
- 1Spring5源码分析六
- 2CashFiesta 攻略_cashfiesta攻略
- 3如何从零开始搭建一套四旋翼无人机?
- 42021年全国职业院校技能大赛-网络搭建与应用赛项-公开赛卷(五)技能要求_所有用户使用漫游用户配置文件,配置文件存储在windows-1的 c:\profiles文件夹
- 5Git 多个账户,多个SSH配置_多个gitlab账号可以共用同一个ssh keys吗
- 6fastadmin二次开发使用教程php,fastAdmin插件开发教程之简明开发入门教程
- 7使用yolov8对视频进行实时检测_yolov8 检测视频
- 8用Django构建网上商城:django网上商城从零到有开发讲解_django商城
- 9Java网络爬虫——jsoup快速上手,爬取京东数据。同时解决‘京东安全’防爬问题_京东爬虫
- 10升级uniapp后小程序编译提示[ project.config.json 文件内容错误] project.config.json: libVersion 字段需为string
Title: CoCoOp:Conditional Prompt Learning for Vision-Language Models_cocoop模型论文
赞
踩
Authors:Kaiyang Zhou Jingkang Yang Chen Change Loy Ziwei Liu S-Lab, Nanyang Technological University, Singapore
code:https://github.com/KaiyangZhou/CoOp.git
paper:2203.05557.pdf (arxiv.org)
Abstract
随着预训练模型视觉-语言模型(如CLIP)能力的不断提升,探索如何将这些模型适应下游数据集或任务就显得很重要了。近期提出了CoOp方法引入了Prompt learning的概念。将视觉域是英语预训练的视觉-语言模型。具体的CoOp将提示的文本内容转换成了一些列可训练的向量,只采用少量的标签进行学习,其效果取得了远超密集人为提示(指的是ZSCLIP,其设定的模板是a photo is a {label}。),在我们的研究中,我们发现了CoOp存在一个严重的问题:学习的文本不足以泛化用于大量未知的样本类别,这表明CoOp对基本类别的训练是存在过拟合的。
为了解决这个问题,本文提出Conditional Context Optimization(CoCoOp),通过进一步的学习轻量级的神经网络为每个图像生成一个条件token(vector).这广泛的的扩展了CoOp。相比较于CoOp的静态提示(static prompts),我们的动态提示适用于每个案例因而对类别迁移具备更低的敏感性(less sensitive to class shift)。广泛性实验表明CoCoOp的泛化性比CoOp要更好针对于未见过的类别。甚至展示了超过了单个数据集的转移性同时也获得了更强大的域泛化能力。
好奇:泛化性是怎么测试和比较的?
Motivated
总结:CoOp在未知类别的检测过程中存在泛化性过低的情况,CoOp针对每个类别设计自学习的learnable进行设计,本文基于每个案例进行迁移设计。也就是condition Context Optimization.(下面的话可以不用看^__^!)
大尺寸预训练语言-视觉模型已经在zero-shot 图像识别领域已经取得了较大的进展,展示出了在开放世界中学习概念的潜力。这个关键设计在于可视化概念的建模。 在传统的监督学习中标签是离散的,每个类别采用一个随机的初始化权重向量来关联,通过学习优化图片间映射的最小化距离来表示包含相同的类别。这些方法重点在封闭视觉概念,受限于模型预定义的系列类别以及不可扩展。
相反,视觉语言模型相CLIP和ALIGN 模型,分类权重是通过一个参数化的文本编码器通过提示生成的。相对于离散化的标签,视觉-语言模型的超视觉的资源来源于自然语言,这允许开放的视觉概念可以进行广泛的探索 同时也证明其在可迁移表征上的有效性。随着强有力的视觉语言模型的增长,研究社区已经开始探索潜在的方法区有效的适应下游数据集。(如果针对CLIP这样的大模型采用finetuning的方式进行训练容纳更多的训练数据是不行的,一方面,这不切实际,另一方面,也会破坏大模型已经训练好的表征空间,这个大家都知道,按下不表)
比较安全的做法是通过添加一些文本来调优prompt。但prompt engineering 采用试错的方式是十分耗时和没有效率的,无法保证一个优化的提示。自动提示工程Zhou et al 近期探索提示学习的概念,一个近期的趋势在NLP中表现为自适应预训练的视觉语言模型。 Context Optimization(CoOp)将文本转换成一个可学习的向量。结合神经网络可微分的性质。通过少量标记样本的学习,与manual prompts 方法相比,CoOp实现了较大的提升。
CoOp存在重大问题:在同一个任务中,学习的文本时不可泛化的扩展到不可见的类别中。

