
- 1Flink学习(二) job 执行流程
- 2代码提交规范-ESLint+Prettier+husky+Commitlint_eslint commit husky
- 3部门异地办公研讨会_每个团队都计划在本月召开一次异地会议
- 4vue的git代码提交报错_vue3 git提交报错
- 5小黄鸟抓包京东APPCK_小黄鸟 ck
- 6Wheeltec小车的开发实录(1)_build.make:498: recipe for target '/home/wheeltec/
- 7参数高效微调(PEFT)技术概览
- 8CSDN新星计划/原力计划来喽,对此你有何期待_csdn实力新星多久奖励能领到
- 9Flink CDC在阿里云DataWorks数据集成应用实践
- 10【有料】Redis中的LRU淘汰策略分析_lru淘汰策略有两种
数据仓库-基础知识(维度建模)_数据仓库维度建模
赞
踩
一、数据仓库概述
1.1 数据仓库定义
数据仓库:Data Warehouse,是为企业所决策制定过程,提供所有支持类型的数据集合。用于分析性报告和决策支持。数仓是一个面向主题、集成的、相对稳定、反应历史变化的数据集合,随着大数据技术的发展,其作用不再局限于决策分析、还可以为业务应用、审计、追踪溯源等多方面提供数据支撑,帮助企业完成数字化转型。
1.2 数据仓库特点
-
面向主题
-
普通的操作型数据库主要面向事务性处理,而数据仓库中的所有数据一般按照主题进行划分。主题是对业务数据的抽象,是从较高层次上对信息系统中的数据进行归纳和整理。
-
集成性
-
面向操作型的数据库通常是异构的、并且相互独立,所以无法对信息进行概括和反映信息的本质。而数据仓库中的数据是经过数据的抽取、清洗、切换、加载得到的,所以为了保证数据不存在二义性,必须对数据进行编码统一和汇总,以保证数仓内的数据一致性,消除冗余数据。
-
稳定性
-
数据仓库中的数据反映的都是一段历史时期的数据内容,它的主要操作是查询、分析而不进行一般意义上的更新(操作型数据库主要完成数据的增加、修改、删除、查询),一旦某个数据进入到数据仓库后,一般情况下数据会被长期保留,当超过规定的期限才会被删除。通常数据仓库需要做的工作就是加载、查询和分析,一般不进行修改操作。
-
反映历史变化
-
数据仓库不断从操作型数据库或其他数据源获取变化的数据,从而分析和预测需要的历史数据,所以一般数据仓库中数据表的维度与事实表中都含有时间键,以表明数据的历史时期信息,然后不断增加新的数据内容。通过这些历史信息可以对企业的发展历程和趋势做出分析和预测。数据仓库的建设需要大量的业务数据作为积累,并将这些宝贵的历史信息经过加工、整理,最后提供给决策分析人员,这是数据仓库建设的根本目的。
1.3 数据库与数据仓库的区别
-
数据库
-
用于OLTP(On-Line Transaction Processing 联机事务处理过程),主要用于操作型处理
-
数据库是面向事物处理的,数据是由日常的业务产生的,常更新;
-
数据库一般用来存储当前事务性数据,如交易数据、业务数据;
-
数据库的设计一般是符合三范式的,有最大的精确度和最小的冗余度,有利于数据的插入;
-
数据仓库
-
用于OLAP(On-Line Analytical Processing 联机事务分析过程),支持管理决策。
-
数据仓库是面向主题的,数据来源多样,经过一定的规则转换得到,用来分析。
-
数据仓库一般存储的历史数据。
-
数据仓库的设计一般不符合三范式,并且反规划范,有利于查询。
1.4 数据域与主题域的区别
-
主题域
