
- 1next 14 appRouter redux数据持久化_nextjs redux 持久化存储
- 2mac与windows服务器 访问和共享
- 3Android 15全面解读:性能飙升、隐私守护与智能生活新纪元_安卓15
- 4标题:怎样通过Dialogflow构建一个聊天机器人?React版。_dialogflow机器人
- 5连接Mongodb数据库的步骤以及注意事项_如何连接mongodb数据库
- 6小程序公告php实现,小程序两种滚动公告栏的实现方法
- 7Git仓库完整迁移全过程_gitee 将a仓库的克隆到b仓库
- 8FP6381AS5CTR原厂SOT23-5 1.2A同步降压IC DC-DC变频器
- 9STM32参考代码,编译时出现“cannot open source input file, no such file or directory"错误
- 10微信小程序用户隐私保护指引设置指南_mp后台-设置-基本设置-服务内容声明-用户隐私保护指引]中声明“剪切板”隐私收集
(六)哈希函数_m-d结构
赞
踩
哈希函数
这里指的哈希函数是密码哈希函数,另一种常见的是非密码哈希函数,常用于哈希表的实现,没有安全性。
安全性
对称密码保证数据的保密性,哈希函数保证数据的完整性。
安全哈希函数的行为类似于真正的随机函数。安全哈希函数应该具有任何随机函数所具有的属性或模式。
它具有原像攻击抗性(单向性)和抗碰撞性。
原像攻击抗性
给定任意哈希值H,原像是指满足Hash(M)=H的消息M。
hash函数单向性:可以根据消息计算hash值,但是不能根据hash值计算消息,即使给定无限的计算能力,哈希函数也不可逆。
第一原像攻击抗性(原像攻击抗性)描述了:给定随机哈希值,攻击者将永远不会找到原始消息。
次原像攻击抗性描述了:当给定消息M1时,不可能找到另一条消息M2,其哈希值与M1的相同。
抗碰撞性
鸽子洞原理:如果有n只鸽子要放入m个洞中,并且n大于m,则至少有一个洞中包含多于一只鸽子。
不管选择使用什么哈希函数,碰撞将不可避免地存在。(因为hash值长度是有限的,而消息量是无限的)
抗碰撞性:如果可以为哈希函数找到第二个原消息,则可以找到碰撞,否则不能。
抗碰撞性和次原像攻击抗性在根本上是一回事,如果具有次原像攻击抗性,也就具有抗碰撞性。
查找碰撞的前提知识
生日悖论:即一个只有23个人的小组,其中包括两个出生日期相同的人的概率约为1/2。
设房间里有 n 个人,一年有365天,至少两个人生日相同的概率为 P。
先计算所有人的生日都不相同的概率(1-P),第一个人的生日是 365天里选 365天,第二个人是 365 天选 364天(去掉第一个人选的那天)…… 第 n 个人的生日是 365 天选 365-(n-1)天。则所有人生日都不相同的概率为

n为23时,1-P ≈ 49.27%,即23人里至少2人出生日期相同的概率P ≈ 50.73%
生日攻击:是根据生日悖论设计的密码学攻击方法。对于给定N条消息和同样多的哈希值,对每个消息-哈希对总共可以生成N×(N–1)/2个可能的碰撞。
查找碰撞
查找碰撞比查找原像要快,大约需要2^(n/2)次运算。在搜索原像的情况下,N个消息只得到N个候选原像,而同样的N个消息给出大约N^2个潜在的碰撞。
寻找碰撞常用的方法:
朴素生日攻击:
1.计算任意选择的2^(n/2)个消息的哈希,共2^(n/2)个,并将所有的消息-哈希对存储在列表中。
2.重排哈希值列表,移动哈希值使任何相同的值相邻。
3.搜索排序后的列表以查找具有相同哈希值的两个连续条目。
需要耗费大量内存,排序时耗费时间很长。
低内存碰撞搜索-Rho方法:
1.给定具有n比特哈希值的哈希函数,选择一些随机哈希值(H1),并定义H1=H'1。
2.计算H2=Hash(H1)和H'2=Hash(Hash(H'1));
3.迭代该过程并计算H(i+1)=Hash(Hi),H'(i+1)=Hash(Hash(H'i));直到达到i,使得Hi+1=H'i+1。
下图展示Rho搜索的示意图。其中箭头从H1到H2表示H2=Hash(H1)。序列最终进入一个回路(循环),形状类似于希腊字母rho(ρ)。循环开始于H5,其特征在于碰撞Hash(H4)=Hash(H10)=H5,发现了循环的位置,也就找到了碰撞。

哈希函数的分类
迭代哈希
将消息分成多个分组,使用类似的算法连续地处理每个分组。这种策略被称为迭代哈希,它有两种主要形式:
● 使用压缩函数迭代哈希,将输入转换为较小的输出,这种技术也被称为Merkle–Damgård结构(以密码学家Ralph Merkle和Ivan Damgård的名字命名)。
● 使用将输入转换为相同大小的输出的函数进行迭代哈希,使得任意两个不同的输入给出两个不同的输出(即置换),这种函数称为海绵函数。
Merkle–Damgård(M-D)结构
MD4、MD5、SHA-1、SHA-2系列都是这种结构。
M-D结构将消息分成大小相同的分组,并使用压缩函数将这些分组与内部状态混合。
图中H0是内部状态的初始值(标记为IV),值H1、H2等被称为链值,并且内部状态的最终值就是消息的哈希值。
消息分组通常是512比特或1024比特,可以是任意大小的。不过对于给定的哈希函数,分组长度是固定的。例如,SHA-256与512比特分组一起工作,SHA-512与1024比特分组一起工作。

填充块
既然分组长度固定那么一定会遇到分组不完整问题。例如,如果分组是512比特的,那么520比特的消息将由一个512比特分组加上8比特组成。在这种情况下,M–D采用如下方式形成最后的分组:取剩下的比特块8,追加一个比特1,然后接下来的比特追加0,最后是原始消息的长度的编码(二进制表示)。这种填充技巧保证了任何两个不同的消息都会给出一个截然不同的分组序列,从而给出一个截然不同的哈希值。
例如使用SHA-256(512比特分组长度)对10101010进行哈希,长度为8(二进制1000),则填充后的分组为:
101010101(中间有499个0)1000
多重碰撞
当有三个或更多消息哈希到同一个值时,就会发生多重碰撞。
有一个简单的技巧可以用与单个碰撞几乎相同的成本找到多重碰撞,方法如下:
1.找到第一个碰撞:Compress(H0,M1.1)=Compress(H0,M1.2)=H1。即现在有两个消息哈希到相同的值。
2.找到与H1的第二次碰撞作为起始链值:Compress(H1,M2.1)=Compress(H1,M2.2)=H2。现在有了4重碰撞,4个消息哈希到相同的值H2:M1.1||M2.1、M1.1||M2.2、M1.2||M2.1和M1.2||M2.2。
3.重复并发现N次碰撞,有2^N个N-消息分组哈希到相同的值,即2^N重碰撞,代价是N2^N次哈希计算。
不过这种方式需要先找到一个碰撞。
压缩函数:Davies–Meyer结构
常见的哈希函数的压缩函数都基于分组密码,最常见的压缩函数为Davies–Meyer结构。
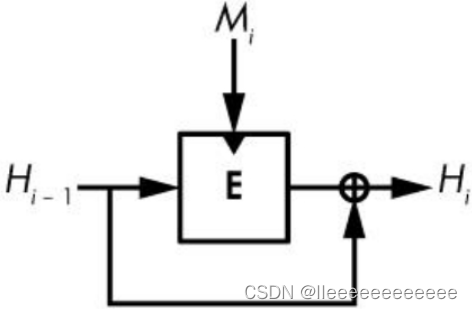
倒黑三角表示分组密码的密钥输入位置
给定一个消息分组Mi和前一个链值H(i-1),Davies–Meyer压缩函数使用分组密码E计算新链值为:
Hi=E(Mi,H(i-1)) ⊕ H(i-1)
消息分组Mi充当了分组密码的密钥,链值H(i-1)充当其明文分组。只要分组密码是安全的,产生的压缩函数就也是安全的,同时具有抗碰撞性和原像攻击抗性。
如果没有前面链值的异或(⊕H(i-1)),Davies–Meyer将是不安全的,因为可以使用分组密码的解密函数将其从新的链值转换为前一个链值。
海绵函数
海绵函数使用单个置换而不是压缩函数和分组密码。
海绵函数通常由一个内部状态、一个填充函数、一个置换函数构成。
最著名的海绵函数是Keccak,也称为SHA-3。

海绵函数的工作模式如下:
1.异或第一个消息分组M1和内部状态的初始值H0。(消息分组都有相同的长度且小于内部状态,长度不够先用填充函数填充)
2.置换函数P,将1步骤生成的新的内部状态转换为相同大小的另一个值。
3.异或M2分组,再次使用P,然后重复对消息分组M3、M4等进行运算。这称为吸收阶段。
4.在注入所有消息分组之后,它再次使用P,并从状态中提取一个分组形成哈希。(如果需要更长的哈希值,应用P再提取一个分组。)这称为挤压阶段。
安全性
海绵函数的安全性取决于其内部状态的长度和分组的长度。如果消息分组是R比特长,内部状态是W比特长,则内部状态的C=W–R比特不能被消息分组修改(无法与消息分组参与运算)。C的值被称为海绵的容量,海绵函数的安全保证级别为C/2。
例如,为了用64比特消息分组达到256比特安全性时,内部状态应该是W=2×256+64=576比特。当然,安全级别也取决于哈希值的长度n。
海绵函数填充过程:消息的末尾通常填充一个1,紧随其后的都是0。
SHA系列哈希函数
安全哈希算法(SHA)哈希函数是NIST(美国国家标准与技术研究院)定义的标准,它们被认为是世界性的标准。
SHA-1
