
- 1【数据结构】归并排序 的递归实现与非递归实现_归并排序递归
- 2Semantic-NeRF: Semantic Neural Radiance Fields(Semantic-NeRF:语义神经辐射场)_语义nerf
- 3Linux平台上直接运行Android应用,android开发入门与实战体验_linux怎么用app软件
- 4大数据分析与机器学习:改变传统行业的方式
- 5java字符串忽略大小写_Java 8忽略大小写排序字符串
- 6Neo4j入门_neo4j 4.x版本
- 7Mysql中去重的语法_mysql之简单查询(小白入门必备)
- 8SpringBoot校园二手书管理系统_二手书springboot
- 9区块链详细应用举例(一)_区块链 应用 案例 ppt
- 10 推荐一款高效智能的校园考勤系统:Sistem Absensi Sekolah Berbasis QR Code
《十堂课学习 Flink》第九章:Flink Stream 的实战案例一:CPU 平均使用率监控告警案例_flink内存cpu任务监控告警
赞
踩
9.1 本章概述
本章的所有需求、设计、开发仅是模拟真实业务场景,因为实际业务需求、现场环境更加复杂,并且考虑到本系列课程本身就偏向于基础内容,因此这里我们对自己假设的业务场景进行设计与开发,整个流程虽然简单,但涉及到的内容较多,通过这个案例可以初步了解整个flink流计算开发案例的基本过程。
效果演示
运行不同案例查看kafka通讯以及风险触发过程
9.2 需求描述
这个案例中,我们假设,需要对 多个机器集群 进行监控,即定期采样这 若干个集群 中的每台机器的CPU使用率,并将采样结果写入 kafka 。我们的任务是开发一个 flink 项目,监听 kafka 作为输入数据,并且满足 特定条件 时进行告警。
9.2.1 通讯流程
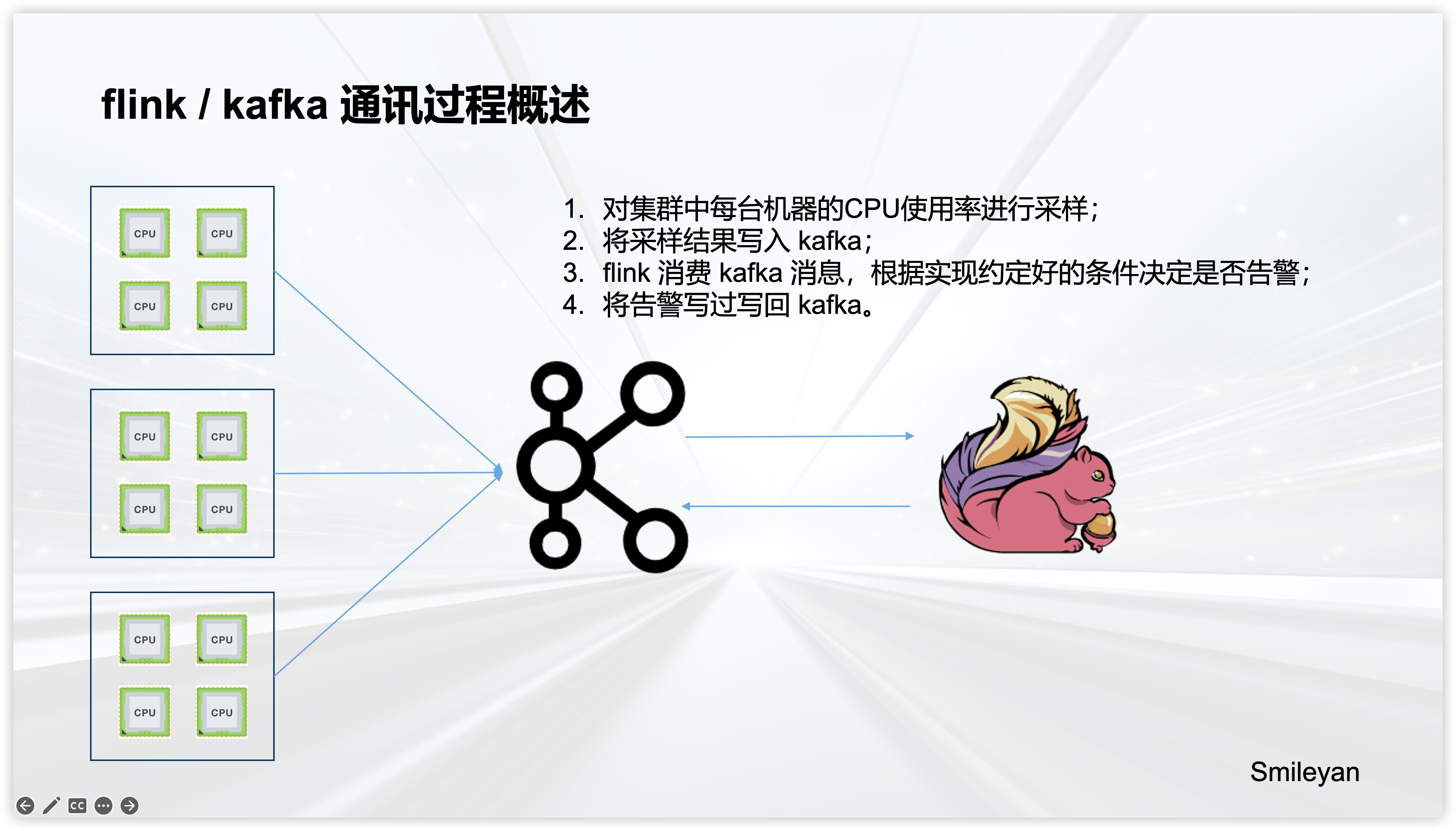

9.2.2 通讯协议 —— 采样数据
我们需要与负责采样的上游约定通讯协议,按照指定的 json 格式进行通讯。上游按照指定的格式将样本数据写入 kafka 后,flink 根据kafka消息进行聚合、触发检测、返回告警结果等。
{
"taskId": "39xr4d2dnb9x72d",
"clusterId": "49xrt",
"itemId": "38fx2d",
"clusterSize": 4,
"currentIndex": 0,
"data": {
"timestamp": 1715003462,
"value": 0.43
},
"thresholdConfig": {
"cpuUsageThresholdAverage": 0.93,
"cpuUsageThresholdMax": 0.99
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
其中,
taskId是每个集群检测任务的唯一标识,同一个集群中的不同机器具有相同taskId,同一个集群中同一台机器在不同时间的采样结果对应的样本编号均不同。在排查问题时可以根据这个定位到哪条消息有问题等。clusterId是指集群编号,同一个集群中的不同机器具有相同的集群编号,集群编号不因为采样时间而改变。itemId:集群中某机器的唯一标识;clusterSize:集群大小,即集群中含有多少台机器。currentIndex:当前消息在集群中的索引,从0开始。比如一个集群中共 4 台机器,索引分别为 0, 1, 2, 3。由于 kafka 集群、flink 集群等环境原因,接收到 kafka 的消息可能不会严格按照索引从小到大的顺序。data:采样实体类,即某个时刻采样得到CPU使用率的值timestamp: 采样时的时间戳(10位,精度为秒)value:采样的值,即CPU使用率。
thresholdConfig:检查时的触发风险阈值,因为不同的业务场景下不同集群可能导致 CPU 使用率情况不同,所以应该对不同集群有相应的触发配置。cpuUsageThresholdAverage:集群中平均CPU使用率阈值;cpuUsageThresholdMax:集群中单个CPU使用率阈值。
9.2.3 通讯协议 —— 结果数据
经过检测以后,算法返回对集群的检查结果,检查规则我们在后面介绍。这里只定义大致的检查结果实体结构:
{
"taskId": "xejcfl34w23mfs"
"clusterId": "49xrt",
"results": {
"code": 0,
"message": "success",
"data": {
"riskType": 0,
"timestamp": 1715003462,
"riskItems": []
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
其中,
taskId:任务唯一编号,与接收到任务编号保持一致。clusterId:集群编号。results:结果实体类code:结果通讯码,成功为 0 ,样本数据缺失为1,执行过程未知异常为 -1。message:结果消息说明。data:结果实体类riskType:结果类型;timestamp:检查数据的采样时间;riskItems:有风险的机器编号链表,即输入数据中的itemId。
9.2.4 风险检查规则
对 CPU集群 进行检测,检测规则包括
-
- 不满足以下条件,无风险
-
- 集群中 CPU 采样数据是否存在缺失,比如 CPU 1 采集到了,CPU 2 采集不到
-
- 集群中 CPU 平均使用率是否超过阈值(阈值在接收数据中配置)
-
- 集群中单个CPU使用率是否超过阈值(阈值在接收数据中配置)
9.3 开发过程设计
