
- 12024年最新wxid转微信号方法
- 2练习7-4 找出不是两个数组共有的元素(20 分)
- 3[PHP] CURL 的各种骚使用(GET,POST,上传下载图片,带认证,带COOKIE)_php curl 下载图片
- 4演示:MyBatis Plus 写业务代码,确实一把梭!
- 5数据结构实验之栈与队列四:括号匹配
- 6基于FPGA的数字秒表设计——嵌入式_fpga秒表功能分析
- 7基于 STM32自研多任务+SpringBoot+Vue 农业大棚智能调光系统_stm32 java温室大棚
- 8什么是神经网络和机器学习?【云驻共创】_机器学习和神经网络
- 9关于MySQL Connector/C++那点事儿
- 10MacOS的ARM64的R如何解决编译问题_macos arm 编译
国家标准《数据分类分级规则》解析与多行业标准及实践分享系列-第一部分_行业数据标准
赞
踩
国标《数据分类分级规则》发布后,解析的文章不少,但是在和朋友们交流的过程中,都觉得缺少了针对行业或企业级别实践落地的内容,鼹鼠哥于是借这个假期对规则重新做了解析,重点是对《规则》所提及的七大行业,以及其他数据治理走在前列的行业如金融和电信行业的落地实践案例,以求和大家共同进步。

本文分为三个部分:第一部分将针对日前发布的国家标准《数据分类分级规则》进行规则制定背景及内容解析;在第二部分结合相关省市和行业领域的数据分类分级标准深入解析,分别阐述各省市和行业对分类分级规则的思路和方法;第三部分将针对企业如何开展数据分类分级介绍原则和流程,并结合具体企业案例进行分享。
全文超过两万字,将分为多篇发布,本篇为系列的第一部分。
第一部分约7000字,分为三个小章节:
-
1. 规则制定背景。
-
2. 什么是数据的分类和分级及其必要性。
-
3. 《数据分类分级规则》解析:
-
针对《规则》的1).原则,2).分类规则,3).分级框架和4).分类分级流程,以及5).《规则》附录共五个部分分别进行解析。
01—规则制定背景
《数据安全法》第二十一条明确规定“国家建立数据分类分级保护制度”,提出根据数据在经济社会发展中的重要程度,以及-旦遭到篡改、损毁、泄露或者非法 获取、非法使用,对国家安全、公共利益或者个人、组织合法权益造成的危对数据实行分类分级保护。
基于该规定,2024年3月21日,全国网络安全标准化技术委员会发布GB/T 43697-2024《数据安全技术 数据分类分级规则》,于2024年10月1日实施,该标准于2024年3月15日由国家市场监督管理总局、国家标准化管理委员会发布的中华人民共和国国家标准公告(2024年第1号)获批。
