
- 1ChatGPT之后,值得关注的垂直领域大模型
- 2BERT文本分类实战_bert进行英文分类
- 3【iVX】iVX的低代码未来发展趋势:加速应用开发的创新之路_ivx发展规划
- 4最常问的MySQL面试题集合
- 5单片机开发教程3——串口发送MPU6050姿态角_mpu6050数据 串口收发
- 6基于Java的XxlCrawler网络信息爬取基础篇
- 7Android studio页面跳转时闪退_安卓跳转多次activity闪退
- 8【蚂蚁笔试题汇总】[全网首发] 2024-03-30-蚂蚁春招笔试题-三语言题解(CPP Python Java)_蚂蚁笔试解析
- 9「6.1K Star 项目推荐」github主页”快速装修“神器
- 10【微信小程序】基础篇 -- 案例 - 本地生活(列表页面)(三十)_微信小程序设计实例
百万奖金赛事之(时间序列)供水管网压力预测--方案分享_2018至2019年的30个压力监测点近两年的压力数据、2018年至2019年的天气数据,以及
赞
踩
一、赛题描述
主办方提供某新区供水管网数据,数据划分如下:
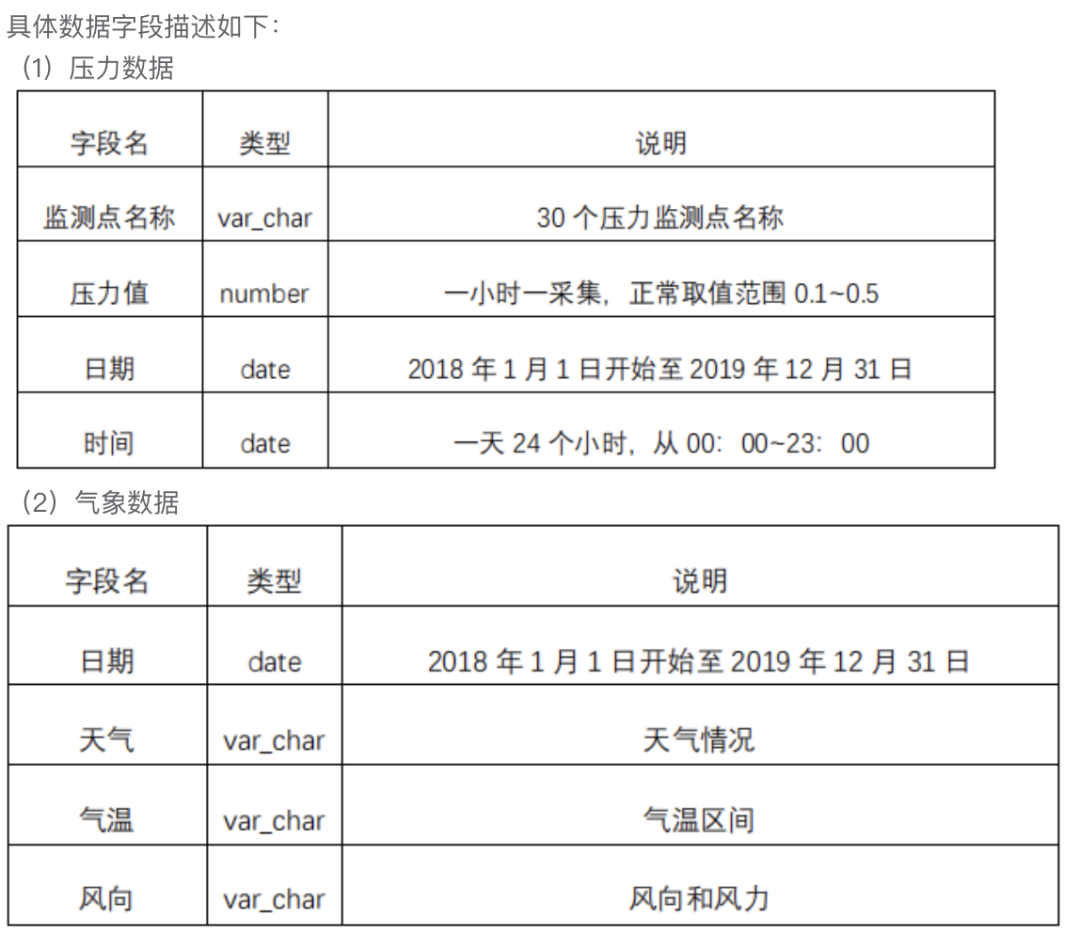
训练集:2018至2019年的30个压力监测点近两年的压力数据、2018年至2019年的天气数据,以及标明了30个压力监测点位置的供水管网互通图。
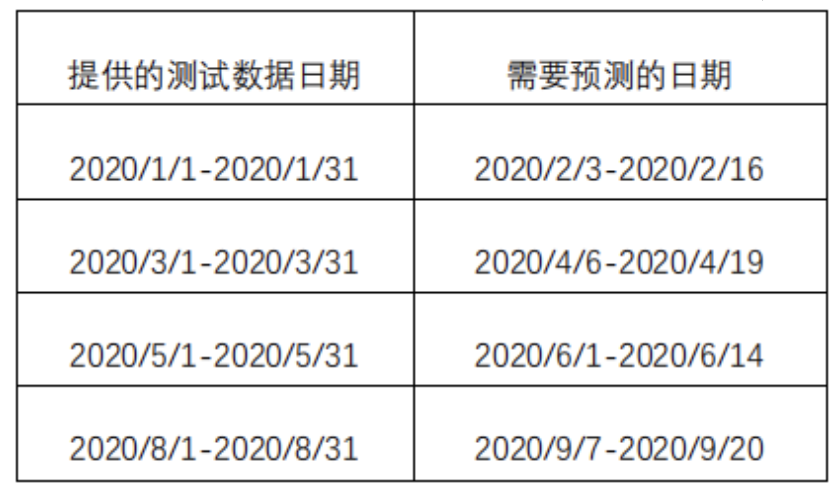
测试集:以下4段时间的每小时的压力数据、每天的天气数据,需要分别去预测对应日期每小时的压力数据。
![]()
注1:压力监测点数值中数值为0或者负数时为非有效数值。
注2:压力数据,每小时1条数据记录;气象数据,每天1条数据记录。
注3:选手不能利用“未来的实际数据”预测“过去的数据”,例如,假设要预测2020/2/13 23:00的压力值,就不能利用这个时间点以后的真实数据进行预测,尤其需要注意气象数据的使用。
注4:天气原因会对居民用水造成影响,而居民用水情况又会对压力产生一定的影响。例如,假设某新区内管网总供水数量保持恒定,30个压力监测点都同时受居民用水量增减影响,居民用水量大,必然造成管网压力监测点数值下降,反之压力升高。
注5:本次大赛提供的全部数据、信息等,视为水务的保密信息。未经允许,任何人不可以任何形式使用、传播、披露、授权他人使用。作品必须健康、合法、无任何不良信息及商业宣传行为,不违反任何中华人民共和国有关法律。须保证原创性,不侵犯任何第三方知识产权或其他权利;一经发现或经权利人指出,主办方将直接取消其参赛资格,主办方保留赛事解释权。
二、评分标准
本模型依据提交的结果文件,采用均方误差MSE进行评价。
观测值actual(t),预测值forecast(t),待预测的样本数为n,计算公式如下:
参考代码如下:
- from sklearn.metrics import mean_squared_error
- y_true = [0.1,0.2,0.3,0.4]
- y_pred = [0.2,0.2,0.2,0.3]
- mse = mean_squared_error(p_true, y_pred)
注:本次竞赛将mse值扩大了10000倍,即最终得分为:score=mse*10000
三、赛题的一些解题思路
1.防止时间穿越问题
由于他是给出2018-2019年的训练数据,预测2月中的14天,1月份做验证;预测4月中的14天,给出3月份做验证;预测6月中的14天,给出5月份做验证;预测9月中的14天,给出8月做验证。
因此在做每一段的预测时候,不能拼接所有的验证集去训练,否则就会用到未来数据信息,而是采用分段预测,这里我只用到了2020年的数据(也就是把官方给的验证数据当作训练集),分段预测如下:
- # 分段1
- train1 = train2020[(train2020['Time_time'] >= '2020-1-1') & (train2020['Time_time'] <= '2020-1-31')]
