
- 1[算法]广度优先搜索VS深度优先搜索_广度优先搜索和深度优先搜索
- 2Ubuntu安装Kali全套渗透测试工具教程
- 3php从mysql中统计人数_PHP+Mysql+jQuery统计当前在线用户数
- 4宜搭低代码开发师(高级)考试选择题(超级详细版)_以下属于宜搭连接器的类型的有
- 5网络安全(黑客)—2024最新自学笔记
- 6华为OD机试真题-中文分词模拟器-2023年OD统一考试(C卷)_中文分词模拟器 给定一个连续不包含空格字符串,该字符串仅包含英文小写字母及英文
- 7从Tensorflow模型文件中解析并显示网络结构图(CKPT模型篇)_拆ckpt模型
- 8ELk日志平台搭建_elk日志监控平台
- 9存档解密之Protobuf反序列化
- 10计算机毕设Python+Vue智慧工地管理系统(程序+LW+部署)_智慧工地python
零次学习(Zero-Shot Learning)_零样本学习
赞
踩
零次学习(Zero-Shot Learning)
零样本学习zero-shot learning,是最具挑战的机器识别方法之一。2009年,Lampert 等人提出了Animals with Attributes数据集和经典的基于属性学习的算法,开始让这一算法引起广泛关注。
零样本学习涉及的主要数据,
- 已知类:模型训练时用到的带类别标签的。
- 未知类:模型测试、训练时不知道类别标签的。
- 辅助信息:对已知类和未知类data的描述/语义属性/词嵌入等信息。该信息充当了已知类和未知类之间的桥梁。
Zero-Shot Learning (ZSL)是机器学习中的一种策略,其目标是使模型能够理解并识别它在训练阶段未曾遇到过的类别。
- 这个概念首次被引入是为了解决现实世界中类别过多、每个类别的样本过少的问题。
- 基于这个理念,如果有一种方法可以让机器学习模型理解未曾见过的新类别,那将是极其有用的。
原理:
在ZSL中,模型通常会接受到一些额外的信息,用来帮助理解新的类别。
- 这种信息通常是以人类可理解的形式提供的,如文本描述、属性列表或是语义向量等。
- 模型通过学习已知类别和这些附加信息之间的映射,从而理解新的类别。
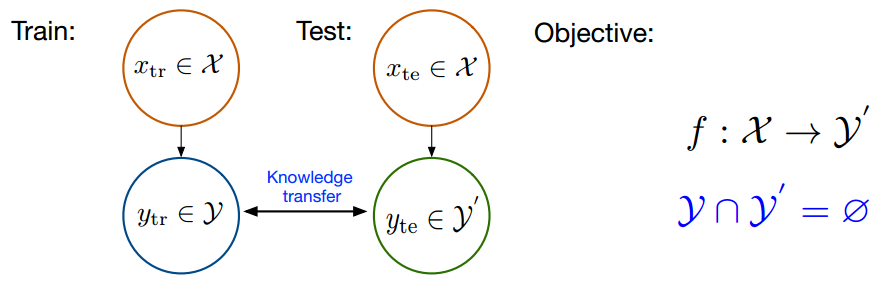
举例
例如,一个图像分类模型在训练时可能只见过“猫”、“狗”和“鸟”这三个类别的图像。
- 在ZSL的设置下,我们可能希望模型能处理“马”的图像。
- 为了达到这个目标,我们可能会给模型一个关于“马”的描述
- 比如“马是一种有四条腿和一条长尾巴的动物”
- 然后让模型通过这个描述来理解“马”的类别。
目前的研究方式
在上文中提到,要实现ZSL功能似乎需要解决两个部分的问题:
- 第一个问题是获取合适的类别描述
- 第二个问题是建立一个合适的分类模型
目前大部分工作都集中在第二个问题上,而第一个问题的研究进展比较缓慢。

发展与现状
ZSL的研究工作从最初的文本和图像的跨模态学习扩展到了许多其他领域,如视频分析、语音识别等。
- 同时,ZSL的方法也在逐渐改进,比如从原始的属性标签学习扩展到了使用深度学习模型学习更高层次的语义信息。
难点
ZSL的主要难点在于如何建立有效的已知类别到未知类别的映射
- 以及如何处理模型在训练和测试阶段面临的数据分布不同的问题(这被称为领域偏移或领域间隔问题)。
创新点
ZSL的主要创新在于提出了一种新的学习范式,该范式允许模型处理在训练阶段未曾见过的类别。
- 此外,ZSL还尝试使用人类可理解的语义信息来帮助模型理解新的类别,这在传统的监督学习方法中是没有的。
一般过程
零次学习(Zero-Shot Learning,ZSL)的基本原理是通过学习已知类别和语义描述之间的映射,从而理解并识别新的、未曾见过的类别。
- 在许多ZSL模型中,我们需要一种方式来表示类别的语义信息,这通常是通过所谓的属性向量或者类别嵌入向量实现的。
以下是一个简化的版本的ZSL的一般过程:
-
类别嵌入:首先,我们需要一个能够表示类别语义信息的向量。这可以通过一组预定义的属性(例如,“有羽毛”、“能飞”等)实现,也可以通过其他方式实现,比如将类别名称输入一个预训练的词嵌入模型(如Word2Vec或GloVe)得到的向量。
-
特征抽取:然后,我们需要从输入数据(例如,图像或文本)中抽取特征。这通常可以通过一个预训练的深度神经网络实现。
-
映射学习:接着,我们需要学习一个映射,将输入数据的特征空间映射到类别嵌入空间。这可以通过多种方式实现,例如,可以训练一个神经网络,使得同一类别的样本的特征在类别嵌入空间中尽可能接近,而不同类别的样本的特征在类别嵌入空间中尽可能远离。这个过程可以通过最小化某种距离或损失函数实现,例如,可以使用余弦距离或者交叉熵损失。
以上是ZSL的基本流程。
当然,实际的ZSL模型可能会更加复杂,例如,可能会考虑类别间的关系,或者使用更复杂的映射函数等。
具体实现
对于 Zero-Shot Learning (ZSL) 的具体实现,常见的方法之一是利用视觉-语义映射。
我们来详细介绍一下这个过程:
1. 视觉特征提取:我们首先从输入样本中提取视觉特征。假设我们的输入样本是图像,我们可以使用卷积神经网络(CNN)来提取特征。我们用φ(·)来表示特征提取函数,那么对于一个输入图像x,我们可以得到它的视觉特征φ(x)。
