- 1『Kafka』在Docker中快速部署Kafka及其管理平台搭建_kafka管理平台
- 2Cesium 三维热力图_cesium 热力图
- 3前端 JS 经典:变量交换_js [a,b] = [b,a]
- 4cmd命令行怎样运行python,在CMD命令行中运行python脚本的方法
- 5计算机毕业设计hadoop+spark+hive新能源汽车数据分析可视化大屏 汽车推荐系统 新能源汽车推荐系统 汽车爬虫 汽车大数据 机器学习 大数据毕业设计 深度学习 知识图谱 人工智能_基于hive的新能源汽车统计分析
- 6Python小记:14.数据分析基础知识点汇总_33ax,xffts
- 7浅谈医疗AI软件测试技术发展_ct ai 分析 试用
- 8蛋糕商城项目完整源码_javaweb程序设计蛋糕商城注册页面源代码
- 9使用python进行傅里叶FFT-频谱分析详细教程
- 10如何做到数据防篡改
Java使用PaddleOCR识别身份证信息_java paddleocr
赞
踩
之前使用过opencv+tess4j实现对身份证识别的内容,但是这个方案的局限性很大,图片歪的还要调整图片的角度,而且识别的准确率不是很让人满意。然后就发这个基于深度学习框架的PaddleOCR,使用这个完全不需要担心图片歪与不歪的,只要不是歪得太离谱就可以了,这个正确率不是一般的高。
具体效果如下所示:后面有完整的代码
PaddleOCR官网
飞浆官网:
飞桨PaddlePaddle-源于产业实践的开源深度学习平台 这里有使用PaddleOCR的安装过程,这个最麻烦的就是安装过程,我在安装过程中遇到各种问题,后续会写一篇笔记记录这个PaddleOCR的安装过程, 这里直接先使用着先,这里主要记录java调用PaddleOCR中基于PaddleHub Serving的服务部署接口,我这里使用的是windows10,部署paddleOCR的基于PaddleHub Serving的服务部署,然后通过Java请求部署提供的接口进行身份证的文字识别。要完成部署,需要下载对应的文件,具体可以到下面的gitee和GitHub上下载。
gitee:
PaddleOCR: 基于飞桨的OCR工具库,包含总模型仅8.6M的超轻量级中文OCR,单模型支持中英文数字组合识别、竖排文本识别、长文本识别。同时支持多种文本检测、文本识别的训练算法。 (gitee.com)
github:
GitHub - PaddlePaddle/PaddleOCR: Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
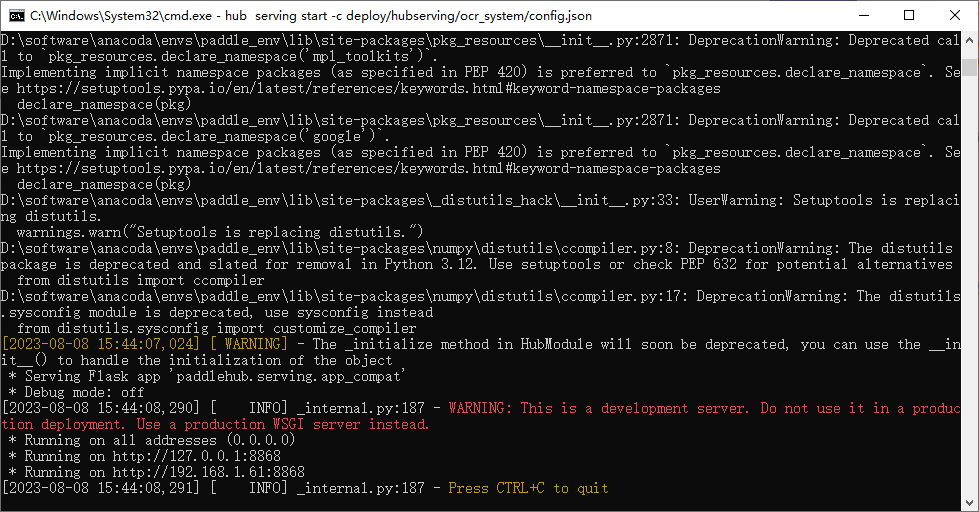
启动PaddleOCR的基于PaddleHub Serving的服务部署
这个PaddleOCR的安装和部署过程,后续会写一篇文章的(PaddleOCR在windows中的使用_m0_62317155的博客-CSDN博客 安装和部署过程在这里,看这篇文章就好了)。这里不是重点,这里只要记录Java调用启动PaddleOCR的基于PaddleHub Serving的服务部署的接口实现对身份证文字的识别。启动成功之后,可以看到如下的信息
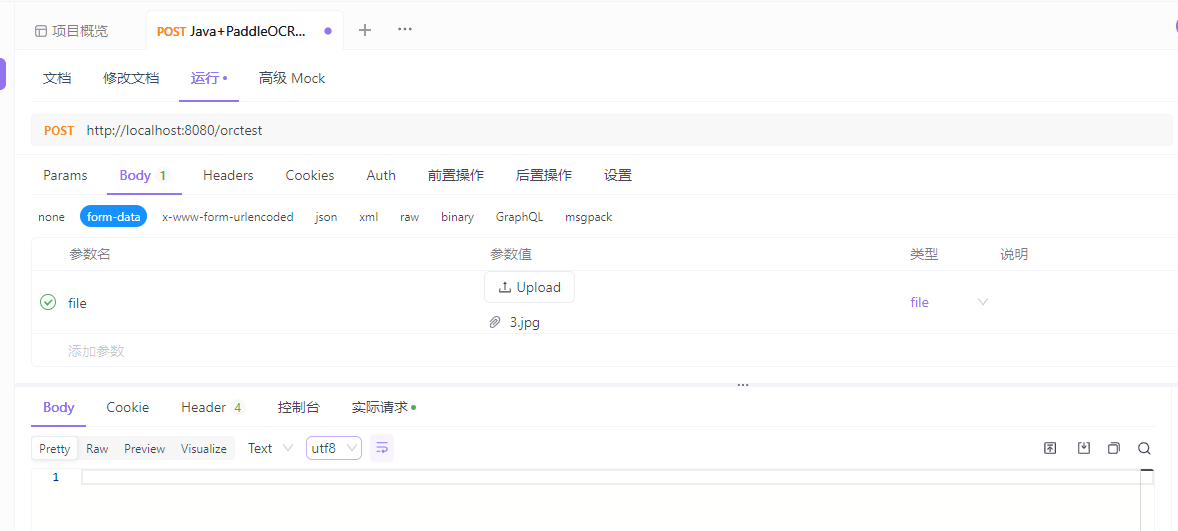
然后使用postman或者apifox发送请求,然后试一试,有没有启动成功。我这里使用的是apifox,感觉这个比postman好用。使用apifox请求接口传入图片需要,变成base64位的图片,可以在这个网站将图片转成base64位
图片转换base64编码 在线图片Base64编码转换工具 iP138在线工具 如下面这一张图片,然后,将图片放在上面的在线网站,转图片为base64位的图片

注:图片来源于网络,如有不对的地方,请联系删除一下

从GIF图中,可以看到能够识别出来身份证的结果了
Java + PaddleOCR身份证识别
这里使用的是springboot2.7.10 + jdk11,下面就是一个简单的springboot的web项目,什么maven依赖都不需要添加,只是一个简单的springboot 的web项目就行了。
就这么一个简单的springboot 的web项目就行了,这里使用lombok,是考虑到可以会记录日志。所以这个加不加都行!