SHA-1结合了Merkle–Damgård哈希函数和一种基于专门设计的分组密码的Davies-Meyer压缩函数,有时也被称为SHACAL,SHA-1通过在512比特消息分组(M)上迭代以下操作来工作:
H = E(M,H) + H
E(M,H)和H被看作32比特整数的数组,并且位于相同位置的两个字相加:E(M,H)的第一个32比特字和H的第一个32比特字相加,以此类推。对于任何消息,H的初始值是固定常数,然后计算新的链值H,并且将处理所有分组之后H的最终值作为消息的哈希返回。
分组密码使用消息分组作为密钥并使用当前160比特链值作为明文分组,160比特的结果可以看作由5个32比特字组成的数组,每个字被添加到初始值H中的32比特计数器部分。
下面是SHA-1的核心伪代码部分。
- /**
- * SHA-1压缩函数
- * H为链值
- * M为消息分组(512比特)
- */
- SHA1-Compress(H,M){
- //将链值解析为5个32比特字的分组
- (a0,b0,c0,d0,e0) = H
- (a,b,c,d,e) = SHA1-blockcipher(a0,b0,c0,d0,e0,M)
- return (a + a0, b + b0, c + c0, d + d0, e + e0)
- }
-
- /**
- * 分组密码
- * a0~e0 5个32比特字(链值解析的)
- * M 是消息分组(512比特)
- */
- SHA1-blockcipher(a0,b0,c0,d0,e0,M){
- W = expand(M)
- //迭代80次运算进行转换
- for i = 0 to 79{
- //5个字的组合生成新的值new
- new = (a<<<5) + f(i,b,c,d) + e + K[i] + W[i]
- //用new替换a,其他的移位
- (a,b,c,d,e) = (new, a, b>>>2, c, d)
- }
- return (a,b,c,d,e)
- }
-
- /**
- * M作为16个32比特字组成的数组处理
- */
- expand(M){
- // W为容量为80的32比特字的空数组
- W = []
- for i = 0 to 79{
- //将W的前16个字设置为M对应下标的值
- if i<16 then W[i] = M[i]
- else
- //第17个字开始 计算前几个W值的异或,然后循环左移1位
- W[i] = (W[i-3]⊕W[i-8]⊕W[i-14]⊕W[i-16])<<<1
- }
- return W
- }
-
- /**
- * 依赖于轮数的基本比特位逻辑操作(布尔函数)的序列
- */
- f(i,b,c,d){
- if i<20 then return ((b&c)⊕(~b&d))
- if i<40 then return (b⊕c⊕d)
- if i<60 then return ((b&c)⊕(b&d)⊕(c&d))
- if i<80 then return (b⊕c⊕d)
- }

安全性
SHA-1仍然不够安全,已经被研究人员构造出了碰撞,Chrome浏览器也会将HTTPS连接中使用SHA-1的网站标记为不安全。
SHA-2
SHA-2是SHA-1的继任者,由NSA设计并由NIST标准化。SHA-2是一个由4个哈希函数组成的系列:SHA-224、SHA-256、SHA-384和SHA-512,SHA-256和SHA-512是其中的两个主要算法,256或512表示每个哈希的比特长度。
SHA-256
SHA-256具有256比特链值,也具有512比特的消息分组,其他方面和SHA-1相似,不过,它只运算64轮。
下面是SHA-256的expand函数。
- expand256(M){
- // W为容量为80的32比特字的空数组
- W = []
- for i = 0 to 63{
- //将W的前16个字设置为M对应下标的值
- if i<16 then W[i] = M[i]
- else{
- //注意最后一个是>>
- s[0] = (W[i-15] >>> 7)⊕(W[i-15] >>> 18)⊕(W[i-15] >> 3)
- s[1] = (W[i-2] >>> 17)⊕(W[i-2] >>> 19)⊕(W[i-2] >> 10)
- //第17个字开始 计算前几个W值的异或,然后循环左移1位
- W[i] = W[i-16] + s0 + W[i-7] + s1
- }
- }
- return W
- }
