
- 1ControlNet作者新作爆火:P照片换背景不求人,AI打光完美融入
- 2论文高质量翻译:The Claude 3 Model Family: Opus, Sonnet, Haiku Claude 3 模型系列:Opus、Sonnet、Haiku 超越GPT4_研究生级别的谷歌防护问答基准)
- 3使用SpringBoot完成excel表格导入导出_excel导入 spring boot
- 4浅谈——图像梯度算法中算子由来_图形梯度算子
- 52023年,程序员如何构建持续增长的被动收入?
- 6git命令推送本地到远程分支_git push 远程分支
- 7一文详解8种异常检测算法(附Python代码)
- 8Eureka搭建及使用_eureka搭建与使用
- 9ov5640介绍
- 10Excel表格和SpringBoot整合进行导入和导出操作_springboot excel 合并 导入
使用Python爬取淘宝商品并做数据分析
赞
踩
使用Python爬取淘宝商品并做数据分析,可以按照以下步骤进行操作:
-
确定需求:确定要爬取的淘宝商品的种类、数量、关键词等信息。
-
编写爬虫程序:使用Python编写爬虫程序,通过模拟浏览器请求,获取淘宝商品的页面源代码。
-
解析页面:使用HTML解析库(如BeautifulSoup或PyQuery)解析页面,提取出需要的商品信息,如商品名称、价格、销量等。
-
存储数据:将提取到的商品信息存储到数据库或文件中,方便后续的数据分析。
-
数据分析:根据需求,对爬取到的数据进行分析,可以使用数据可视化工具(如Matplotlib或Seaborn)进行图表展示,或进行统计分析。
-
结果展示:将分析结果进行展示,可以生成报告、图表或可视化界面,使数据更直观地呈现出来。
-
例如想在淘宝开个小鱼零食的网店,想对目前这个市场上的商品做一些分析,本来手动去做统计和分析也是可以的,这些信息都是对外展示的,只是手动比较麻烦。
-

-
具体的要求如下:
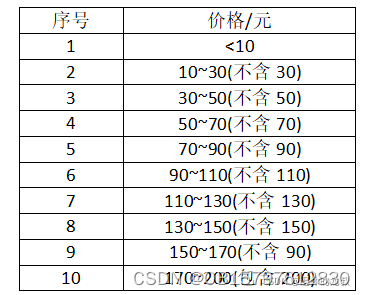
在淘宝搜索“小鱼零食”,想知道前10页搜索结果的所有商品的销量和金额,按照他划定好的价格区间来统计数量,给我划分了如下的一张价格区间表:
-

-
这10页搜索结果中,商家都是分布在全国的哪些位置?
这10页的商品下面,用户评论最多的是什么?
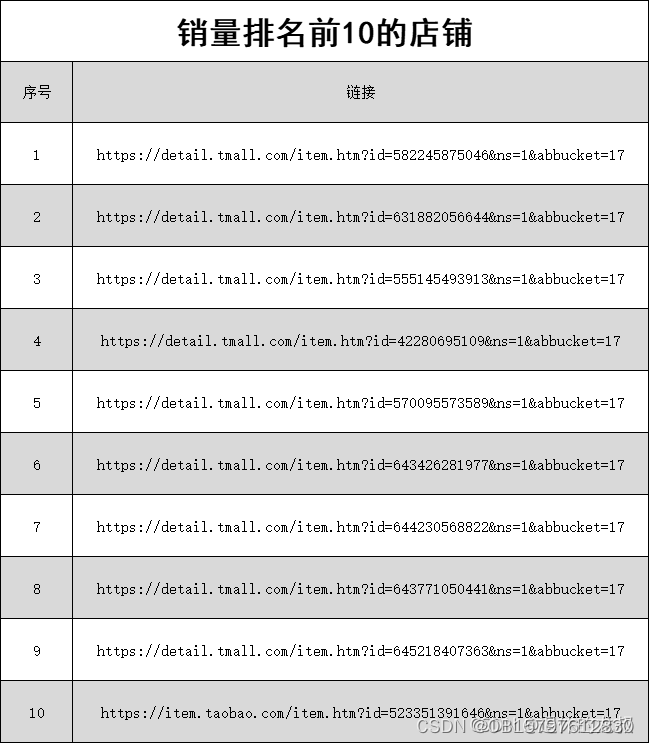
从这些搜索结果中,找出销量最多的10家店铺名字和店铺链接。
从这些要求来看,其实这些需求也不难实现,我们先来看一下项目的效果。
-
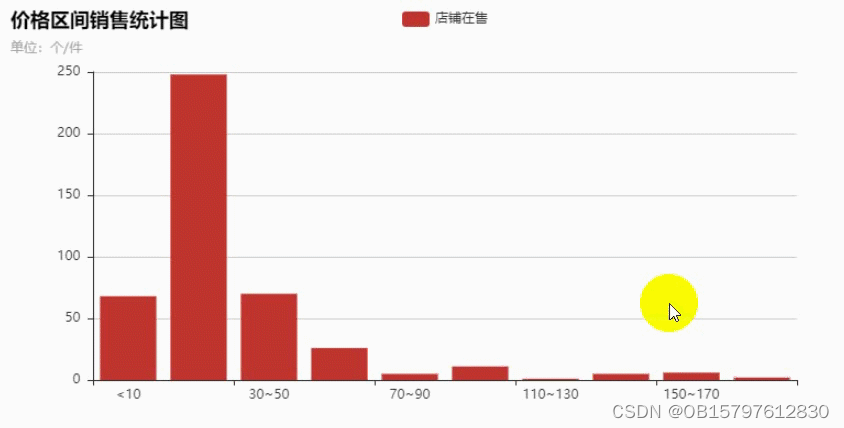
获取到数据之后做了下分析,最终做成了柱状图,鼠标移动可以看出具体的商品数量。
-
在10~30元之间的商品最多,越往后越少,看来大多数的产品都是定位为低端市场。
-
再来看一下用户都在商品下面评论了一些什么:
-

-
最后就是销量前10的店铺和链接了。
-
-
在拿到数据并做了分析之后,我也在想,如果这个东西是我来做的话,我能不能看出来什么东西?或许可以从价格上找到切入点。
-
由于源码分了几个源文件,还是比较长的,所以这里就不跟大家一一讲解了,懂爬虫的人看几遍就看懂了点击获取测试key和secret