如图1 展示,通过CoOp工作学习的文本在基础的学习类别中表现的很好,但是迁移到没有见过的类别中 如wind farm 和train railway中,尽管任务识别是相同的,但是这不同获取更多泛化性的元素用于更广的空间的识别。我们认为这个问题是CoOp的静态设计造成的:静态设计的定义:一旦训练完成,context是固定的,被优化用于具体的训练类别。相反的是,人为设计的zero shot prompts adoptor 相对来说更具有泛化性。(疑问,仅仅是针对这少量的图片或类别就可以断定CoOp的新类识别的泛化性少于CoCoOp).
为了解决弱泛化性的问题,本文引入新的概念:条件提示学习(conditional prompt learning) 这个关键是用一个prompt 条件状态于每个输入案例而不是一个固定的学习。为了使得模型的参数发更有效率,
引入了一个简单的且有效的conditional prompt learning.具体的,我们扩展CoOp通过进一步学习一个轻量型的神经网络为每个图像生成一个conditional token(vector)。我们叫这个方法为CoCoOp。 此方法类似于image captioning, 这个也解释了为什么instance conditional prompts可以更加泛化性:
他们是优化每一个案例(more robust to class shift)而不是服务于具体的一个类别。
Innovation
针对CoOp泛化性不强进行改进,在CoOp的基础上引入了Meta-Net 模型用以生成Meta-token,也就是每个案例的token,然后加上可学习的context tokens 一起进行解码和计算得到Class。
Approach
方法总览如图2所示,属于less is more系列。

针对CoOp泛化性不强进行改进,在CoOp的基础上引入了Meta-Net 模型用以生成Meta-token,也就是每个案例的token,然后加上可学习的context tokens 一起进行解码和计算得到Class。
Contrastive Language-Image Pre-training
对比语言和图像学习预训练模型如CLIP, 已经很好的证明了学习开放视觉概念的学习,CLIP建立于两个encoders的基础上。在训练的过程中,CLIP采用了一个对比损失用于学习两种模态的联合的嵌入空间。具体的是一个小鼻梁的图像和文本对,CLIP最大化每个图片预期匹配的文本的cosine similarity. 经过训练CLIP可以用于zero-shot 图像识别。让表示图像编码器生成的图像特征,
是文本编码器产生的权重向量,每个可以表示一个类别。总计有K个类别,具体的是
是一个提示,如 a photo of a {class } 其中class token 就是第i个类别的名字。所以预测的概率是
其中sim 表示cosine similarity, 表示学习的温度参数。
CoOp 表示旨在克服prompt engineering领域中低效率问题,用于使预训练视觉-语言模型更好的应用于下游的应用。 CoOp的核心思路是使用连续的向量来端到端的学习建模来自数据的每个文本token。CoOp引入M个可学习的文本向量,每个有相同维度的词向量,用
表示第i个类别,那么
,
是词向量的类别。这个context vectors是所有类别共享的,使用
表示文本编码器,预测的概率则是
为了适应CLIP到下游任务,使用交叉熵(CE Loss)作为学习目标,因此text encoder(文本编码器)是可以微分的,可以更新所有的文本向量。但是基本的CLIP在整个训练过程中是冻结的。
CoCoOp:Conditional Context Optimization
CoOp是一个数据有效的方法,通过少量标记图片就可以训练好文本向量,然而,由于认为CoOp在同一任务中不具备足够的泛化能力扩展到没有见过的类别的划分中去。我们认为个例级别的条件文本时可以泛化的很好的,因为它可以偏移集中于一些具体的类别中去,减少过拟合。
直观的方式应用CoCoOp时构建M个神经网络得到M个context tokens。 然而,这些设计需要M倍东西啊小的神经网络,这个比M个内容的文本向量要大很多,因此,选择一个参数和效率的设计方法,实际中表现也比较好。 具体的是,这里再M个文本向量中,我们进一步学习一个一个轻量级的神经网络,叫做Meta-Net, 生成每个输入的条件token(condition token), 当我们采用表示Meta-Net,
表示网络参数。
, 当
同时
.第i个类的提示因此可以编码为输入
, 这个预测的概率可以计算为
训练期间,通过参数更新context vectors
. Meta-Net使用的是两层bottleneck 结构Linear-ReLU-Linear, hidden layer 减少了输入特征16x,输入为图像编码器的输出。
Experiments
training details
ViT-B/16 zhot . Learning to prompt for vision-language models 说短的context length表现会更好,因此,训练的长度固定为4,初始化的词嵌入初始化为“a photo of a {label}”。(这里有些好奇长度固定为4表现最好?难道是原来CLIP训练时的影响?)
此外,由于CoCoOp的增加了instance-condition,需要更大的显存,GPU训练bs为1。
generalization fom base to new classes with in a dataset

