
- 1Cocos Creator开发制作的小游戏《5人足球》_cocos 体育
- 2大数据【八十六】Sqoop【一】-- 概述/ 原理/ 安装配置/ Sqoop的导入和导出_把sqoop数据 从hdfs 导出 和 从hive导出有什么区别?
- 31Panel开源面板全平台下载总量突破500,000次!
- 4FPGA之JESD204B接口——总体概要 实例 下_hmc7044驱动
- 5Python利用Selenium实现弹出框的处理_selenium点击按钮弹出窗口
- 6网络抓取的最佳用户代理 2024 | 避免在抓取时被禁止使用 UA_用户代理ua
- 7防止Android截屏_android 禁止截屏
- 8uniapp运行微信小程序--本地图片无法显示_uni-app微信小程序无法加载网络图片
- 9学生宿舍用电安全监控系统_宿舍用电监控
- 10neo4j图数据库入门_刘嘉玲8分
文生视频系列溯源-Latte: Transformer Diffusion_(diffusion-generated video detector)的文生视频检测工具
赞
踩
0. 资源链接
-
论文:https://arxiv.org/abs/2401.03048
-
项目: https://github.com/Vchitect/Latte
1. 背景动机
首先看看题目
-
论文题目翻译为:“Latte: 用于视频生成的潜在扩散Transformer”。题目最重要的信息指的是作者提出的一个名为Latte的新型视频生成模型,该模型是基于潜在扩散Transformer(latent diffusion transformer)。
为什么需要谈论这篇论文?
-
基于U-Net结构的Diffusion模型获得了长足的发展。如图像生成模型Stable Diffusion 1.5/2.1/XL,视频生成模型Stable Video Diffusion,这些模型有十分优秀的语义理解能力和生成能力。但是,在我看来他们有两个缺点:
-
数据的长度变化时,难以维持生成质量
-
视频生成的长度受到严格限制。生成帧数的多少直接影响生成的质量。
-
-
在这篇论文后的一个月,OpenAI的Sora视频横空出世。这证明Transformer结构在生成领域具有无限的潜能
2. 内容提要
-
【目前存在的问题】视频生成任务中,生成高质量、高分辨率且具有连贯时空信息的视频仍然面临挑战,这主要是由于视频数据的复杂性和高维度。