首先这里引入相关依赖如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.smileyan.demos</groupId> <artifactId>flink-cpu-demo</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <scala.binary.version>2.12</scala.binary.version> <lombok.version>1.18.30</lombok.version> <flink.version>1.14.6</flink.version> <slf4j.version>2.0.9</slf4j.version> <logback.version>1.3.14</logback.version> </properties> <dependencies> <!-- flink 相关 --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>com.alibaba.fastjson2</groupId> <artifactId>fastjson2</artifactId> <version>2.0.45</version> </dependency> <!-- 编译工具 --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>${lombok.version}</version> <scope>provided</scope> </dependency> <!-- log 相关 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>${slf4j.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-core</artifactId> <version>${logback.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>${logback.version}</version> <scope>provided</scope> </dependency> </dependencies> <build> <plugins> <!-- Java Compiler --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.1</version> <configuration> <source>${maven.compiler.source}</source> <target>${maven.compiler.target}</target> </configuration> </plugin> <!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. --> <!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.1.1</version> <executions> <!-- Run shade goal on package phase --> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <artifactSet> <excludes> <exclude>org.apache.flink:flink-shaded-force-shading</exclude> <exclude>com.google.code.findbugs:jsr305</exclude> <exclude>org.slf4j:*</exclude> <exclude>org.apache.logging.log4j:*</exclude> <exclude>ch.qos.logback:*</exclude> </excludes> </artifactSet> <filters> <filter> <!-- Do not copy the signatures in the META-INF folder. Otherwise, this might cause SecurityExceptions when using the JAR. --> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> <exclude>logback.xml</exclude> </excludes> </filter> </filters> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
9.3.1 main 方法入口
这里是总体流程,我们大概可以分为3个过程:
- 初始化kafka连接(包括source与sink对象)。
- 编写收集kafka数据以及窗口化过程,前面需求中有提到我们检测的是集群中各机器的CPU使用率情况。因此可能接收同个集群中的多条消息,需要进行窗口化聚合,进而进行检测。
- 检测过程,根据实际数据表现对风险等级进行评分。
- 返回风险结果到 kafka 中。
package cn.smileyan.demos; import cn.smileyan.demos.core.CpuCheckMapFunction; import cn.smileyan.demos.core.TaskProcessingFunction; import cn.smileyan.demos.entity.TaskClusterData; import cn.smileyan.demos.entity.TaskInput; import cn.smileyan.demos.entity.TaskOutput; import cn.smileyan.demos.core.CountAndTimeTrigger; import cn.smileyan.demos.io.KafkaArgsBuilder; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.connector.kafka.sink.KafkaSink; import org.apache.flink.connector.kafka.source.KafkaSource; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.DynamicEventTimeSessionWindows; import org.apache.flink.streaming.api.windowing.assigners.SessionWindowTimeGapExtractor; import java.util.Objects; /** * flink 任务入口 * @author smileyan */ public