- 1数学运算符_数字运算符
- 2TextBlob进行情感分析_textblob自定义情感分析
- 3正弦波脉宽调制SPWM波形发生器verilog语言basys3开发板代码_pwm模拟正弦波
- 4FreeBSD原生虚拟化Jail的管理软件比较
- 5tensorflow2------dnn实现_tensorflow2 dnn
- 6Python新手入门教程 | 如何用Python进行数据分析(非常详细)
- 7深入探索Stage #2:属性中的XSS注入技术
- 8江协科技STM32学习-1 购买24Mhz采样逻辑分析仪
- 9【python】PyCharm设置utf-8中文编码_pycharm设置utf8
- 10微信小程序的发送请求_vue制作微信小程序如何发送请求
大模型~合集18_contextual position encoding: learning to count wh
赞
踩
# huggingface
速度秒掉GPT-4o、22B击败Llama 3 70B,Mistral AI开放首个代码模型, 开放但禁止商用用途。
对标 OpenAI 的法国 AI 独角兽 Mistral AI 有了新动作:首个代码大模型 Codestral 诞生了。
作为一个专为代码生成任务设计的开放式生成 AI 模型,Codestral 通过共享指令和补全 API 端点帮助开发人员编写并与代码交互。Codestral 精通代码和英语,因而可为软件开发人员设计高级 AI 应用。
Codestral 的参数规模为 22B,遵循新的 Mistral AI Non-Production License,可以用于研究和测试目的,但禁止商用。
目前,该模型可以在 HuggingFace 上下载。
-
下载地址:https://huggingface.co/mistralai/Codestral-22B-v0.1
-
免费试用地址:https://t.co/LsgC84GCYw
Mistral AI 联合创始人、首席科学家 Guillaume Lample 表示,Codestral 可以很轻松集成到 VS Code 插件中。
有用户将 Codestral 与 GPT-4o 进行了比较,Codestral 速度直接秒了 GPT-4o。
精通 80 + 编程语言
Codestral 在包含了 80 + 种编程语言的多样化数据集上训练,包括 Python、Java、C、C++、JavaScript、Bash 等流行编程语言。此外也在 Swift 和 Fortran 等编程语言上表现良好。
因此,广泛的语言基础确保 Codestral 可以在各种编码环境和项目中为开发人员提供帮助。
Codestral 可以胜任编写代码、 编写测试并使用中间填充(fill-in-the-middle)机制补全任何代码部分,为开发人员节省时间和精力。同时使用 Codestral,还有助于提高开发人员的编码水平,降低错误和 bug 风险。 Taobao 天皓智联 whaosoft aiot http://143ai.com
代码生成性能新标准
作为一个 22B 参数的模型,Codestral 与以往的代码大模型相比,在代码生成性能和延迟空间方面树立了新标准。
从下图 1 可以看到,Codestral 的上下文窗口长度为 32k,竞品 CodeLlama 70B 为 4k、DeepSeek Coder 33B 为 16k、Llama 3 70B 为 8k。结果显示,在代码生成远程评估基准 RepoBench 上,Codestral 的表现优于其他模型。
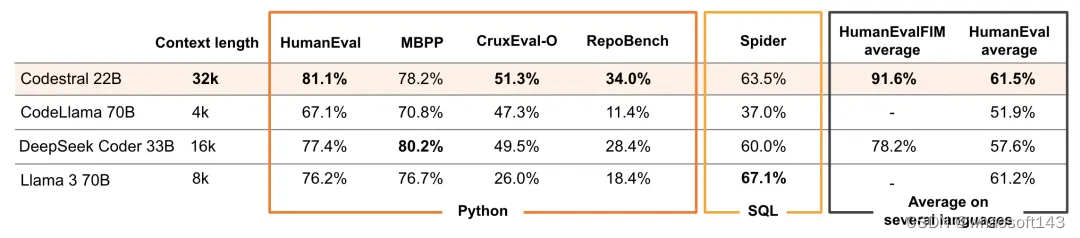
Mistral AI 还将 Codestral 与现有的特定于代码的模型进行了比较,后者需要较高的硬件需求。
在 Python 上的表现。研究者使用 HumanEval pass@1、MBPP sanitised pass@1 基准来评估 Codestral 的 Python 代码生成能力;除此以外,研究者还用到了 CruxEval、RepoBench EM 基准评估。
在 SQL 上的表现。为了评估 Codestral 在 SQL 中的性能,研究者使用了 Spider 基准测试。
在其他编程语言上的表现。研究者还在其他六种编程语言(包括 C++、bash、Java、PHP、Typescript 和 C#)中对 Codestral 进行了评估,并计算了这些评估的平均值。
 FIM 基准。研究者还评估了 Codestral 在代码片段中间有缺失的情况下补全代码的能力,主要是在 Python、JavaScript 和 Java 上进行实验,结果显示,Codestral 补全的代码,用户可以立即运行。
FIM 基准。研究者还评估了 Codestral 在代码片段中间有缺失的情况下补全代码的能力,主要是在 Python、JavaScript 和 Java 上进行实验,结果显示,Codestral 补全的代码,用户可以立即运行。

