
- 1swagger-bootstrap-ui_com.github.xiaoymin swagger-bootstrap-ui
- 2【Machine Learning】监督学习、非监督学习及强化学习对比
- 3git ignore DS_Store
- 4Blackbox AI:你的智能编程伙伴
- 5Linux YUM源(本地/网络源)配置详解_linux yum源配置本地
- 6AWS backup服务和 RDS snapshot的关系
- 7M1000 4G蓝牙网关:高速稳定,赋能物联网新体验
- 8单链表的创建(静态链表,动态链表)_建立单链表时,首先输入链表长度 根据输入值确定链表中的节点个数
- 9测试笔试:逻辑题(持续更新)
- 10swagger配置及升级版swagger-bootstrap-ui配置+访问账号密码登录限制
DS/ML:数据科学技术之机器学习领域六大阶段最强学习路线(初步探索性数据分析EDA→数据预处理/广义的特征工程→模型训练/评估/推理→模型分析/反思/再优化→模型部署与监控→模型全流程优化)详解_机器学习评估 ds
赞
踩
DS/ML:数据科学技术之机器学习领域六大阶段最强学习路线(初步探索性数据分析EDA→数据预处理/广义的特征工程→模型训练/评估/推理→模型分析/反思/再优化→模型部署与监控→模型全流程优化)详解
导读:数据科学和机器学习实战最强学习路线,博主这次花了真的是好久好久的时间(大概数不清的凌晨吧),以数据科学生命周期和机器学习工程化的视角进行了精心整理,今天终于结束了,真心不容易……希望能够对家学习数据科学和机器学习技术有所帮助。本文章是博主在数据科学和机器学习领域,先后实战过几百个应用案例之后的精心总结,应该是完全覆盖了数据科学的整个生命周期及其各个阶段的要点。其中机器学习领域六大阶段更是在整个数据科学生命周期中扮演着极其重要的角色。同时,因为涉及到博主出书中出版社要求在线去重的需要,博主并没有完全把书内的所有内容罗列在本文章内(而以……符号代替原书内容),但是本文章的内容已经足以完整地列出了数据科学领域处理现实任务的思维架构路线。如果大家需要查看更多详细内容,请详见详见博主即将出版的新书《数据驱动世界:机器学习在现实世界中的实战应用》、《语言之舞:跳动的自然语言与大模型实战案例》,同时也感谢大家对本文章提出更加宝贵的意见和建议。
目录
DS/ML:数据科学技术之数据科学生命周期(四大层次+机器学习六大阶段+数据挖掘【5+6+6+4+4+1】步骤)的全流程最强学习路线讲解之详细攻略
DS/ML:数据科学技术之机器学习领域六大阶段最强学习路线(初步探索性数据分析EDA→数据预处理/广义的特征工程→模型训练/评估/推理→模型分析/反思/再优化→模型部署与监控→模型全流程优化)详解
AI之MLOPS:数据科学/机器学习算法领域之工程化五大核心技术—MLOPS简介、模型开发(流水线/并行处理/持久化/可解释性)、模型部署(两大底层/四大服务)、模型监控、模型管理、自动化技术之详细攻
MLOPS:大数据/服务器下的大规模机器学习技术—并行计算技术的简介、两种并行技术(数据并行【MPI/Hadoop】、模型并行【CUDA/TensorFlow】)、两种实现方式之详细攻略
MLOPS:数据科学/机器学习算法领域之工程化五大核心技术—模型开发之持久化技术(使用时不再训练)的简介(省时/快移/个性化应用)、六大常用文件(pkl/pt……/json)、案例应用之详细攻略
XAI/ML:可解释人工智能XAI/ 机器学习模型可解释性的简介(背景/术语解释/核心思想/意义/方法/技术/案例)、常用工具包、案例应用(DS/CV/NLP各领域)之详细攻略
AI/ML:人工智能领域-自动化技术之机器学习自动化技术的简介(预处理→设计算法→训练模型→优化参数)、常用工具或框架(机器对比)之详细攻略
AI/ML:人工智能领域-机器学习算法之模型部署—模型训练技术点VS模型部署技术点、模型上线部署八大流程之详细攻略
ML之Server:服务器上部署机器学习任务的必用库/框架、对比单机电脑的机器学习任务(特征工程阶段+模型训练预测阶段)的区别、经验积累
Soft:软件开发/软件测试/运维的简介(经验/注意事项)、常用工具、案例应用之详细攻略
Tool之Airflow:Airflow(管理-调度-监控数据处理工作流的平台/DAG)的简介(可管理和调度机器学习模型的训练和预测过程)、安装、使用方法之详细攻略
ML之FE:数据分析之数据概要报告的简介(生成探索性分析EDA报告)、使用方法之详细攻略
ML之FE:在特征工程/数据预处理阶段分离特征与标签/目标变量的三种实现方法之详细攻略
ML之R:通过数据预处理(缺失值/异常值/特殊值的处理/长尾转正态分布/目标log变换/柱形图-箱形图-小提琴图可视化/构造特征/特征筛选)利用算法实现二手汽车产品交易价格回归预测之详细攻略
ML之FE:金融风控—基于预处理(PSI+标签编码+文本型抽数字+缺失值RF模型拟合填充)+多种筛选指标(PCA/IV值/Gini/熵/丰富度)利用CatBoost实现贷款违约二分类预测案例之详细攻略
ML之FE:树类模型、基于样本距离的模型在特征工程/数据预处理阶段各自的特点和处理技巧之详细攻略
ML之FE:在机器学习领域,常见的机器学习算法各自对【数值型】特征和【类别型】特征的处理技巧总结以及有哪些算法喜欢高斯分布类型的数据
ML之FE:基于titanic泰坦尼克数据集对object列的字符串数据内提取关键信息并进行数据对齐(统一特征子类别的含义)实现代码
ML之FE:特征工程/数据预处理中的数据缺失值的简介、检测方法、处理方法(删除/三种填充思路七种方法)、经典案例应用实现(包括基础函数代码)之详细攻略
Python之pandas:pandas中缺失值与空值处理的简介及常用函数(drop()、dropna()、isna()、isnull()、fillna())函数详解之详细攻略
ML之FE:特征工程/数据预处理中的数据异常值的简介、检测方法(【十类二十种算法:【数值型】+【类别型】)、处理方法(删除/填充/变换/区别对待)、经典案例应用实现(包括基础函数代码)之详细攻略
2.2.3.1、分布性分析/独立分析:单个特征的丰富度/多样性统计及其可视化
2.2.3.2、相关性分析/关联分析:各特征间或与label间的柱形图/箱形图/小提琴图可视化
2.2.4.1、分布性分析/独立分析与处理:单个【数值型】特征的分布性
2.2.4.2、相关性分析/关联分析:【数值型】特征间的相关性
(1)、基于【类别型】特征不同子类颜色区分分组统计【数值型】特征
T2、构造特征组合四则运算/多项式的特征—适合【数值型】特征
T3、构造特征交叉的装箱统计/分组聚合—适合【数值型】特征+【类别型】特征
T5、构造分桶字段/数据分桶/特征分箱/离散化/二值化:尤其适合长尾分布字段等
NLP:自然语言处理技术之NLP技术实践—自然语言/人类语言“计算机化”的简介、常用方法分类(基于规则/基于统计,离散式/分布式)之详细攻略
NLP:自然语言处理领域常见的文本特征表示/文本特征抽取(本质都是“数字化”)的简介、四大类方法(基于规则/基于统计,离散式【one-hot、BOW、TF-IDF】/分布式)之详细攻略
ML之FE:树类模型、基于样本距离的模型在特征工程/数据预处理阶段各自的特点和处理技巧之详细攻略
ML之Tree:在机器学习算法python编程中,树类模型算法是如何体现处理【类别型】特征?可否直接将【类别型】特征object格式的数据输入到树类模型中对象中进行训练与预测?
ML之Tree:决策树模型常见分类(CART、ID3、C4.5算法的对比)、【数值型】特征中“离散性”特征和“连续性”特征的处理区别、树类模型处理【类别型】特征的两种策略及其代码实战
ML:基于泰坦尼克号数据集利用多种树类算法(独热编码/标签编码+DT/RF/XGBoost/LightGBM/CatBoost+主要探究各算法对【类别型】特征的处理)进行交叉验证训练并对比模型性能
2.4.1.1、两大无量纲化技术(区间缩放归一化、Z-Score归一化(即标准化))的概述
ML之FE:数据预处理/特征工程之两大类特征(连续型特征/离散型特征)、四大数据类型(数值型/类别型/字符串型/时间型)简介、类别型特征编码的基础代码实现之详细攻略
2.4.2.3、广义—【类别型】数据编码化—NLP领域的文本型特征
2.4.3、所有数据的向量化(标准化)—一般水到渠成(如果有需要)
ML之FE:特征工程/数据预处理之特征筛选FS三大技术简介之Filter、Wrapper(基于搜索策略的三类)、Embedded)及其代码实现
ML之FE之FS:特征工程/数据预处理—特征选择之利用过滤式filter、包装式wrapper、嵌入式Embedded方法(RF/LGBM)进行特征选择(基于boston房价数据集回归预测)实现代码
ML之FE之FS:特征工程/数据预处理—特征选择之利用过滤式filter、包装式wrapper、嵌入式Embedded方法(RF/SF)进行特征选择(mushroom蘑菇数据集二分类预测)案例应用
T2、包裹式/包装式wrapper:递归地训练基模型,将权值系数较小的特征从特征集合中消除
T3、嵌入式Embedded(算法内置):训练基模型,选择权值系数较高的特征
ML之FE:机器学习算法建模中的特征穿越/数据泄露的简介、常见案例、解决方法之详细攻略
ML之FE:特征工程中常用的五大数据集划分方法(留1法/留p法、随机划分法、K折交叉验证法、自定义分割法、特殊类型数据分割法【时间序列数据】、自助采样法)理论讲解及其代码实现
ML:机器学习模型提效之监督学习中概率校准的简介、案例应用之详细攻略
ML之LoR:基于泰坦尼克号数据集分别利用Platt校准和等距回归校准算法实现概率校准进而提高二元分类模型的预测准确性(模型提效)应用案例
MLOPS:数据科学/机器学习工程化—模型开发四大技术之模型持久化技术(使用时不再训练)之模型导出与载入常用文件格式对比(pkl/pickle、pth、h5、PMML、ONNX 、json)之详细攻略
TF之DNN:基于泰坦尼克号数据集(独热编码)利用Tensorflow框架的浅层神经网络算法(h5模型文件/模型参数/json模型结构/onnx文件格式的模型导出和载入)实现分类预测应用案例
PT之DNN:基于泰坦尼克号数据集(独热编码/标签编码)利用PyTorch框架的浅层神经网络算法(pth和onnx文件的模型导出和载入推理)实现二分类预测应用案例
ML之FE:树类模型、基于样本距离的模型在特征工程/数据预处理阶段各自的特点和处理技巧之详细攻略
ML之FE:在机器学习领域,常见的机器学习算法各自对【数值型】特征和【类别型】特征的处理技巧总结以及有哪些算法喜欢高斯分布类型的数据
4.4.2、集成学习/模型融合/构建集成模型的三大层面、四大策略、四大分类
ML之EL:集成学习/模型融合/构建集成模型的简介(三大层面/四大策略/四大分类)、相关库函数/工具(Scikit-learn框架/PyTorch/TensorFlow框架等)、案例应用之详细攻略
ML之EL:集成学习/模型融合/构建集成模型的简介之Bagging和Boosting算法的联系和区别、Stacking和Blending算法的联系和区别
ML/DL:机器学习模型优化技术之过拟合和欠拟合问题的简介(6大方法解决过拟合+3大方法解决欠拟合)、从欠拟合到过拟合的变化、案例应用之详细攻略
ML与Regularization:正则化理论(权值衰减即L1正则化-L2正则化/提前终止/数据扩增/Dropout/融合技术)在机器学习中的简介、常用方法、案例应用之详细攻略
DS/ML:数据科学技术之机器学习领域六大阶段最强学习路线之模型发布、部署与监控——模型发布的简介、模型七种发布策略之详细攻略
DS/ML:数据科学技术之数据科学生命周期(四大层次+机器学习六大阶段+数据挖掘【5+6+6+4+4+1】步骤)的全流程讲解之详细攻略
AI之MLOPS:数据科学/机器学习算法领域之工程化六大核心技术—MLOPS、模型开发(流水线/并行处理/持久化/可解释性)、模型部署(云端服务器)、模型监控、模型管理、自动化技术之详细攻略
ML:场景实战之模型部署、测试的疑难杂症(如Training-Serving Skew等,比如AUC指标线下上涨但线上却下降等问题)的经验总结
AI/ML:人工智能领域-机器学习算法之模型部署的简介(八大核心技术/三大部署方法/三大服务方法)、模型上线部署七大流程、模型训练技术点VS模型部署技术点之详细攻略
Tool之Airflow:Airflow(管理-调度-监控数据处理工作流的平台/DAG)的简介(可管理和调度机器学习模型的训练和预测过程)、安装、使用方法之详细攻略
ML:机器学习之模型监控阶段—模型稳定性分析的简介、常用的监控指标(CSI/PSI)、提高模型稳定性(通用方法/线性模型场景/树类模型场景)的策略之详细攻略
ML之CSI:特征稳定性指标(Characteristic Stability Index)的简介(特征筛选/特征监控、CSI和PSI指标对比)、使用方法、案例应用之详细攻略
ML之PSI:人群偏移度指标(Population Stability Index)的简介(特征筛选/特征监控/模型监控/AB测试)、使用方法、案例应用(风控业务/风险评估/市场分析等)之详细攻略
相关文章
DS/ML:数据科学技术之数据科学生命周期(四大层次+机器学习六大阶段+数据挖掘【5+6+6+4+4+1】步骤)的全流程最强学习路线讲解之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130592322
DS/ML:数据科学技术之机器学习领域六大阶段最强学习路线(初步探索性数据分析EDA→数据预处理/广义的特征工程→模型训练/评估/推理→模型分析/反思/再优化→模型部署与监控→模型全流程优化)详解
https://yunyaniu.blog.csdn.net/article/details/128509774
AI之MLOPS:数据科学/机器学习算法领域之工程化五大核心技术—MLOPS简介、模型开发(流水线/并行处理/持久化/可解释性)、模型部署(两大底层/四大服务)、模型监控、模型管理、自动化技术之详细攻
https://yunyaniu.blog.csdn.net/article/details/130120082
MLOPS:大数据/服务器下的大规模机器学习技术—流水线处理技术的简介(标准化/自动化/可复用化)、常用框架(Pipeline/TFX、Airflow/Beam/Kubeflow/MLflow、Flink/Kafka)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130847621
MLOPS:大数据/服务器下的大规模机器学习技术—并行计算技术的简介、两种并行技术(数据并行【MPI/Hadoop】、模型并行【CUDA/TensorFlow】)、两种实现方式之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130312560
MLOPS:数据科学/机器学习算法领域之工程化五大核心技术—模型开发之持久化技术(使用时不再训练)的简介(省时/快移/个性化应用)、六大常用文件(pkl/pt……/json)、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130656042
XAI/ML:可解释人工智能XAI/ 机器学习模型可解释性的简介(背景/术语解释/核心思想/意义/方法/技术/案例)、常用工具包、案例应用(DS/CV/NLP各领域)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/126576465
MLOPS:机器学习算法领域之工程化五大核心技术之模型部署的简介(八大核心/两种方式/两大底层/两种服务/四大部署方式)、模型上线部署七大流程、部署前三大优化(按需加载/单机提效/分布式框架)、模型训练VS模型部署技术点之详细攻略
https://yunyaniu.blog.csdn.net/article/details/129783816
MLOPS:机器学习算法领域之工程化六大核心技术之模型监控的简介(2大原则/5+1监控内容)、模型稳定性(两大算法策略)、智能风控场景的模型监控、三大类监控工具(ML框架/ML专用/通用监控工具)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130858455
