
- 1网易区块链,网易区块链赋能赣州脐橙数字藏品,数字指纹解决方案
- 2Classical Maths Books Intro_analysis now
- 3【SpringCloud】6.RabbitMQ消息队列_之前说过,我们现在基于openfeign的调用都属于是同步调用,那么这种方式存在哪些问
- 4水资源管理:云计算在水资源管理中的优势
- 5【计算机毕业设计】springboot电子文档交易系统-04928,毕设开题选题+程序定制+论文书写+答辩ppt书写-原创(题目+编号)的定制程序
- 6微信小程序开发——上传图片_微信小程序开发上传图片
- 7大数据笔记-NIFI(第一篇)_apache nifi下载
- 8强化学习方法归纳_基于价值的强化学习方法
- 92024最新算法:河马优化算法(Hippopotamus optimization algorithm,HO)求解23个基准函数,提供MATLAB代码_河马优化算法python
- 10C#(C Sharp)学习笔记_If条件判断语句【五】_c#if判断语句
详解循环队列——链表与数组双版本
赞
踩
前言:本节内容主要是讲解循环队列。 在本篇中会讲到两个版本——数组版本、链表版本。本篇内容适合正在学习数据结构队列章节或者已经学过队列但对循环队列感觉模糊的友友们 。
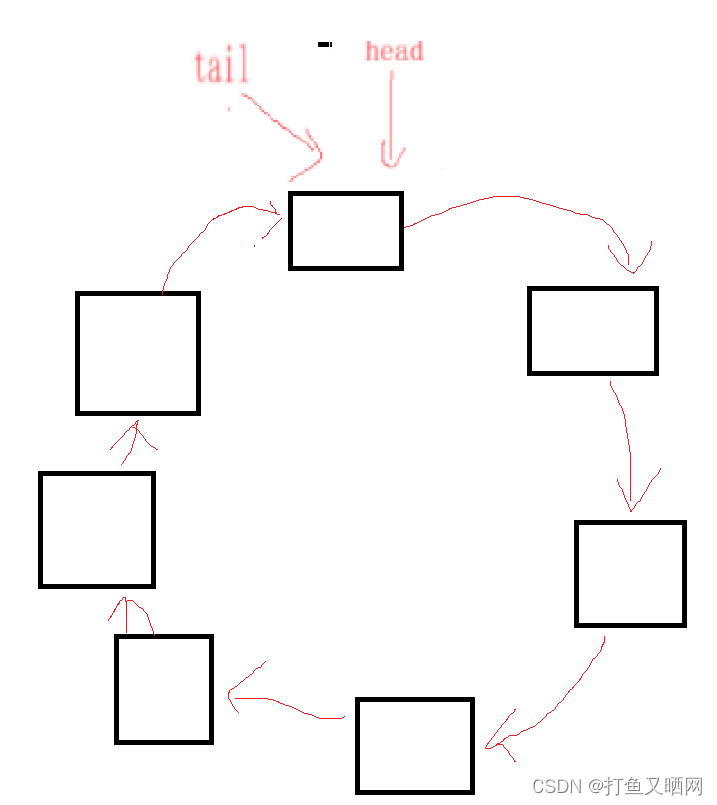
首先先来看一下什么是循环队列
什么是循环队列
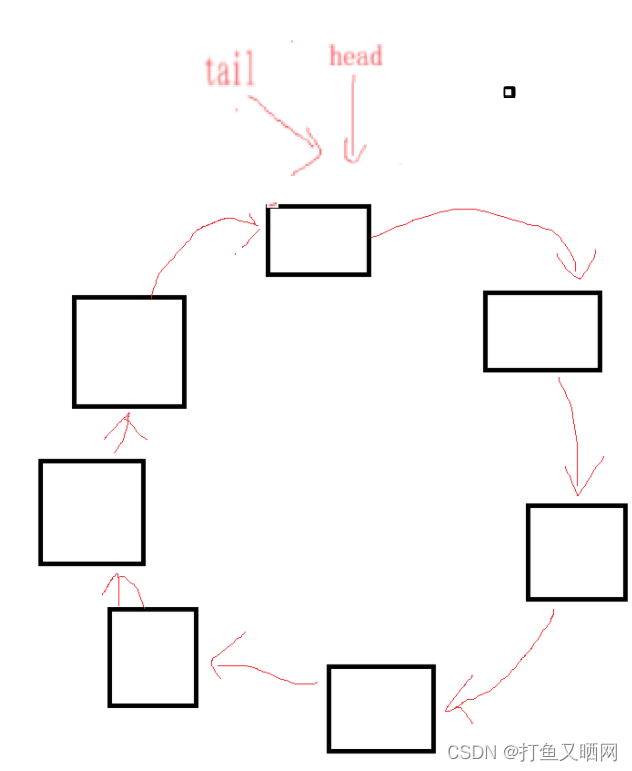
因为是刚开始讲解, 所以我们要先来看什么是循环队列:循环队列就是首和尾相连接的队列。如图分别是链表和数组形式的循环队列:
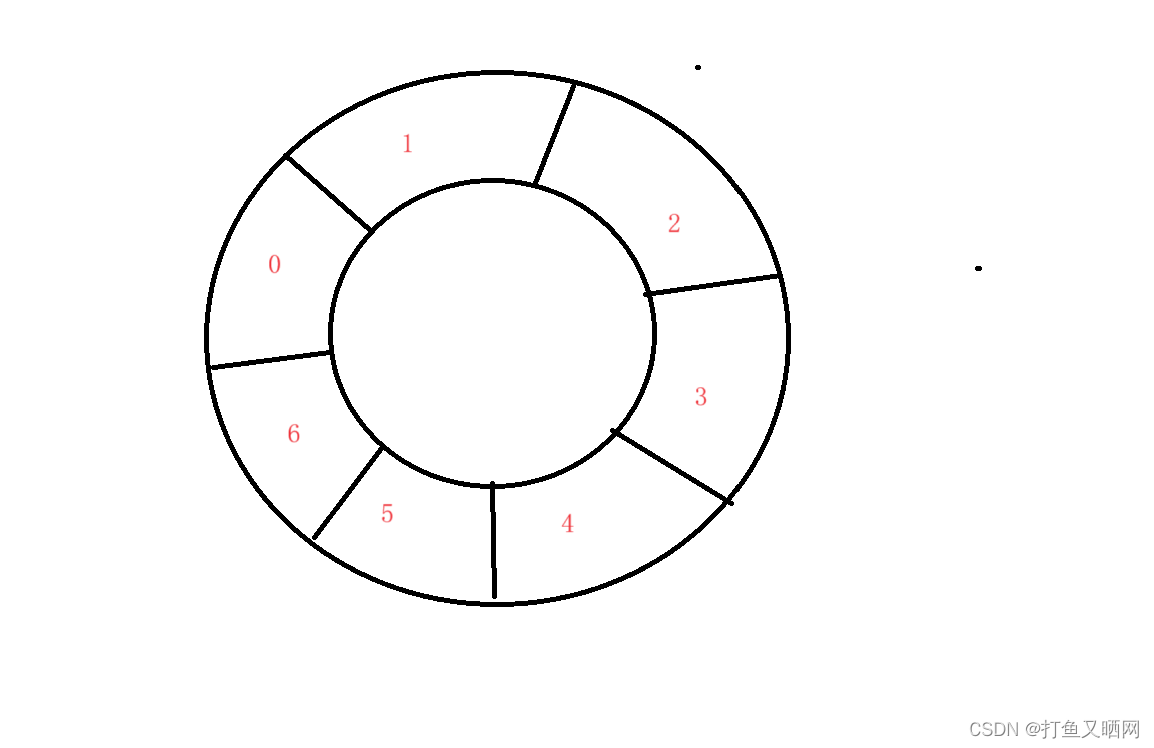

循环队列和普通队列的相同点是:都是从队尾进数据, 从队头出数据。
循环队列和普通队列的不同点是: 普通队列的容量是动态的, 会根据数据的增加而增加。 但是循环队列的容量是静态的, 它不会随着数据的增加而增加。 当队满时, 我们如果想要再添加数据, 只有将对头的数据取出来才能再次添加数据。 循环队列也被成为: 环形缓冲器。
数组版本
判断队空与队满
博主认为对于一个数组版本的循环队列来说, 最重要的就是如何判断它的队空与队满。我们先来看一下如何判断队空和队满
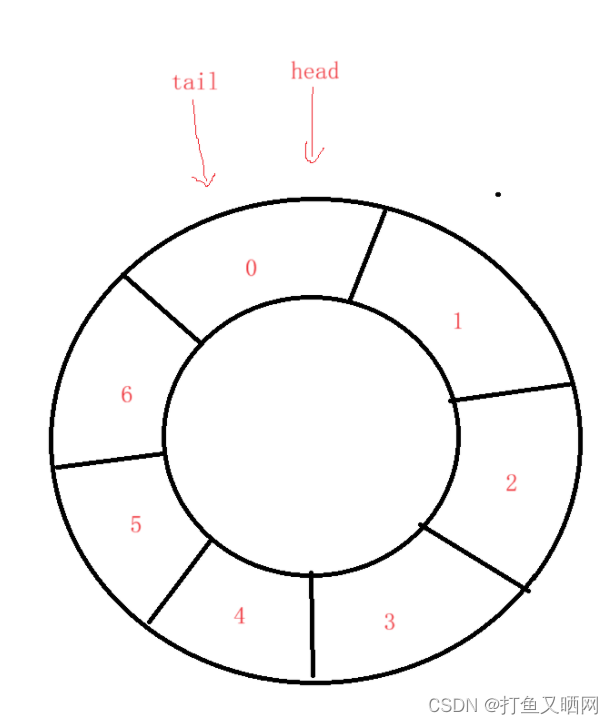
我们利用上图进行分析。 图中tail 和 head为两个指针。 队列中的数字不是存放的数据, 而是数组的下标索引。
我们假设初始化队空的时候tail 和 head指向同一块空间。 那么因为此时队空,所以tail 和head指向的这块空间内没有数据。
