
- 1【Linux】基于 Jenkins+shell 实现更新服务所需文件 -->两种方式:ssh/Ansible
- 2vue中一维数组的全选、全不选、反选(图文示例)_数组全选
- 3Android课设简单实现远程数据库操作——图书管理的增删改查。
- 4Windows 10和Linux Mint 18 双系统安装心得_win10下安装linux mint18
- 5##20 实现图像风格迁移:使用PyTorch深入学习的艺术之旅
- 6macOS Sonoma 14.2 (23C64) 正式版 Boot ISO 原版可引导镜像下载_macos 14.2 iso
- 7pytorch安装报错:ERROR: torch has an invalid wheel, .dist-info directory not found
- 8我让gpt写了一段正则表达式代码,可是运行报错,可以帮忙看看哪里出了问题?...
- 9windows更改主机名称映射_远程桌面映射本地电脑磁盘后如何改名称
- 10Stable Diffusion关键插件ControlNet_提取并生成线稿,通过线稿进行二次绘制
【机器学习基础1】什么是机器学习、预测模型解决问题的步骤、机器学习的Python生态圈
赞
踩
一. 什么是机器学习
1. 概念
机器学习(Machine Learning,ML)是一门多领域的交叉学科,涉及概率论、统计学、线性代数、算法等多门学科。
机器学习所研究的主要内容
是关于在计算机上从数据中产生“模型”(model)的算法,即“学习算法”(learning algorithm)。有了学习算法,我们把经验数据提供给它,它就能基于这些数据产生模型;在面对新的情况时(例如看到一个没剖开的西瓜),模型会给我们提供相应的判断(例如好瓜)。
如果说计算机科学是研究关于“算法”的学问,那么类似的,可以说机器学习是研究关于“学习算法”的学问。
机器学习已经有了十分广泛的应用,例如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用。
2. 机器学习算法分类
机器学习的算法分为两大类:监督学习和无监督学习。
监督学习
监督学习即在机器学习过程中
提供对错指示。一般是在数据组中包含最终结果(0,1),通过算法让机器自己减少误差。这一类学习主要应用于分类和预测(Regression &Classify)。
基本逻辑
监督学习从给定的训练数据集中学习出一个目标函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入和输出,也可以说包括特征和目标,训练集中的目标是由人标注的。
常见的监督学习算法包括回归分析和统计分类。
非监督学习
非监督学习又称
