
- 1AI大模型探索之路-训练篇1:大语言模型微调基础认知
- 2【亲为】yoloV8收集数据->数据标注->数据集训练->模型验证
- 3git查看修改用户名、密码、邮箱_git config user.password
- 4java8 映射方法(map,flatMap)_java mapper.map list映射
- 5WPF Menu动态绑定View_wpf mvvm绑定菜单
- 6基于TI Sitara Cortex-A8的USB网口模块测试_lan9500a驱动程序
- 7Python Flask简介及安装_flask_login安装包
- 8Linux tar命令教程:文件打包和压缩的神器(附案例详解和注意事项)_tar 打包文件
- 92024最新付费短剧追剧影视小程序源码,带支付收益_短剧源码
- 10Jenkins构建时间与服务器时间不同最简单解决方案_jenkins docker里面时间和外面不一样
【Flink】Flink 1.14.0 全新的 Kafka Connector_cannot resolve org.apache.flink:flink-connector-ka
赞
踩

1.概述
转载并且补充:Flink 1.14.0 全新的 Kafka Connector
扩展:【Flink】Flink 1.13 版本 KafkaSource 代码解读
Flink 提供了一个 Apache Kafka 连接器,用于从 Kafka Topic 读取数据和向 Kafka Topic 写入数据,并保证恰好一次次语义。
2.Dependency
Apache Flink 附带了一个通用的 Kafka 连接器,它试图跟踪最新版本的 Kafka 客户端。它使用的客户端版本可能会在 Flink 版本之间发生变化。最近的 Kafka 客户端向后兼容 broker 版本 0.10.0 或更高版本。关于 Kafka 兼容性的详细信息,请参考 Kafka 官方 文档。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.14.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
Flink 的流连接器目前不是二进制发行版的一部分。在此处 查看如何与它们链接以进行集群执行。
3.Kafka Source
本部分介绍基于新 数据源 API 的 Kafka Source。
Kafka Source 提供了一个 builder 类来构建 KafkaSource 的实例。下面的代码片段展示了如何构建一个 KafkaSource 来消费来自主题 “input-topic” 最早偏移量的消息,消费者组是“my-group”,并且仅将消息的值反序列化为字符串。
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("input-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
构建 KafkaSource 「需要」以下属性:
- Bootstrap servers,通过 setBootstrapServers(String)来配置
- Topics / partitions to subscribe,请参阅以下 主题-分区订阅 以了解更多详细信息。
- Deserializer to parse Kafka messages,更多详细信息请参见以下 Deserializer。
4.Topic-partition Subscription
Kafka 源码提供了 3 种 topic-partition 订阅方式:
主题列表,订阅主题列表中所有分区的消息。例如
KafkaSource.builder().setTopics("topic-a", "topic-b")
- 1
- 2
主题模式,从名称与提供的正则表达式匹配的所有主题订阅消息。例如:
KafkaSource.builder().setTopicPattern("topic.*")
- 1
- 2
分区集,订阅提供的分区集中的分区。例如:
final HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList(
- 1
- 2
5.Deserializer
解析 Kafka 消息需要一个反序列化器。Deserializer(反序列化模式)可以通过 配置setDeserializer(KafkaRecordDeserializationSchema),其中KafkaRecordDeserializationSchema定义了如何反序列化一个 Kafka ConsumerRecord。
如果只需要 Kafka ConsumerRecord的值,可以使用 setValueOnlyDeserializer(DeserializationSchema)在 builder 中使用,其中DeserializationSchema定义了如何反序列化 Kafka 消息值的二进制文件。
你还可以使用 Kafka Deserializer 来反序列化 Kafka 消息值. 例如使用 StringDeserializer 将 Kafka 消息值反序列化为字符串:
import org.apache.kafka.common.serialization.StringDeserializer;
KafkaSource.<String>builder()
.setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringSerializer.class));
- 1
- 2
- 3
- 4
- 5
- 6
6.Starting Offset
Kafka Source 能够通过指定 OffsetsInitializer来消费从不同偏移量开始的消息。内置的初始值设定项包括:
KafkaSource.builder()
// Start from committed offset of the consuming group, without reset strategy
.setStartingOffsets(OffsetsInitializer.committedOffsets())
// Start from committed offset, also use EARLIEST as reset strategy if committed offset doesn't exist
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))
// Start from the first record whose timestamp is greater than or equals a timestamp
.setStartingOffsets(OffsetsInitializer.timestamp(1592323200L))
// Start from earliest offset
.setStartingOffsets(OffsetsInitializer.earliest())
// Start from latest offset
.setStartingOffsets(OffsetsInitializer.latest())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果上面的内置初始值设定项无法满足你的要求,您还可以实现自定义偏移量初始值设定项。
如果未指定 offsets 初始值设定项,「则」默认使用 「OffsetsInitializer.earliest()」。
7.Boundedness
Kafka Source 旨在支持流式和批量运行模式。默认情况下,KafkaSource 设置为以流式方式运行,因此永远不会停止,直到 Flink 作业失败或被取消。您可以使用setBounded(OffsetsInitializer)指定停止偏移量并设置以批处理模式运行的源。当所有分区都达到它们的停止偏移量时,Source 将退出。
您还可以将 KafkaSource 设置为在流模式下运行,但仍然使用setUnbounded(OffsetsInitializer). 当所有分区达到其指定的停止偏移量时,Source 将退出。
8.Additional Properties
除了上述属性外,您还可以使用setProperties(Properties)和为 KafkaSource 和 KafkaConsumer 设置任意属性setProperty(String, String)。KafkaSource 有以下配置选项:
-
client.id.prefix定义用于 Kafka 消费者的客户端 ID 的前缀 -
partition.discovery.interval.ms定义 Kafka 源发现新分区的时间间隔 im 毫秒。有关更多详细信息,请参阅下面的 动态分区发现。 -
register.consumer.metrics指定是否在 Flink 指标组中注册 KafkaConsumer 的指标 -
commit.offsets.on.checkpoint指定是否在检查点向 Kafka broker 提交消费偏移量
KafkaConsumer 的配置可以参考 Apache Kafka文档 了解更多。
请注意,即使配置了以下键,构建器也会覆盖它:
key.deserializer 始终设置为 ByteArrayDeserializer
value.deserializer 始终设置为 ByteArrayDeserializer
auto.offset.reset.strategy 被起始偏移量覆盖 OffsetsInitializer#getAutoOffsetResetStrategy()
partition.discovery.interval.ms 被调用时被覆盖为 -1 setBounded(OffsetsInitializer)
- 1
- 2
- 3
- 4
下面的代码片段显示了配置 KafkaConsumer 以使用“PLAIN”作为 SASL 机制并提供 JAAS 配置:
KafkaSource.builder()
.setProperty("sasl.mechanism", "PLAIN")
.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" passw
- 1
- 2
- 3
- 4
9.Dynamic Partition Discovery
为了在不重启 Flink 作业的情况下处理主题扩展或主题创建等场景,可以将 Kafka 源配置为在提供的主题-分区订阅模式下定期发现新分区。要启用分区发现,请为 property 设置一个非负值partition.discovery.interval.ms:
KafkaSource.builder()
.setProperty("partition.discovery.interval.ms", "10000") //
- 1
- 2
默认情况下「禁用」分区发现。您需要明确设置分区发现间隔才能启用此功能。
10.Event Time and Watermarks
默认情况下,记录将使用嵌入在 Kafka 中的时间戳ConsumerRecord作为事件时间。您可以定义自己WatermarkStrategy的从记录本身提取事件时间,并在下游发出水印:
env.fromSource(kafkaSource, new CustomWatermarkStrategy(), "Kafka Source With Custom Watermark Strategy")
- 1
- 2
- 3
本文档 描述了有关如何定义WatermarkStrategy.