主题域是按照数据分析应用的角度进行划分的,通常是联系较为紧密的数据主题的集合。可以根据业务的需求特点,将从业务系统划分的数据域重新划分至不同的主题域。如同图书馆面向社会不同群体的需求,对图书划分为经济类、医学类、哲学类、管理类等多个主题。
主题域的确定必须由最终用户和数据仓库的设计人员共同完成。
-
数据域
数据域是指面向业务分析,将业务过程或者维度进行抽象的集合。它是以业务系统的角度,对业务过程进行归纳,抽象出来的数据域。
-
数据域与主题域区别
数据域是自下而上,以业务数据视角来划分数据,一般进行完业务系统数据调研之后就可以进行数据域的划分,是对数据的分类。
主题域则自上而下,以业务分析视角来划分数据,一般进行完业务需求调研之后才可以进行主题域的划分,是对业务的分类。
一般情况 DWD 层划分数据域,DWS、数据集市划分主题域,ADS划分业务域
-
例子
面向业务系统划分数据域 —— 饭店采购的食材根据特点分别放置在了肉禽区、果蔬区、调味区
面向业务分析划分主题域—— 根据不同食客群体的口味将食材做成了江浙菜、鲁菜、川菜等
二、数数仓库分层设计
2.1 数仓分层的作用
-
清洗数据结构
每一个数据都有它的作用域,我们在使用表的时候能更方便的定位和理解
-
减少重复开发
规范数据分层,开发一些通用的中年层数据,能够减少极大的重复计算
-
把复杂问题简单化
将一个复杂的任务分解成多个步骤来完成,每一层主处理单一的步骤
-
屏蔽原始数据的异常,解耦
屏蔽业务的影响,不必改一次业务就需要重新接入数据
2.2 数仓分层概述
| ODS(operation data store) | 原始数据层,保持数据原貌不做处理 |
| DWD(data warehouse detail) | 明细数据层,基于维度建模理论进行构建,保持和ods一样的粒度,对数据进行清洗,整合,规范化,脱敏等处理 |
| DIM(Dimension) | 公共维度层,由维度表构成,基于维度建模理念,建立整个企业的一致性维度 |
| DWS(data warehouse service) | 数据服务层,基于dwd层的数据,整合汇总成分析某一个主题域的服务数据,一般是宽表 |
| ADS(application data store) | 数据应用层,提供数据产品和数据分析使用的数据,一般会放在ES、MYSQL等系统中使用 |
2.3 数仓构建流程
-
数据调研、划分主题域
通过与业务部门交流,建立数仓要解决的问题,确定数据分析或前端展现的主题和各个主题下的查询分析需求,主题要体现出某一方面的各分析维度和度量的之间的关系
-
明确统计指标
确定好主题后,需要考虑分析的各种指标,它们一般为数据值型数据,基于常用的度量可以进行复杂关键性的设计和计算,指标一般分为原子指标(业务过程的度量)、派生指标(原子指标+周期+粒度)、衍生指标(比率、比例)
-
构建总线矩阵
明确业务过程和维度所属的主题域、明确维度与业务过程的关系,最终形成一个总线矩阵图表。矩阵的行是一个个业务过程,列是一个个的维度,行列的交点表示业务过程与维度的关系,通常只包含事务性事实表
-
构建明细模型
DIM公共维度层:由维度表构成,基于维度建模理论,建立整个企业的一致性维度,维度是逻辑概念,是衡量和观察业务的角度,在划分数据域、构建总线矩阵时,需要结合对业务过程的分析定义维度
DWD明细事实表:将原始数据表和各个维度表进行关联生成事实表
-
构建汇总模型
基于原子指标、派生指标、衍生指标进行构建,一张汇总表通常包含业务过程相同,统计周期相同,统计粒度相同的多个派生指标
-
ETL以及代码实现
数据清洗、转换、加载、传输
-
数仓应用、结果验证
数据的分析应用,满足业务部门对数据进行分析的需求
-
数据管理