- test1 = test[(test['Time_time'] >= '2020-2-3') & (test['Time_time'] <= '2020-2-16')]
- #分段2
- train2 = train2020[(train2020['Time_time'] >= '2020-3-1') & (train2020['Time_time'] <= '2020-3-31')]
- test2 = test[(test['Time_time'] >= '2020-4-6') & (test['Time_time'] <= '2020-4-19')]
- #分段3
- train3 = train2020[(train2020['Time_time'] >= '2020-5-1') & (train2020['Time_time'] <= '2020-5-31')]
- test3 = test[(test['Time_time'] >= '2020-6-1') & (test['Time_time'] <= '2020-6-14')]
- #分段4
- train4 = train2020[(train2020['Time_time'] >= '2020-8-1') & (train2020['Time_time'] <= '2020-8-31')]
- test4 = test[(test['Time_time'] >= '2020-9-7') & (test['Time_time'] <= '2020-9-20')]
2.异常值的处理
由于训练集中压力数据有不少的-9999,一方面会影响模型学习历史的趋势信息,另一方面还会影响我们的线下评判,无法估算线上结果。
对异常值的处理有很多想法,比如-9999的上一个值填充、下一个值填充、众数填充、前后两个值的均值填充等;这里我们采用上一个值填充,后面发现前后两个值均值填充效果更好,大家可以自行优化一下。
- def abnormal(df):
- '''
- 处理-9999异常值: 上一个值填充
- '''
- index_value = list(df[df['pressure'] == -99999].index)
- for i in index_value:
- value = df[df.index== (i - 1)]['pressure'].iloc[0]
- df.loc[i, 'pressure'] = value
- return df
- train2018 = abnormal(train2018)
- train2019 = abnormal(train2019)
- train2020 = abnormal(train2020)
3.添加历史行为信息
由于只用了2020年数据,例如1月份训练,预测2月份,模型是无法学习到月份之间带来的差异,因此根据2018年或者2019年的月份之间的压力数据差距,可以直接平移加和到2020年上来(也可以尝试权重衰减的的平移加和上去)
- #分段1的历史数据信息
- train2019Mon2 = train2019[(train2019['Time_time'] >= '2019-2-1') & (train2019['Time_time'] <= '2019-2-28')]
- train2019Mon1 = train2019[(train2019['Time_time'] >= '2019-1-1') & (train2019['Time_time'] <= '2019-1-28')]
- Mon_2_1_2019 = train2019Mon2['pressure'].mean() - train2019Mon1['pressure'].mean()
- test1['pressure'] = preds + Mon_2_1_2019