class CpuCheckJob { /** * 参数解释: * -bs broker 地址 localhost:9092 * -kcg kafka consumer group * -it kafka 输入数据 topic test-input-topic * -ot kafka 输出数据 topic test-output-topic * -ct 可选,是否自动创建 topic,使用方法 添加 -ct 即可,无需指定其值 * -pt topic 可选,分区数 1 * -rf topic 可选,副本数 1 * example: * -bs localhost:9092 -it test-input-topic -ot test-output-topic -pt 1 -rf 1 -ct */ public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); final KafkaArgsBuilder kafkaArgsBuilder = new KafkaArgsBuilder(args); final KafkaSource<TaskInput> source = kafkaArgsBuilder.buildSource(TaskInput.class); final KafkaSink<TaskOutput> kafkaSink = kafkaArgsBuilder.buildSink(TaskOutput.class); final long gapSeconds = 10L; final DynamicEventTimeSessionWindows<TaskInput> dynamicWindow = DynamicEventTimeSessionWindows.withDynamicGap( (SessionWindowTimeGapExtractor<TaskInput>) element -> gapSeconds * element.getClusterSize()); final DataStreamSource<TaskInput> dataStreamSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source"); SingleOutputStreamOperator<TaskClusterData> mergedTaskData = dataStreamSource .filter(Objects::nonNull) .keyBy(TaskInput::getTaskId) .window(dynamicWindow) .trigger(new CountAndTimeTrigger<>()) .process(new TaskProcessingFunction()) .name("taskProcessing"); SingleOutputStreamOperator<TaskOutput> resultData = mergedTaskData.filter(Objects::nonNull) .map(new CpuCheckMapFunction()) .name("cpu usage check"); resultData.sinkTo(kafkaSink); env.execute("Flink Kafka Example"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
9.3.2 编写 kafka 序列化与反序列化类
package cn.smileyan.demos.io; import com.alibaba.fastjson2.JSON; import lombok.extern.slf4j.Slf4j; import org.apache.flink.api.common.serialization.DeserializationSchema; import org.apache.flink.api.common.serialization.SerializationSchema; import org.apache.flink.api.common.typeinfo.TypeInformation; import java.nio.charset.StandardCharsets; /** * 将字节码数据进行序列化,以及将实体类转换 * @author smileyan * @param <O> 实体类 */ @Slf4j public class CommonEntitySchema<O> implements DeserializationSchema<O>, SerializationSchema<O> { private final Class<O> clazz; public CommonEntitySchema(Class<O> clazz) { this.clazz = clazz; } @Override public O deserialize(byte[] message) { try { String str = new String(message, StandardCharsets.UTF_8); log.info("kafka received message: {}", str); return JSON.parseObject(str, clazz); } catch (Exception e) { log.error(e.getMessage()); } return null; } @Override public boolean isEndOfStream(O nextElement) { return false; } @Override public TypeInformation<O> getProducedType() { return TypeInformation.of(clazz); } @Override public byte[] serialize(O element) { return JSON.toJSONBytes(element); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
9.3.3 编写 kafka 的 source 与 sink 构建器