元数据治理、数据质量监控、数据血缘管理
三、数据仓库建模
3.1 建模方法论
3.1.1 维度建模模型
3.1.1.1 概述
是由数据仓库领域 Ralph Kimball大事倡导的,是最流行的数仓建模经典。以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。
3.1.1.2 事实表
3.1.1.2.1 事实表定义
事实表作为数仓建模的核心,紧紧围绕着业务过程来设计,通过获取描述业务过程的度量来表达业务过程,包含了引用的维度和业务过程有关的度量。事实表中一条记录所表达的业务细节程度被称为粒度(业务中的细节程度)。通常粒度可以通过两种方式来表达:一种是维度属性组合所表示的细节程度,另一种是所表示的具体业务含义。作为业务过程的度量,一般有可加性、半可加性、不可加性三种类型。
可加事实:是指可以按照与事实表相关的维度进行累加,例如事务性事实表中的事实
半可加事实:是指只能按照与事实表相关的一部分维度进行累加,例如周期型快照事实表中的事实,各仓库中商品的每天快照库存,按照仓库维度和商品维度可进行累加,不能按照时间维度进行累加
不可加事实:是指完全不具备可加性,例如比率型事实。不可加事实通常需要转化为可加事实,例如比率可转化为分子和分母
3.1.1.2.2 事实表分类
事务性事实表:用来记录业务过程,保存的是业务过程的原子操作事件,既最细粒度的操作事件,如订单流水,银行流水
-
数据更新方式:增量更新,只增加新的数据,不对旧的数据进行更改
周期性快照事实表:周期快照事实表以具有规律性的、可预见的时间间隔来记录事实(记录的不是明细数据),主要用于分析一些存量型(例如商品库存,账户余额)或者状态型(空气温度,行驶速度)指标。
-
数据更新方式:全量,每天一个快照
累积型快照事实表:用来描述过程开始和结束之间的关键步骤事件,覆盖过程的整个生命周期,通常具有多个日期字段来记录关键时间点;当过程随着生命周期不断变化时,记录也会随着过程的变化而被修改;
-
数据更新方式:全量,每天一个快照
无事实的实时表:事实表没有相关的度量
3.1.1.3 维度表
3.1.1.3.1 维度表定义
维度是用于分析事实所需要的多样环境,度量是事实,环境是维度,维度的设计过程就是确定维度属性的过程,作用主要是查询约束,分类汇总,以及排序等
3.1.1.3.2 维度设计的目标
-
尽可能生成丰富的维度属性,为下游的数据统计、分析、探查提供良好的基础
-
尽可能多底给出包括一些富有意义的文字性描述
-
区分数值型属性和事实
-
尽量沉淀出通用的维度属性,构建企业范围内一致性维度来构建总线架构
-
易用性: 模型可理解性高、访问复杂度低。用户能够方便地从模型中找到对应的数据表,并能够方便的查询和分析
3.1.1.3.3 维度设计基本方法
-
第一步:选择维度和新建维度,保证维度唯一
-
第二步:确定主维表,例如商品是主维度
-
第三步:确定相关维表,和商品相关的类目、品牌、卖家、店铺是相关联维度
-
第四步:确定维度属性
3.1.1.3.4 缓慢变化维度方案
-
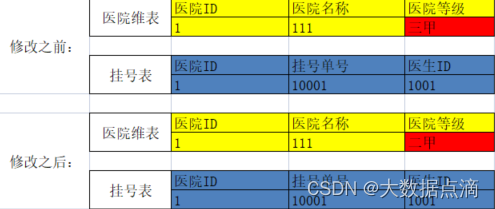
重写维度值
在维度表中,不保留历史数据,始终取最新数据,历史数据不可读
缺点:如果业务需要准确的跟踪历史变化,这种方案是比较慢实现,后续更改成本大
-
插入新的维度行
在维度表中,插入新的维度行,保留历史数据
缺点:数据会冗余,维护成本高,且该方式不能将变化前后的记录的事实归一位变化前的维度或者归一为变化后的维度

-
添加维度列
维度值每次变化就增加一个属性字段,或者保留最近的维度值,横向扩展,不易维护

-
