
- 1深入探索基于KCF跟踪器的DSST跟踪算法的Python实现_dsst算法 python实现
- 2Printf() 限定最小宽度_c语言printf输出最小宽度
- 3网络编程—TCP、UDP编程_tcp udp 编程
- 4我们能从主机游戏的UI设计里学到什么?_主机游戏设计规范
- 5UIView显示时遮挡导航栏的方法
- 6Hive映射Hbase表_hive建hbase映射表
- 7iOS 下载和播放 M3U8
- 8[Style Transfer]——Adversarial Stain Transfer for Histopathology Image Analysis
- 9QT:实现图片选择器
- 10three.js 设置Geometry顶点位置、顶点颜色数据_three.js中的new three.geometry();
斯坦福发布大模型Alpaca:A100上训3小时,性能比较GPT-3.5,被挤爆!
赞
踩

源|新智元
Meta的LLaMA模型开源,让文本大模型迎来了Stable Diffustion时刻。今天,斯坦福发布了一个由LLaMA 7B微调的模型Alpaca,训练3小时,性能比肩GPT-3.5。
一觉醒来,斯坦福大模型Alpaca(草泥马)火了。

没错,Alpaca是由Meta的LLaMA 7B微调而来的全新模型,仅用了52k数据,性能约等于GPT-3.5。
关键是训练成本奇低,不到600美元。具体花费如下:
在8个80GB A100上训练了3个小时,不到100美元;
生成数据使用OpenAI的API,500美元。

斯坦福大学计算机科学副教授Percy Liang称,
由于缺乏透明度/无法完全访问像GPT 3.5这样的有能力的指令模型,进而限制了这一重要领域的学术研究。我们在 Alpaca (LLaMA 7B + text-davinci-003)上迈出了一小步。

看到又有人在自家大模型上取得了新的成果,Yann LeCun疯狂转发(宣传要到位)。
3小时微调70亿参数,600美元搞定
话不多说,先试用一波。
问:告诉我一些关于羊驼的事情。
答:羊驼是来自南美洲的骆驼品种,与美洲驼和骆驼有关。它们通常因其纤维而被饲养,用于制造奢侈品,如毛衣和毛毯。由于羊驼的温柔和友好的天性,它们也是很受欢迎的宠物。

体验链接:
https://crfm.stanford.edu/alpaca/

对于斯坦福的团队来说,想要在预算内训练一个高质量的指令遵循模型,就必须面临2个重要的挑战:要有一个强大的预训练语言模型,以及一个高质量的指令遵循数据。
恰恰,提供给学术研究人员使用的LLaMA模型搞定了第一个问题。
对于第二个挑战,「Self-Instruct: Aligning Language Model with Self Generated Instructions」论文给了很好的启发,即使用现有的强语言模型来自动生成指令数据。
然而,LLaMA模型最大的弱点是缺乏指令微调。OpenAI最大的创新之一就是将指令调优用在了GPT-3上。
对此,斯坦福使用了现有的大语言模型,来自动生成遵循指令演示。

首先从自生成指令种子集中的175个人工编写的「指令-输出」对开始,然后,提示text-davinci-003使用种子集作为上下文示例来生成更多指令。
通过简化生成管道改进了自生成指令的方法,这样大大降低了成本。在数据生成过程中,产生了52K个独特指令和相应的输出,使用OpenAI API的成本不到500美元。
有了这个指令遵循的数据集,研究人员利用Hugging Face的训练框架对LLaMA模型进行微调,利用了完全分片数据并行(FSDP)和混合精度训练等技术。