package cn.smileyan.demos.io; import lombok.extern.slf4j.Slf4j; import org.apache.flink.api.java.utils.MultipleParameterTool; import org.apache.flink.connector.base.DeliveryGuarantee; import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema; import org.apache.flink.connector.kafka.sink.KafkaSink; import org.apache.flink.connector.kafka.source.KafkaSource; import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer; import org.apache.kafka.clients.admin.AdminClient; import org.apache.kafka.clients.admin.AdminClientConfig; import org.apache.kafka.clients.admin.NewTopic; import java.util.Collections; import java.util.Properties; import java.util.concurrent.ExecutionException; /** * 通过参数构建通用的 kafka 通讯序列化与反序列化实体 * @author smileyan */ @Slf4j public class KafkaArgsBuilder { /** * 构建参数 */ private final MultipleParameterTool parameterTool; public KafkaArgsBuilder(String[] args) { parameterTool = MultipleParameterTool.fromArgs(args); } /** * 构建kafka sink * @param clazz 实体类class * @param <E> 实体类泛型 * @return kafka sink 对象 */ public <E> KafkaSink<E> buildSink(Class<E> clazz) { final String bs = parameterTool.getRequired(KafkaArgs.BOOTSTRAP_SERVER.key); final String ot = parameterTool.getRequired(KafkaArgs.OUTPUT_TOPIC.key); return KafkaSink.<E>builder() .setBootstrapServers(bs) .setRecordSerializer(KafkaRecordSerializationSchema.builder() .setTopic(ot) .setValueSerializationSchema(new CommonEntitySchema<>(clazz)) .build()) .setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE) .build(); } /** * 构建kafka source * @param clazz 实体类class * @param <E> 实体类泛型 * @return kafka source 对象 */ public <E> KafkaSource<E> buildSource(Class<E> clazz) throws ExecutionException, InterruptedException { final String kafkaConsumerGroup = parameterTool.getRequired(KafkaArgs.KAFKA_CONSUMER_GROUP.key); final String bootstrapServer = parameterTool.getRequired(KafkaArgs.BOOTSTRAP_SERVER.key); final String inputTopic = parameterTool.getRequired(KafkaArgs.INPUT_TOPIC.key); final boolean createTopic = parameterTool.has(KafkaArgs.CREATE_TOPIC.key); if (createTopic) { final int partition = parameterTool.getInt(KafkaArgs.CREATE_TOPIC_PARTITION.key, 1); final short replicationFactor = parameterTool.getShort(KafkaArgs.REPLICATION_FACTOR.key, (short) 1); createTopic(bootstrapServer, inputTopic, partition, replicationFactor); } return KafkaSource.