
- 1无人驾驶汽车系统入门(十八)——使用pure pursuit实现无人车轨迹追踪_小车无人驾驶最常用的局部路径跟踪方法
- 2Spring boot使用easy-es操作elasticsearch_easy-es学习
- 3阿里: 高效两阶段知识迁移的多实体跨域推荐
- 415个经典面试问题及回答思路,,大厂面试必问_程序员面试问公司问题
- 5在 Golang 中执行 Shell 命令_go语言执行shell脚本
- 6.gitignore文件不生效解决方法_git:下列路径根据您的一个.gitignore
- 7【无标题】安装ROS E: 无法定位软件包 ros-melodic-desktop-full_unable to locate package ros-melodic-desktop-full
- 8SpringBoot整合RabbitMQ,实现MQ动态配置交换机-路由-队列信息_spring boot 接入rabbitmq,使用外部配置文件(如yaml或properties)来
- 9buildroot创建最小根文件(支持驱动与QT)_buildroot qt
- 10Python-VBA函数之旅-len函数_excel的len函数在vba如何用
Textual Inversion、DreamBooth、LoRA、InstantID:从低成本进化到零成本实现IP专属的AI绘画模型_instant id论文
赞
踩
2023年7月份国内有一款定制写真AI工具爆火。一款名为妙鸭相机的AI写真小程序,成功在C端消费者群体中出圈,并在微信、微博和小红书等平台迅速走红,小红书上的话题Tag获得了330多万的浏览量,相关微信指数飙升到了1800万以上。
其他能够提供类似功能例如:LensaAI,Midjourney,DALL-E3,Stable Diffusion,Tiamat。只不过LensaAI和妙鸭相机对于定制图像生成更加专精一些。
这背后用到技术演化,就是Textual Inversion、DreamBooth、LoRA、InstantID这四类,从一开始需要样本数据微调,到2024年1月发布InstantID不需要样本数据微调。
本文跟朋友们分享相关技术。
欢迎关注留言!
Stable Diffusion 简称 SD。
Textual Inversion
为了更好理解Textual Inversion算法,我先回顾下SD词嵌入向量的使用方式。
也可以看我以前的文章。
当我在SD AI上画画时,我会先输入一个提示。这个提示会被一个叫做“tokenizer”的工具拆分成很多小部分,每个小部分都有一个独特的标识,叫做“token_id”。接着,这些“token_id”会在一个已经准备好的词库里找到对应的词嵌入向量。这些词嵌入向量就像是我们提示的“翻译”,让机器能更好地理解。
然后,我会把这些词嵌入向量放在一起,传给CLIP的文本编码器。这个编码器会帮我把这些向量变成一种更容易理解的形式,也就是文本表征。有了这个文本表征,我就可以用一个叫做“交叉注意力机制”的工具来控制我的图像生成了。简单来说,就是我想画什么,机器就能帮我画出什么。
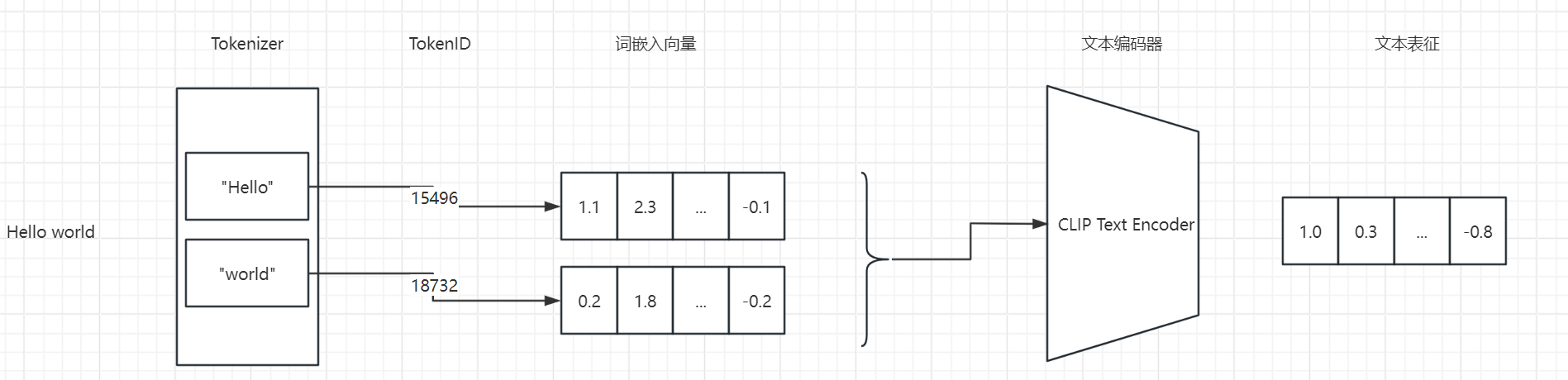
理解了 SD 词嵌入向量的使用,再来学习 Textual Inversion 这个算法就会非常简单。
Textual Inversion 算法的本质是学习一个全新的词嵌入向量,用于指代定制化的内容。其核心思想便是,对于一个给定的物体或者风格,去学习一个全新的词嵌入向量,并绑定一个符号比如 S*,为其分配一个新的 token_id。这样,每次文生图的时候只需要带上 S*,就能生成我们想要定制化的物体或者风格。
**重点在于,这个过程不需要对整个AI模型进行调整或重新训练,只是在它的词汇库中添加了一个新的词汇而已。**这样做的好处是可以保留AI模型原有的理解能力和创造力,同时又增加了一些个性化的元素。
需要3到5张展示特定概念(比如你的猫)的图片来训练AI。
论文地址:https://arxiv.org/pdf/2208.01618.pdf


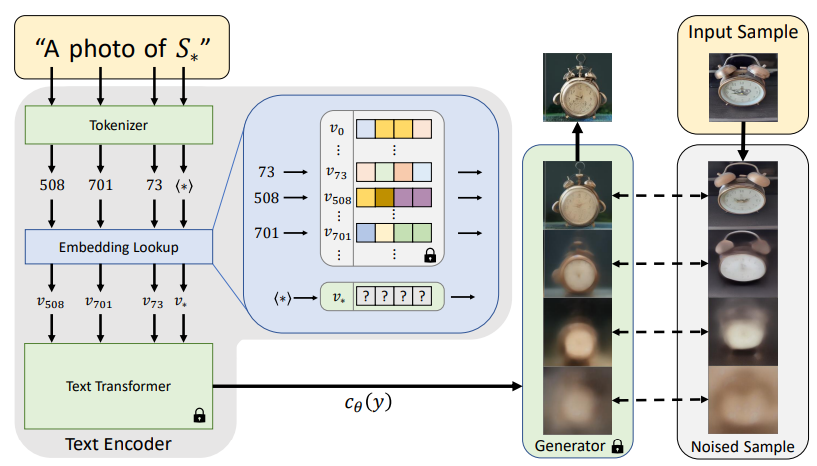