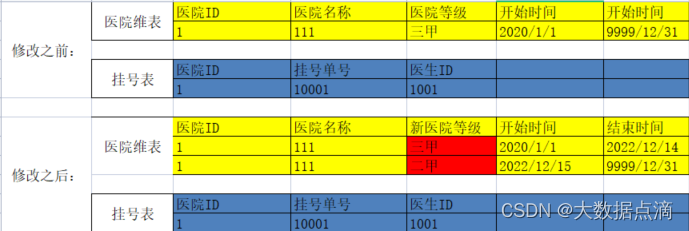
拉链表处理
可以精确跟踪变化维度属性的主要技术,记录数据的历史状态以及变化的记录 ,不把变化频繁的维度加入,避免维度过快增长,例如会员积分
3.1.1.3.5 多值维度及多值属性(交叉维度)
多值维度的处理方式:
如果事实表中一条记录在某个维度表中有多条记录与之对应,称为多值维度。例如,下单事实表中的一条记录为一个订单,一个订单可能包含多个商品,所会商品维度表中就可能有多条数据与之对应。
-
降低事实表的粒度,例如将订单事实表的粒度由一个订单降低为一个订单中的一个商品项。
-
采用多字段,每个字段保存一个维度id。这种方案只适用于多值维度个数固定的情况。
-
采用桥接表
多值属性的处理方式:
维表中的某个属性同时有多个值,称之为“多值属性”,例如商品维度的平台属性和销售属性,每个商品均有多个属性值。
-
保持维度主键不变,将多值属性放在维度的一个属性字段中,通过k-v对的形式
-
保持维度主键不变,将多值属性放在维度的多个属性字段中
-
维度主键大声变化,一个维度值存放多条记录
3.1.1.3.6 维度退化
退化维度(Degenerate Dimension,DD),就是那些看起来像是事实表的一个维度关键字,但实际上并没有对应的维度表。
维度除了主键外没有其他内容,例如,当某一发票包含多个数据项时,数据项事实行继承了发票的所有描述性维度外键,发票除了外键无其他项,但发票数量仍然是在此数据项级别的合法维度键。这种退化维度被放事实表中,清楚的表明没有关联的维度表,退化维度常见于交易和累计快照事实表中(Kimball书中描述)。
3.1.1.4 模型分类
维度建模一般分为三种:星型模型、雪花模型、星座模型
-
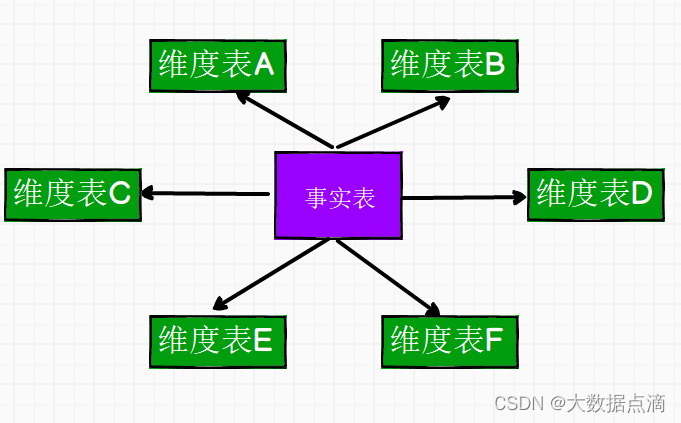
星型模型
星型模型中有一张事实表,以及零个或多个维度表,事实表与维度表通过主键外键相关联,维度表之间没有关联,形状像星星,故称星型模型
星型模型是一种非正规化的机构,多维数据集的每个维度直接与事实表想连接,不存在渐变维度,所以有一定的冗余
-
雪花模型
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的维度表,形成一些局部的“层次“区域,这些被分解的表都连接到主维度表而不是事实表。如图,将地域维表又分解为国家,省份,城市等维表。它的优点是:通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据几余

-
星座模型
星座模型是由星型模型延伸而来,星型模型是基于一张事实表而星座模式是基于多张事实表,并且共享维度表信息,这种模型往往应用于数据关系比星型模型和雪花模型更复杂的场合。星座模型需要多个事实表共享维度表,因而可以视为星形模型的集合,故亦被称为星系模型。
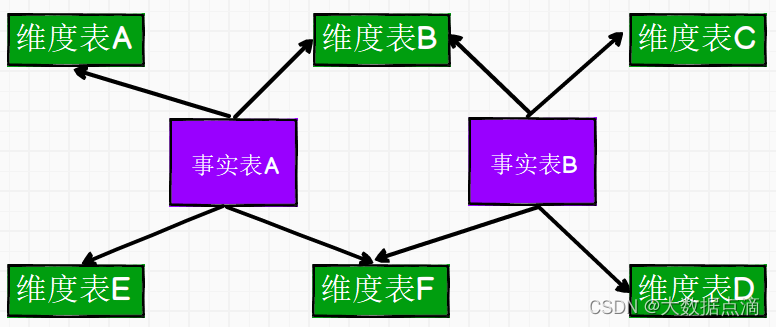
三种模型的对比:
-
星型模型和雪花模型主要区别就是对维度表的拆分,对于雪花模型,维度表的设计更加 规范,一般符合三范式设计;而星型模型,一般采用降维的操作,维度表设计不符合三范式 设计,反规范化,利用冗余牺牲空间来避免模型过于复杂,提高易用性和分析效率。
-
星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率 比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。
-
雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定 有星型模型高。