然后我们进行入队操作, 入队一个‘5’, 这个‘5’我用绿色用来表示存放的数据。如下图:
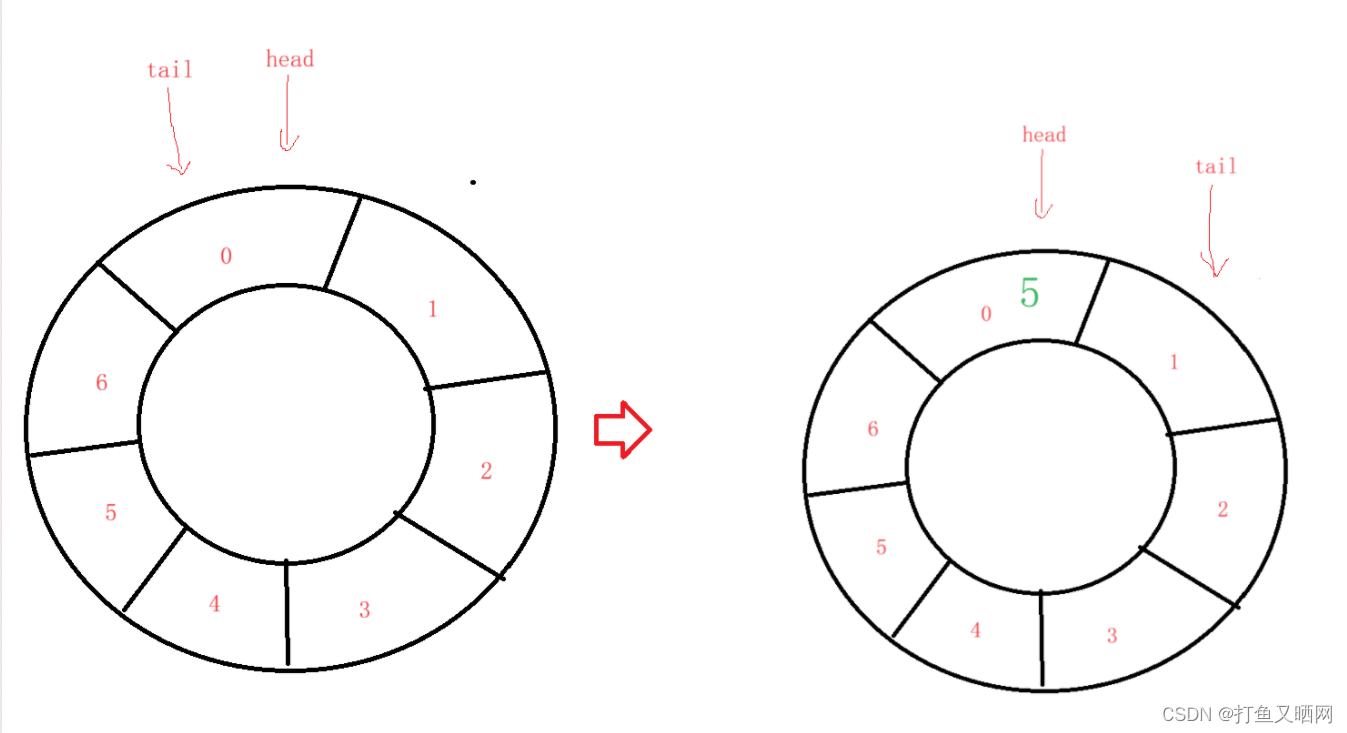
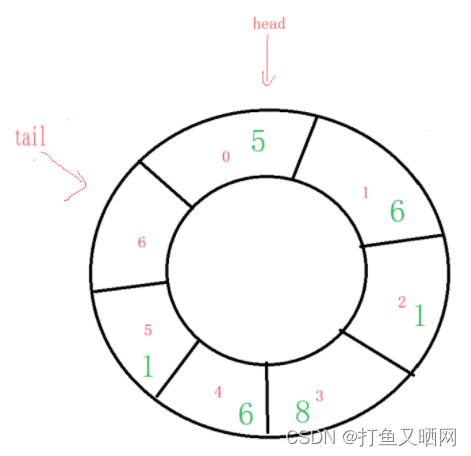
既然, ‘5’入队, 那么tail一定要向后移动一位, 所以结果就是上图的情况。 接下来我们再进行入队操作, 依次入队‘6’、‘1’、‘8‘、’6‘、’1‘。这些元素入队后的情况如下图: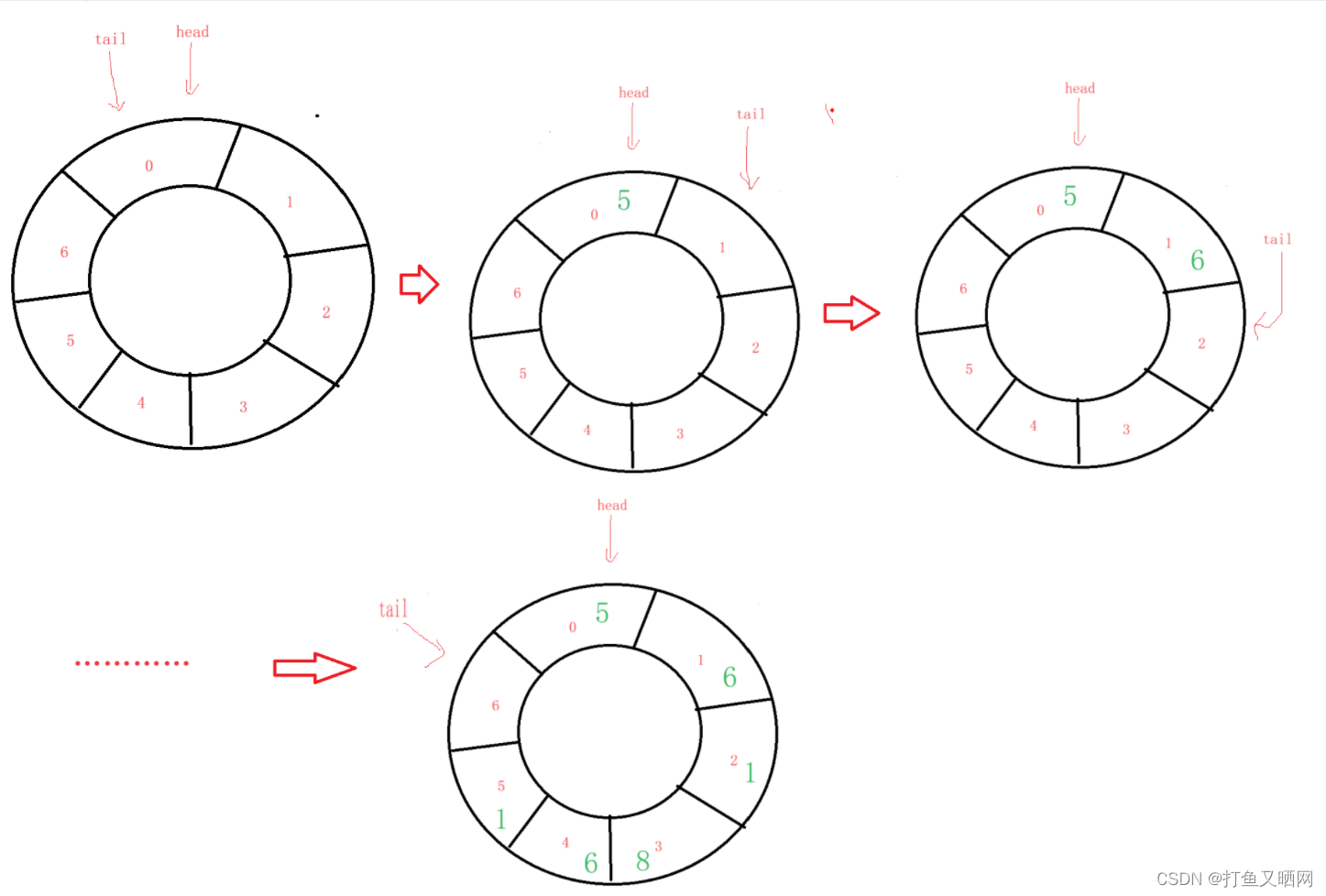
ok, 到了这一步请思考一下, 这个循环队列应该是此时为满, 还是应该再入队一个元素才满?
我们在这里进行假设如果再入队一个元素为满。 那么再入队一个元素后,假设这个元素为‘5’,循环队列的情况就是这个样子:
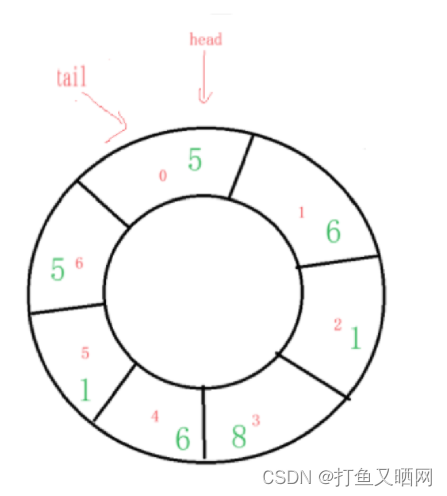
现在, 请将这两个图对比着看:
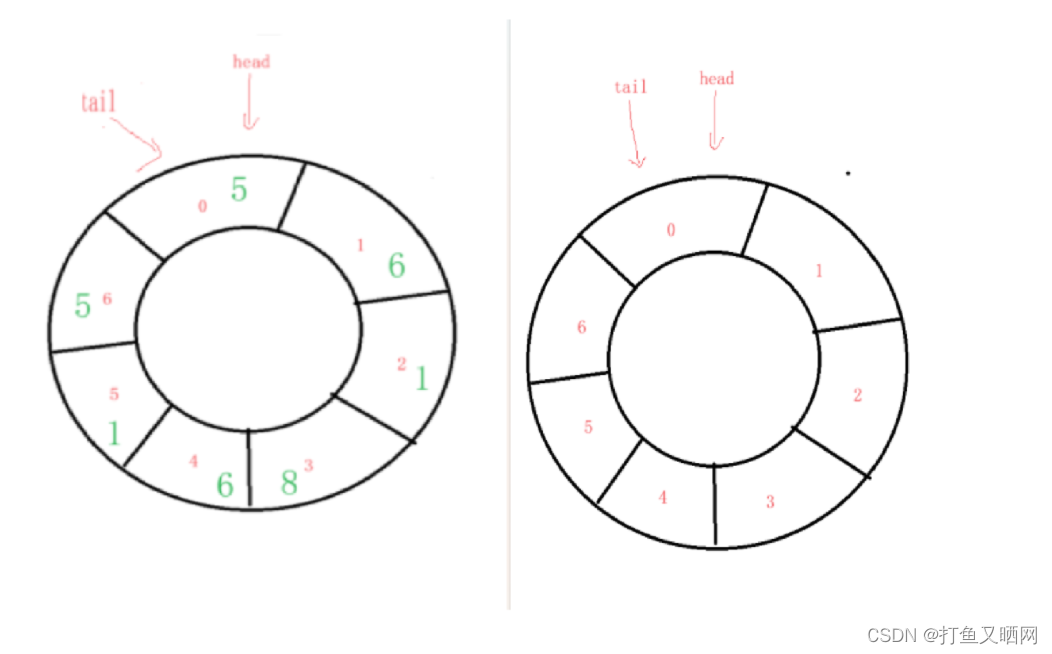
要知道, 如果此时的状态为满, 那么判满的条件就是 tail == head ; 而判空的条件我们上面说到了也是 tail == head 。那么我们如何区分这个条件下到底是满还是空?所以我们的假设是错误的。真正为满的时候应该是这样的:
这个时侯其实就是该循环队列队满的情况。 那么为什么会空出来一个位置, 这个位置怎么处理? 对于这个问题。 回答是循环队列的元素个数要比开的空间数小一。 当然有别的办法解决这个问题, 但是传统的数组循环队列, 这里就是这样处理的:元素个数的最大容量要比开的空间数小一。
入队和出队
第二个重要的需要搞明白的就是对于数组循环队列来说的插入和删除。指针如何偏移的问题。
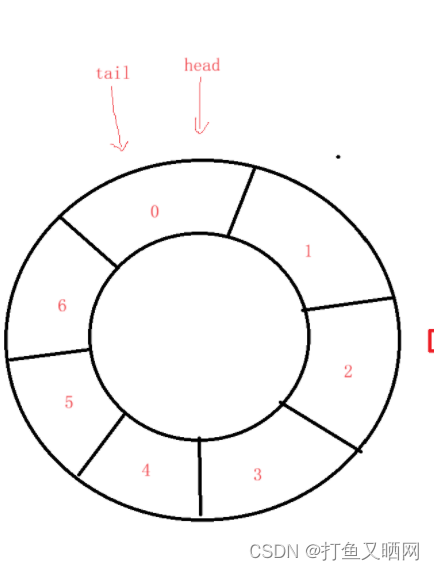
我们在上面画的这个圆是我们想象出来的逻辑结构, 而真正的数组应该是一串连续的空间。 如下图:
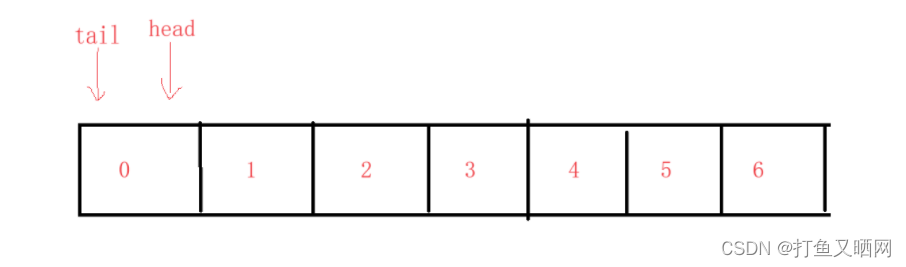
那么如果我们给这个队列入数据, 当队满时真正的物理结构其实是这种情况:
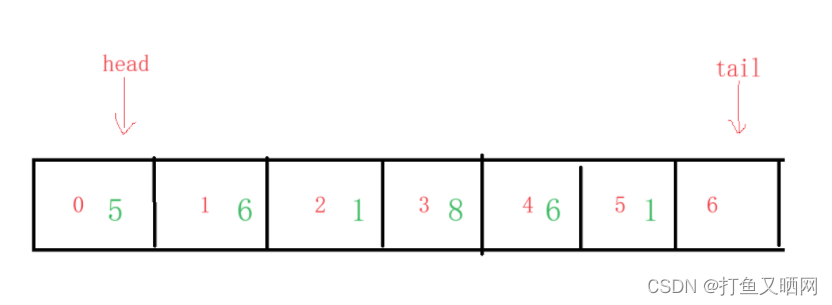
逻辑结构是这样的情况:
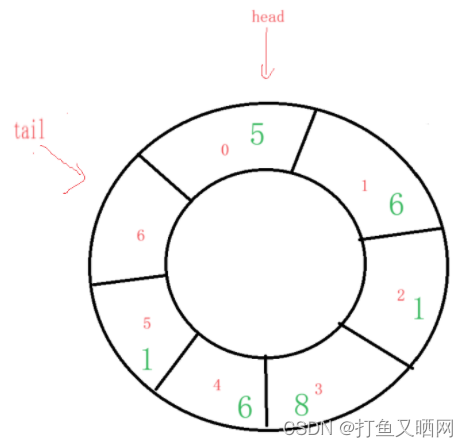
然后我们出一次数据:
这是物理结构:
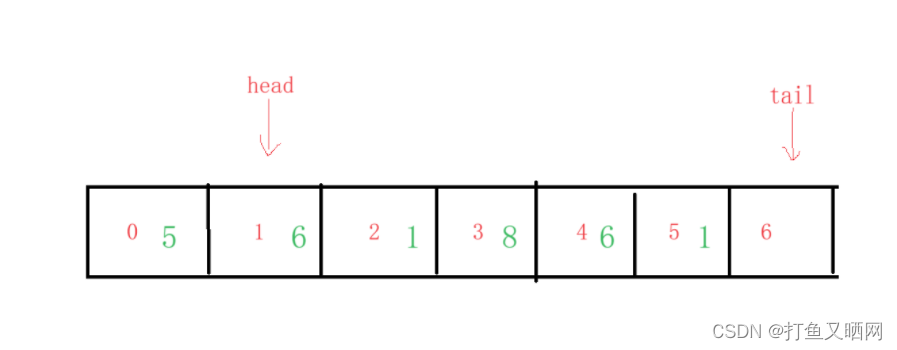
这是逻辑结构:

从逻辑结构我们可以看出来循环队列这个时候已经不是队满了。 但是在真正的物理结构里我们如果入数据, 那么tail指针就会越界。 如何解决这个问题呢?
