
- 1Mars3D手把手开发教程(vue3)
- 2百度生成式AI产品文心一言邀请测试,五大场景、五大能力革新生产力工具_生成式ai场景还是多模态情感生成
- 3市值216亿芯片股收监管工作函;工信部将采取举措推动算力发展;文心大模型3.5能力已超ChatGPT 3.5丨每日大事件...
- 4数电实验74151芯片
- 5华为VRP目录和文件操作实验
- 6【STM32单片机+DHT11温度传感器】快速上手,适用于多种型号芯片_32+dht11
- 7“老司机”和你聊聊云数据库系统容灾那些事
- 8数字城市:智慧水库(泉舟时代)_福建泉舟时代
- 9微信小程序获取用户信息(getUserProfile接口回收后)——通过头像昵称填写获取用户头像和昵称_uni.getuserprofile被收回了
- 10js判断radio是否被选中(一)_js判断radio是否选中
Mamba部分代码解读及使用_mamba模块使用
赞
踩
code:https://github.com/state-spaces/mamba
目录结构
mamba ├── benchmarks │ └── benchmark_generation_mamba_simple.py // 示例模型的推理脚本 ├── csrc │ └── selective_scan // 选择性扫描的c++实现 ├── evals │ └── lm_harness_eval.py ├── mamba_ssm │ ├── models │ │ ├── config_mamba.py │ │ └── mixer_seq_simple.py // 使用mamba构建的一个完整的语言模型示例 │ ├── modules │ │ └── mamba_simple.py // mamba block的实现 │ ├── ops │ │ ├── triton │ │ │ ├── layernorm.py │ │ │ ├── selective_state_update.py │ │ └── selective_scan_interface.py // 选择性SSM层的实现 │ ├── utils │ │ ├── generation.py │ │ └── hf.py └── test └── ops ├── triton │ ├── test_selective_state_update.py └──test_selective_scan.py

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
代码解读
代码中很多地方使用到了
if x.stride(-1) != 1:
x = x.contiguous()
- 1
- 2
这段代码的意思是:如果 x 在最后一个维度上的步长不是1(即元素在内存中不是紧密排列的),那么调用 .contiguous() 来重新排列 x,保证它在内存中是连续存储的。目的是为了确保后续操作的效率和正确性。
选择性SSM层的实现:selective_scan_interface.py

选择性SSM通过引入输入依赖的参数,如动态调整的 delta 、A、B、C 参数,来实现对序列数据的选择性处理。选择性扫描根据这些参数,执行具体的计算步骤,从而实现SSM的选择性功能。
SelectiveScanFn 类
是通过c++ ( mamba/csrc/selective_scan.cpp ) 实现的选择性扫描。
- forward方法:接受输入序列 u、选择性因子 delta、状态空间模型的参数 A、B、C,以及可选的 D、z、delta_bias 等参数。它的主要任务是根据提供的参数和输入,执行选择性扫描操作,生成输出序列。方法内部使用 selective_scan_cuda.fwd (selective_scan.cpp中的selective_scan_fwd) 来高效地完成计算。该方法支持返回最后的状态信息,以便于某些应用场景。
- backward 方法:用于计算梯度。接受从前向传播中输出的梯度 dout,并根据保存的前向传播中的张量(通过 ctx.save_for_backward 方法)和参数,通过 selective_scan_cuda.bwd (selective_scan.cpp中的selective_scan_bwd) 计算输入张量、选择性因子和状态空间模型参数的梯度。
selective_scan_fn 函数
SelectiveScanFn 类的包装函数,简化使用。
selective_scan_ref 函数
是选择性扫描的参考实现,使用纯PyTorch操作。便于于理解操作的逻辑。
函数参数:
- u: 输入序列,形状为(B, D, L),其中 B 是批大小,D 是特征维度,L 是序列长度。
- delta: 选择性因子,形状与 u 相同,用于控制每个时间步对应的状态更新程度。
- A, B, C: 状态空间模型(SSM)的参数。A 表示状态转移矩阵,B 和 C 分别表示输入到状态和状态到输出的映射矩阵。
- D: 可选参数,用于直接调整输出序列。
