
- 1vue项目依赖的下载_vue 下载element-ui
- 2Mac上Flutter开发环境搭建_mac debug flutter
- 3大数据基础习题_联邦查询 数据安全
- 4Ubuntu系统使用快速入门实践(八)—— git 命令使用_ubuntu 初始化git
- 5【微信小程序开发实战项目】——花店微信小程序实战项目(4)
- 6DI-engine强化学习入门(五)配置和运行针对PyBullet环境的SAC算法_pybullet速度控制
- 7毕业生求职简历范文(通用17篇)
- 8媲美Sora,免费使用!带物理模拟的,文生视频模型_ollama 文生视频
- 98.4 MapReduce 三大组件(二):Sort_mapreduce组件sort的作用
- 10通过 docker-compose 快速部署 Hadoop 集群极简教程_dockercompose 单机部署hadoop ha
ElasticSearch基础:从倒排索引说起,快速认知ES_es中的索引和倒排索引有什么关系
赞
踩
ElasticSearch基础:从倒排索引说起,快速认知ES
- ElasticSearch第二篇:ElasticSearch进阶:一文全览各种ES查询在Java中的实现
1 ElasticSearch认知
ElasticSearch(简称ES)是什么?按照 ElasticSearch官网 的定义,Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎。
很官方,但也很晦涩。所以,接下来我们尝试比较直白地去描述它。
1.1 关于搜索
首先,需要弄明白下面几个问题:
- 什么是搜索?
- 为什么数据库不适合处理搜索?
- 什么是全文检索和Lucene?
提到搜索,人们会立刻联想到在百度、谷歌上输入关键词获取相关的内容的场景。但搜索不等于百度,大部分APP支持的站内搜索更加大行其道。
数据库是储存和查询数据的利器,那么数据库是否适合做搜索呢?答案是不合适。第一个原因是,当数据库存储了大量数据后,查询效率大幅降低。
另外有些搜索场景,数据库也是不支持的,例如在下表中,我们试图通过“中国足球”这个关键词搜索数据,数据库是无法查询到相应内容的。
| id | name |
|---|---|
| 1 | 中国男子足球队 |
| 2 | 中国男子田径队 |
| 3 | 中国女子排球队 |
| 4 | 中国女子跳水队 |
1.2 倒排索引
什么是倒排索引?倒排索引也叫反向索引,我们通常理解的索引是通过key寻找value,与之相反,倒排索引是通过value寻找key,故而被称作反向索引。
下面我们用一个简单的例子描述一下倒排索引的作用过程:
假如现在有三份数据文档,内容分别是:
Doc 1:Java is the best programming language
Doc 2:PHP is the best programming language
Doc 3:Javascript is the best programming language
- 1
- 2
- 3
- 4
- 5
为了创建索引,ES引擎通过分词器将每个文档的内容拆成单独的词(称之为词条,或term),再将这些词条创建成不含重复词条的排序列表,然后列出每个词条出现在哪个文档,结果如下:
| term | Doc 1 | Doc 2 | Doc 3 |
|---|---|---|---|
| Java | √ | ||
| is | √ | √ | √ |