这里用到的是一点数学的运算。
我们设这个循环队列的最大空间是数是:maxsize。那么我们只需要在每次入数据和出数据的时候让tail或者head模上一个maxsize就可以解决这个问题。
比如图中tail == 6, maxsize == 7. 那么当tail向后移动一位时, 再取模变成 (tail + 1) % maxsize;
所以, 综上,当tail 指针或者 head指针在进行入队或者出队时, 要进行的操作是 : (tail + 1) % maxsize 或者 (head + 1) % maxsize;
取对头和取队尾
取对头比较简单, 因为head指针指向的位置就是对头的位置。如图:

这个时候我们直接取对头的数据 :
data[head]; //伪代码但是取队尾就可能有问题。 就像上图,此时tail指向了索引为0的位置。 然后在逻辑结构上面我们看到只要 tail - 1 就可以拿到索引为6的队尾数据5。但是要知道, 上图的是逻辑结构。 这个循环队列真正的物理结构应该是一块连续的数组, 就像下图这样:
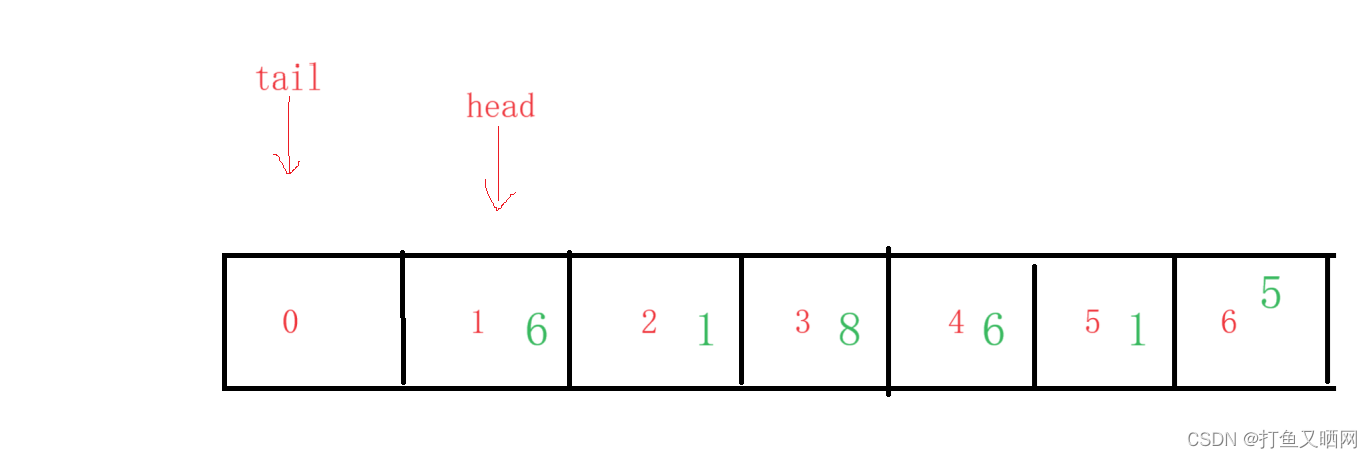
这个时候我们直接取 data[tail - 1]就会越界访问,显然是不正确的。
那么解决这个问题也是用取模的方法, 但是在取模的时候要先加上一个maxsize。也就是这样
- int index = (tail - 1 + maxsize) % maxsize;
- data[index]; //伪代码
当tail - 1 >= 0的时候,加上maxsize 再模上maxsize相当于将加上的maxsize又消去了。
当tail - 1 < 0的时候, 加上maxsize就变成了小于maxsize的正数, 取模后还是它本身。
以上, 就是取对头和取队尾的需要注意的事项。
代码
知道了上面的知识点后, 我们就可以着手用代码实现我们的循环队列了。 由于知识点已经讲过了, 所以代码直接贴图了。部分内容会有注释, 但不做讲解。
-
- //重定义数据类型。 便于维护
- typedef int SQDataType;
-
- typedef struct SeqQueue
- {
- SQDataType* _data;
- int _tail;
- int _head;
- int _maxsize;
- }SQ;
-
-
- //初始化 maxsize为循环队列的最大容量
- void Init_SQ(SQ* sq, size_t maxsize)
- {
- sq->_maxsize = maxsize;
- sq->_data = (SQDataType*)malloc(sizeof(SQDataType) * maxsize);
- //
- sq->_tail = 0;
- sq->_head = 0;
- }
-
- //判断队满
- bool judge_full(SQ* sq)
- {
- return (sq->_tail + 1) % sq->_maxsize == sq->_head; //逻辑上tail + 1 == head为队满
- }
-
- //判断队空
- bool judge_empty(SQ* sq)
- {
- return sq->_tail == sq->_head; //当tail == head队空
- }
-
- //入队列
- void Push_SQ(SQ* sq, SQDataType data)
- {
- //先判断队列是否为满, 如果满了就返回
- if (judge_full(sq))
- {
- printf("队满\n");
- return;
-
- }
-
- sq->_data[sq->_tail] = data;
- sq->_tail = (sq->_tail + 1) % sq->_maxsize; //入队列要取模
- }
-
- //出队列
- void Pop_SQ(SQ* sq)
- {
- //判断队列是否为空, 如果为空就返回
- if (judge_empty(sq))
- {
- printf("队空\n");
- return;
- }
-
- sq->_head = (sq->_head + 1) % sq->_maxsize;
- }
-
- //取对头数据
- SQDataType Top_SQ(SQ* sq)
- {
- //判断是否为空
- if (judge_empty(sq))
- {
- printf("队空\n");
- exit(-1);
- }
-
- return sq->_data[sq->_head];
- }
-
- //取队尾数据
- SQDataType Back_SQ(SQ* sq)
- {
- //判断是否为满
- if (judge_empty(sq))
- {
- printf("队空\n");
- exit(-1);
- }
- int index = ((sq->_tail - 1) + maxsize) % maxsize;
- return sq->_data[index];
- }

链表版本
入出队以及取队中数据
其实循环队列链表版本要比数组版本更加麻烦。 首先我在这里先抛出几个问题:
首先, 我们让这个循环队列的初始位置仍旧是tail == head。 那么它的队满位置由上面的学习我们知道是 tail->next == head;(下图中绿色数字表示节点中存放的数据)
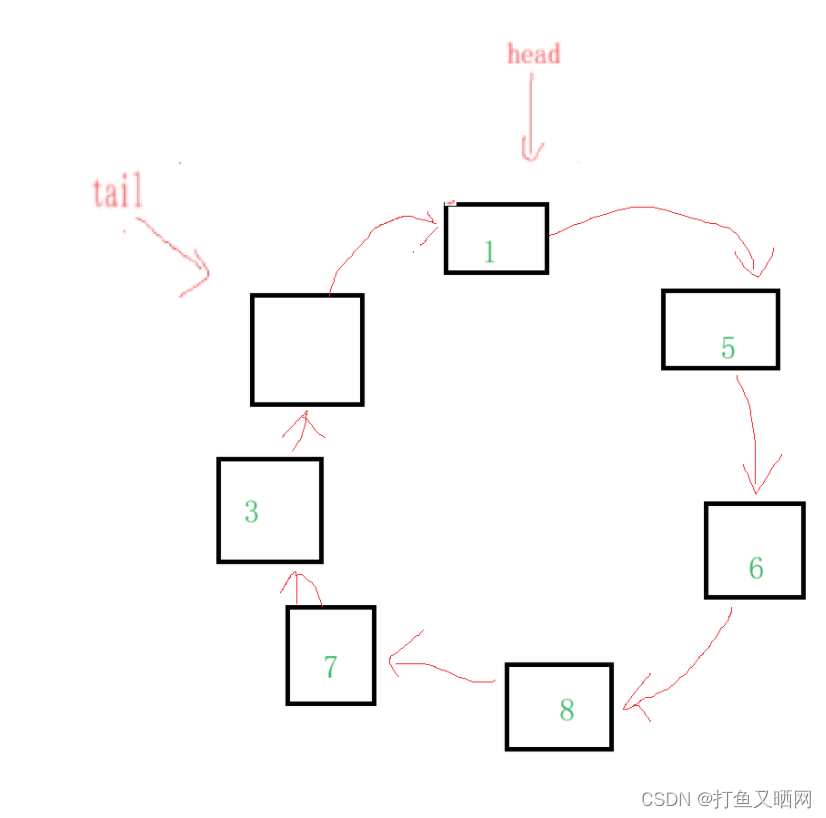
这里有两个问题:
- 我们如何取到队尾的元素?