<E>builder() .setGroupId(kafkaConsumerGroup) .setStartingOffsets(OffsetsInitializer.latest()) .setBootstrapServers(bootstrapServer) .setTopics(inputTopic) .setValueOnlyDeserializer(new CommonEntitySchema<>(clazz)) .build(); } public enum KafkaArgs { /* * kafka 服务地址 */ BOOTSTRAP_SERVER("bs"), /* * kafka 消费者组 */ KAFKA_CONSUMER_GROUP("kcg"), /* * kafka 输入主题 */ INPUT_TOPIC("it"), /* * kafka 输出主题 */ OUTPUT_TOPIC("ot"), /* * 是否自动创建主题 */ CREATE_TOPIC("ct"), /* * 分区数 */ CREATE_TOPIC_PARTITION("pt"), /* * 副本数 */ REPLICATION_FACTOR("rf"); private final String key; KafkaArgs(String key) { this.key = key; } } /** * 如果 TOPIC 不存在则创建该 TOPIC * @param bootstrapServer kafka broker 地址 * @param topic 想要创建的 TOPIC * @param partitions 并行度 * @param replicationFactor 副本数 */ public static void createTopic(String bootstrapServer, String topic, int partitions, int replicationFactor) throws ExecutionException, InterruptedException { Properties adminProperties = new Properties(); adminProperties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServer); try (AdminClient adminClient = AdminClient.create(adminProperties)) { if (!adminClient.listTopics().names().get().contains(topic)) { NewTopic newTopic = new NewTopic(topic, partitions, (short) replicationFactor); adminClient.createTopics(Collections.singletonList(newTopic)).all().get(); log.info("created topic: {}", topic); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
9.3.4 自定义 window 触发器
这里我们不使用默认的触发器,而是自定义一个更加方便的触发器。当接收到相同 taskId 的数据时,我们需要确定,什么时候确定接收完成,并触发检测过程。
需要注意的地方包括:
- 消息接收完成就触发。比如一个集群中总共有4台机器,当接收到这个4台机器的样本数据时,就应该触发检测过程。
- 消息接收到一半突然终止。比如一个集群中总共有4台机器,接收到3台机器的采样数据以后,等了很久没有收到第四条消息。等待超时后触发检查。
package cn.smileyan.demos.core; import cn.smileyan.demos.entity.TaskInput; import lombok.extern.slf4j.Slf4j; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.api.common.state.ReducingState; import org.apache.flink.api.common.state.ReducingStateDescriptor; import org.apache.flink.api.common.typeutils.base.LongSerializer; import org.apache.flink.streaming.api.windowing.triggers.Trigger; import org.apache.flink.streaming.api.windowing.triggers.TriggerResult; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; /** * 自定义 window 触发器 * @author smileyan */ @Slf4j public class CountAndTimeTrigger<T extends TaskInput, W extends TimeWindow> extends Trigger<T, W> { /** * ReducingStateDescriptor 的 key 字段,上下文根据这个字段获取状态指 */ private static final String COUNT_KEY = "count"; /** * ReducingStateDescriptor 根据聚合过程更新 count 结果 */ private final ReducingStateDescriptor<Long> stateDesc = new ReducingStateDescriptor<>(COUNT_KEY, new Sum(), LongSerializer.INSTANCE); @Override public TriggerResult onElement(T element, long timestamp, W window, TriggerContext ctx) throws Exception { ctx.registerEventTimeTimer(window.getEnd()); ctx.registerProcessingTimeTimer(window.getEnd()); final int size = element.getClusterSize(); final String id = element.getTaskId(); ReducingState<Long> count = ctx.getPartitionedState(stateDesc); count.add(1L); log.info("[{}] window: ({}, {}) -> merged {}", ctx.getCurrentWatermark(), window.getStart(), window.getEnd(), count.get()); if (count.get().intValue() == size) { log.info("[{} -> {}] merged