博客地址:https://mistral.ai/news/codestral/

# ChatTTS
爆火ChatTTS突破开源语音天花板,未来人与人的交流,难道是这个样?
近日,一个名为 ChatTTS 文本转语音项目爆火出圈,引来大家极大的关注。短短三天时间,在 GitHub 上已经斩获了 9.2 k 的 Star 量。
项目地址:https://github.com/2noise/ChatTTS/tree/main
作者本人也在 x 上表示,ChatTTS 突破了开源天花板。不过,目前开源的只是底模,没有经过 SFT 监督微调。
该项目将文本转换成语音,效果是这样的:
ChatTTS 不仅能说中文,英文也能 hold 住,还支持一些细粒度控制,它允许你加入笑声、说话间的停顿,还有语气词,可玩性很强。
它可以复刻已经逝去的人的绝版声音,想要再听到乔布斯开发布会,随时都可以。听它模仿霉霉的音色,不论是语调还是语气的变化,都挺接近本人,几乎听不出来 AI 味儿。
中英文混说也能拿捏,这口半英半中的腔调勇闯留子圈,ChatTTS 的语言能力已达到 next level。
以上音频来自 B 站: https://www.bilibili.com/video/BV1zn4y1o7iV/?share_source=copy_web&vd_source=983ec32a3036bb1cf2699e4fdbce3c28
从上述展示中我们可以看出,ChatTTS 能够实现自然流畅的语音合成,同时支持多说话人;还能预测和控制细粒度的韵律特征,包括笑声、停顿和插入词等;ChatTTS 在韵律方面超越了大部分开源 TTS 模型。
目前 ChatTTS 支持中文和英文。最大模型使用了超过 10 万小时的中英文数据进行训练。在 HuggingFace 中开源的版本为 4 万小时训练且未 SFT 的版本。
值得一提的是,上述展示的音频都是基于语音合成技术制作,旨在展示技术成果,无意冒犯或侵犯他人权益。
项目一经发布,各路网友纷纷试用起来,给出了声音确实真假难辨。
还有人拿 GPT 生成文本,让 ChatTTS「读」出来,语气语调和真人的差距非常小:
效果这么好,自然是想要上手试试。怎样才能用 ChatTTS 当你的嘴替,可以参考如下方法进行操作。
在线体验地址:https://huggingface.co/spaces/Dzkaka/ChatTTS
ChatTTS 主要有两种核心功能,第一种是文字转语音,第二种是将与大语言模型实时语音对话。在这些功能之外,可以在「Audio Seed」处调节数字指定说话人的音色,或者摇骰子随机生成一种。但是有不少测试者表示,每次采用一样的参数,生成的音色也不一定固定。
2Noise 称,目前支持音色克隆,但需要更大的数据量。
在文本框内输入文本后,ChatTTS 会自动为你生成韵律和停顿,还会加入一些如「然后」之类的语气词。如果你在输入时在文本中加入 [laugh] 和 [uv_break],就能手动控制 ChatTTS 在说话间产生一些「笑果」。
不过 ChatTTS 现在还不能搞定比较长的文本,有网友让它挑战了一下有声书,发现初始版本不能生成超过 30 秒的音频,需要手动修复。遇到比较长的文本时,ChatTTS 的分词也会出问题。
# ChatDirector
2D头像生成3D虚拟人开视频会,谷歌新作让人难绷,未来人与人的交流,难道是这个样?
开视频远程会议的时候,很多人都不喜欢打开摄像头。即使开了,在界面上大家也都被框在不同的窗口里。虽然这种形式操作起来很方便,但总是缺乏点临场感。
最近,谷歌提出了一项研究旨在解决这个问题,这个名叫 ChatDirector 的技术可以使用静态的 2D 头像生成 3D 虚拟人,让大家一同「坐在会议室里」开会,只是看起来样子有点夸张:

ChatDirector 通过空间化视频头像、虚拟环境和自动布局转换,构建了一个拟真的虚拟环境。
虽说只是早期研究,虚拟人物口型也能准确对上,但总觉得有一点喜剧效果。对此大片评论表示绷不住了:这或许能给在线会议创造出轻松的气氛。
ChatDirector 是一个研究原型,它将传统的视频会议转变为使用 3D 视频头像、共享 3D 场景和自动布局转换。
此前,谷歌展示的 Visual Captions 和开源的 ARChat,以促进实时视觉效果的口头交流为目标。在 CHI 2024 上展示的《ChatDirector: Enhancing Video Conferencing with Space-Aware Scene Rendering and Speech-Driven Layout Transition》中,谷歌介绍了一种新原型,通过在空间感知共享会议环境中为所有参与者提供语音驱动的视觉辅助,增强了传统的基于 2D 屏幕的视频会议体验。
设计思考
谷歌研究人员邀请了来自公司内部不同岗位的十位参与者,包括软件工程师、研究人员和 UX 设计师,共同讨论影响虚拟会议质量的因素,分析视频会议系统和面对面互动的特点,最后将建议提炼为原型系统的五个基本考虑因素:
-
DC1、通过空间感知可视化增强虚拟会议环境。处于同一个空间对于改善视频会议体验来说至关重要。好用的系统应采用典型的面对面会议形式,将与会者安排在指定座位的桌子周围,构建切实的共同存在感和空间定位感。
-
DC2、不能简单复制现实会议,而需要提供语音驱动的协助。鉴于小组对话中发言人频繁更换、话题快速转换,系统应提供额外的数字功能,让参与者跟进对话流程并积极参与会议。
-
DC3、重现面对面互动的视觉效果。在开虚拟会议时,参与者通常在电脑前保持静止。系统应增强他们在屏幕上的动作,以模仿头部转动和眼神接触等动态身体动作,这些动作可作为更有效地跟进对话的提示。
-
DC4、尽量减少认知负荷。系统应避免同时显示过多信息,或要求用户频繁操作。这种方法有助于防止分心,并允许参与者更有效地专注于倾听和说话。
-
DC5、确保兼容性和可扩展性。系统应与标准视频会议设备(如带摄像头的笔记本电脑)兼容,以促进广泛采用。这种兼容性还将促进其他生产力功能和工具(如屏幕共享和其他应用程序)的无缝集成,以增强系统的整体效用。
空间感知的场景渲染 pipeline
为了解决 DC1(通过空间感知可视化增强虚拟会议环境)和 DC5(确保兼容性和可扩展性),谷歌首先设计了一个渲染 pipeline,以将人的视觉呈现重建为 3D 肖像头像。
谷歌在轻量级深度推理神经网络 U-Net 上构建了此 pipeline,并结合了自定义渲染方法,该方法将 RGB 和深度图像作为输入并输出 3D 肖像头像网格。
该 pipeline 从深度学习 (DL) 网络开始,利用该网络从实时 RGB 网络摄像头视频中推断深度。接着使用 MediaPipe 自拍分割模型分割前景,并将处理后的图像馈送到 U-Net 神经网络。
其中,编码器逐渐缩小图像,而解码器将特征分辨率提高回原始分辨率。来自编码器的 DL 特征连接到具有相同分辨率的相应层,以帮助恢复几何细节,例如深度边界和薄结构。
下图所示的自定义渲染方法将 RGB 和深度图像作为输入,并重建 3D 肖像头像。
研究团队开发了一个空间感知的视频会议环境,可以在 3D 会议环境中显示远程参与者的 3D 肖像化身。
在每个本地用户的设备上,ChatDirector 会产生:
-
附带由 Web Speech API 识别的语音文本的音频输入
-
由 U-Net 神经网络推断的 RGB 图像和深度图像。
同时,当系统接收到每个远程用户的数据后,会重建 3D 肖像化身,并在本地用户的屏幕上显示出来。
为了实现视差效果,该团队根据使用 MediaPipe 人脸检测所检测到的本地用户的头部移动来调整虚拟渲染摄像机。音频会被用作输入到下一节中将要解释的语音驱动布局转换算法。
数据通信则通过 WebRTC 实现。

