
- 1Qt窗体之间相互传值的三种方式_qt不同窗口之间发送数据
- 2超融合架构与容器超融合
- 3【Java】数组详解_java数组
- 4zMUD里的颜色触发_zmud颜色触发
- 5利用Java实现HDFS文件上传下载_java实现hadoop下载大文件的方法
- 6学习笔记——rabbitMq_rabbittemplate.convertandsend什么时候执行一次
- 7OpenAI ChatGPT 3.5模型和清华开源ChatGLM-6B模型的对比,到底ChatGPT强在哪里(内含几个国内GPT可用途径)_清华glm模型与gpt区别
- 8Android studio 的Gradle问题(新手)_android studio打开 gradle背景橙色
- 9CAP框架异常处理、实现分布式事务及其它用法_cap标记为异常
- 10CVE-2016-2183
讲讲情感分析_情感分析模型的作用是什么
赞
踩
最近闲来无事,和朋友一起报名参加了美赛春季赛,在其中我使用了情感分析模型,下面就给大家介绍一下。
情感分析模型是什么?
Introduction
情感分析(sentiment analysis)表面上是指利用计算机技术对文本、图像、音频、视频甚至跨模态的数据进行情绪挖掘与分析。但从广义上讲,情感分析还包括对观点、态度、倾向的分析等。情感分析主要涉及两个对象,即评价的对象(包括商品、服务、组织、个体、话题、问题、事件等)和对该对象的态度、情感等。情感分析在社会的舆情管理,商业决策,精准营销等领域有着广泛的应用。在股市预测、选举预测等场景中,情感分析有着举足轻重的作用。情感分析的诞生和发展主要源于社交媒体和网络,如论坛、博客、微博等。至2000年起情感分析便成为自然语言处理中活跃的领域之一。然而现实生活中,社交网络的情感分析仍存在较大的困难(主要原因之一为社交网络的数据存在大量无用的“垃圾”信息,这也是自然语言处理中大部分工作(如机器翻译等)应用于实际生活场景中很难取得较好效果的原因)。
情感分析的研究方法
情感分析的研究方法主要包括有监督和无监督两种方法。早期的有监督学习是指SVM、最大熵、朴素贝叶斯等这类浅层模型,而无监督学习则为基于词典、语义分析等方法。深度学习的出现使得其在许多分类、回归任务中均取得了最好的结果。近年来应用deep learning进行情感分析也成为了研究的热点。
情感分析的三个层面
情感分析主要分为三个层面,分别为:Document level、Sentence level和aspect level。其中Document level是将整个文档作为分析单元并假设该文档讨论的对象为单一实体且情感、观点都是鲜明、清晰的,即neural, positive or negative 。Sentence level则是以每个句子作为单独的分析对象,由于句子与句子间可能存在某些关联,因此我们不能将其认为是观点明确的。而对于aspect level其分类粒度更细,即我们需要抽取出targets不同层面相互独立的评价,并进行总结综合得到最后的情感。其将涉及ascept extraction, entity extraction以及aspect sentiment classification。例如,对于Deep Learning虽然结果可解释性差,但对于图像识别任务是非常有效的。其中Deep Learning即为entity,extraction identity则为“结果”和“图像识别”,对于“结果”为其情感为negative,“图像识别”为positive。
对于文档级别的情感分析其主要是一个二分类问题(positive or negative),我们当然也可将其转化为回归问题即对于文档的情感给出打分。期初对于该问题比较传统的解决方法是基于文档词袋模型,如计算word frequence或TF-IDF score。该方法带来的最直接的问题便是矩阵稀疏,而且该方法忽略了句子中词语的先后顺序。因此后来便引入了n-gram模型(n-gram模型通过对语料库中的词汇进行简单统计得到序列出现的概率,在过去的几十年中n-gram模型是NLP中的核心模块,最长使用的包括2元文法和3元文法等),改模型可以同时考虑多个词,一定程度上缓解了短文本的词语间的顺序问题,然而对于未登录词我们仍需进行平滑处理,而且该方法并没用考虑任何的语义信息。在此之后03年Benjio提出了词向量,通过将文章表示为稠密的向量而在神经网络中广泛使用(但是word embedding并不能解决一词多义问题,直到ELMO的出现才给出了一个优雅的解决方案)。