SHA-3
主要成员有BLAKE、Grøstl、JH、Keccak、Skein,其中Keccak被认为是最好的算法。
BLAKE是一种增强的Merkle–Damgård哈希,其压缩函数基于分组密码,而分组密码又基于序列密码ChaCha的核心功能,一个加法、异或操作和字移位组成的链。
Grøstl是一种增强的Merkle–Damgård哈希,其压缩函数使用基于AES分组密码的核心函数的两个置换(或固定密钥分组密码)。
JH是一种经过调整的海绵函数结构,其中消息分组在置换之前和之后都被注入,而不是仅在置换之前。置换还执行类似替换-置换分组密码的操作。
Keccak 一个海绵函数,其置换只执行比特运算。
Skein是一种基于不同于Merkle–Damgård操作模式的哈希函数,其压缩函数基于仅使用整数相加、异或和字移位的新型分组密码。
Keccak
Keccak的核心算法是一个1600比特状态的置换,它吸收1152、1088、832或576比特的分组,分别产生224、256、384或512比特的哈希值(C=(W-R)/2)。.
tiny_sha3的Keccak的核心算法部分源码如下所示
- #ifndef KECCAKF_ROUNDS
- #define KECCAKF_ROUNDS 24
- #endif
- //用给定的轮数更新内部状态
- void sha3_keccakf(uint64_t st[25])
- {
- // constants
- const uint64_t keccakf_rndc[24] = {
- 0x0000000000000001, 0x0000000000008082, 0x800000000000808a,
- 0x8000000080008000, 0x000000000000808b, 0x0000000080000001,
- 0x8000000080008081, 0x8000000000008009, 0x000000000000008a,
- 0x0000000000000088, 0x0000000080008009, 0x000000008000000a,
- 0x000000008000808b, 0x800000000000008b, 0x8000000000008089,
- 0x8000000000008003, 0x8000000000008002, 0x8000000000000080,
- 0x000000000000800a, 0x800000008000000a, 0x8000000080008081,
- 0x8000000000008080, 0x0000000080000001, 0x8000000080008008
- };
- const int keccakf_rotc[24] = {
- 1, 3, 6, 10, 15, 21, 28, 36, 45, 55, 2, 14,
- 27, 41, 56, 8, 25, 43, 62, 18, 39, 61, 20, 44
- };
- const int keccakf_piln[24] = {
- 10, 7, 11, 17, 18, 3, 5, 16, 8, 21, 24, 4,
- 15, 23, 19, 13, 12, 2, 20, 14, 22, 9, 6, 1
- };
-
- // variables
- int i, j, r;
- uint64_t t, bc[5];
-
- //转为小端字节排列
- #if __BYTE_ORDER__ != __ORDER_LITTLE_ENDIAN__
- uint8_t *v;
-
- // endianess conversion. this is redundant on little-endian targets
- for (i = 0; i < 25; i++) {
- v = (uint8_t *) &st[i];
- st[i] = ((uint64_t) v[0]) | (((uint64_t) v[1]) << 8) |
- (((uint64_t) v[2]) << 16) | (((uint64_t) v[3]) << 24) |
- (((uint64_t) v[4]) << 32) | (((uint64_t) v[5]) << 40) |
- (((uint64_t) v[6]) << 48) | (((uint64_t) v[7]) << 56);
- }
- #endif
-