ChatDirector 的系统架构。
一个本地用户对具有 3D 肖像头像的空间感知视频会议环境的视角。
语音驱动的布局转换算法
为了解决 DC2(提供超越简单复制现实世界聚会的语音驱动辅助)和 DC3(重现面对面互动的视觉线索),研究者开发了一个决策树算法。
该算法根据正在进行的对话调整渲染场景的布局和化身的行为,允许用户通过接收自动视觉辅助来跟随这些对话,从而不需要在 DC4(最小化认知负荷)上额外浪费精力。
对于算法的输入,他们将群组聊天建模为一系列语音轮转。
在每个时刻,每个与会者都将处于三种语音状态之一:
-
静默:与会者正在听取他人发言;
-
与某人交谈(Talk-to):与会者正在与特定人交谈;具体来说,通过侦测参与者的姓名(当他们加入会议室时所输入的结果)来检测使用是否在与某人交谈。
-
宣布(Announce):与会者正在向所有人发言。通过使用关键词检测(如「everybody」、「ok, everybody」),Web 语音 API 来进行识别此种类型的语音状态。
该算法产生了两个增强视觉辅助的关键输出(DC3)。第一个组件是布局状态,它决定了会议场景的整体可视化。
这包括几种模式:
-
「一对一(One-on-One」,仅显示一个远程参与者,以便与本地用户进行直接互动;
-
「两两对话(Pairwise)」,将两个远程参与者并排排列,表示他们的一对一对话;
-
「全景(Full-view)」,默认设置显示所有参与者,表示一般讨论。

ChatDirector 的布局转换算法。

算法输出:布局状态。从左至右分别为:一对一(One-on-One)语音状态,两两对话(Pairwise)语音状态,全景(Full-view)语音状态。
网络视频开会这下更逼真了,领导和你可以交换眼神了。
研究团队基于 3D 肖像化化身渲染能力,通过操纵远程化身的行为来模拟类似于面对面会议中的眼神交流。
他们通过将化身状态(Avatar State)设立为算法的附加输出,以控制每个化身的方向。
在这种设置中,每个化身可以处于两种状态之一:「本地」状态,其中化身旋转面向本地用户,和「远程」状态,其中化身旋转与另一个远程参与者互动。
算法输出:化身(聊天室中代表使用者的形象)状态。当左侧用户与右侧用户交谈时,化身状态从「本地」状态转变为「远程」状态,此时左侧化身会转向右侧化身。
定性表现评估:用户研究
为了评估基于语音的布局转换算法的性能以及空间感知会议场景的整体有效性,研究团队进行了一项实验室研究,涉及 16 名参与者,分成四个团队。
与作为基准的传统视频会议相比,研究发现 ChatDirector 显著改善了与语音处理相关的问题,这表现在用户对注意力转移辅助的积极评价上。
此外,该团队对调查结果还进行了威尔科克森符号秩检验(Wilcoxon Signed-Rank Test )。

会议环境的空间感知和语音驱动布局转换算法的用户研究结果(N=16)。( *:p<.05, **: p<.01, *** :p< .001)
此外,根据 Temple Presence Inventory(TPI)评分,与标准的基于 2D 的视频会议系统相比,它提升了共存感和参与度。

