
- 1Paxos算法和ZooKeeper使用的Zab(ZooKeeper Atomic Broadcast)算法
- 2山东供销合作社发展的实施意见 国研政情·谋定论道-经济信息智库
- 3使用 Meltano 将数据从 Snowflake 导入到 Elasticsearch:开发者之旅
- 4【C语言实现贪吃蛇】(内含源码)
- 5[计算机视觉DL学习] 迁移学习 风格迁移基础学习_使用预训练模型 计算两张图片的风格损失
- 6使用PyTorch进行中文文本分类:一个深度学习实践项目
- 7关于undefined method `each‘ for nil:NilClass的报错
- 8GPT-4完全破解版:用最新官方API微调,想干啥就干啥,网友怕了_gpi4
- 9初级开发人员的缺点_在您担任初级开发人员的第一年,获得此建议
- 10作为 IT 行业的过来人,你有什么话想对后辈说的?
开源模型应用落地-总述_qwen1.5流式输出
赞
踩
一、背景
在当今社会,实际应用比纯粹理解原理和概念更为重要。即使您对某个领域的原理和概念有深入的理解,但如果无法将其应用于实际场景并受制于各种客观条件,那么与其一开始就过于深入,不如先从基础开始,实际操作后再逐步深入探索。
在这种实践至上的理念下,或许我可以为您提供一种直接的、实际操作的方法。希望能借助我的经验,为各位朋友带来一些有帮助的建议,例如:
1、您是否也在迫不及待地期待在AI时代中展示自己的能力?
2、您是否一直在研究如何使用开源模型?
3、您是否一直在寻找将AI与业务结合的方向?
4、您是否一直在寻找模型推理加速的方法?
5、您是否一直在努力整合来自互联网上零散的资料?
如果您在上述问题中有类似的疑问,我非常希望您能从中受益。
二、项目架构
简化后的示意图如下:
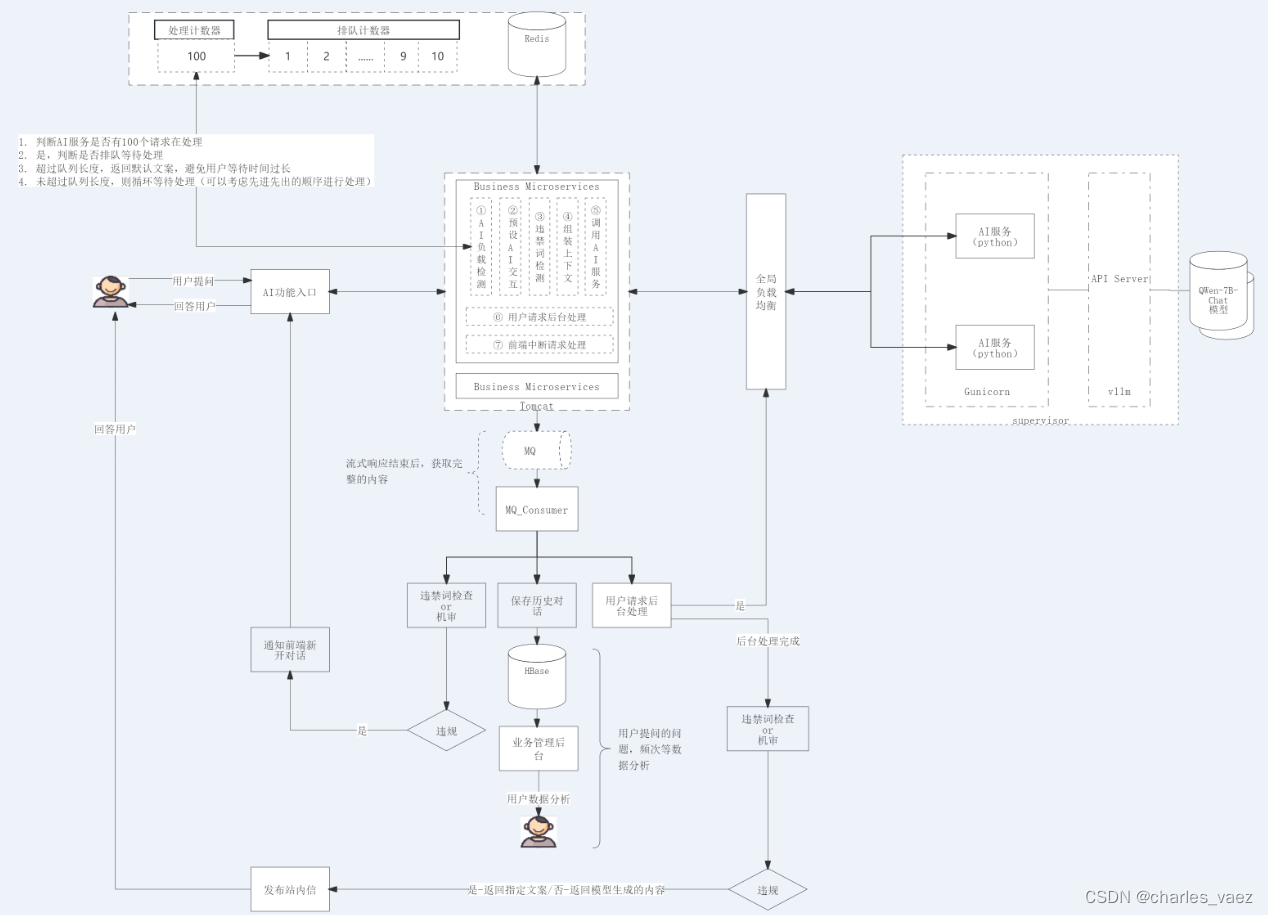
三、总览
通过实际案例,我们将为大家呈现一系列文章,帮助您了解如何将开源模型与业务整合。这些文章将引导您深入掌握该过程。
3.1. 初级入门系列
3.1.1. 开源模型应用落地-qwen模型小试-入门篇系列
重点:在windows环境下,使用transformer调用Qwen-1_8B-Chat模型
重点:在windows环境下,使用transformer设置模型参数/System Prompt/历史对话
重点:在linux环境下,使用transformer调用Qwen-1_8B-Chat模型
重点:使用gradio,构建Qwen-1_8B-Chat模型的测试界面
重点:使用modelscope api调用Qwen-1_8B-Chat模型,实现非流式/流式输出
重点:Qwen1.5系列模型的新特性及使用方式
3.1.2. 开源模型应用落地-baichuan模型小试-入门篇系列
3.1.3. 开源模型应用落地-chatglm模型小试-入门篇系列
