
- 1Typora + PicGo + Gitee/GitHub 免费搭建个人图床_gitee+github
- 2CONVERT 转换函数的简单使用方法_convert函数
- 3数据结构--带头结点的单向链表_带头结点的单链表
- 4JavaScript 中的数学与时光魔法:Math与Date对象大揭秘
- 5网络运输层之(3)GRE协议
- 6OpenCV安装:最基础的openCV程序运行示例_opencv安装程序
- 7如何利用python选股
- 8数据结构修炼第一篇:时间复杂度和空间复杂度_栈和队列的时间复杂度和空间复杂度
- 9计算机网络管理 常见的计算机网络管理工具snmputil,Mib browser,SNMPc管理软件的功能和异同_snmp网络管理软件
- 10基于n-gram模型的中文分词_ngram分词
大语言模型Transformer优化
赞
踩
Large Transformer Model Inference Optimization
Large transformer models are mainstream nowadays, creating SoTA results for a variety of tasks. They are powerful but very expensive to train and use. The extremely high inference cost, in both time and memory, is a big bottleneck for adopting a powerful transformer for solving real-world tasks at scale.
Why is it hard to run inference for large transformer models? Besides the increasing size of SoTA models, there are two main factors contributing to the inference challenge (Pope et al. 2022):
- Large memory footprint. Both model parameters and intermediate states are needed in memory at inference time. For example,
- The KV cache should be stored in memory during decoding time; E.g. For a batch size of 512 and context length of 2048, the KV cache totals 3TB, that is 3x the model size (!).
- Inference cost from the attention mechanism scales quadratically with input sequence length.
- Low parallelizability. Inference generation is executed in an autoregressive fashion, making the decoding process hard to parallel.
In this post, we will look into several approaches for making transformer inference more efficient. Some are general network compression methods, while others are specific to transformer architecture.
Methods Overview
We in general consider the following as goals for model inference optimization:
- Reduce the memory footprint of the model by using fewer GPU devices and less GPU memory;
- Reduce the desired computation complexity by lowering the number of FLOPs needed;
- Reduce the inference latency and make things run faster.
Several methods can be used to make inference cheaper in memory or/and faster in time.
- Apply various parallelism to scale up the model across a large number of GPUs. Smart parallelism of model components and data makes it possible to run a model of trillions of parameters.
- Memory offloading to offload temporarily unused data to the CPU and read them back when needed later. This helps with memory usage but causes higher latency.
- Smart batching strategy; E.g. EffectiveTransformer packs consecutive sequences together to remove padding within one batch.
- Network compression techniques, such as pruning, quantization, distillation. A model of smaller size, in terms of parameter count or bitwidth, should demand less memory and run faster.
- Improvement specific to a target model architecture. Many architectural changes, especially those for attention layers, help with transformer decoding speed.
Check the previous post on large model training on different types of training parallelism and memory saving designs including CPU memory offloading. This post focuses on network compression techniques and architecture-specific improvement for transformer models.
Distillation
Knowledge Distillation (KD; Hinton et al. 2015, Gou et al. 2020) is a straightforward way to build a smaller, cheaper model (“student model”) to speed up inference by transferring skills from a pre-trained expensive model (“teacher model”) into the student. There is no much restriction on how the student architecture should be constructed, except for a matched output space with the teacher in order to construct a proper learning objective.
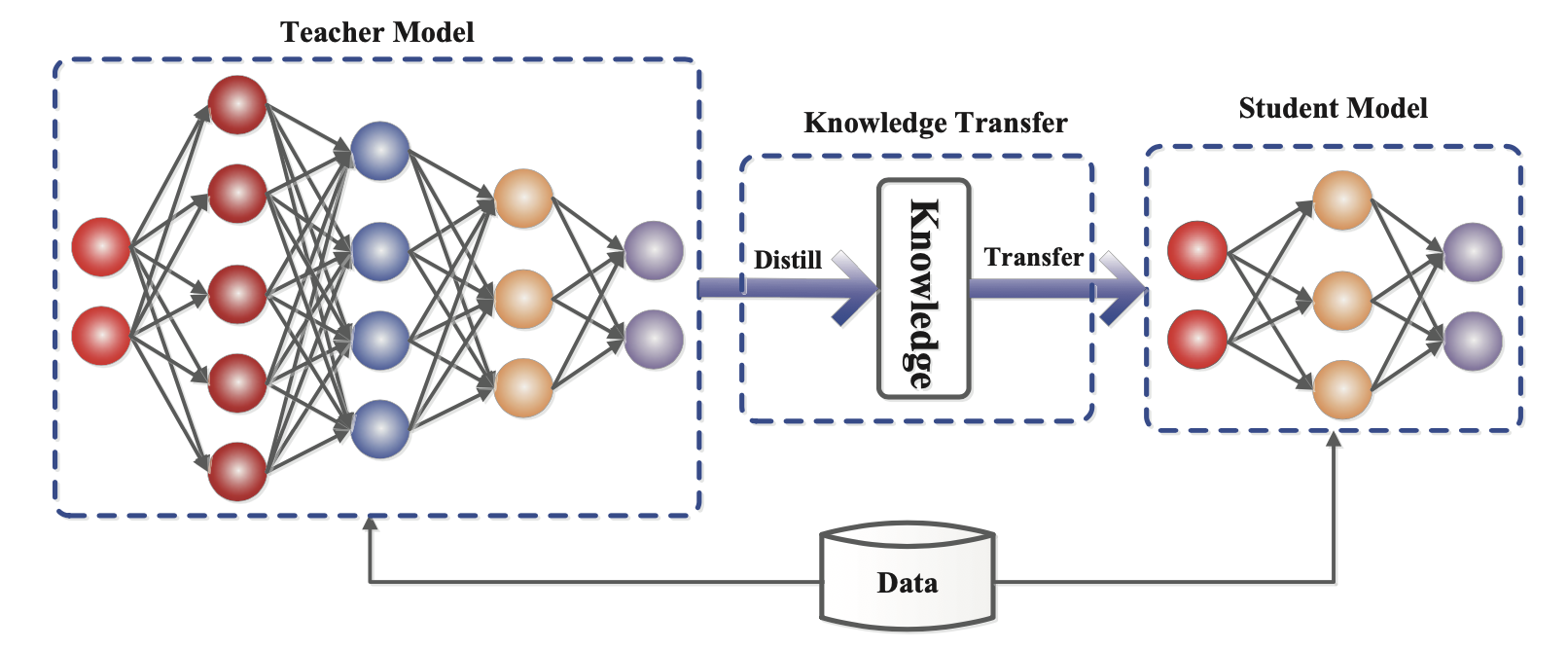
Fig. 1. The generic framework of teacher-student knowledge distillation training. (Image source: Gou et al. 2020)
Given a dataset, a student model is trained to mimic outputs of a teacher via distillation loss. Usually a neural network has a softmax layer; For example, a LLM outputs a probability distribution over tokens. Let’s denote the logits layer right before softmax as 声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