Temple Presence Inventory(TPI)结果显示了 ChatDirector 系统的社交存在评级(N=16)。( *:p<.05, **: p<.01, *** :p< .001)
由于 ChatDirector 基于视频会议室使用者的肖像化身,肖像安全的问题将成为未来研究发展的重中之重。
研究团队在最后表示,希望 ChatDirector 能够激发在利用先进的感知和交互技术来增加共同在场的感受和参与度日常计算平台上的持续创新。
研究人员同时指出,解决负责任的 AI 考虑及其数字相似性的含义是极其重要的。因为以这种方式转换「用户的视频」可能会引发关于他们对自身肖像控制的问题,所以需要进一步的研究和仔细考虑。
当这类工具部署时,至关重要的是需要基于用户的同意并遵守相关道德准则。
该团队还提供了一个 ChatDirector 的交互技术演示,在视频内容里展示了更多的 3D 视频示例。
视频链接:https://youtu.be/mO2rZL48C1Y
参考链接:https://research.google/blog/chatdirector-enhancing-video-conferencing-with-space-aware-scene-rendering-and-speech-driven-layout-transition/
# SketchDream
作者是中国科学院计算技术研究所高林老师及其博士生刘锋林,香港城市大学傅红波老师,卡迪夫大学来煜坤老师。该项研究工作受到国家自然科学基金委、北京市自然科学基金委、北京市科学技术委员会的资助,由信息高铁智算算力网平台提供算力支持。
基于人工智能的数字内容生成,即 AIGC 在二维图像生成领域取得了很大的成功,但在三维生成方面仍存在挑战。智能化生成三维模型在 AR/VR、工业设计、建筑设计和游戏影视等方面都有应用价值,现有的智能化三维生成方法已经可以生成高质量的三维模型,但如何对生成结果进行精确控制,并对真实模型或生成的模型进行细节的修改,从而让用户自由定制高质量的三维模型仍然是一个待解决的问题。
近期,一篇题为《SketchDream: Sketch-based Text-to-3D Generation and Editing》的论文提出了基于线稿和文本的三维内容生成和编辑方法 SketchDream [1],论文发表在 SIGGRAPH 2024,并被收录于图形学顶级期刊 ACM Transactions on Graphics。这个 3D AIGC 工作助你成为神笔马良,通过画笔画出三维世界,已入选 SIGGRAPH 精选亮点工作宣传片。
-
论文:SketchDream: Sketch-based Text-to-3D Generation and Editing
-
论文地址:https://arxiv.org/pdf/2405.06461
-
项目主页:http://www.geometrylearning.com/SketchDream/
使用该系统,即使用户不会使用复杂的三维软件,也可以基于线稿自由创作三维内容,并对真实的模型进行修改和编辑。先来看看使用 SketchDream 创作的模型的效果:
图 1 基于 SketchDream 的三维生成效果
图 2 基于 SketchDream 的三维编辑效果
背景
最近,AI 绘画非常火爆,基于 Stable Diffusion [2] 和 ControlNet [3] 等方法,通过指定文本可以生成高真实感的二维图像。最新的视频生成方法 Sora [4],已经可以基于文本生成高质量影视级的视频。但是,上述工作无法直接生成高质量的三维模型,更无法对现有的三维模型进行编辑和修改。
针对上述问题,DreamFusion [5] 提出了 Score Distillation Sampling (SDS) 的方法,利用二维图像的 Diffusion model 生成模型优化神经辐射场,基于文本合成任意类别的高质量的三维模型。后续一系列工作 [6][7][8] 对该方法进行了改进,提升了生成的三维模型的质量,并使生成的过程更加稳定。但是,仅仅基于文本,难以实现对几何细节的控制,例如物体的形状和轮廓,不同的组件的形状和位置等。为了提高可控性,许多方法 [9][10] 使用额外的图像作为输入,生成高质量的模型,但用户依然需要提前获取合适的图像。
除了三维内容生成,如何对已有的三维模型进行再创作,即对真实的三维模型进行修改和编辑也是非常重要的问题。Vox-e [11] 和 DreamEditor [12] 根据文本自适应的确定三维编辑区域,再实现基于文本的编辑效果。为了实现更精细的控制,SKED [13] 使用线稿编辑三维模型,但如何处理复杂编辑情景仍然较为困难。
线稿作为一种用户友好的交互方法,被广泛用于三维建模。艺术家们通常会先绘制物体的线稿,再进一步使用专业软件进行建模。然而,直接使用线稿生成高质量的三维物体存在下述挑战:首先,线稿风格多样且过于稀疏,很难使用单视角的线稿约束三维物体的生成;其次,二维线稿只包含了单视角的信息,如何解决歧义性,生成侧面和背面区域较为困难。基于线稿的模型编辑则更具挑战性,如何分析并处理不同组件的关系,如何保证编辑区域的生成质量,如何保持非编辑区域不变,都是需要解决的问题。
SketchDream 算法原理
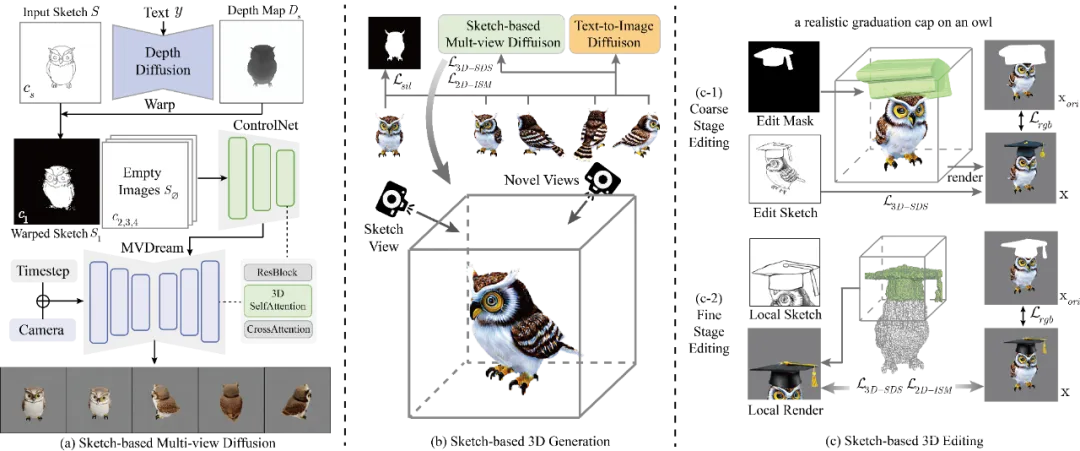
图 3 SketchDream 的网络架构图,生成和编辑流程
基于线稿的多视角图像生成网络
给定单视角的手绘线稿后,仅在线稿对应的视角添加约束,无法生成合理的三维模型。因此,需要将线稿的信息有效地传播到三维空间中的新视角,从而合成与线稿对应的高质量的模型。SketchDream 算法构建了基于线稿的多视角图像生成的扩散模型。具体而言,算法在多视角图像生成网络 MVDream [8] 的基础上,添加了与 ControlNet 结构类似的控制网络,基于线稿控制多视角图像的特征。网络使用了 3D Self-Attention,在不同视角之间共享 Q,K,V 特征,从而生成三维一致的结果。
直接使用单视角二维线稿作为多视角图像控制网络的输入,由于缺乏三维信息和空间对应,难以实现有效的线稿控制。因此,算法使用扩散模型生成线稿对应的深度图,补充稀疏线稿缺失的几何信息。进一步,基于深度对线稿变形,从而将线稿显式地变换到相邻的新视角,其他视角则直接输入空白图像。尽管其他视角输入了空白图像,但 3D Self-Attention 保证了视角间的信息交换,从而实现对多视角图像的有效控制。
基于线稿的三维生成
为了实现高质量的三维生成,算法基于线稿的多视角图像扩散模型,反向优化神经辐射场。优化过程中,每一个迭代的步骤,使用不同的相机参数渲染模型并计算梯度,反向优化三维模型。算法基于多视角图像生成网络计算 SDS Loss,保证三维模型的几何合理性。并且,为了提升纹理细节的质量,算法基于 2D 的图像生成网络,计算 ISM Loss [14],提高模型生成质量。算法额外添加蒙版约束和正则化项,提高线稿的对应性和模型的合理性。
基于线稿的三维编辑
为了实现精细化的编辑,算法提出了两阶段编辑方法:粗粒度编辑阶段,算法分析组件的交互关系,生成初始的编辑结果,并基于此获取更精确的三维蒙版;细粒度编辑阶段,算法对局部编辑区域进行渲染优化,并保持非编辑区域的特征,实现高质量的局部编辑效果。
具体而言,在粗粒度编辑阶段,将手绘的 2D 蒙版转换为 3D 空间中的圆柱网格模型,粗略标记编辑的区域。优化过程中,使用与生成相同的损失函数进行优化,但在非编辑区域额外添加与原始模型的 L2 损失,保持原始模型的特征。进一步,从粗略编辑的 NeRF 结果中提取网格模型,标记 3D 网格的局部区域表示待编辑的区域,获取精细化的 3D 蒙版。在细粒度编辑阶段,为了提升编辑区域的质量,算法对局部编辑区域进行渲染,添加基于线稿的 SDS 约束,并添加更精细的非编辑区域的约束,生成更高质量的编辑效果。
效果展示
如图 4 所示,给定手绘线稿和文本描述,该方法可以生成高质量的三维模型。算法生成的结果没有类别限制,结果具备合理的几何属性和高质量的纹理属性。用户可以自由变换视角,都能得到非常真实的渲染结果。