另外,微调一个7B的LLaMA模型在8个80GB的A100上花了3个多小时,在大多数云计算供应商那里的成本不到100美元。
约等于GPT-3.5
为了评估Alpaca,斯坦福研究人员对自生成指令评价集的输入进行了人工评估(由5位学生作者进行)。
这个评价集是由自生成指令作者收集的,涵盖了多样化的面向用户的指令,包括电子邮件写作、社交媒体和生产力工具等。
他们对GPT-3.5(text-davinci-003)和Alpaca 7B进行了比较,发现这两个模型的性能非常相似。Alpaca在与GPT-3.5的比较中,获胜次数为90对89。
鉴于模型规模较小,且指令数据量不大,取得这个结果已经是相当惊人了。
除了利用这个静态评估集,他们还对Alpaca模型进行了交互式测试,发现Alpaca在各种输入上的表现往往与GPT-3.5相似。
斯坦福用Alpaca进行的演示:
演示一让Alpaca来谈谈自己和LLaMA的区别。

演示二让Alpaca写了一封邮件,内容简洁明了,格式也很标准。
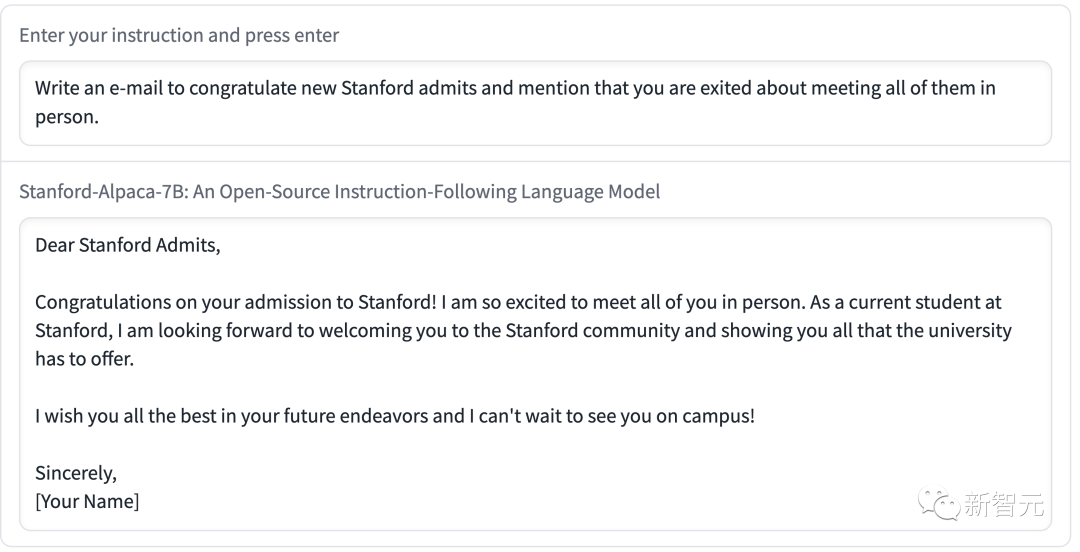
上述例子可以看出,Alpaca的输出结果一般都写得不错,而且答案通常比ChatGPT简短,体现了GPT-3.5较短输出的风格。
当然了,Alpaca表现出语言模型常见的缺陷。
比如,将坦桑尼亚的首都说成了达累斯萨拉姆。实则,1974年之后,多多马是坦桑尼亚的新首都了,达累斯萨拉姆只是坦桑尼亚最大的城市。
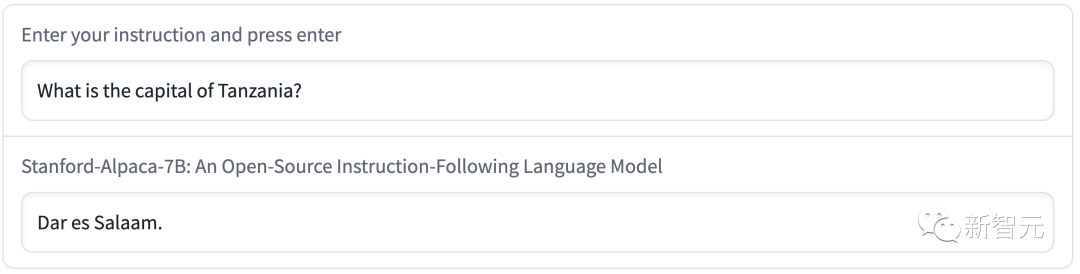
撰写周详的论文摘要时,Alpaca传播了错误的信息。