结果如下所示,代码在GIF的后面,完整的Java代码在后面,具体看代码就行了。
项目目录如下所示:
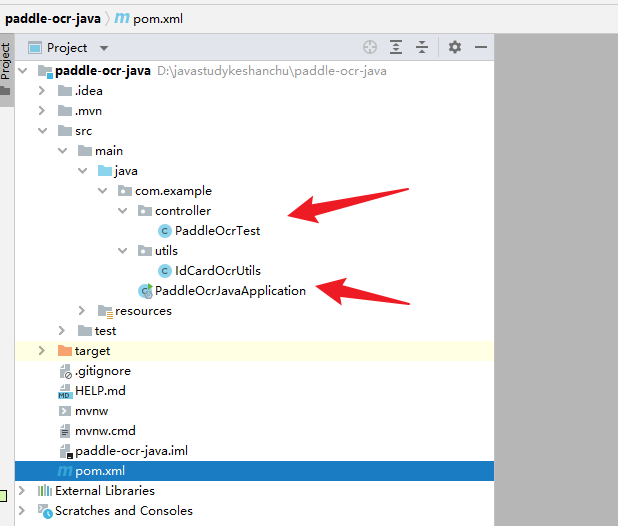
项目中的pom.xml如下所示:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.7.10</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.example</groupId> <artifactId>paddle-ocr-java</artifactId> <version>0.0.1-SNAPSHOT</version> <name>paddle-ocr-java</name> <description>paddle-ocr-java</description> <properties> <java.version>11</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> </plugins> </build> </project>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
Controller的代码
package com.example.controller; import com.example.utils.IdCardOcrUtils; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RestController; import org.springframework.web.multipart.MultipartFile; import java.io.IOException; import java.util.Map; @RestController public class PaddleOcrTest { @PostMapping("/orctest") public Map<String, String> ocrTest(MultipartFile file) { try { byte[] bytes = file.getBytes(); Map<String, String> userInfoMap = IdCardOcrUtils.getStringStringMap(bytes); return userInfoMap; } catch (IOException e) { e.printStackTrace(); return null; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
身份证识别的utils
这个工具类可以写在service中的,先用service定义一个接口,然后再serviceImpl中实现这个工具类的功能。毕竟按照三层结构,Controller + service + dao层的,这个标准模式好一点。这里变成工具类时因为,懒!毕竟是笔记,不想搞得项目目录太复杂。
package com.example.utils; import org.springframework.http.HttpEntity; import org.springframework.http.HttpHeaders; import org.springframework.http.MediaType; import org.springframework.util.Base64Utils; import org.springframework.util.LinkedMultiValueMap; import org.springframework.util.MultiValueMap; import org.springframework.web.client.RestTemplate; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.regex.Matcher; import java.util.regex.Pattern; public class IdCardOcrUtils { private IdCardOcrUtils() { } /** * 身份证完整信息识别 * * @param bytes 输入流,的bytes数组 * @return 身份证信息 */ public static Map<String, String> getStringStringMap(byte[] bytes) { StringBuilder result = new StringBuilder(); HttpHeaders headers = new HttpHeaders(); //设置请求头格式 headers.setContentType(MediaType.APPLICATION_JSON); //构建请求参数 MultiValueMap<String, String> map = new LinkedMultiValueMap<String, String>(); //添加请求参数images,并将Base64编码的图片传入 map.add("images", ImageToBase64(bytes)); //构建请求 HttpEntity<MultiValueMap<String, String>> request = new HttpEntity<MultiValueMap<String, String>>(map, headers); RestTemplate restTemplate = new RestTemplate(); //发送请求, springboot内置的restTemplate Map json = restTemplate.postForEntity("http://127.0.0.1:8868/predict/ocr_system", request, Map.class).getBody(); System.out.println(json); List<List<Map>> jsons = (List<List<Map>>) json.get("results"); System.out.println(jsons); for (int i = 0; i < jsons.get(0).size(); i++) { System.out.println("当前的文字是:" + jsons.get(0).get(i).get("text")); // 这里光靠这个trim()有些空格是去除不掉的,所以还需要使用替换这个,双重保险 result.append(jsons.get(0).get(i).get("text").toString().trim().replace(" ", "")); } String trim = result.toString().trim(); System.out.println("=================拼接后的文字是========================="); System.out.println(trim); System.out.println("=======================接下来就是使用正则表达提取文字信息了==============================="); List<Map> maps = jsons.get(0); String name = predictName(maps); if (name.equals("") || name == null) { name = fullName(trim); } System.out.println("姓名:" + name); String nation = national(maps); System.out.println("民族:" + nation); String address = address(maps); System.out.println("地址:" + address); String cardNumber = cardNumber(maps); System.out.println("身份证号:" + cardNumber); String sex = sex(cardNumber); System.out.println("性别:" + sex); String birthday = birthday(cardNumber); System.out.println("出生:" + birthday); // return json1; Map<String, String> userInfoMap = new HashMap<>(); userInfoMap.put("name", name); userInfoMap.put("nation", nation); userInfoMap.put("address", address); userInfoMap.put("cardNumber", cardNumber); userInfoMap.put("sex", sex); userInfoMap.put("birthday", birthday); return userInfoMap; } // 上面的方法,使用了static修饰,下面的方法,也需要使用static修饰,这里使用 // private修饰的话,在其他类中直接通过IdCardOcrUtils.predictName()这个就访问不到了, 或者protected修饰, // 不然其他类访问不就行了吗? // 这里唯一能通过IdCardOcrUtils.方法名,访问的是public修饰的方法 /** * 获取身份证姓名 * * @param maps 识别的结果集合 * @return 姓名 */ private static String predictName(List<Map> maps) { String name = ""; for (Map map : maps) { String str = map.get("text").toString().trim().replace(" ", ""); if (str.contains("姓名") || str.contains("名")) { String pattern = ".*名[\\u4e00-\\u9fa5]{1,4}"; Pattern r = Pattern.compile(pattern); Matcher m = r.matcher(str); if (m.matches()) { name = str.substring(str.indexOf("名") + 1); } } } return name; } /** * 为了防止第一次得到的名字为空,以后是遇到什么情况就解决什么情况就行了 * * @param result panddleOCR扫描得到的结果拼接: * 如:姓名韦小宝性别男民族汉出生1654年12月20日住址北京市东城区景山前街4号紫禁城敬事房公民身份证号码11204416541220243X * @return */ private static String fullName(String result) { String name = ""; if (result.contains("性") || result.contains("性别")) { String str = result.substring(0, result.lastIndexOf("性")); String pattern = ".*名[\\u4e00-\\u9fa5]{1,4}"; Pattern r = Pattern.compile(pattern); Matcher m = r.matcher(str); if (m.matches()) { name = str.substring(str.indexOf("名") + 1); } } return name; } /** * 获取民族 * * @param maps 识别的结果集合 * @return 民族信息 */ private static String national(List<Map> maps) { String nation = ""; for (Map map : maps) { String str = map.get("text").toString(); String pattern = ".*民族[\u4e00-\u9fa5]{1,4}"; Pattern r = Pattern.compile(pattern); Matcher m = r.matcher(str); if (m.matches()) { nation = str.substring(str.indexOf("族") + 1); } } return nation; } /** * 获取身份证地址 * * @param maps 识别的结果集合 * @return 身份证地址信息 */ private static String address(List<Map> maps) { String address = ""; StringBuilder addressJoin = new StringBuilder(); for (Map map : maps) { String str = map.get("text").toString().trim().replace(" ", ""); if (str.contains("住址") || str.contains("址") || str.contains("省") || str.contains("市") || str.contains("县") || str.contains("街") || str.contains("乡") || str.contains("村") || str.contains("镇") || str.contains("区") || str.contains("城") || str.contains("组") || str.contains("号") || str.contains("幢") || str.contains("室") ) { addressJoin.append(str); } } String s = addressJoin.toString(); if (s.contains("省") || s.contains("县") || s.contains("住址") || s.contains("址") || s.contains("公民身份证")) { // 通过这里的截取可以知道,即使是名字中有上述的那些字段,也不要紧,因为这个ocr识别是一行一行来的,所以名字的会在地址这两个字 // 前面,除非是名字中也有地址的”地“或者”址“字,这个还可以使用lastIndexOf()来从后往左找,也可以在一定程度上避免这个。 // 具体看后面的截图,就知道了 address = s.substring(s.indexOf("址") + 1, s.indexOf("公民身份证")); } else { address = s; } return address; } /** * 获取身份证号 * * @param maps ocr识别的内容列表 * @return 身份证号码 */ private static String cardNumber(List<Map> maps) { String cardNumber = ""; for (Map map : maps) { String str = map.get("text").toString().trim().replace(" ", ""); // 之里注意了,这里的双斜杆,是因为这里是java,\会转义,所以使用双鞋干\\,去掉试一试就知道了 String pattern = "\\d{17}[\\d|x|X]|\\d{15}"; Pattern r = Pattern.compile(pattern); Matcher m = r.matcher(str); if (m.matches()) { cardNumber = str; } } return cardNumber; } /** * 二代身份证18位 * 这里之所以这样做,是因为如果直接从里面截取,也可以,但是从打印的内容中,有时候 * 性别性别男,是在同一行,有些照片是 * 性 * 别 * 男 * 等,如果单纯是使用字符串的str.contains("男") ==》 然后返回性别男, * str.contains("女") ==> 然后返回性别女 * 这个万姓名中有男字,地址中有男字,等。而这个人的性别是女。这是可能会按照识别顺序 * 排序之后,识别的是地址的男字,所以这里直接从身份证倒数第二位的奇偶性判断男女更加准确一点 * 从身份证号码中提取性别 * * @param cardNumber 身份证号码,二代身份证18位 * @return 性别 */ private static String sex(String cardNumber) { String sex = ""; // 取倒身份证倒数第二位的数字的奇偶性判断性别,二代身份证18位 String substring = cardNumber.substring(cardNumber.length() - 2, cardNumber.length() - 1); int parseInt = Integer.parseInt(substring); if (parseInt % 2 == 0) { sex = "女"; } else { sex = "男"; } return sex; } /** * 从身份证中获取出生信息 * * @param cardNumber 二代身份证,18位 * @return 出生日期 */ private static String birthday(String cardNumber) { String birthday = ""; String date = cardNumber.substring(6, 14); String year = date.substring(0, 4); String month = date.substring(4, 6); String day = date.substring(6, 8); birthday = year + "年" + month + "月" + day + "日"; return birthday; } /** * 获取图片的base64位 * @param data 图片变成byte数组 * @return 图片的base64为内容 */ private static String ImageToBase64(byte[] data) { // 直接调用springboot内置的springframework内置的犯法 String encodeToString = Base64Utils.encodeToString(data); return encodeToString; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
传入如下三张图片

注:图片来源于网络,如有不对的地方,请联系删除一下
注:图片来源于网络,如有不对的地方,请联系删除一下

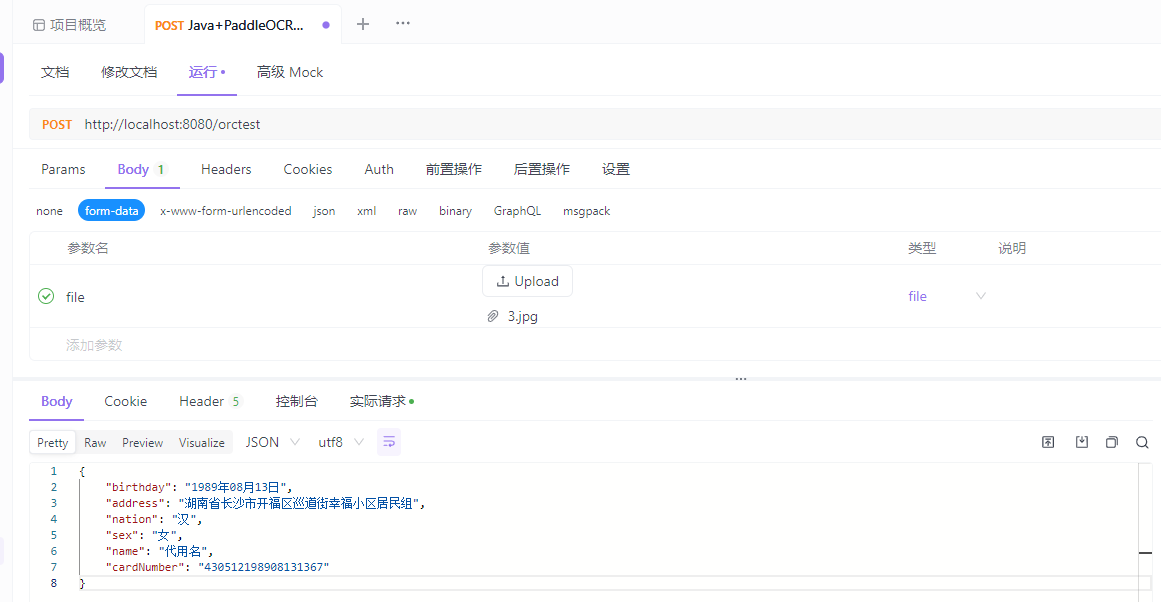
结果如下所示:
从GIF中,可以看图片识别的结果,apifox的内容,因为这里的性别是从身份证倒数第二位的奇偶性判断的,所以!!!