图 4 基于线稿生成的三维模型
如图 5 所示,给定真实的三维模型,用户可以选择任意的视角,对渲染出的线稿进行修改,从而编辑三维模型。该方法可以对已有模型的部件进行替换,例如左侧的修改狮子头部、更换裙子等,也可以添加新的部件,例如右侧的添加新的房间、添加翅膀等。

图 5 基于线稿的三维模型编辑结果
如图 6 所示,给定线稿和文本描述,该方法可以对应的三维模型。进一步,用户可以旋转到新的视角,对局部区域进行修改,实现三维模型的精细化定制。
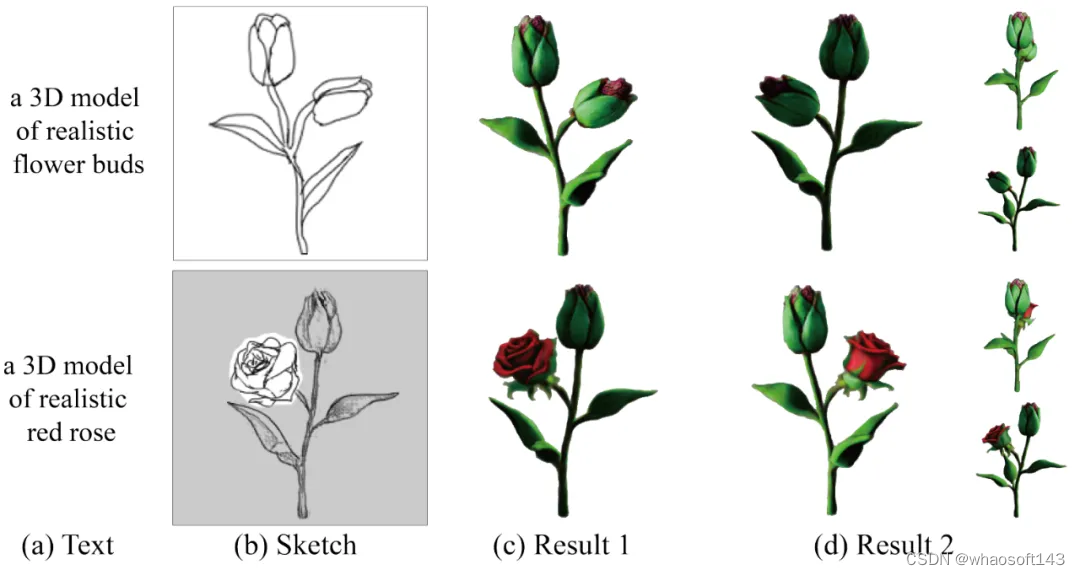
图 6 基于线稿的生成和编辑效果
如图 7 所示,针对同一个三维模型,用户可以绘制不同的线稿,从而生成具备多样性的结果。线稿也实现了较为精细化的控制,实现了对鸵鸟不同颈部姿态的控制效果。