successfully.", id, ctx.getCurrentWatermark()); clear(window, ctx); ctx.getPartitionedState(stateDesc).clear(); return TriggerResult.FIRE_AND_PURGE; } else if (count.get() > size) { log.warn("[{} -> {}] sent more than need {}", id, ctx.getCurrentWatermark(), size); return TriggerResult.PURGE; } return TriggerResult.CONTINUE; } @Override public TriggerResult onProcessingTime(long time, W window, TriggerContext ctx) throws Exception { if (time >= window.getEnd()) { log.debug("[ -> {}] onProcessingTime", ctx.getCurrentWatermark()); return TriggerResult.FIRE_AND_PURGE; } return TriggerResult.CONTINUE; } @Override public TriggerResult onEventTime(long time, W window, TriggerContext ctx) throws Exception { if (time >= window.getEnd()) { log.debug("[ -> {}] onEventTime", ctx.getCurrentWatermark()); return TriggerResult.FIRE_AND_PURGE; } return TriggerResult.CONTINUE; } @Override public void clear(W window, TriggerContext ctx) throws Exception { log.debug("[ -> {}] cleaning window ({}, {})", ctx.getCurrentWatermark(), window.getStart(), window.getEnd()); ctx.deleteEventTimeTimer(window.getEnd()); ctx.deleteProcessingTimeTimer(window.getEnd()); } @Override public boolean canMerge() { return true; } @Override public void onMerge(TimeWindow window, OnMergeContext ctx) throws Exception { log.debug("[ -> {}] onMerge ({}, {})", ctx.getCurrentWatermark(), window.getStart(), window.getEnd()); ctx.mergePartitionedState(stateDesc); } private static class Sum implements ReduceFunction<Long> { private static final long serialVersionUID = 1L; @Override public Long reduce(Long value1, Long value2) throws Exception { return value1 + value2; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
此处有两个地方需要额外强调:
- 必须重写 canMerge 与 onMerge 方法。
- 必须使用ReducingStateDescriptor状态描述器而不是对象的属性。这里牵扯到 flink 的特性,比如4条消息每到来一次,对应的应该是再次创建
CountAndTimeTrigger对象进行trigger检查,并根据检查结果决定是否触发风险。
9.3.5 将集群中每台机器的采样结果进行合并
package cn.smileyan.demos.core; import cn.smileyan.demos.entity.CpuDataItem; import cn.smileyan.demos.entity.TaskClusterData; import cn.smileyan.demos.entity.TaskInput; import cn.smileyan.demos.entity.ThresholdConfig; import lombok.extern.slf4j.Slf4j; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import java.util.Iterator; import java.util.LinkedList; import java.util.List; /** * 合并任务数据为集群数据 * @author smileyan */ @Slf4j public class TaskProcessingFunction extends ProcessWindowFunction<TaskInput, TaskClusterData, String, TimeWindow> { @Override public void process(String key, ProcessWindowFunction<TaskInput, TaskClusterData, String, TimeWindow>.Context context, Iterable<TaskInput> elements, Collector<TaskClusterData> out) throws Exception { log.info("[{}] starting merge processing", key); final List<CpuDataItem> cpuDataItems = new LinkedList<>(); Iterator<TaskInput> inputIterator = elements.iterator(); TaskInput first = inputIterator.next(); cpuDataItems.add(new CpuDataItem(first)); String clusterId = first.getClusterId(); String taskId = first.getTaskId(); Integer clusterSize = first.getClusterSize(); ThresholdConfig thresholdConfig = first.getThresholdConfig(); while(inputIterator.hasNext()) { cpuDataItems.add(new CpuDataItem(inputIterator.next())); } log.info("[{}] finished merge processing", key); out.collect(new TaskClusterData(taskId, clusterId, clusterSize, thresholdConfig, cpuDataItems)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
9.3.6 最核心的风险检查过程
package cn.smileyan.demos.core; import cn.smileyan.demos.entity.CpuDataItem; import cn.smileyan.demos.entity.TaskClusterData; import cn.smileyan.demos.entity.TaskOutput; import cn.smileyan.demos.entity.TaskResult; import cn.smileyan.demos.entity.TaskResultData; import org.apache.flink.api.common.functions.MapFunction; import java.util.LinkedList; import java.util.List; import java.util.OptionalDouble; import java.util.stream.Collectors; /** * 对 CPU集群 进行检测,检测规则包括 * 0. 不满足以下条件,无风险 * 1. 集群中 CPU 采样数据是否存在缺失,比如 CPU 1 采集到了,CPU 2 采集不到 * 2. 集群中 CPU 平均使用率是否超过阈值(阈值在接收数据中配置) * 3. 集群中单个CPU使用率是否超过阈值(阈值在接收数据中配置) * @author smileyan */ public class CpuCheckMapFunction implements MapFunction<TaskClusterData, TaskOutput> { @Override public TaskOutput map(TaskClusterData taskClusterData) { TaskOutput taskOutput = new TaskOutput(); taskOutput.setTaskId(taskClusterData.getTaskId()); taskOutput.setClusterId(taskClusterData.getClusterId()); TaskResult taskResult = new TaskResult(); taskOutput.setResults(taskResult); TaskResultData taskResultData = new TaskResultData(); taskResultData.setTimestamp(taskClusterData.getCpuDataItems().get(0).getTimestamp()); List<String> items = taskClusterData.getCpuDataItems().stream().map(CpuDataItem::getItemId).collect(Collectors.toList()); /* * 1. 集群中 CPU 采样数据是否存在缺失,比如 CPU 1 采集到了,CPU 2 采集不到 */ if (taskClusterData.getClusterSize() != taskClusterData.getCpuDataItems().size()) { taskResult.setCode(ResultCodeEnum.MISSING.getCode()); taskResult.setMessage(ResultCodeEnum.MISSING.getMessage()); return taskOutput; } taskResult.setCode(ResultCodeEnum.SUCCESS.getCode()); taskResult.setMessage(ResultCodeEnum.SUCCESS.getMessage()); taskResultData.setRiskType(RiskTypeEnum.NONE.getValue()); /* * 2. 集群中 CPU 平均使用率是否超过阈值(阈值在接收数据中配置) */ OptionalDouble average = taskClusterData.getCpuDataItems().stream().mapToDouble(CpuDataItem::getValue).average(); if (average.isPresent()) { if (average.getAsDouble() > taskClusterData.getThresholdConfig().getCpuUsageThresholdAverage()) { taskResultData.setRiskItems(items); taskResultData.setRiskType(RiskTypeEnum.CPU_USAGE_AVERAGE.getValue()); return taskOutput; } } else { taskResult.setCode(ResultCodeEnum.UNKNOWN_ERROR.getCode()); taskResult.setMessage(ResultCodeEnum.UNKNOWN_ERROR.getMessage()); return taskOutput; } // 3. 