
热门标签
热门文章
- 1深度学习知识点:循环神经网络(RNN)、长短期记忆网络(LSTM)、门控循环单元(GRU)_循环神经网络与传统神经网络的区别
- 2社交网络图中结点的“重要性”计算【Floyd算法】_在社交网络中,个人或单位(结点)之间通过某些关系(边)联系起来。他们受到这些关系
- 3【NLP】一文带你了解LLAMA(羊驼)系列
- 4stm32 Flash 简单应用 减少擦除 提高寿命_stm32f103rct6 flash寿命
- 5【Linux】yum与vim命令详解_yum vim
- 6Android 中资源文件夹RES/RAW和ASSETS的使用区别_raw文件夹
- 7代码行统计工具---cloc(Count Lines of Code)_代码统计工具
- 8系统移植——STM32MP135_stm32mp135移植教程
- 9C进阶-动态内存管理+柔性数组
- 10selenium使用代理IP(1)
当前位置: article > 正文
【大数据工具】Spark 伪分布式、分布式集群搭建_spark伪分布式集群搭建
作者:我家自动化 | 2024-05-23 04:16:26
赞
踩
spark伪分布式集群搭建
Spark 集群搭建
Spark 安装包下载地址:https://archive.apache.org/dist/spark/
1. Spark 伪分布式安装
安装前提:安装 Spark 前需要先安装好 JDK
1. 上传并解压 Spark 安装包
- 使用 fileZilla 或其他文件传输工具上传 Spark 安装包:
spark-2.1.0-bin-hadoop2.7.tgz - 解压安装包
[root@bigdata software]# tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz -C .
- 1
2. 编辑配置文件
- 编辑 Spark 环境文件
[root@bigdata software]# cd spark-2.1.0-bin-hadoop2.7/conf/
[root@bigdata conf]# cp spark-env.sh.template spark-env.sh
[root@bigdata conf]# vi spark-env.sh
# 将下边三行配置添加到文件最后
export JAVA_HOME=/software/jdk # 提前安装好jdk并将JDK安装包更名为jdk
export SPARK_MASTER_HOST=bigdata # 本机hostname
export SPARK_MASTER_PORT=7077
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 编辑 Spark Slaves 文件
[root@bigdata conf]# cp slaves.template slaves
# 把文件最后一行的localhost改为本机hostname或ip
bigdata
- 1
- 2
- 3
3. 验证
- 由于没有设置环境变量,因此启停服务需要去
${SPARK_HOME}/sbin下执行
[root@bigdata conf]# ../sbin/start-all.sh
- 1
- 启动后发现该机器上启动了一个 master 节点和一个 worker 节点
[root@bigdata conf]# jps
1937 Master
2013 Worker
9869 Jps
- 1
- 2
- 3
- 4
- 在 Web Console 页面查看(端口:8080)
172.16.15.111:8080
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qiXVPUnd-1686100487975)(/Users/jason93/Library/Application Support/typora-user-images/image-20230216084302024.png)]](https://img-blog.csdnimg.cn/37dbe9bc81564049b5b1eaa758a56431.png)
2. Spark 分布式集群安装
1. 将 spark-2.1.0-bin-hadoop2.7.tgz 上传至 hadoop0:/software/ 下
2. 解压(在当前目录下)
tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz -C .
- 1
3. 改名并配置Spark环境变量文件 spark-env.sh
[root@hadoop0 software]# cd spark-2.1.0-bin-hadoop2.7/conf/
[root@hadoop0 conf]# cp spark-env.sh.template spark-env.sh
[root@hadoop0 conf]# vi spark-env.sh
# 将下边三行添加到spark-env.sh的末尾
export JAVA_HOME=/software/jdk
export SPARK_MASTER_HOST=hadoop0
export SPARK_MASTER_PORT=7077
- 1
- 2
- 3
- 4
- 5
- 6
- 7
4. 改名并配置从节点信息文件 slaves
[root@hadoop0 conf]# cp slaves.template slaves
[root@hadoop0 conf]# vi slaves
# 将最后的localhost,添加下边两行
hadoop1
hadoop2
- 1
- 2
- 3
- 4
- 5
5. 把安装配置好的主节点的Spark目录文件复制到两个从节点
[root@hadoop0 software]# scp -r spark-2.1.0-bin-hadoop2.7 root@hadoop1:/software/
[root@hadoop0 software]# scp -r spark-2.1.0-bin-hadoop2.7 root@hadoop2:/software/
- 1
- 2
6. 配置完成,在主节点上启动
- 启动前确保集群的ZooKeeper集群已经启动
[root@hadoop0 spark-2.1.0-bin-hadoop2.7]# sbin/start-all.sh
org.apache.spark.deploy.master.Master running as process 1348. Stop it first.
hadoop2: org.apache.spark.deploy.worker.Worker running as process 1278. Stop it first.
hadoop1: org.apache.spark.deploy.worker.Worker running as process 1295. Stop it first.