图 7 基于线稿的多样化的编辑效果
如图 8 所示,针对同一个三维模型,用户可以指定不同的文本,从而生成具备纹理多样性的结果。在给定相同线稿的情况下,可以生成黄金、铜制和石头质感的狮子头,并保持其他区域不变。

图 8 基于文本的多样化的编辑效果
结语
基于人工智能的数字内容生成技术蓬勃发展,在很多领域已经有广泛的应用。针对三维内容生成,除了保证高真实感的生成质量,如何提高用户的可控性是重要的问题。SketchDream 提供了一种可行的解决方案,基于手绘线稿,用户可以生成高质量的三维模型,并支持对真实模型的可控编辑。
基于该系统,我们无需安装繁杂的三维建模软件并学习复杂的技能,也不需要花费数个小时时间精力,仅仅通过勾勒简单的线条,普通用户也能轻松构建心中完美的三维模型,并得到高质量的渲染结果。SketchDream 已经被 ACM SIGGRAPH 2024 接收,并将刊登在期刊 ACM Transactions on Graphics 上,已入选 SIGGRAPH 精选亮点工作宣传片。
# 解决Transformer根本缺陷
即使最强大的 LLM 也难以通过 token 索引来关注句子等概念,现在有办法了。
最近两天,马斯克和 LeCun 的口水战妥妥成为大家的看点。这两位 AI 圈的名人你来我往,在推特(现为 X)上相互拆对方台。
LeCun 在宣传自家最新论文时,也不忘手动 @ 一把马斯克,并意味深长地嘱咐道:「马斯克,我们这项研究用来改善你家的 Grok 也没问题。」
LeCun 宣传的这篇论文题目为《 Contextual Position Encoding: Learning to Count What’s Important 》,来自 Meta 的 FAIR。
骂战归骂战,这篇论文的重要性不言而喻。短短 24 小时之内就成为了 AI 领域最热门的论文之一。它有望解决如今大模型(LLM)最让人头疼的问题。
论文地址:https://arxiv.org/pdf/2405.18719
总的来说,该研究提出了一种新的用于 transformer 的位置编码方法 CoPE(全称 Contextual Position Encoding),解决了标准 transformer 无法解决的计数和复制任务。传统的位置编码方法通常基于 token 位置,而 CoPE 允许模型根据内容和上下文来选择性地编码位置。CoPE 使得模型能更好地处理需要对输入数据结构和语义内容进行精细理解的任务。文章通过多个实验展示了 CoPE 在处理选择性复制、计数任务以及语言和编码任务中相对于传统方法的优越性,尤其是在处理分布外数据和需要高泛化能力的任务上表现出更强的性能。
CoPE 为大型语言模型提供了一种更为高效和灵活的位置编码方式,拓宽了模型在自然语言处理领域的应用范围。
有网友表示,CoPE 的出现改变了在 LLM 中进行位置编码的游戏规则,此后,研究者能够在一个句子中精确定位特定的单词、名词或句子,这一研究非常令人兴奋。
这篇论文主要讲了什么,我们接着看。
许多常见的数据源(例如文本、音频、代码)都是顺序序列(ordered sequences)。在处理此类序列时,顺序(ordering)信息至关重要。对于文本,位置信息不仅对于解码单词之间的含义至关重要,而且在其他尺度(例如句子和段落级别)上都是必需的。
作为当前大型语言模型 (LLM) 的主要支柱 Transformer 架构,依赖于注意力机制,而这种机制本身就缺乏顺序信息,因此,需要一种额外的机制来编码数据的位置信息。
先前有研究者提出了位置编码(PE,Position encoding),该方法通过为每个位置分配一个嵌入向量,并将其添加到相应的 token 表示中来实现这一点。然而,当前的位置编码方法使用 token 计数来确定位置,因此无法推广到更高层次如句子。
为了将位置与更具有语义的单元(如单词或句子)联系起来,需要考虑上下文。然而,使用当前的位置编码方法无法实现这一点,因为位置寻址是独立于上下文计算的,然后再与上下文寻址合并。
Meta 认为,位置与上下文寻址的这种分离是问题的根本所在,因此他们提出了一种新的 PE 方法,即上下文位置编码( CoPE ),将上下文和位置寻址结合在一起。
方法介绍
CoPE 首先使用上下文向量确定要计数的 token。具体来说,给定当前 token 作为查询向量,接着使用先前 token 的键向量计算一个门值(gate value)。然后汇总这些门值,以确定每个 token 相对于当前 token 的相对位置,如图 1 所示。
与 token 位置不同,上下文位置可以取分数值,因而不能具有指定的嵌入。相反,该研究插入赋值为整数值的嵌入来计算位置嵌入。与其他 PE 方法一样,这些位置嵌入随后被添加到键向量中,因此查询向量可以在注意力操作中使用它们。由于上下文位置可能因查询和层而异,因此该模型可以同时测量多个单元的距离。