-
正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的 ETL、以 及后期的维护都要复杂一些。因此在冗余可以接受的前提下,数仓构建实际运用中星型模型 使用更多,也更有效率。
3.1.1.5 维度建模步骤
选择业务过程:业务过程是一个个不可拆分的行为事件,选择合适的业务,即确定事实表
声明粒度:声明粒度意味着精确定义事实表中的一行数据表示什么,应该尽可能选择最小的粒度
确认维度:确定与每张事务事实表相关的维度有哪些
确认事实:指的是每个业务过程的度量值(通常是可累加的数字类型的值,例如:次数、个数、件数、金额等)
3.1.2 ER模型(范式模型)
Entity Relationship, 由数据仓库之父Bill Inmon提出,是数据库设计的理论基础,当前几乎所有的OLTP系统设计都采用ER模型建的方式,这种建模方式基于三范式。在信息系统中,将事物抽象为 “实体”,“属性”,“关系”来表示数据关联和事物的描述,这种对数据的抽象建模就是ER模型
实体(Entity):实体是一个数据对象,指应用中可以区别的客观存在的事物。例如:商品、用户、学生、课程等。它具有自己的属性,一类有意义的实体构成实体集。在ER实体关系模型中实体使用方框表示。
属性:对实体的描述,修饰就是属性,即:实体的某一特性称为属性。例如:商品的重量、颜色、尺寸。用户的性别、身高、爱好等。在ER实体关系模型中属性使用椭圆来表示。
关系(Relationship):表示一个或多个实体之间的关联关系。实体不是孤立的,实体之间是有联系的,这就是关系。例如:用户是实体,商品是实体,用户选购商品这个过程就会产生“选购商品数量”,“金额”这些属性,这就是关系。再如:学生是实体,课程是实体,学生选择课程这个过程就产生了“课程数量”、“分数”这些属性,这就是关系。在ER实体关系模型中关系使用菱形框表示,并用线段将其与相关的实体链接起来.
ER实体关系模型又叫E-R关系图,实体与实体之间的关系存在一对一的关系、一对多的关系、多对多的关系。
第一范式:属性不可分割。说直接一点就是一列中不能包含多个属性第二范式:不能存在部分函数依赖第三范式:不能存在传递函数依赖
优点:节约存储,结构清晰
缺点:构建比较复杂,查询需要关联多表
3.1.3 Data Vault模型
Data Vault 是Dan Linstedt发起创建的一种模型,是ER模型的衍生,基于主题概念将企业数据进行结构化组织,并引入了更近一步的范式处理来优化模型,以及对原系统的变更的扩展性。也是为了实现数据的整合,但是不能直接用于数据分析决策,它强调建立一个可审计的基础数据,也就是强调数据的历史性,可追溯性和原子性,而不要求对数据进行过度的一致性处理和整合
3.1.4 Anchor模型
Anchor 对 Data Vault 模型做了进一步的规范化处理,它的核心思想是所有的扩展只是添加而不是修改,因此将模型规范到6NF,基本变成了k-v结构化模型
3.2 ER模型与维度建模模型对比
1、Inmon是自上而下的瀑布流开发方式,以数据源为导向,偏向三范式数据仓库建设,数据存储为最细粒度
Kinball架构是自下而上的开发方式,以业务需求为导向,一般使用维度建模方式,数据存储粒度来说,最细粒度及汇总数据都是可以提供的
2、Inmon架构存在真实数据集市(独立数据集市,有自己源数据和ETL架构),而Kimball数据架构不存在真实数据集市,只有通过主题域构建的虚拟数据集市。
3、Inmon数据仓库数据的读取只能通过数据集市,不能直接读取数据仓库的数据,但是Kimball数据架构的数据仓库数据可以直接对外提供。

