
- 1利用机器学习打造反电信诈骗系统_实时机器学习模型在银行对公客户反电诈的创新
- 2YOLOv10:实时端到端目标检测的新突破_yolo10 psa是transformer吗
- 3异星探险家自建服务器,异星探险家详细开服教程 如何开服
- 4爱奇艺联合IJCAI举办算法大赛 2020iCartoonFace正式启动
- 5git学习——第4.6节 分支管理之多人协作_git 多分支协同
- 6python中的split()、rsplit()、splitlines()用法比较
- 7STC89C52定时器的简介
- 8Hbase常用命令速查
- 9数据结构各内部排序算法总结对比及动图演示(插入排序、冒泡和快速排序、选择排序、堆排序、归并排序和基数排序等)_内部排序算法比较
- 10RockedMq 角色_roctmq
分类-3-生成学习-3-朴素贝叶斯模型、laplace平滑、多元伯努利事件模型、多项式事件模型_该模型还要求向量x中的元素 是相互独立的,即
赞
踩
多元伯努利事件模型( multi-variate Bernoulli event model)
在 GDA 中,我们要求特征向量 x 是连续实数向量。如果 x 是离散值的话,可以考虑采用朴素贝叶斯的分类方法。
假如要分类垃圾邮件和正常邮件。
我们用一个向量→x(m×1)表示一个包含m个单词的字典。当邮件中出现字典(→x)中的第i个单词时,我们便将xi置1,否则xi=0。
举个例子如下:

邮件中包含“a”,”buy”且字典→x中也包含它们,因此字典中的对应位置置1;
而邮件中的单词“aardvark”,“aardwolf”,“zygmurgy”并没有出现在字典中,这类单词我们忽略它们;
而对于字典中未在邮件中出现过的单词,对应的位置我们置为0。
我们的目的是为了建立模型p(x|y).
假如字典中的单词数为50000,这时就会有250000中可能的输入组合,这样我们就需要250000个参数(实际上是需要250000−1个参数,这里的参数其实是多项式分布中的pi),参数太多,不可能用来建模。
begin-补充:多项式分布模型(二项式分布的扩展)
多项式分布( multinomial distribution)
某随机实验如果有 k 个可能结局 A1,A2,…,Ak,它们的概率分布分别是 p1,p2,…,pk,那么在 N 次采样的总结果中, A1 出现n1 次,A2出现 n2 次, …, Ak 出现 nk次的这种事件的出现概率 P 有下面公式:(Xi代表出现ni次)
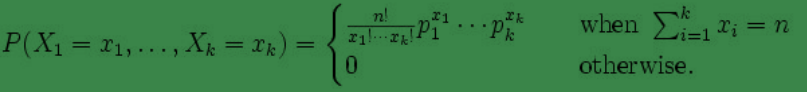
end-补充
因此,我们假设当y确定时,向量→x中的元素xi的取值(0或1)是相互独立的。这就是朴素贝叶斯假设(Naive Bayes (NB) assumption),基于它的算法称为朴素贝叶斯分类器( Naive Bayes classifier)。
注:假设中是→x中的任意两个元素在y的条件下,是相互独立的即:p(xi|y)=p(xi|y,xj) (i≠j),而不是→x中的任意两个元素是相互独立的:p(xi)=p(xi|xj) (i≠j)。
在朴素贝叶斯假设下我们有:、
因此我们的原问题可写为下面的形式:
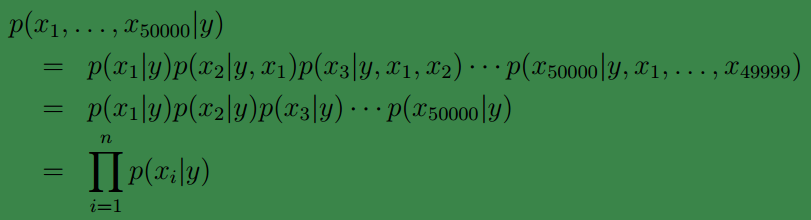
第一个等式根据概率密度链式法则得到,第二个等式由朴素贝叶斯假设得到。
下面给出我们模型的参数:
首先回想朴素贝叶斯公式:p(y|x)=p(x|y)p(y)p(x),我们的目的是为p(x|y)和p(y)建模。
针对p(y)我们可以给出ϕy=p(y=1),显然此时p(y=0)=1−ϕy;
由于p(x|y)=∏ni=1p(xi|y),因此为了建立p(x|y=1)和p(x|y=0)的模型,就必须先求出所有的p(xi|y=1)和p(xi|y=0)(可以理解为等价于对所有的p(xi|y=1)和p(xi|y=0)建模)。因此可以给出:ϕi|y=1=p(xi=1|y=1)和ϕi|y=0=p(xi=1|y=0)。
因此我们的参数如下:
现在根据给定的训练集
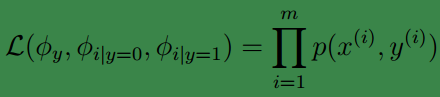
这里求似然值和高斯辨别中一样,也是利用的联合概率分布积。
求解后便可得到参数值:

有了参数之后我们便可以用来预测了,对于一个输入样本,我们可由下式预测结果:

对于。
在之前的博文中已经提到分母是不需要计算的,因为对多有样本而言,它的值是固定不变的。
最终的结果取中的较大者。
多分类情况
朴素贝叶斯模型可以很容易的推广到多分类的情况,比如三分类()。只需要添加参数:且将原来的参数用两个参数替代:,然后就是求最大似然值,获得各个参数的值。
拉普拉斯平滑
朴素贝叶斯方法有个致命的缺点就是对数据稀疏问题过于敏感。即:若字典()中的某个单词(例如“NIPS”)没有在训练样本中出现过。当我们测试一个样本时,若该样本中有单词“NIPS”(假设它是中的第35000个元素代表的单词)那么可得:
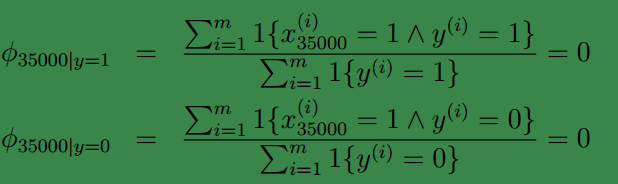
这将会导致都为:
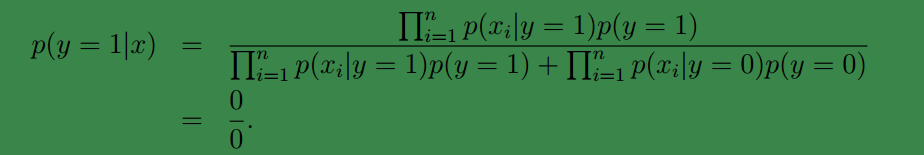
原因就是我们的特征概率条件独立,使用的是相乘的方式来得到结果。
为了解决这个问题,我们打算给未出现特征值,赋予一个“小”的值而不是 0。
具体平滑方法如下:
对于二分类的情况:我们有
回到朴素贝叶斯分类中可得此时参数应为:
上面是对于二项分布的情况,一般的,若x为k项分布,我们类似的在分子加1,在分母加k。
多项式事件模型(multinomial event model)与文本分类
回想一下我们刚刚使用的用于文本分类的朴素贝叶斯模型,这个模型称作多值伯努利事件模型( multi-variate Bernoulli event model)。在该模型中,我们通过检查邮件中的单词是否在字典中出现,以及对应的,最终通过来判定是否为垃圾邮件。
让我们换一个思路,这次我们不先从词典入手,而是选择从邮件入手。让 表示邮件中的第个词, 表示这个词在字典中的位置,那么取值范围为, 是字典中词的数目。 这样第封邮件可以表示成,代表邮件中的单词数, 可以变化,因为每封邮件的词的个数不同。 例如,若邮件以“A NIPS…”开头,若”A”是字典中的第1个单词,“NIPS”是字典中的第35000个单词,那么。显然,这里的已经不再是二值(0,1)的了,而是多值的,所以该模型称作多项式事件模型。
现在描述符已介绍完毕,让我们来看看具体是怎么做的吧:
首先假定我们要有一封300个单词的垃圾邮件(假设为垃圾邮件),我们遍历该邮件,将邮件中的单词与其在字典中的序号依次存放在中,这里也是假设在邮件中的每一个单词的出现都是相互独立的事件,它们对应的概率分布我们类似的可以写成,因此类似与多元伯努利事件模型,我们能够得到
注:因为邮件中一个单词有可能出现多次,故可能存在,这也是多项式事件模型与多元伯努利事件模型的主要不同之处,即:多项式事件模型考虑了单词出现的次数,而多元伯努利事件模型并未考虑单词出现次数。
仿照多元伯努利事件模型中,将合并成一个式子:
从形式上看,和多元伯努利事件模型一样,但是它们是不同的。
首先,
其次,注意第一个的
然后,参数形式也有所变化:
下面两个参数变了
给定训练集,其中 ,之前已经说过, 代表第i封邮件中的单词数。
参数和训练样本都有了,下面开始求最大似然值:
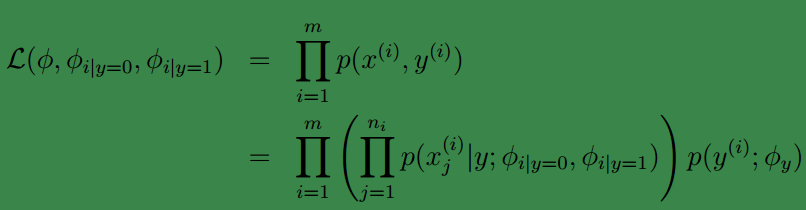
求最大似然值片可获得参数:
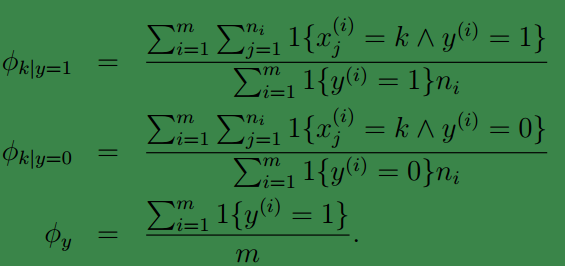
应用拉普拉斯平滑:
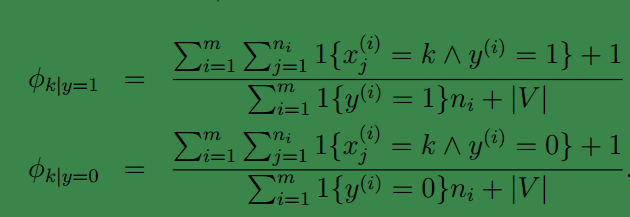
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

