
热门标签
热门文章
- 1LeetCode刷题笔记第1859题:将句子排序
- 2一段c语言的代码,一段C语言代码 据说是最烂的代码
- 3java json 嵌套list_java-嵌套JSON的POJO格式?
- 4验证二叉搜索树
- 5用 | 操作符进行取整操作-Ts_ts 取整
- 6Xilinx DDR3 IP核使用问题汇总(持续更新)和感悟
- 7任意命令执行漏洞
- 8Linux 的 MySQL 5.x - 关于 Windows 10 的 Navicat Premium 导入 Excel (.xlsx)文件,报错问题集锦_navicat导入excel数据报错
- 9linux secure boot(安全启动)下为内核模块签名
- 10紫光 DDR3 IP核调试_紫光ddr调试
当前位置: article > 正文
表情识别项目综述论文阅读总结
作者:我家自动化 | 2024-05-26 18:15:21
赞
踩
表情识别项目综述
文章目录
Machine Learning-Based Student Emotion Recognition for Business English Class
Emotion Recognition Technology
Facial Expression recognition
- 面部表情诗人表达情绪状态的一个重要的途径,学习者大部分的情绪状态都可以通过处理和分析表情获得。下图展示了兴奋和情绪的关系,越舒服和适应,越能够产生积极的情绪。相应地,越能够促进认知能力的提高。相反的,厌恶的情绪越多,也会阻碍你的认知能力。

- 常见的表情识别有两种类型,一种是基于静态图像特征,另外一种是基于动态连续图像特征。静态图像特征,能够提取、分类和辨识面部表情特征信息。动态连续图像特征包含表情连续变化的动态特征。
- 静态方法主要有三种
- global information method(全局信息方式)
- Principal component analysis(主成分分析)
- Linear discriminant method (线性判别)
- Gabor wavelet transform(小波变换)
- geometric feature method(几何特征方式)
- mixed feature method(混合特征方式)
- global information method(全局信息方式)
- 动态方法,主要有以下三种方法
- optical flow method
- feature point tracking method
- differential imaging method
Analysis of emotion recognition algorithm
- 根据国内外的学术研究,表情识别的基本过程分为如下:获取面部表情,然后对图片进行预处理,接着提出图片对应的面部表情特征,最后选择对应适合的分类网络将图片进行分类。如下图展示。
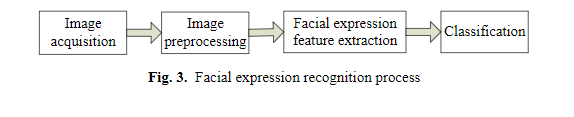
基于融合特征的表情序列图片特征提取方法
- 关键词:Facial feature extraction,facial expression recognition,the peak frame of expression images,
- 面部表情特征提取图像识别的重点。提取出能够的总结面部特征变化的关键特征能够改善分类器的识别效果,所以很重要。针对以下问题,过高的特征维度、过度的内存消耗和信息冗余,故采用峰值帧的方式从序列中提取关键帧。面部表情的变化过程和与面部表情相关的关键特征点高度相关。峰值帧就是时刻跟踪面部关键特征点的变化,来提取关键帧。同时在跟踪面部表情关键点的变换过程中,可以忽略背景因素对于特征提取的影响。
Facial expression classification method based on deep multi-kernel learning
- 关键词:deep multi-kernel learning ,deep core-kernel learning method,Gabor features(小波特征,描述肌理构成)
- 表情提取的核心就是特征提取,只要提取好了特征,将之和标签输入到分类器中,就得到了一个训练好的分类器。就可以对剩下的没有的标签的数据进行分类。关于分类器主要用到了两种思路,多核心学习和深度学习
- 多核心学习:定义一组学习的基本核,并获取最优核
- 深度多核心学习:它是由多个核心函数层和神经网络构成。核心函数是核心,并且他的结构是一个多层网络结构,每一层都有很多的核心。
- 面部表情分析过程如下:
- 首先,从每一帧中提取出人脸图片以及相关特征。其中几何特征描述人脸局部变化,小波特征描述人脸的肌理构成原理
- 然后将提取到的特征进行混合,一块输入到多核心分类网络中进行训练。
- 最后的训练好的模型被用于分类表情。
- 模型的分类效果对比如下,混合特征的效果是由优于单个特征的,为什么不使用卷积网络提取特征。

Human-Computer Interaction Control method Based on Machine learning

- 图片7展示了3维卷积神经网络的卷积方式图表。三维卷积神经网络能够在同一时间解决时间和空间问题
Multimodel emotion recognition based on peak frame selection from video
abstract(概述)
- 提出了三种视频关键帧的检测方法,其中MAXDIST和DEND-CLUSTER是不需要训练和预先学习的,EIFS是需要先验学习的,需要确定中性表情,然后在计算别的不明显的表情和中性表情的“距离”。
Introduction
- 关键词:geometric features,appearance-based features
- 自动化情绪识别在人机交互中很重要。
- 表情识别相关工作的研究
- 一些最新的表情识别的方法,一般都是利用2维特征。而二维特征可以被分为几何特征和外貌特征。
- 几何特征一般指得是脸部的突出点的坐标,主要是通过面部特征点的形变过程来检测表情的。
- 面部特征指得是丰富面部表情的纹理变化特征
- 参考一下,通过预先的训练和学习,找到中性表情区间集,通过中性集来对表情进行判定
Mulimodal emotion recognition system
- 这部分主要讲提取音视频特征提取方法,分类方法和多通道决策融合方法
Feature extraction from video
- 关键词:peak frame,maximum dissimilarity-based method,clustering-based method(DEND-CLUSTER)
- 比较了三种峰值帧选择方法
- 最大不同法(MACDIST)
- 基于聚类的方法(DEND-CLUSTER)
- 情感强度法(EIFS)
- 在所有方法中,作为一个预处理步骤,主要是检测视频序列中的人脸,然后对齐,并进行剪裁,从而消除不必要的区域,比如说背景和头发。因为一些脸部区域并没有携带任何表情信息,我们将脸部区域分为若干子模块,将不相干的模块丢弃。具体操作如下图。在剩余的模块中,我们提取LPQ特征来获取面部表情的优化特征向量。

- 在上图中,a表示面部识别和对齐,b表示才裁剪面部区域,c提取每一帧的面部特征,d计算相异矩阵,并且选出相异值最高的k帧作为训练的依据
Maximum dissimilarity-based peak frame selection method
- 关键词:the average dissimilarity score,a miximum dissimilarity criteria,LPR feature
- 最大差异选择法是建立在峰值帧和其他所有的帧都不同的前提下。因此,首先连续帧之间的不同是通过比对面部特征进行计算的。该方法根据帧相对于其他帧的平均不相似度分数对帧进行排序,并选择对应于K个最大平均不相似度分数的帧(即峰值帧)。我们将这种方法称为MAXDIST,因为峰值帧是使用最大不相似准则来选择的。
基于自适应关键帧选取的人脸表情识别
摘要
-
问题:
- 人脸表情序列中存在大量的冗余信息,找到人脸表情序列中的峰值表情能够有效提升人脸表情识别的准确度。
-
方法:
- 通过计算表情变化过程中人脸关键点信息的变化来确定选取处于峰值表情的人脸图像,来确定峰值表情在人脸中的位置
-
验证
- 通过一个Baseline网络结构进行特征提取,验证自适应关键帧选取方法的有效性
-
项目结构,总共三个模块
- 自适应关键帧提取,确定表情的内容
- Baseline网络训练
- 分析实验结果,验证方法的有效性
自适应关键帧的提取
- 关键点
- 通过计算表情变化后图象人脸的关键特征点信息与中性表情图象的人脸关键点信息之间的差异能有效定位表情序列中的关键帧。
- 实现过程
- 默认第一帧式无表情的中性人脸图像,将其作为基准
- 计算序列后续的所有人脸的图象和第一帧图象之间关键点的变化,判断关键帧在序列中的位置
- 计算距离的过程
- 确定原点,计算各个点到原点的欧式距离
- 将两张图片对应的欧氏距离做差,求和,得到表情的量化值。
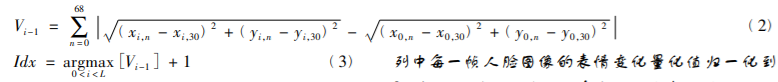
Baseline网络结构
- 卷积网络的特点