-
【本文如何解决这些问题】作者通过提出Latte模型,采用Transformer作为骨干网络,有效地模拟了视频在潜在空间中的分布,并引入了多种模型变体和策略来提高生成视频的质量。
-
【为了解决这些问题,提出的算法】提出Latte模型,包括四种不同的模型变体,以及一系列最佳实践,如视频片段补丁嵌入、时间步类信息注入、时间位置嵌入等。
-
【提出算法的具体实现】Latte使用预训练的变分自编码器(VAE)将输入视频编码为潜在空间中的特征,然后通过一系列Transformer对这些特征进行编码。同时,作者还探索了不同的视频片段嵌入方法、时间步类信息注入方式、时间位置嵌入策略,并通过实验分析确定了最佳的模型配置和训练策略。
3. 技术细节
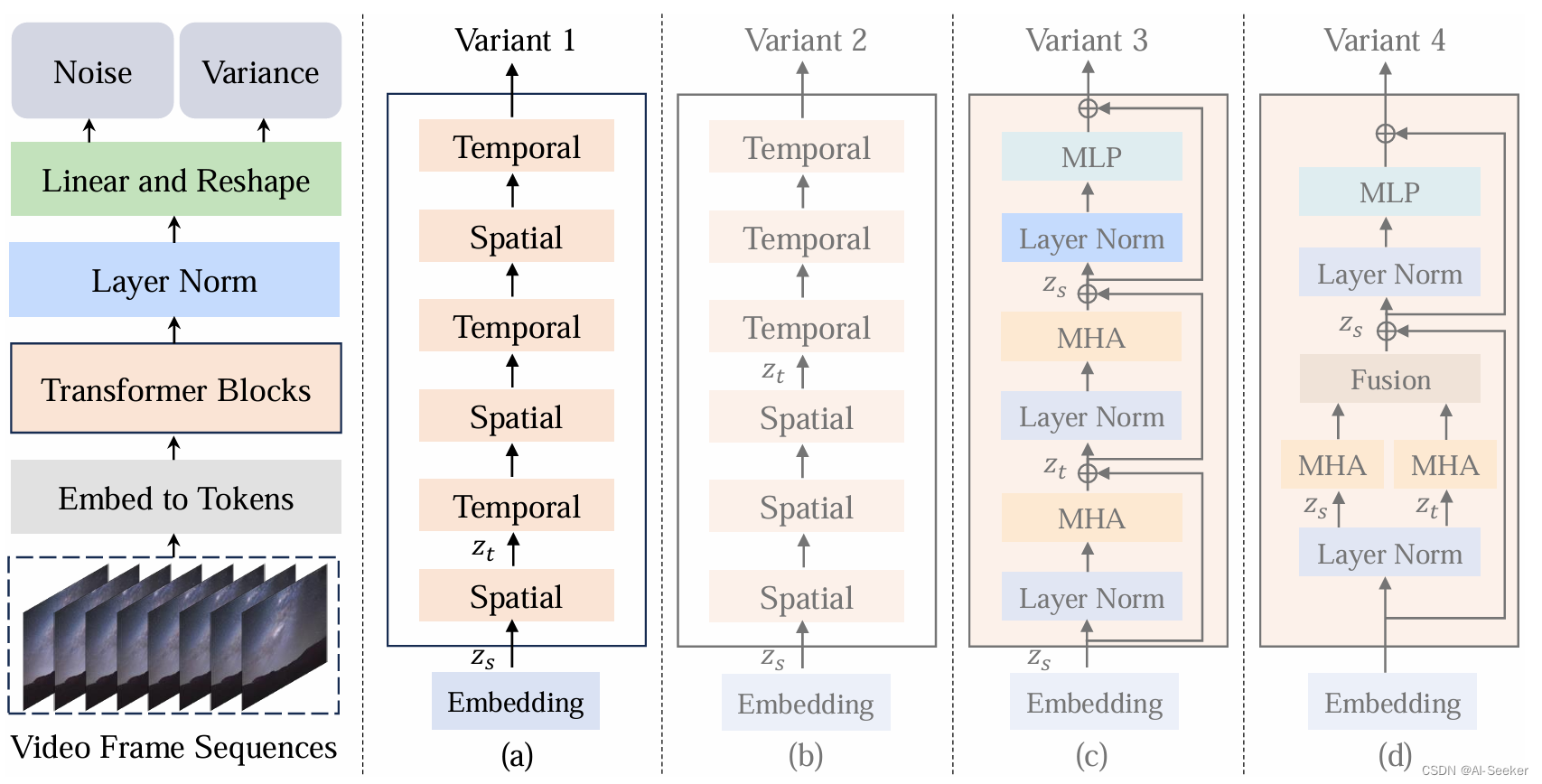
3.1 Latte模型的四个变体
作者提出了四种不同的Latte模型变体,以高效地捕获视频中的时空信息。以下是对这些模型变体的描述和分析:
-
Variant 1:
-
这个变体的Transformer主干包含两种不同类型的Transformer块:空间Transformer块和时间Transformer块。
-
空间Transformer块专注于捕获具有相同时间索引的令牌之间的空间信息。
-
时间Transformer块以“交错融合”的方式捕获跨时间维度的时序信息。
-
-
Variant 2:
-
与Variant 1相比,这个变体采用了“晚期融合”方法来结合时空信息。
-
它包含与Variant 1相同数量的Transformer块,但是空间和时间信息的融合方式不同。
-
-
Variant 3:
-
Variant 3主要关注Transformer块中多头注意力(Multi-Head Attention, MHA)的分解。
-
该变体最初只计算空间维度上的自注意力,然后计算时间维度上的自注意力。
-
每个Transformer块都捕获了空间和时间信息。
-
-
Variant 4:
-
在这个变体中,多头注意力被分解为两个组件,每个组件使用一半的注意力头。
-
不同的组件分别处理空间和时间维度上的令牌。
-
两种不同的注意力操作计算完成后,将时间维度的令牌重新整形并相加以供Transformer块中的下一个模块使用。
-
3.2 详细设计
-
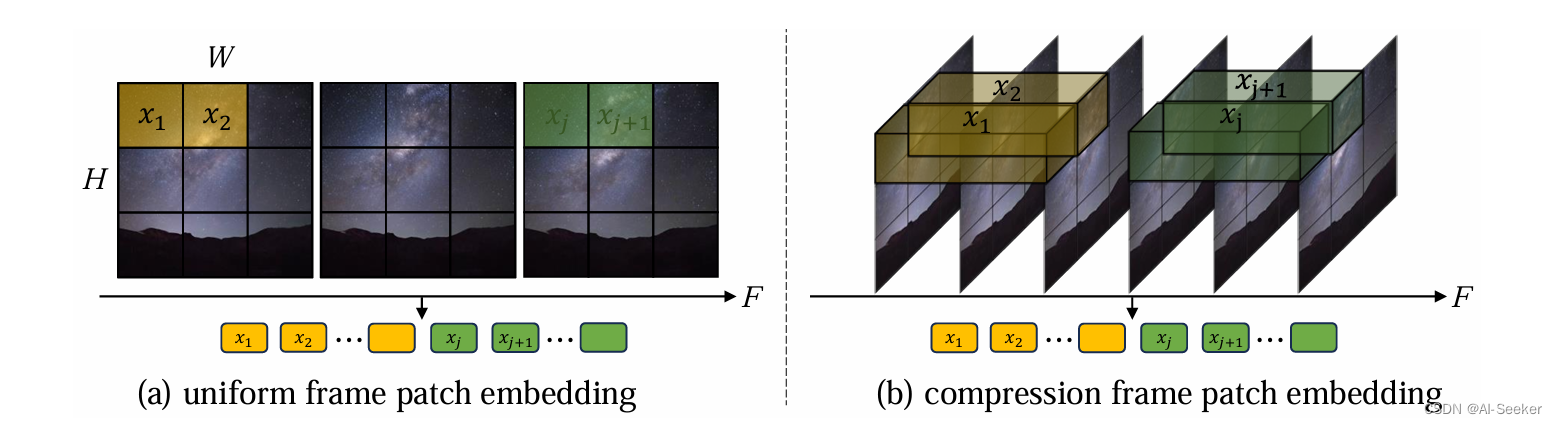