集群中单个CPU使用率是否超过阈值(阈值在接收数据中配置) List<String> riskItems = new LinkedList<>(); for (CpuDataItem cpuDataItem : taskClusterData.getCpuDataItems()) { if (cpuDataItem.getValue() > taskClusterData.getThresholdConfig().getCpuUsageThresholdMax()) { riskItems.add(cpuDataItem.getItemId()); } } if (!riskItems.isEmpty()) { taskResultData.setRiskItems(riskItems); taskResultData.setRiskType(RiskTypeEnum.CPU_USAGE_MAX.getValue()); return taskOutput; } return taskOutput; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
9.3.7 其他部分代码未展示
由于篇幅问题,这里省略了一部分不那么重要的代码,具体内容请参考 https://gitee.com/smile-yan/flink-cpu-demo
9.4 编写测试
9.4.1 测试数据准备
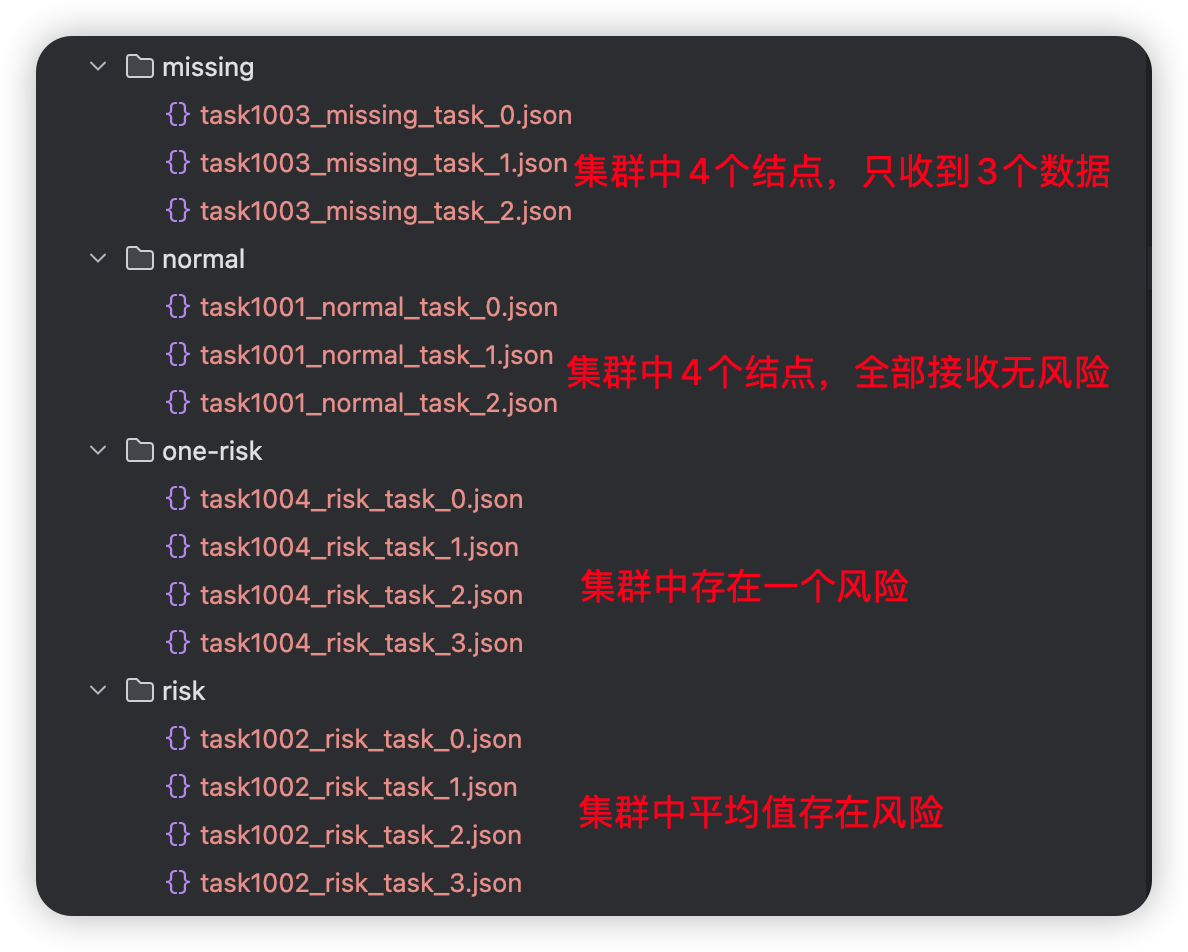
我们准备了一些测试数据,主要包括以下几种情况:
- 数据 size 不够聚合,比如期望达到 4 条消息时,才进行合并并检测;
- 数据 size 足够聚合,并且数据正常;
- 数据 size 足够聚合,但存在个别数据有风险;
- 数据 size 足够聚合,所有数据都存在风险。
具体内容请参考我的开源地址:https://gitee.com/smile-yan/flink-cpu-demo
9.4.2 测试脚本准备
我们需要将前面准备的 json 数据按照顺序写入 kafka ,以触发数据的聚合以及检测。
这里我们准备了一份python 脚本,将 json 文件写入 kafka 中。
import os import sys from kafka import KafkaProducer import json if __name__ == '__main__': kafka_broker, kafka_topic = sys.argv[1], sys.argv[2] files_dir = sys.argv[3] producer = KafkaProducer(bootstrap_servers=kafka_broker, value_serializer=lambda v: json.dumps(v).encode('utf-8')) files = os.listdir(files_dir) for file in files: if file.endswith(".json"): with open(f'{files_dir}/{file}', 'r') as f: data = json.load(f) producer.send(kafka_topic, data) producer.flush() producer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
注意,这里我们考虑到不同用户的存放数据的位置不同、绝对路径不同,将存放数据的路径、kafka 的相关参数以参数的形式存放在 main 方法的参数中,其中:
- 参数 1:kafka 的服务地址,比如 localhost:9092
- 参数 2:kafka 的通讯 topic,也就是 flink 任务监听的 topic。比如 input-test-data
- 参数 3:json 文件所在文件夹,前面有提到四个场景中存放在四个文件夹中。比如
/Users/smileyan/me/flink-cpu-demo/scripts/normal。
9.4.3 运行 flink 任务
运行时需要注意启动参数:
-bs
localhost:9092
-kcg
flink-consumer
-it
test-input-topic
-ot
test-output-topic
-ct
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
运行时还需要添加
9.5 运行效果展示
9.5.1 启动 kafka 过程
这个过程不再重复介绍,本地启动 kafka 两行命令即可。
$ bin/zookeeper-server-start.sh config/zookeeper.properties
- 1
$ bin/kafka-server-start.sh config/server.properties
- 1
9.5.2 运行 flink 与 kafka 过程录屏
flink-kafka检测CPU使用率风险检查案例
运行不同案例查看kafka通讯以及风险触发过程
这里案例中,我们通过脚本将每个文件夹中的文件发送到 kafka 中,触发检测过程。
9.5.3 源码地址
https://gitee.com/smile-yan/flink-cpu-demo
除了 java 源码,还包括生成测试数据的脚本,以及发送数据的脚本,以及已经生成的数据文件夹。
9.5 总结
本章内容提供了一个非常简单的Flink Stream 计算案例,涉及内容包括:kafka 通讯,flink 的动态时间窗口,自定义窗口聚合条件以及 flink 的窗口聚合处理等。此外,本章通过录屏的方式验证整个项目运行正常。
希望作为 flink 的初学者能够提供一个简单案例。感谢各位小伙伴们的支持 ~ 共勉 ~
如果认为本章节写得还行,一定记得点击下方免费的赞 ~ 感谢 !

Smileyan
2024.05.12 18:19