- 使用小的卷积核代替大的卷积核,在提升网络的深度的同时,又减少了参数量

- 使用小的卷积核代替大的卷积核,在提升网络的深度的同时,又减少了参数量
数据处理
- 使用表情视频验证关键帧提取方法的有效性,十折交叉验证
数据预处理及数据增强
- 数据预处理
- 识别出人脸并对其进行切割,排除背景对图象的影响
- 数据增强
- 图像旋转
- 高斯噪声的添加
- 对比度增强
- 亮度变化
- 图像翻转
实验设置以及实验结果的分析
- 对比方面
- 关键帧选取和传统的数据选取方式之间的对比,验证自适应的关键帧选取方法的有效性
- 利用Baseline网络结构和关键帧提取结合的实验结果,对比其他方法
- 要验证你的方法在不同数据集之间都有效才行
- 要改变条件,使用不同的数据集进行对比
借鉴和学习
- 关于卷积核考虑是一个很重要的切入点,要自己去调整和修改一下。
- 表情关键帧的确定,方法值得借鉴,但是在标注的过程中发现,并不是每一个器官都会发生明显的变化,主要是眼睛和嘴巴的之间的变化,而且也主要是通过这两个器官。但是关于权重的设定还没有想好。我会考虑到不同器官对于表情变化和判定的影响,进行判定统一帧。
- 表情表达情感信息的重要性
基于视频分析的学生课堂听课状态的系统研发
- 将人脸识别技术应用到学生课堂听课场景中,运用统计学原理对学生听课状态进行判断。
- 人脸识别算法使用局部二值模型LBP和神经网络算法构成
- 系统框架使用Spring+SpringCloud+SpringBoot+Mybatis主流框架,使用git版本控制系统工具,代码上传到云服务进行部署
- 视频解析使用FFmpeg软件,将音视频转化为视频流
- 对人脸的抓拍、对比、统计和分析功能上,采用多线程
引言
研究背景与意义
- 如何判断学生的听课状态是本文的主要研究内容
- 长久并且连续化的记录学生的听课状态,减少老师的工作量,节省了很多时间
人脸识别研究技术的现状
- 基于几何特征的人脸正面识别方法
- 基于特征的由下而上的可以用人眼表现出来的检测方法,存在隐藏假设,固有的人脸特征或属性无论在任何条件下都不会发生改变
- 基于连接机制的人脸正面自动识别方法
- 利用机器学习算法将人脸构造成二维矩阵,形象地保存了人脸的关键信息,减少了复杂提取的大量工作,但是过程繁琐,并且准确率很低
- 基于几何特征的人脸正面自动识别方法
- 太复杂,不记录了
借鉴和学习
- 自己不能老是各自开发自己,要将代码放到gitee上,大家一块开发完成。
- 别的借鉴意义不大,他并不是表情识别,主要是人脸识别
基于深度学习的人脸微表情识别
摘要
- 基于CASMEI和CASMEII数据集训练改进卷积神经网络模型,将特征提取盒分类识别结合在一块,充分提取微表情的特征
引言
- 微表情是无法掩饰的面部表情,反映了人的真实心理和情感,暴露内心想法
- 面部表情分类:宏表情和微表情
基于卷积神经网络的微表情识别
预处理部分
- 消除外部的因素变化的方式:直方图均衡化,滤波去噪,大小变化
- 直方图均衡化:将图片变为灰色,并做直方图均衡化处理,增强图象的亮度,细节更加清晰,减少光照影响
- 滤波去噪:使用中值滤波减少噪声点,高斯滤波减少优化边缘信息
- 尺寸变化:通过将图象尺寸的放大或者缩小,将之进行归一化。
基于LBP-TOP的微表情特征提取
- LBP简介:基于三个正交平面的局部二值模式
- 原理:
- LBP:有效处理光照变化,在纹理分析和识别方面被广泛应用,只能处理单张二维图片。有个很不错的了解的连接。
- LBP-TOP:在图片的XY坐标系上又引入了T轴,XY正常的图象,XT每一行沿着时间轴扫过的纹理,YT每一列沿着时间轴扫过的图象。
- 对三个平面的LBP特征进行提取,连接起来就是LBP-TOP
- 在本文中先是对图片进行LBP-TOP特征提取,在进行输出。对于这种图片的特征了解的不是很清楚,为什么单张图像会在XT和YT有内容
基于微表情识别的卷积神经网络构建
- 网路输入时LBP-TOP特征,通过卷积,池化和全连接层识别的常规操作
- 改进之处在最大池化层和结构优化
最大值池化层
- 作用:压缩卷积层提取出来的特征
- 改进:并不是逐步池化,而是将卷积之后的矩阵分成若干个不相交的相邻区域,对每一个区域进行最大池化操作
结构优化
- 改进:使用后向传播算法训练权重
- 这部分没有看懂,不过他说后向传播仅仅是为了计算更加高效
借鉴和学习
- 特征提取和分类识别结合
- 学习表情就很像微表情,比起常规的表情,我们需要更加细致操作,更加细致的观察
- 可以尝试一下LBP-TOP的算法,因为我们的表情本身也就是动态的
- 对于池化层的修改可以借鉴一下,由原来逐步池化改成相邻的区间
学生表情识别研究综述
摘要
- 主要是的面向学生表情识别的表情分类和数据库研究进展
