
hadoop安装与配置_根据要求修改hadoop相关文件(hadoop-env.sh、core-site.xml、hdfs-
赞
踩
hadoop安装与配置
目标:搭建由三台节点(master、node1、node2)组成的hadoop集群
准备工作:
1.创建虚拟机安装centos
2.配置虚拟机网络
3.配置三台虚拟机ssh免密
4.上传hadoop2.7.3与jdk1.8.1压缩包到虚拟机
主要流程:
1.解压hadoop与jdk配置环境变量
2.修改hadoop配置文件
3.将hadoop与jdk分发到另外两台节点
4.初始化namenode
1.解压配置环境变量
(1)使用解压命令将hadoop与jdk解压
tar -zxvf hadoop-2.7.3.tar.gz
- 1
tar -zxvf jdk1.8.0_161.tar.gz
- 1
(2)配置jdk与hadoop的环境变量
进入到etc/profile添加环境变量
vi /etc/profile
- 1
在文件的最后添加
export HADOOP_HOME=/home/hadoop1/hadoop-2.7.3
export JAVA_HOME=/home/hadoop1/jdk1.8.0_161
export PATH=.:$HADOOP_HOME/bin:\$HADOOP_HOME/sbin:\$JAVA_HOME/bin:\$PATH
- 1
- 2
- 3
在配置完成后更新环境变量
source /etc/profile
- 1
输入如下命令即可查看jdk与hadoop版本信息

2.修改Hadoop配置文件
首先进入到hadoop下的/etc/hadoop目录下
要修改的文件有hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-sit.xml、yarn-site.xml、slaves六个文件
(1)修改hadoop-env.sh
#打开文件
vi hadoop-env.sh
- 1
- 2
找到JAVA_HOME参数位置,修改为自己jdk所在的位置

(2)修改core-site.xml
#打开文件
vi core-site.xml
- 1
- 2
添加如下信息:

(3)修改hdfs-site.xml
#打开文件
vi hdfs-site.xml
- 1
- 2
添加如下信息:

(4)修改mapred-sit.xml
#复制mapred-site.xml.template
cp mapred-site.xml.template mapred-site.xml
#打开文件
vi mapred-site.xml
- 1
- 2
- 3
- 4
添加如下信息:(指定在YARN上运行mapreduce)
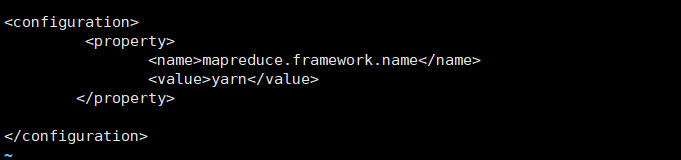
(5)修改yarn-site.xml
#打开文件
vi yarn-site.xml
- 1
- 2
添加如下信息:

(6)修改slaves:
#打开文件
vi slaves
- 1
- 2
添加如下信息:
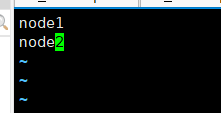
3.分发jdk与hadoop到其他两台节点
scp /etc/profile node1:/etc/profile
scp /etc/profile node2:/etc/profile
scp -r /hadoop/ node1:/ #将整个hadoop文件夹分发到node1
scp -r /hadoop/ node2:/
scp -r /jdk/ node1:/ #将整个jdk文件夹分发到node1
scp -r /jdk/ node2:/
- 1
- 2
- 3
- 4
- 5
- 6
分发完成后,分别在两台节点上使用“source /etc/profile”更新环境变量
4.格式化namenode
安装完成后,首先要在第一次启动前格式化namenode
hdfs namenode -format
- 1
格式化成功的标志为运行格式化命令后,打印的日志中有successfully formatted信息。
5.启动集群
# 启动
start-all.sh
# 关闭
stop-all.sh
- 1
- 2
- 3
- 4
在主机浏览器上查看hadoop的ui页面需要在主机上添加与虚拟机的ip映射,添加后在网站输入master:8088与master:50070即可



