
- 1机器学习实践(2.2)LightGBM回归任务
- 2搜索广告召回技术在美团的实践_美团 多模态生成式向量召回
- 3iOS 警告收集快速消除
- 4真实靠谱:百度的职级、T系列、薪资、及晋升潜规则
- 5Python之序列_python序列
- 6【OpenCV】图像/视频相似度测量PSNR( Peak signal-to-noise ratio) and SSIM,视频/图片转换
- 7最新php淘宝客优惠券网站源码
- 8面试题009-Java-MyBatis
- 9解决:安装MySQL 5.7 的时候报错:unknown variable ‘mysqlx_port=0.0‘_mysqlx-port
- 10大模型推理:vllm多机多卡分布式本地部署_vllm 多卡推理
Amazon DocumentDB 与 Amazon OpenSearch Service 的零 ETL 集成现已推出
赞
踩

近日,亚马逊云科技宣布正式推出了 Amazon DocumentDB(兼容 MongoDB)与 Amazon OpenSearch Service 的 零 ETL (Zero-ETL)集成。
Amazon DocumentDB 提供原生的文本搜索和向量搜索功能。借助 Amazon OpenSearch Service,您可以对 Amazon DocumentDB 数据执行高级搜索分析,例如模糊搜索、同义词搜索、跨集合搜索和多语言搜索等。
零 ETL 集成可简化用于高级搜索功能的架构。利用这种集成,您可以摆脱无差别的繁重任务,并消除在两项服务之间构建和管理数据管道架构和进行数据同步的相关成本。
本文将向您展示如何使用 Amazon OpenSearch Ingestion,来配置 Amazon DocumentDB 与 Amazon OpenSearch Service 的零 ETL 集成。这涉及到对 Amazon DocumentDB 数据执行完全加载,并使用变更流将最新数据流式传输到 Amazon OpenSearch Service。有关其他摄取方法,请扫码参阅文档。

Amazon DocumentDB
(兼容 MongoDB)
扫码了解更多

Amazon OpenSearch Service
扫码了解更多

零 ETL 集成
扫码了解更多

Amazon OpenSearch Ingestion
扫码了解更多

摄取方法相关文档
扫码了解更多
左右滑动查看更多
解决方案概览
总体而言,此解决方案涉及以下步骤:
在 Amazon DocumentDB 集合上启用变更流。
创建 Amazon OpenSearch Ingestion 管道。
在 Amazon DocumentDB 集群上加载示例数据。
在 Amazon OpenSearch Service 中验证数据。
先决条件
要实施此解决方案,您需要满足以下先决条件:
一个基于 Amazon DocumentDB 实例的集群。您可以使用现有集群,也可以创建新集群。
一个有效的 Amazon OpenSearch Service 域。您可以使用现有域,也可以创建新域。
一个存储在 Amazon Secrets Manager 中的 Amazon DocumentDB 集群密钥。
一个 Amazon Simple Storage Service(Amazon S3)存储桶。
零 ETL 会对 Amazon DocumentDB 集群的主实例进行集合扫描,以这种方式对集合执行初始的完整加载。根据数据的大小,这可能需要几分钟才能完成,在此期间您会观察到集群的资源消耗上升。

创建新集群
扫码了解更多

创建新域
扫码了解更多

Amazon Secrets Manager
扫码了解更多

密钥
扫码了解更多

Amazon Simple Storage Service
扫码了解更多
左右滑动查看更多
在 Amazon DocumentDB
集合上启用变更流
Amazon DocumentDB 变更流事件由按照时间排序的一系列数据变更组成,这些变更来自于对数据的插入、更新和删除操作。我们使用这些变更流事件,将数据变更从 Amazon DocumentDB 集群传输到 Amazon OpenSearch Service 域。
默认情况下,变更流处于禁用状态;您可以分别在集合级别、数据库级别或集群级别启用变更流。要在您的集合上启用变更流,请完成以下步骤:
使用 mongo shell 连接到 Amazon DocumentDB。
使用以下代码在您的集合上启用变更流。在本文中,我们使用 Amazon DocumentDB 数据库 inventory 和集合 product:
- db.adminCommand({modifyChangeStreams: 1,
- database: "inventory",
- collection: "product",
- enable: true});
左右滑动查看完整示意
如果您有多个集合,并且要将其中的数据流式传输到 Amazon OpenSearch Service,请为每个集合启用变更流。如果您要在数据库或集群级别启用变更流,请扫码参阅 “Enabling Change Streams”。
建议仅为所需的集合启用变更流。

Enabling Change Streams
扫码了解更多
创建 OpenSearch Ingestion 管道
Amazon OpenSearch Ingestion 是一个完全托管式数据收集器,可向 Amazon OpenSearch Service 域提供实时日志和跟踪数据。Amazon OpenSearch Ingestion 由开源数据收集器 Data Prepper 提供支持。Data Prepper 是开源 OpenSearch 项目的一部分。
借助 Amazon OpenSearch Ingestion,您可以筛选、扩充、转换和交付数据,用于在下游进行分析和可视化。Amazon OpenSearch Ingestion 采用无服务器架构,因此您无需操心基础设施的扩展、摄取实例集的运行以及软件的修补或更新。
扫描下面二维码了解 Amazon OpenSearch Ingestion 和有关 Data Prepper 开源项目的更多信息。

Amazon OpenSearch Service 域
扫码了解更多

Data Prepper
扫码了解更多

开源 OpenSearch 项目
扫码了解更多

Amazon OpenSearch Ingestion
扫码了解更多

Data Prepper
扫码了解更多

OpenSearch Ingestion 管道
扫码了解更多
左右滑动查看更多
要创建 Amazon OpenSearch Ingestion 管道,请完成以下步骤:
1、在 Amazon OpenSearch Service 控制台上,在导航窗格中选择管道。
2、选择创建管道。
3、在管道名称中输入名称(例如,zeroetl-docdb-to-opensearch)。
4、设置计算资源的管道容量,以便根据当前的摄取工作负载自动扩展管道。
5、输入最小和最大摄取 OpenSearch 计算单位(OCU,OpenSearch Compute Unit)。在此示例中,我们使用默认管道容量设置,即最少 1 个摄取 OCU 和最多 4 个摄取 OCU。
每个 OCU 由大约 8 GB 内存和 2 个 vCPU 组合而成,估计每小时可处理 8 GiB 的数据。Amazon OpenSearch Ingestion 最多支持 96 个 OCU,它会根据您的摄取工作负载需求纵向扩展和缩减。

6、选择配置蓝图,然后在导航窗格的使用案例下选择零 ETL。
7、选择与 Amazon DocumentDB 的零 ETL 集成以构建管道配置。
此管道由来自 Amazon DocumentDB 设置的 source 部分和 Amazon OpenSearch Service 的 sink 部分组成。
您必须设置多个具有必要权限的 Amazon Identity and Access Management(IAM)角色(sts_role_arn),用于从 Amazon DocumentDB 数据库和集合读取数据,并将数据写入到 Amazon OpenSearch Service 域。然后,Amazon OpenSearch Ingestion 管道将代入此角色,以确保在将数据从源迁移到目标时始终保持应有的安全状态。要了解更多信息,请扫码参阅。
每个 Amazon DocumentDB 集合都需要一个 Amazon OpenSearch Ingestion 管道。

Amazon Identity and
Access Management
扫码了解更多

在 Amazon OpenSearch Ingestion 设置角色用户
扫码了解更多
左右滑动查看更多
- version: "2"
- documentdb-pipeline:
- source:
- documentdb:
- acknowledgments: true
- host: "<<docdb-2024-01-03-20-31-17.cluster-abcdef.us-east-1.docdb.amazonaws.com>>"
- port: 27017
- authentication:
- username: ${{aws_secrets:secret:username}}
- password: ${{aws_secrets:secret:password}}
- aws:
- sts_role_arn: "<<arn:aws:iam::123456789012:role/Example-Role>>"
-
- s3_bucket: "<<bucket-name>>"
- s3_region: "<<bucket-region>>"
- # optional s3_prefix for Opensearch ingestion to write the records
- # s3_prefix: "<<path_prefix>>"
- collections:
- # collection format: <databaseName>.<collectionName>
- - collection: "<<databaseName.collectionName>>"
- export: true
- stream: true
- sink:
- - opensearch:
- # REQUIRED: Provide an AWS OpenSearch endpoint
- hosts: [ "<<https://search-mydomain-1a2a3a4a5a6a7a8a9a0a9a8a7a.us-east-1.es.amazonaws.com>>" ]
- index: "<<index_name>>"
- index_type: custom
- document_id: "${getMetadata(\"primary_key\")}"
- action: "${getMetadata(\"opensearch_action\")}"
- # DocumentDB record creation or event timestamp
- document_version: "${getMetadata(\"document_version\")}"
- document_version_type: "external"
- aws:
- # REQUIRED: Provide a Role ARN with access to the domain.This role should have a trust relationship with osis-pipelines.amazonaws.com
- sts_role_arn: "<<arn:aws:iam::123456789012:role/Example-Role>>"
- # Provide the region of the domain.
- region: "<<us-east-1>>"
- # Enable the 'serverless' flag if the sink is an Amazon OpenSearch Serverless collection
- # serverless: true
- # serverless_options:
- # Specify a name here to create or update network policy for the serverless collection
- # network_policy_name: "network-policy-name"
-
- extension:
- aws:
- secrets:
- secret:
- # Secret name or secret ARN
- secret_id: "<<my-docdb-secret>>"
- region: "<<us-east-1>>"
- sts_role_arn: "<<arn:aws:iam::123456789012:role/Example-Role>>"
- refresh_interval: PT1H

左右滑动查看完整示意
提供蓝图中的以下参数:
Amazon DocumentDB 端点 – 提供您的 Amazon DocumentDB 集群端点。
Amazon DocumentDB 集合 – 按照 collections 部分中的 dbname.collection 格式,提供您的 Amazon DocumentDB 数据库名称和集合名称。例如,inventory.product。
s3_bucket – 提供您的 Amazon S3 存储桶名称以及 Amazon 区域和 Amazon S3 前缀。此存储桶用于临时保存来自 Amazon DocumentDB 的数据,以便进行数据同步。
Amazon OpenSearch 主机 – 提供主机的 Amazon OpenSearch Service 域端点,并提供首选的索引名称用于存储数据。
secret_id – 提供 Amazon DocumentDB 集群密钥的 ARN 及其区域。
sts_role_arn – 提供 IAM 角色的 ARN,该角色应具有 Amazon Document DB 集群、Amazon S3 存储桶和 Amazon OpenSearch Service 域的权限。
要了解更多信息,请参阅 “Creating Amazon OpenSearch Ingestion pipelines”。

Creating Amazon OpenSearch Ingestion pipelines
扫码了解更多
5、输入所有必需的值后,验证管道配置是否有任何错误。

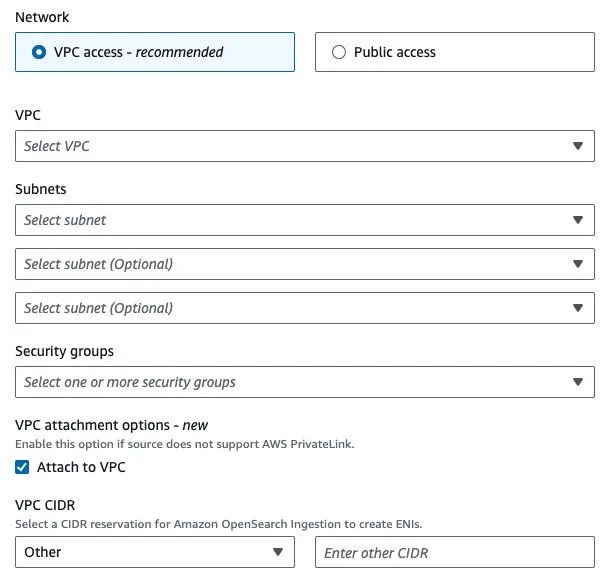
6、设计生产工作负载时,在 VPC 中部署管道。选择您的 VPC、子网和安全组。还要选择附加到 VPC 并选择对应的 VPC CIDR 范围。
安全组入站规则应有权访问 Amazon DocumentDB 端口。有关更多信息,请扫码参阅 “Securing Amazon OpenSearch Ingestion pipelines within a VPC”。

Securing Amazon OpenSearch Ingestion pipelines within a VPC
扫码了解更多
在 Amazon DocumentDB
集群上加载示例数据
完成以下步骤来加载示例数据:
连接到您的 Amazon DocumentDB 集群。
运行以下命令,在 inventory 数据库的 product 集合中插入一些文档。要在 Amazon DocumentDB 上创建和更新文档,请扫码参阅 Working with Documents。

Working with Documents
扫码了解更多
- use inventory;
-
-
- db.product.insertMany([
- {
- "Item":"Ultra GelPen",
- "Colors":[
- "Violet"
- ],
- "Inventory":{
- "OnHand":100,
- "MinOnHand":35
- },
- "UnitPrice":0.99
- },
- {
- "Item":"Poster Paint",
- "Colors":[
- "Red",
- "Green",
- "Blue",
- "Black",
- "White"
- ],
- "Inventory":{
- "OnHand":47,
- "MinOnHand":50
- }
- },
- {
- "Item":"Spray Paint",
- "Colors":[
- "Black",
- "Red",
- "Green",
- "Blue"
- ],
- "Inventory":{
- "OnHand":47,
- "MinOnHand":50,
- "OrderQnty":36
- }
- }
- ])
左右滑动查看完整示意
在 OpenSearch Service 中验证数据
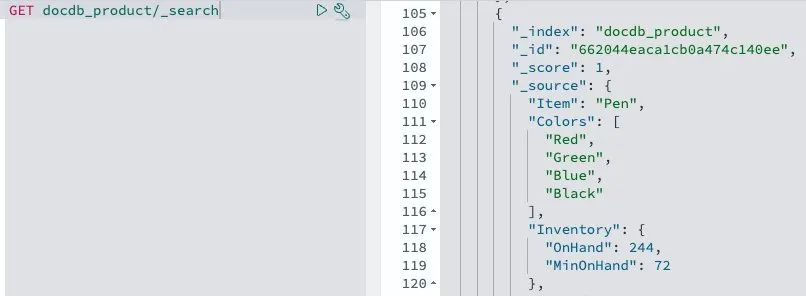
您可以使用 Amazon OpenSearch 控制面板的开发控制台搜索已同步的项目,只需几秒钟时间。有关更多信息,请扫码参阅 “Creating and searching for documents in Amazon OpenSearch Service”。

在 Amazon OpenSearch Service创建和搜索文件
扫码了解更多
要验证变更数据捕获(CDC,Change Data Capture),请运行以下命令,更新 product 集合中现有文档项目 Ultra GelPen 的 OnHand 和 MinOnHand 字段:
- db.product.updateOne({
- "Item":"Ultra GelPen"
- },
- {
- "$set":{
- "Inventory":{
- "OnHand":300,
- "MinOnHand":100
- }
- }
- });
左右滑动查看完整示意
在 Amazon OpenSearch Service 索引上,验证 CDC 中对项目 Ultra GelPen 的文档所进行的更新。
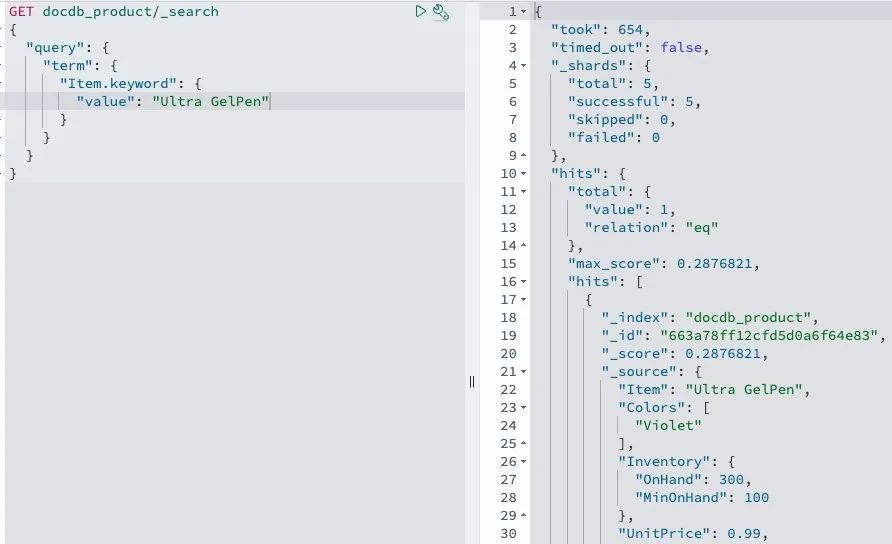
监控 CDC 管道
您可以在 Amazon OpenSearch Service 控制台上查看管道的状态,从而监控管道的状态。此外,您还可以使用 Amazon CloudWatch 来提供实时指标和日志,这样您就可以设置警报,以防超出用户定义的阈值。

Amazon CloudWatch
扫码了解更多
清理
按照本文,您可能会创建一些不再需要的亚马逊云科技资源,请确保清除这些资源,以免产生额外的费用。请按照以下步骤清理您的亚马逊云科技账户:
在 Amazon OpenSearch Service 控制台上的导航窗格中,选择托管集群下的域。
选择要删除的域,然后选择删除。
在导航窗格的摄取下,选择管道。
选择要删除的管道,然后在操作菜单上选择删除。
在 Amazon S3 控制台上,选择 Amazon S3 存储桶,然后选择删除。
总结
本文介绍了如何在 Amazon DocumentDB 变更数据流与 Amazon OpenSearch Service 之间启用零 ETL 集成。要详细了解可用于其他数据来源的零 ETL 集成,请扫码参阅 “Working with Amazon OpenSearch Ingestion pipeline integrations”。

Working with Amazon OpenSearch Ingestion pipeline integrations
扫码了解更多
本篇作者

Praveen Kadipikonda
亚马逊云科技高级分析专家级解决方案构架师。他帮助客户构建高效、高性能且可扩展的分析解决方案。他在构建数据库和数据仓库解决方案等领域工作超过 15 年。

Kaarthiik Thota
亚马逊云科技 Amazon DocumentDB 专家级解决方案架构师。他对数据库技术充满热情,喜欢使用 NoSQL 数据库帮助客户解决问题和打造现代化应用程序。他工作经验深厚,在关系数据库、NoSQL 数据库和商业智能技术领域工作超过 15 年。

Muthu Pitchaimani
亚马逊云科技 Amazon OpenSearch Service 的搜索专家。他构建大规模的搜索应用程序和解决方案。Muthu 的兴趣在于网络和安全等领域,

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」
点击阅读原文查看博客,获得更详细内容
听说,点完下面4个按钮
就不会碰到bug了!