性别这里不用管它,这个身份证号就是乱填的,所以性别不对很正常的
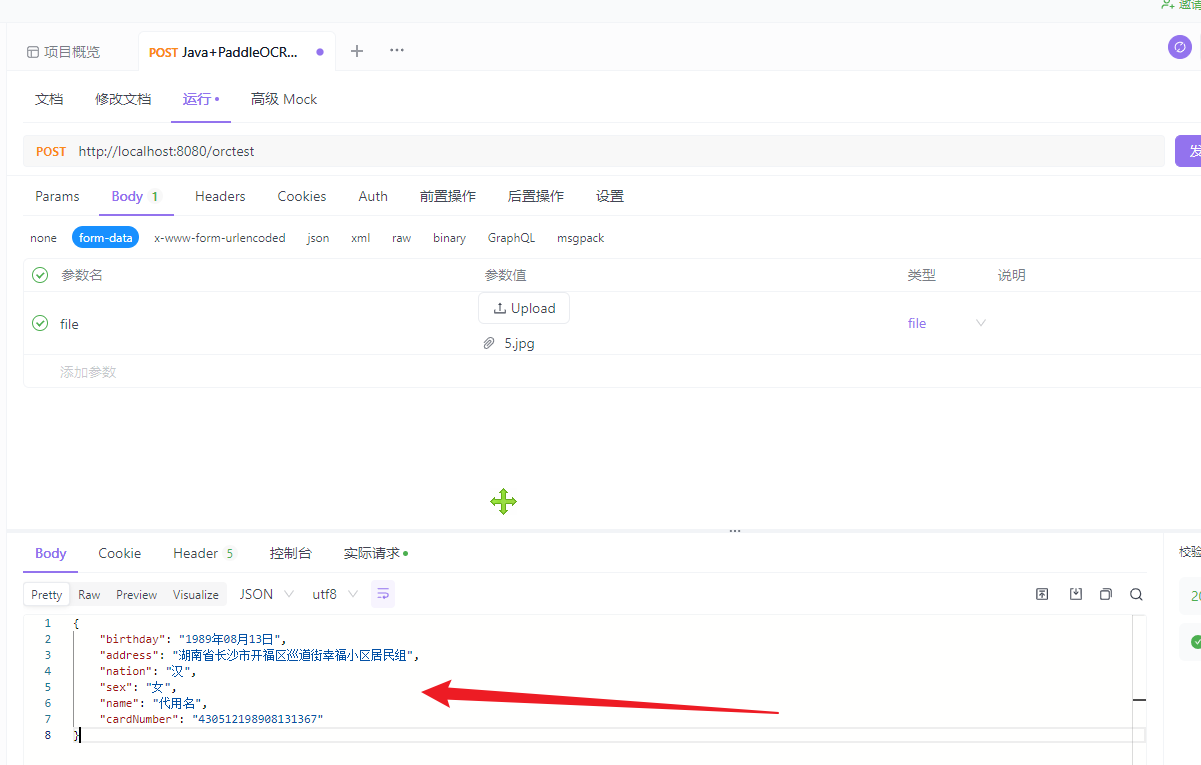
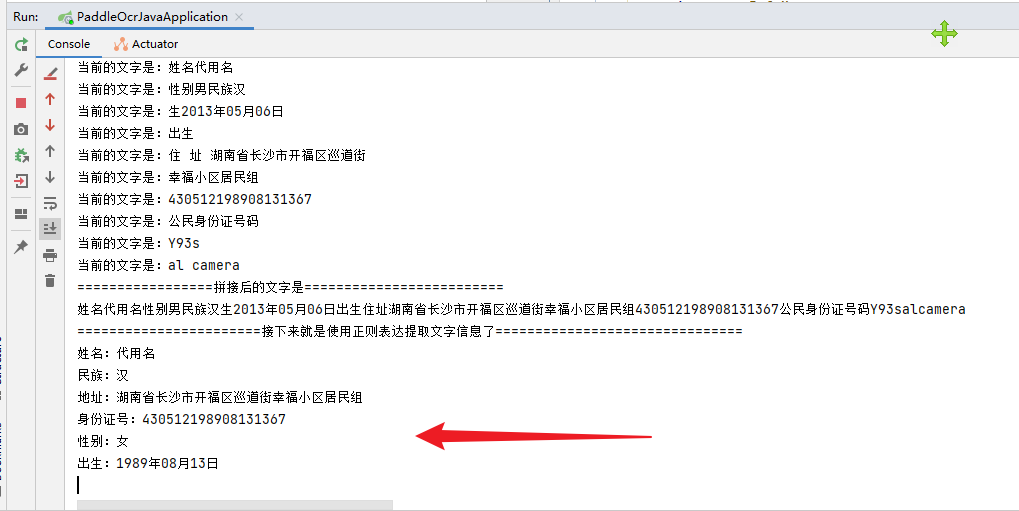
代码中idea打印的内容,至于这里的idea打印的内容,具体看代码就知道了。
因为这里的性别是从身份证倒数第二位的奇偶性判断的,所以!!!
性别这里不用管它,这个身份证号就是乱填的,所以性别不对很正常的
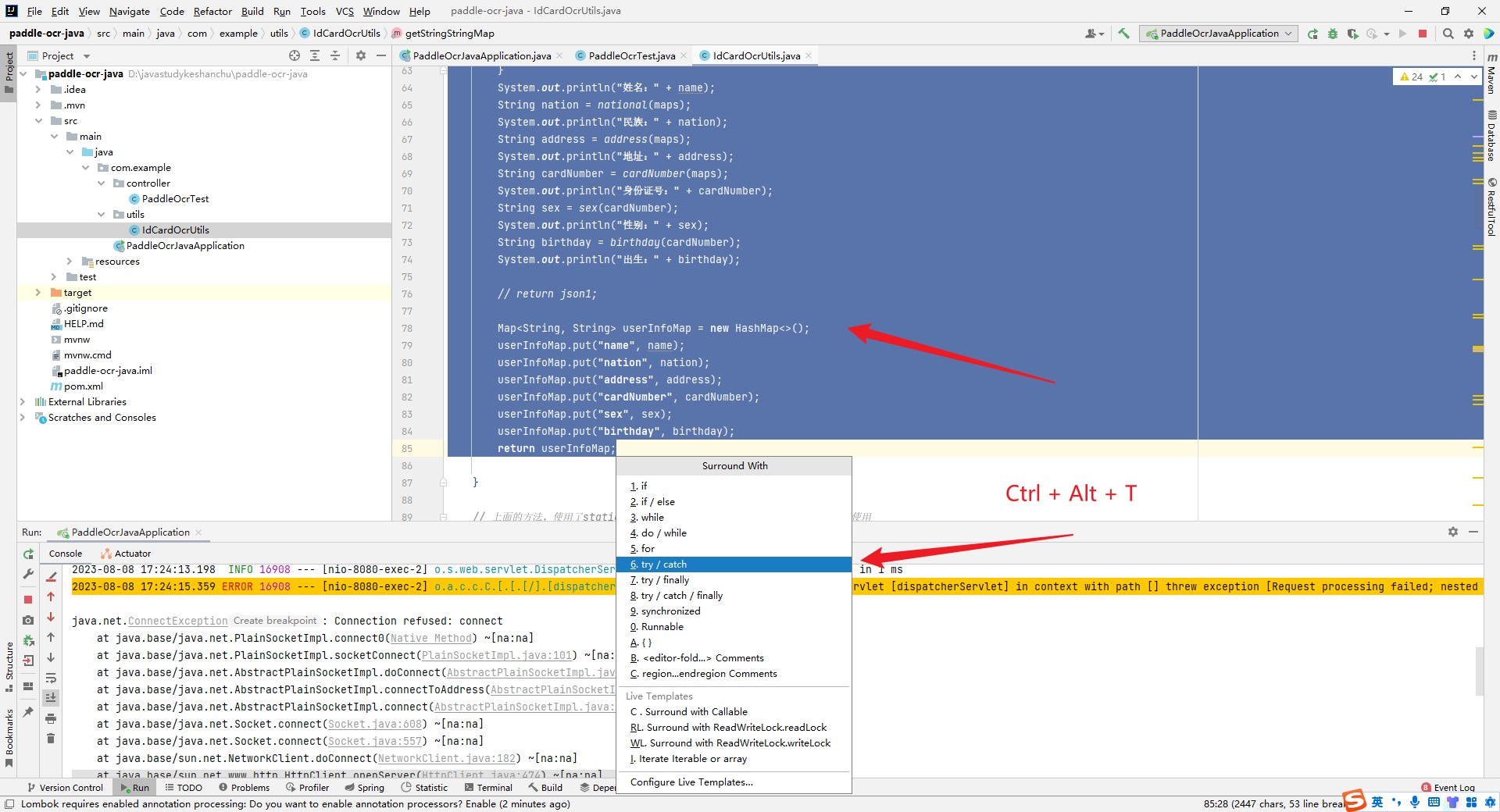
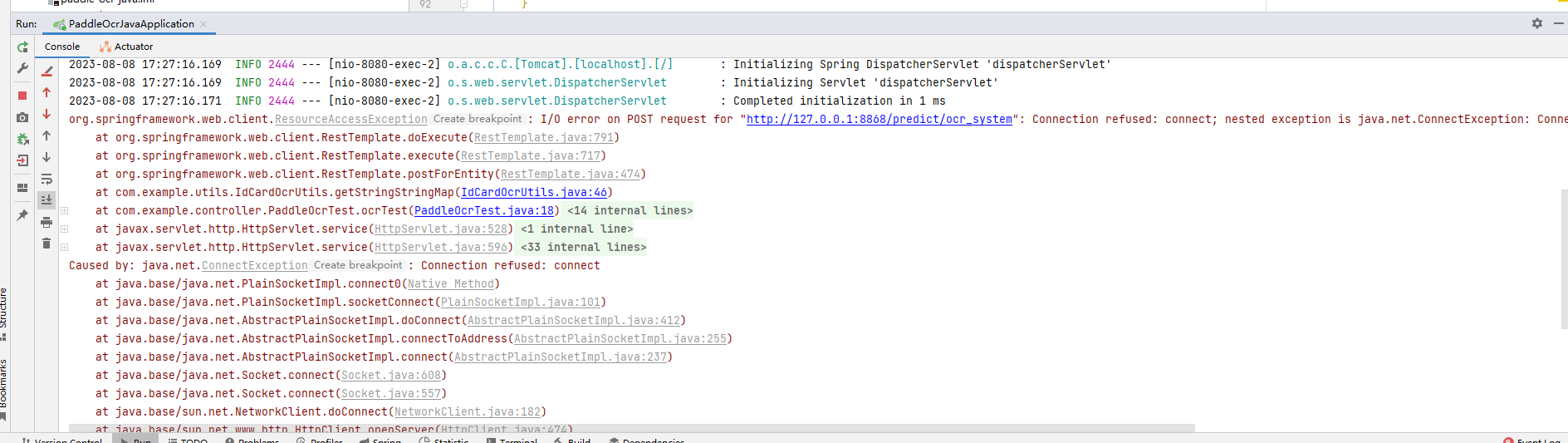
完善代码,提高健壮性
这里进行了一些,处理,防止当PaddleOCR的hubserving部署的服务停止时,Java项目出现异常报错,返回的结果出现问题,对后面的程序造成影响,结果如下图所示:
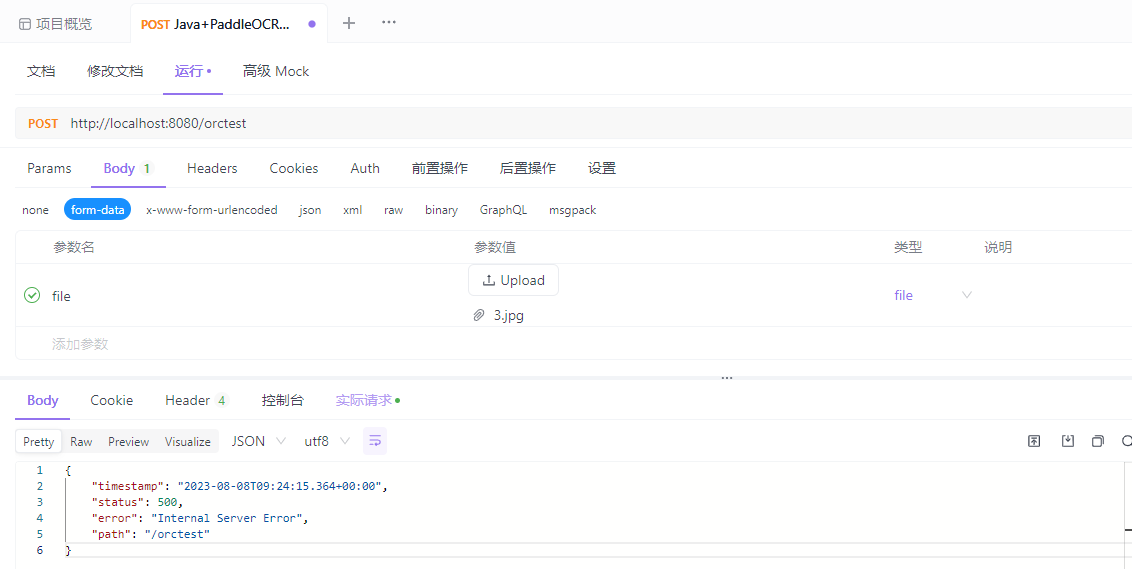
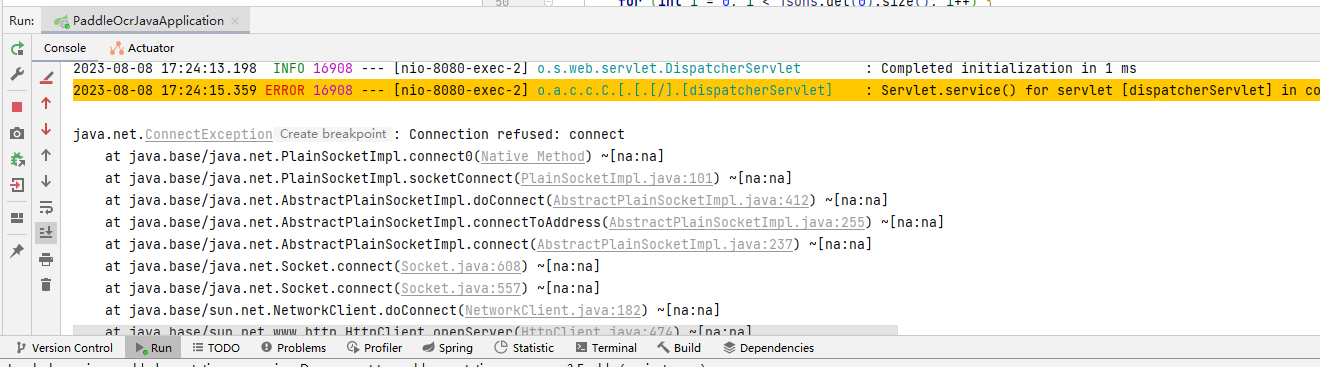
进行处理之后,代码在后面
Controller的代码:
package com.example.controller; import com.example.utils.IdCardOcrUtils; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RestController; import org.springframework.web.multipart.MultipartFile; import java.io.IOException; import java.util.Map; @RestController public class PaddleOcrTest { @PostMapping("/orctest") public Map<String, String> ocrTest(MultipartFile file) { try { byte[] bytes = file.getBytes(); Map<String, String> userInfoMap = IdCardOcrUtils.getStringStringMap(bytes); return userInfoMap; } catch (IOException e) { e.printStackTrace(); return null; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
工具类
package com.example.utils; // import lombok.extern.slf4j.Slf4j; import org.springframework.http.HttpEntity; import org.springframework.http.HttpHeaders; import org.springframework.http.MediaType; import org.springframework.util.Base64Utils; import org.springframework.util.LinkedMultiValueMap; import org.springframework.util.MultiValueMap; import org.springframework.web.client.RestClientException; import org.springframework.web.client.RestTemplate; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.regex.Matcher; import java.util.regex.Pattern; // @Slf4j public class IdCardOcrUtils { private IdCardOcrUtils() { } /** * 身份证完整信息识别 * * @param bytes 输入流,的bytes数组 * @return 身份证信息 */ public static Map<String, String> getStringStringMap(byte[] bytes) { try { StringBuilder result = new StringBuilder(); HttpHeaders headers = new HttpHeaders(); //设置请求头格式 headers.setContentType(MediaType.APPLICATION_JSON); //构建请求参数 MultiValueMap<String, String> map = new LinkedMultiValueMap<String, String>(); //添加请求参数images,并将Base64编码的图片传入 map.add("images", ImageToBase64(bytes)); //构建请求 HttpEntity<MultiValueMap<String, String>> request = new HttpEntity<MultiValueMap<String, String>>(map, headers); RestTemplate restTemplate = new RestTemplate(); //发送请求, springboot内置的restTemplate Map json = restTemplate.postForEntity("http://127.0.0.1:8868/predict/ocr_system", request, Map.class).getBody(); System.out.println(json); List<List<Map>> jsons = (List<List<Map>>) json.get("results"); System.out.println(jsons); for (int i = 0; i < jsons.get(0).size(); i++) { System.out.println("当前的文字是:" + jsons.get(0).get(i).get("text")); // 这里光靠这个trim()有些空格是去除不掉的,所以还需要使用替换这个,双重保险 result.append(jsons.get(0).get(i).get("text").toString().trim().replace(" ", "")); } String trim = result.toString().trim(); System.out.println("=================拼接后的文字是========================="); System.out.println(trim); System.out.println("=======================接下来就是使用正则表达提取文字信息了==============================="); List<Map> maps = jsons.get(0); String name = predictName(maps); if (name.equals("") || name == null) { name = fullName(trim); } System.out.println("姓名:" + name); String nation = national(maps); System.out.println("民族:" + nation); String address = address(maps); System.out.println("地址:" + address); String cardNumber = cardNumber(maps); System.out.println("身份证号:" + cardNumber); String sex = sex(cardNumber); System.out.println("性别:" + sex); String birthday = birthday(cardNumber); System.out.println("出生:" + birthday); // return json1; Map<String, String> userInfoMap = new HashMap<>(); userInfoMap.put("name", name); userInfoMap.put("nation", nation); userInfoMap.put("address", address); userInfoMap.put("cardNumber", cardNumber); userInfoMap.put("sex", sex); userInfoMap.put("birthday", birthday); return userInfoMap; } catch (RestClientException e) { // log.info("请启动身份证识别服务部署!!!以下报错并不会影响运行,所以这个异常不需要特别关心它,这个异常已经处理了!!!"); // System.out.println("请启动身份证识别服务部署!!!以下报错并不会影响运行,所以这个异常不需要特别关心它,这个异常已经处理了!!!"); e.printStackTrace(); // Map<String, String> maps = new HashMap<>(); // maps.put("names", ""); return null; } } // 上面的方法,使用了static修饰,下面的方法,也需要使用static修饰,这里使用 // private修饰的话,在其他类中直接通过IdCardOcrUtils.predictName()这个就访问不到了, 或者protected修饰, // 不然其他类访问不就行了吗? // 这里唯一能通过IdCardOcrUtils.方法名,访问的是public修饰的方法 /** * 获取身份证姓名 * * @param maps 识别的结果集合 * @return 姓名 */ private static String predictName(List<Map> maps) { String name = ""; for (Map map : maps) { String str = map.get("text").toString().trim().replace(" ", ""); if (str.contains("姓名") || str.contains("名")) { String pattern = ".*名[\\u4e00-\\u9fa5]{1,4}"; Pattern r = Pattern.compile(pattern); Matcher m = r.matcher(str); if (m.matches()) { name = str.substring(str.indexOf("名") + 1); } } } return name; } /** * 为了防止第一次得到的名字为空,以后是遇到什么情况就解决什么情况就行了 * * @param result panddleOCR扫描得到的结果拼接: * 如:姓名韦小宝性别男民族汉出生1654年12月20日住址北京市东城区景山前街4号紫禁城敬事房公民身份证号码11204416541220243X * @return */ private static String fullName(String result) { String name = ""; if (result.contains("性") || result.contains("性别")) { String str = result.substring(0, result.lastIndexOf("性")); String pattern = ".*名[\\u4e00-\\u9fa5]{1,4}"; Pattern r = Pattern.compile(pattern); Matcher m = r.matcher(str); if (m.matches()) { name = str.substring(str.indexOf("名") + 1); } } return name; } /** * 获取民族 * * @param maps 识别的结果集合 * @return 民族信息 */ private static String national(List<Map> maps) { String nation = ""; for (Map map : maps) { String str = map.get("text").toString(); String pattern = ".