
- 1Windows靶机应急响应(三)_应急响应 win 靶机 php修复
- 2计算机怎么没有运行命令行,Win7系统开始菜单没有“运行”命令选项如何找回...
- 3arduino STM32F103 SPI接口DMA显示st7789系列TFT屏幕_stm32f103 可带动7寸屏动画吗
- 4京东app优惠券python抓取_教大家用fd来抓取京东app的领券链接
- 5Git pull(拉取),push(上传)命令_数据上传 与数据拉取 的语法
- 6数据结构(逻辑结构与物理结构)_数据结构逻辑结构和物理结构
- 7数字工业 弹性安全丨2022 Fortinet工业互联网安全发展峰会成功举办
- 8新年伊始,和大家聊聊鲜枣课堂的未来
- 9【CS.PL】Lua 编程之道: 基础语法和数据类型 - 进度16%
- 10用lambda表达式创建文件过滤器_lamda创建文件过滤器
Redis缓存击穿,缓存穿透,缓存雪崩,附解决方案_redis 缓存雪崩了 都访问到数据库了 如何马上处理这个问题
赞
踩
前言
在日常的项目中,缓存的使用场景是比较多的。缓存是分布式系统中的重要组件,主要解决在高并发、大数据场景下,热点数据访问的性能问题,提高性能的数据快速访问。本文以Redis作为缓存时,针对常见的缓存击穿、缓存穿透、缓存雪崩问题做简单地说明,并且提供有效的解决方案。
Redis缓存使用场景
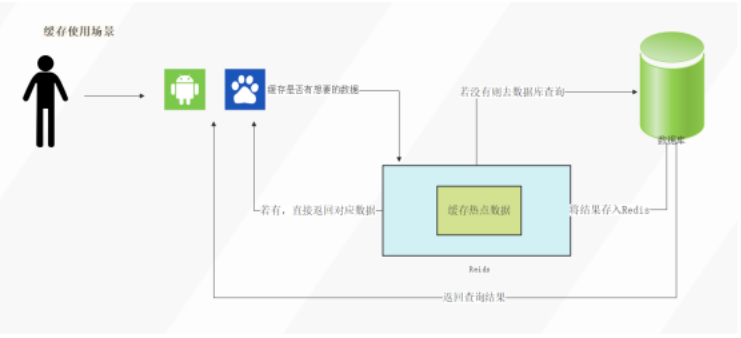
Redis会把数据库中经常被查询的数据缓存起来,比如热点数据,这样当用户通过网站或APP来访问的时候,就不需要到数据库中去查询了,而是直接获取 Redis中的缓存数据,从而降低了后端数据库的读取压力。如果说用户查询的数据Redis中没有,此时用户的查询请求就会转到数据库,当数据库将数据返回给客户端时,同时会将数据缓存到 Redis中,这样用户再次读取时,就可以直接从Redis中获取数据。流程图如下所示:
Redis缓存穿透
缓存穿透是指用户恶意的发起大量请求去查询一个缓存(Redis)和数据库(DB)中都没有的数据,出于容错考虑从数据库(DB)查不到数据则不写入缓存(Redis)这将导致每个请求都要到数据库(DB)中查询,失去了缓存的意义,从而导致数据库因压力过大挂掉。
流程图如下所示:

解决方案
对空值缓存
上面我们也介绍了,之所以会发生穿透,是因为缓存中没有存储这些空数据的key,从而导致每次查询都到数据库去了。
那么我们就可以为这些key的值设置null丢到缓存里面去,后面再出现查询这个key 的请求的时候,直接返回null ,就不用在到数据库中去走一圈了。但是别忘了设置过期时间。
关键代码如下:

添加参数校验
我们可以在接口层添加校验,不合法的直接返回即可,没必要做后续的操作。
例如:使用bitmaps类型定义一个可以访问名单,名单id作为bitmaps的偏移量,每次访问时与bitmaps中的id进行比较,如果访问id不在bitmaps中,则进行拦截,不给其访问。
采用布隆过滤器
布隆过滤器(Bloom Filter),Bloom Filter 类似于一个hash set 用来判断某个元素(key)是否存在于某个集合中,不存在return就好了,存在就去查DB刷新缓存KV再return,它的优点是空间效率和查询时间都比一般算法快,缺点是有一定的误识别率和删除困难。
布隆过滤器的工作方式:
一个空的布隆过滤器是一个由m个二进制位构成的数组。
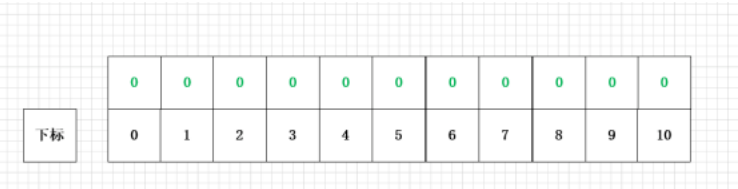
以上只是画了布隆过滤器的很小很小的一部分,实际布隆过滤器是非常大的数组(这里的大是指它的长度大,并不是指它所占的内存空间大)。
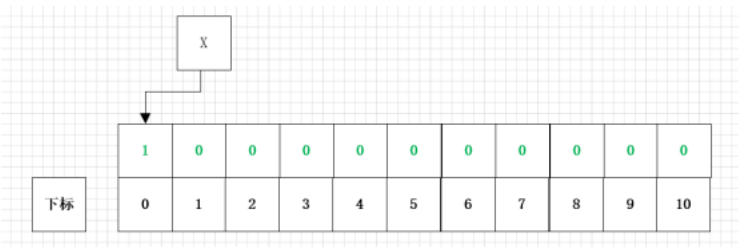
当一个数据进行存入布隆过滤器的时候,会经过若干个哈希函数进行哈希,得到对应的哈希值作为数组的下标,然后将初始化的位数组对应的下标的值修改为1,结果图如下:
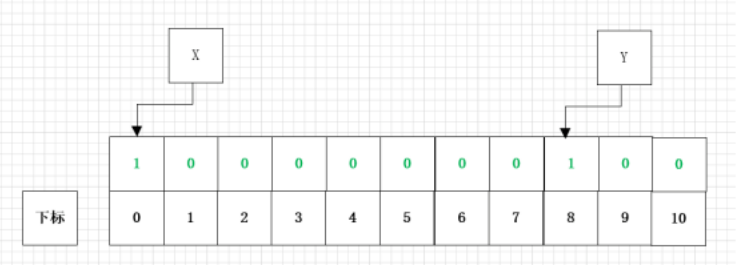
当再次进行存入第二个值的时候,修改后的结果的原理图如下:
那么为什么会有误判率呢?
假设在我们多次存入值后,在布隆过滤器中存在x、y、z这三个值,布隆过滤器的存储结构图如下所示:

当我们要查询的时候,比如查询M这个数,实际中M这个数是不存在布隆过滤器中的,经过哈希函数计算后得到M的哈希值分别为1和7,结构原理图如下:
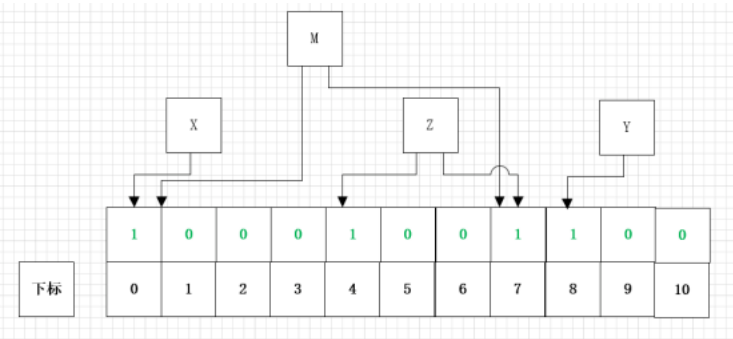
经过查询后,发现1和7位置所存储的值都为1,但是1和7的下标分别是X和Z经过计算后的下标位置的修改,该布隆过滤器中实际不存在M,那么布隆过滤器就会误判改值可能存在,因为布隆过滤器不存元素值,所以存在误判率。
那么为什么不能删除元素呢?
原因很简单,因为删除元素后,将对应元素的下标设置为零,可能别的元素的下标也引用改下标,这样别的元素的判断就会受到影响。
Redis缓存雪崩
缓存雪崩是指大量的应用请求无法在Redis缓存中进行处理,紧接着应用将大量请求发送到数据库层,导致数据库层的压力激增。
缓存雪崩一般是由两个原因导致的,应对方案也有所不同。第一个原因是:缓存中有大量数据同时过期,导致大量请求无法得到处理。第二个原因是:Redis 缓存实例发生故障宕机了,无法处理请求,这就会导致大量请求一下子积压到数据库层,从而发生缓存雪崩。
流程图如下所示:

解决方案
大量热点数据同时失效带来的缓存雪崩问题
避免热key同时失效
使用 EXPIRE命令给每个数据设置过期时间时,给这些数据的过期时间增加一个较小的随机数(例如,随机增加 1~3 分钟)。这样一来,不同数据的过期时间有所差别,但差别又不会太大。既避免了大量数据同时过期,同时也保证了这些数据基本在相近的时间失效,仍然能满足业务需求。
2. 服务降级
所谓的服务降级,是指发生缓存雪崩时,针对不同的数据采取不同的处理方式,例如:
当业务应用访问的是非核心数据时,暂时停止从缓存中查询这些数据,而是直接返回预定义信息、空值或是错误信息;
当业务应用访问的是核心数据时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取。
这样一来,我们就避免了大量请求因缓存缺失,而积压到数据库系统,保证了数据库系统的正常运行。
3. Redis 缓存实例发生故障宕机带来的缓存雪崩问题
从事前预防的角度,我们可以通过主从节点的方式构建 Redis 缓存高可靠集群。如果 Redis缓存的主节点故障宕机了,从节点还可以切换成为主节点,继续提供缓存服务,避免了由于缓存实例宕机而导致的缓存雪崩问题。
如果实际业务系统真发生了Redis 缓存实例不可用的情况,我们可以在业务系统中实现服务熔断或请求限流机制。所谓的服务熔断,是指在发生缓存雪崩时,为了防止引发连锁的数据库雪崩,甚至是整个系统的崩溃,我们暂停业务应用对缓存系统的接口访问。
Redis缓存击穿
我们在平常高并发的系统中,大量的请求同时查询一个key时,假设此时这个key正好失效了,就会导致大量的请求都打到数据库上面去,这种现象我们称为击穿。
这么看缓存击穿和缓存雪崩有点像,但是又有一点不一样,缓存雪崩是因为大面积的缓存失效,打崩了DB,而缓存击穿不同的是「缓存击穿」是指一个Key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个完好无损的桶上凿开了一个洞,如下图所示:

解决方案
1. 热key不过期
预先设置热门数据:在Redis高峰访问时期,提前设置热门数据到缓存中,对这些热key不设置失效时间,不过这样设置需要区分场景。
实时调整:实时监控哪些数据热门,实时调整key过期时间。
2. 分布式锁
为了避免出现缓存击穿的情况,我们可以在第一个请求去查询数据库的时候对他加一个分布式锁,其余的查询请求都会被阻塞住,直到锁被释放,后面的线程进来发现已经有缓存了,就直接走缓存,从而保护数据库。但是也是由于它会阻塞其他的线程,此时系统吞吐量会下降。需要结合实际的业务去考虑是否要这么做。
关键代码如下:

总结
缓存击穿
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。一般通过互斥锁,热点数据永不过期,定时刷新过期时间等方法解决该问题。
缓存穿透
key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。一般通过对空数据进行缓存,布隆过滤器等方法解决该问题。
缓存雪崩
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。一般通过加锁排队,设置过期时间随机值等方法解决该问题。