另外,Alpaca可能还存在许多与底层语言模型和指令微调数据相关的局限。然而,Alpaca为我们提供了一个相对轻量级的模型,它可以成为未来研究大模型重要缺陷的基础。
目前,斯坦福仅公布了Alpaca的训练方法和数据,并打算在未来发布模型的权重。
但是,Alpaca是不能用于商业用途,只能用于学术研究。具体原因有三:
LLaMA是一个非商业许可的模型,Alpaca是基于该模型生成的;
指令数据是基于OpenAI的text-davinci-003,其使用条款禁止开发与OpenAI竞争的模型;
没有设计足够多的安全措施,所以Alpaca还没有做好广泛使用的准备
除此之外,斯坦福研究人员总结了Alpaca未来研究会有三个方向。
评估:
从HELM(语言模型的整体评估)开始捕捉更多的生成性、遵循指令的场景。
安全:
进一步研究Alpaca的风险,并使用自动红队分组、审计和适应性测试等方法提高其安全性。
理解:
希望能更好地理解模型能力是如何从训练方法中产生的。需要基础模型的什么属性?扩大模型规模时会发生什么?需要指令数据的什么属性?在GPT-3.5上,除了使用自生成指令,还有什么替代方法?
大模型的Stable Diffusion
现在,斯坦福「羊驼」直接被网友奉为「文本大模型的Stable Diffusion」。
Meta的LLaMA模型可以免费给研究人员使用(当然需要申请后)简直利好AI圈友们。
自ChatGPT横空出世以来,让许多人对AI模型的内置限制感到沮丧。这些限制阻止ChatGPT讨论OpenAI认为敏感的话题。

因此,AI社区便希望能够有一个开源大语言模型(LLM),任何人都可以在本地运行而无需审查,也无需向OpenAI支付API费用。
要说这样开源大模型现在也有,比如GPT-J,但美中不足的是需要大量的GPU内存和存储空间。
另一方面,其他开源平替版无法在现成的消费级硬件上拥有GPT-3级别的性能。
2月底,Meta推出了最新的语言模型LLaMA,参数量分别是70亿(7B)、130亿(13B)、330亿(33B)和650亿(65B)。评测结果显示,其13B版本便可以与GPT-3相媲美。