- //#####
- // 迭代轮
- for (r = 0; r < KECCAKF_ROUNDS; r++) {
-
- //1 Theta
- //异或后填充bc数组元素
- for (i = 0; i < 5; i++)
- bc[i] = st[i] ^ st[i + 5] ^ st[i + 10] ^ st[i + 15] ^ st[i + 20];
-
- for (i = 0; i < 5; i++) {
- t = bc[(i + 4) % 5] ^ ROTL64(bc[(i + 1) % 5], 1);
- for (j = 0; j < 25; j += 5)
- st[j + i] ^= t;
- }
-
- //2 Rho Pi
- t = st[1];
- for (i = 0; i < 24; i++) {
- j = keccakf_piln[i];
- bc[0] = st[j];
- st[j] = ROTL64(t, keccakf_rotc[i]);
- t = bc[0];
- }
-
- //3 Chi
- for (j = 0; j < 25; j += 5) {
- for (i = 0; i < 5; i++)
- bc[i] = st[j + i];
- for (i = 0; i < 5; i++)
- st[j + i] ^= (~bc[(i + 1) % 5]) & bc[(i + 2) % 5];
- }
-
- //4 Iota
- st[0] ^= keccakf_rndc[r];
- }
-
- //转为小端字节排列
- #if __BYTE_ORDER__ != __ORDER_LITTLE_ENDIAN__
- // endianess conversion. this is redundant on little-endian targets
- for (i = 0; i < 25; i++) {
- v = (uint8_t *) &st[i];
- t = st[i];
- v[0] = t & 0xFF;
- v[1] = (t >> 8) & 0xFF;
- v[2] = (t >> 16) & 0xFF;
- v[3] = (t >> 24) & 0xFF;
- v[4] = (t >> 32) & 0xFF;
- v[5] = (t >> 40) & 0xFF;
- v[6] = (t >> 48) & 0xFF;
- v[7] = (t >> 56) & 0xFF;
- }
- #endif
- }
代码中#####位置开始迭代了一系列轮,其中每轮包括4个主要步骤:
● 第一步(Theta),包括64比特字之间的异或(XOR)或字的1位移位(ROTL64(w,1)运算是指字w向左移位1位)。
● 第二步(Rho Pi),包括硬编码在keccakf_rotc[]数组中的64比特字的移位。
● 第三步(Chi),包括更多的异或(XOR),同时也包含64比特字之间的逻辑与(&)。这些是Keccak中唯一的非线性操作,它们增强了密码强度。
● 第四步(Iota),包括与硬编码在keccakf_rndc[]中的64比特常数的异或。
这些操作为SHA-3提供了一种没有任何统计偏差或可利用结构的强置换算法,到目前为止还没有人破解。
BLAKE2哈希函数
由Jean-Philippe Aumasson、Samuel Neves、Zooko Wilcox-O’Hearn和Christian Winnerlein设计。它包括 :
● BLAKE2b(或仅仅BLAKE2),为64位平台优化,产生从1字节到64字节的摘要。
● BLAKE2s,为8到32位平台优化,可以产生1到32字节的摘要。
BLAKE2b、BLAKE2bp的并行对应运行在四核上,而BLAKE2sp运行在八核上。
BLAKE2的压缩函数是Davies–Meyer的一个变体,用参数作为附加输入,即计数器和标志。
计数器确保每个压缩函数的行为不同。
标志指示压缩函数是否正在处理最后一个消息块,目的是提高安全性。
BLAKE2压缩函数中的分组密码是基于序列密码ChaCha的,类似于salsa20,核心操作由以下算式生成:(Mi和Mj是2个消息字)
a = a + b + Mi
d = ((d⊕a)>>>32)
c = c + d
b = ((b⊕c)>>>24)
a = a + b + Mj
d = ((d⊕a)>>>16)
c = c + d
b = ((b⊕c)>>>63)