AI/ML:人工智能领域-自动化技术之机器学习自动化技术的简介(预处理→设计算法→训练模型→优化参数)、常用工具或框架(机器对比)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/129779086
AI/ML:人工智能领域-机器学习算法之模型部署—模型训练技术点VS模型部署技术点、模型上线部署八大流程之详细攻略
https://yunyaniu.blog.csdn.net/article/details/129783816
ML之Server:服务器上部署机器学习任务的必用库/框架、对比单机电脑的机器学习任务(特征工程阶段+模型训练预测阶段)的区别、经验积累
https://yunyaniu.blog.csdn.net/article/details/130119165
Soft:软件开发/软件测试/运维的简介(经验/注意事项)、常用工具、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130177765
Tool之Airflow:Airflow(管理-调度-监控数据处理工作流的平台/DAG)的简介(可管理和调度机器学习模型的训练和预测过程)、安装、使用方法之详细攻略
https://yunyaniu.blog.csdn.net/article/details/111569808
一、初步探索性数据分析EDA
| 简介 | EDA是对原始数据集进行初步分析和可视化,以了解数据分布、特点和潜在关系。 |
| 意义 | EDA可以对数据集进行全面的探索,获得宝贵的洞见。这对后续建模工作具有非常重要的启示和指导意义。 获取数据集的总体认识 检测和处理数据异常值 发现数据集的特点和模式 提出假设,过滤噪声数据 对数据集有初步的理解,为后续建模奠定基础 |
| 涉及内容 | 1.1.、载入数据集常用的一些工具库:pandas、numpy等; 1.2、初步EDA对数据集进行整体把握基本信息; 1.3、特征类型划分:一般划分为数值型和类别型数据。 1.4、分离特征与标签 |
1.0、相关术语
对比:特征VS特征工程
特征:数据中抽取出来的对结果预测有用的信息。
特征工程:使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
对比:数字VS数值
| 数字(符号) | 数值(有物理意义的值) | |
| 简介 | 数字是一种抽象的符号,用于表示某个具体的数量或量,例如1、2、3等。 | 数值是指数字所代表的具体的数量或量,例如1、2、3所代表的具体数量分别为1个、2个、3个。 |
| 功能 | 数字用于计数 数字表示离散对象的个数 | 数值用于度量 数值表示连续物理量的大小 |
| 是否连续 | 数字是离散的 数字只能是整数 | 数值是连续的 数值可以是任意实数 |
| 比较大小 | 数字可以直接比较大小 | 数值需要换算到同一单位后比较 |
| 联系 | (1)、数字本身是一种抽象的符号,而数值则是数字所代表的具体的数量或量,它们通常是通过一些度量或计数方式得到的。例如,一个人身高为1.75米,其中1.75就是数值,而"1"、"."和"7"、"5"则是数字。 | |
| 应用 | 数字型特征,是离散性的,通常是整数,用于表示某种分类或标签。 | 数值型特征,通常是连续性的,可以是实数、整数等 |
| 注意事项 | 在数据预处理过程中,需要将数字型特征转换成数值型特征,比如OneHot编码等,以便机器学习算法能够对其进行处理和分析。 | |
对比:定性变量VS定量变量
| 定性变量 | 定量变量 | |
| 简介 | 定性变量包括定类变量(如血型)和定序变量(问卷满意度)。 | 定量变量(数值型特征)包括连续性变量和离散性变量。 所以,离散性特征是定量型变量的一种。 |
对比:【类别型】特征、定性特征、“离散性”特征
【类别型】特征:定性变量、“离散性”变量、连续变量;
【数值型】特征:定量变量、“连续性”变量、离散变量;【数值型】特征包含“连续性”特征和“离散性”特征。
备注:特征的类型中,之所以采用【数值型】而不采用【数字型】,因为有些类别型的表现形式也是【数字型】,但其实际意义是离散性,即数字之间没有大小之分(离散性数据无法比较大小,只是不同类别),只是个代号。
| 【类别型】特征 | 定性特征 | “离散性”特征 | |
| 简介 | 类别型特征(categorical feature),也称为名义型变量(nominal variable),是指一种无序的、分类的、有限的特征取值集合。 类别型特征是指具有离散分类标签的特征,通常用于描述具有固定数量的不同取值的属性。 | 定性特征(qualitative feature):也称为质性变量(qualitative variable),是指一种无序的、分类的、可以用某种描述性语言来描述的特征。 (1)、通常是一些非数值型变量。 | 离散性特征(discrete feature):是指取值有限且数量可数的特征。 (1)、通常是整数型数值变量。 |
| 特点 | 取值的个数一般较少。 | 取值的个数较多。 | |
| 举例解释 | 例如,性别、颜色、国家、等特征。 | 例如,性别、学历、品牌等特征。 | 例如,家庭人数、购买数量等特征。 例如,一个人的年龄可以是离散性特征,因为年龄只能是整数,而不能是小数。 |
| 相同点 | (1)、在FE中共指同一对象:类别型特征、定性特征、离散性特征指的是同一类特征的不同名称。 (2)、无序性+没有大小性:三者共同的特点是没有任何大小或者等级之分,只有一些相互区分的类别。 | ||
| 对比 | (1)、类别型特征和定性特征是概念上的同义词:用于描述数据的分类或者归属关系,即把不同的数据划分为不同的类别或者属性。 例如,对于一个人的性别,可以把它分为“男”和“女”两类,对于一个水果的种类,可以把它分为“苹果”、“梨子”、“桔子”等不同的类别。 (2)、“离散性”特征是特殊的【类别型】特征:离散性特征是指具有有限个数取值的特征,例如考试成绩、家庭人口数等。比如每个月的天数28、29、30、31,就这几个离散值。它们可以被视为一种特殊的类别型特征, | ||
| 总结 | (1)、类别型特征和定性特征描述的是数据的属性,离散性特征描述的是数据取值的范围和属性。 举个例子,对于一个餐厅的菜单数据集,其中包含了每个菜品的名称、类别和价格等特征。在这个数据集中,菜品的名称和类别就是类别型特征或定性特征,因为它们是用来描述菜品属性的;菜品的价格则是离散性特征,因为价格只能取有限的离散值,而不能是任意连续的值。 | ||
| 应用 | 在实际的数据分析中,这些特征类型都需要经过适当的处理和转换,才能进行进一步的分析和建模。 | ||
1.1、载入数据集
| 术语定义 | 验证集:其实就是完全不参与训练的数据 |
| 存储数据的数据结构 | 存储数据的数据结构有三大“容器”: Dictionary(字典):字典是一种键-值对的映射结构,用于存储具有特定标识符的数据。 Array(数组):numpy的array格式数据,数组是一种类似于列表的序列类型,但是只能存储相同类型的数据,并且支持高效的数值运算。 DataFrame(数据帧):pandas的dataframe格式数据,数据帧是一种表格型的数据结构,可以存储异质数据(即不同类型的数据),常用于数据分析和处理。 |
| 实战代码 | T1、pandas读入csv、xlxs、parquet等格式数据 T2、open函数读入txt格式数据 |
1.2、初步把握数据基本信息
| 基本内容 | 统计并分析整体数据的size、各个特征的类型、【数值型】特征的统计量、【类别型】特征的子类别及其计数等内容。 (1)、输出数据集形状(行数、列数)、列名、列类型,头部、尾部数据 (2)、计算出【数值型】特征七个基本统计量:Min、Max、Mean、Std、1/4分位数、2/4分位数、3/4分位数 (3)、for循环统计指定字段类的不重复类别及其长度,且统计每个类别的个数 |
| 核心技术点 | 数据类型转换:有的原始数据某个特征内的存储数值不规范,则需要对该特征的数据类型进行修正。 |
| 实战代码 | T1、利用Print_DataInfo(data_name,df_data)函数一步输出 T2、利用成数据报告导出到html文件:一步生成探索性分析EDA |
ML之FE:数据分析之数据概要报告的简介(生成探索性分析EDA报告)、使用方法之详细攻略
https://yunyaniu.blog.csdn.net/article/details/126161530
1.3、特征类型划分:【类别型】特征和【数值型】特征
| 特征简介 | 特征是指在数据集中用于描述事物的各种属性或变量,可以分为不同的类型,其中最常见的类型有三种:【类别型】特征和【数值型】特征。 |
| 两大特征类型 | 两大特征类型及其预处理方式 1、类别型特征在入模前,常用编码方式表示,如独热编码(one-hot encoding)等。 2、“离散性”特征多种处理方式:在模型预测中,“离散性”特征,因为一般都是数字形式,要根据具体的场景需求和应用的算法,…… |
| “连续性”特征:连续性特征是指具有无限取值范围的特征,例如身高、体重、温度等。由于连续性特征的取值范围是连续的,因此它们通常不能用编码方式表示,而是需要采用其他处理方式,例如分段、归一化等。 | |
| 经验技巧 | 1、特征分布可视化的前提是特征数据中不能存在缺失值。 2、不同的特征类型在不同的机器学习算法中具有不同的处理方式和重要性。例如, (1)、在树类算法中,…… (2)、而在神经网络算法中,【…… |
| 实战代码 | for循环依次对【数值型】、【类别型】特征可视化 |
| T1、pandas中的select_dtypes函数 T2、自定义统计(for循环+if判断)分析各个字段的数据类型 T3、将dataframe中每列及其数据类型以字典格式导出到csv |
ML之FE:数据预处理/特征工程之两大类特征(连续型特征/离散型特征)、四大数据类型(数值型/类别型/字符串型/时间型)简介、类别型特征编码的基础代码实现之详细攻略
https://yunyaniu.blog.csdn.net/article/details/91361912
1.4、分离特征与标签label
ML之FE:在特征工程/数据预处理阶段分离特征与标签/目标变量的三种实现方法之详细攻略
https://yunyaniu.blog.csdn.net/article/details/105375109
二、数据预处理/广义的特征工程
备注:本过程是按照数据预处理步骤顺序撰写,但是有些步骤是要经常性的交叉使用和回用。
实战:综合案例
ML之R:通过数据预处理(缺失值/异常值/特殊值的处理/长尾转正态分布/目标log变换/柱形图-箱形图-小提琴图可视化/构造特征/特征筛选)利用算法实现二手汽车产品交易价格回归预测之详细攻略
https://yunyaniu.blog.csdn.net/article/details/129226043
ML之LightGBM:通过数据预处理(分布图/箱型图/模型寻找异常值/热图/散点图/回归关系/修正分布正态化/QQ分位图/构造交叉特征/平均数编码)利用十种算法模型调优实现工业蒸汽量回归预测(交叉训练/R2-MSE曲线/模型融合)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/128979166
ML之FE:金融风控—基于预处理(PSI+标签编码+文本型抽数字+缺失值RF模型拟合填充)+多种筛选指标(PCA/IV值/Gini/熵/丰富度)利用CatBoost实现贷款违约二分类预测案例之详细攻略
https://yunyaniu.blog.csdn.net/article/details/109559217
2.0、数据预处理/广义的特征工程的简介
2.0.0、数据预处理和特征工程的对比
| 数据预处理(关注数据本身质量+机械化) | 特征工程(提取有意义特征+创造性) | |
| 简介 | 数据预处理是指将原始数据转换成模型可以使用的形式,清理数据,产生更加整洁的数据集。 | 特征工程,本质是一项工程活动,是指从原始数据中提取和选择最有用的特征(有意义的特征),以提高模型的性能和准确度。 (1)、特征工程是一个入门简单但精通非常难的事情 |
| 目的 | 数据预处理旨在消除数据中的噪声和不一致性,避免在训练模型时对数据造成影响,使得数据更加可靠和完整。 | 目的是最大限度地从原始数据中提取提取和选择最有用的特征,以提高模型的准确性和可解释性。 |
| 意义 | 数据预处理的目的是确保数据集中的信息是准确、完整和一致的,以便模型能够从中学习。 | 特征工程的目的是将原始数据转换为更具代表性和可解释性的特征,以便模型能够更好地捕捉数据中的模式。 |
| 主要内容 | 数据分析+数据处理 这通常包括数据清洗(删除重复项/纠正错误)、缺失值处理、异常值处理、规范化数据(数据类型转换)等步骤,以及对数据进行归一化等。 | 特征分析+特征处理 它通常包括特征选择、特征提取、特征变换,以及创建新特征等步骤。 |
| 特点 | 数据预处理通常较为机械化,可重复使用相同流程。 | 而特征工程需要基于数据和任务的理解,创造性地构建特征,较难复制。 |
| 联系 | 目标相同:数据预处理和特征工程都是为了提高机器学习模型的性能。通过对原始数据进行处理,可以使模型更容易地捕捉到数据中的模式,从而提高预测准确性和泛化能力。 顺序关系:数据预处理是特征工程的一部分,它通常是特征工程的前置步骤,即特征工程基于预处理后的数据来构建特征。 互补关系:数据预处理为特征工程提供了干净规范的数据环境,特征工程基于此来创造和选择最能代表数据信息和学习任务的特征子集。 | |
备注:鉴于以上关系,同时为了统一术语,后续的特征工程也都纳入到预处理阶段中,即预处理=数据预处理+特征工程。
2.0.1、数据预处理/广义的特征工程的概述
| 广义和狭义的FE | 广义的特征工程/数据预处理:广义的特征工程=数据的各种预处理+再构建特征。 本阶段是数据预处理+特征工程阶段,目的是通过对数据各种分析和预处理,进而来构造优秀的特征。考虑到目的论,以结果为导向,特征工程=数据预处理。 |
| 侠义特征工程:仅指构造特征这一步骤,基于原始数据,同时结合利用领域知识,来创建强大的新特征—黄金特征,比如两个特征的差异、比例、幂次方等等。这通常是提高模型准确性的最有效方法, | |
| 主要内容 | 数据预处理涉及数据清洗、数据转换、特征工程、数据集成、数据集划分等任务。 (1)、数据集划分:将原始数据划分为训练集、验证集和测试集等,用于模型的训练、优化和测试,确保模型的泛化能力和效果。 |
| 核心内容主要包括处理缺失值、类别特征编码、特征数据三化等。 | |
| 目的 | 整理数据并为模型训练做准备,将数据转换为能更好地表示潜在问题的特征,从而提高机器学习的模型性能。比如, …… |
| 核心思想 | 目的是要使得入模的特征质量非常好,好到即使采用一般的算法模型也能获得很好的性能,当然,这也更容易理解和维护。 |
| 意义 | 预处理的意义:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。好数据比算法更重要,因为好数据直接影响算法结果。 |
| 1、提高数据本身信息利用率:不同的机器学习算…… | |
| 2、提高后续模型泛化力:预处理可以有效提高模型的效果和泛化能力。 (1)、数据增强…… (2)、数据清洗…… (5)、数据标准化和归一化:将不同量纲、分布不同的特征转化为相同的标准形式,避免特征之间的差异对模型造成影响。 | |
| 应用 | 在数据科学竞赛相关的领域,优秀的特征工程会得出好更好的排名和成绩。 |
| 经验总结 | (1)、树类等算法不必…… (2)、业务对提取特征非常终于:要多去结合业务提取有意义的信息。 |
| 实战代码 | T1、使用sklearn中的preproccessing库来进行数据预处理,可以覆盖本阶段的大多数问题。 |
ML之FE:树类模型、基于样本距离的模型在特征工程/数据预处理阶段各自的特点和处理技巧之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130397774
ML之FE:在机器学习领域,常见的机器学习算法各自对【数值型】特征和【类别型】特征的处理技巧总结以及有哪些算法喜欢高斯分布类型的数据
https://yunyaniu.blog.csdn.net/article/details/130599888
2.1、数据清洗
| 内容 | 对数据进行预处理,例如数据清洗、数据去重、异常值处理、缺失值填充等。 |
| 意义 | 数据预处理,通过清除异常样本,来保证数据的质量,改进……。 |
2.1.1、数据对齐
| 简介 | 数据对齐是指将来自不同数据源的数据进行整合和匹配,使其具有一致的结构和格式,以便于进行分析和挖掘。 |
| 目的 | 数据对齐的目标是使得不同数据源的数据可以在同一个数据结构中表示,从而…… |
| 原因 | 因为不同数据源可能采用不同的数据格式、命名方式、…… |
| 意义 | 数据对齐是在数据清洗阶段的重要步骤。数据对齐是数据挖掘中的关键步骤,它可以消除数据的重复和冗余,丰富数据的信息,提高数据质量,从而提高数据驱动模型的性能。 |
| 涉及内容 | …… |
| 具体方法 | …… |
ML之FE:基于titanic泰坦尼克数据集对object列的字符串数据内提取关键信息并进行数据对齐(统一特征子类别的含义)实现代码
https://yunyaniu.blog.csdn.net/article/details/130306523
2.1.2、缺失值的分析与处理
| 背景 | 处理数据的缺失值,要先了解数据存在缺失值的原因,从而更加针对性的处理。 (1)、机械原因:是由机械导致的数据缺失,比如数据存储的失败,机械故障导致某段时间的数据未能收集(对于定时数据采集而言)。 (2)、人为原因:是由人的主观失误,历史局限或者有意隐瞒造成的数据缺失。 1)、数据采集错误:在数据采集过程中,可能由于各种原因(例如设备故障、人为操作失误等)导致数据缺失。 2)、数据处理错误:在数据预处理、清洗、转换等过程中,可能由于算法错误或者数据格式不兼容等原因导致数据缺失。 (3)、历史原因:数据不适用/属性过期。某些数据项可能不适用于某些样本,例如在医学研究中,某些病人可能没有某些特定的症状,这种情况下该症状数据就不存在。 (4)、法规原因:数据隐私保护。在某些情况下,数据的收集和发布可能需要保护数据的隐私性,例如脱敏处理、数据采样等方式可能会导致数据缺失。 |
| 缺失值的四大类型 | 从缺失的分布来看,缺失值主要分为以下四类: (1)、随机丢失:即变量的值随机丢失,并且丢失的概率会因其他输入变量的值或级别不同而变化。 (2)、完全随机丢失:即对于所有的观察结果,丢失的概率是相同的。 (3)、取决于特征自身属性的缺失:即发生缺失的概率受缺失值本身的影响,比如在随机调查问卷中,身份证特征比性别特征会缺失更多。 (4)、不可预测因子导致的缺失:即数据不是随机缺失,而是受一切潜在因子的影响,比如基于时间顺序的数据,会缺失断电时间段的日期数据。 |
| 目的 | 尽量保留或者还原源数据的本质特性,进而挖掘更多的信息。 |
| 常用技巧 | …… |
| 填充补全技术常用四法 | …… |
| 经验积累 | …… |
| 实战内容 | …… |
| 实战代码 | 分析 df_titanic[col01].isnull().sum() |
| T1、增值—填充补全: T1、使用pandas自带的 df.fillna(df.median() inplace=True)函数 # mode众数 df.fillna(method='ffill',inplace=True)函数 T2、利用Imputer().fit_transform()函数,默认使用mean方式填充 删除 df.dropna(axis=0,how='any',subset=[col01],inplace=True) T2、直接删除 titanic_df = titanic_df.dropna() # 删除带有缺失值的行 |
ML之FE:特征工程/数据预处理中的数据缺失值的简介、检测方法、处理方法(删除/三种填充思路七种方法)、经典案例应用实现(包括基础函数代码)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/114954135
Python之pandas:pandas中缺失值与空值处理的简介及常用函数(drop()、dropna()、isna()、isnull()、fillna())函数详解之详细攻略
https://yunyaniu.blog.csdn.net/article/details/108504178
2.1.2.1、缺失值的统计与分析
2.1.2.2、缺失值的处理
2.1.3、异常值的分析与处理
| 异常值 | 一般将远远偏离整个样本总体的观测值,称为异常值。 |
| 异常值产生的原因 | 异常值可能是由数据输入误差、测量误差、实验误差、有意造成异常值、数据处理误差、采样误差等因素造成的。 (1)、数据输入误差:是指在数据收集、输入过程中、人为错误产生的误差; (2)、测量误差:这是异常值最常见的来源; (3)、实验误差:实验误差也会导致出现异常值; (4)、数据处理误差:在操作或数据提取的过程中造成的误差; (5)、有意造成异常值:这通常发生在一些涉及敏感数据的报告中; |
| 简介 | 数据异常值检测是数据科学领域中常用的技术之一,旨在识别数据集中的异常值或离群点,这些值可能是由于错误、噪音、异常事件或其他原因引起的。 |
| 异常的两种情况 | 异常的两种情况 (1)、某个特征内单独的异常值:比如年龄字段中的220,即为单个异常值; (2)、整个数据集中某一个样本/样例的异常:比如预测学生是否健康的体检数据集中,某一样例(学生张三)的所有体检数据全为0(空)或者大部分都为0(空); |
| 影响 | (1)、带来偏差:异常…… |
| 涉及内容 | …… |
| …… | |
| 经验 | (1)、分析模型差是否与异常值有关,比如各列的0值占比; (2)、异常样本要经业务再次确定:某些筛选出来的异常样本,需要再次确定是否真的是不需要的异常特征样本,最好结合业务再确认一编,防止正常样本被过滤。 |
ML之FE:特征工程/数据预处理中的数据异常值的简介、检测方法(【十类二十种算法:【数值型】+【类别型】)、处理方法(删除/填充/变换/区别对待)、经典案例应用实现(包括基础函数代码)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/129782360
# 2.1.3.1、异常值检测与分析
# T1、利用散点图scatter寻找异常点/分布间相关性:图中远离正斜角线的数据点,皆为异常点
# (1)、散点图可视化2个【数值型】特征分布
# (2)、【数值型】特征矩阵关系分布图(全散点图+对角线折线图)
# T2、利用百位数化分法之QQ分位数图可视化异常值
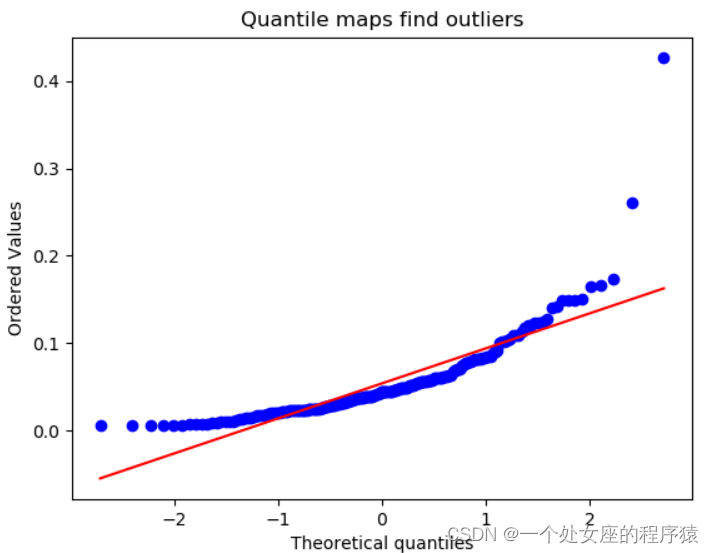
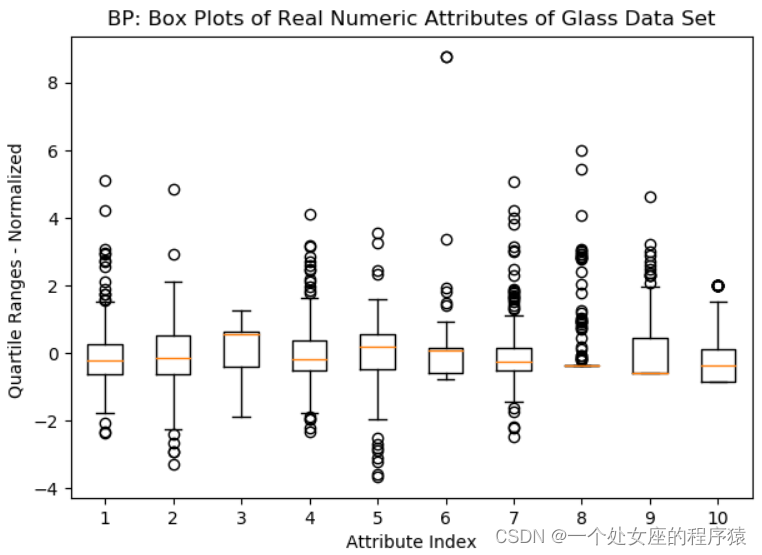
# T3、利用百位数化分法之BP箱线图/BP-N寻找异常点/异常值
# (1)、建议选择归一化后再BP可视化
# (2)、若特征中包含缺失值,则该特征不会绘制BP
# BP图所有特征在一个大图中
# BP图矩阵可视化:各个特征各个BP可视化
# T4、利用模型预测计算残差标准差的3σ原则方法找出异常值
ML之FE:基于波士顿房价数据集利用LightGBM算法进行模型预测然后通过3σ原则法(计算残差标准差)寻找测试集中的异常值/异常样本
https://yunyaniu.blog.csdn.net/article/details/130606128
# 2.1.3.2、异常值处理
# T1、基于指定成对列的删除异常样本点:删除散点图右下角、左上角区域的异常点
# T2、基于3-Sigma标准差的删除异常样本点+箱线图对比可视化:将基于当前特征的所有异常样本数据都删掉
# T3、对异常值执行截断处理:只针对异常值,截断阈值要具体看分布
2.1.4、特殊值/特定值/脏数据的分析与处理
| 简介 | 特殊值:有时候数据集中会存在特殊值,比如有些数据经常会默认0或null; 脏数据:当前值不为0、null但却没有意义的数据,这个需要基于业务知识判定。比如性别特征中有男、女、男女,可知意外出现了“男女”等类似的篡改数据。 |
| 实战内容 | (1)、特定值检测与分析 比如各列的0、1值占比,进行统计可视化 |
2.2、数据分析/处理→挖掘信息
| 简介 | 本阶段通过各种统计技术和可视化技术对数据集进行挖掘信息,涉及内容包括 >> 校验数据集是否同分布; >> 目标变量的分析与处理; >> 【类别型】特征的分析; >> 【数值型】特征的分析与处理; >> 关联统计分析; |
| 意义 | (1)、加深对数据集的理解和直观感受; (2)、挖掘信息为业务需求提供更好思路; (3)、相关性分析的意义:分析相关进行进而为构造特征提供思路; (4)、分析特征属性可更好的选择和构建算法; |
| 经验积累 | “连续性”特征常用技巧:二值化 “离散性”特征常用技巧:哑编码/独热编码 |
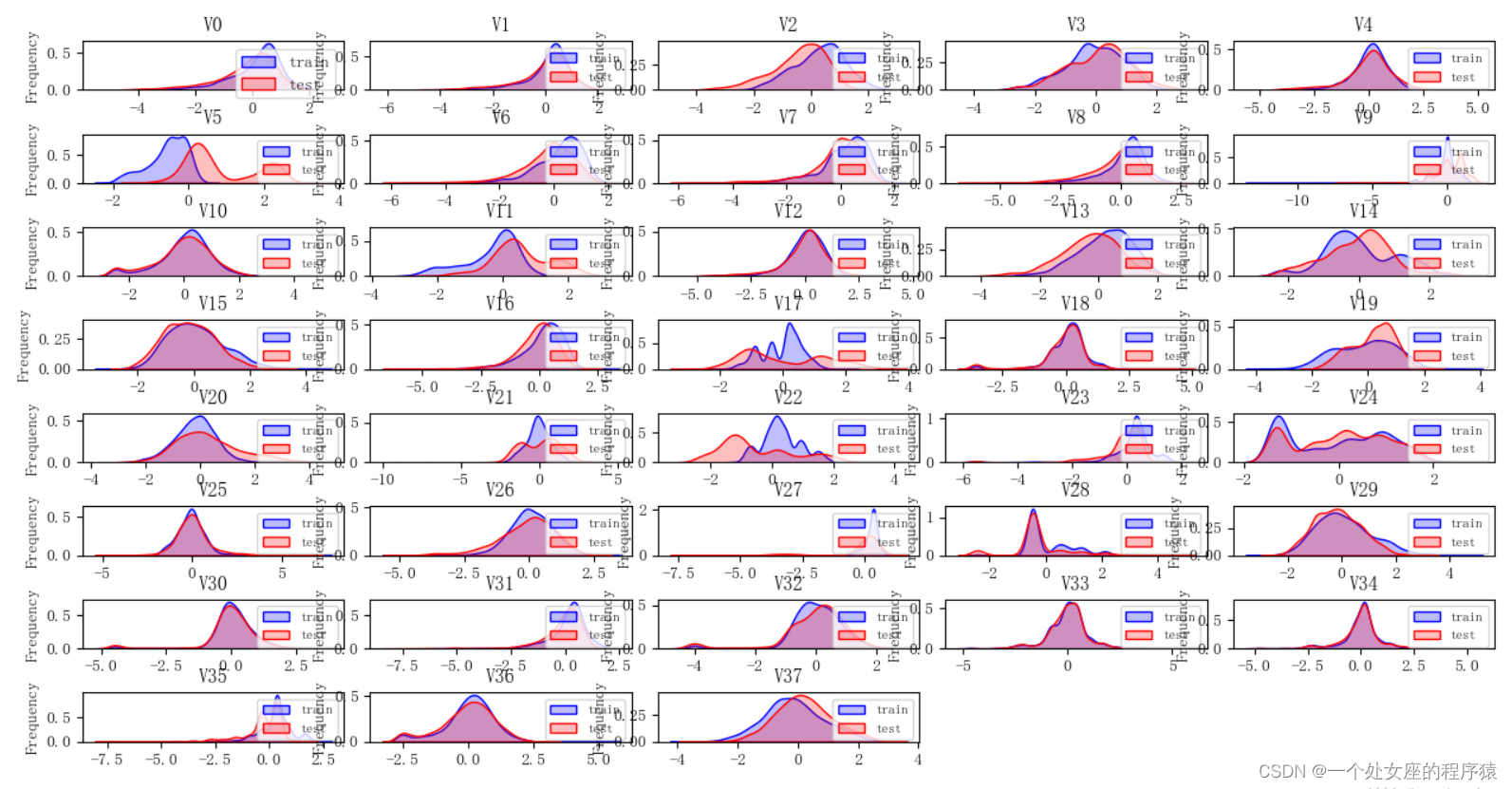
2.2.1、校验两份数据集是否同分布
分布可视化:校验训练集与测试集数据是否同分布
# (1)、【数值型】分布对比可视化
2.2.2、目标变量label/target的分析与处理
| A-在【回归】预测中 | B-在【分类】预测中 | |
| 研究内容 | 标签分布可视化:是否满足高斯分布 标签分布的变换处理: | 标签分布可视化:是否均匀分布 |
| 分析 | T1、折线图可视化:对比理论正态分布,是否符合高斯分布,如果长尾分布需要变换; 变量的四种分布可视化:无界约翰逊分布johnsonsu、正态norm、对数正态lognorm 查看skewness and kurtosis T2、Q-Q分位数图可视化:看是否与理论的一致 | T1、柱状图可视化各类别频数: 柱状图显示频数 T2、饼状图可视化各类别占比:如果占比不平衡需要重新采样; T3、词云图可视化 |
| 处理 | label的【数值型】特征若非正态分布需变换:详见—《【数值型】特征处理之数据变换》 |
2.2.2.1、查看label的分布
T1、折线图/QQ图/饼状图分布可视化
2.2.2.2、计算label的skew、kurt
2.2.2.3、label若非正态分布需变换
2.2.3、【类别型】特征分析——不包含编码化(在后边)
2.2.3.1、分布性分析/独立分析:单个特征的丰富度/多样性统计及其可视化
| 研究内容 | 统计某个【类别型】字段的多样性占比—即子样本频率分布:字段下的细分类及个数,统计子类别名及其长度、每个子类别的个数。 |
| 意义 | 多样性的意义:若一个特征的数据内容多样性为100%,可知该特征没有重复的值,也就是无法学习到东西,比如证件号字段,不能入模。 |
| 代码实战 | 1、统计分析技术 T1、利用pandas的unique函数列出每一个【类别型】特征的细分类; T2、利用pandas的value_counts函数统计每一个【类别型】特征的多样性(子类别名称及其对应个数); |
| 2、可视化技术 T1、柱状图可视化:plt.bar()函数、sns.barplot()函数,count_plot函数; T2、饼状图可视化:【类别型】特征内部子元素个数统计分析:对于多个元素,只挑选前几大元素,其余归为“其它”类别; T3、词云图可视化:类别型特征内部子元素个数统计词云图可视化; | |
| 待优化 | 1)、单张图、批量可视化、适应于4个特征2*2可视化 2)、某个特征内统计类别柱状图/饼状图可视化 |
T1、【类别型】特征的频数统计柱状图/饼状图/词云图可视化
2.2.3.2、相关性分析/关联分析:各特征间或与label间的柱形图/箱形图/小提琴图可视化
| 研究内容 | 【类别型】特征交互可视化:主要包括特征之间、特征与标签之间的关系可视化; 【类别型】特征编码处理:类别型特征数字化/编码化——在后边讲述 |
| 分析 | (1)、各个特征间的交互关系可视化:…… (2)、单特征与label之间的关系可视化…… (3)、多个组合特征与label之间的关系可视化:…… |
| 代码实战 | T1、柱状图可视化…… T2、散点图可视化:…… T3、箱形图可视化:…… T4、小提琴图可视化…… |
| 除了像Tableau 、PowerBI 等第三方工具外,主要可以利用编程语言实现 T1、pandas自带的函数:pd.crosstab().plot()函数柱状图可视化 T2、利用matplotlib、seaborn等库函数实现 |
(1)、各个特征间的关系可视化
(2)、单特征与label之间的关系可视化
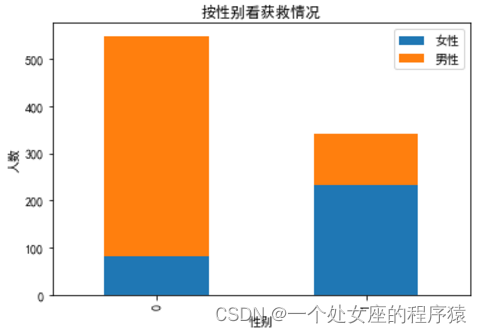
(3)、多个组合特征与label之间的关系可视化
2.2.4、【数值型】特征分析与处理
| 研究内容 | 主要包括分布性分析、相关性分析、【数值型】特征编码等内容 |
2.2.4.1、分布性分析/独立分析与处理:单个【数值型】特征的分布性
| 研究内容 | (1)、分布可视化:包括计算偏态和峰态; (2)、判断是否服从正态分布…… |
| 代码实战 | T1、折线图可视化 T2、(分箱后)柱状图可视化 T3、散点图可视化 T4、QQ分位图(直方图带分布线+散点图带分布线)可视化 |
| # T1、折线图分布/直方图分布(分箱后)可视化 sns.distplot(df['SleepTime'])函数 |
ML之FE:特征工程/数据预处理—转换和变换的区别、线性变换和非线性变换的区别、数据变换/特征变换的简介(特征的线性变换+特征的非线性变换)、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/129108740
(1)、统计并可视化所有【数值型】变量的偏态skew、峰态kurt
(2)、【数值型】特征分布性可视化
(3)、【数值型】特征的长尾分布转为正态分布
2.2.4.2、相关性分析/关联分析:【数值型】特征间的相关性
| 研究内容 | (1)、各个特征间的交互关系可视化: (2)、单特征与label之间的关系可视化:比如,基于泰坦尼克数据集,查看年龄段和乘客获救字段关系; (3)、多个组合特征与label之间的关系可视化:比如两个特征【数值型】与【类别型】标签之间散点图/小提琴图分布可视化 |
| 代码实战 | T1、柱状图关系可视化 T2、散点图关系可视化:即其中一个变量(特征/label)尽量为【类别型】特征 T3、箱形图关系可视化:sns.boxplot()函数 T4、QQ分位图可视化: T5、小提琴图关系可视化:sns.violinplot()函数 T6、热图关系可视化 …… |
(1)、各个特征间的交互关系可视化
T2、散点图关系可视化
T3.1、散点图可视化两个【数值型】特征分布
T3.2、散点图2+1特征可视化:两个特征结合label相关的散点图可视化
T3.3、散点图可视化所有【数值型】特征分布
T3、【数值型】特征间的散点图可视化
T3.1、【数值型】特征矩阵关系分布图(全散点图+对角线折线图)
T3.2、【数值型】特征矩阵关系分布图(全散点趋势线图+对角线折线图)
T3.3、【数值型】特征散点趋势线图之单个特征与label
T6、热图关系可视化
T1、PCC皮尔森矩阵线性相关性可视化
(1)、手动批量计算两个特征之间的PCC
(2)、for循环计算挑选N个特征与label的PCC
(3)、PCC皮尔森矩阵线性相关性可视化:两种风格可视化
T2、MIC最大互信息系数相关性热图可视化
(1)、单独计算某个重要特征与label之间的MIC值
(2)、for循环计算挑选N个特征与label的MIC
(3)、计算整个数据集进行MIC矩阵值
(4)、整个数据集MIC矩阵热图可视化
(2)、单特征与label之间的关系可视化
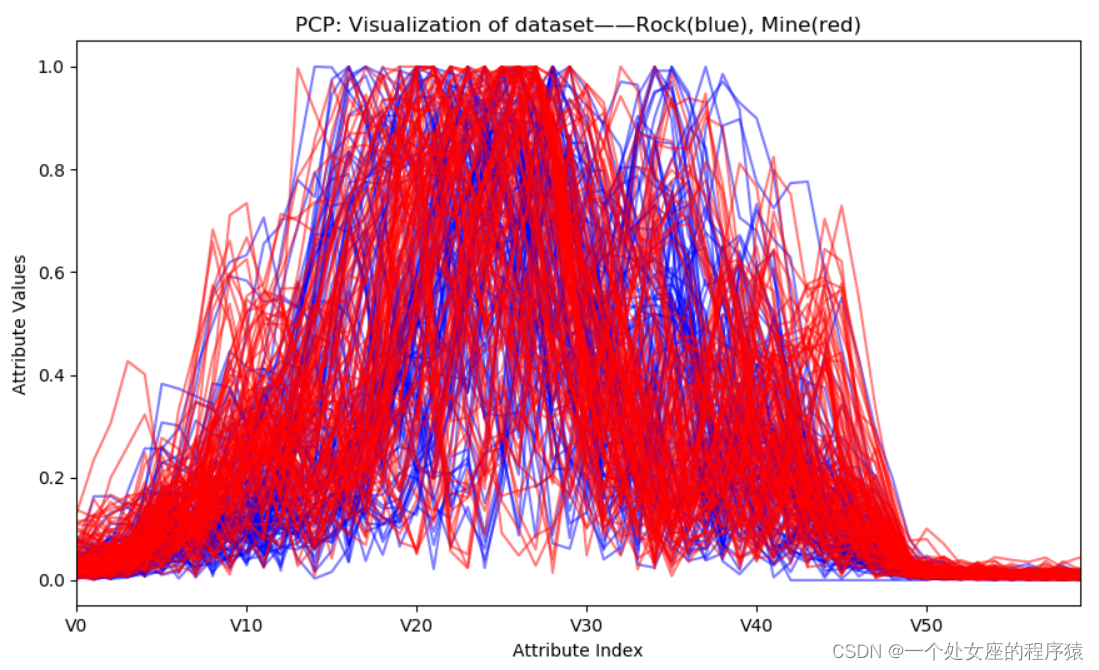
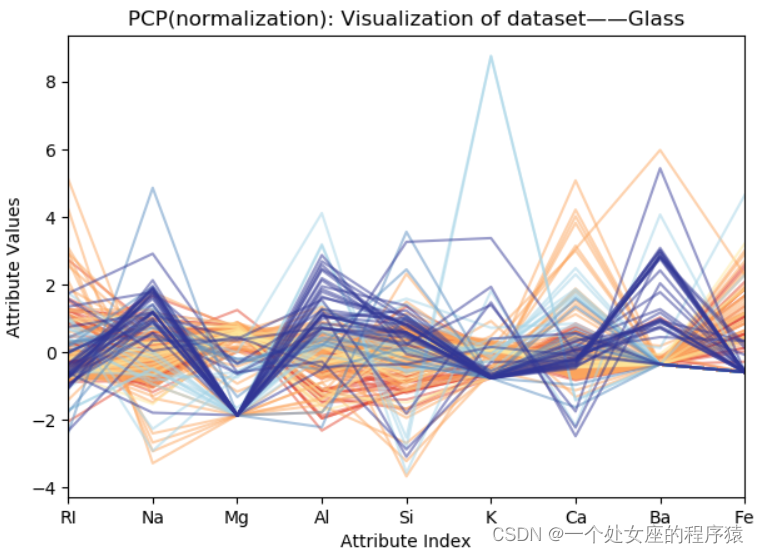
T7、PCP(平行坐标图)折线图可视化
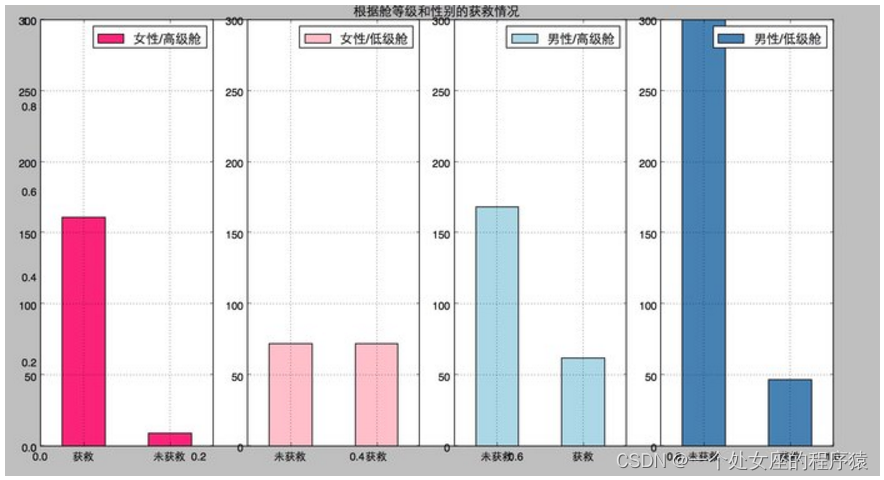
| A-在【回归】预测中 | B-在【分类】预测中 | |
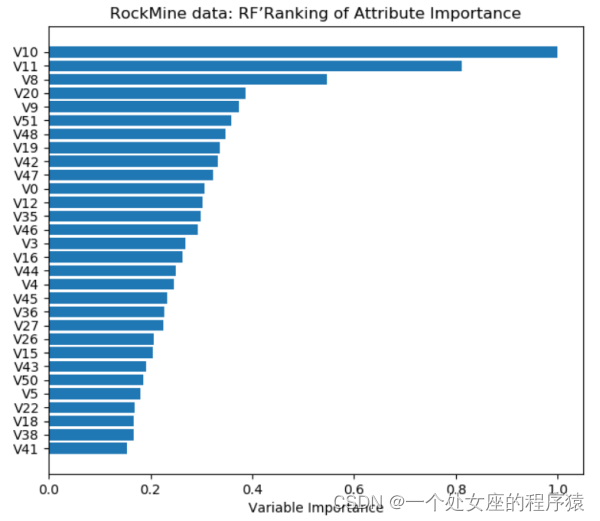
| 简介 | T1、PCP折线图直接可视化 T2、PCP折线图label颜色归一化后可视化 | 二分类:如图所示蓝色折线代表岩石、红色折线代表鱼雷 |
| 可视化 |
|
|
2.2.4.3、【数值型】特征编码之平均数编码
DataScience之ME:平均数编码(Mean Encoding)的简介、代码实现、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/129001861
ML之CatBoost:金融风控之通过数据预处理(中位数填充/校验同分布/文本型日期拆解/平均数编码-标签编码)利用CatBoost算法+模型可解释性(Shap/LIME)预测用户的车险是否为欺诈行为
https://yunyaniu.blog.csdn.net/article/details/125591806
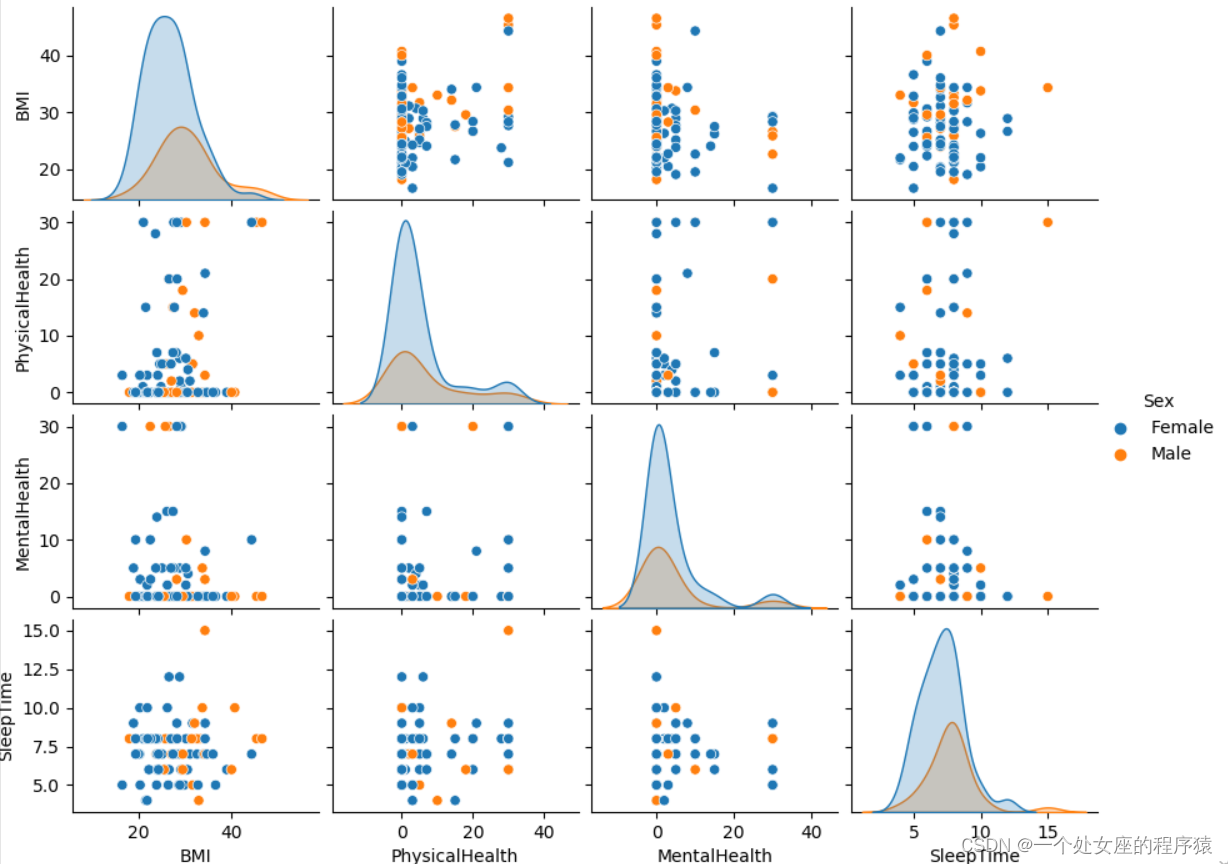
2.2.5、组合关联统计分析(针对【类别型】+【数值型】)
| 涉及内容 | (1)、仅包含综合对【类别型】+【数值型】特征关联统计 (2)、包含单独对【类别型】或【数值型】特征关联统计 |
| 实战 | 比如,根据A列(地区)不同类别进行分组统计B列(房价)平均计结果 T1、采用data_frame.groupby方法 T2、利用sns.pairplot(df)函数,指定hue参数 |
(1)、基于【类别型】特征不同子类颜色区分分组统计【数值型】特征
2.3、构造特征
| 内容 | 构造特征/构建特征,也称特征衍生,是指从原始数据中创建新特征的过程。在机器学习任务中,特征构造是一个重要的预处理步骤,因为原始数据通常包含大量的信息,但这些信息可能需要被转换或重新表达才能更好地支持模型的学习。 在特征工程中,构造特征是非常重要的一步。 |
| 核心思想 | 核心思想是利用原始数据中已有的信息,通过统计分析、数学变换、引入先验知识等方法,创造新的、有意义的、更有效的特征。这些新特征应该有助于更好地区分不同的样本,提取出对目标变量预测有帮助的信息。 核心思想是利用领域知识和数据挖掘技术,将原始数据转化为更具代表性和区分度的特征,从而提高模型的预测能力。 |
| 意义 | 特征构造对于机器学习和深度学习模型的性能至关重要。通过构造更具代表性的特征,可以帮助模型更好地理解数据,提高模型的泛化能力和预测准确性。 (1)、生成……征: (2)、更好或更充分的表达信息: (3)、增强数据质量从而……: |
| 评估指标 | (1)、相关性指标:评估构造的特征与已有特征的相关性; (2)、准确性指标:基于构造的特征,评估模型性能,是否减小了loss。 |
| 4+3种方法 | 1、四种数据类型处理技巧 数值特征处理:归一化、标准化、对数变换、取根号、分箱等。 类别特征处理:独热编码、标签编码、目标编码等。 时间特征处理:提取年、月、日、星期等信息,计算时间差等。 文本特征处理:词袋模型、TF-IDF、词嵌入等。 |
| 2、三种技术手段 统计特征:计算均值、中位数、众数、标准差等统计量。 交互特征:特征之间的加减乘除、特征组合等。 聚类特征:使用聚类算法将数据分组,将分组信息作为新特征。 | |
| 四大思路 | 构造特征的四大思路 1、基于常识经验角度—引入先验知识:详见2.3.1、基于常识经验/先验知识角度 2、基于纯技术角度: 详见2.3.2、构造基于技术的衍生式字段 详见2.3.3、构造基于技术的统计量式字段 3、基于业务意义角度:…… 4、基于综合上述技巧的角度:…… |
| 三大技巧 | (1)、特征组合:…… (2)、特征转换:…… (3)、特征抽取:…… |
| 两大方式 | (1)、线性组合的方式构建特征:…… (2)、非线性组合的方式构建特征:…… |
| 经验积累 | (1)、不同的预测模型构造手段也不同:…… (2)、要充分利用领域知识理解数据—基于业务知识构造特征…… (3)、尝试多种方法—多种技术综合优化构造特征…… (4)、迭代式构造新特征…… (5)、及时评估特征质量—避免多重共线/重复信息…… (6)、及时评估模型—避免过拟合…… |
| 注意事项 | (1)、构造特征比较耗时:特征构造需要花费大量时间和计…… (2)、构造特征避免数据泄露:特征构造也需要注意避免泄露训练…… (3)、不要太复杂尽量保留特征解释性:构造特征不要太复杂,要尽量保持特征的解…… |
2.3.1、基于常识经验/先验知识角度
T1、构造与时间信息相关的特征
| 简介 | 构造与时间信息相关的特征:根据日期构造出包括相对时间和绝对时间,节假日、双休日、每月假期天数、季度等; |
| 单特征构造 | 构造切分式—…… 构造判断式—…… 构造周期值:…… 构造过程式—………… 构造关联式—;…… 构造特殊式—单独增Saturday/Sunday两字段 构造时间衰减: |
| 构造批量特征 | 时间序列特征(Time Series Feature):针对时间序列类型的特征进行处理,例如滑动窗口、指数平滑、ARIMA模型等。时间序列特征可以将时间序列数据转化为有意义的数值特征,提高模型的准确率。 |
T2、构造与地理信息相关的特征
| 简介 | 构造与地理信息相关的特征:比如根据邮政编码构造出城市特征; |
| 常用方法 | 地理位置编码:将经纬度坐标转化为具有语义含义的特征,例如城市、州、国家等,以更好地理解和分析地理数据。例如,将经纬度坐标转化为州的信息,可以帮助我们更好地分析不同州之间的差异。…… 距离特征:…… 地形特征:…… 地理区域特征:…… 地理聚类特征:通过对地理位置进行聚类,可以帮助我们理解和发现地理空间上的模式和规律,例如人口聚集、商业中心等。例如,在分析城市交通拥堵情况时,可以使用地理聚类特征来识别交通瓶颈和交通高峰期。 |
T3、特征聚类:根据描述内容相似性/聚类算法构造新特征
| 简介 | 特征聚类(Feature Clustering):通过对相似的特征进行聚类,构造新特征。例如,对于一个有多个描述颜色特征的数据集(如“色相”、“亮度”),可以将这些特征聚类成一类“颜色”特征,实现构造新特征。 |
T4、构造先验知识字段
| 简介 | 基于先验知识构造字段,指的是在特征工程过程中,利用领域知识、统计分析、经验规则等先验知识构造新的特征。 |
| 常用方法 | 英文姓名中可以提取性别、称呼等信息 邮编中提取城市信息:“city”字段,从邮编中提取城市信息,相当于加入先验知识; 名字中提取称呼信息:“name”字段,从名字中提取称呼信息,相当于加入先验知识。如「Mr」「Master」「Dr」等,这些称呼体现了乘客的身份等信息,我们可以对其做抽取构建新的特征。 |
ML之FE:基于titanic泰坦尼克数据集对object列的字符串数据内提取关键信息并进行数据对齐(统一特征子类别的含义)实现代码
https://yunyaniu.blog.csdn.net/article/details/130306523
2.3.2、构造基于技术的衍生式字段
| 简介 | 从纯技术角度出发设计 |
| 常用方法 | T1、特征非线性变换实现构造特征—适合【数值型】特征:包括log/exp变换、取根号/平方变换, T2、构造特征组合四则运算/多项式的特征—适合【数值型】特征:比如通过初始减去结尾日期得 …… T3、构造特征交叉的装箱统计/分组聚合特征—适合【数值型】特征+【类别型】特征: T6、特征独热编码化也是一种构造特征的技术 |
T1、特征非线性变换实现构造特征—适合【数值型】特征
ML之FE:特征工程/数据预处理—转换和变换的区别、线性变换和非线性变换的区别、数据变换/特征变换的简介(特征的线性变换+特征的非线性变换)、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/129108740
T2、构造特征组合四则运算/多项式的特征—适合【数值型】特征
| 简介 | 特征组合(Feature Combination):将原始特征组合起来构造新特征。构造组合特征的过程中,需要对特征进行归一化或标准化等处理,以确保不同特征之间的尺度一致,避免因为特征值大小不同而导致的模型偏差或不稳定性。 |
| 策略 | (1)、【数值型】+【数值型】:加减乘除,多项式特征,二阶差分等。 |
| 常用方法 | (1)、乘积特征:将两个或多个特征相乘,例如身高和体重的乘积可以表示一个人的体型大小。 (2)、算术特征:将两个或多个特征进行加减乘除等运算,例如将收入和支出相减得到一个人的净收入。 |
ML之FE:特征工程/数据预处理中的构造特征之构造特征组合四则运算/多项式的特征的应用案例(基于titanic泰坦尼克数据集)实现代码
https://yunyaniu.blog.csdn.net/article/details/130312790
Py之featuretools:featuretools库的简介、安装、使用方法之详细攻略
https://yunyaniu.blog.csdn.net/article/details/106027740
T3、构造特征交叉的装箱统计/分组聚合—适合【数值型】特征+【类别型】特征
| 简介 | 特征交叉(Feature Crossing):将不同特征之间的关联进行交叉,将两个或多个特征进行交叉,构造新特征。 特征遍历构造交叉特征,利用groupby,agg 等这样一些操作进行一些特征统计; |
| 常用方法 | …… |
| 应用 | …… |
T4、构造统计量式字段—适合【数值型】特征
| 内容 | 构造类7+个统计量等特征:从原始数据中提取统计特征,例如计数、求和、比例、均值、方差、最大值、最小值等,还包括四分位数、中位数、平均值、标准差、偏差、偏度、偏锋。 |
| 意义 | 统计特征可以为模型提供更加丰富的特征信息,提高模型的分类性能。 |
| 适应场景 | …… |
| 常用方法 | …… |
| 经验 | (1)、计算某cat_col(如品牌)的label_name(如售价)统计量:基于训练集的“brand”和label_name构造七个统计量字段,并归属到整个数据集。 # 注意此处虽以基于label构造,但是test中可以根据brand字段进行归类,即同一个品牌归属于同一个平均值! |
T5、构造分桶字段/数据分桶/特征分箱/离散化/二值化:尤其适合长尾分布字段等
| 简介 | 特征分箱(Feature binning)是特征工程中常用的一种数据预处理方法,将连续数值离散化为有序的离散特征,把连续数值切段,并把连续值归属到对应的段中,以提高模型的泛化能力和预测性能。 |
| 目的 | 通过对数据分布的分析和转化,使得离散化后的特征更加符合模型的假设和需求。 |
| 意义 | 为什么要做数据分桶呢? (1)、简化性:特征分…… |
| 常用方法 | …… |
| 两大分类 | …… |
| 拓展 | …… |
| 经验积累 | …… |
| 实战代码 | # T1、根据该字段desc的5个统计量进行自动分箱 # T2、手动分箱:根据字段的mean和75%确定分箱区间 |
ML之FE:特征工程/数据预处理之构造特征之特征分箱/数据分桶的常用六大类方法—基于统计(等距/等频+分位数+标准差/f方差)、基于数据分布(自然断点+重尾分布)、基于评价指标的自适应(卡方/Best-KS分箱)、基于特征交互(WOE/IV)、基于模型算法预测(有监督决策树+无监督聚类)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/129929428
DataScience:机器学习—评分卡模型中数据分桶/变量分箱/特征分箱的简介(分箱的有效期/特征分箱的优势)、常用方法、案例应用(为例)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/125311299
(1)、从数据分布看该特征是否可以使用分桶技术
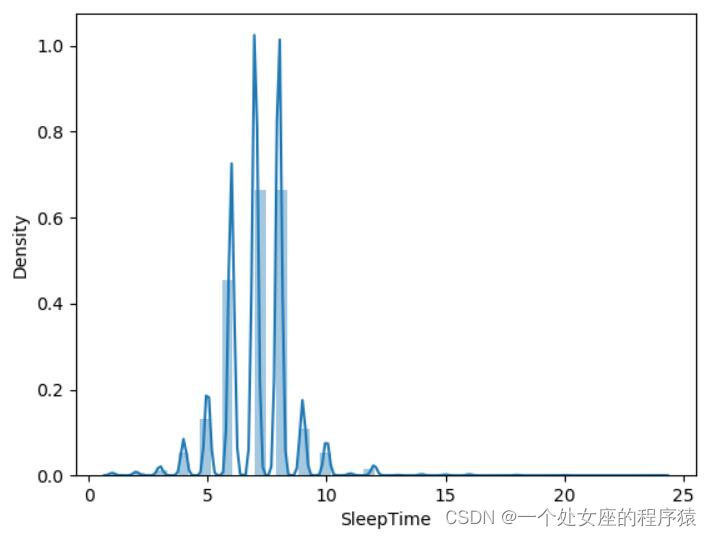
# T1、根据该字段desc的5个统计量进行自动分箱
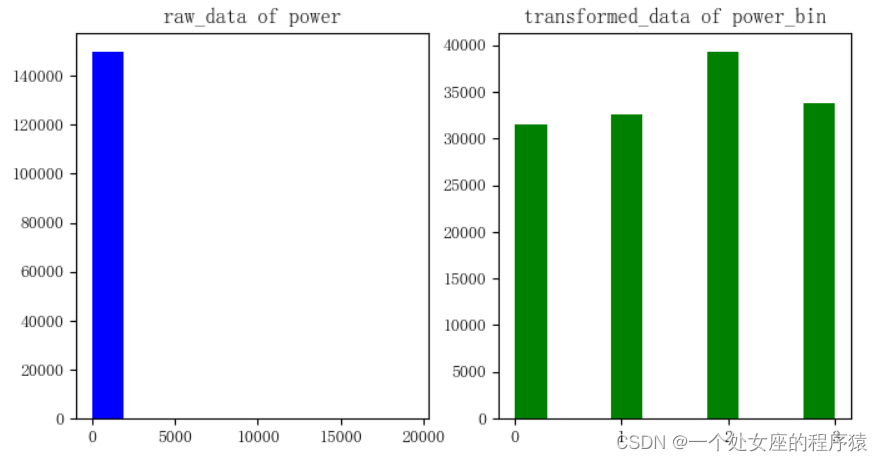
# T2、手动分箱:根据字段的mean和75%确定分箱区间
T6、自动构造特征
(1)、自动构建二次加工特征:基于决策树叶节点编码自动构造特征的方法
| 简介 | 基干树模型创造新特征,这一种特征工程方法,即将每个样本在决策树上的叶子节点映射为一个新的特征,可以是一个index或者one-hot-encoding-vector,然后将这个新特征加入到模型中。这种方法可以用于决策树系列算法,例如随机森林、梯度提升树等。 |
| 本质 | 这种方法可以被视为是对原始特征的一种二次加工,它利用决策树的非线性映射能力,将原始特征映射为一组离散的特征,这些特征更能反映样本之间的差异和相似性,从而提高了模型的表达能力。 具体地,利用决策树对原始特征进行组合,将每个样本映射到叶子节点上,并将叶子节点编码作为新特征,该叶子节点对应于一组原始特征的取值范围。将这个叶子节点的编号或者编码作为新的特征,可以将原始特征与决策树的非线性特征组合能力结合起来。 |
| 原理 | 决策树系列算法中,每个样本都会被映射到决策树叶子上。把样本经过每一棵决策树映射后的index或one-hot-encoding-vector作为一项新特征,加入到模型中。 |
| 核心思想 | …… |
| 适应场景 | …… |
| 思路步骤 | …… |
| 优缺点 | 自动性:可以自动构造特征,不需要人工干预; 非线性:它可以将非线性特征组合能力引入到线性模型中,从而提高模型的表现力和泛化能力。 |
| 复杂性:缺点在于它可能会增加模型的复杂度和计算量,并且在特征空间非常大的情况下,可能会导致过拟合。 | |
| 实战经验 | 在实际应用中,可以通过将多棵决策树的叶子节点编码组合成新的特征,进一步提高模型的表现力和泛化能力。 |
ML之XGBoost:基于titanic泰坦尼克数据集(数据对齐+独热编码/标签编码+构造新特征【四则运算+采用DT/RF树叶节点编码自动构造特征】)利用XGBoost算法实现二分类预测应案例
https://yunyaniu.blog.csdn.net/article/details/130393794
Py之featuretools:featuretools库的简介、安装、使用方法之详细攻略
https://yunyaniu.blog.csdn.net/article/details/106027740
2.3.3、构造基于业务规则/业务意义的特征
| 简介 | 首先需要了解业务领域的知识和规则,然后根据这些知识和规则,将原始数据转换成可以反映业务意义的特征。 |
| 意义 | 这种方法可以使得特征更加具有可解释性。这种方法所构造出的特征通常可以被业务专家所理解,从而能够更好地应用于业务决策。 |
| 以风控场景为例 | …… …… …… …… …… (7)、客户社交属性:朋友圈和关注的公众号等。 如可以构造"同行业朋友占比"、"金融公众号关注时长"这些特征。 |
2.4、数据数字化/特征三化/数据规范化
| 主要内容 | 特征三化:…… |
| 目的 | 最终得到无量纲化特征(全部变为数字) |
| 意义 | 非树类模型时必须的步骤 |
| 必要性 | (1)、大多线性算法的要求/利于其模型提高效能 (2)、计算机性质的要求 (3)、语言编程工具的要求 |
| 实战 | …… |
| 经验积累 | (1)、建议所有特征数字化后(包括【类别型】特征编码化后),最后统一采用归一化方法。 |
NLP:自然语言处理技术之NLP技术实践—自然语言/人类语言“计算机化”的简介、常用方法分类(基于规则/基于统计,离散式/分布式)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/128877887
NLP:自然语言处理领域常见的文本特征表示/文本特征抽取(本质都是“数字化”)的简介、四大类方法(基于规则/基于统计,离散式【one-hot、BOW、TF-IDF】/分布式)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/128877833
ML之FE:树类模型、基于样本距离的模型在特征工程/数据预处理阶段各自的特点和处理技巧之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130397774
ML之Tree:在机器学习算法python编程中,树类模型算法是如何体现处理【类别型】特征?可否直接将【类别型】特征object格式的数据输入到树类模型中对象中进行训练与预测?
https://yunyaniu.blog.csdn.net/article/details/130397623
ML之Tree:决策树模型常见分类(CART、ID3、C4.5算法的对比)、【数值型】特征中“离散性”特征和“连续性”特征的处理区别、树类模型处理【类别型】特征的两种策略及其代码实战
https://yunyaniu.blog.csdn.net/article/details/130633620
ML:基于泰坦尼克号数据集利用多种树类算法(独热编码/标签编码+DT/RF/XGBoost/LightGBM/CatBoost+主要探究各算法对【类别型】特征的处理)进行交叉验证训练并对比模型性能
https://yunyaniu.blog.csdn.net/article/details/130621317
2.4.1、【数值型】特征无量纲化
2.4.1.1、两大无量纲化技术(区间缩放归一化、Z-Score归一化(即标准化))的概述
| 无量纲化技术的简介 | 【数值型】特征无量纲化,主要是指连续值的无量纲化,成为标量。无量纲化技术是消除由于量纲不同、自身变异或者数值相差较大而引起的误差。经过归一化处理,可以使得不同的特征具有相同的尺度。 |
| 主要内容 | 主要是针对【数值型】特征,归一化幅度较大的字段,进行无量纲化。对特征进行缩放,使其数值范围在固定的区间范围内或者非固定的区间范围内。 |
| 适用阶段 | …… |
| 线性变换的两大归一化 | …… |
| 意义 | 1、线性变换的意义——线性变换的两大归一化不会改变顺序:本质上都是对数据的线性变化,不会改变原始数据值的排列顺序。这些性质决定了对数据改变后不会造成“失效”,反而能提高数据的表现。 2、去量纲化的意义——可比性—去量纲化后才具有可比性:去除数据的单位限制,将其转化为无量纲的纯数值。把有量纲表达式变成无量纲表达式, …… 6、标准正态分布的意义——Z-Score归一化的线性变换有很多优秀的性质:当数据符合标准正态分布时…… |
| 不需要标准化/归一化的场景 | 1、特殊场景不需要:…… 2、基于非距离模型的算法:…… |
| 经验积累 | 1、在实践中,就算应用了不需要的数据归一化,但是大多数情况下,…… |
| 实战 | T1.1、利用sklearn的MinMaxScaler().fit_transform()函数进行数据标准化 |
ML之FE:特征工程/数据预处理—转换和变换的区别、线性变换和非线性变换的区别、数据变换/特征变换的简介(特征的线性变换+特征的非线性变换)、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/129108740
DataScience:数据预处理/特征工程之线性变换—四种特征缩放Scaling算法简介、区间缩放归一化和非固定区间归一化(即标准化)的各自角度的概述与对比、国外文章的解读
https://yunyaniu.blog.csdn.net/article/details/130312586
T1、Z-Score标准正态化/StandardScaler函数
T2、归一化/MinMaxScaler函数/MaxAbsScaler函数
# MinMaxScaler归一化对比可视化:单个特征
# MinMaxScaler归一化:多个特征
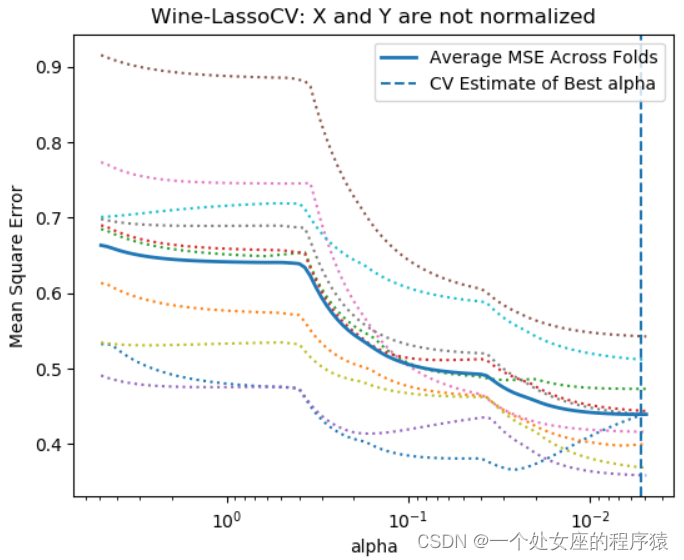
(1)、对比是否归一化的效果
T1、X和Y都不做归一
T2、X和Y都做归一
T3、X做归一且Y不做归
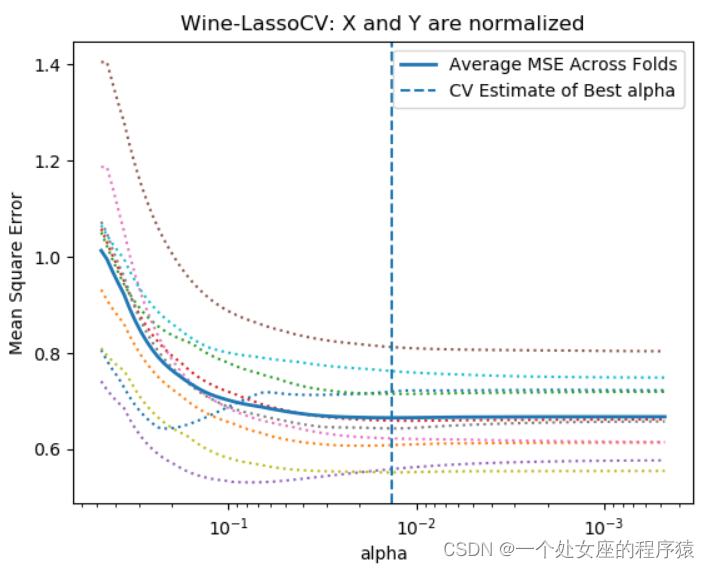
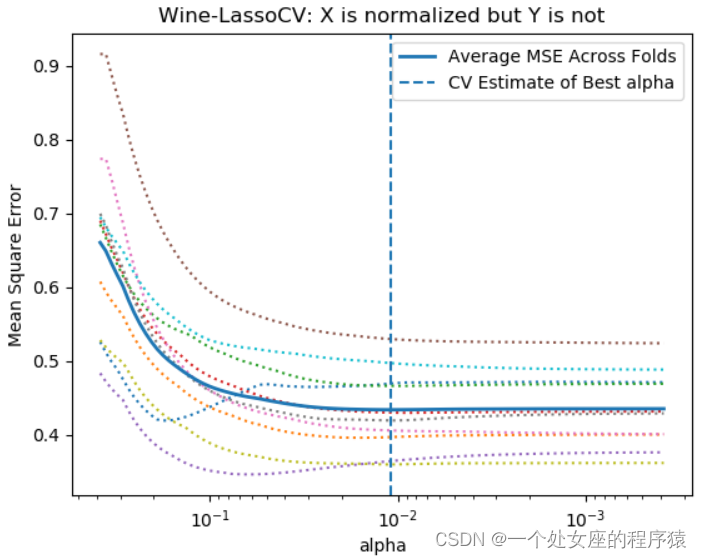
2.4.2、【类别型】特征编码化
| 主要内容 | 本阶段特指【类别型】特征进行编码,实现将string转为num类型; |
| 意义 | 通过数字化后,属性矩阵就完全成了真正意义上的数值矩阵,即数学上的矩阵。 |
| 应用领域 | (1)、DS领域的object类型转数值 (2)、NLP领域的文本转数值 (3)、CV领域的图像转数值 |
| 三种场景 | A、纯类别:…… B、顺序(Ordinal)类别:…… C、数值(Cardinal)类别:…… |
| 三大特点 | (1)、原始字符串性: (2)、无顺序性:一般情况下; (3)、子类别有限性:二值或多值性 |
| 方法 | 5+2种编码方式 T1、Ordinal Encoding序列编码/序号编码 T2、OneHotEncoder独热编码…… T5、统计编码:如频率编码、概率编码、联合频率编码、权重编码、目标编码、CatBoost 编码、平均数编码等使用各种统计量数值化进行的编码。 T6、Embedding嵌入…… T7、Hash与聚类处理 |
| 实战 | T3.1、利用sklearn的LabelEncoder结合fit+transform函数实现 T3.2、利用pandas自带的map函数结合映射字典实现 T4.1、Pandas的get_dummies()方法 T4.2、Sklearn的OneHotEncoder()方法 |
| 经验积累 | (1)、LE编码在特征和标签上的区别:…… (2)、【类别型】特征LE编码数值化需导出映射字典:一般都需要保存前后映射关系。 (3)、…… |
ML之FE:数据预处理/特征工程之两大类特征(连续型特征/离散型特征)、四大数据类型(数值型/类别型/字符串型/时间型)简介、类别型特征编码的基础代码实现之详细攻略
https://yunyaniu.blog.csdn.net/article/details/91361912
ML之FE:特征工程/数据预处理中的数据数字化/特征编码化之统计编码(基于统计量的编码,频率编码、概率编码、联合频率编码、权重编码、目标编码、CatBoost 编码、平均数编码等)的简介、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130316172
2.4.2.1、狭义—【类别型】数据编码
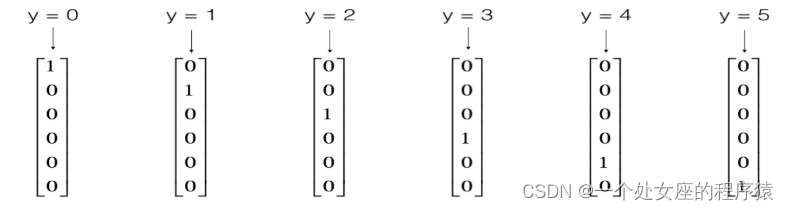
T2、OneHotEncoder独热向量编码化/哑变量编码
| 简介 | …… |
| 意义 | 对于线性模型来说,使用哑编码后的特征可达到非线性的效果。 |
| 实战 | 利用OneHotEncoder().fit_transform(data)函数实现 |
| 经验 | one-hot编码是处理类别特征的一个通用方法,但是不适合树模型中当类别特征中类别个数很多的情况下。 |
#比如颜色 红、蓝、黄 会被编码为[1, 0, 0],[0, 1, 0],[0, 0, 1]

T4、LabelEncoder标签编码化
# (1)、基本类别编码,直接在train上执行LabelEncoder,不考虑test中的新值
# (2)、高级类别编码,test中的新值映射为unknown
调用本函数前提:所有数据均已填充
T5.1、Mean Encoding均值编码
T6、Embedding嵌入
T7、Hash与聚类处理
2.4.2.2、广义—【类别型】数据编码化—时间型特征
| 简介 | 若时间特征为本身就带有对应数字的时间,如年月日、时分秒等,对于决策树模型会原样使用该特征,不需要编码。 如果时间特征只有文本格式,如"2018-01-01"形式,需要先转换为日期格式,则需要数值编码。 |
2.4.2.3、广义—【类别型】数据编码化—NLP领域的文本型特征
| 简介 | 文本处理(Text Processing):针对文本类型的特征进行处理,例如分词、去停用词、词向量化等。文本处理可以将文本特征转化为数值特征,提高模型的准确率。 (1)、NLP领域的【类别型】特征,是指文本string类型的特征; |
| 方法 | A、文本表示模型 …… B、文本字符串的五种编码方式 …… |
2.4.3、所有数据的向量化(标准化)—一般水到渠成(如果有需要)
| 内容 | 此处标准化是指数据内容从格式上或者表现形式上,对数据进行数据表现统一标准化,即所有特征统一向量或矩阵的方式存储。比如,深度学习模型中,要求入模的数据是三维的array形状。 |
| 思路 | 第一步,要区分【类别型】离散值、【数值型】连续值,便于做不同的特征处理; 第二步,对【类别型】离散值向量化为X_vec_con; X_vec_con = vec.fit_transform(X_dictCon) 第三步,对【数值型】连续值向量化为X_vec_cat; X_vec_cat = vec.fit_transform(X_dictCat) 第四步,对以上两种类型拼接,组合在一起为X_vec X_vec = np.concatenate((X_vec_con, X_vec_cat), axis=1) #最后的特征 |
| 实战 | T1、存为dataframe格式数据: T2、array格式数据:在深度学习中,特别要入入模数据类型为三维; Y_vec_reg = data_df['registered'].values.astype(float) |
| 经验积累 | …… |
(1)、对【类别型】离散值、【数值型】连续值两种类型拼接

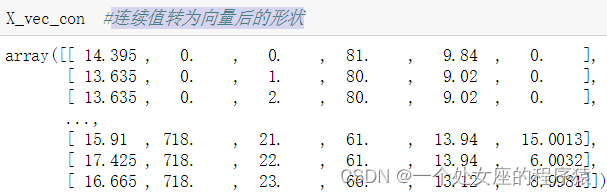
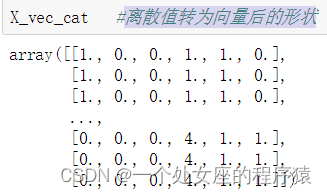
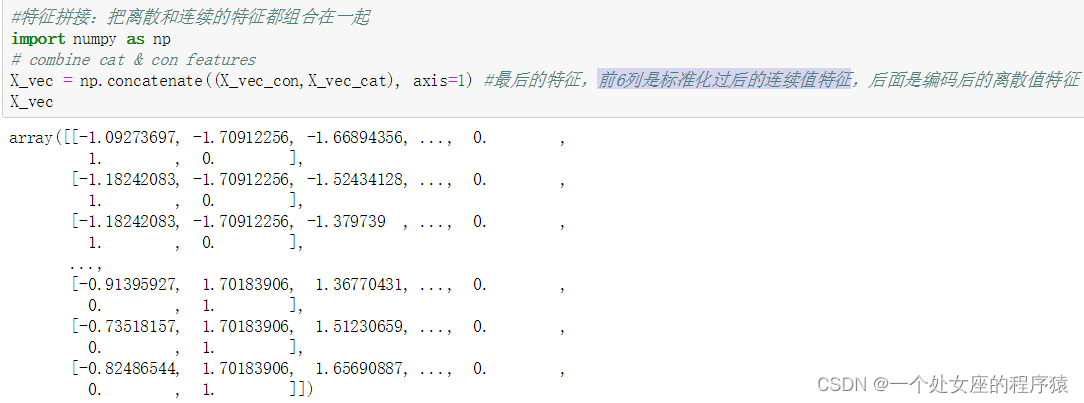
前6列是标准化过后的连续值特征,后面是编码后的离散值特征
2.5、定义入模特征
| 背景 | 当数据预处理和特征工程全部完成后,我们需要选择有意义的特征,输入到机器学习的算法和模型进行训练。 |
| 主要内容 | 定义数据的入模特征,一般包括删掉无意义的特征、选择具有表现力的特征,还包括数据降维的内容。然后将这样优秀的特征送去训练学习器/模型算法,从而提高模型的性能。 本阶段的内容,除了在第一章节的特征初步筛选中,已经进行了对无意义特征的筛选过滤,在此基础上再次从业务角度、技术角度进行筛选。 |
| 两大角度 | T1、特征的分布性:…… T2、特征的相关性:…… |
| 目的 | 过滤掉无意义/使结果准确度下降的列 |
| 两大角度 | 1、基于常识和业务经验的特征删除: T1、删除重复性字段…… T2、删除一些分布/严重倾斜不一致特征…… T3、删除已基于此衍生新特征的字段…… 2、基于三大技术的特征筛选:过滤式filter、包裹式wrapper、嵌入式Embedded。 |
| 实战 | data.drop(['datetime', 'count','date','time','dayofweek'], axis=1)#把原始数据的时间重复等字段去掉 |
2.5.1、删除特征
T1、删除一些分布/严重倾斜不一致特征
T2、删除已基于此衍生新特征的字段/过程特征
2.5.2、特征筛选FS—广义的特征降维
| 简介 | 特征选择(Feature Selection)/特征筛选:从现有特征中选择出一部分最有用的、最有代表性的特征(实现数据降维),以便用于训练机器学习模型,提高模型的预测性能。 |
| 目的 | 降维→提效:在不影响模型性能的前提下,减少特征数量,降低特征维度,避免过拟合,提高训练速度和模型性能。 |
| 原则 | 找出最佳的特征数量,要取决于我们可用的数据量以及试图实现的任务的复杂性; |
| 场景 | 特征筛选适用于特征较多、样本较少或需要实现实时预测的情况。 |
| 核心原理 | 核心原理是找到对目标变量具有最大预测能力的特征,从而在保留较少的特征的情况下提高模型的预测性能。 |
| 意义 | (1)、降低过拟合风险、提高泛化力和预测精度:若存在非信息特征(如ID)、不良/噪声特征,会降低模型准确度; (2)、加快训练速度:降低过拟合风险:若存在相关特征,带来冗余特征,且耗算力; (3)、增加模型可解释性/数据可视化:维度过高导致可解释性变弱。奥卡姆剃刀原理,模型应当简单易懂。如果特征太多,就失去了可解释性; (4)、简化模型并降低部署难度:避免维度灾难,维度过高部署也会很困难; |
| 筛选两大类别 | T1、线性关系筛选:皮尔森相关系数热图,主要用于判别线性相关; T2、非线性关系(复杂关系)筛选:如果存在更复杂的函数形式的影响,则建议使用树模型(非线性算法)的特征重要性去选择。 |
| 筛选三大技术 | 基于评价准则划分的三种方法,见下边更详细解释; T1、过滤式filter(最快):列入一些筛选特征的标准;先对特征集进行特征选择再训练学习器,特征选择的过程与后续学习器无关。 T2、包裹式wrapper:将特征选择看作是搜索问题;选择的是“量身定做”的特征子集,比过滤式filter更精确但耗内存、成本高。 T3、嵌入式Embedded(最常用):嵌入法使用内置的特征选择方法的算法;融为一体,在学习的过程中自动进行特征选择,让模型自己来分析特征的重要性。 |
| 总结:前两种方法,是将“子集评价”与“子集选择”分开的,而嵌入法将两者融为一体,在同一个优化过程中完成,在学习训练的过程中,自动进行特征选择。 | |
| 经验积累 | (1)、反向研究特征 (2)、特征越多越好:这是一个错误的观点,模型的特征越多,过拟合的风险就越大…… (3)、选择特征原则:…… (4)、对于类别型特征变量,…… (5)、对于【数值型】特征变量,可以直接用线性模型和基于相关性的选择器来选择变量; (6)、对于二分类问题,…… |
| 实战 | T1、使用sklearn中的feature_selection库来进行特征选择 |
ML之FE:特征工程/数据预处理之特征筛选FS三大技术简介之Filter、Wrapper(基于搜索策略的三类)、Embedded)及其代码实现
https://yunyaniu.blog.csdn.net/article/details/81711158
ML之FE之FS:特征工程/数据预处理—特征选择之利用过滤式filter、包装式wrapper、嵌入式Embedded方法(RF/LGBM)进行特征选择(基于boston房价数据集回归预测)实现代码
https://yunyaniu.blog.csdn.net/article/details/129902180
ML之FE之FS:特征工程/数据预处理—特征选择之利用过滤式filter、包装式wrapper、嵌入式Embedded方法(RF/SF)进行特征选择(mushroom蘑菇数据集二分类预测)案例应用
https://yunyaniu.blog.csdn.net/article/details/129915144
T1、过滤式filter:挑选相关性变量
| 简介 | 通过某种评价准则对每个特征进行评价,并选择出得分最高的特征。主要考察自变量与目标变量之间的关系,通过采用一些筛选特征的评分标准,自定义阈值,实现特征筛选。比如相关性筛选,只选取包含与目标变量存在相关性特征变量的特征子集。 (1)、如果两个特征之间的相关性(线性相关性和非线性相关性)为0,这意味着改变这两个特征中的任何一个都不会影响到另一个。 |
| 核心思想 | 评估单个特征和目标值间的关系程度:按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数来选择特征。 |
| 场景 | 线性关系表征:pearson相关系数来描述; 单调关系表征:spearman、kendall等来描述; 非线性关系表征:距离相关系数、MIC、基于模型的特征重要性排序等来描述; |
| 方法 | 常见的方法:基本上所有方法都可以用在【回归】任务上,就算原先是用在【分类】任务上(比如卡方检验),也可以通过对数据分桶间接应用在【回归】任务上。 T1、基于自身方差相关:…… T2、基于度量的特征选择法:…… T3、基于信息相关的特征选择法(主要应用离散特征和【分类】问题):…… |
| 实战 |
ML之FE之FS:特征工程/数据预处理—特征选择之利用过滤式filter之利用方差阈值的特征筛选(自定义数据集,多种方法实现)案例实现代码
https://yunyaniu.blog.csdn.net/article/details/130058743
ML之chi-square:卡方检验(chi-square test)的简介、代码实现、使用方法之详细攻略
https://yunyaniu.blog.csdn.net/article/details/127723156
ML之FE之chi2:基于mushroom蘑菇数据集利用对RF模型采用chi2算法(基于P值调参的k值挑选)实现特征筛选并可视化特征个数与模型得分的变化曲线、输出最佳特征个数Top_i的特征名称应用案
https://yunyaniu.blog.csdn.net/article/details/129930807
(1)、基于信息相关的四种特征选择法
| 类别 | 核心原理 | |
| 基于信息论 | 信息增益IG | …… |
| 互信息MI | …… | |
| 基于统计学 | 最大信息系数MIC | …… |
| 信息价值IV | …… |
T2、包裹式/包装式wrapper:递归地训练基模型,将权值系数较小的特征从特征集合中消除
| 对比 | 从最终的学习器性能来看,wrapper特征选择比filter特征选择更好。但是,由于在特征选择过程中需多次训练学习期,因此包裹式特征选择的计算开销通常要更大。 |
| 简介 | 通过建立一个分类器或回归模型,来评价每个特征的重要性,并选择最具有代表性的特征。 比如根据目标函数(AUC/MSE,即模型效果得分),来决定是否添加或删除一个变量,这种方法将是将特征选择看作是搜索问题。如递归特征消除。 …… |
| 核心思想 | 根据目标函数(通常是预测效果评分),每次选择若干特征或者排除若干特征。 |
| 案例理解 | 比如用LoR,怎么采用Wrapper呢? …… |
| 方法 | T2.1、全局最优搜索/完全搜索 T2.2、随机搜索(GA、SA):详见最优化理论之GA、SA T2.3、启发式搜索:例如前向/后向/双向/递归特征消除 T2.3.1、前向选择方法:逐步增特征是寻更优,自下而上的选择方法,又称集合增加法。 >> 逐步将变量一个一个放入模型,并计算相应的指标,如果指标值符合条件,则保留;继续放入下一个变量,直到没有符合条件的变量纳入或者所有的变量都可纳入模型。 T2.3.2、后向选择方法:逐步减某特征寻更优,自上而下的选择方法,又称集合缩减法。 >> 一开始,就将所有变量纳入模型,然后挨个移除不符合条件的变量;持续整个过程,直到留下所有最优的变量为止。 T2.3.3、双向/逐步选择stepwise 该算法是向前选择和向后选择的结合,逐步放入最优的变量、移除最差的变量。 T2.3.4、递归特征消除RFE T2.4、基于排列重要性算法PFI |
| 实战 | 通过 coef_或者feature_importances_属性可以获得特征的重要性 |
ML之FS之RFE:RFE递归特征消除算法的简介、代码实现、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130354807
XAI之PFI:PFI/Permutation排列重要性/置换重要性算法(What—哪些特征对预测的影响最大)的简介(原理/意义/优缺点/应用/改良)、常用工具包、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/128795667
T3、嵌入式Embedded(算法内置):训练基模型,选择权值系数较高的特征
| 简介 | 嵌入法使用内置的特征选择方法的算法,即利用学习器自身自动选择特征。通过某种机器学习模型算法来训练,获得各个特征的重要度(权重系数/重要性分值),然后降序筛选。模型根据权重从大到小自动选择特征。 …… |
| 核心思想 | 先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。 |
| 方法分类 | T3.1、采用正则化相关的算法: T3.1.1、采用L1的Lasso正则化进行变量筛选; T3.1.2、采用L2的Ridge正则化进行变量筛选; T3.2、采用ML算法模型 T3.2.1、线性模型的权重系数:LoR模型权重变量系数正负符号,结合P值大小实现变量筛选; T3.2.2、基于树的方法: T3.2.3、采用深度学习算法 |
| 常用方法 | 嵌入式选择最常用的是L1正则化与L2正则化 T1、L1正则化/Lasso套索回归: T2、L2正则化/Ridge岭回归: |
ML与Regularization:正则化理论(权值衰减即L1正则化-L2正则化/提前终止/数据扩增/Dropout/融合技术)在机器学习中的简介、常用方法、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/107929447
2.5.3、特征降维—狭义的特征降维
更多内容详见,5.4、降维任务中的算法
2.6、导出入模数据集
| 简介 | 利用python编程把数据预处理和特征工程之后的数据集导出,以方便后期模型训练使用。 |
| 常用方法 | T1、CSV…… …… |
| 实战 | T1、data.to_csv('processed_data_export.csv', index=False) T2、data.to_excel('processed_data_export.xlsx', index=False) T3、连接到SQLite数据库,将数据集保存到数据库 conn = sqlite3.connect('mydatabase.db') data.to_sql('mytable', conn, if_exists='replace', index=False) T4、将数据集保存为LibSVM格式 dump_svmlight_file(X, y, 'iris.svm') |
三、模型训练/评估与推理
| 背景 | 模型构建的概念比较广,指根据问题定义和数据集,设计和搭建合适的机器学习或深度学习模型的过程。它是机器学习中非常重要的一环,它主要涉及到选择合适的算法、特征工程、模型训练等技术,从而实现对数据的预测、分类、聚类等功能。但是,本阶段的模型构建特指选择模型算法、调整超参数、训练模型等内容。 |
| 简介 | 模型构建、模型评估和模型推理是机器学习项目的三个关键步骤。 模型构建:即模型搭建与训练。根据训练数据构建机器学习模型,选择模型算法、调整超参数、训练模型等。 模型评估:即模型评估与验证。包括选择合适的评估指标、评估模型性能、调整模型参数等。 模型推理:将最终模型应用于新的数据,得到模型预测结果。 |
| 经验技巧 | 数据流水线:…… |
3.0、数据降内存:通过调整……——模型提效技巧点☆
3.1、数据集切分:划分训练集/验证集/测试集
| 内容 | 数据集切分是指将原始数据集划分为训练集、验证集和测试集三部分。 训练集:用于训练模型; 验证集:用于模型的调参和评估,调整模型超参数; 测试集:用于最终模型的评估和性能测试,评估模型的泛化能力; |
| 目的 | 数据集划分的目的是为了避免过拟合和欠拟合,提高模型的泛化能力(鲁棒性)。 可以更好地了解模型在未知数据上的表现,防止过拟合,并优化模型性能。 |
| 核心技术点 | 1、划分比例:划分比例的选择对模型性能影响较大,通常将数据集按照6:2:2的比例划分为训练集、验证集和测试集。当数据集较大时,也可以考虑将验证集和测试集合并。 2、划分策略: …… |
| 经验积累 | (1)、划分比例的选择:…… (2)、避免数据泄露:…… …… (5)、交叉验证:除了简单的划分数据集,也可以采用交叉验证的方法,这是一种用于模型评估和参数调优的技术。如k折交叉验证等,以避免模型的过拟合和欠拟合。k折交叉验证:是将数据集分成K个不相交的子集,然后进行K次训练和验证过程,每次使用不同的子集作为验证集,其余子集作为训练集。最后计算K次验证结果的平均值作为模型性能指标。 |
| 切分方式 | 切分两种思路 T1、切分先整再细…… |
| 三大场景 | T1、自定义比例随机划分法(如70%来训练):利用sklearn的train_test_split函数实现 T2、分层抽样SS法 T3、特殊类型数据分割法 |
| 特殊场景 | 针对基于时间序列数据类型:对于时间序列数据,我们需要按照时间顺序进行切分,…… |
| 实战代码 | 随机切分:利用scikit-learn库train_test_split函数; 分层切分:利用scikit-learn库中StratifiedKFold或StratifiedShuffleSplit函数实现; 时间序列切分:利用scikit-learn库的TimeSeriesSplit类; K-折交叉验证:利用scikit-learn库中KFold或StratifiedKFold类 |
ML之FE:机器学习算法建模中的特征穿越/数据泄露的简介、常见案例、解决方法之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130215772
ML之FE:特征工程中常用的五大数据集划分方法(留1法/留p法、随机划分法、K折交叉验证法、自定义分割法、特殊类型数据分割法【时间序列数据】、自助采样法)理论讲解及其代码实现
https://yunyaniu.blog.csdn.net/article/details/108411370
3.2、模型搭建与训练
| 简介 | 选择合适的算法:根据任务类型、数据类型和数据量等因素,选择适合的算法。 模型训练:使用训练数据对模型进行训练,调整模型参数,使其能够准确地预测未知数据。该部分内容还与数据集切分内容相关; |
| 核心技术点 | 模型选择:选择适合任务的模型,并进行参数优化,提高模型性能。 交叉验证:使用交叉验证方法对模型进行评估,避免过拟合和欠拟合。 可视化:使用可视化工具将训练过程可视化。 |
| 经验积累 | (1)、充分了解不同算法的优缺点,以便根据问题特点选择合适的算法。 (2)、参考相关领域的研究论文和开源项目,借鉴成功的模型架构和超参数设置。 |
| 算法选择技巧 | 在机器学习领域,不同的算法针对不同的任务,常用的经验有…… |
3.2.1、选择算法
此处部分主要是以应用案例为主,有关于算法理论本身的介绍,主要详见算法介绍章节
ML:数据科学/机器学习领域经验总结—对于特征个数大于样本量的高维数据集,用什么算法进行预测,效果会更好?
https://yunyaniu.blog.csdn.net/article/details/129828539
A、【分类】任务中
(1)、二分类预测
ML之LoR:利用LoR算法对2018足球世界杯各个组进行输赢预测
T1、利用OLS对岩石-水雷数据集构建分类器
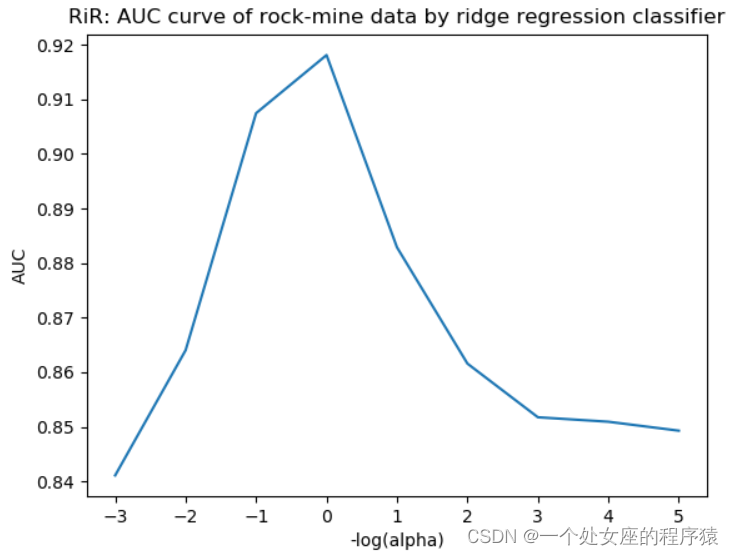
T2、利用RiR对岩石-水雷数据集构建分类器+AUC度量分离器性能
T3、用回归工具将岩石-水雷二分类转为回归问题并采用LARS算法构建分类器
T4、利用ElasticNet回归对岩石水雷数据集构建二分类器(DIY交叉验证+分类的两种度量PK)
T5、EL之RF(RFC):利用RF对二分类问题(声纳数据集)进行建模并预测(未爆炸的水雷)
T6、EL之GB(GBC):利用GB对二分类问题(声纳数据集)进行建模并预测(未爆炸的水雷)
ElasticNet之PLoR:在二分类(岩石水雷)数据集上调用Glmnet库训练PLoR模型(T2)
ElasticNet之PLoR:在二分类(岩石水雷)数据集上调用Glmnet库训练PLoR模型(T2)
(2)、多分类预测
T1、使用PLiR实现对玻璃样本进行多分类
T2、EL之RF(RFC):利用RF对多分类问题(玻璃数据集)进行建模(六分类+分层抽样)并评估
T3、EL之GB(GBC):利用GB对多分类问题(玻璃数据集)进行建模(分层抽样+调1参)并评估
B、【回归】任务中
(1)、整数值预测
A、鲍鱼数据集
T1、EL之RF(RFR):利用RF对(鲍鱼物理指标)回归(性别属性编码)问题(整数值年龄预测)建模
T2、EL之GB(GBM):利用GB对(鲍鱼物理指标)回归(性别属性编码+调2参)问题(整数值年龄预测)建模
B、红酒数据集
T1、在红酒品质数据集上利用FSR(前向逐步回归)
T2、在红酒品质数据集上利用RiR(岭回归)
T3、在红酒品质数据集上利用基扩展BasisExpand
(2)、浮点数预测
T1、ML之LGBMRegressor:利用LGBMRegressor算法对住房月租金进行预测
C、【聚类】任务中
(1)、结构化数据聚类
(2)、非结构化数据聚类
A、图片聚类
B、文本聚类
3.2.2、模型训练
| 简介 | 模型训练是机器学习建模过程中非常重要的一环,通过训练模型,使得模型能够从数据中学习到规律和特征,达到预测或分类的目的。 |
| 核心技术点 | 损失函数的选择:…… 优化器的选择:…… 学习率的设置:…… 批量大小的设置:主要是针对深度学习技术,批量大小是指每次训练模型使用的样本数,合理设置批量大小可以在保证训练效果的同时提高训练速度。 |
| 经验积累技巧 | 预训练:…… 提前停止:…… |
| 常用方法 | T1、留1法/留P法训练验证:Holdout留出验证 T2、n 折交叉训练验证:L-oneCrVa、k-fCrVa |
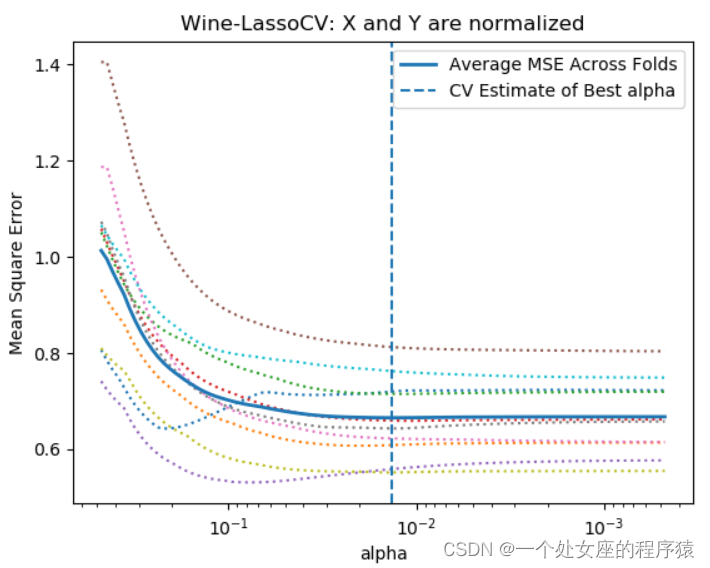
| 实战代码 | 模型训练:一般都是fit函数,利用KFold()、cross_val_score()等函数。 (1)、LassoCV(cv=10).fit(X, Y) #执行10 折交叉验证,利用10折交叉训练模型并可视化(交叉验证error曲线) |
3.2.2.1、模型一次性训练
3.2.2.2、模型交叉训练
# 注意:但交叉验证不适合基于时间序列数据集的回归预测
# 选择几个最佳模型再进行交叉训练确保模型稳定性
(1)、同时绘制在10份数据上的错误平均值,每一份上绘制错误随α 变化的曲线
3.2.2.3、模型训练曲线可视化
绘制基于交叉验证的train和val学习曲线
3.3、模型评估与验证(偏实战)
| 简介 | 本阶段内容主要包括模型评估、模型调优、模型预测误差可视化等内容。 |
| 核心技术点 | 划分数据集的方式:训练集、验证集、测试集。 评估指标:选择合适的评估指标,如准确率、精确率、召回率、F1值等。 参数调优:对模型进行参数调优,提高模型性能。 交叉验证:使用交叉验证方法对模型进行评估,避免过拟合和欠拟合。 可视化:使用可视化工具将评估结果可视化,从而更直观地比较模型性能。 |
| 经验积累 | 多指标评估(技术指标+业务指标):…… |
3.3.1、模型评估
| 简介 | 模型评估是模型构建后的重要环节,它主要涉及到使用验证或测试数据,对模型性能的评估和比较,分析模型评估指标,进而确定模型的有效性和可靠性。 |
| 核心思想 | 根据以前看不见的数据测试模型,这些看不见的数据在某种程度上代表了现实世界中的模型性能,但仍然有助于调整模型。 |
| 核心技术点 | (1)、如何选择验证数据集:…… (2)、如何选择评估指标:…… |
| 模型评估两大类指标 | 评估模型性能,最终还是要根据业务需求权衡各种评价指标的重要性。 T1、模型评估的技术指标:用于衡量模型的准确性和效率; A、【分类】任务模型常用评估指标:更多内容详见——5.4、模型评估常用指标; B、【回归】任务模型常用评估指标:更多内容详见——5.4、模型评估常用指标; T2、模型评估的业务指标:用于衡量模型对业务的贡献和价值,在保险风控领域,常用机器学习算法实现是否欺诈的预测,在评估欺诈模型性能时,除了考虑AUC、F1等技术指标外,还需要考虑一些业务指标,如下所示: …… |
A、【分类】任务中模型常用评估指标:6个
T1、正确率和误分类率
T1.1、正确率ACC
T1.2、误分类率—最初不考虑代价
(1)、对模型性能评价:输出最好的误分类error值及其对应的决策树个数
(2)、绘出deviance偏差、误分类误差随着GB中决策树的个数变化曲线图
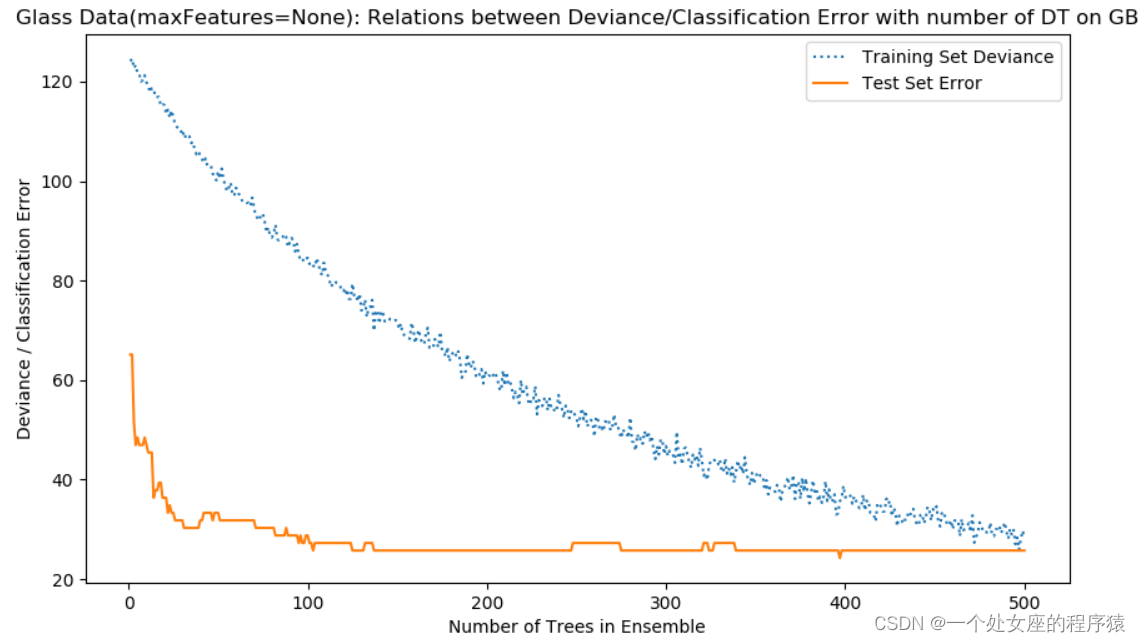
1)、偏差展示了训练的过程。测试数据集的误分类误差用来确定模型(或算法)是否过拟合。
但在DT数目达到200左右后,性能也不再提升,因此可以终止测试。
2)、使用的是RF基学习器。这导致误分类率改善了大概10%
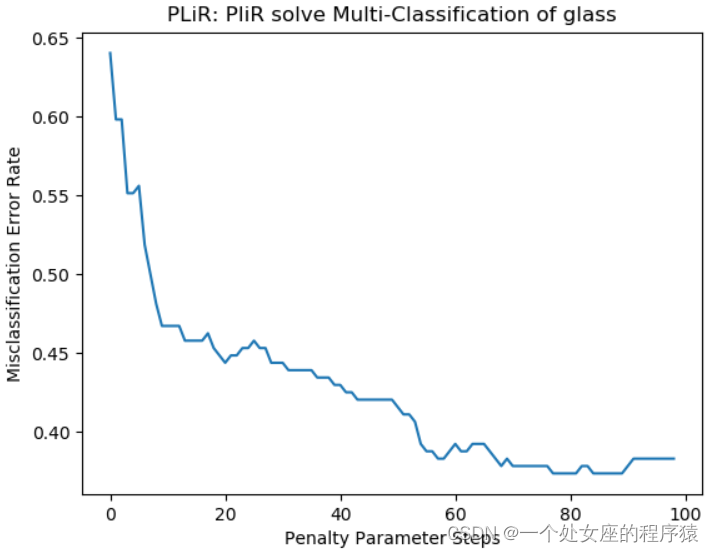
绘制误分类错误随惩罚参数减少的变化图
(3)、在性能随α变化的图上,选择离左边较远的点往往是一个不错方案。因为右侧的点更容易充分拟合数据。
(4)、选择离左边较远的解是相对保守的方案,在这种情况下,很有可能部署错误与交叉验证的错误程度一致。
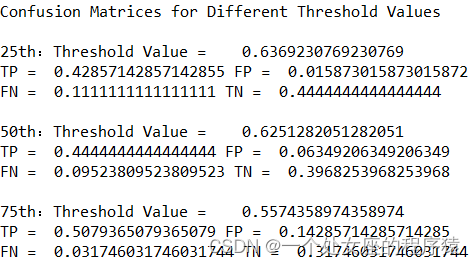
T2、混淆矩阵CE的6个指标AP、mAP、P、R、F1分数、PR曲线
1)、选择一些阈值并计算最佳预测的混淆矩阵,选取25、50和75百分位的阈值
2)、请注意,GBM预测不在(0,1)范围内。
3)、阈值为3个四分位数,结果显示了当阈值从一个分位数转移到另外一个分位数时,假阳性、假阴性是如何变化的。
4)、计算总分、总阳性和总阴性
输出不同阈值下的混淆矩阵,依次输出25th、50th和75th阈值的混淆矩阵
5)、输出最好预测值的混淆矩阵

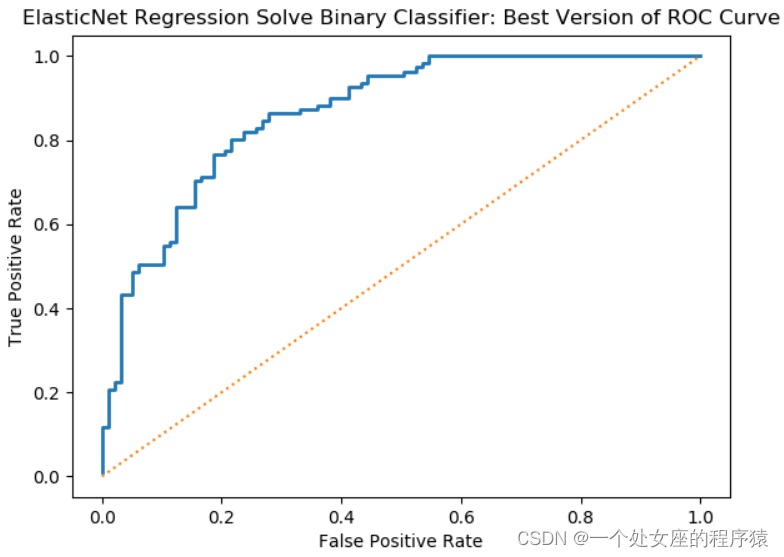
T3、ROC曲线和AUC值
(1)、ROC的曲线各点反映相同的感受性
(2)、绘制ROC曲线:绘制出最佳性能分类器的ROC曲线,即为最大化AUC分类器的ROC曲线;
T2.1、ROC感受性曲线即TPR~FPR曲线
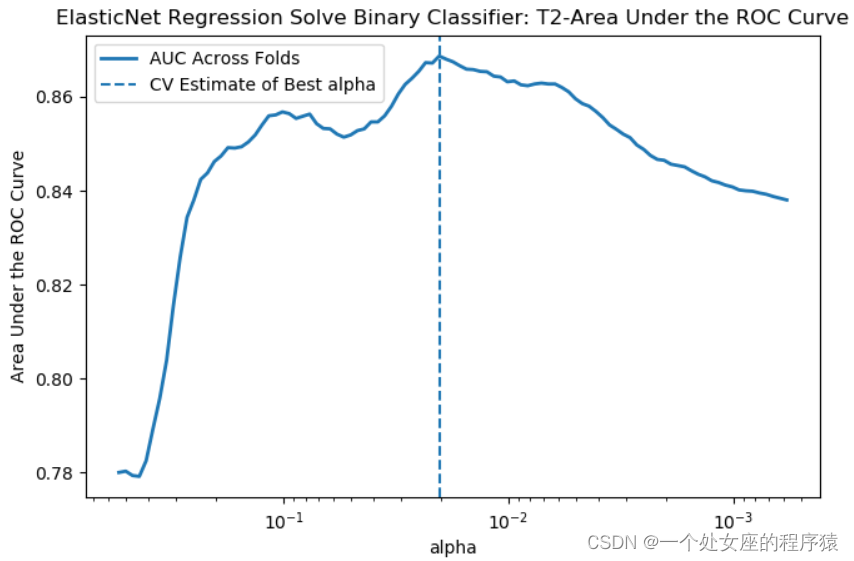
T2.2、AUC即ROC曲线下的面积值
(1)、测试集上,绘制AUC曲线度量分类器性能
测试集上计算AUC的值。生成的曲线从上往下看类似于误分类错误曲线,从上到下是因为AUC的值越大越好,误分类错误越小越好。
AUC与alpha 参数的关系,该图展示了在系数向量上使用欧式长度限制可以降低解的复杂度。
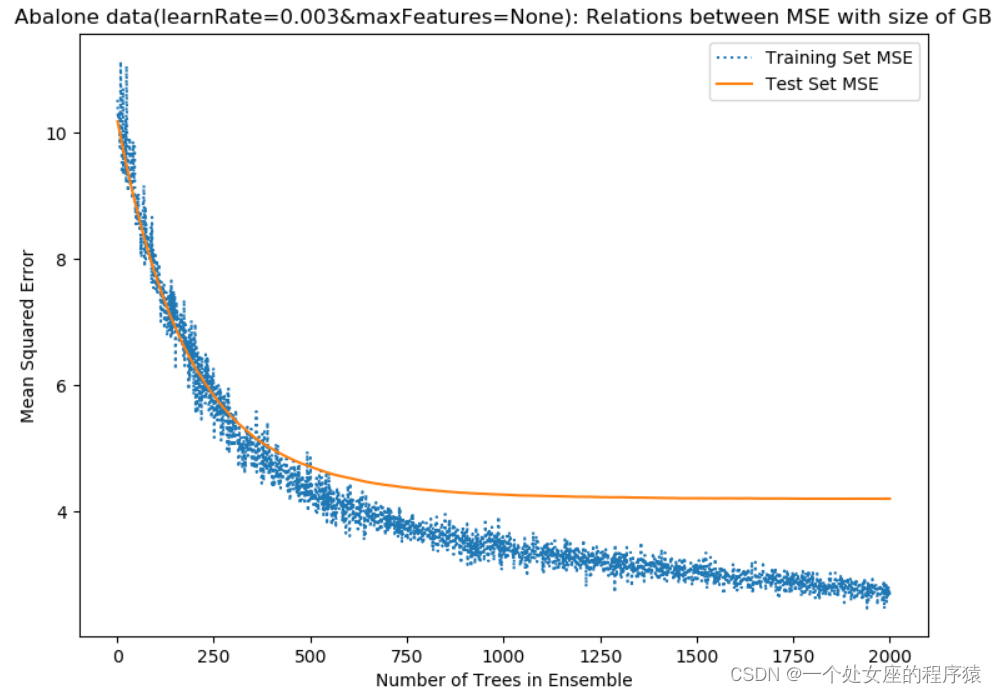
B、【回归】任务中模型常用评估指标:4种
T1、MSE和RMSE
绘制训练集和测试集的errors随着GB中决策树的个数变化曲线
T2、MAE和MAPE
T3、R2
C、【聚类】任务中模型常用评估指标:6个
更多内容详见——聚类任务章节中的聚类模型评估指标
3.3.2、模型调优
| 背景 | 能够调优的内容都可以理解为是一种参数,除了超参数,“选择算法”也可以理解为是一种参数优化。 |
| 简介 | 模型调优包括模型选择调优、模型参数调优、超参数调优。在机器学习中,模型的性能很大程度上取决于其参数和超参数的选择。在参数调优中主要的研究内容是超参数调优。 …… |
| 目的 | 需要同时优化整个建模过程中涉及的所有参数,以达到最佳的模型效果。 |
| 特点 | (1)、耗时性:模型调优通常需要耗费大量时间和计算资源。 …… |
| 调参方法 | (1)、超参数调优可以采用自动调参工具进行优化,如网格搜索、随……等方法。 …… |
| 实战 | T1、单参数for循环搜索 T2、多参数搜索:四大参数搜索方法在在后边章节 |
ML/DL模型调参:机器学习和深度学习中模型调优的简介、模型参数调优VS超参数调优、常用调参优化方法(整体调优-手动调参/随机调参/网格调参/贝叶斯调参)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/125548554
3.3.2.1、模型算法选择调优
3.3.2.2、模型参数调优
3.3.2.3、超参数调优
模型结构相关参数的调优:比如增加神经网络的深度和宽度会改变模型的拓扑结构,从而影响模型的性能和训练效率。
(1)、在深度学习中,通常采用试错的方式调整模型结构,尝试不同的深度和宽度组合,从而找到最优的结构。这个过程可以手动进行,也可以使用自动调参工具进行优化,如……等方法。
| 超参数 | 超参数是指模型结构或训练过程中,无法通过数据学习得到的参数,需要手动设置的参数,当然也包括模型深度和宽度结构相关的参数。 |
| 简介 | 超参数(hyperparameters)调优是指在训练模型时,…… (1)、超参数调整是一种“艺术形式”而不是科学:…… (2)、有时候会放大不正确的…… |
| 内容 | T1、模型内部超参数调优 T2、模型外部超参数调优(网络结构的深度和宽度) |
| 意义 | 超参数是模型上的神奇数字:…… |
| 目的 | 优化模型性能,提高模型的准确性,使其在新数据上表现最佳。…… |
| 调参原因 | 如果依赖于模型开发人员的默认超参数,这些参数值的组合可能完全不适合你的问题。 (1)、比如,有的案例使用类似的MNIST数据集为类似任务,优化的基线默认超参数提高了315%。所以,需要进行自动调参,找到适合自己数据集所对应的超参数组合。 |
| 核心技术 | 超参调整范围:要基于经…… 交叉验证技术:超参数的选择通常需要进行多次试验和调整—交叉验证等技术,以找到最佳的…… |
| 常见的超参数 | 1、机器学习中通用的超参数: (1)、学习率:控制每次参数更新的步长,如果学习率设置过小,模型训练速度会很慢;如果学习率设置过大,会导致模型训练不稳定。通常可以采用网格搜索、随机搜索、学习率衰减等方法调整学习率。 (2)、优化器:用于更新模型参数的算法,包括SGD、Adam、RMSprop等。通过调整优化器的超参数,可以控制模型的收敛速度和精度。 (3)、正则化参数:通过在损失函数中加入正则项的方法来惩罚模型复杂度,避免过拟合。常见的正则化方法包括L1正则化、L2正则化和Dropout。通过调整正则化参数可以控制模型复杂度,避免过拟合。 (4)、迭代次数:指模型在训练数据上迭代的次数,如果迭代次数设置过小,模型可能无法充分学习数据;如果迭代次数设置过大,可能会导致模型过拟合。 2、传统机器学习中的超参数:比如DT/RF/XGBOost中的树的个数、树的深度等。 3、深度学习中神经网络结构相关的超参数:包括神经网络的层数、每层神经元的个数、激活函数的选择等,调整神经网络结构可以影响模型的性能和训练效率。 (1)、批次大小/批量大小:控制每次参数更新所使用的数据量,如果批次大小设置过小,会导致模型训练速度变慢;如果批次大小设置过大,可能会导致模型过拟合。 (2)、训练轮数:与数据集的规模和批次大小有关系。 |
ML/DL模型调参:深度学习神经网络超参数调优简介、自适应调参、基于网格搜索(逐个调优,如batch_size/epoch/lr/优化器/激活函数/Dropout 正则化/神经元个数等)
https://yunyaniu.blog.csdn.net/article/details/104833424
T1、模型内部超参数调优
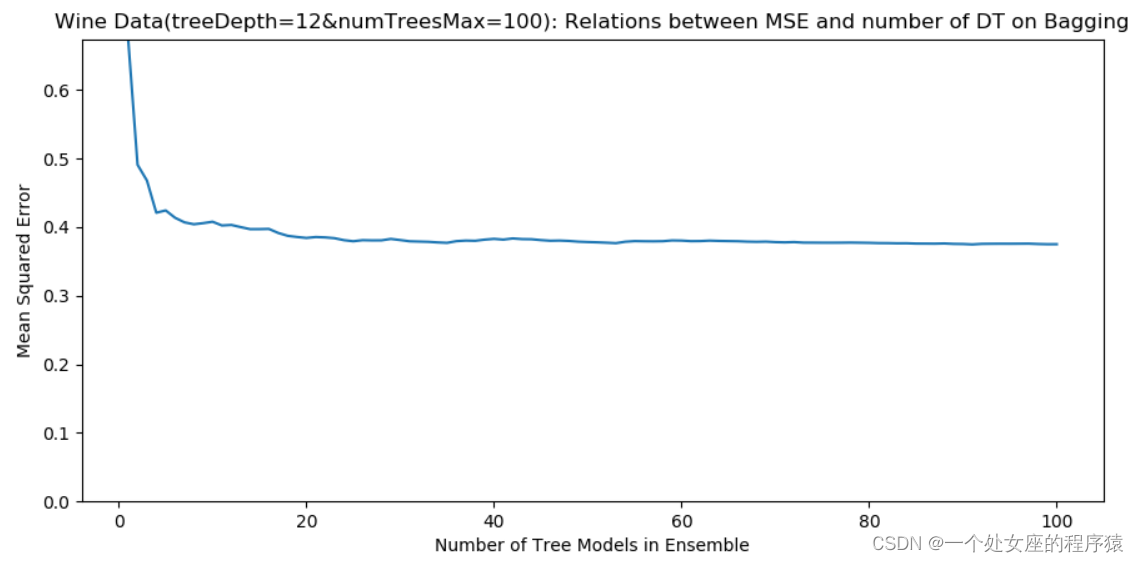
(1)、当决策树深度=12 时,Bagging 集成方法的均方误差与决策树数目的关系
可知,可以采用更深的树、更多的决策树个数可以进一步提升Bagging 集成方法的性能
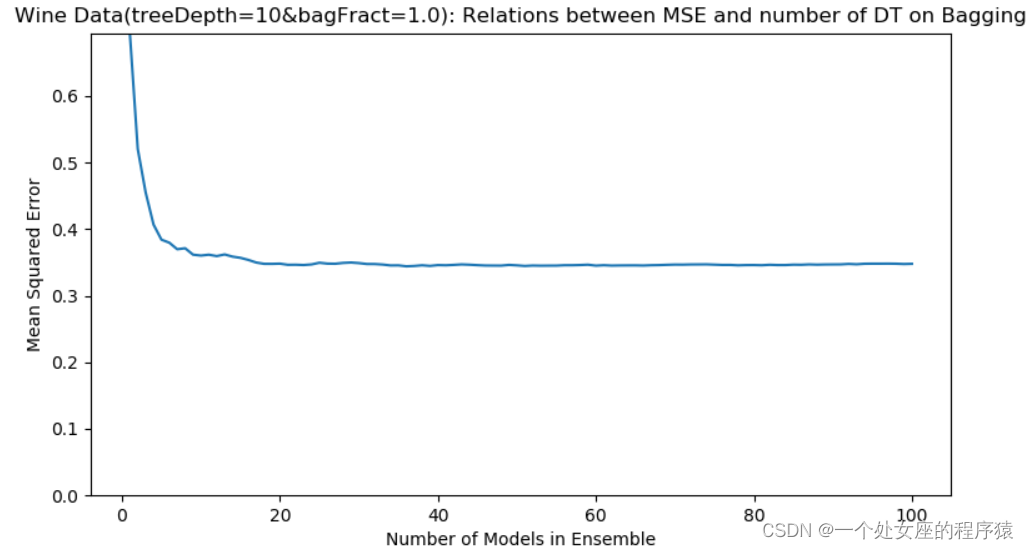
(2)、当treeDepth=10、bagFract=1.0时,训练用的自举样本规模与初始数据集规模一样。在上述参数设置条件下,Bagging 取得了与RF、GB同级别的性能。
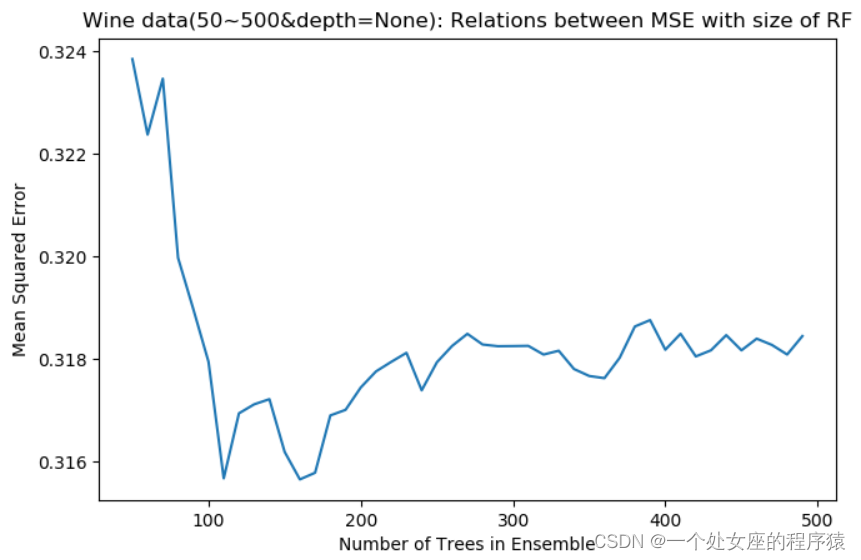
(3)、绘制训练集和测试集的errors随着RF中决策树的个数变化曲线
展示了RF算法的减少方差的特性。随着RF数目的增加,预测误差在下降,曲线的统计波动也在减少。RF产生近乎独立的预测,然后取它们的平均值。因为是取平均值,增加更多的决策树不会导致过拟合,因此图中曲线上的最小值是统计上的波动造成的,不是可重复的最小值。
T2、模型外部超参数调优(网络结构的深度和宽度)
3.3.2.4、模型调参方法
T1、随机搜索参数/随机调参
T2、……调参(交叉验证取平均):耗时最短
T3、……调参(交叉验证取平均):耗时最长
T4、……调参(交叉验证取平均)
T5、……调参(交叉验证取平均)
3.3.3、对比预测值与真实值:误差/残差绝对值的可视化
| 简介 | 比较两个不同的模型预测值与真实y值,并输出误差绝对值、对比可视化 |
| 方法 | T1、【回归预测】折线图可视化; T2、【分类预测】散点图可视化; |
T1、【分类】任务中折线图可视化
(1)、预测值与真实值相差对比之折线图可视化
T1、折线图可视化之实值对比
T2、折线图可视化之误差绝对值对比:比较两个不同的回归模型预测值与真实y值,并输出误差绝对值、对比可视化
ML之FE:基于波士顿房价数据集利用LightGBM算法进行模型预测然后通过3σ原则法(计算残差标准差)寻找测试集中的异常值/异常样本
https://yunyaniu.blog.csdn.net/article/details/130606128
ML:根据不同机器学习模型输出的预测值+且与真实值相减得到绝对误差对比+误差可视化
https://yunyaniu.blog.csdn.net/article/details/94052293
QuantitativeFinance:量化金融之金融时间序列分析—时间序列建模之ARIMA建模流程以及如何通过ACF和PACF图确定ARIMA模型的参数p、d、q之详细攻略
https://yunyaniu.blog.csdn.net/article/details/129640276
Math之ARIMA:基于statsmodels库利用ARIMA算法(ADF检验+差分修正+ACF/PACF图)对上海最高气温实现回归预测案例
https://yunyaniu.blog.csdn.net/article/details/129633598
Math之ARIMA:基于statsmodels库利用ARIMA算法对太阳黑子年数据(来自美国国家海洋和大气管理局)实现回归预测(ADF检验+LB检验+DW检验+ACF/PACF图)案例
https://yunyaniu.blog.csdn.net/article/details/129651655
Math之ARIMA:基于statsmodels库利用ARIMA算法(ADF检验+差分修正+ACF/PACF图)对上海最高气温实现回归预测案例
https://yunyaniu.blog.csdn.net/article/details/129633598
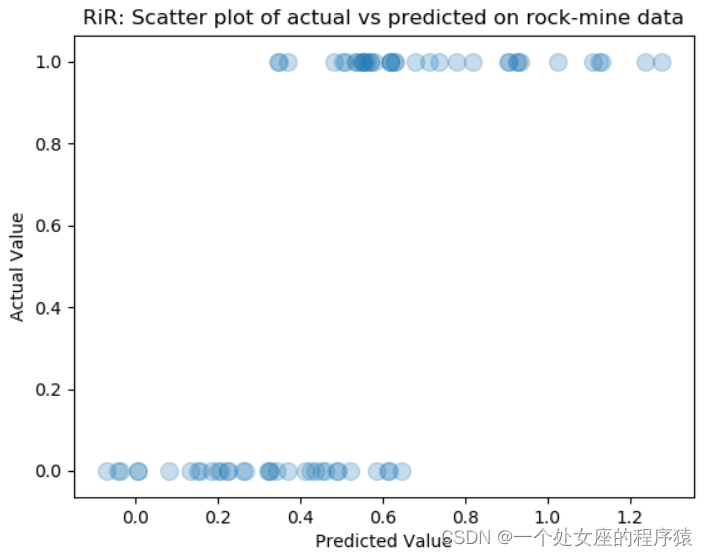
T2、【分类】任务中散点图可视化
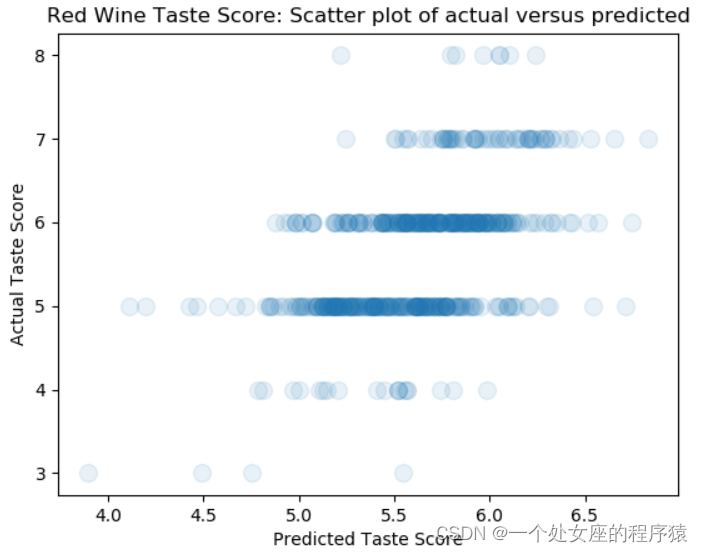
实际分类结果与分类器预测结果的散点图。该图与红酒预测中的散点图类似。因为实际预测的输出是离散的,所以呈现2 行水平的点。
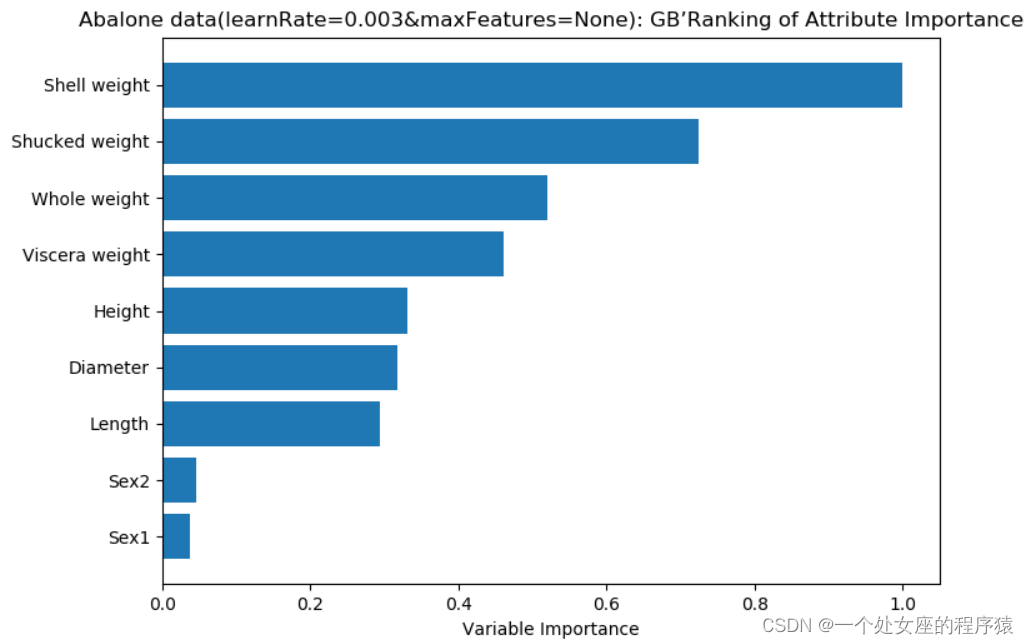
3.4、模型特征重要性可视化分析
| 分类 | 不同的机器学习算法模型有不同的计算特征重要性的方法 T1、线性模型:…… T2、树类算法:…… T3、神经网络算法:可以通过计算每个特征对模型输出的影响程度(敏感程度)来得到。 |
| 其它算法 T4、朴素贝叶斯算法:……。 T5、KNN算法:…… T6、支持向量机算法:可以通过计算每个特征在支持向量中的权重来得到。支持向量的权重越大,表示该特征在模型中的重要性越高。 | |
| 实战 | T2.1、XGBR库自带的plot_importance进行特征重要性排序并可视化 T2.2、lgbm库自带的feature_importance进行特征重要性排序输出 T2.3、catboost 库自带的feature_names_函数和feature_importances_函数 |
| 经验积累 | (1)、最好先按最大最小重要性进行归一化,再输出相对重要性—模型重要性占比 |
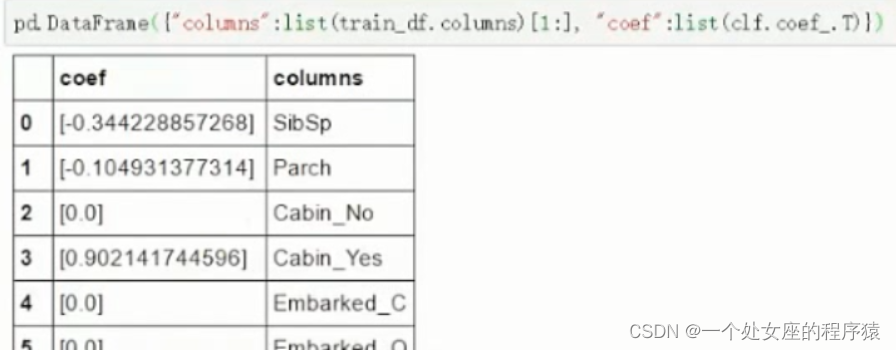
T1、线性模型
T1.1、LiR算法可以输出其截距与各个特征权重
由代码导出所有特征及其对应权重,观察最高权重和最低权重对应的字段
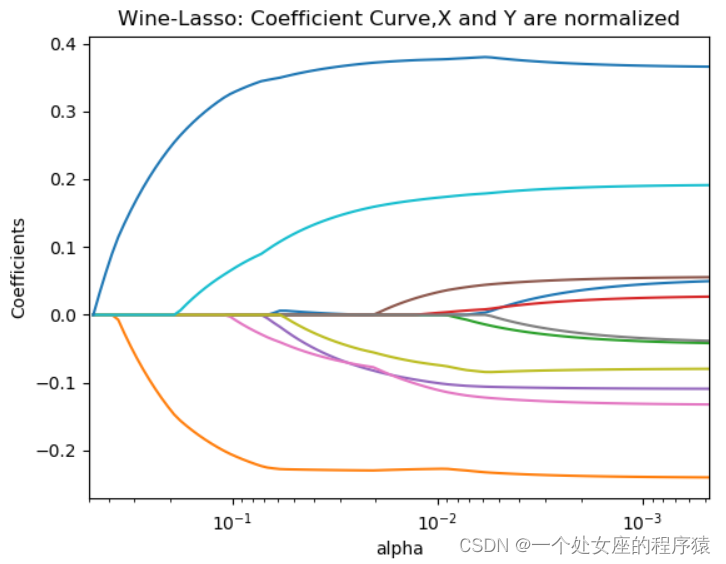
T1.2、Lasso算法的系数曲线:分别为基于归一化属性以及非归一化属性
1)、基于非归一化属性的系数曲线,相较于归一化属性的系数曲线更加无序。
2)、几个早期进入解的系数相对于后续进入解的系数更接近于0。这种现象正好证明了系数进入模型的顺序,与最佳解的系数尺度的顺序存在本质不同。

T2、树类算法
3.5、误差/误分类分析
| 背景 | 机器学习领域,会经常对模型预测后的结果进行分析,比如在分类任务中会经常遇到被误分类的样本,在回归预测任务中会经常遇到被预测偏低或者偏高的样本,这个过程叫做模型的误差/误分类分析。 |
| 简介 | Bad-case分析,…… |
| 目的 | 误差/误分类分析可以帮助我们更全面地审视模型,…… |
| 意义 | 为了更好地分析模型的错误类型,…… |
| 思路 | 主要是针对【分类】预测任务中: …… |
| 分析角度 | 主要是针对【分类】预测任务中: …… |
| 分析方法 | 统计:统计错误样本的数量、错误率、错误样本的特征分布等。 可视化:使用 confusion matrix 矩阵、heatmap、散点图等可视化手段。 |
| 经验技巧 | (1)、按照错误高频特征再训练一个专门的模型。 (2)、对错误高频的样本加强监督,优化训练数据。 (3)、集成学习:比较有效减少整体错误率。 |
ML:机器学习模型提效之监督学习中概率校准的简介、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130570112
ML之LoR:基于泰坦尼克号数据集分别利用Platt校准和等距回归校准算法实现概率校准进而提高二元分类模型的预测准确性(模型提效)应用案例
https://yunyaniu.blog.csdn.net/article/details/130570325
A、【分类】任务中
B、【回归】任务中
3.6、模型导出与推理(基于无标签的新数据)
| 简介 | 模型推理是将训练好的模型应用到实际数据中,进行预测、分类、聚类等操作的过程。具体地,指将训练好的模型从训练环境中导出,以便在实际应用场景中使用。导出后的模型可以被部署到服务器、嵌入式设备或移动设备等上,用于对新数据进行预测或分类操作。 模型导出可以是一次性的,也可以是定期进行的。模型导出的目的是为了提高模型的可用性和生产力。 |
| 目的 | 模型导出的目的:…… |
| 涉及内容 | 三大内容 …… |
| 意义 | 模型导出的意义:将训练好的模型导出,把模型转换为可以部署使用和分享的形式,可以极大地提高的可移植性和灵活性,同时保证模型的一致性和稳定性。 (1)、离线推理节省资源:…… |
| 思路 | 第一步,加载训练好的模型; 第二步,…… |
| 模型导出 | 模型导出的三种方式:可以分开保存模型结构(architecture)和权重参数(weights),然后在推理时加载。 (1)、导出整个模型(模型结构和参数):…… (2)、仅导出模型文件: (3)、仅导出模型权重参数:…… (4)、仅导出模型结构:…… |
| 核心技术点 | 模型推理提效:模…… 设计推理专用轻量化模型—优化压缩:通过裁剪、量化等技术,优化后的模型专门用于推理。 (1)、仅保存需要的层:…… |
| 经验积累 | (1)、新数据的预处理方式要与训练数据保持一致,否则…… |
| 转换文件 | (1)、转 FlatBuffers 格式:利用 FlatBuffers 等格式将模型压缩后导出。 (2)、转…… |
3.6.1、模型导出和模型载入
| 模型导出 | 模型载入 | |
| 简介 | 对于训练好的模型,导出模型是把模型转换为可以部署使用和分享的形式。 模型导出通常包括模型结构和参数两部分,以便能够在不同的环境中重建相同的模型。 | |
| 常用方法 | (2)、仅导出模型文件: T1、利用joblib库导出pkl模型文件 T2、利用…… T5、利用PT框架导出pth和onnx模型文件 (3)、仅导出模型权重参数 (4)、仅导出模型结构 T1、利用自身算法库导出模型结构:比如利用lightgbm的save_model导出模型结构的txt文件; | (1)、仅载入模型文件 T4、载入pmml模型文件:利用pypmml.Model载入 |
| 经验技巧 | (1)、选择合适的导出格式和方法,可以大大提高模型导出的效率和性能。 (2)、精度要求:检查导出模型的精度是否满足产品需求; (3)、文件大小要求:尽量以小的体积存储已经训练好的模型。 | |
| 注意事项 | (1)、结构一致性:检查导出的模型结构是否与训练结构一致; (2)、效…… (3)、环境…… (4)、规避版权和IP问题,避免公开完整模型代码; |
MLOPS:数据科学/机器学习工程化—模型开发四大技术之模型持久化技术(使用时不再训练)之模型导出与载入常用文件格式对比(pkl/pickle、pth、h5、PMML、ONNX 、json)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130656042
TF之DNN:基于泰坦尼克号数据集(独热编码)利用Tensorflow框架的浅层神经网络算法(h5模型文件/模型参数/json模型结构/onnx文件格式的模型导出和载入)实现分类预测应用案例
https://yunyaniu.blog.csdn.net/article/details/130652148
PT之DNN:基于泰坦尼克号数据集(独热编码/标签编码)利用PyTorch框架的浅层神经网络算法(pth和onnx文件的模型导出和载入推理)实现二分类预测应用案例
https://yunyaniu.blog.csdn.net/article/details/130653053
3.6.2、模型推理
| 简介 | 模型实时推理是指将训练好的机器学习模型应用于生产环境,对实时产生的数据进行预测。这一过程通常包括模型的导入、数据预处理、模型预测、结果后处理以及结果输出等环节。 |
| 应用价值 | 将训练好的模型部署到生产环境,可以帮助企业或个人解决实际问题,实现数据驱动的决策。 |
| 本质 | 模型推理在生产环境中是机器学习的最终目标,它可以应用于各种领域,如图像识别、自然语言处理、推荐系统等,可以自动化和提高各种应用的效率和准确性,节省人力和物力成本。 |
| 原则 | 生产环境中的模型推理通常…… |
| 特点 | 实时性:…… 自动化:…… |
| 常用方法 | 本地部署:…… |
| 核心技术点 | 模型提效: (1)、模型优化,为了提高模型推理的速度和准确性…… 模型提速: (1)、选择专门的硬件或软件加速…… (2)、对模型进…… (3)、多…… (4)、批…… (5)、分…… |
| 经验技巧 | (1)、数据流水线化—进而实现自动化:构建高效的数据流水线,从数据输入到模型推理输出,实现端到端的高效处理,提高模型推理的速度和效率。 (2)、数据预处理:确保生产环境中的数据预处理流程与模型训练时的预处理流程一致,以保证模型的预测准确性。 (3)、异常数据处理:对模型的输入数据进行合法性检查,对异常数据进行处理,避免模型推理时的错误。 (4)、模型推理的质量评估:这也是很重要的,需要选择合适的评价指标,并进行测试和验证,以确保模型在生产环境中的准确性。 |
| 注意事项 | (1)、运维:在生产环境中,模型推理需要考虑实时性和可靠性,需要进行充分的测试和评估,并具备自动化的运维和监控机制。关注容错与恢复,设计容错机制,确保模型在生产环境中的稳定运行。 (2)、保护:需要对模型和数据进行保护,以防止泄漏和滥用,同时需要遵守相关法律法规和隐私政策。 (3)、业务:模型推理需要和实际业务场景结合,充分理解业务需求和用户需求,以实现最佳的性能和用户体验。 |
四、模型分析/反思/再优化—提效总结
4.1、模型提效总结概述
| 模型分析 | (1)、结合实际代价综合分析—合理设计成本代价:实际问题需考虑误分类成本代价,解决方法采用混淆矩阵CM。 T1、赋权重最小总代价化 T2、数据均衡化 |
| 目的 | 提高模型性能 |
| 常用方法 | 数据层面 (1)、数据增强:…… |
| 算法层面 (1)、算法挑选: ……
|
4.2、数据扩展—特征构造、数据扩张(引入外部数据)
| 简介 | 数据的基扩展:基于原始数据的样本量、特征个数进行扩展,来改进性能 |
| 思路 | T1、原数据重采样调优 T2、改变特征或样本个数调优 |
4.3、算法改进——模型提效技巧点☆
| 思想 | 不同模型会使用不同的…… |
| 经验总结 | 1、对于集成模型,…… 2、对于线性模型,…… |
ML之FE:树类模型、基于样本距离的模型在特征工程/数据预处理阶段各自的特点和处理技巧之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130397774
ML之FE:在机器学习领域,常见的机器学习算法各自对【数值型】特征和【类别型】特征的处理技巧总结以及有哪些算法喜欢高斯分布类型的数据
https://yunyaniu.blog.csdn.net/article/details/130599888
4.4、集成学习/模型融合/构建集成模型—模型提效技巧点☆
4.4.1、集成学习/模型融合/构建集成模型的概述
| 简介 | 集成学习/模型融合(Model Ensemble)是指将多个模型的预测结果结合起来,以达到比单一模型更好的性能的一种技术。它是一种提高机器学习模型性能的技术,通过结合多个模型的预测结果来获得更好的预测效果。这种方法可以有效地减少单个模型的过拟合风险,提高模型的泛化能力。 |
| 思路步骤 | 集成学习的主要思路是先通过一定的规则生成多个学习器,再采用某种集成策略进行组合,最后综合判断输出最终结果。 |
| 核心内容 | 三大核心内容 1、如何选择分类器—多样性+偏弱分类器: (1)、一般采用弱…… 2、如何训练多个弱分类器:…… 3、如何组合这些弱分类器—结合策略: 基本分类器之间的整合方式,一般有简单多数投票、权重投票,贝叶斯投票,基于D-S证据理论的整合…… |
| 本质 | 本质是利用多个模型的集成来减少单个模型的偏差(bias)和方差(variance)。通过多个模型的组合,充分利用不同模型的补充性和强弱点,从而获得一个性能更好的最终模型,可以减少模型的过拟合和欠拟合,提高模型的泛化能力,从而达到提高模型性能的目的。 |
| 意义 | 在机器学习领域中,模型融合技术可以用于提高模型的准确性、泛化能力、鲁棒性、稳定性等方面的性能,尤其适用于大规模数据、复杂问题、高维特征等场景下的模型构建和优化。 |
| 目的 | 目的是提高模型的准确性和稳定性。通过结合多个模型,可以降低单个模型的不足,提高整体预测能力。此外,模型融合还可以提高模型的鲁棒性,使其在面对不同类型的数据时表现更加稳定。 利用不同模型的补充性:不同模型可能捕捉不同方面的知识,进行融合可以整合更多信息。 提高预测准确性…… 增强模型稳定性:…… 提高鲁棒性:模型融合可以提高模型在面对不同类型的数据时的鲁棒性。 |
| 优缺点 | 准确度高: 鲁棒性好: 泛化能力好: |
| 可解释性差: 部署困难: 计算量大: | |
| 应用 | 分类问题集成、回归问题集成、特征选取集成、异常点检查集成等。 |
| 经验积累 | (1)、经常会基于…… (2)、模型融合对于线上…… (3)、选取具有多样性的模型进行…… |
4.4.2、集成学习/模型融合/构建集成模型的三大层面、四大策略、四大分类
| 三大层面 | T1、模型推理结果层面的融合…… T2、特征层面分割后的融合…… T3、模型层面堆叠的融合…… |
| 四大策略 | Bagging集成学习:通过自助采样(Bootstrap Aggregating)生成多个训练集,然后训练多个模型并进行投票或简单平均。代表性算法:随机森林(Random Forest)。 Boosting迭代学习:通过迭代地训练一系列弱学习器,并根据前一个学习器的错误调整样本权重。代表性算法:AdaBoost,GBDT,XGBoost,LightGBM。 Stacking堆叠学习:将多个模型的预测结果作为输入,训练一个元模型(Meta-model)进行最终预测。代表性算法:Stacked Generalization。 Blending混合学习/聚合学习:与Stacking类似,但使用验证集的预测结果作为新特征输入,训练一个元模型(Meta-model,如线性回归算法)进行最终预测。 |
| 四大分类 | 1、基于投票的模型融合方法—Bagging—群众的力量是伟大的…… (1)、硬投票…… (2)、软投票…… 2、基于加权平均的模型融合方法—Boosting—反复学习+权重分配…… 3、基于堆叠的模型融合方法—Stacking和Blending—站在巨人的肩膀上…… 4、基于……… |
| 代码实战 | 【分类】任务 # T1.1、Voting硬投票机制 # T1.2、Voting软投票机制 【回归】任务 # T1.1、加权平均融合模型 # T1.2、mean平均融合模型 # T1.3、median取中位数融合模型 # T1.4、采用基于MAE系数的加权融合模型 # T1.5、采用基于MSE系数的加权融合模型 # T1.6、采用基于R2系数的加权融合模型 # T1.7、基于R2或MSE的模型权重矩阵筛选:通过评估验证集筛选最佳权重,是一种不错的筛选方式 |
ML之EL:集成学习/模型融合/构建集成模型的简介(三大层面/四大策略/四大分类)、相关库函数/工具(Scikit-learn框架/PyTorch/TensorFlow框架等)、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/81746396
ML之EL:集成学习/模型融合/构建集成模型的简介之Bagging和Boosting算法的联系和区别、Stacking和Blending算法的联系和区别
https://yunyaniu.blog.csdn.net/article/details/130668384
4.5、模型过拟合/欠拟合问题
| 判断 | 在模型训练中,可以通过监控模型在训练集和测试集上的表现来判断模型是否存在过拟合或欠拟合。 |
| 简介 | 过拟合和欠拟合是机器学习中常见的问题,它们会影响模型的预测能力和泛化能力。但是,在很多任务中,更多的是处理过拟合的问题。 在训练模型时,应该尽量避免过拟合和欠拟合。可以通过交叉验证等方法来评估模型的性能,同时使用不同的算法和参数来寻找最优的模型; |
| 思考 | 过拟合一定程度上是难以完全避免的,关键是找到一个合适的trade-off。 |
| 判断 | 如何判断模型过拟合? 可视化训练曲线:…… |
| 经验积累 | (1)、在使用集成学习方法时,应该注意不…… (2)、通过交叉验证(Cross Validation)来选择最优的模型,减少过拟合的影响。 –将数据集切分成两部分:训练集(training set)和测试集(validation set 或testing set) –在训练集上训练模型,在测试集上对模型进行验证 –为降低切分带来的不确定性,常采用多轮切分 |
ML/DL:机器学习模型优化技术之过拟合和欠拟合问题的简介(6大方法解决过拟合+3大方法解决欠拟合)、从欠拟合到过拟合的变化、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/90579459
ML与Regularization:正则化理论(权值衰减即L1正则化-L2正则化/提前终止/数据扩增/Dropout/融合技术)在机器学习中的简介、常用方法、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/107929447
五、模型发布、部署与监控
5. 1、模型发布
5.1.1、模型发布的概述
| 简介 | 模型发布是指将训练完成的机器学习模型应用到实际生产环境中,以解决实际业务问题并实现模型的实时效果。 |
| 五大内容 | …… |
| 模型七种发布策略 | …… |
| 五大核心技术点 | …… |
| 四大注意事项 | …… |
5.1.2、常见的发布策略—模型七种发布策略
DS/ML:数据科学技术之机器学习领域六大阶段最强学习路线之模型发布、部署与监控——模型发布的简介、模型七种发布策略之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130858264
5. 2、模型部署
5.2.1、模型部署的概述
| 简介 | 模型部署:将训练好的模型部署到生产环境,如云服务器、边缘设备等,以便在实际业务中实现自动化决策和预测。让模型可以对新的数据进行预测和推理,产生实际效益。模型部署是机器学习工程化的最后一步,也是最重要的一步。 模型部署是机器学习工程化过程中非常重要的一步,需要综合考虑环境、技术和业务需求等多个因素,以实现高质量、高效率、可扩展和可重复的模型生产流程。 在数据科学生命周期中,模型部署是至关重要的一步,需确保模型在实际环境中的稳定性、可扩展性和性能。 |
| 原则 | 模型部署的目标是实现可重复和可扩展的流程,以实现自动化的模型生产,同时保证高质量的模型输出和系统性能。 |
| 本质 | 本质是将机器学习算法从研究阶段推进到实际生产应用的阶段。 在于将研究和开发阶段训练好的模型,转化为可在生产环境中运行的服务。 |
| 目标 | 模型服务化:型部署的本质是将研发环境中的模型文件(参数文件、代码等)迁移和推送到生产环境,让模型可以在线上服务。 |
| 八大核心技术 | 1、选择合适的部署方案—基于业务:…… 2、环境依赖与配置—建立开发环境和部署环境…… 3、序列化…… 4、实现模型……用可以访问,接收新的数据后进行推理预测。常用的方法是部署为Web服务或在消息队列等进行推理。 5、模型文件管理…… 6、监控与异常…… 7、自动化部署…… |
| 三大部署方法 | …… |
| 三大服务方法 | 常用模型部署方法有在线Web服务部署、在消息队列中部署、在数据库内部署等。 1、API封装:…… |
| 注意事项 | 1、确保模型的准确性和稳定性:在部署前,需要对模型进行充分的测试和验证,确保模型的准确性和稳定性。 2、保证数据的安全性…… 3、考虑性能和并发…… 4、定期更新和优化…… 5、合理利用资源…… |
| 经验总结 | 模型部署需要花费大量的时间和精力,需要对每一个步骤都进行认真的评估和测试,以确保模型在生产环境中的准确性和稳定性。 1、提前规划…… 2、单元测试…… |
DS/ML:数据科学技术之数据科学生命周期(四大层次+机器学习六大阶段+数据挖掘【5+6+6+4+4+1】步骤)的全流程讲解之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130592322
AI之MLOPS:数据科学/机器学习算法领域之工程化六大核心技术—MLOPS、模型开发(流水线/并行处理/持久化/可解释性)、模型部署(云端服务器)、模型监控、模型管理、自动化技术之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130120082
ML:场景实战之模型部署、测试的疑难杂症(如Training-Serving Skew等,比如AUC指标线下上涨但线上却下降等问题)的经验总结
https://yunyaniu.blog.csdn.net/article/details/130148050
ML与Docker:《Deploy Machine Learning Pipeline on the cloud using Docker Container使用Docker容器在云端部署机器学习管道》的翻译与解读—PyCaret(训练和部署机器学习管道和模型到生产环境中)+Flask(构建Web应用程序)+Docker(通过使用容器来创建-部署-运行应用程序)+Microsoft Azure(云服务)
https://yunyaniu.blog.csdn.net/article/details/129201074
5.2.2、模型上线部署七大流程
AI/ML:人工智能领域-机器学习算法之模型部署的简介(八大核心技术/三大部署方法/三大服务方法)、模型上线部署七大流程、模型训练技术点VS模型部署技术点之详细攻略
https://yunyaniu.blog.csdn.net/article/details/129783816
5.3、模型监控
5.3.1、模型监控的概述
| 简介 | 模型监控是将机器学习模型部署到生产环境后,持续跟踪、定期监控和评估模型性能的过程。主要目的是发现和解决模型性能下降的问题,让模型在生产环境中稳定运行。 |
| 本质 | 模型监控的本质是持续获取测试数据,计算监控指标,与预期值相比较,发现模糊性能下降的迹象。 通过对模型预测结果的监控和分析,及时发现模型的问题,并采取调整模型参数或重新训练模型来修正问题,以保证模型的可靠性和稳定性。 |
| 原则 | 需要设置合理的监控指标,如准确率、召回率、精确率等,记录这些指标随时间的变化情况。 |
| 涉及内容 | 1、模型性能监控(稳定性)—设置预警阈值:周期性计算监控指标。 准确性指标…… 稳定性指标…… 2、数据漂…… 3、模型漏洞…… 4、模型版…… |
| 核心技术点 | 持续获取测试数据(A/B测试、线上样本) 1、指标曲线可视化:…… 2、实时监控…… 3、预警和报警机制…… |
| 常用方法 | (1)、手动采样测试数据,周期性计算监控指标 (2)、使用自动化监控工具,实时自动采集测试数据,计算监控指标。比如Airflow |
| 经验积累 | (1)、自动化和人工相结合:使用自动化…… (2)、不断优化流程:…… |
MLOPS:机器学习算法领域之工程化六大核心技术之模型监控的简介(2大原则/5+1监控内容)、模型稳定性(两大算法策略)、智能风控场景的模型监控、三大类监控工具(ML框架/ML专用/通用监控工具)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130858455
Tool之Airflow:Airflow(管理-调度-监控数据处理工作流的平台/DAG)的简介(可管理和调度机器学习模型的训练和预测过程)、安装、使用方法之详细攻略
https://yunyaniu.blog.csdn.net/article/details/111569808
DataScience&ML:金融科技领域之风控场景之模型监控的意义、具体内容—16大指标【线上线下一致性监控、前端监控(客群稳定性/风控决策全流程)、后端监控(模型性能评估/资产质量分析)、模型表现监控和模型影响分析】之详细攻略
https://yunyaniu.blog.csdn.net/article/details/125436903
补充链接:风控模型监控报告系统设计 - 知乎
ML:机器学习之模型监控阶段—模型稳定性分析的简介、常用的监控指标(CSI/PSI)、提高模型稳定性(通用方法/线性模型场景/树类模型场景)的策略之详细攻略
https://yunyaniu.blog.csdn.net/article/details/125252250
ML之CSI:特征稳定性指标(Characteristic Stability Index)的简介(特征筛选/特征监控、CSI和PSI指标对比)、使用方法、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/125382811
ML之PSI:人群偏移度指标(Population Stability Index)的简介(特征筛选/特征监控/模型监控/AB测试)、使用方法、案例应用(风控业务/风险评估/市场分析等)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/115191030
六、模型全流程优化
AI之MLOPS:数据科学/机器学习算法领域之工程化五大核心技术—MLOPS简介、模型开发(流水线/并行处理/持久化/可解释性)、模型部署(两大底层/四大服务)、模型监控、模型管理、自动化技术之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130120082
6.1、代码优化总结
| 简介 | 在代码优化是指在整个模型全流程中,需要优化代码的质量和效率,以确保模型的高效运行。需要考虑代码的可维护性、可扩展性和可重用性。 |
| 经验总结 | 使用高效的算法:选择时间复杂度和空间复杂度更低的算法。 使用向量化操作:…… 避免使用循环:…… 选择高效的数据结构…… 减少不必要的计算+减少内存使用…… 使用并行计算……进…… |
6.2、系统优化
| 简介 | 系统优化,包括分布式计算、高效存储等技术手段来提高系统的可扩展性、稳定性和可靠性。 |
| 方法 | …… …… …… |
| 核心技术 | …… …… …… |