《数据分类分级规则》作为全国网络安全标准化技术委员会更名后发布的第一部以“数据安全技术”命名的国家标准,是指导各领域数据分类分级工作的基础性国标;通过合并“数据分类分级指南”和“重要数据识别要求”两个标准,代替《信息安全技术 重要数据识别指南(征求意见稿)》,是贯彻国务院办公厅《扎实推进高水平对外开放更大力度吸引和利用外资行动方案》(国办发〔2024〕9号)提出的“科学界定重要数据的范围”的重要一环。
相关标准如下表所示:

网安标委简介
这里对网安标委做一个简单介绍。
全国网络安全标准化技术委员会(简称“网安标委”)前身为成立于2002年的全国信息安全标准化技术委员会(简称“信安标委”),在更名前已经组织制定网络安全国家标准三百余项。
该组织的行业地位从官方网站的领导概况介绍中相关领导的主要职务即可窥一斑,不再赘述。

当前组织内部设置如下工作组:

02—什么是数据的分类和分级及其必要性
1.数据分类
数据分类是数据资产管理的第一步。不论是对数据资产进行编目、标准化,还是数据的确权、管理,或是提供数据资产服务,进行有效的数据分类都是其首要任务。
数据分类更多是从业务角度或数据管理的方向考量的,包括行业维度、业务领域维度、数据来源维度、共享维度、数据开放维度等。同时,根据这些维度,将具有相同属性或特征的数据,按照一定的原则和方法进行归类。
2.数据分级
数据分级则是按数据的重要性和影响程度区分等级,确保数据得到与其重要性和影响程度相适应的级别保护。
鼹鼠哥:数据的分类和分级是两个事情,大家不要混为一谈。
影响对象一般是三类对象,分别是国家安全和社会公共利益、企业利益(包括业务影响、财务影响、声誉影响)、用户利益(用户财产、声誉、生活状态、生理和心理影响)。
鼹鼠哥:数据的分类是分级的前提,没有分类就谈不上分级,而数据分级本质上就是数据敏感维度的数据分类。
企业建议选取影响程度中的最高影响等级为该数据对象的重要敏感程度。同时,数据定级可根据数据的变化进行升级或降级,例如包括数据内容发生变化、数据汇聚融合、国家或行业主管要求等情况引起的数据升降级。
数据分级本质上就是数据敏感维度的数据分类。
按照本标准,分级为如下五个等级

但是分类就会比较麻烦,主要存在如下挑战:
1. 复杂业务的分类分级标准与规则不好定义,行业标准对落地细则的指导不足。