| the | √ | √ | √ |
| best | √ | √ | √ |
| programming | √ | √ | √ |
| language | √ | √ | √ |
| PHP | √ | √ | |
| Javascript | √ | √ |
这种结构由文档中所有不重复的词的列表构成,对于其中每个词都有至少一个文档与与之关联。这种由属性值来确定记录的位置的结构就是倒排索引,带有倒排索引的文件被称为倒排文件。
将上表转为更直观的图片来展示倒排索引:
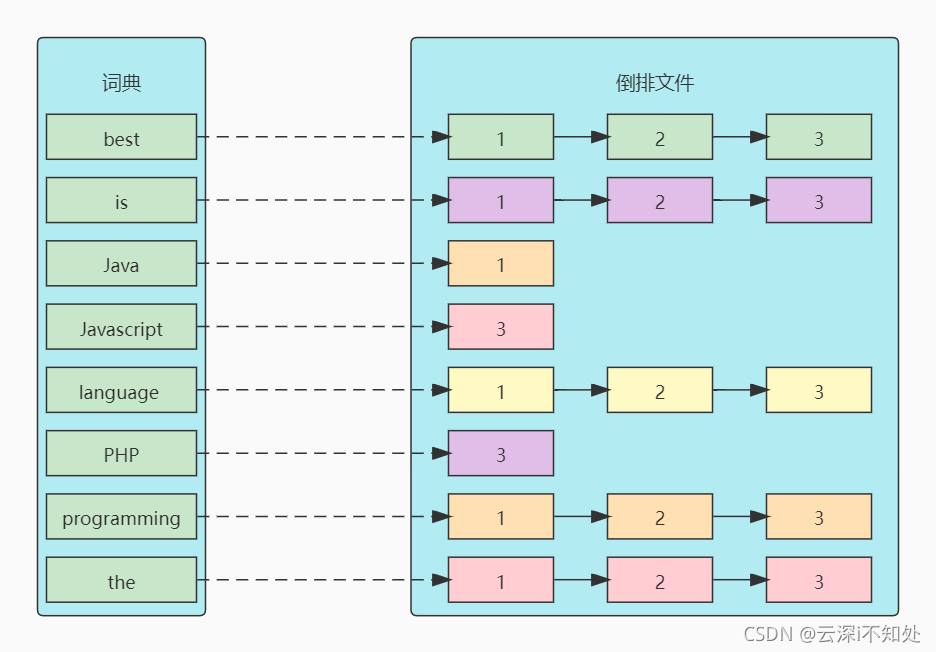
其中,几个核心术语需要着重理解:
- 词条(term):索引里面最小的存储和查询单元,对于英文来说是一个词,对于中文来说一般指分词后的一个词。
- 词典(Term Dictionary):也叫字典,是词条的组合。搜索引擎的通常索引单位是单词,单词词典是文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向倒排所有的指针。
- 倒排表(Post list):一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过及出现的位置。每个记录称为一个倒排项(Posting),倒排表记录的不单单是文档编号,还记录了词频等信息。
- 倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
词典和倒排表是 Lucene这种很重要的两种数据结构,是实现快速检索的重要基石。词典和倒排文件是分两部分存储的,词典在内存中而倒排文件存储在磁盘。
1.3 Lucene
至于Lucene,直白地说,它就是一个jar包,封装好了各种建立倒排索引、匹配索引进行搜索的各种算法。我们可以引入Lucene,基于它的API进行开发。
ElasticSearch就在Lucene的基础上实现的,对Lucene进行了良好的封装,简化开发,并提供了很多高级功能。
ElasticSearch生态
ElasticSearch 为快速检索和分析大数据而生,目前已形成丰富的生态。
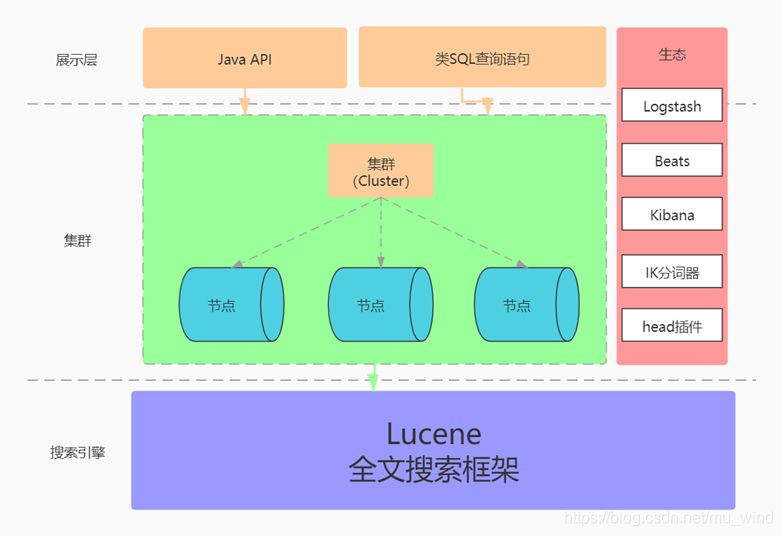
例如目前比较流行的ELK体系:
Elasticsearch是位于Elastic堆栈核心的分布式搜索和分析引擎。Logstash和Beats有助于收集、聚合和丰富数据,并将其存储在Elasticsearch中。Kibana使您能够以交互方式探索、可视化和共享对数据的见解,并管理和监视堆栈。
1.4 ES基本概念
要了解 Elasticsearch ,首先要先了解下面的几个专有名词:索引(Index)、类型(Type)、文档(Document)、映射(mapping)。
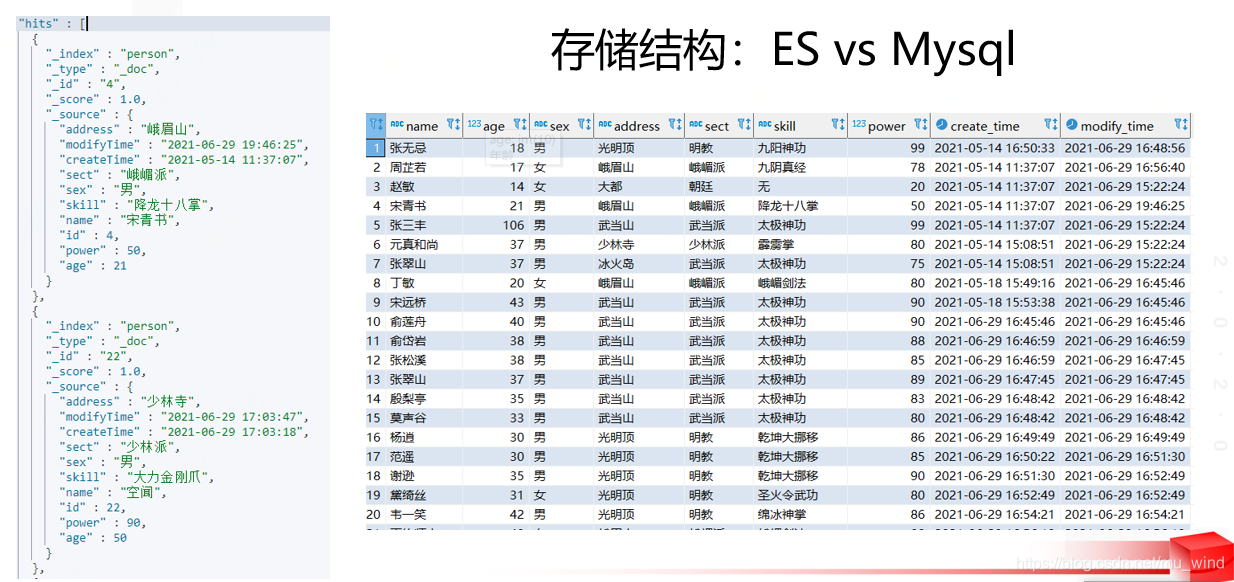
既然 Elasticsearch 能够存储和查询数据,那么我们自然要将其和最具知名度的数据库-Mysql进行一番对比,两者之间可以通过下表做一个并不非常严谨的类比,主要是为了方便理解。
| Elasticsearch | Mysql |
|---|---|
| 索引(Index) | 库(Database) |
| 表(Table) | |
| 文档(Document) | 行(Row) |
| 字段(Field) | 列(Column) |
| 映射(Mappings) | 表结构(schema) |