Textual Inversion 的训练其实挺简单的,分两步走。
首先,你得给你想要的关键词,比如 S*,配一个新的“身份证”,我们叫它 token_id。然后,给这个新“身份证”初始化一个词嵌入向量。举个例子,如果原来的词库里已经有 20000 个词了,那 S* 的“身份证”就是第 20001 号。
接下来,找个已经训练好的 AI 画画模型,比如 Stable Diffusion 或者 DALL-E 3。在训练的时候,CLIP 文本编码器和 UNet 这些模型的“技能”都不变,就固定在那里。然后,用你提供的 3-5 张图片,按照模型的标准训练方法来训练。这个过程中,只有你给 S* 新初始化的那个词嵌入向量在“学习”。
训练完了,你就得到了一个定制化的词嵌入向量,它能帮你表达出训练图片里的物体或者风格。
这里有两点要注意:
一是这个词嵌入向量是和你选的 AI 绘画模型绑在一起的;
二是 Textual Inversion 还可以同时优化好几个新增的词嵌入向量。
如果你想更深入了解,可以点击链接去看看 Textual Inversion 的训练代码。
https://github.com/huggingface/diffusers/blob/main/examples/textual_inversion/textual_inversion.py
DreamBooth
DreamBooth 论文:https://arxiv.org/abs/2208.12242
Textual Inversion 在训练时,能学习的参数并不多,大概只有512或768个浮点数那么点儿。所以,它在定制化生成方面的能力就有点儿局限。在市场上,如果你想要更个性化的生成效果,大家通常更喜欢用 DreamBooth。
说到 DreamBooth 这个名字,其实挺有意思的。Google 团队打了个比方,说它就像一个摄影棚,你进去拍照后,不仅仅是一张公开可用的图片,还能把你拍的东西放到你梦想的任何场景里。用 DreamBooth 的时候,你上传3~5张图,再加个新的描述词,就能定制一个物体或者一种风格了。后面我放了些图片,你可以看看 DreamBooth 的生成效果有多酷。



我来给你讲讲这个方案是怎么一回事吧。其实步骤很简单,就两步。
首先,你得挑个不常见的词作为关键词,比如说“CSS”。这个和Textual Inversion有点儿不同,那里的词得绑定全新的词嵌入向量,但这里不用。
然后呢,你得找个已经训练好的AI绘画模型,比如Stable Diffusion或者DALL-E 3。在训练过程中,UNet模型的权重是要打开的。接下来,就按照对应的AI绘画模型的标准训练方法,在你给的3-5张图片上训练一下。
你可能会有个疑问:就用这么几张图去调整UNet那么多参数,模型会不会变得太“偏执”了?比如说,如果你用了3-5张自己小狗的照片去训练,那模型是不是就只会画这一种样式的小狗了?没错,确实会有这个问题。这样训练出来的模型,不管你的prompt是“a CSS dog”还是“a dog”,它都只会画出你训练用的那种小狗。
不过别担心,论文作者已经想到了解决办法,那就是保留损失(preservation loss)。具体操作就是,先用AI绘画模型生成一批小狗的图片,然后在训练DreamBooth的时候,也把这批图像加进去一起训练。这样一来,模型就不会那么“偏执”了。
哦对了,训练DreamBooth的时候,CLIP文本编码器也是可以打开的。实践证明,这样做可以让定制化图像生成的效果更好。
总的来说,Textual Inversion和DreamBooth的区别就在于:前者只是优化一两个词嵌入向量,而后者则是对整个AI绘画模型进行微调。
如果你想更深入了解,可以点击链接去看看 DreamBooth 的训练代码。
https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth.py
更多内容关注这个用户,以后大部分内容都迁移到这里:欢迎关注
每天学点新技术,生活工作更自如!
我是 李孟聊AI,独立开源软件开发者,SolidUI作者,对于新技术非常感兴趣,专注AI和数据领域,如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢!