2. 数据分类分级之后缺乏对应的有效管理和使用策略,让数据分类分级流于形式。
3. 部分业务数据不具备明显数据特证,通过规则自动识别准确率不高。特别是针对非结构化数据的分类分级识别困难较大。
3.数据分类分级的必要性
数据已与土地、劳动力、资本、技术并列为先进生产力五大要素,是国家重要的基础性、战略性资源。如何开放数据共享、提升数据价值的同时保障数据生命周期安全与合规,是企业需要解决的重要问题。而对数据进行数据分类分级安全管理,是数据安全保护的重要措施之一。
满足法律合规要求
我国多部法律规定了数据分类分级的要求,2017年发布的《网络安全法》提出网络运营者应当采取数据分类的安全保护措施,2021年发布的《数据安全法》确立了数据安全管理制度。
《数据安全法》第二十一条规定:“国家建立数据分类分级保护制度,根据数据在经济社会发展中的重要程度,以及一旦遭到篡改、破坏、泄露或者非法获取、非法利用,对国家安全、公共利益或者个人、组织合法权益造成的危害程度,对数据实行分类分级保护。”明确了数据分类分级的依据是数据的重要程度以及数据安全性遭到破坏时的危害程度,同时还提出加强对重要数据的保护,对于核心数据实行更加严格的管理制度。
《网络数据安全管理条例(征求意见稿)》进一步明确了国家将数据分为三级,分别是一般数据、重要数据和核心数据,对于不同级别的数据采取不同的保护措施。同时条例还规定了对个人信息和重要数据进行重点保护,对核心数据实行更加严格的保护。
此外,《个人信息保护法》第五十一条也要求个人信息的处理者对个人信息进行分类管理,同时《个人信息保护法》对于敏感个人信息提出了更严格的要求,目的是实施不同程度的保护。因此,分类分级是数据合规的必要内容。
降低数据安全风险
数据经过分类分级之后,企业可以科学合理地划分资源,配套相应的安全风险控制措施,在释放数据资源价值的同时,保护数据安全和个人隐私。
通过识别出组织内重要敏感数据,掌握组织敏感数据资产分类、分级、分布情况及各类数据的使用场景。进而可以制定有效的防护措施,平衡数据流动创造价值与数据安全的矛盾,降低企业开展业务的安全风险。最后实现数据资产精细化管控,有效监控敏感数据的动态流向,使数据使用、数据共享行为“可见可控”。
满足自身业务需求
数据资产清单是数据治理的基础,提升数据质量能够帮助业务部门、在涉及数据处理活动业务场景、制定更为合理的策略,提升业务运营能力、为组织提供精准的数据服务,促使组织业务良性持续发展。而且,数据资产的精细化管理必将成为企业业务优化的发力点或突破点,也是企业竞争力之一。