Index:索引,相当于关系数据库中的database概念,是一类数据的集合,是一个逻辑概念。Type:类型,相当于数据库中的table概念,在6.0版本之前,一个Index中可以有多个type,7.0版本后彻底废弃多type,每个索引只能有一个type,即“ _doc”。这个概念就不用太关注了。Document:文档,存储在ES中的主要实体叫文档,可以理解为关系型数据库中表的一行数据记录。每个文档由多个字段(field)组成。区别于关系型数据库的是,ES是一个非结构化的数据库,每个文档可以有不同的字段,并且有一个唯一标识。Field:字段,存在于文档中,字段是包含数据的键值对,可以理解为Mysql一行数据的其中一列。Mapping:映射,是对索引库中的索引字段及其数据类型进行定义,类似于关系型数据库中的表结构。ES默认动态创建索引和索引类型的Mapping。
ES和Mysql直观对比:
1.5 ES集群概念
Elasticsearch 设计上是天然支持分布式的,下面我们了解一下集群相关概念。
cluster:集群,一个ES集群由多个节点(node)组成, 每个集群都有一个共同的集群名称最为标识。node:节点,一个ES实例即为一个节点,一台机器可以有多个节点。shard:分片,如果某个索引包含大量数据,以至于一台机器无法存储,ES可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。这样,ES就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个最小工作单元,承载部分数据,具有一个lucene实例和完整的建立索引、处理请求的能力。replica:副本,就是shard的冗余备份,它可以防止数据丢失以及shard异常时负责容错和负载均衡。
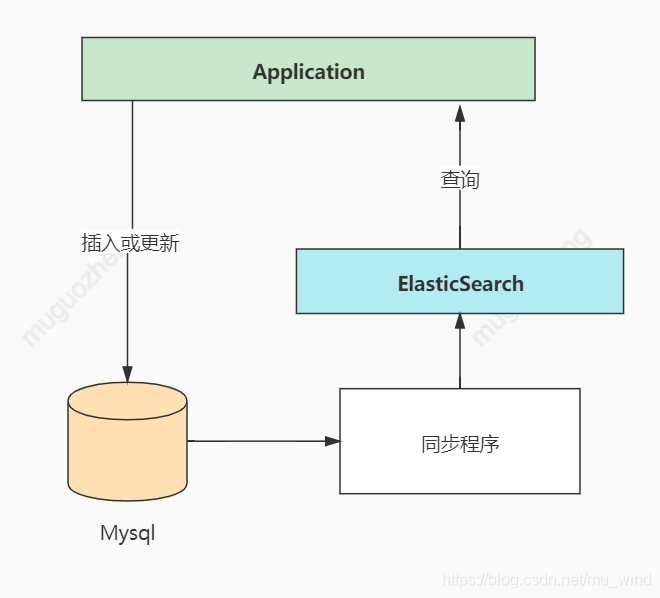
在实际生产中,ES通常与Mysql等存储系统联合使用,例如下面这个设计:
2 SpringBoot集成ES
Springboot集成ES非常方便,只要三步操作:
1、pom.xml添加依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.8.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2、application.yml增加配置:
elasticsearch:
host: 11.50.36.97
port: 9200
- 1
- 2
- 3
3、新建config类:
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
@Data
public class ESConfig {
private String host;
private Integer port;
@Bean(destroyMethod = "close")
public RestHighLevelClient client(){
return new RestHighLevelClient(RestClient.builder(new HttpHost(host, port)));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
写个测试方法测试一下:
@RunWith(SpringJUnit4ClassRunner.class) @SpringBootTest(classes = DemoApplication.class) @Slf4j public class BasicTest { @Autowired private RestHighLevelClient client; /** * 添加索引 * * @throws IOException */ @Test public void addIndex() throws IOException { //1.使用client获取操作索引对象 IndicesClient indices = client.indices(); //2.具体操作获取返回值 //2.1 设置索引名称 CreateIndexRequest createIndexRequest = new CreateIndexRequest("person"); CreateIndexResponse createIndexResponse = indices.create(createIndexRequest, RequestOptions.DEFAULT); //3.根据返回值判断结果 System.out.println(createIndexResponse); } /** * 查询所有的索引 * * @throws IOException */ @Test public void indexTest() throws IOException { GetAliasesRequest request = new GetAliasesRequest(); GetAliasesResponse alias = client.indices().getAlias(request, RequestOptions.DEFAULT); Map<String, Set<AliasMetadata>> map = alias.getAliases(); map.forEach((k, v) -> { if (!k.startsWith(".")) { System.out.println(k); } }); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
3 ElasticSearch安装
3.1 下载与安装
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
安装:
1、将压缩包上传到linux服务器到特定目录,比如 /export/test
2、解压压缩包:tar -zxvf elasticsearch-7.13.2-linux-x86_64.tar.gz
ES目录介绍:
bin:可执行文件在里面,运行es的命令就在这个里面,包含了一些脚本文件等config:配置文件目录JDK:java环境lib:依赖的jar,类库logs:日志文件modules:es相关的模块plugins:可以自己开发的插件data:自建目录,后面要用,用来放置索引
3.2 修改配置
首先,我们需要做一些系统配置,要使用有权限的用户,例如root用户。
1、配置用户
因为root用户不能直接运行ES,所以新增一个用户(如果有非root用户,直接用也可以)
useradd es
passwd es
chown -R es elasticsearch
- 1
- 2
- 3
2、设置最大句柄数(nofile)和最大进程数(nproc):
vim /etc/security/limits.conf
- 1