归纳性学习(Clustering),利用K方式(KMean)建立中心(Centriole),通过循环和递减运算(Iteration&Descent)来减小误差,达到分类的目的。
二. 利用预测模型解决问题的步骤
预测模型
与统计学不同,机器学习的预测模型是用来理解数据的,聚焦于如何创建一个更加精准的模型,而不是用来解释模型是如何设置的。
利用机器学习的预测模型来解决问题共有六个基本步骤,如图:
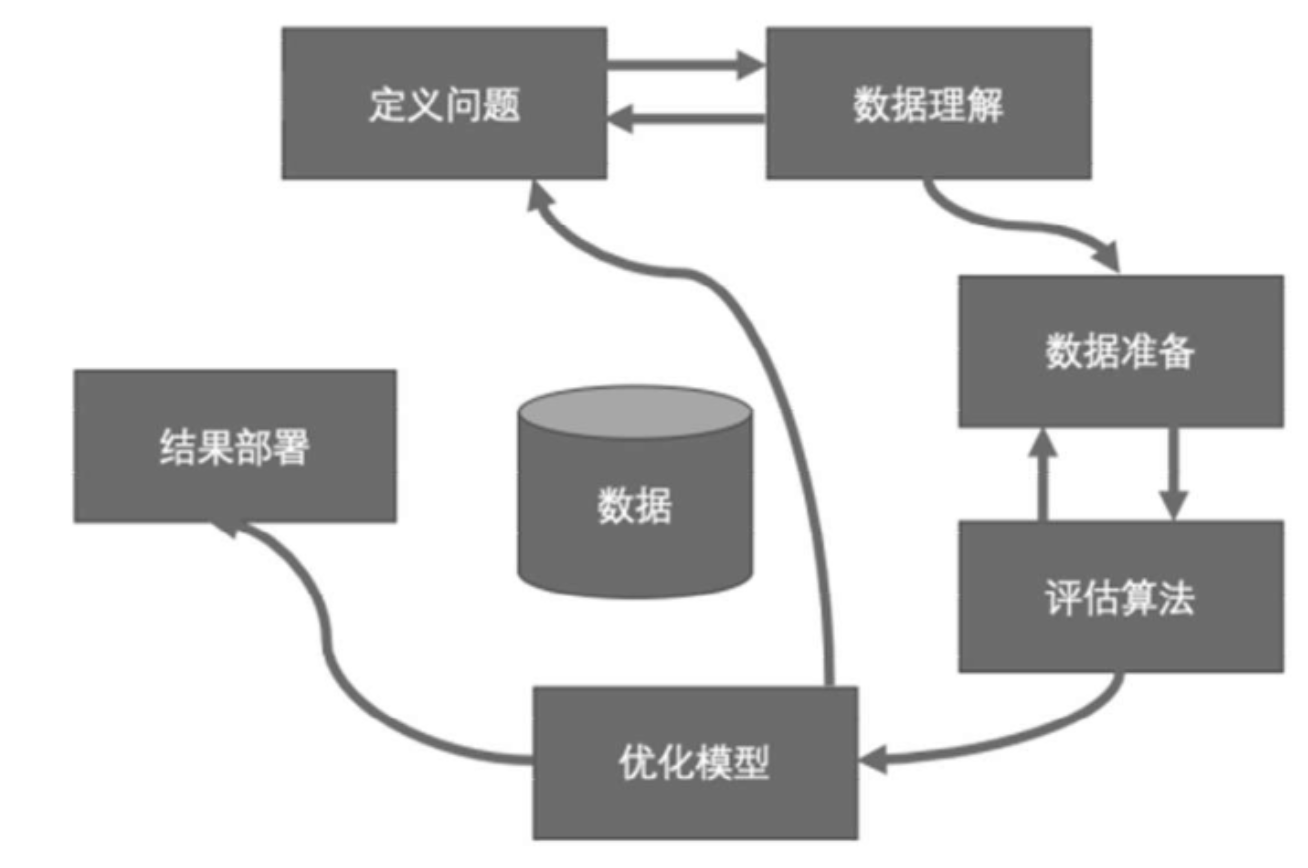
- 定义问题:研究和提炼问题的特征,以帮助我们更好地理解项目的目标。
- 数据理解:通过描述性统计和可视化来分析现有的数据。
- 数据准备:对数据进行格式化,以便于构建一个预测模型。
- 评估算法:通过一定的方法分离一部分数据,用来评估算法模型,并选取一部分代表数据进行分析,以改善模型。
- 优化模型:通过调参和集成算法提升预测结果的准确度。
- 结果部署:完成模型,并执行模型来预测结果和展示。
一旦明白了如何使用Python平台来完成机器学习的任务,就可以在不同的项目中重复使用这种方法解决问题。
三. 机器学习的Python生态圈
Python是一种功能强大且灵活的编程语言,特别适用于机器学习,这得益于其可读性、一致性和健壮的数据科学库生态系统。
- Python基础:Python编程需要理解基本语法、数据类型、错误处理和面向对象编程。
- 数据科学库:熟悉NumPy进行
数值操作,用Pandas进行数据处理和分析,用Matplotlib和Seaborn做数据可视化。- 数据预处理:涉及特征缩放和规范化、处理缺失数据、异常检测、类别数据编码,以及将数据分割为训练、验证和测试集。
- 机器学习库:熟练使用Scikit-learn,这是一个提供广泛的
监督和无监督学习算法的python库。这里需要理解如何实现线性回归、逻辑回归、决策树、随机森林、最近邻(K-NN)和K均值聚类等算法。
简单来说
- scikit-learn提供的机器学习的算法
- 利用NumPy数组来准备机器学习算法的
数据- 使用Matplotlib来创建
图表,展示数据- 通过Pandas导入、展示数据,以便增强对数据的理解和
数据清洗、转换等工作.
其中
scikit-learn依赖于SciPy及其相关类库来运行。scikit-learn的基本功能主要分为六大部分:分类、回归、聚类、数据降维、模型选择和数据预处理。
需要指出的是,由于scikit-learn本身不支持深度学习,也不支持GPU加速,因此scikit-learn对于多层感知器(MLP)神经网络的实现并不适合处理大规模问题。(scikit-learn对MLP的支持在0.18版之后增加)。
《机器学习》-- 周志华