11 Consumer Offset Committing
Kafka source 在 checkpoint 「完成」时提交当前消费的 offset ,以保证 Flink 的 checkpoint 状态和 Kafka brokers 上的 commit offset 的一致性。
如果未启用检查点,则 Kafka 源依赖于 Kafka 消费者内部的自动定期偏移提交逻辑,由Kafka 消费者的属性配置enable.auto.commit并在其属性中配置auto.commit.interval.ms。
需要注意的是 Kafka source 不依赖提交偏移量来实现容错。提交偏移量只是为了暴露消费者和消费组的进度以供监控。
12.Monitoring
Kafka Source 在各自的 范围内 公开以下指标。
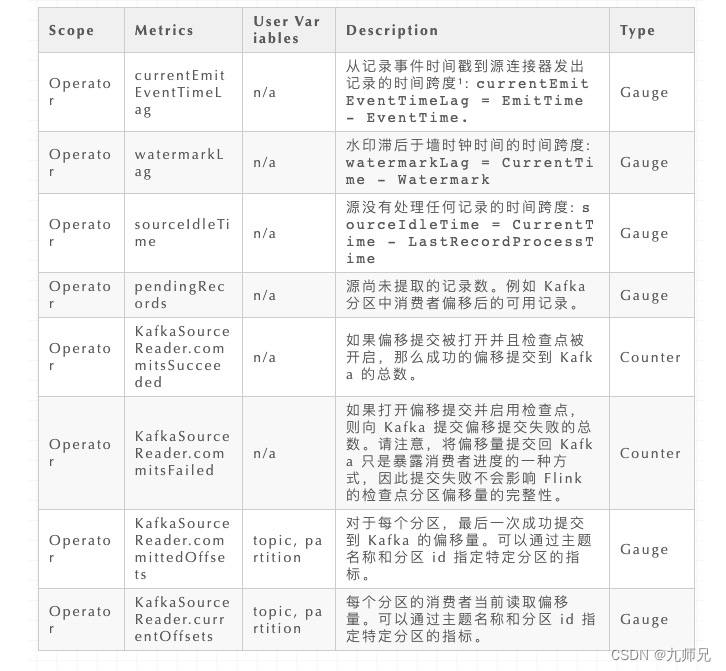
¹ 该指标是为最后处理的记录记录的瞬时值。提供此指标是因为延迟直方图可能很昂贵。瞬时延迟值通常足以很好地指示延迟。
12.1 Kafka Consumer Metrics
Kafka 消费者的所有指标也都注册在 group 下KafkaSourceReader.KafkaConsumer。例如,Kafka 消费者指标“records-consumed-total”将在指标中报告:
<some_parent_groups>.operator.KafkaSourceReader.KafkaConsumer.records-consumed-total。
- 1
您可以通过配置 option 来配置是否注册 Kafka 消费者的指标register.consumer.metrics。默认情况下,此选项将设置为 true。
对于 Kafka 消费者的指标,您可以参考 Apache Kafka 文档 了解更多详细信息。
13.Behind the Scene
如果您对 Kafka Source 在新数据源 API 的设计下如何工作感兴趣,您可能需要阅读此部分作为参考。有关新数据源 API 的详细信息,数据源 文档 和FLIP-27 提供了更多描述性讨论。
在新数据源 API 的抽象下,Kafka Source 由以下组件组成:
13.1 Source Split
Kafka Source 中的一个源拆分代表 Kafka 主题的一个分区。Kafka Source 拆分包括:
TopicPartition 分裂代表
分区的起始偏移量
停止分区的偏移量,仅在源以有界模式运行时可用
- 1
- 2
- 3
Kafka source split 的状态也存储了partition 的当前消费 offset,当 Kafka source reader 为 snapshot 时,状态会转换为 immutable split,将当前 offset 赋值给immutable split 的起始偏移量。
您可以查看类 KafkaPartitionSplit和KafkaPartitionSplitState`了解更多详情。
13.2 Split Enumerator
Kafka 的拆分枚举器负责在提供的主题分区订阅模式下发现新的拆分(分区),并将拆分分配给读者,以循环方式均匀分布在子任务中。请注意,Kafka Source 的拆分枚举器会急切地将拆分推送到源阅读器,因此它不需要处理来自源阅读器的拆分请求。
13.3 Source Reader
Kafka source 的 source reader 扩展了提供的SourceReaderBase,并使用单线程多路复用线程模型,该模型读取多个分配的拆分(分区),一个 KafkaConsumer 由一个 驱动SplitReader。消息在从 Kafka 中获取后立即反序列化SplitReader。拆分的状态或消息消费的当前进度由 更新KafkaRecordEmitter,它还负责在记录向下游发出时分配事件时间。
14.Kafka SourceFunction
FlinkKafkaConsumer已弃用,将随 Flink 1.15 一起删除,请使用 KafkaSource。
对于较旧的参考,您可以查看 Flink 1.13文档。
15.Kafka Sink
KafkaSink 允许将记录流写入一个或多个 Kafka 主题。
Kafka sink 提供了一个 builder 类来构造一个 KafkaSink 的实例。下面的代码片段显示了如何将字符串记录写入 Kafka 主题,并保证至少一次交付。
DataStream<String> stream = ...