在末尾追加内容(已有的话忽略):
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
- 1
- 2
- 3
- 4
3、调整vm.max_map_count的大小
max_map_count文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量
vim /etc/sysctl.conf
- 1
在文尾追加(已有的话则忽略此步):
vm.max_map_count=262144
- 1
执行以下命令使该配置生效:
sysctl -p
- 1
接下来,切换到刚刚创建的用户,修改ES配置文件:
su es
vim config/elasticsearch.yml
- 1
- 2
主要修改以下几项:
# 1. 修改集群名称
cluster.name: test-es
# 2. 修改当前的es节点名称
node.name: node-1
# 3. 修改data数据保存地址(按自己的实际路径填写)
path.data: /export/test/elasticsearch-7.13.2/data
# 4. 日志数据保存地址(按自己的实际路径填写)
path.logs: /export/test/elasticsearch-7.13.2/logs
# 5. 绑定es网络ip
network.host: 0.0.0.0
# 6. 修改初始化master节点
cluster.initial_master_nodes: ["node-1"]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
启动es服务:
cd bin
./elasticsearch
- 1
- 2
访问 http://192.168.1.13:9200/,出现以下信息,表示es启动成功。
{ "name" : "node-1", "cluster_name" : "elasticsearch", "cluster_uuid" : "vMavXuuVTbmqykZpDEM0zQ", "version" : { "number" : "7.13.2", "build_flavor" : "default", "build_type" : "zip", "build_hash" : "4d960a0733be83dd2543ca018aa4ddc42e956800", "build_date" : "2021-06-10T21:01:55.251515791Z", "build_snapshot" : false, "lucene_version" : "8.8.2", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
设置后台启动:
./bin/elasticsearch -d
- 1
3.3 配置Kibana
下载地址:https://www.elastic.co/cn/downloads/kibana
Kibana是Java应用,解压即可。解压后,进入文件目录的config目录中,编辑kibana.yml文件,修改该项:
# 指向我们安装好的ES服务地址
elasticsearch.hosts: ["http://11.50.36.97:9200/"]
- 1
- 2
然后,进入bin目录,双击kibana.bat 即可启动。
以上是ElasticSearch基础的内容,后续将持续添加更多内容,敬请关注!

