
热门标签
热门文章
- 1数据分享及分析方法——热门气象数据集_室内温度数据集
- 2从入门到入土,万字超详细Redis学习笔记 【基础篇】+【实战篇】
- 3【JavaWeb】SpringBootWeb入门_javaweb和springboot
- 4前端TypeScript学习day04-交叉类型与泛型_ts 泛型交叉类型工具
- 5云原生是整个信息化行业的未来,一文彻底搞懂云原生_云原生为啥会发展起来
- 6【Kafka】Kafka消息乱码解决
- 7集成Redis优化登录模块_redis优化登录流程
- 8操作系统安全:Windows与Linux的安全标识符,身份鉴别和访问控制_linux管理员用户的安全标识符
- 9MobaXterm的安装和使用_mobaxterm mac
- 10【C++】模板中template、typename的非常见用法_c++中typename和template
当前位置: article > 正文
Hadoop3:HDFS读数据的流程讲解
作者:我家自动化 | 2024-05-19 11:46:23
赞
踩
Hadoop3:HDFS读数据的流程讲解
一、场景描述
我们登陆HDFS的web端,下载一个大文件。
二、流程图
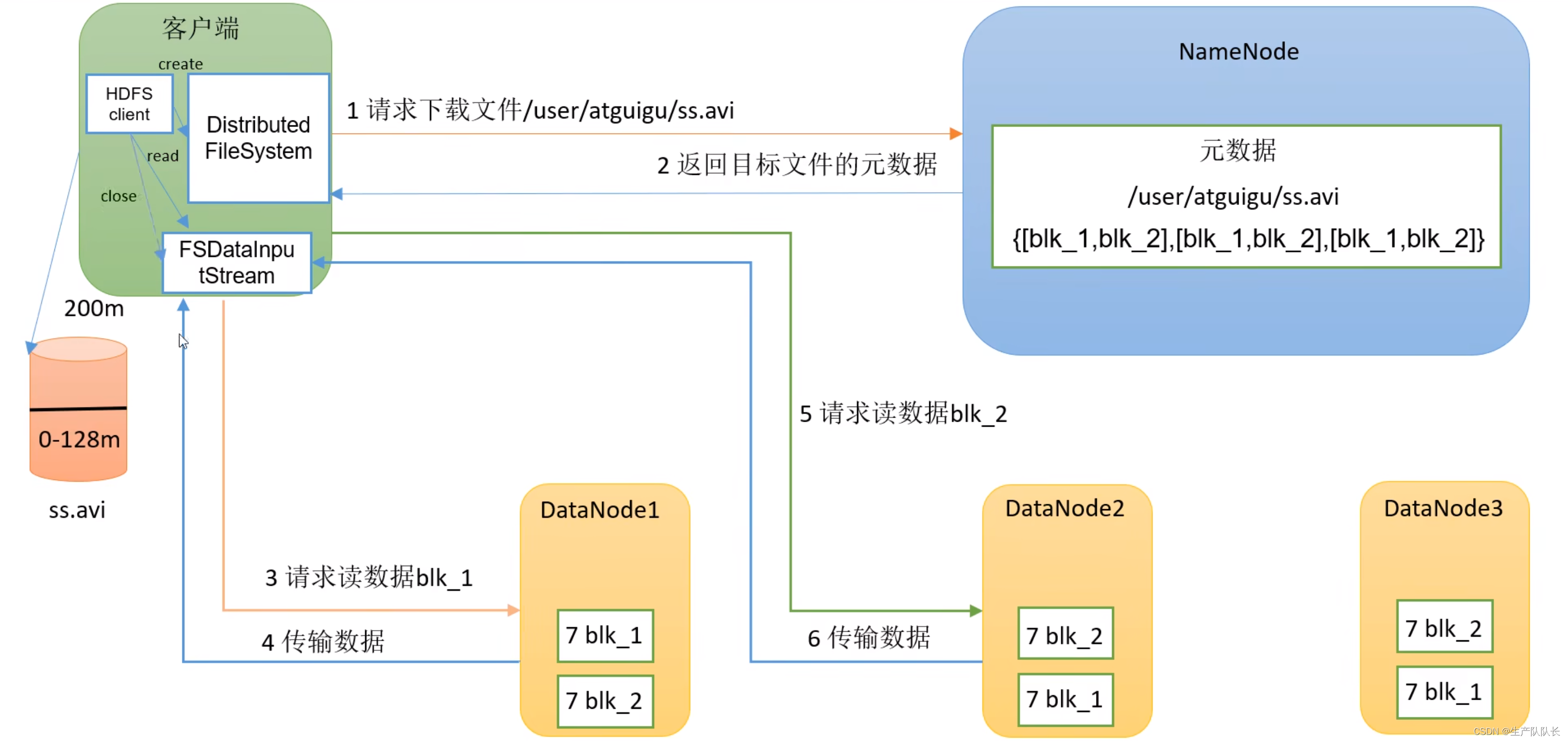
三、讲解
流程1(Client与NameNode交互)
1、HDFS client创建DistributedFileSystem,通过dfs与NameNode进行1次(一来一回2次)对话(request和response),如图所示。
2、NameNode收到client的请求后,首先,检查用户权限,是否有下载该文件的权限。其次,检查元数据里是否存在该文件信息。通过后,则将对应的元数据信息,反馈给client。
流程2(Client与DataNode交互)
3、client收到元数据后,创建FSDataOutputStream,并选择相应的副本节点,进行读取下载。此时,选择节点的两条原则:1、距离最近。2、节点请求量负载够用。
4、读数据,按顺序,先读blk1,在读blk2.是串行下载的。
5、DataNode是以Packet为单位进行数据校验与传输的,client以Packet为单位进行接收。先缓存,后写入磁盘。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/592693
推荐阅读
相关标签

