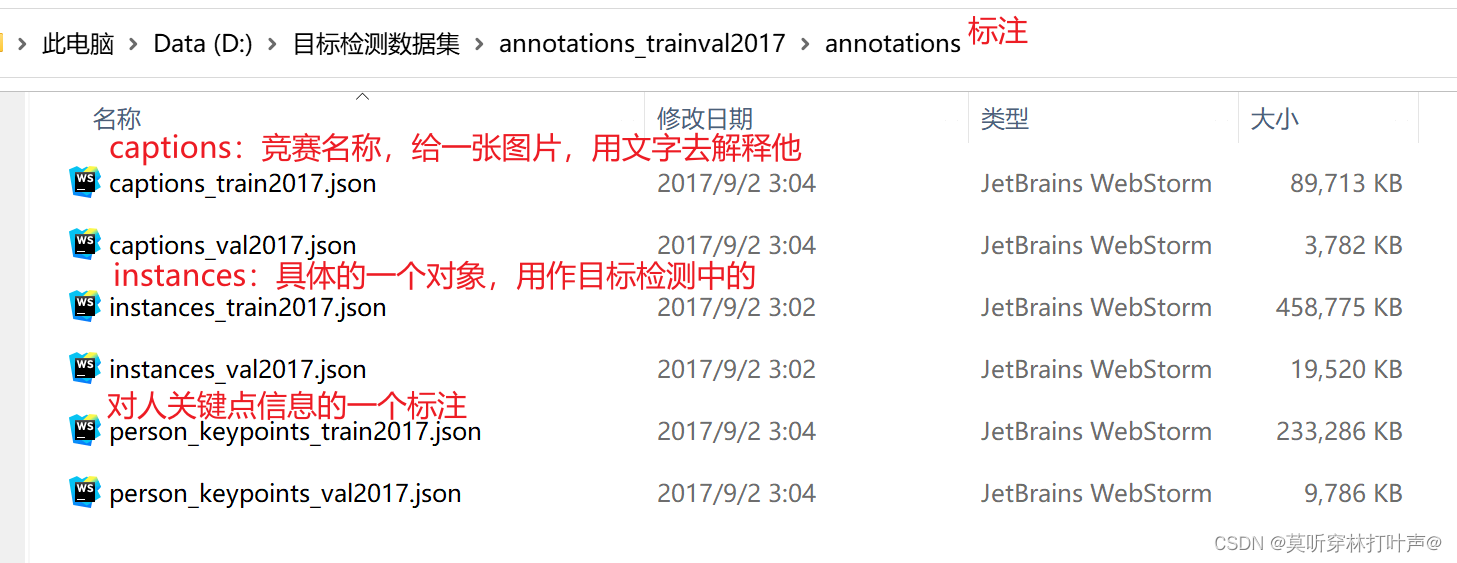
打开任意的一个instance的json文件,发现很大,这里用一小部分举例子(只有两张图片)。
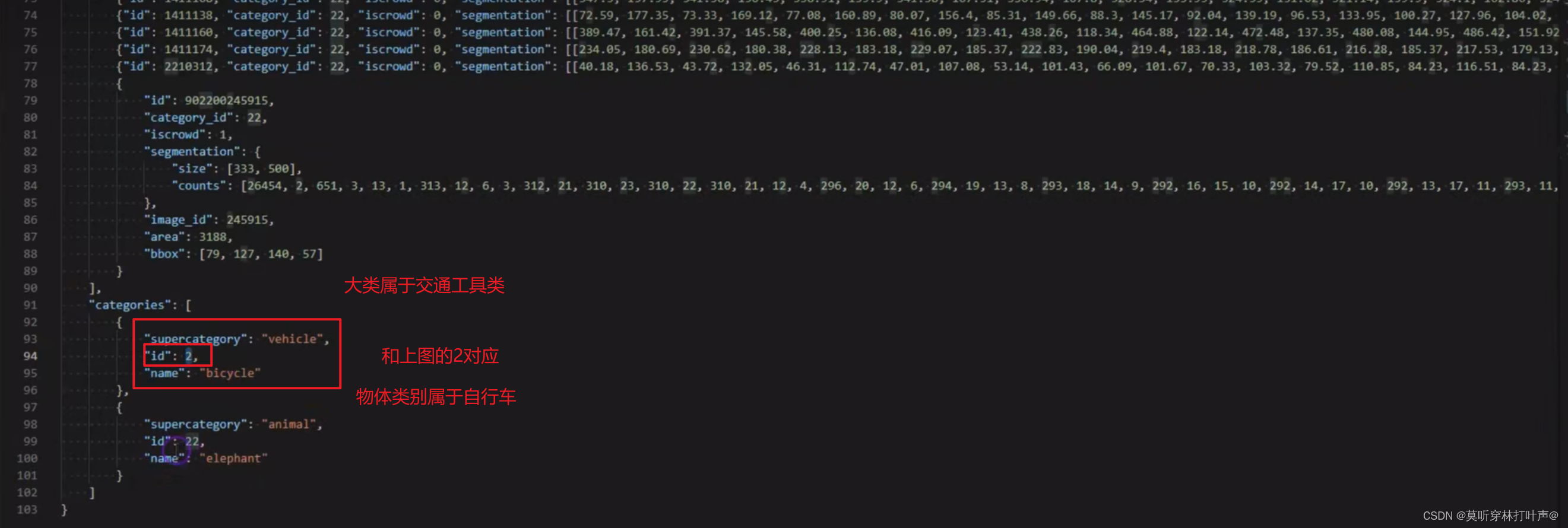