2. 语义嵌入:我们需要一种方式来表示类别的语义信息。这可以通过词嵌入模型实现,比如Word2Vec或GloVe。我们用ψ(·)来表示词嵌入函数,那么对于一个类别c,我们可以得到它的语义嵌入ψ(c)。
3. 视觉-语义映射:接着,我们需要学习一个映射函数f(·),它能够将视觉特征空间映射到语义嵌入空间。假设我们有一个数据集D = {(x1, c1), (x2, c2), ..., (xn, cn)},其中xi是图像,ci是对应的类别。我们的目标是学习映射函数f(·),使得对于所有的样本,f(φ(xi))尽可能接近ψ(ci)。这个过程可以通过最小化以下损失函数来实现:
L = Σ ||f(φ(xi)) - ψ(ci)||^2
- 1
这里||·||^2表示平方L2范数,也就是欧氏距离。Σ表示对所有样本求和。
在训练过程中,我们通过反向传播和梯度下降等优化方法来最小化损失函数,从而学习到映射函数f(·)。
4. 预测:在测试阶段,给定一个新的图像x,我们首先用f(φ(x))得到它在语义嵌入空间中的表示,然后找到最接近的语义嵌入ψ(c),对应的类别c就是我们的预测结果。
这就是视觉-语义映射方法在 ZSL 中的应用。请注意,这只是其中一种方法,实际上 ZSL 的实现方法有很多种,每种方法都有其优点和局限。
简化的实现过程
在Zero-Shot Learning(ZSL)中,一个常见的框架是直接学习从视觉特征到语义嵌入空间的映射。假设我们有一个函数f(·)来提取输入样本的特征,一个函数g(·)来表示类别的语义信息,我们的目标是学习一个映射函数h(·),使得我们可以用h(f(x))来预测样本x的类别。
给出更具体的数学形式,假设我们有一个数据集D = {(x1, y1), (x2, y2), ..., (xn, yn)},其中xi是样本,yi是对应的类别标签。每个类别y都对应一个语义嵌入g(y)。我们的目标是学习一个映射函数h(·),使得对于所有的样本,h(f(xi))尽可能接近g(yi)。这可以通过最小化以下损失函数来实现:
L = Σ ||h(f(xi)) - g(yi)||^2
- 1
这里||·||^2表示平方L2范数,也就是欧氏距离。Σ表示对所有样本求和。
在测试阶段,给定一个新的样本x,我们首先用h(f(x))得到它在语义嵌入空间中的表示,然后找到最接近的语义嵌入g(y),对应的类别y就是我们的预测结果。
请注意,这只是ZSL的一个非常简化的版本,实际的ZSL模型可能会考虑更复杂的情况,例如类别间的关系,或者使用更复杂的映射函数等。
此外,以上的公式并没有考虑正则化项,实际使用时通常会加上一些正则化项以防止过拟合。
研究论文参考
零次学习(Zero-Shot Learning,ZSL)是一个非常活跃的研究领域,有很多重要和有影响力的论文。以下是一些经典和重要的论文:
-
Attribute-based Classification for Zero-Shot Visual Object Categorization
- 论文链接: [https://ieeexplore.ieee.org/abstract/document/6247951]
- 概述: 这篇论文是ZSL领域的早期工作,作者提出了基于属性的分类方法,可以处理未在训练集中出现的类别。
-
Zero-Shot Learning through Cross-Modal Transfer
- 论文链接: [https://papers.nips.cc/paper/2013/hash/9aa42b31882ec039965f3c4923ce901b-Abstract.html]
- 概述: 这篇论文提出了通过跨模态转移进行ZSL的方法。这篇论文的一个重要贡献是提出了在训练和测试阶段使用不同的特征的问题。
-
Zero-Shot Learning - A Comprehensive Evaluation of the Good, the Bad and the Ugly
- 论文链接: [https://arxiv.org/abs/1707.00600]
- 概述: 这篇论文对ZSL进行了全面的评估。作者指出了现有方法的一些问题,并提出了新的评估协议。
对于多模态的ZSL,也有一些重要的工作,例如:
-
Zero-Shot Learning of Class Semantics via Temporal Attention
- 论文链接: [https://arxiv.org/abs/1809.00116]
- 概述: 这篇论文研究了如何利用视频中的动态信息进行ZSL。作者提出了一个基于时间注意力机制的模型,可以学习到类别的语义信息。
-
Learning Semantic Models for Cross-Modal Zero-Shot Sketch Data Retrieval
- 论文链接: [https://www.sciencedirect.com/science/article/abs/pii/S0031320318303701]
- 概述: 这篇论文研究了如何进行跨模态的零次学习,特别是在草图数据检索的任务中。
以上这些论文只是零次学习领域的冰山一角,具体选择哪篇论文取决于你的具体需求和兴趣。我建议你在阅读这些论文的同时,也查阅一下他们的引用文献,以了解更多相关的工作。