其中CLIP表示的zero-shot,CoOp表示是16shot,CoCoOp也是16shot。Base表示训练的抽样16shot,new表示unseen类别。使用原来的测试集用于测试。H表示调和平均数,导数的和再求平均后再倒数。重点看几个精度低的类,B,E, H,I,DTD,EuroSAT,UCF101表现堵在90以下。可能是原有的clip对这类数据的包含量较少。也可以说域偏移较大(暂定表述)
此外,我们可以关注到,在CLIP中,BASE的精度要低于NEW的,但是在CoOp和CoCoOp中,所有的BASE是要高于NEW类的精度。尽管每个类的检测困难度不一样,但是统一的基类要比新类预测高是符合overfit的可能的。特别关注到一些CLIP表现精度低的数据集,特别如DTD,EuroSAT, UCF101等,CLIP的新类要比CoOp和CoCoOp的都要好,此外,基本上,CLIP在NEW的测试比其它两个方法的验证精度要高。这其实也侧面印证了CLIP的泛化性其实最强。依次是CLIP>CoCoOp>CoOp。
对比CoCoOp与CoOp,CoCoOp的拟合程度还是要好一些。

CoCoOp Is More Compelling Than CLIP
CLIP有更好的表现,CoCoOp胜了CLIP 4/11个数据集,但是CLIP超过的数据集超的也不多,除了FGVCA之外,后续在Context length的消融实验中,发现FGVCA实际上是适合longer Context,这个与zhou et al的发现也是吻合的。 在人为设定的规则和自动学习的提示的方法中在unseen的学习中仍存在较大的差距。
跨数据集比较:如表3所示,基本上CoCoOp要比CoOp表现要好些,这些数据集中可能有些类别是相同的。

Context Length
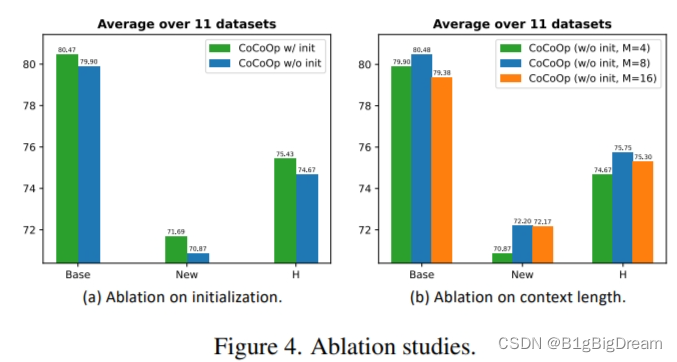
总体来说 M( context tokens)取值为4,8,16 我们可以看到,在基类中BASE最好的表现是M=8, 当M=16时不升反降。在新类的表现M=8和M=16精度类似。但是比M=4要高2个点左右。H的趋势受到BASE类的影响。 这里有个疑问,为什么不在表格1中选M=8时最好的表现与CoOp与CLIP进行泛化性比较?是CoOp和CLIP的长度为4么?
CoCoOp vs a Bigger CoOp

这里比较了参数相当并不会提升性能,但是我想ctx可以为8与CoOp比较一下?因为在上文的描述中,ctx越长,反而是会下降的。这里需要继续探讨一下!
Conclusion
该方案的总体性能比CoOp和CLIP要好,在新类迁移上相比CLIP还是存在一定的差距。这个原因可能归咎于prompt训练原本就会倾向于base 类别的过拟合。这个也合理。但是否可以弥补这一差距? how to do it?
此外,CoCoOp的训练要比CoOp训练效率慢很多,CoCoOp需要每张图片的prompt独立前向通过文本编辑器,这个比CoOp只需要单个的 prompt通过文本编辑器要小很多,也更有效率。但也不仅于此,再反向的时候,是不是也需要反向通过text CoCoOp来获得梯度调整Meta-Net的参数?
总体来说,这个问题解决了一个预训练AI模型适应下游任务的方法。这种foundation model AI大模型不管在学术界还是工业界已经引起了较大的关注,它们的能力志强足以适应下游的任务,基础大模型在数据尺度和计算资源独有较大的耗费。较大的参数量用以满足性能需求,CLIP模型的ViT-b/16就有巨大的150M的参数。 这些因素催生了导致了对基础模型平民化有效适应及应用方法的研究需求。
it would be interesting to see if such an idea can scale to, e.g., bigger model size for the Meta-Net, larger-scale training images, and even hetero-geneous training data mixed with different datasets 这是作者最后的寄语可能的改进方向举例!各位看官自取或移步原文观看!