对于句子级别的情感分析,与文档类似我们也需要将其变化为句向量然后进行分类。所不同的是,由于句子长度较短因此我们可以结合句法依存树等进行处理,此外对于社交媒体文本数据,如Tweets,我们还可以对social relationships等信息进行考虑。在早期的研究中,结合句法树分析的模型占主导地位,后来神经网络成为主流。
对于aspect级别的情感分析,其有别于文档和句子,我们即需要考虑target的情感同时还要分析aspect的情感,而不同的上下文所包含的情感均会影响最终结果,因此在建模时必须同时考虑目标对象以及上下文间的情感关系,这也增加了任务的困难。在神经网络中我们一般将aspect level sentiment classfication分解为三个子任务:第一,上下文语境词的表示;第二,target的表示,可通过embedding解决;第三,识特定目标情感语境词的识别。

下面就给大家介绍一下我的模型。
数据展示
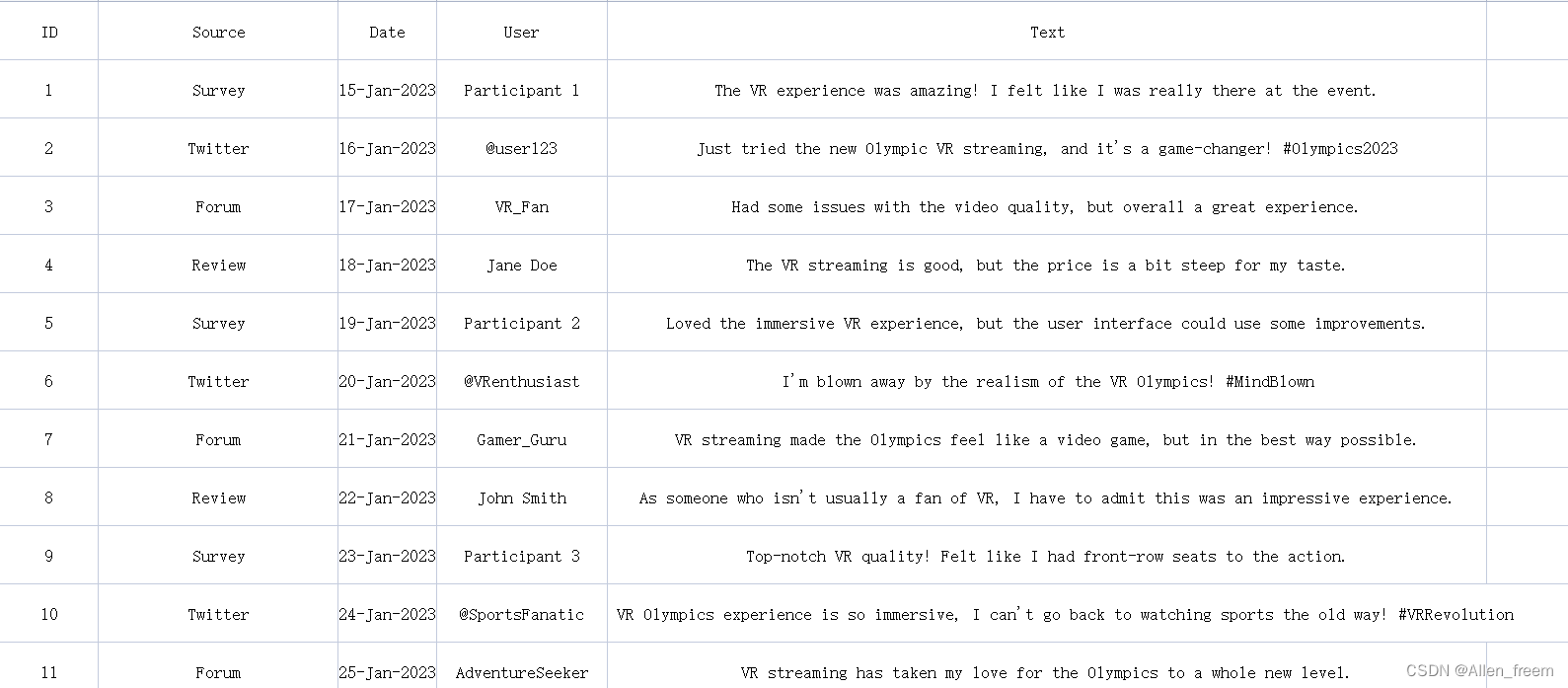
这是其中的部分数据。
我的代码:
- import pandas as pd
- import numpy as np
- import re
- from textblob import TextBlob
- import nltk
- from nltk.corpus import stopwords
- from nltk.stem import PorterStemmer
-
- # nltk.download('stopwords')
- # 读取数据
- data = pd.read_excel('C:/Users/HP/Desktop/PRO/User evaluation.xlsx')
-
- # 预处理文本数据
- def preprocess_text(text):
- text = re.sub('[^a-zA-Z]', ' ', text) # 去除特殊字符和数字
- text = text.lower() # 将文本转换为小写
- text = text.split() # 将文本拆分为单词
- text = [word for word in text if not word in set(stopwords.words('english'))] # 移除停用词
- stemmer = PorterStemmer()
- text = [stemmer.stem(word) for word in text] # 执行词干提取
- text = ' '.join(text) # 将单词重新组合为文本
- return text
-
- data['Processed_Text'] = data['Text'].apply(preprocess_text)
-
- # 执行情感分析
- def get_sentiment(text):
- analysis = TextBlob(text)
- return analysis.sentiment.polarity
-
- data['Sentiment_Score'] = data['Processed_Text'].apply(get_sentiment)
-
- # 计算整个数据集的平均情感得分
- average_sentiment_score = np.mean(data['Sentiment_Score'])
- print(f'Average Sentiment Score: {average_sentiment_score}')
-
- # 检查不同来源的情感得分分布
- sentiment_by_source = data.groupby('Source')['Sentiment_Score'].mean()
- print(sentiment_by_source)


