
- 1go 针对 time类型字段,前端查询,后端返回数据格式为UTC时间
- 2git clone没有权限的解决方法_git没有权限clone代码
- 3Kafka-消费者(订阅主题消费数据及常用调优参数解析)
- 4Raid介绍_服务器raid
- 5mysql 数据导入sqlserver_如何从mysql中将数据导入到sqlserver
- 6【Python数据挖掘课程】四.决策树DTC数据分析及鸢尾数据集分析_decision tree test data
- 7Mysql查看连接并批量kill线程_show processlist kill 批量
- 8vue3.0使用axios 解决跨域问题_vue3 axios跨域
- 9Python 数据挖掘 | 第3章 使用 Pandas 数据分析_pandas 并计算潜力低、中等、优秀三个等级的数量
- 10如何读源码-方法论总结_常用方法论总结
大数据分析你不能不懂的6个核心技术
赞
踩

目前,大数据领域每年都会涌现出大量新的技术,成为大数据获取、存储、处理分析或可视化的有效手段。大数据技术能够将大规模数据中隐藏的信息和知识挖掘出来,为人类社会经济活动提供依据,提高各个领域的运行效率,甚至整个社会经济的集约化程度。
1大数据生命周期
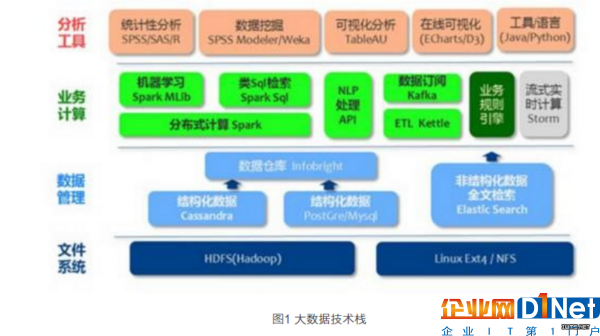
图1展示了一个典型的大数据技术栈。底层是基础设施,涵盖计算资源、内存与存储和网络互联,具体表现为计算节点、集群、机柜和数据中心。在此之上是数据存储和管理,包括文件系统、数据库和类似YARN的资源管理系统。然后是计算处理层,如hadoop、MapReduce和Spark,以及在此之上的各种不同计算范式,如批处理、流处理和图计算等,包括衍生出编程模型的计算模型,如BSP、GAS 等。数据分析和可视化基于计算处理层。分析包括简单的查询分析、流分析以及更复杂的分析(如机器学习、图计算等)。查询分析多基于表结构和关系函数,流分析基于数据、事件流以及简单的统计分析,而复杂分析则基于更复杂的数据结构与方法,如图、矩阵、迭代计算和线性代数。一般意义的可视化是对分析结果的展示。但是通过交互式可视化,还可以探索性地提问,使分析获得新的线索,形成迭代的分析和可视化。基于大规模数据的实时交互可视化分析以及在这个过程中引入自动化的因素是目前研究的热点。
有2个领域垂直打通了上述的各层,需要整体、协同地看待。一是编程和管理工具,方向是机器通过学习实现自动最优化、尽量无需编程、无需复杂的配置。另一个领域是数据安全,也是贯穿整个技术栈。除了这两个领域垂直打通各层,还有一些技术方向是跨了多层的,例如“内存计算”事实上覆盖了整个技术栈。
2.大数据技术生态
大数据的基本处理流程与传统数据处理流程并无太大差异,主要区别在于:由于大数据要处理大量、非结构化的数据,所以在各处理环节中都可以采用并行处理。目前,Hadoop、MapReduce和Spark等分布式处理方式已经成为大数据处理各环节的通用处理方法。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。Hadoop 是一个数据管理系统,作为数据分析的核心,汇集了结构化和非结构化的数据,这些数据分布在传统的企业数据栈的每一层。Hadoop也是一个大规模并行处理框架,拥有超级计算能力,定位于推动企业级应用的执行。Hadoop又是一个开源社区,主要为解决大数据的问题提供工具和软件。虽然Hadoop提供了很多功能,但仍然应该把它归类为多个组件组成的Hadoop生态圈,这些组件包括数据存储、数据集成、数据处理和其他进行数据分析的专门工具。图2 展示了Hadoop 的生态系统,主要由HDFS、MapReduce、Hbase、Zookeeper、Oozie、Pig、Hive等核心组件构成,另外还包括Sqoop、Flume等框架,用来与其他企业融合。同时,Hadoop 生态系统也在不断增长,新增Mah