03—《数据分类分级规则》解析-(1)核心内容
《规则》核心内容包含:
适用范围:规定了数据分类分级的原则、框架、方法和流程,给出了重要数据识别指南适用于行业领域主管(监管)部门参考制定本行业本领域的数据分类分级标准规范,也适用于各地区、各部门开展数据分类分级工作,同时为数据处理者进行数据分类分级提供参考。不适用于涉及国家秘密的数据和军事数据。
基本原则:数据分类分级遵循科学实用、边界清晰、就高从严、点面结合和动态更新的原则。
数据分类规则:数据按照行业领域分类,分为工业数据、电信数据、金融数据、能源数据、交通运输数据、自然资源数据、卫生健康数据、教育数据、科学数据等。
再按业务属性细分,包括业务领域、责任部门、描述对象、流程环节、数据主体、内容主题、数据用途、数据处理和数据来源等。
这是《规则》的核心部分之一,后续会有详细解析。
数据分级规则:数据分级框架将数据分为核心数据、重要数据和一般数据三个级别,根据数据的重要程度和可能造成的危害程度进行分级。
这个分级规则也和大多数的行业或地方标准的分级规则是一致的,详见下文。
数据分级要素:包括数据的领域、群体、区域、精度、规模、深度、覆盖度和重要性等。
数据影响分析:分析数据一旦遭到泄露、篡改、损毁或非法使用等情况下,可能影响的对象和影响程度。
级别确定规则:根据数据影响对象和影响程度,确定数据为核心数据、重要数据或一般数据。
数据分类分级流程:包括行业领域数据分类分级流程和处理者数据分类分级流程,涉及制定标准规范、开展分类分级、审核上报目录和动态更新管理等步骤。
影响对象和影响程度,这两个要素大家要记牢,后续会多次频繁出现,也是大多数规则考量级别确定的依据。
附录:提供了基于描述对象与数据主体的数据分类参考、个人信息分类示例、数据分级要素识别常见考虑因素、安全风险常见考虑因素、影响对象考虑因素、影响程度参考示例、重要数据识别指南、一般数据分级参考、衍生数据分级参考和动态更新情形参考等。
04—《数据分类分级规则》解析-(2)重点章节解析-原则
下边我们对规则内容进行详细解析。
文中包含了三大块7个部分:
1范围,2规范性引用文件,3术语与定义;
4基本原则,5数据分类规则,6数据分级规则;
7数据分类分级流程;
以及附录A-J共十个资料性和规范性文件和参考文献。
我们直接从第4节开始。
第4节.原则
《规则》指出,数据分类分级原则应包含五个方面:科学实用、边界清晰、就高从严、点面结合和动态更新。