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("topic-name")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
stream.sinkTo(sink);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
构建 KafkaSink 「需要」以下属性:
- Bootstrap servers, setBootstrapServers(String)
- Record serializer, setRecordSerializer(KafkaRecordSerializationSchema)
- 如果您配置交货保证 DeliveryGuarantee.EXACTLY_ONCE 你也必须设置 setTransactionalIdPrefix(String)`
15.1 Serializer
你始终需要提供一个KafkaRecordSerializationSchema以将传入元素从数据流转换为 Kafka 生产者记录。Flink 提供了一个模式构建器来提供一些常见的构建块,即键/值序列化、主题选择、分区。您也可以自行实现接口以施加更多控制。
KafkaRecordSerializationSchema.builder()
.setTopicSelector((element) -> {<your-topic-selection-logic>})
.setValueSerializationSchema(new SimpleStringSchema())
.setKeySerializationSchema(new SimpleStringSchema())
.setPartitioner(new FlinkFixedPartitioner())
.build();
- 1
- 2
- 3
- 4
- 5
- 6
据「需要」始终设定的值序列化方法和一个主题(选择方法)。此外,还可以通过使用setKafkaKeySerializer(Serializer)或来使用 Kafka 序列化器代替 Flink 序列化器setKafkaValueSerializer(Serializer)。
15.2 . Fault Tolerance
总的来说,KafkaSink支持三种不同的DeliveryGuarantees。ForDeliveryGuarantee.AT_LEAST_ONCE和DeliveryGuarantee.EXACTLY_ONCE。 Flink 的检查点必须启用。默认情况下KafkaSink使用DeliveryGuarantee.NONE. 您可以在下面找到对不同保证的解释。
-
DeliveryGuarantee.NONE不提供任何保证:如果 Kafka broker 出现问题,消息可能会丢失,如果 Flink 故障,消息可能会重复。 -
DeliveryGuarantee.AT_LEAST_ONCE:接收器将等待 Kafka 缓冲区中所有未完成的记录在检查点上由 Kafka 生产者确认。如果 Kafka 代理出现任何问题,则不会丢失任何消息,但是当 Flink 重新启动时,消息可能会重复,因为 Flink 会重新处理旧的输入记录。 -
DeliveryGuarantee.EXACTLY_ONCE:在这种模式下,KafkaSink 将写入 Kafka 事务中的所有消息,这些消息将在检查点上提交给 Kafka。因此,如果消费者只读取提交的数据(参见 Kafka 消费者配置隔离级别),则在 Flink 重启的情况下不会看到重复数据。但是,这会有效地延迟记录可见性,直到写入检查点,因此相应地调整检查点持续时间。请确保在同一 Kafka 集群上运行的应用程序中使用唯一的transactionalIdPrefix,这样多个正在运行的作业不会干扰它们的事务!此外,强烈建议调整Kafka 事务超时(请参阅 Kafka 生产者 transaction.timeout.ms)» 最大检查点持续时间 + 最大重启持续时间或当 Kafka 未提交的事务到期时可能会发生数据丢失。
15.2.Monitoring
Kafka sink 在各自的 scope 中 公开以下指标。

16.Kafka Producer
FlinkKafkaProducer已弃用,将随 Flink 1.15 一起删除,请使用 KafkaSink。
对于较旧的参考,您可以查看 Flink 1.13文档。
16.1 Kafka Connector Metrics
Flink 的 Kafka 连接器通过 Flink 的指标系统提供了一些指标来分析连接器的行为。生产者和消费者通过 Flink 的所有支持版本的指标系统导出 Kafka 的内部指标。Kafka 文档在其文档中列出了所有导出的指标。
也可以register.consumer.metrics通过本节概述的 KafkaSource 配置或在使用 KafkaSink 时禁用 Kafka 指标的转发,您可以通过生产者属性将配置设置register.producer.metrics为 false。