*民族[\u4e00-\u9fa5]{1,4}"; Pattern r = Pattern.compile(pattern); Matcher m = r.matcher(str); if (m.matches()) { nation = str.substring(str.indexOf("族") + 1); } } return nation; } /** * 获取身份证地址 * * @param maps 识别的结果集合 * @return 身份证地址信息 */ private static String address(List<Map> maps) { String address = ""; StringBuilder addressJoin = new StringBuilder(); for (Map map : maps) { String str = map.get("text").toString().trim().replace(" ", ""); if (str.contains("住址") || str.contains("址") || str.contains("省") || str.contains("市") || str.contains("县") || str.contains("街") || str.contains("乡") || str.contains("村") || str.contains("镇") || str.contains("区") || str.contains("城") || str.contains("组") || str.contains("号") || str.contains("幢") || str.contains("室") ) { addressJoin.append(str); } } String s = addressJoin.toString(); if (s.contains("省") || s.contains("县") || s.contains("住址") || s.contains("址") || s.contains("公民身份证")) { // 通过这里的截取可以知道,即使是名字中有上述的那些字段,也不要紧,因为这个ocr识别是一行一行来的,所以名字的会在地址这两个字 // 前面,除非是名字中也有地址的”地“或者”址“字,这个还可以使用lastIndexOf()来从后往左找,也可以在一定程度上避免这个。 // 具体看后面的截图,就知道了 address = s.substring(s.indexOf("址") + 1, s.indexOf("公民身份证")); } else { address = s; } return address; } /** * 获取身份证号 * * @param maps ocr识别的内容列表 * @return 身份证号码 */ private static String cardNumber(List<Map> maps) { String cardNumber = ""; for (Map map : maps) { String str = map.get("text").toString().trim().replace(" ", ""); // 之里注意了,这里的双斜杆,是因为这里是java,\会转义,所以使用双鞋干\\,去掉试一试就知道了 String pattern = "\\d{17}[\\d|x|X]|\\d{15}"; Pattern r = Pattern.compile(pattern); Matcher m = r.matcher(str); if (m.matches()) { cardNumber = str; } } return cardNumber; } /** * 二代身份证18位 * 这里之所以这样做,是因为如果直接从里面截取,也可以,但是从打印的内容中,有时候 * 性别性别男,是在同一行,有些照片是 * 性 * 别 * 男 * 等,如果单纯是使用字符串的str.contains("男") ==》 然后返回性别男, * str.contains("女") ==> 然后返回性别女 * 这个万姓名中有男字,地址中有男字,等。而这个人的性别是女。这是可能会按照识别顺序 * 排序之后,识别的是地址的男字,所以这里直接从身份证倒数第二位的奇偶性判断男女更加准确一点 * 从身份证号码中提取性别 * * @param cardNumber 身份证号码,二代身份证18位 * @return 性别 */ private static String sex(String cardNumber) { String sex = ""; // 取倒身份证倒数第二位的数字的奇偶性判断性别,二代身份证18位 String substring = cardNumber.substring(cardNumber.length() - 2, cardNumber.length() - 1); int parseInt = Integer.parseInt(substring); if (parseInt % 2 == 0) { sex = "女"; } else { sex = "男"; } return sex; } /** * 从身份证中获取出生信息 * * @param cardNumber 二代身份证,18位 * @return 出生日期 */ private static String birthday(String cardNumber) { String birthday = ""; String date = cardNumber.substring(6, 14); String year = date.substring(0, 4); String month = date.substring(4, 6); String day = date.substring(6, 8); birthday = year + "年" + month + "月" + day + "日"; return birthday; } /** * 获取图片的base64位 * * @param data 图片变成byte数组 * @return 图片的base64为内容 */ private static String ImageToBase64(byte[] data) { // 直接调用springboot内置的springframework内置的犯法 String encodeToString = Base64Utils.encodeToString(data); return encodeToString; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
启动PaddleOCR的hubserving部署时

代码在码云:Java + PaddleOCR身份证识别: 这个是使用百度的Java + PaddleOCR识别身份证信息!!! - Gitee.com
结合vue2+element实现身份证识别
介绍 — Vue.js (vuejs.org), 我今天去vue2官网看的时候,发现有一个公告,说vue2停止准备停止更新了。看这里就知道了Vue.js (vuejs.org)。
element UI的官网如下所示组件 | Element
注意了这里只是实现功能而已,至于样式什么的我就不设置了,这个毕竟是一个示例,没必要写得这么详细,如果是样式问题,可以看着修改就行了。这里样式就不考虑了,只考虑实现功能!!!注意了这里的Java实现了身份证的正反面识别,代码中的前端只实现了正面识别的展示,反面识别同样的道理,可以看自己的需求添加身份证发面识别的展示,这里就不写出来了,跟正面识别用一个道理!!!