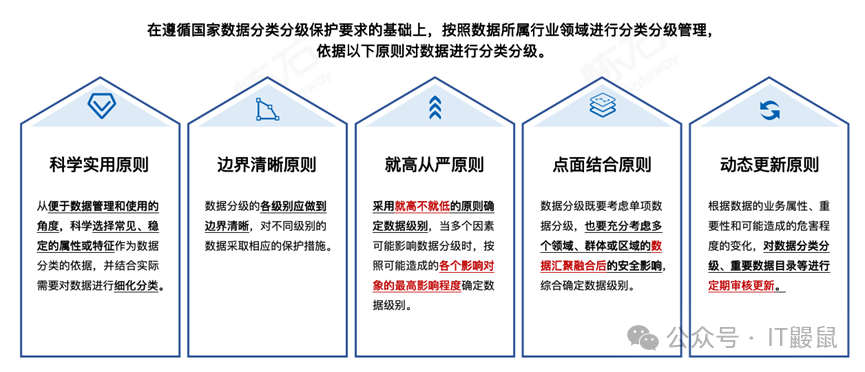
这个地方是原则性的说明,也比较清晰易懂,不再赘述。我们重点看 后边的分类和分级规则。
05—《数据分类分级规则》解析-(2)重点章节解析-第5节.分类规则
分类规则分为了两个部分阐述,即分类框架和分类方法。
如下图,分类框架按照行业领域和业务属性两个层级进行了分类。首先承认了行业的差异性,第一层就是要按照行业建立分类方法,各行业按照自己的规则去实施。这里分了工业、电信、金融、能源等等九类。
其次,不同行业内如何分类呢,就是按照业务属性去分。包括业务领域、责任部门、描述对象等也是九类业务属性。
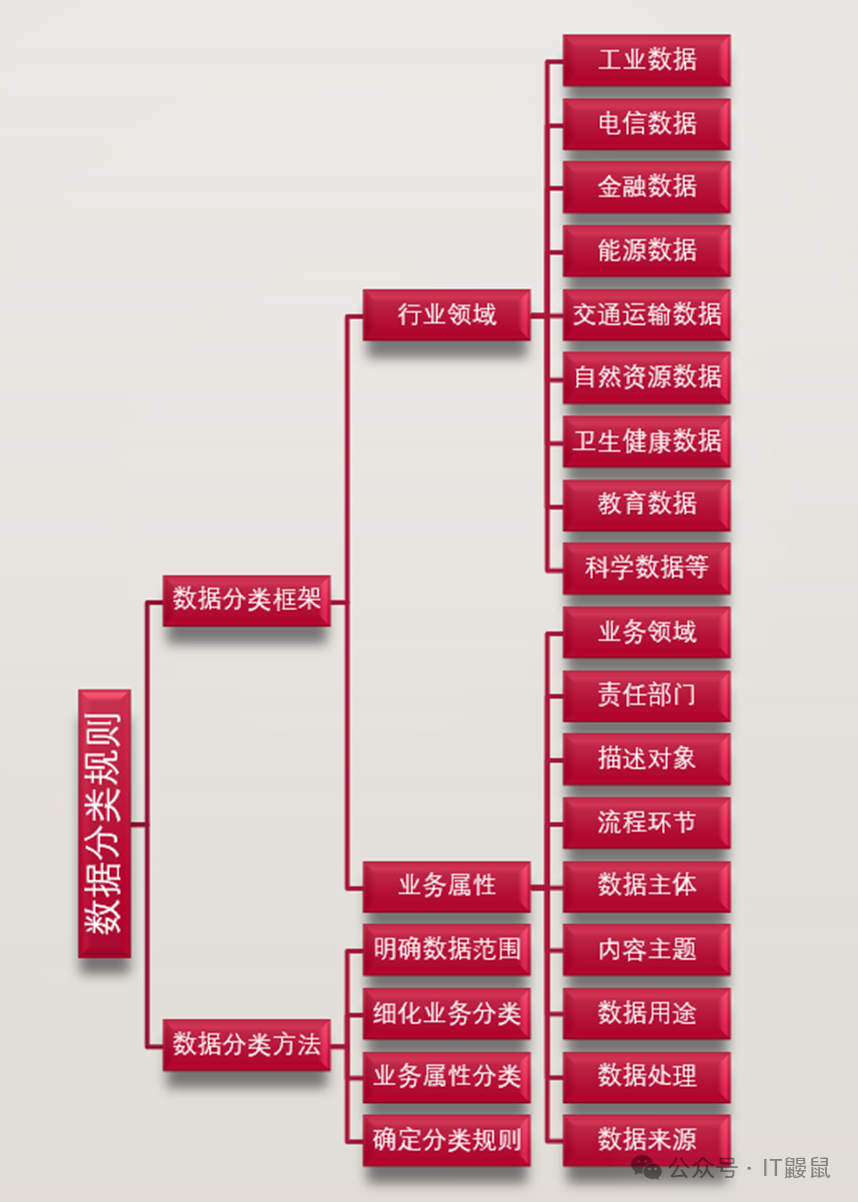
在具体操作过程中,《规则》也在行业这个粒度给出了参考的分类方法路径,即通过四步:
明确数据范围,细化业务分类,业务属性分类,确定分类规则。
其中前两步相对明确,即明确本行业本领域管理的数据范围,进而对业务进行细化分类。这些工作大家应该都是有一定实践和积累的。
第三步“业务属性分类”相对繁琐,需要选择合适的业务属性,对关键业务的数据进行细化分类。简单一句,其中选择“合适的业务属性”以及“关键业务”就会成为老大难,后边我们会结合具体行业案例跟大家做具体解析。
第四步是确定分类规则,这也是整个《规则》中分类方法的要点,需要相当的实操经验支持才可以达到较好的落地效果。《规则》中只是做了一般性的描述:“梳理分析各关键业务的数据分类结果,根据行业领域数据管理和使用需求, 确定行业领域数据分类规则”。
针对分类方法路径,《规则》举了两个例子,即
-
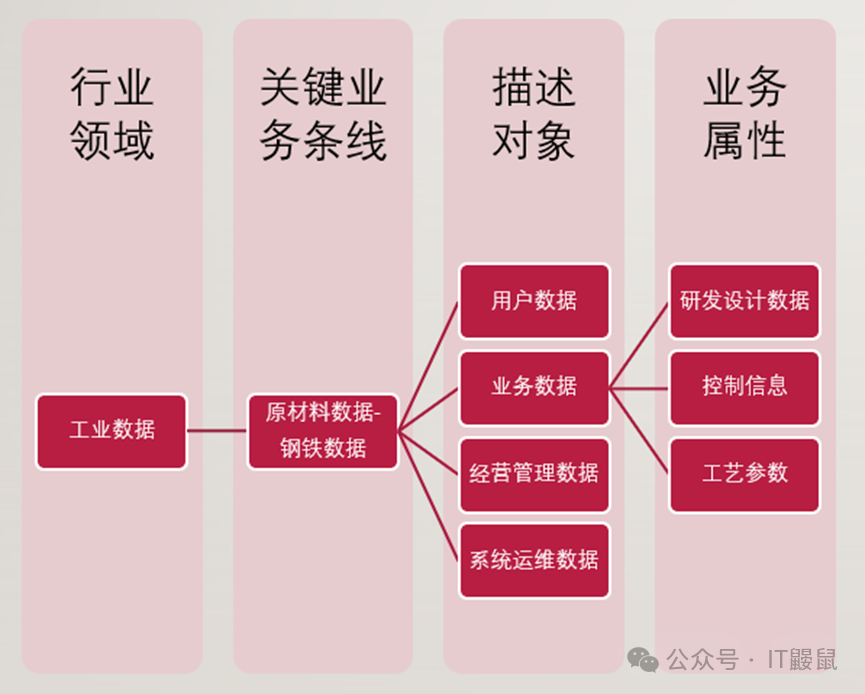
1. 可采取“业务条线—关键业务—业务属性分类”的方式给出数据分类规则;
举例:钢铁数据按照数据描述对象,分为用户数据、业务数据、经营管理数据、系统运维数据等,业务数据细分为研发设计数据、控制信息、工艺参数等,其中研发设计数据类别能标识为“工业数据-原材料数据-钢铁数据-业务数据-研发设计数据”。
鼹鼠哥:这里钢铁数据案例就是以分类框架-业务属性-描述对象为维度,把数据首先按照数据分类方法进行了业务属性分类。然后对分类还进行了第二层的细分,即把业务数据又细分为三类。这样就形成了总共五级的数据分类,其中研发设计数据就是第五级的一个分类,第一级是行业领域即工业数据。
-
2. 也可对关键业务的数据分类结果进行归类分析,将具有相似主题的数据子类进行归类。