- 我们如何进行出队和入队操作?出队需要释放节点吗? 如果释放节点, 那么入队时是不是需要申请节点?又或者我们直接偏移指针就可以?
对于这两个问题, 我们先来思考一下第一个问题:
想要取到队尾元素, 就要拿到tail指向节点的前一个节点。 那么就有两个办法解决这个问题——第一个办法就是创建一个前置指针指向tail的前一个节点, 如图:
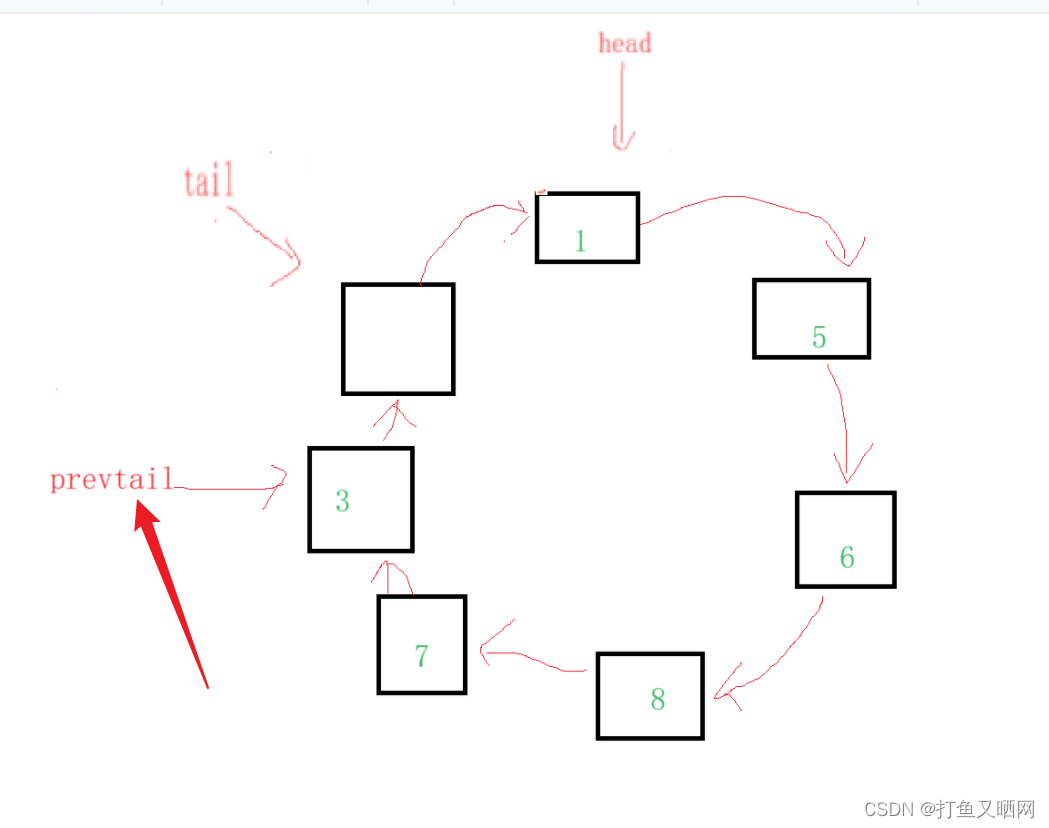
第二个办法就是弄成双向链表
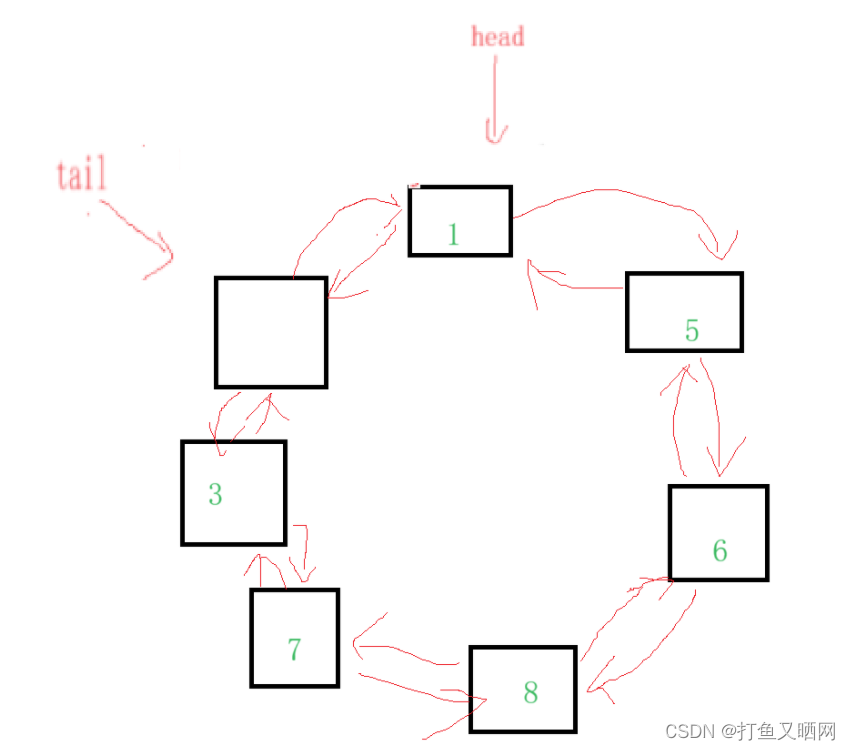
这样取队尾就可以直接访问tail的前一个节点。
然后再思考第二个问题:我们在入队和出队的时候需要释放节点和申请节点吗?