完整代码如下所示
pom.xml,跟上面一样,并没有变
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.7.10</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.example</groupId> <artifactId>paddle-ocr-java</artifactId> <version>0.0.1-SNAPSHOT</version> <name>paddle-ocr-java</name> <description>paddle-ocr-java</description> <properties> <java.version>11</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> </plugins> </build> </project>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
PaddleOcrTest.java
package com.example.controller; import com.example.utils.IdCardOcrUtils; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import org.springframework.web.multipart.MultipartFile; import java.io.IOException; import java.util.Map; @RestController public class PaddleOcrTest { /** * 身份证正面识别 * @param file 文件名 * @return 身份证正面信息的Map集合,包括姓名、性别、民族、住址、出生、身份证号码 */ @PostMapping("/orctest") public Map<String, String> ocrTest(MultipartFile file) { try { byte[] bytes = file.getBytes(); // 这里可以考虑将前端页面上传的文件保存到文件夹中,返回图片的访问地址给前端。 // 也可考虑转成base64位,把base64位返回给前端。 // 或者在前端那里直接将图片转base64位,然后将base64位的图片赋值到对应的字段中,提交后保存到数据库中 // 然后用户在前端点击提交用户信息时,将对应的信息保存到数据库中 Map<String, String> userInfoMap = IdCardOcrUtils.getStringStringMap(bytes); // userInfoMap.put("imgUrl", "图片的访问地址或者图片的base64位"); return userInfoMap; } catch (IOException e) { e.printStackTrace(); return null; } } /** * 身份证反面识别功能 * @param file 传入的文件 * @return 身份证反面信息,Map集合,包括身份证反面的:签发机关、有效期限 */ @RequestMapping("/ocrfanmian") public Map<String, String> ocrFanMian(MultipartFile file) { try { byte[] bytes = file.getBytes(); // 这里可以考虑将前端页面上传的文件保存到文件夹中,返回图片的访问地址给前端。 // 也可考虑转成base64位,把base64位返回给前端。 // 或者在前端那里直接将图片转base64位,然后将base64位的图片赋值到对应的字段中,提交后保存到数据库中 // 然后用户在前端点击提交用户信息时,将对应的信息保存到数据库中 Map<String, String> fanmianInfo = IdCardOcrUtils.getFanMian(bytes); // fanmianInfo.put("imgUrl", "图片的访问地址或者图片的base64位"); return fanmianInfo; } catch (IOException e) { e.printStackTrace(); return null; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
IdCardOcrUtils.java
package com.example.utils; // import lombok.extern.slf4j.Slf4j; import org.springframework.http.HttpEntity; import org.springframework.http.HttpHeaders; import org.springframework.http.MediaType; import org.springframework.util.Base64Utils; import org.springframework.util.LinkedMultiValueMap; import org.springframework.util.MultiValueMap; import org.springframework.web.client.RestClientException; import org.springframework.web.client.RestTemplate; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.regex.Matcher; import java.util.regex.Pattern; // @Slf4j public class IdCardOcrUtils { private IdCardOcrUtils() { } /** * 身份证正面完整信息识别 * * @param bytes 输入流,的bytes数组 * @return 身份证正面信息的Map集合,包括姓名、性别、民族、住址、出生、身份证号码 */ public static Map<String, String> getStringStringMap(byte[] bytes) { try { StringBuilder result = new StringBuilder(); HttpHeaders headers = new HttpHeaders(); //设置请求头格式 headers.setContentType(MediaType.APPLICATION_JSON); //构建请求参数 MultiValueMap<String, String> map = new LinkedMultiValueMap<String, String>(); //添加请求参数images,并将Base64编码的图片传入 map.add("images", ImageToBase64(bytes)); //构建请求 HttpEntity<MultiValueMap<String, String>> request = new HttpEntity<MultiValueMap<String, String>>(map, headers); RestTemplate restTemplate = new RestTemplate(); //发送请求, springboot内置的restTemplate Map json = restTemplate.postForEntity("http://127.0.0.1:8868/predict/ocr_system", request, Map.class).getBody(); System.out.println(json); List<List<Map>> jsons = (List<List<Map>>) json.get("results"); System.out.println(jsons); for (int i = 0; i < jsons.get(0).size(); i++) { System.out.println("当前的文字是:" + jsons.get(0).get(i).get("text")); // 这里光靠这个trim()有些空格是去除不掉的,所以还需要使用替换这个,双重保险 result.append(jsons.get(0).get(i).get("text").toString().trim().replace(" ", "")); } String trim = result.toString().trim(); System.out.println("=================拼接后的文字是========================="); System.out.println(trim); System.out.println("=======================接下来就是使用正则表达提取文字信息了==============================="); List<Map> maps = jsons.get(0); String name = predictName(maps); if (name.equals("") || name == null) { name = fullName(trim); } System.out.println("姓名:" + name); String nation = national(maps); System.out.println("民族:" + nation); String address = address(maps); System.out.println("地址:" + address); String cardNumber = cardNumber(maps); System.out.println("身份证号:" + cardNumber); String sex = sex(cardNumber); System.out.println("性别:" + sex); String birthday = birthday(cardNumber); System.out.println("出生:" + birthday); // return json1; Map<String, String> userInfoMap = new HashMap<>(); userInfoMap.put("name", name); userInfoMap.put("nation", nation); userInfoMap.put("address", address); userInfoMap.put("cardNumber", cardNumber); userInfoMap.put("sex", sex); userInfoMap.put("birthday", birthday); return userInfoMap; } catch (RestClientException e) { // log.info("请启动身份证识别服务部署!!!以下报错并不会影响运行,所以这个异常不需要特别关心它,这个异常已经处理了!!!"); // System.out.println("请启动身份证识别服务部署!!!