举例:工业领域数据也按照数据处理、流程环节等业务属性进行分类,首先按照数据处理者类型分为工业企业工业数据、平台企业工业数据,再将工业企业工业数据分为研发数据、生产数据、运维数据、管理数据、外部数据,然后按照数据主题将生产数据分为控制信息、工况状态、工艺参数、系统日志等。
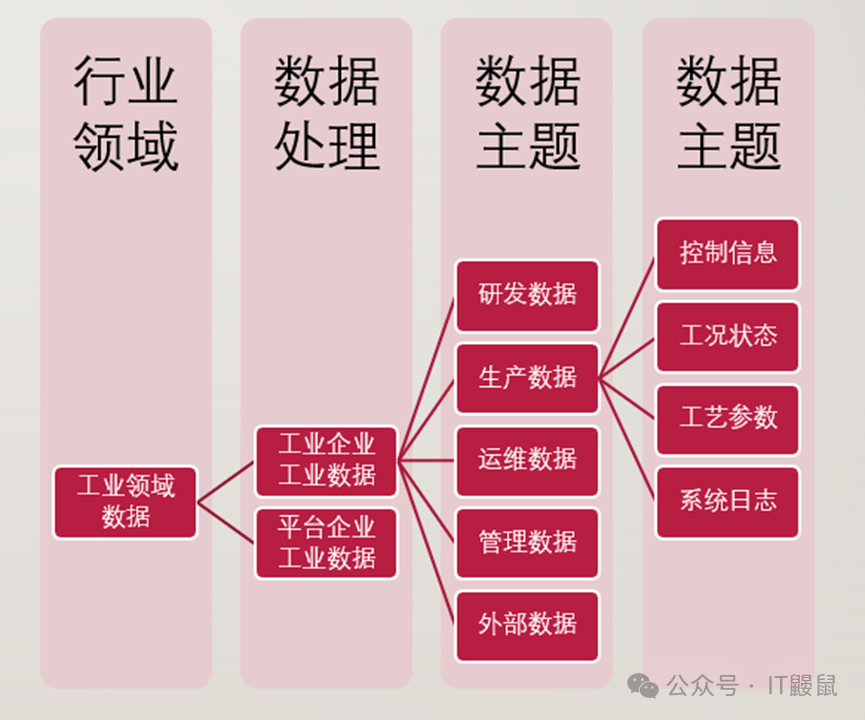
鼹鼠哥:同上,工艺参数数据就是第四级的一个分类,即“工业领域数据-工业企业工业数据-生产数据-工艺参数”。
06—《数据分类分级规则》解析-(2)重点章节解析-第6节.分级框架
分级框架指出,数据分级要从数据重要程度和危害程度两方面来判定,进行综合评价。
文中规则表如下,根据规则,不属于“核心数据”或“重要数据”的数据,一般都确定为“一般数据”,对于我们大多数企业和个人所接触及处理的数据,大多数情况下均为“一般数据”,所以我们后边的讨论也以“一般数据”的处理方法和规则为主来展开。
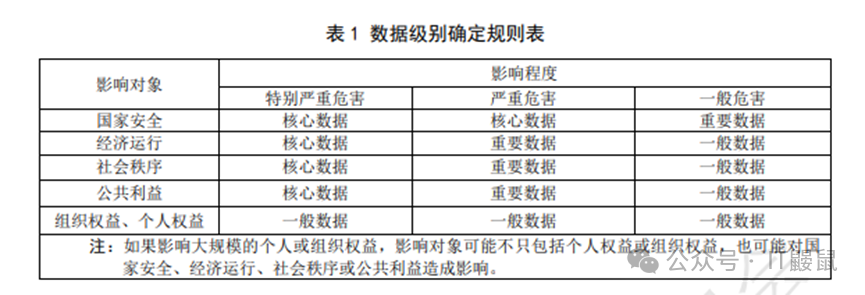
在按照规则表确定数据级别后,还要结合具体情况进行综合判定。主要包括如下几个方面:
-
1. 对一般数据还可以进行细化分级保护。
按照数据一旦遭到泄露、篡改、损毁或者非法获取、非法使用、非法共享,对经济运行、社会秩序、公共利益或个人、组织合法权益等造成的危害程度,将一般数据从低到高分为1级、2级、3级、4级共四个级别。1级遇到泄露等情况时,不会对个人权益、组织权益等造成危害。4级则对个人权益、组织权益造成特别严重危害,或对经济运行、社会秩序、公共利益造成一般危害。4 级数据按照批准的授权列表严格管理,仅能在受控范围内经过严格审批、评估后才可共享或传播。
-
2. 衍生数据级别可按照就高从严原则,在原始数据级别的基础上,综合考虑加工后的数据深度等分级要素对国家安全、经济运行、社会秩序、公共利益、组织权益、个人权益的影响进行确定。
《规则》对衍生数据分为了四类,即脱敏数据、标签数据、统计数据、融合数据。
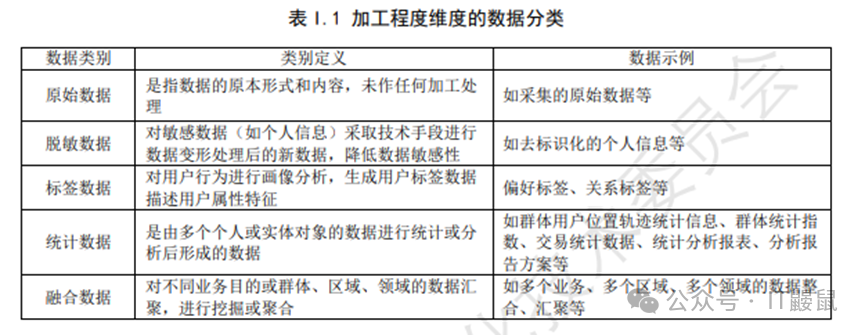
衍生数据级别可参考原始数据级别,综合考虑数据加工对分级要素、影响对象、影响程度的影响,按照第 6 章进行数据分级。
《规则》还明确了衍生数据和原始数据之间的级别关系:
脱敏数据级别可比原始数据级别降低;
标签数据级别可比原始数据级别降低或升高;
统计数据级别可比原始数据级别降低或升高;