潜在视频片段补丁嵌入(Latent video clip patch embedding):
-
均匀帧补丁嵌入(Uniform frame patch embedding): 该方法将每个视频帧单独应用ViT中的补丁嵌入技术。这意味着从每个视频帧中提取不重叠的图像补丁。
-
压缩帧补丁嵌入(Compression frame patch embedding): 这种方法通过将ViT的补丁嵌入方法从2D扩展到3D,来模拟潜在视频片段中的时间信息。通过以步长s沿时间维度提取管状区域,并将它们映射到令牌。
-
-
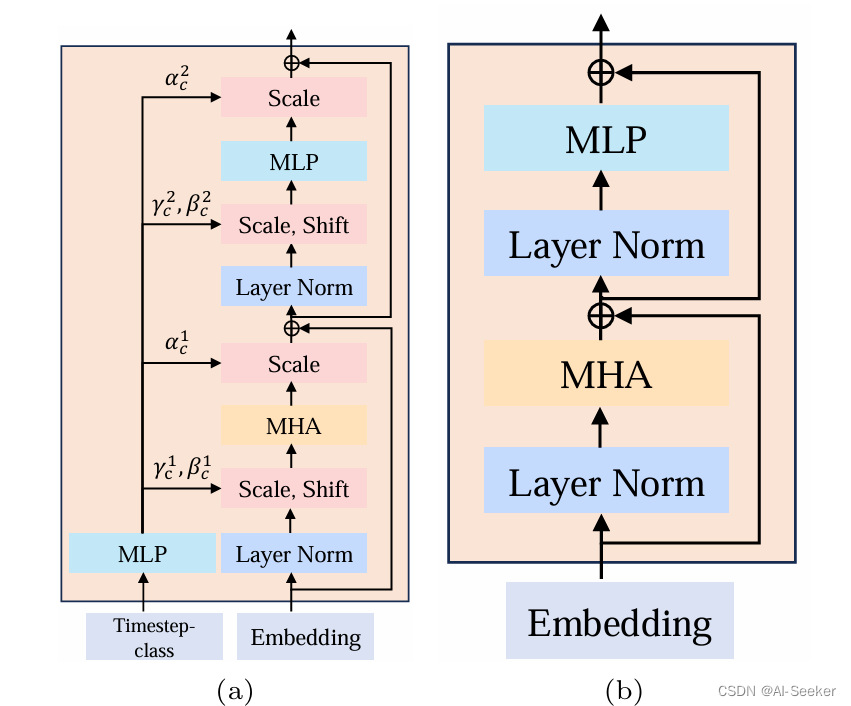
时间步类信息注入(Timestep-class information injection):
-
所有令牌(All tokens): 这种方法将时间步或类别信息c作为令牌直接注入到模型的输入层。
-
可扩展的自适应层归一化(S-AdaLN): 类似于自适应层归一化(AdaLN),使用线性回归计算基于输入c的γc和βc,并将这些参数应用于Transformer块内的隐藏嵌入。
-
-
时间位置嵌入(Temporal positional embedding):
-
绝对位置编码(Absolute positional encoding): 使用不同频率的正弦和余弦函数,使模型能够识别视频中每一帧的确切位置。
-
相对位置编码(Relative positional encoding): 使用旋转位置嵌入(RoPE)来使模型理解连续帧之间的时间关系。
-
-
通过学习策略增强视频生成(Enhancing video generation with learning strategies):
-
使用预训练模型学习(Learning with pre-trained models): 利用在ImageNet上预训练的图像生成模型来加速视频数据集上的模型训练。
-
使用图像-视频联合训练学习(Learning with image-video joint training): 探索同时进行视频和图像生成训练的策略,以提高生成视频的质量。
-
4. 题外话
-
随着Sora类,Stable Diffusion 3等模型的发展,Transformer在生成领域取代U-Net已经是板上钉钉的事了。问题是什么时候呢?我认为可能是Stable Diffusion 3开源的时候~