以下报错并不会影响运行,所以这个异常不需要特别关心它,这个异常已经处理了!!!"); e.printStackTrace(); // Map<String, String> maps = new HashMap<>(); // maps.put("names", ""); return null; } } /** * 身份证反面识别 * * @param bytes 图片的byte字节数组 * @return 身份证反面信息,Map集合,包括身份证反面的:签发机关、有效期限 */ public static Map<String, String> getFanMian(byte[] bytes) { try { StringBuilder result = new StringBuilder(); HttpHeaders headers = new HttpHeaders(); //设置请求头格式 headers.setContentType(MediaType.APPLICATION_JSON); //构建请求参数 MultiValueMap<String, String> map = new LinkedMultiValueMap<String, String>(); //添加请求参数images,并将Base64编码的图片传入 map.add("images", ImageToBase64(bytes)); //构建请求 HttpEntity<MultiValueMap<String, String>> request = new HttpEntity<MultiValueMap<String, String>>(map, headers); RestTemplate restTemplate = new RestTemplate(); //发送请求, springboot内置的restTemplate Map json = restTemplate.postForEntity("http://127.0.0.1:8868/predict/ocr_system", request, Map.class).getBody(); System.out.println(json); List<List<Map>> jsons = (List<List<Map>>) json.get("results"); System.out.println(jsons); for (int i = 0; i < jsons.get(0).size(); i++) { System.out.println("当前的文字是:" + jsons.get(0).get(i).get("text")); // 这里光靠这个trim()有些空格是去除不掉的,所以还需要使用替换这个,双重保险 result.append(jsons.get(0).get(i).get("text").toString().trim().replace(" ", "")); } String trim = result.toString().trim(); List<Map> maps = jsons.get(0); // 身份证反面签发机关 String qianFaJiGuan = qianFaJiGuan(maps); // 身份证反面有效期限 String youXiaoQiXian = youXiaoQiXian(maps); Map<String, String> mapsInfo = new HashMap<>(); mapsInfo.put("qianFaJiGuan", qianFaJiGuan); mapsInfo.put("youXiaoQiXian", youXiaoQiXian); // maps.put("flag", "back"); 本来想放一个标记的,用来标记正反面 return mapsInfo; } catch (RestClientException e) { e.printStackTrace(); return null; } } // 下面代码中有好多地方使用到了正则表达式 // 上面的方法,使用了static修饰,下面的方法,也需要使用static修饰,这里使用 // private修饰的话,在其他类中直接通过IdCardOcrUtils.predictName()这个就访问不到了, 或者protected修饰, // 不然其他类访问不就行了吗? // 这里唯一能通过IdCardOcrUtils.方法名,访问的是public修饰的方法 /** * 获取身份证姓名 * * @param maps 识别的结果集合 * @return 姓名 */ private static String predictName(List<Map> maps) { String name = ""; for (Map map : maps) { String str = map.get("text").toString().trim().replace(" ", ""); if (str.contains("姓名") || str.contains("名")) { String pattern = ".*名[\\u4e00-\\u9fa5]{1,4}"; Pattern r = Pattern.compile(pattern); Matcher m = r.matcher(str); if (m.matches()) { name = str.substring(str.indexOf("名") + 1); } } } return name; } /** * 为了防止第一次得到的名字为空,以后是遇到什么情况就解决什么情况就行了 * * @param result panddleOCR扫描得到的结果拼接: * 如:姓名韦小宝性别男民族汉出生1654年12月20日住址北京市东城区景山前街4号紫禁城敬事房公民身份证号码11204416541220243X * @return */ private static String fullName(String result) { String name = ""; if (result.contains("性") || result.contains("性别")) { String str = result.substring(0, result.lastIndexOf("性")); String pattern = ".*名[\\u4e00-\\u9fa5]{1,4}"; Pattern r = Pattern.compile(pattern); Matcher m = r.matcher(str); if (m.matches()) { name = str.substring(str.indexOf("名") + 1); } } return name; } /** * 获取民族 * * @param maps 识别的结果集合 * @return 民族信息 */ private static String national(List<Map> maps) { String nation = ""; for (Map map : maps) { String str = map.get("text").toString(); String pattern = ".*民族[\u4e00-\u9fa5]{1,4}"; Pattern r = Pattern.compile(pattern); Matcher m = r.matcher(str); if (m.matches()) { nation = str.substring(str.indexOf("族") + 1); } } return nation; } /** * 获取身份证地址 * * @param maps 识别的结果集合 * @return 身份证地址信息 */ private static String address(List<Map> maps) { String address = ""; StringBuilder addressJoin = new StringBuilder(); for (Map map : maps) { String str = map.get("text").toString().trim().replace(" ", ""); // 看身份证地址那一栏,具体可以看一下自己的身份证,几乎都包含这些字,具体可以自己debugger看一下就知道了 // 具体可以自己debugger看一下就知道了 if (str.contains("住址") || str.contains("址") || str.contains("省") || str.contains("市") || str.contains("县") || str.contains("街") || str.contains("乡") || str.contains("村") || str.contains("镇") || str.contains("区") || str.contains("城") || str.contains("组") || str.contains("号") || str.contains("幢") || str.contains("室") ) { addressJoin.append(str); } } String s = addressJoin.toString(); if (s.contains("省") || s.contains("县") || s.contains("住址") || s.contains("址") || s.contains("公民身份证")) { // 通过这里的截取可以知道,即使是名字中有上述的那些字段,也不要紧,因为这个ocr识别是一行一行来的,所以名字的会在地址这两个字 // 前面,除非是名字中也有地址的”地“或者”址“字,这个还可以使用lastIndexOf()来从后往左找,也可以在一定程度上避免这个。 // 具体看后面的截图,就知道了 address = s.substring(s.indexOf("址") + 1, s.indexOf("公民身份证")); } else { address = s; } return address; } /** * 获取身份证号 * * @param maps ocr识别的内容列表 * @return 身份证号码 */ private static String cardNumber(List<Map> maps) { String cardNumber = ""; for (Map map : maps) { String str = map.get("text").toString().trim().replace(" ", ""); // 之里注意了,这里的双斜杆,是因为这里是java,\会转义,所以使用双鞋干\\,去掉试一试就知道了 String pattern = "\\d{17}[\\d|x|X]|\\d{15}"; Pattern r = Pattern.compile(pattern); Matcher m = r.matcher(str); if (m.matches()) { cardNumber = str; } } return cardNumber; } /** * 二代身份证18位 * 这里之所以这样做,是因为如果直接从里面截取,也可以,但是从打印的内容中,有时候 * 性别性别男,是在同一行,有些照片是 * 性 * 别 * 男 * 等,如果单纯是使用字符串的str.contains("男") ==》 然后返回性别男, * str.contains("女") ==> 然后返回性别女 * 这个万姓名中有男字,地址中有男字,等。而这个人的性别是女。这是可能会按照识别顺序 * 排序之后,识别的是地址的男字,所以这里直接从身份证倒数第二位的奇偶性判断男女更加准确一点 * 从身份证号码中提取性别 * * @param cardNumber 身份证号码,二代身份证18位 * @return 性别 */ private static String sex(String cardNumber) { String sex = ""; // 取倒身份证倒数第二位的数字的奇偶性判断性别,二代身份证18位 String substring = cardNumber.substring(cardNumber.length() - 2, cardNumber.length() - 1); int parseInt = Integer.parseInt(substring); if (parseInt % 2 == 0) { sex = "女"; } else { sex = "男"; } return sex; } /** * 从身份证中获取出生信息 * * @param cardNumber 二代身份证,18位 * @return 出生日期 */ private static String birthday(String cardNumber) { String birthday = ""; String date = cardNumber.substring(6, 14); String year = date.substring(0, 4); String month = date.substring(4, 6); String day = date.substring(6, 8); birthday = year + "年" + month + "月" + day + "日"; return birthday; } /** * 获取图片的base64位 * * @param data 图片变成byte数组 * @return 图片的base64为内容 */ private static String ImageToBase64(byte[] data) { // 直接调用springboot内置的springframework内置的犯法 String encodeToString = Base64Utils.encodeToString(data); return encodeToString; } /** * 获取身份证反面信息的签发机关 * * @param maps ocr识别的内容列表 * @return 身份证反面的签发机关 */ private static String qianFaJiGuan(List<Map> maps) { String qianFaJiGuan = ""; for (Map map : maps) { String str = map.get("text").toString().trim().replace(" ", ""); if (str.contains("公安局")) { // 为什么要有这一步,是因为,有时候身份证的签发机关(这四个字)和XXX公安局,是在一起并且是同一行的, // 如图片比较正的时候,识别得到的结果是:签发机关XXX公安局, // 如果图片是歪的,识别到的结果,签发机关和XXX公安局不在用一行的 // 具体那一张稍微正一点的图片和一张歪一点的图片,debugger,这里看一下就知道了 if (str.contains("签发机关")) { // String为引用类型 str = str.replace("签发机关", ""); } String pattern = ".*公安局"; Pattern r = Pattern.compile(pattern); Matcher m = r.matcher(str); if (m.matches()) { qianFaJiGuan = str; } } } return qianFaJiGuan; } /** * 身份证反面有效期识别 * * @param maps ocr识别的内容列表 * @return 身份证的有效期 */ private static String youXiaoQiXian(List<Map> maps) { String youXiaoQiXian = ""; for (Map map : maps) { String str = map.get("text").toString().trim().replace(" ", ""); // 为什么要有这一步,是因为,有时候身份证的有效期限(这四个字)和日期是在一起并且是同一行的, // 如图片比较正的时候,识别得到的结果是:效期期限2016.02.01-2026.02.01 // 如果图片是歪的,识别到的结果,有效期限和日期不在用一行的 // 具体那一张稍微正一点的图片和一张歪一点的图片,debugger,这里看一下就知道了 if (str.contains("有效期限")) { // String为引用类型 str = str.replace("有效期限", ""); } String pattern = "\\d{4}(\\-|\\/|.)\\d{1,2}\\1\\d{1,2}-\\d{4}(\\-|\\/|.)\\d{1,2}\\1\\d{1,2}"; Pattern r = Pattern.compile(pattern); Matcher m = r.matcher(str); if (m.matches()) { youXiaoQiXian = str; } } return youXiaoQiXian; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
vue-element-ocr_test.html,的代码如下所示,下面所示的代码中因为引入的是在线的vue和element UI,所以运行代码的时候需要联网
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>PaddleOCR身份证识别</title> <!-- 在线引入vue,具体看官网:https://v2.cn.vuejs.org/v2/guide/ --> <script src="https://cdn.jsdelivr.net/npm/vue@2"></script> <!-- 下面是在线引入element ui的样式和组件库,具体看官网:https://element.eleme.cn/#/zh-CN/component/installation --> <!-- 引入样式 --> <link rel="stylesheet" href="https://unpkg.com/element-ui/lib/theme-chalk/index.css"> <!-- 引入组件库 --> <script src="https://unpkg.com/element-ui/lib/index.js"></script> </head> <body> <div id="app"> <el-row> <!-- 注意了,这里是element UI的组件库用法,不同的组件库上传文件的配置或者返回的结果是不一样的,这里只是举一个例子 --> <!-- 如vant和element UI组件库上传文件的操作也是不一样的,看对应的官网然后进行相对应的开发就可以了 --> <el-upload action="http://localhost:8080/orctest" list-type="picture-card" :on-preview="handlePictureCardPreview" :on-remove="handleRemove" :on-success="handleSuccess"> <i class="el-icon-plus"></i> </el-upload> <el-dialog :visible.sync="dialogVisible"> <img width="100%" :src="dialogImageUrl" alt=""> </el-dialog> </el-row> <el-row style="width: 400px; margin-top: 10px;"> <!-- 这里只是一个示例,就不考虑表单验证之类的了 --> <el-form ref="form" :model="userInfoForm" label-width="80px"> <el-form-item label="姓名"> <el-input v-model="userInfoForm.name"></el-input> </el-form-item> <el-form-item label="民族"> <el-input v-model="userInfoForm.nation"></el-input> </el-form-item> <el-form-item label="性别"> <el-radio-group v-model="userInfoForm.sex"> <el-radio label="男"></el-radio> <el-radio label="女"></el-radio> </el-radio-group> </el-form-item> <el-form-item label="住址"> <el-input type="textarea" v-model="userInfoForm.address"></el-input> </el-form-item> <el-form-item label="身份证号"> <el-input v-model="userInfoForm.cardNumber"></el-input> </el-form-item> <el-form-item> <el-button type="primary" @click="onSubmit">提交表单</el-button> <el-button>取消</el-button> </el-form-item> </el-form> </el-row> </div> <script> var app = new Vue({ el: '#app', data: { userInfoForm: { name: undefined, nation: undefined, address: undefined, cardNumber: '', sex: undefined, birthday: '' }, dialogImageUrl: '', dialogVisible: false }, methods: { // element UI中el-upload图片上传成功时的回调,详情看官网 // https://element.eleme.cn/#/zh-CN/component/upload handleSuccess(response, file, fileList) { console.log(response) this.userInfoForm = response }, handleRemove(file, fileList) { console.log(file, fileList); if (fileList.length == 0) { this.userInfoForm = { name: undefined, nation: undefined, address: undefined, cardNumber: undefined, sex: undefined, birthday: undefined } } }, handlePictureCardPreview(file) { this.dialogImageUrl = file.url; this.dialogVisible = true; }, // 发送axios请求,将表单数据保存的数据库中 onSubmit() { // 这里可以发送axios请求,将表单数据保存到数据库中 } } }) </script> </body> </html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
结果如下面的GIF图所示
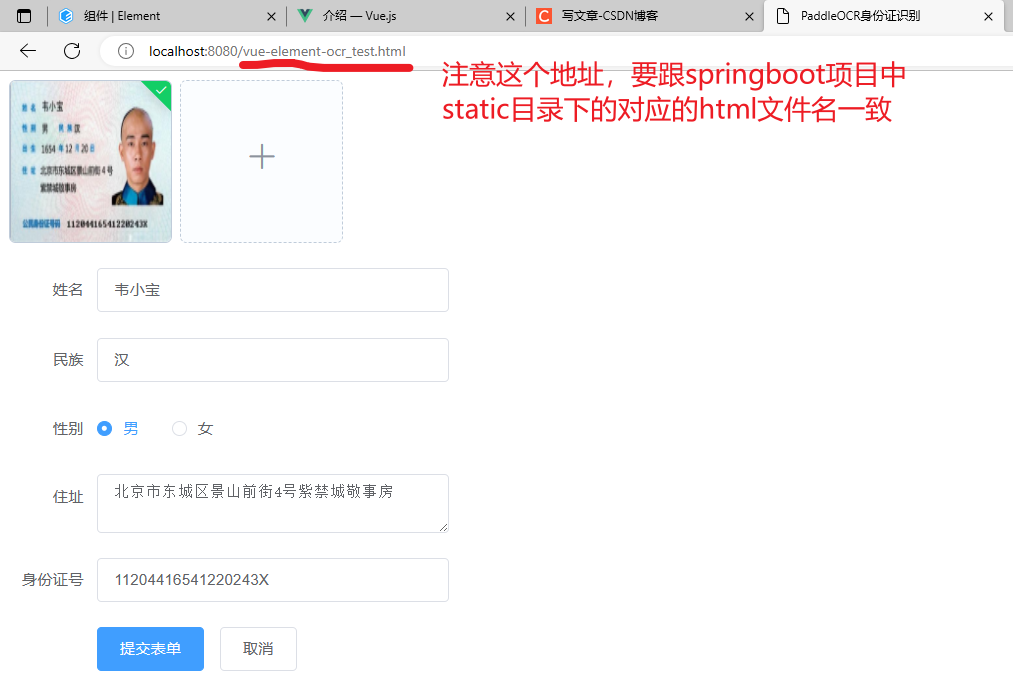
正图图片和偏移图片的区别
这里可以不看的,我在上面的代码已经考虑过了。为什么要写这个呢,我之前是想着直接把所有内容拼接在一起:如下图所示的idea打印的结果:

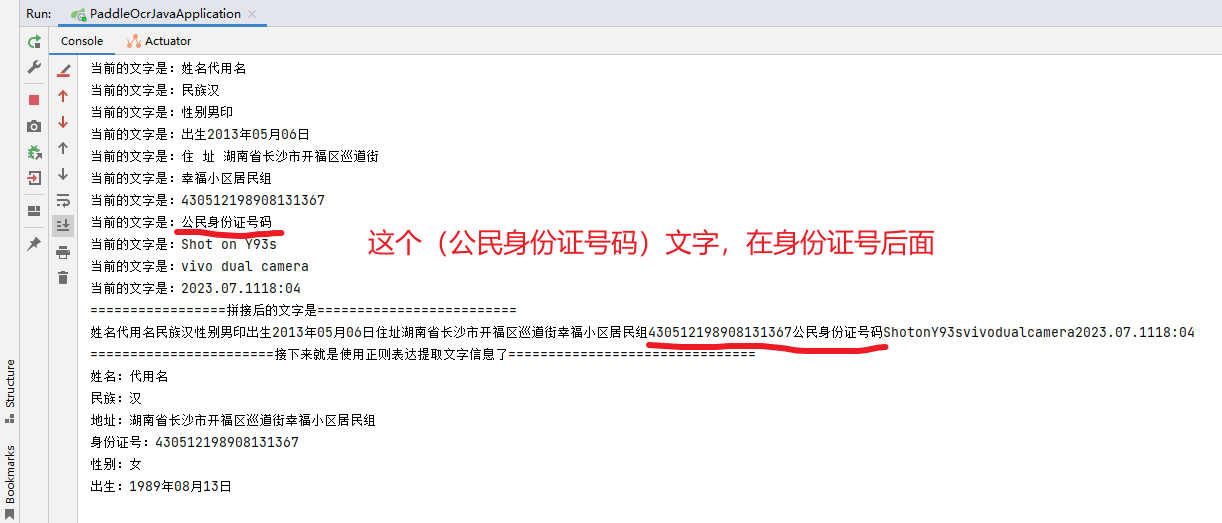
但是这里有问题,具体看后面的解释!!!然后根据身份证的特定字段如:姓名、性别、出生、住址、公民身份证号码。这些固定的字段,截取内容,如使用Java对str.substring(str.indexOf(“姓名”) ,str.idnexOf(“性别”))的字符串的截取,就可以得到对应的名字。具体看idea打印的内容截图就知道了,特别是下面画红线的内容。但是后面发现歪了一些的图片(只要不是歪得太离谱)的文字位置不一定对,就像下面划线的内容,OCR得到的结果不一定是按照身份证上面的顺序排列文字的,所以我就在代码中考虑了使用正则表达式的匹配的方式了。这样就不需要知道位置了。这里写这个是单存记录一下这个过程。
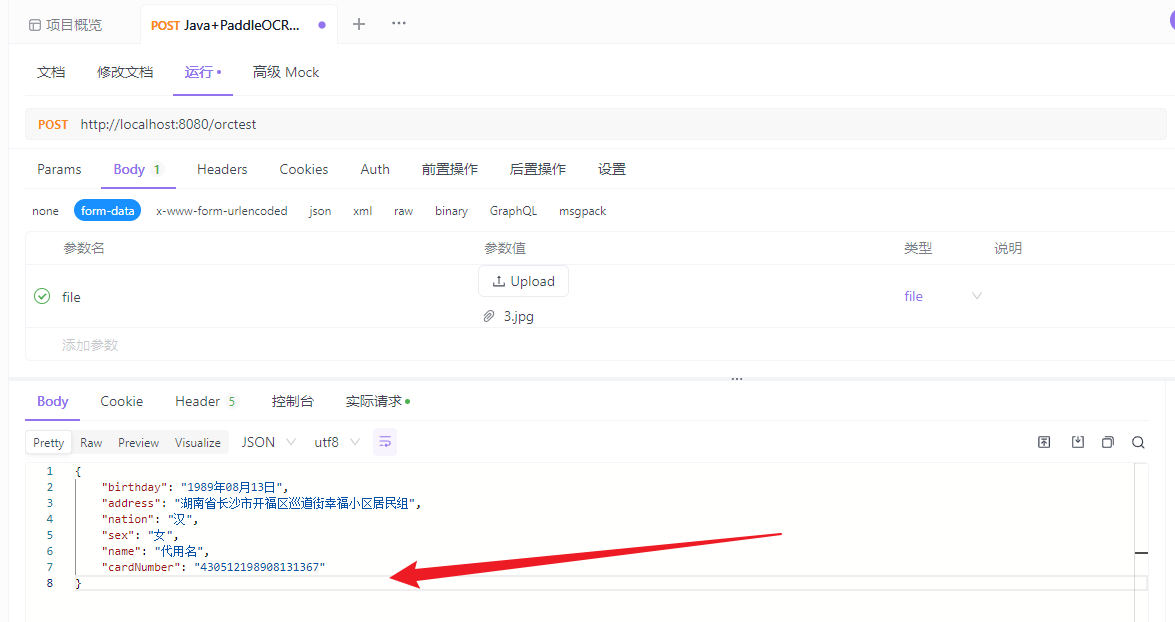
正图图片:



apifox的内容:因为这里的性别是从身份证倒数第二位的奇偶性判断的,所以!!!
性别这里不用管它,这个身份证号就是乱填的,所以性别不对很正常的
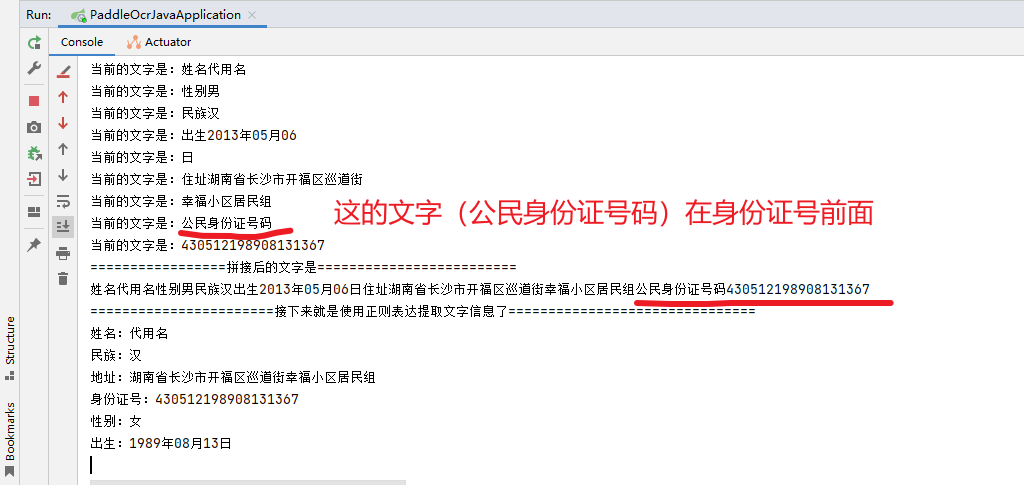
idea打印的内容如下所示:因为这里的性别是从身份证倒数第二位的奇偶性判断的,所以!!!
性别这里不用管它,这个身份证号就是乱填的,所以性别不对很正常的
偏移的图片:


apifox的内容:因为这里的性别是从身份证倒数第二位的奇偶性判断的,所以!!!
性别这里不用管它,这个身份证号就是乱填的,所以性别不对很正常的
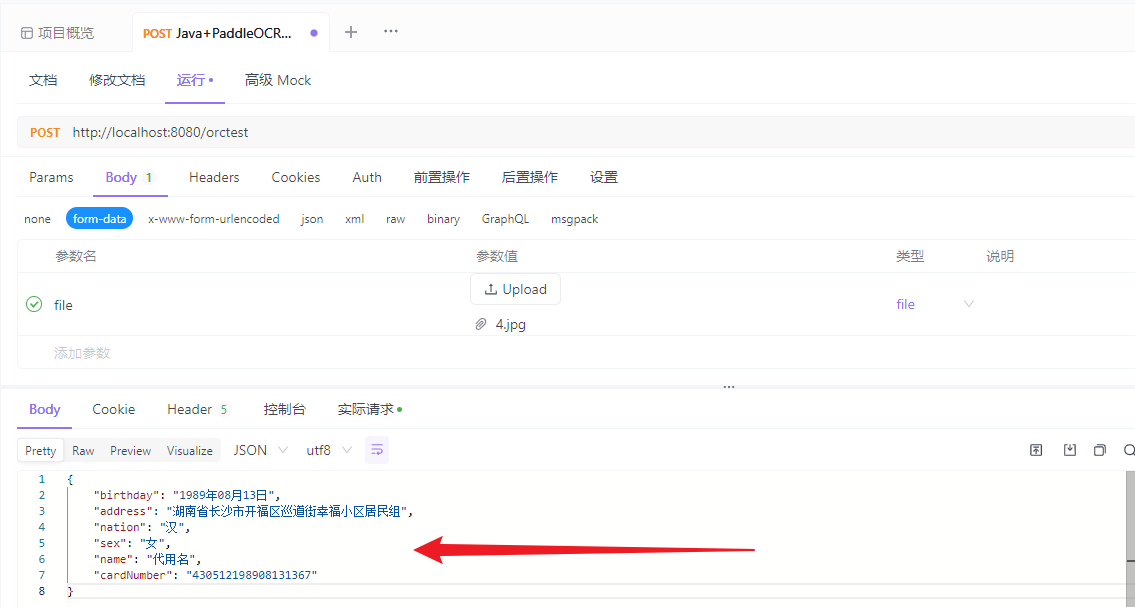
idea打印的内容:因为这里的性别是从身份证倒数第二位的奇偶性判断的,所以!!!
性别这里不用管它,这个身份证号就是乱填的,所以性别不对很正常的