- z: 可选参数,形状与 u 相同,可以用于进一步调整输出序列。
- delta_bias: 选择性因子 delta 的偏置项,用于调整 delta 的值。
- delta_softplus: 布尔值,指示是否在 delta 上应用 softplus 函数,以确保 delta 为正。
- return_last_state: 布尔值,指示是否返回最后的状态向量。
- 其中 A、B、C 既可以为实数矩阵,也可以为复数矩阵。
实现细节:
-
初始化和调整 delta: 对 delta 进行偏置调整(如果提供了 delta_bias)并应用 Softplus 激活(如果 delta_softplus 为 True),以确保 delta 为正值。
-
处理 B 和 C 的可变性:
根据 B 和 C 的维度,判断它们是否为变量(即是否依赖于输入)。如果是,将它们调整为适合状态空间模型的形状。
-
使用线性层由输入得到B,C的调整(由于该函数仅为参考实现所以没有使用线性层),再使用delta进行离散化
-
选择性扫描的主体逻辑:根据 delta 和参数 A、B、C 执行状态更新和输出生成。包括使用线性层由输入动态调整delta,B,C(由于该函数仅为参考所以没有使用线性层),再使用delta进行离散化,再进行状态更新和输出生成。x为状态,y为输出
-
生成输出序列: 根据更新后的状态和参数 C 生成输出序列。如果提供了 D 参数,还会考虑 u 对输出的直接影响。如果提供了额外信息 z,则在输出阶段对其进行处理。
MambaInnerFn 类
Mamba模型的关键操作,不仅包含了选择性扫描操作,还整合了其他处理步骤,如一维因果卷积、线性变换等,使用了核融合,以实现Mamba模型的完整计算流程。
mamba_inner_fn 函数
MambaInnerFn 类的包装函数,简化使用。
mamba_inner_ref 函数
mamba_inner的参考实现,使用纯PyTorch操作。便于于理解操作的逻辑。
输入参数:
- xz: 输入张量,其中包含了两部分信息,通常分为数据 (x) 和额外信息 (z),形状为 (batch, dim, seqlen)
- conv1d_weight, conv1d_bias: 用于一维卷积操作的权重和偏置参数。
- x_proj_weight, delta_proj_weight: 分别用于对卷积输出进行线性变换以生成中间表示和计算选择性因子 delta 的权重。
- out_proj_weight, out_proj_bias: 用于最终输出变换的权重和偏置参数。
A, B, C, D: 状态空间模型的核心参数,分别控制状态更新、输入到状态的映射、状态到输出的映射和直接输入影响。 - delta_bias, B_proj_bias, C_proj_bias: 额外的偏置调整参数。
- delta_softplus: 指示是否在计算 delta 时应用 Softplus 激活函数。
实现细节:
- 输入处理: 将输入张量 xz 分为数据 x 和额外信息 z。对数据 x 应用一维卷积操作,并使用 silu (Swish) 激活函数激活卷积输出。
- 线性变换: 对卷积输出应用线性变换(x_proj_weight),生成用于计算 delta 和动态参数 B, C 的中间表示 x_dbl。
- 选择性因子 delta 的计算: 利用 delta_proj_weight 和 x_dbl 计算选择性因子 delta,可能通过 delta_bias 进行调整,并可选择应用 Softplus 激活。
- 动态参数 B, C 的生成: 如果 B, C 为 None,则从 x_dbl 中动态生成这些参数,可能加上相应的偏置 (B_proj_bias, C_proj_bias)。
- 选择性扫描: 使用 selective_scan_fn 函数,根据输入数据 x、选择性因子 delta 和参数 A, B, C, D 进行选择性扫描。这一步是实现选择性状态更新的关键,可以基于输入动态调整模型的行为。
- 输出变换: 将选择性扫描的结果 y 通过另一线性变换 (out_proj_weight, out_proj_bias),生成最终的输出
选择性的实现:
- 动态 delta:delta 的动态调整使得模型能根据输入序列的特征动态决定每一步的状态更新强度,实现对信息的选择性关注。
- 输入依赖的 B 和 C:如果 B 和 C 依赖于输入(即为变量),它们将根据每个输入序列的特征调整,进一步增强模型的选择性。
- 可选激活和偏置调整:通过对 delta 应用 Softplus 激活和进行偏置调整,细微调整模型对不同输入的敏感度和反应方式。
Mamba 模块的实现:mamba_simple.py
Mamba 类
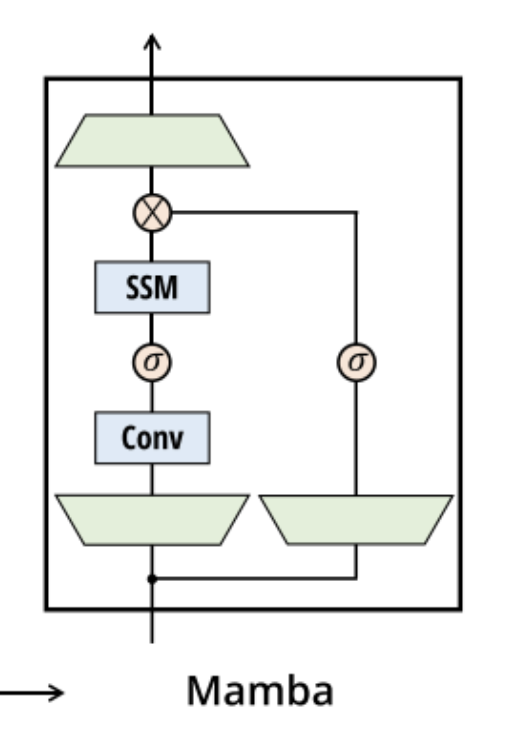
初始化方法(init):
- 模型参数:d_model, d_state, d_conv, expand 等参数控制模型的基本结构和大小。d_model 表示模型的维度,d_state 是SSM状态扩展因子,d_conv 是局部卷积宽度,expand 为块膨胀系数。