在 CoPE 中,位置是通过上下文相关的方式来测量的,而不是简单的 token 计数。该方法的工作原理是首先决定在使用上下文向量测量距离时应包含哪些 token。因此,对每个查询 q_i 和键 k_j 对计算门值
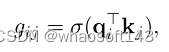
其中 j < i 且 σ 是 sigmoid 函数。门值为 1 表示该键将被计入位置测量中,而 0 表示将被忽略。例如,要计算 token i 和 j 之间的句子,仅对于诸如 “.” 之类的句子分隔 token,门值应为 1。门以查询为条件,如果需要,每个查询可以有不同的位置测量。软门控函数(soft gating function)允许微分,以便可以通过反向传播来训练系统。
然后,该研究通过添加当前 token 和目标 token 之间的门值来计算位置值。
值得注意的是,如果门值始终为 1,则 p_ij = i − j + 1 ,并且恢复基于 token 的相对位置。因此,CoPE 可以被视为相对 PE 的泛化。然而,一般来说,p_ij 可以是特定单词或单词类型(如名词或数字)的计数、句子的数量或 Transformer 认为在训练期间有用的其他概念。
与 token 位置不同,位置值 p_ij 不限于整数,并且因为 sigmoid 函数的原因可以采用小数值。这意味着不能像相对 PE 中那样使用嵌入层将位置值转换为向量。
首先,该研究为每个整数位置 p ∈ [0, T] 分配一个可学习的嵌入向量 e [p],那么位置 p_ij 的嵌入将是两个最接近的整数嵌入的简单插值。
最后,计算类似于如下等式的注意力权重。

CoPE 的多头扩展非常简单,因为每个头都会独立执行自己的 CoPE。头之间的键和查询向量是不同的,这意味着它们可以实现不同的位置测量。
实验结果
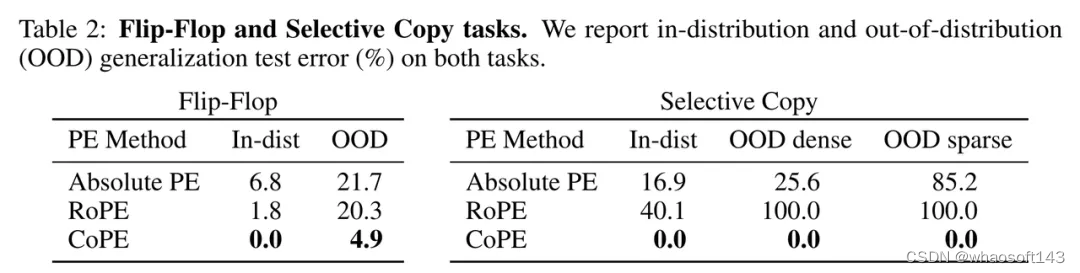
Flip-Flop 任务
Liu 等人 [2024] 提出了 Flip-Flop 语言建模任务,以揭示 Transformer 模型无法在长距离输入序列上进行稳健推理。
结果如表 2(左)所示。结果表明,CoPE 优于现有方法,使模型不仅可以学习分布内任务,还可以推广到 OOD 序列 —— 这是现有 PE 方法无法提供的属性。
选择性复制任务
Gu 和 Dao [2023] 提出的选择性复制任务需要上下文感知推理才能进行选择性记忆。
表 2(右)中给出的结果显示,在分布内测试集上,新方法 CoPE 可以解决该任务,而其他方法则无法解决。同样的,CoPE 在密集和稀疏 OOD 测试集上都具有更好的泛化能力。空白 token 的存在使得找到下一个要复制的 token 变得更加困难,但 CoPE 只能计算非空白 token,因此更加稳定。在每个步骤中,它可以简单地复制距离为 256(非空白)的非空白 token。重复此操作 256 次将复制整个非空白序列。
计数任务
计数比简单地回忆上一个实例更具挑战性,因为它需要在一定范围内更均匀的注意力。
结果见表 3 和图 2。具有相对 PE 的基线模型很难学习此任务,尤其是当有多个变量需要跟踪时。绝对 PE 的表现更差。最佳表现来自 CoPE,在 1 个变量的情况下获得满分。对于 OOD 泛化,相对 PE 表现出较差的泛化能力,而 CoPE 的泛化能力非常好,如表 4 所示。有关这些实验的标准差,请参见附录表 9。

语言建模
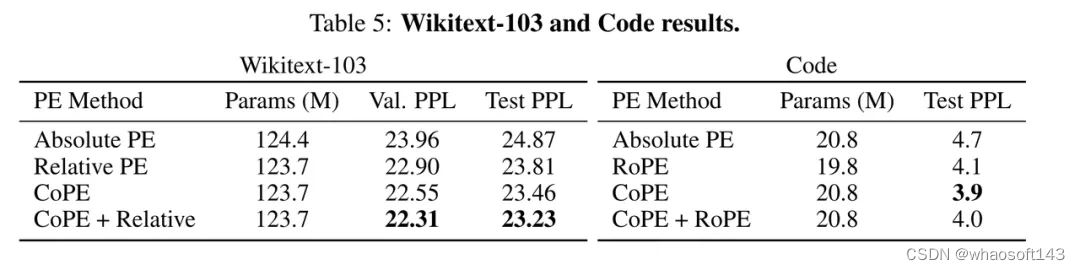
为了在语言建模任务上测试新方法,研究人员使用了 Wikitext-103 数据集,该数据集包含从 Wikipedia 中提取的 1 亿个 token。
表 5(左)中比较了不同的 PE 方法:绝对 PE 表现最差,CoPE 优于相对 PE,与相对 PE 结合使用时效果更佳。这表明,即使在一般语言建模中,CoPE 也能带来改进。