- 1
- 2
- 3
- 4
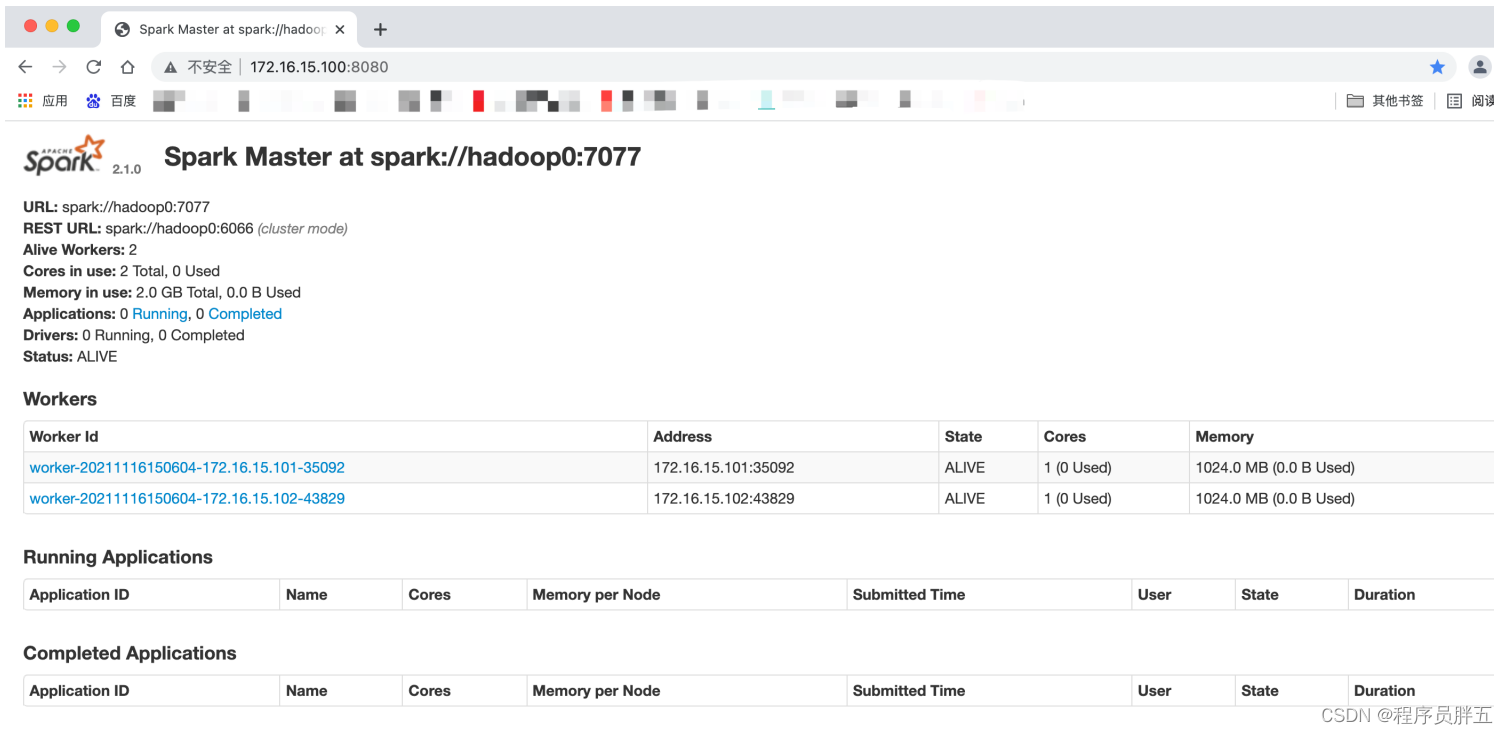
7. 网页上观察:172.16.15.100:8080
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/611295?site
推荐阅读
相关标签