融合数据级别要考虑数据汇聚融合结果,如果结果数据汇聚了更大规模的原始数据或分析挖掘出更敏感、更深层的数据,级别可以升高,但如果结果数据降低了标识化程度等,级别可以降低。
-
1. 跨行业领域数据分级,原则上可按照数据来源的行业领域数据分级规则确定级别,如果存在跨行业领域数据融合加工,需考虑融合加工对数据分级要素的影响,按照衍生数据确定级别。
-
2. 根据数据重要程度和可能造成的危害程度的变化,应对数据级别进行动态更新。
07—《数据分类分级规则》解析-(2)重点章节解析-第7节.分类分级流程
分类分级流程按照操作主体分为两类:
1.行业领域数据分类分级流程
《规则》规定行业领域主管(监管)部门的工作分为两部分:
首先是制定行业标准规范,包括了四个方面的工作:明确行业数据分类细则,明确行业重要数据识别细则,明确行业核心数据识别细则,明确行业一般数据范围。
其次是依据标准规范开展数据分类分级:组织行业数据处理者开展数据分类分级工作,指导数据处理者准确识别、及时报送重要数据和核心数据目录。
2.处理者数据分类分级流程
行业数据处理者的数据分类分级工作分为如下六个步骤:
-
1. 数据资产梳理:对数据资产进行全面梳理,确定待分类分级的数据资产及其所属的行业领域。
-
2. 制定内部规则:按照行业领域数据分类分级标准规范,结合处理者自身数据特点,参考本文件制定自身的数据分类分级细则
-
3. 实施数据分类:对数据进行分类,并对公共数据、个人信息等特殊类别数据进行识别和分类。
-
4. 实施数据分级:对数据进行分级,确定核心数据、重要数据和一般数据的范围。(鼹鼠哥:大部分企业需要关注的主要是一般数据)
-
5. 审核上报目录:对数据分类分级结果进行审核,形成数据分类分级清单、重要数据和核心数据目录,并对数据进行分类分级标识,按有关程序报送目录。
-
6. 动态更新管理:根据数据重要程度和可能造成的危害程度变化,对数据分类分级规则、重要数据和核心数据目录、数据分类分级清单和标识等进行动态更新管理。
我们可以简单概括为:摸家底,定规则,实施分类分级,报目录,常更新。

08—《数据分类分级规则》解析-(3)附录解析
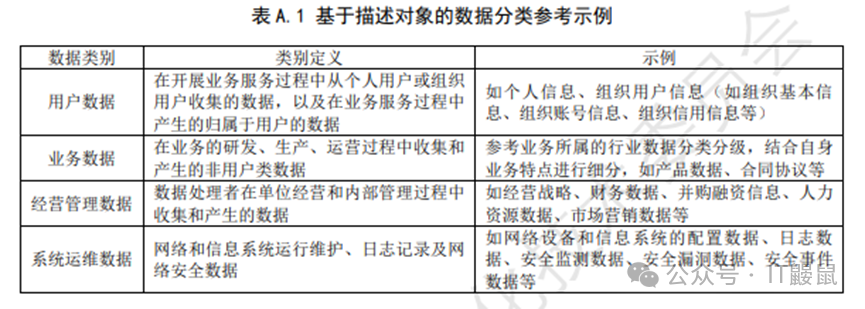
附录A:基于描述对象与数据主体分类
数据分类分级实务中,按照描述对象是最常见的分类方法。《规则》中所举的例子也是以描述对象为分类维度。《规则》中从从数据描述对象角度,将数据分为了用户数据、业务数据、经营管理数据、系统运维数据四个类别。