16.2 Enabling Kerberos Authentication
Flink 通过 Kafka 连接器提供一流的支持,以对为 Kerberos 配置的 Kafka 安装进行身份验证。只需配置 Flink的配置文件flink-conf.yaml即可为 Kafka 启用 Kerberos 身份验证,如下所示:
通过设置以下内容来配置 Kerberos 凭据 -
-
security.kerberos.login.use-ticket-cache:默认情况下,这是trueFlink 将尝试在由kinit. 请注意,在 YARN 上部署的 Flink 作业中使用 Kafka 连接器时,使用票证缓存的 Kerberos 授权将不起作用。 -
security.kerberos.login.keytab和security.kerberos.login.principal:要改用 Kerberos 密钥表,请为这两个属性设置值。
附加KafkaClient到`security.kerber启用基于 Kerberos 的 Flink 安全性后,您可以使用 Flink Kafka Consumer 或 Producer 向 Kafka 进行身份验证,只需在传递给内部 Kafka 客户端的提供的属性配置中包含以下两个设置:
设置security.protocol为SASL_PLAINTEXT(默认NONE):用于与 Kafka 代理通信的协议。使用独立的 Flink 部署时,也可以使用SASL_SSL; 请在此处查看如何为 SSL 配置 Kafka 客户端。
- 设置
sasl.kerberos.service.name为kafka(默认kafka):此值应与用于 Kafka 代理配置的值相匹配sasl.kerberos.service.name。客户端和服务器配置之间的服务名称不匹配将导致身份验证失败。
有关 Kerberos 安全性的 Flink 配置的更多信息,请参阅此处。您还可以在此处找到有关 Flink 如何在内部设置基于 Kerberos 的安全性的更多详细信息。os.login.contexts`:这告诉 Flink 将配置的 Kerberos 凭据提供给 Kafka 登录上下文以用于 Kafka 身份验证。
17.Upgrading to the Latest Connector Version#
升级作业和 Flink 版本指南中概述了通用升级步骤。对于 Kafka,您还需要执行以下步骤:
-
请勿同时升级 Flink 和 Kafka Connector 版本。
-
确保您为您的消费者配置了一个group.id。
-
在消费者上设置
setCommitOffsetsOnCheckpoints(true),以便将读取偏移量提交给 Kafka。在停止并获取保存点之前执行此操作很重要。您可能必须在旧的连接器版本上执行停止/重新启动循环才能启用此设置。 -
在消费者上设置
setStartFromGroupOffsets(true),以便我们从 Kafka 获得读取偏移量。这只有在 Flink 状态下没有读取偏移时才会生效,这也是下一步非常重要的原因。更改源/接收器的分配uid。这确保新的源/接收器不会从旧的源/接收器操作符读取状态。 -
开始新作业,–allow-non-restored-state因为我们在保存点中仍然拥有先前连接器版本的状态。
18.Troubleshooting
❝如果您在使用 Flink 时遇到 Kafka 问题,请记住,Flink 只包装了KafkaConsumer或KafkaProducer,您的问题可能与 Flink 无关,有时可以通过升级 Kafka brokers、重新配置 Kafka brokers 或重新配置KafkaConsumer或KafkaProducerin Flink 来解决。下面列出了一些常见问题的示例。
18.1 Data loss
根据您的 Kafka 配置,即使在 Kafka 确认写入之后,您仍然可能会遇到数据丢失的情况。特别要记住 Kafka 配置中的以下属性:
acks
log.flush.interval.messages
log.flush.interval.ms
log.flush.*
- 1
- 2
- 3
- 4
上述选项的默认值很容易导致数据丢失。更多解释请参考 Kafka 文档。
18.2 UnknownTopicOrPartitionException
此错误的一个可能原因是正在进行新的领导者选举时,例如在重新启动 Kafka Broker 之后或期间。这是一个可重试的异常,因此 Flink 作业应该能够重新启动并恢复正常运行。它也可以通过更改retries生产者设置中的属性来规避。然而,这可能会导致消息重新排序,反过来,如果不需要,可以通过设置为 1 来规避max.in.flight.requests.per.connection。
18.2 ProducerFencedException
此异常的原因很可能是代理端的事务超时。随着KAFKA-6119的实施,(producerId, epoch)将在事务超时后被隔离,并且其所有挂起的事务都被中止(每个transactional.id都映射到一个单独的事务producerId;这在下面的博客文章中有更详细的描述)。