引言
- 心理学家Mehrabian 通过研究发现:“情绪表达=7%的语言+38%的姿势表情+55%的面部表情”,面部表情包含丰富直观的情绪信息。 研究表明,在学习环境下,面部表情不仅能直观反映学生的情绪状态,还能反映学生的心理状态。 因此,面部表情识别已成为感知学习情绪的主要途径
- 随后 Ekman 等人开发的面部动作编码系统 (Facial Action Coding System,FACS) 受到广泛注,FACS 根据面部肌肉活动定义了 46 个动作单元来判断面部表情,但其实际应用中的使用效率并不高。
- 通过基于计算机视觉的表情识别方法准确识别学习情绪,既可以解决学习情绪状态难以自动感知的问题,也顺应了信息技术与教育教学深度融合的发展趋势。
表情分类以及数据库的构建
- 学生表情分类
- 特征:学习情绪不仅具有人类情绪的普遍性,而且还具有其独特性,例如学生表情大多时候处于中性状态,波动幅度不大,而类似于“悲伤” 和“生气”这类强烈的负面情绪则需要较强的诱导因素 才会出现。 由此可见研究者应将关注点置于频率出现较 高且能真实反映学生学习状态的表情,才能挖掘出学生在不同学习环境下的真实学习情绪。
- 常见的经典的表情分类

- 在这里我要给出我们规定的六种表情的原因和特色,以及出发点
- 数据集设计
- 学生扮演表情数据集:
- **徐振国[12]建立了由 70 名研究生组成的包含常态、高兴、愤怒、悲伤 、惊恐、专注、走神 等 7 种学习情绪的 73500 张面部表情图像库。**标准的数据集很重要,这里可以参考一下,想办法找到就行了
- 学生自发表情的数据集
- 如 Kappor 等[14]采用电脑解谜的诱导方式,采集到了 136 名儿童高兴趣、中兴趣、低兴趣、乏味和休息五种状态下的自然表情。
- 这个表情分类和我们的很像,所以也可以参考一下这个数据集
- D’Mello 等[9]借助摄像机和身体测试系统采集到了 28 名大学生 在与 AutoTutor互动过程中的自然表情
- Whitehill 等[3]提取了 34 名学生在认知实验过程中产生的快乐、 悲伤、 厌恶、恐 惧、惊讶和中性六种表情数据
- 如 Kappor 等[14]采用电脑解谜的诱导方式,采集到了 136 名儿童高兴趣、中兴趣、低兴趣、乏味和休息五种状态下的自然表情。
- 学生扮演表情数据集:
常见的研究方法
基于传统机器学习
- 人脸检测
- 基于特征的方法:
- 从表层特征中提取出中高层特征,并进行结合,在进行分类表达
- 常见的有:ObjectiveBank,Distinctive Part
- 基于统计学习的方法
- AdaBoost适合线上学习环境的人脸检测
- 基于特征的方法:
- 数据预处理
- 影响因素:头部姿势,光照变化,噪声干扰等
- 对齐人脸:深度学习人脸对齐算法,常用的是端到端推理决策网络方法
- 数据扩容:随机扰动和变换,翻转,平移,缩放,对比度,噪声,颜色抖动
- 特征提取
- 静态图片
- 视频
- 表情分类:
- 。。。。
基于深度学习
基于静态图像的表情识别
- 例如徐振国[12]设计了一种 7 层 CNN 模型,该模型能快速且准确地识别学生表情并进一步判断学生情绪状态
- Xu 等[17]提出了一种基于情绪感知的学习框架, 利用 CNN 模型对学生进行脸部检测和表情强度排序。
- 使用卷积网络的缺点:自动提取特征,无用的特征的会干扰有用的特征,提高模型的识别性能,不断对CNN进行简化和改进
基于视频的表情识别
- 真实学习环境中表情的特点:
- 低强度、时间短、持续性和时序性
- 通过连续帧识别面部表情更自然,识别结果更为精准
- 使用RNN(序列分析任务的有效性)
- Zhang 等[30]基于 RNN 设计了一种时空递归神经网络模型,利用输入信号的时空依赖性学习隐藏特征,并在脑电波和面部表情数据集上证明了其有效性。
- 缺点:容易丧失学习序列时域特征的能力
- 长 短 时 记 忆(Long ShortTermMemory,LSTM)
- 如王素琴等[31]建立了 VGGNet-LSTM 模型
- 首先通过 VGGNet 模型提取表情图像的视觉特征
- 使用 LSTM 提取图像序列的时序特征,通过特征融合后在此基础上进行分类
- 如王素琴等[31]建立了 VGGNet-LSTM 模型
学习
- 尝试使用Adaboost,将人脸提取出来,并能够单独标出来,去除背景对于识别的影响。
- 使用卷积网络的模型可以借鉴徐振国的模型,同时在图片预处理中,借助常规方式来减少无用的特征,提高准确率
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/627808
推荐阅读
相关标签