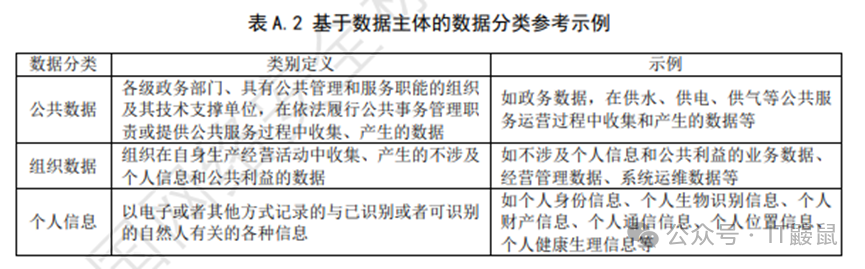
其次,还可以按照数据主体分类,《规则》中从数据主体角度,可将数据分为公共数据、组织数据、个人信息三个类别。
附录H:一般数据分级参考
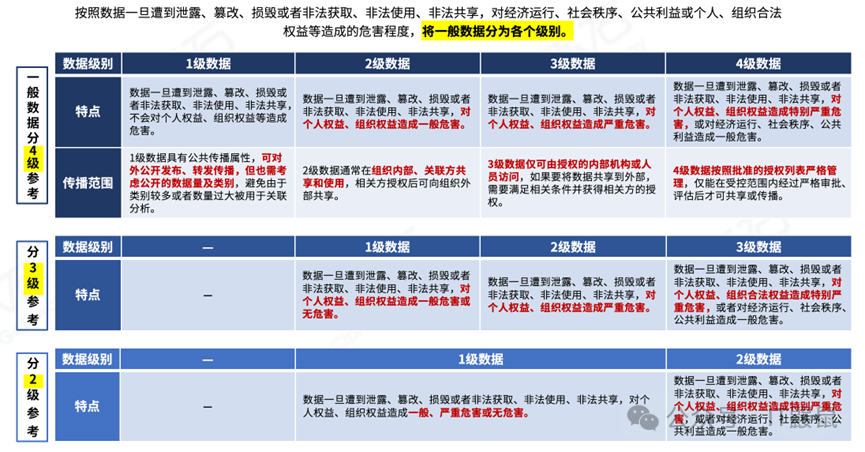
如正文中所述,大多数个人和企业能接触和处理的都是一般数据,如果需要对一般数据做细化分级,可以参考本章节。
《规则》对一般数据分级提供了分为4,3,2级的三类参考。
我们以四级分类为例,其中第一级级别最低,《规则》中描述为:
1 级数据:数据一旦遭到泄露、篡改、损毁或者非法获取、非法使用、非法共享,不会对个人权益、组织权益等造成危害。1 级数据具有公共传播属性,可对外公开发布、转发传播,但也需考虑公开的数据量及类别,避免由于类别较多或者数量过大被用于关联分析。
对于4级,则为:
4 级数据:数据一旦遭到泄露、篡改、损毁或者非法获取、非法使用、非法共享,对个人权益、组织权益造成特别严重危害,或对经济运行、社会秩序、公共利益造成一般危害。4 级数据按照批准的授权列表严格管理,仅能在受控范围内经过严格审批、评估后才可共享或传播。
鼹鼠哥:这里可以很清楚的看出。级别1的数据一般是可以对外公开发布和传播,而到了级别4,则需要进行严格管理,经过审批以后才可以传播。
我们引用CipherGateway的图表进行说明:

附录I:衍生数据分级参考
衍生数据,是按照数据加工程度维度对数据进行分类的。顾名思义,就是从原始数据通过加工处理衍生而来的数据。《规则》中把衍生数据分为了四类:脱敏数据、标签数据、统计数据、融合数据。衍生数据的定义和举例如下:
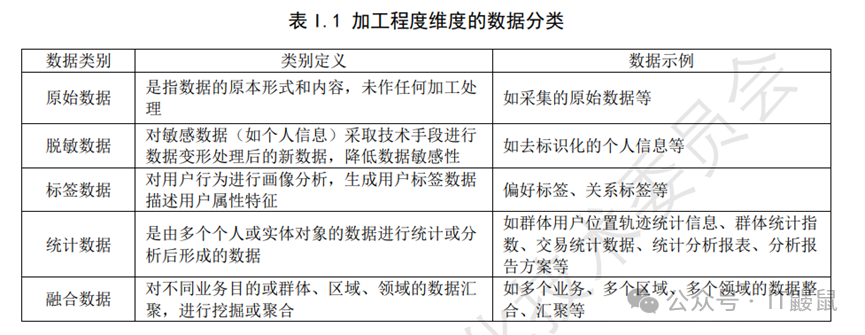
对于四类衍生数据的分级,《规则》规定如下:
i. 脱敏数据级别可比原始数据级别降低;
ii. 标签数据级别可比原始数据级别降低或升高;
iii. 统计数据级别可比原始数据级别降低或升高;
iv. 融合数据级别要考虑数据汇聚融合结果,如果结果数据汇聚了更大规模的原始数据或分析挖掘出更敏感、更深层的数据,级别可以升高,但如果结果数据降低了标识化程度等,级别可以降低。
09—待续
数据分类分级地方和行业标准
数据分类分级行业实践指南
数据分类分级行业实践案例
10—资料下载
公众号后台发送消息“分类分级规则”,即可下载国标《数据安全技术 数据分类分级规则》原文。