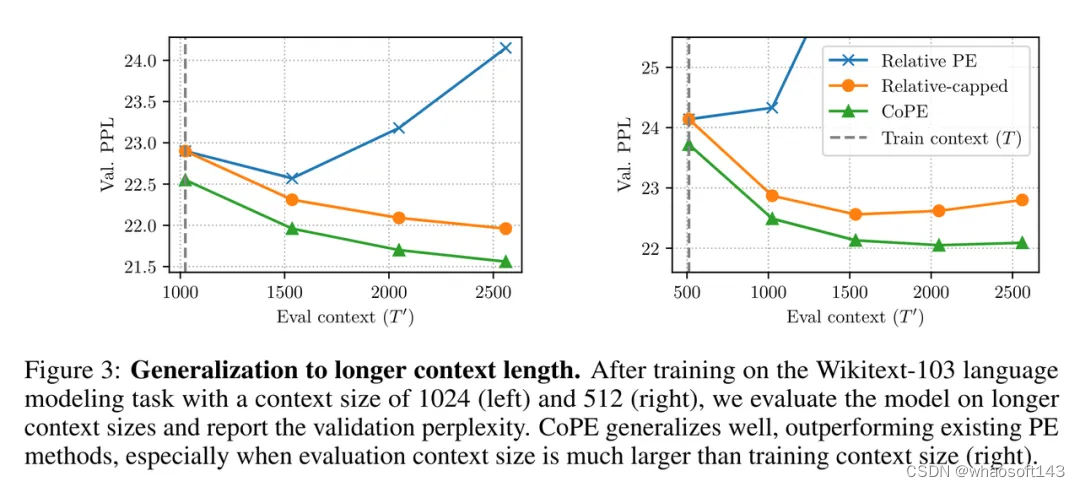
接下来,作者测试了 CoPE 推广到比训练上下文更长的上下文的效果。
结果如图 3 所示。相对 PE 推广到更长的上下文效果不佳。相比之下,相对上限版本的表现要好得多。然而 CoPE 的表现仍然优于它,当测试上下文比训练上下文长得多时,差距会扩大(见图 3 右)。
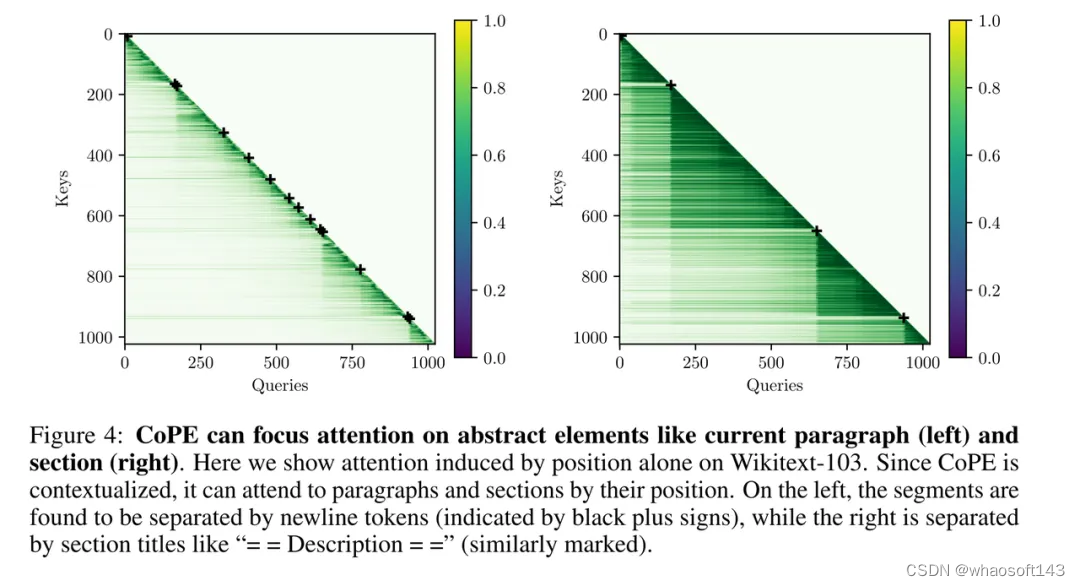
如图 4 所示,作者展示了使用 sep-keys 训练的模型的注意力图示例(gate 是用分离的键计算的)。注意力图仅根据位置构建(它们必须与上下文注意力相乘才能得到最终的注意力),这能让我们更好地了解 CoPE 正在做什么。作者还进行了归一化,以便每个查询的最大注意力权重始终为 1。首先,我们可以看到位置明显具有上下文相关性,因为无论它们的相对位置如何,注意力都倾向于落在特定的 token 上。
仔细观察这些 token 会发现,注意力主要集中在最后一段(左)或部分(右)上。为清楚起见,实际的段落和部分边界用黑色加号标记。在 CoPE 中,这是可能的,因为一个注意力头可以计数段落,而另一个注意力头计数部分,然后它可以只关注位置 0。
代码建模
作者通过对代码数据进行评估来进一步测试 CoPE 的能力。与自然语言相比,代码数据具有更多的结构,并且可能对上下文学习更敏感。
结果总结在表 5(右)中。CoPE 嵌入的困惑度比绝对 PE 和 RoPE 分别提高了 17% 和 5%。将 RoPE 和 CoPE 嵌入结合在一起可以改善 RoPE,但不会比所提出的嵌入方法带来任何改进。