3.1.4. 开源模型应用落地-KnowLM模型小试-入门篇系列
重点:调用KnowLM模型,实现知识抽取
重点:优化模型参数,提高知识提取效率和质量
3.2. 高级进阶系列
3.2.1. 开源模型应用落地-向量数据库小试-入门篇系列
3.2.2. 开源模型应用落地-qwen-7b-chat与vllm实现推理加速的正确姿势系列
开源模型应用落地-qwen-7b-chat与vllm实现推理加速的正确姿势(一)
重点:qwen-7b-chat集成vllm
开源模型应用落地-qwen-7b-chat与vllm实现推理加速的正确姿势(二)
重点:gunicorn+flask构建AI服务
开源模型应用落地-qwen-7b-chat与vllm实现推理加速的正确姿势(三)
重点:supervisor提升服务的稳定性
开源模型应用落地-qwen-7b-chat与vllm实现推理加速的正确姿势(四)
重点:鉴权和限流提升AI服务的安全性和稳定性
开源模型应用落地-qwen-7b-chat与vllm实现推理加速的正确姿势(五)
重点:定时任务处理隐藏盲点
开源模型应用落地-qwen-7b-chat与vllm实现推理加速的正确姿势(六)
重点:改变模型自我认知
开源模型应用落地-qwen-7b-chat与vllm实现推理加速的正确姿势(七)
重点:AI服务性能优化
开源模型应用落地-qwen1.5-7b-chat与vllm实现推理加速的正确姿势(八)
重点:qwen1.5-7b-chat集成vllm
开源模型应用落地-qwen1.5-7b-chat与vllm实现推理加速的正确姿势(九)
重点:qwen1.5-7b-chat集成vllm,构建与OpenAI-API兼容的API服务
3.2.3. 开源模型应用落地-业务整合系列
重点:使用HttpURLConnection/OkHttp/HttpClient多种方式调用AI服务
重点:使用Netty库快速构建WebSocket服务,实现客户端与AI服务交互
重点:spring boot集成netty服务,实现用户界面交互
重点:构建websocket身份校验机制,避免无效连接
重点:构建websocket心跳机制,及时释放一些无效的连接
3.2.4. 开源模型应用落地-业务优化系列
重点:使用线程池提升处理效率
重点:使用Redis队列和分布式锁实现请求排队
重点:使用SLB实现AI服务水平扩容
重点:多级数据缓存概述
重点:使用HanLP进行词性标注,并使用Redis作为一级缓存
重点:使用向量数据库作为二级缓存,来为AI服务减负,提升处理效率
重点:使用RocketMQ提升处理效率
重点:统计问题的请求频次,实现热门问题的实时缓存
3.2.5. 开源模型应用落地-安全合规系列
重点:使用DFA算法检测输入内容的合法性
重点:使用腾讯云文本内容安全服务检测输入内容的合法性