- #分段2的历史数据信息
- train2019Mon4 = train2019[(train2019['Time_time'] >= '2019-4-1') & (train2019['Time_time'] <= '2019-4-30')]
- train2019Mon3 = train2019[(train2019['Time_time'] >= '2019-3-1') & (train2019['Time_time'] <= '2019-3-30')]
- Mon_4_3_2019 = train2019Mon4['pressure'].mean() - train2019Mon3['pressure'].mean()
- test2['pressure'] = preds + Mon_4_3_2019
- #分段3的历史数据信息
- train2019Mon6 = train2019[(train2019['Time_time'] >= '2019-6-1') & (train2019['Time_time'] <= '2019-6-30')]
- train2019Mon5 = train2019[(train2019['Time_time'] >= '2019-5-1') & (train2019['Time_time'] <= '2019-5-30')]
- Mon_6_5_2019 = train2019Mon6['pressure'].mean() - train2019Mon5['pressure'].mean()
- test3['pressure'] = preds + Mon_6_5_2019
- #分段4的历史数据信息
- train2019Mon9 = train2019[(train2019['Time_time'] >= '2019-9-1') & (train2019['Time_time'] <= '2019-9-30')]
- train2019Mon8 = train2019[(train2019['Time_time'] >= '2019-8-1') & (train2019['Time_time'] <= '2019-8-30')]
- Mon_9_8_2019 = train2019Mon9['pressure'].mean() - train2019Mon8['pressure'].mean()
- test4['pressure'] = preds + Mon_9_8_2019

4.站点之间会影响压力数据值
这里YIN叔提供了一种想法,根据压力数据度量站点之间的距离,从而转化为站点之间的联系。
- for i in range(1,31):
- for j in range(1,31):
- df = df3[(df3["MeasName"]=="站点"+str(i))&(df3["Month"]=='01')]
- pressure0 = df["pressure"].values
-
- df = df3[(df3["MeasName"]=="站点"+str(j))&(df3["Month"]=='01')]
- pressure1 = df["pressure"].values
-
- d = np.linalg.norm(pressure0-pressure1)
- print(str(round(d,2))+" ",end=" ")
- print()
四、总结
-
这份base中还没有使用气象数据表,大家可以考虑添加进去训练构建一些特征训练;
-
仅使用了2020年数据,可以添加2018、2019年的数据自行划分训练集训练;
关注公众号ChallengeHub回复“水管”获取5.84分完整代码。想了解更多方案干货,请关注我们!!!
最后欢迎大家关注我们的公众号:ChallengeHub,加入ChallengeHub粉丝群,共同探讨,共同学习,共同进步!!!