那么请看如果我们释放节点的时候会发生什么情况?如图是该循环队列的某个状态:
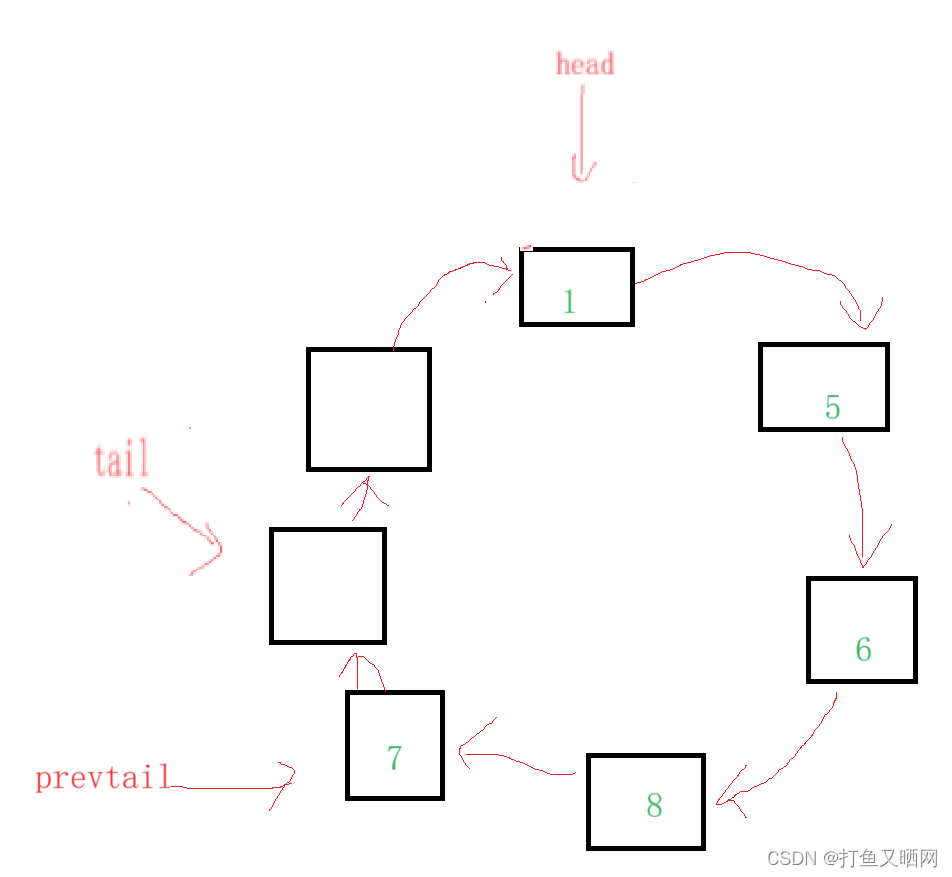
在这个状态下, 我们如果出队, 那么释放节点后让head指向下一个节点:
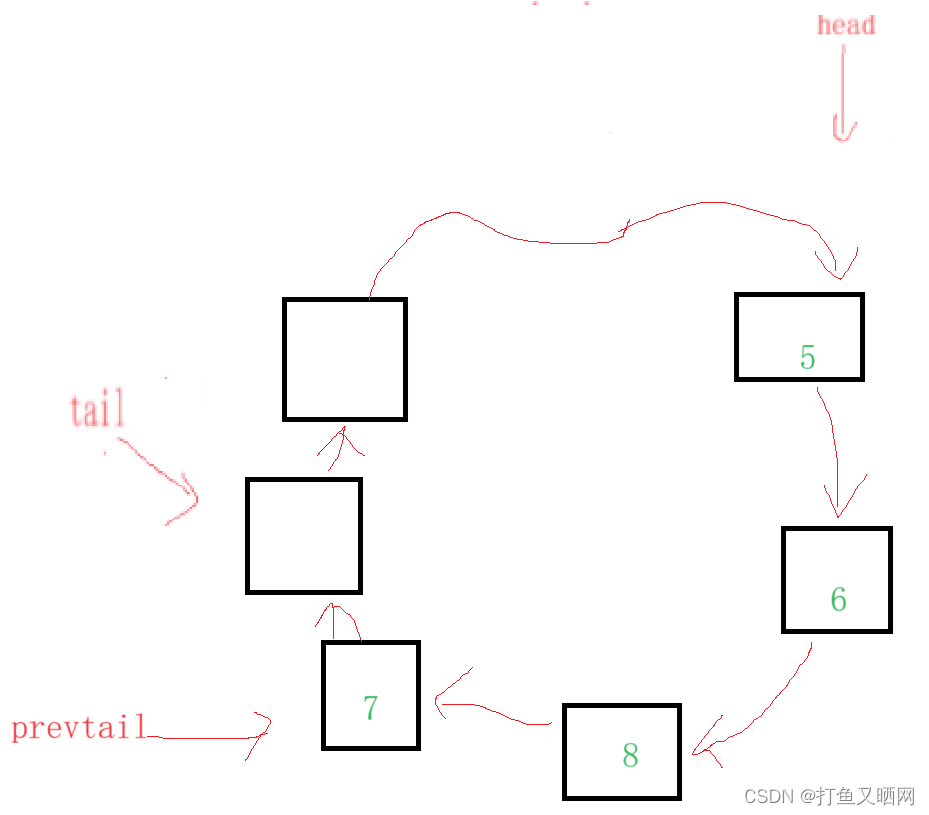
那么注意, 现在的容量减少了。 我们如果再进行入队, 假设我们入一个’5‘。 那么就变成了

好, 现在我们再对比一下这个状态和开始的状态:
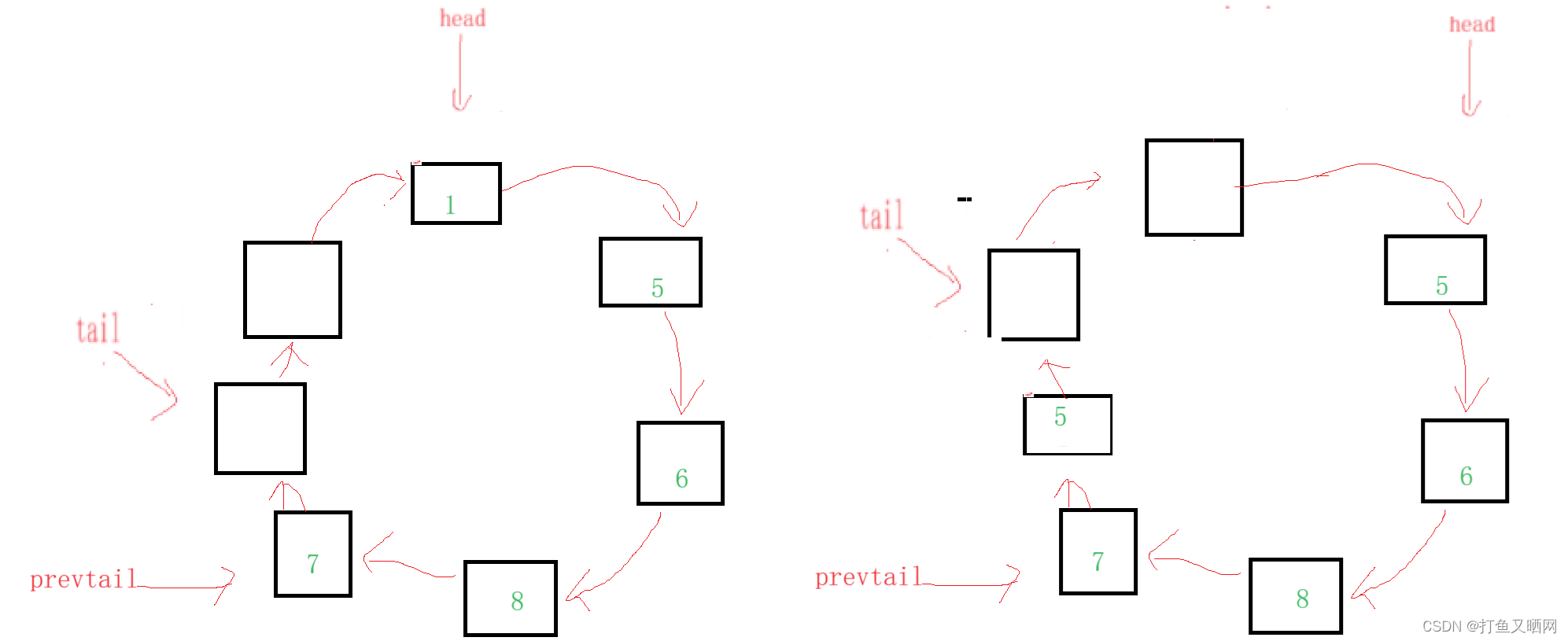
这两种状态, 是不是就是相当于head指针从一开始的指向1那个节点, 然后向后偏移一个节点。 而tail指针也相当于向后偏移了一个节点。 那么我们还有必要释放和申请节点来进行操作吗? 是不是只要偏移指针就可以了?这样是不是减少了申请和释放节点的成本, 更快更简便?