- 输入输出投影:in_proj 和 out_proj 线性层用于输入数据和模型输出的线性变换,使得模型能够适应不同维度的输入和输出需求。
- 一维卷积层:用于捕获序列数据中的局部依赖性,模仿自然语言和其他序列数据中的短期上下文关系。
- 选择性因子 delta 初始化:根据选择性机制,delta 通过 dt_proj 层动态调整,控制模型对于每个输入在状态空间中的转移行为。其初始化策略(例如随机或常数)直接影响模型学习到的状态转移动态。
- 状态空间参数 A 和 D:A 参数控制状态转移矩阵,而 D 参数用于模型的 “跳过连接”,这些参数的初始化和表示对模型性能至关重要。
forward 方法:
训练(卷积模式):
- 输入线性变换:输入序列通过in_proj层进行线性变换,以适配模型内部的维度要求。
- 卷积操作:变换后的输入序列被送入卷积层(conv1d),这一步骤旨在捕捉序列中的局部特征或短期依赖关系。
- 选择性扫描:经过卷积处理的数据随后进行选择性扫描。这是通过selective_scan_fn函数实现的,它根据当前的输入动态调整状态转移矩阵,从而有效地处理长期依赖性。
- 输出线性变换:最后,通过out_proj层将处理后的数据转换为最终的输出。
- 在训练时,forward方法会利用整个输入序列的信息,以便模型能够学习到序列中的复杂模式。此过程中,并行处理能力(尤其是GPU上的)被充分利用,以提高训练效率。
推理(递归模式):
- 状态检查:首先检查是否提供了推理参数(如inference_params)。这些参数包含了推理过程中需要的状态信息,如先前时间步的卷积状态和选择性扫描状态。
- 逐步处理:如果存在推理参数,forward方法将适应性地调整其行为,以支持基于已生成输出的逐步处理。使用step方法或类似逻辑来处理单个时间步长的输入,并更新内部状态。
- 状态更新:在每一步生成新的输出后,相关的状态(如卷积层状态或选择性扫描的内部状态)将根据最新的输出进行更新,以便用于下一个时间步的处理。
step方法:
step方法的设计假定每次调用只处理一个时间步的输入(hidden_states的形状被断言为(batch_size, 1, feature_dim),表示一次只处理一个序列元素)。这意味着要生成整个序列,外部需要一个循环来反复调用step方法,每次生成一个序列元素。
- 卷积状态更新: 如果causal_conv1d_update为None,则使用手动的方式通过torch.roll和卷积权重应用卷积操作,更新conv_state;否则,直接调用causal_conv1d_update进行更新。这一步骤模拟了捕获序列数据局部上下文信息的卷积层的效果。
- 选择性因子和状态空间参数的计算:x通过x_proj层变换,得到用于选择性状态更新的向量,包括选择性因子dt和状态空间模型(SSM)参数B和C。
- 状态空间模型(SSM)的递归更新:使用选择性因子dt和参数A、B、C更新SSM的状态ssm_state。这里体现了递归的本质,即基于当前输入和先前状态对内部状态进行更新。
- 生成当前步输出:基于更新后的ssm_state、当前输入x和其他相关参数(如D和z),生成当前时间步的输出y。涉及到状态的线性变换,激活函数的应用,以及跳跃连接操作。
- 线性投影:最后,out_proj层将y变换回原始特征空间,生成最终的输出。
- 返回输出及更新状态:函数返回更新后的输出out,以及当前的卷积状态conv_state和选择性状态空间模型的状态ssm_state。这些状态在下一次调用step时作为输入提供,以便连续地生成序列。
Mamba模块的使用
import torch
from mamba_ssm import Mamba
batch, length, dim = 2, 64, 16
x = torch.randn(batch, length, dim).to("cuda")
model = Mamba(
# 3 * expand * d_model^2 parameters
d_model=dim, # Model dimension d_model
d_state=16, # SSM state expansion factor
d_conv=4, # Local convolution width
expand=2, # Block expansion factor
).to("cuda")
y = model(x)
assert y.shape == x.shape
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Mamba模块的输出序列的形状应该与输入序列的形状相同。意味着Mamba模块可以相对灵活地被插入到需要处理序列数据的神经网络架构中,例如可以替换Transformer的自注意力层,也可以作为额外的处理层被插入到现有的序列模型中,比如RNN、GRU或LSTM之后,用来进一步提取序列中的特征或增强模型对长期依赖性的捕捉能力。