论文地址:
https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
虽然Meta向通过申请的研究人员开放源代码,但没想到网友最先在GitHub上泄漏了LLaMA的权重。
自此,围绕LLaMA语言模型的发展呈爆炸式增长。
通常,运行GPT-3需要多个数据中心级A100 GPU,再加上GPT-3的权重不是公开的。
网友纷纷自己「操刀」运行LLaMA模型一时引起了轰动。
通过量化技术对模型大小进行优化,LLaMA现在可以在M1 Mac、较小Nvidia消费者GPU、Pixel 6手机、甚至是树莓派上运行。
网友总结了,从LLaMA的发布到现在,大家利用LLaMA做出的一些成果:
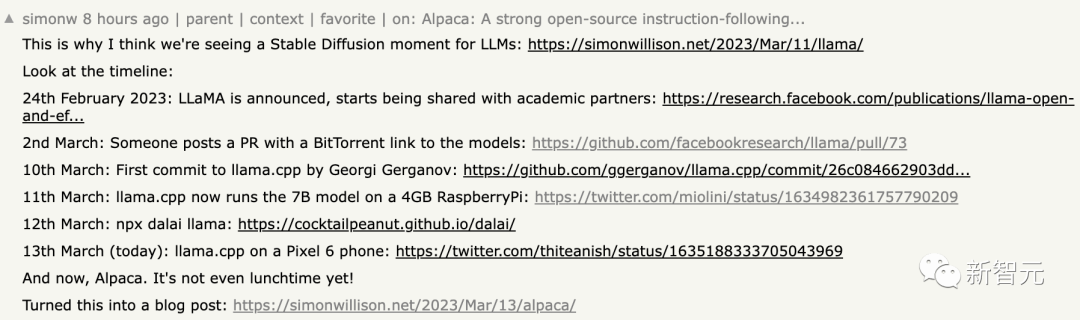
2月24日,LLaMA发布,并在非商业许可下提供给政府、社区和学术界的研究人员和实体工作者;
3月2日,4chan网友泄露了全部的LLaMA模型;
3月10日,Georgi Gerganov创建了llama.cpp工具,可以在搭载M1/M2芯片的Mac上运行LLaMA;
3月11日:通过llama.cpp可以在4GB RaspberryPi上运行7B模型,但速度比较慢,只有10秒/token;
3月12日:LLaMA 7B在一个node.js执行工具NPX上成功运行;
3月13日:llama.cpp可以在Pixel 6手机上运行;
而现在,斯坦福Alpaca「羊驼」发布。
One More Thing
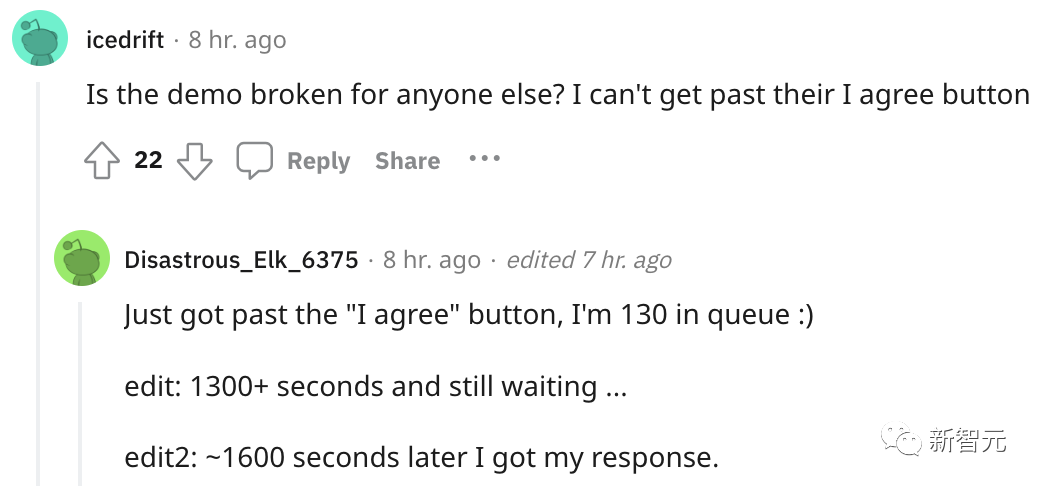
项目没放出多久,Alpaca火爆到直接不能用了....
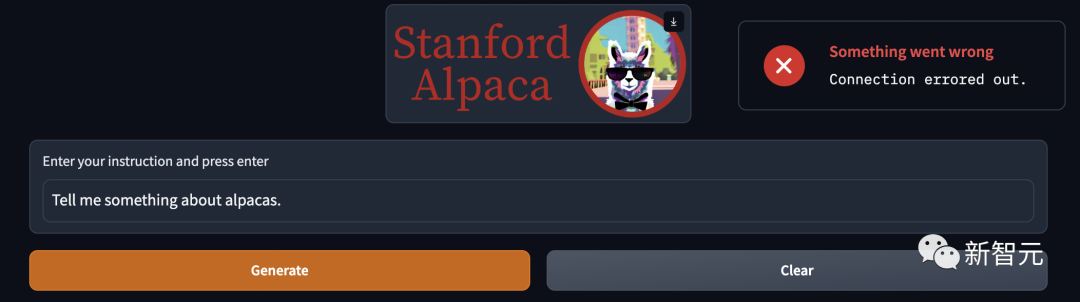
许多网友吵吵,点「生成」没反应,还有的在排队等玩儿。
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
[1]https://simonwillison.net/2023/Mar/13/alpaca/
[2]https://crfm.stanford.edu/2023/03/13/alpaca.html