所以, 综上, 我们就可以推断出, 链表的入队和出队操作我们不必要申请和释放节点, 和数组版本一样, 只要指针偏移即可。
循环队列的初始化
链表循环队列另一个比较重要的要搞清楚的就是 这个队列的初始化结构是什么样的?
其实,我们在初始化的时候将所有节点开好就可以, 然后让tail指针和head指针指向同一个节点。如图:
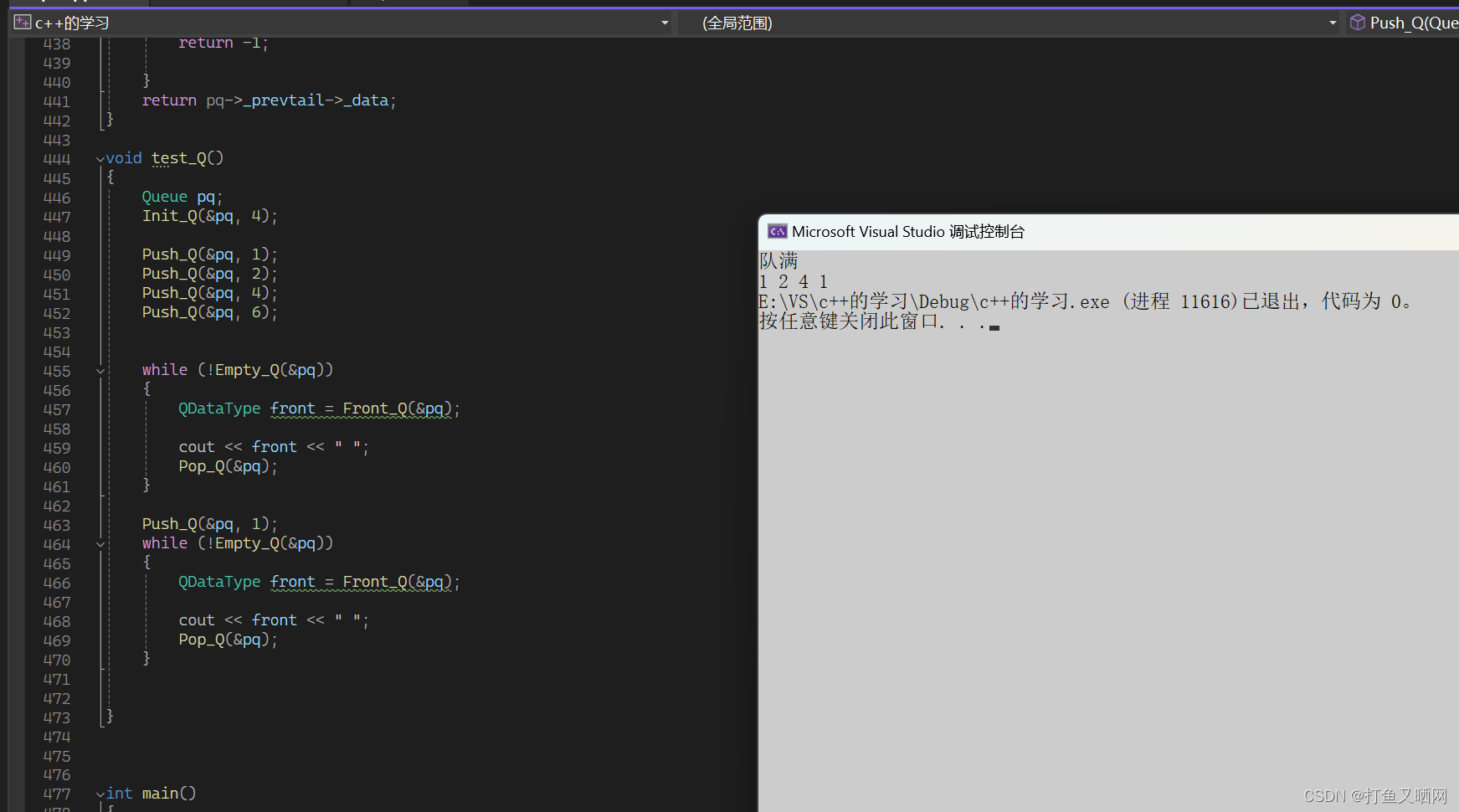
代码
知道上面的所有注意事项后, 我们就可以设计链表循环队列了。 这里使用前置prevtail解决取队尾的问题。 如下为代码:
- typedef int QDataType;
-
- typedef struct QueueNode
- {
- QDataType _data;
- QueueNode* _next;
- }QNode;
-
- struct Queue
- {
- QNode* _head;
- QNode* _tail;
- QNode* _prevtail;
- };
-
-
- //链表队列初始化
- void Init_Q(Queue* pq, int n)
- {
- pq->_head = NULL;
- pq->_tail = NULL;
- QNode* cur = NULL;
- while (n)
- {
- if (cur == NULL) //创建第一个节点, head, tail , prev都指向第一个节点
- {
- cur = pq->_head = pq->_tail = pq->_prevtail = new QNode;
- cur->_next = NULL;
- }
- else //创建之后的节点
- {
- cur->_next = new QNode;
- cur = cur->_next;
- }
- n--;
- }
- cur->_next = pq->_head; //成环
- }
-
- //判断空
- bool Empty_Q(Queue* pq)
- {
- return pq->_head == pq->_tail;
- }
-
- //判断队满
- bool Full_Q(Queue* pq)
- {
- return pq->_tail->_next == pq->_head;
- }
-
- //入队列
- void Push_Q(Queue* pq, QDataType x)
- {
- if (Full_Q(pq))
- {
- printf("队满\n");
- return;
-
- }
- //将数据给tail,prev到tail的位置,tail向后偏移一位
- pq->_tail->_data = x;
- pq->_prevtail = pq->_tail;
- pq->_tail = pq->_tail->_next;
- }
-
- //出队列
- void Pop_Q(Queue* pq)
- {
- if (Empty_Q(pq))
- {
- printf("队空\n");
- return;
-
- }
-
- //head指针向后移动一位即可
- pq->_head = pq->_head->_next;
- }
-
-
- //取队头
- QDataType Front_Q(Queue* pq)
- {
- if (Empty_Q(pq))
- {
- printf("队空\n");
- return -1;
-
- }
-
- return pq->_head->_data;
- }
-
- //取队尾
- QDataType Back_Q(Queue* pq)
- {
-
- if (Empty_Q(pq))
- {
- printf("队空\n");
- return -1;
-
- }
- return pq->_prevtail->_data;
- }
--------------------------------------------------------------------------------------------------------------------------------
以上就是本节的全部内容。