图片中没有群体的情况:


图片中有群体的情况:
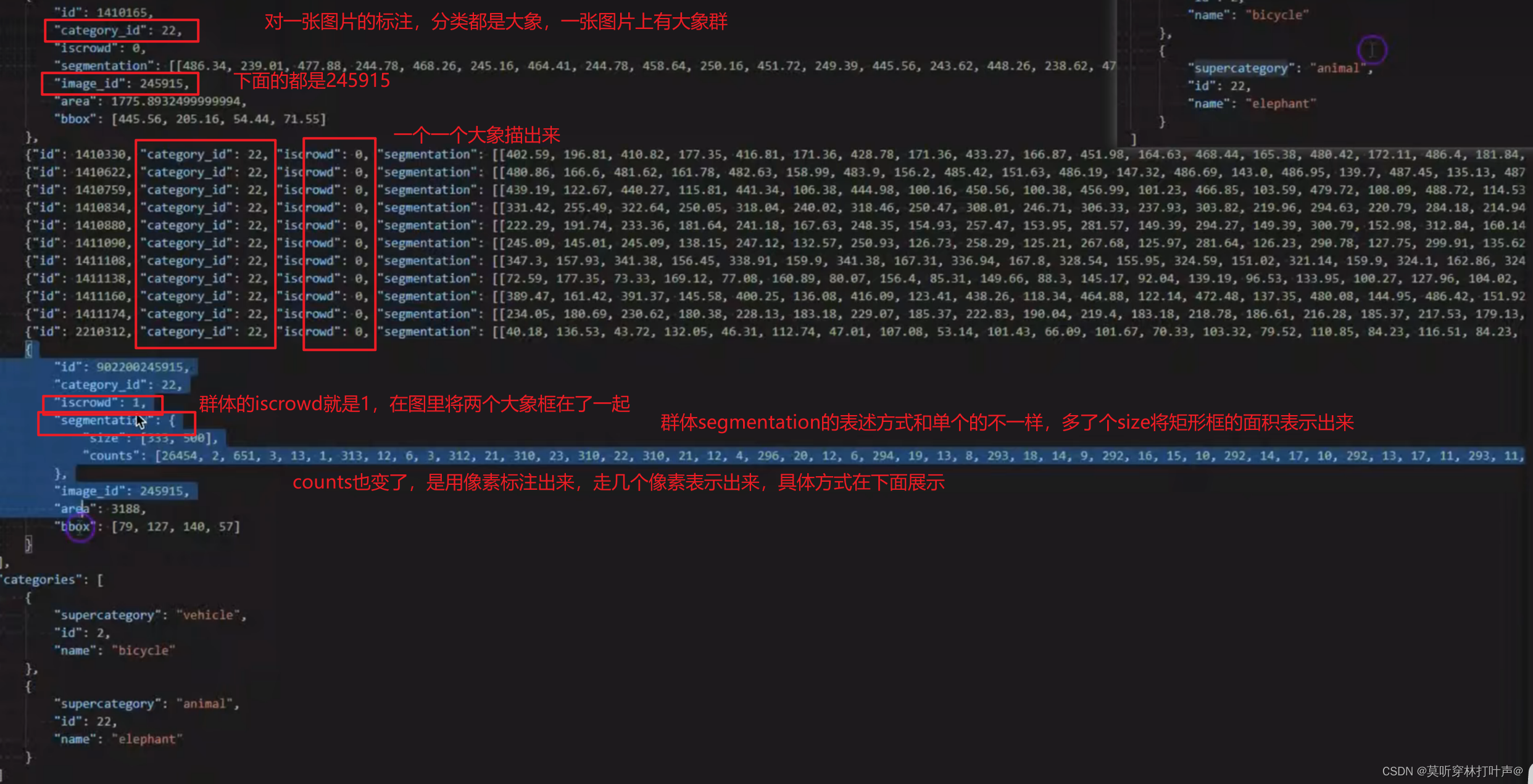

segmentation中的counts表述方式为:



