
- 1Golang中读写锁的底层实现
- 2在 Linux 上使用 lspci 命令查看 PCI 总线硬件设备信息_怎样查看pci设备的设备功能号
- 3sequoiadb java使用_Java开发基础_Java驱动_开发_JSON实例_文档中心_SequoiaDB巨杉数据库...
- 4python安装缺失_python: 自动安装缺失库文件的方法
- 5【边缘检测】基于matlab八方向sobel图像边缘检测【含Matlab源码 1865期】_matlab sobel
- 6OpenAI回应马斯克诉讼:其因个人恩怨而起诉;苹果硬件工程灵魂人物Dan Riccio将退休;AI网络蠕虫被曝光| 极客头条...
- 7助力制造企业降本增效,生成式AI技术大有可为
- 8MYSQL数据库第七次作业---视图_数据库视图的创建含分组和排序
- 9完美解决 studio sdk tools 缺失下载选项问题_mac android-sdk 缺少 tools
- 10windows下编译tensorflow Faster RCNN的lib/Makefile
Amazon Bedrock实践 - AIGC应用助力企业降本增效之路_bedrock的应用
赞
踩
一、前言:
近年来,随着深度学习、大数据、人工智能、AI等技术领域的不断发展,机器学习是目前最火热的人工智能分支之一,是使用大量数据训练计算机程序,以实现智能决策、语音识别、图像处理等任务。
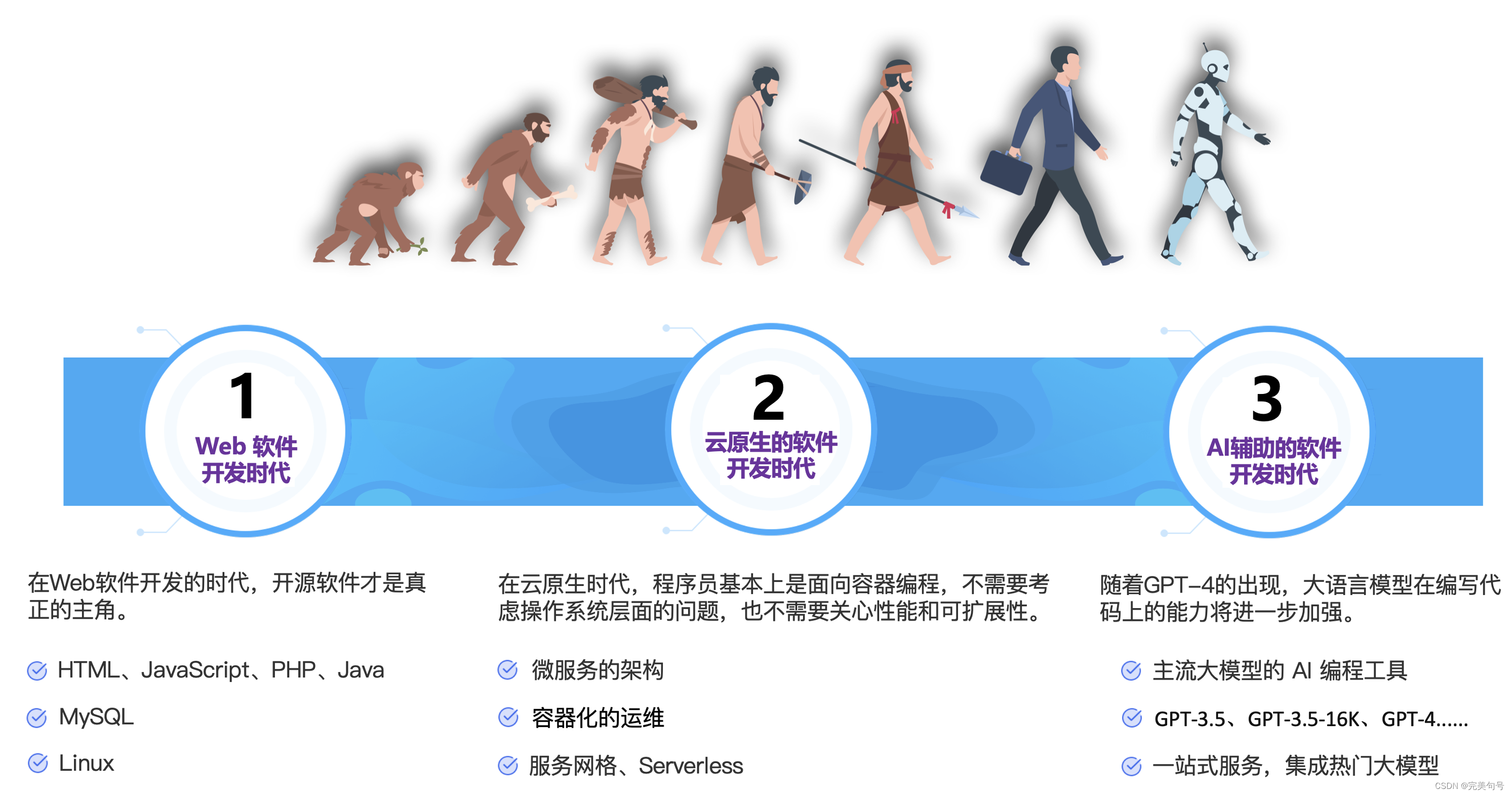
作者也是经过了以上几个阶段的软件开发历程,从Web时代编程、到云时代分布式编程,到如今的AI时代,传统编程是人类程序员手动编写代码来实现特定的功能,而机器学习是通过让计算机程序从数据中学习,自动地提取特征和规律来实现功能。
GPU的广泛应用促进了AI技术的发展,通过GPU的高速计算能力,开发者可以更快地训练模型、测试算法,从而促进AI技术的迅速发展。GPU的出现和发展,也为AI领域的新算法、新模型的研发提供了更多的可能性。
如何解决人工智能(机器学习)模型训练与推理、高性能计算等,往往是对于算法、算力和大数据都是实现大规模应用的必备条件?
在构建自己AIGC技术体系的过程中,需要消耗大量的人力与物力,往往事倍功半,Amazon Bedrock 提供了构建生成式人工智能应用程序所需的一切,它是专门为创新者量身打造的平台。
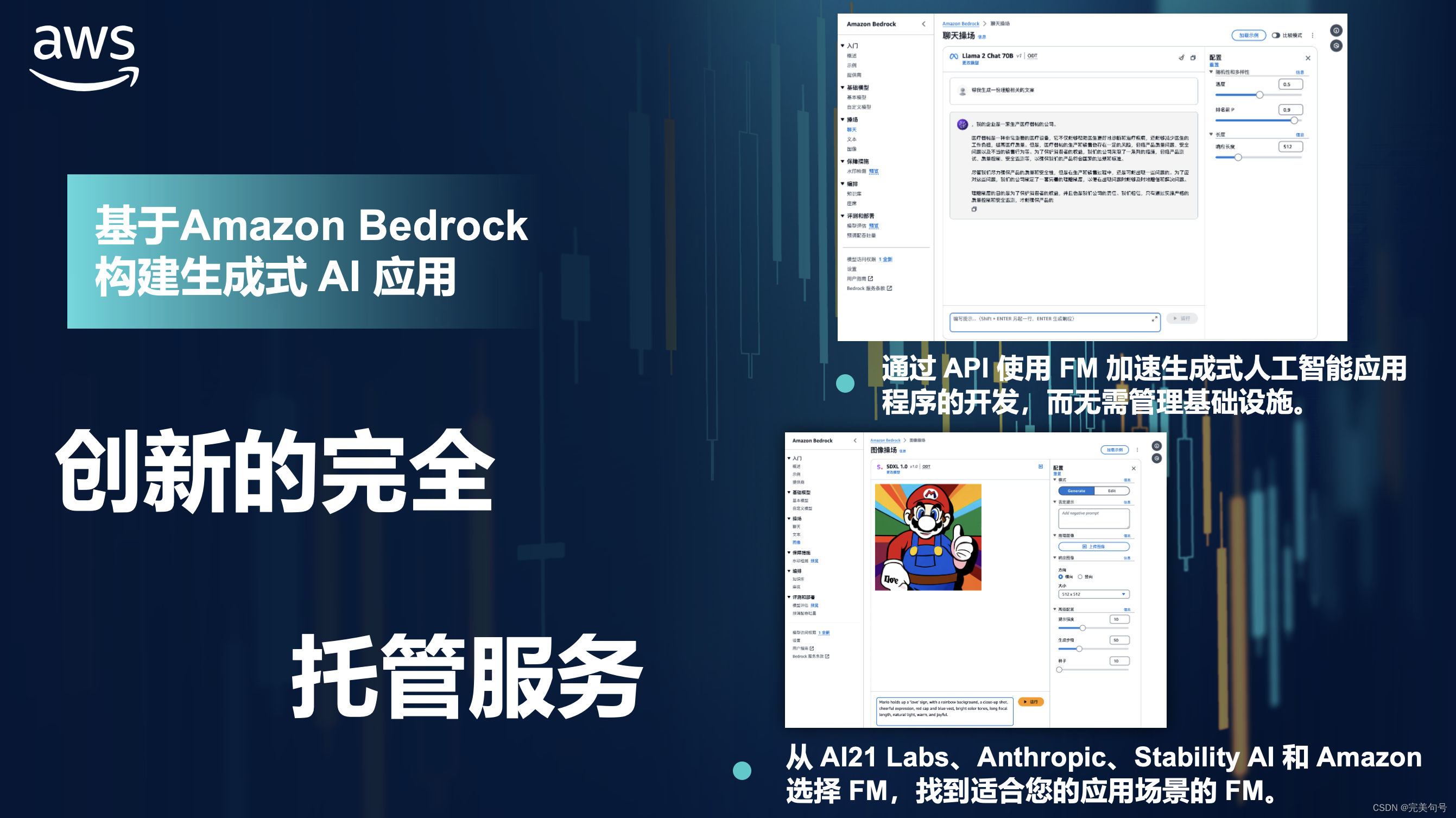
最近Aws推出了一款“高性能的AI应用服务”,融合了人工智能(AI)和机器学习(ML)创新,通过完全托管的 API 提供一系列高性能图像、多模态和文本模型选项。是一款面向 Al应用为中心,亚马逊云科技基于大型数据集对这些模型进行了预训练,使它们成为强大的通用模型,旨在支持各种使用案例,同时还支持负责任地使用人工智能,实现即插即用,助力中小企业及开发者快速部署LLM、AI作画、文本处理、聊天机器人等高性能应用。

Amazon Bedrock 轻松构建,赋能每一位 AI 开发者
通过 Amazon Bedrock 强大的资源和工具,可以迅速体验最新生成式人工智能技术,无论小白或者开发经验丰富的IT人员,无论是否掌握编程技术,无论是AI初学者还是希望提升技能的专家,Amazon Bedrock 都能助你一臂之力,赋能工作、生活场景。
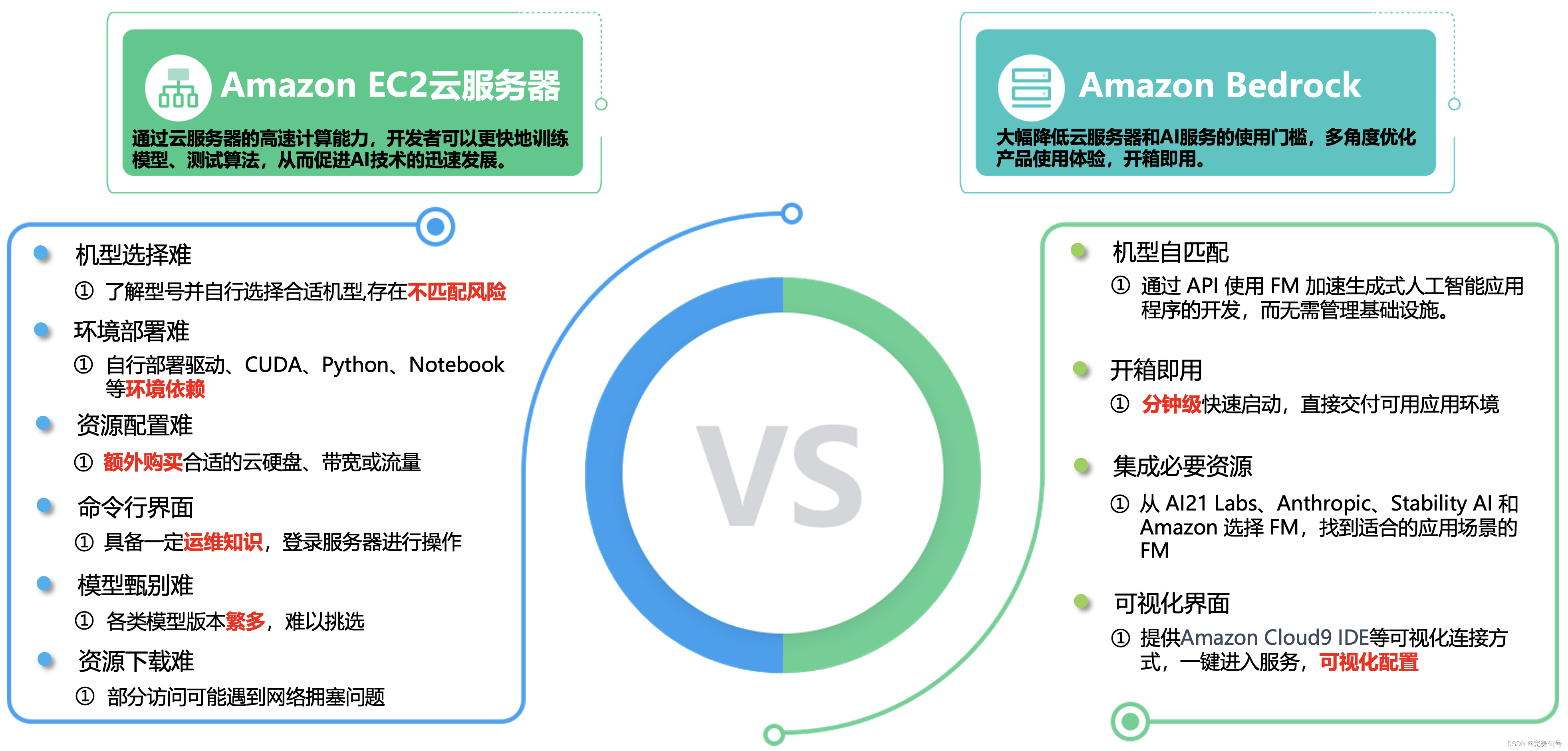
二、即生瑜(Amazon EC2云服务器)何生亮(Amazon Bedrock):
1. Amazon EC2云服务器:
Amazon Elastic Compute Cloud(Amazon EC2)提供最广泛、最深入的计算平台,拥有超过 500 个实例,可选择最新的处理器、存储、网络、操作系统和购买模型,以最好地满足工作负载的需求。同时,是首家支持英特尔、AMD 和 Arm 处理器的主要云提供商,既是唯一具有按需 EC2 Mac 实例的云,也是唯一具有 400 Gbps 以太网网络的云。为机器学习培训提供最佳性价比,同时也为云中的每个推理实例提供了最低的成本。与任何其他云相比,有更多的 SAP、高性能计算 (HPC)、机器学习 (ML) 和 Windows 工作负载在 AWS 上运行。
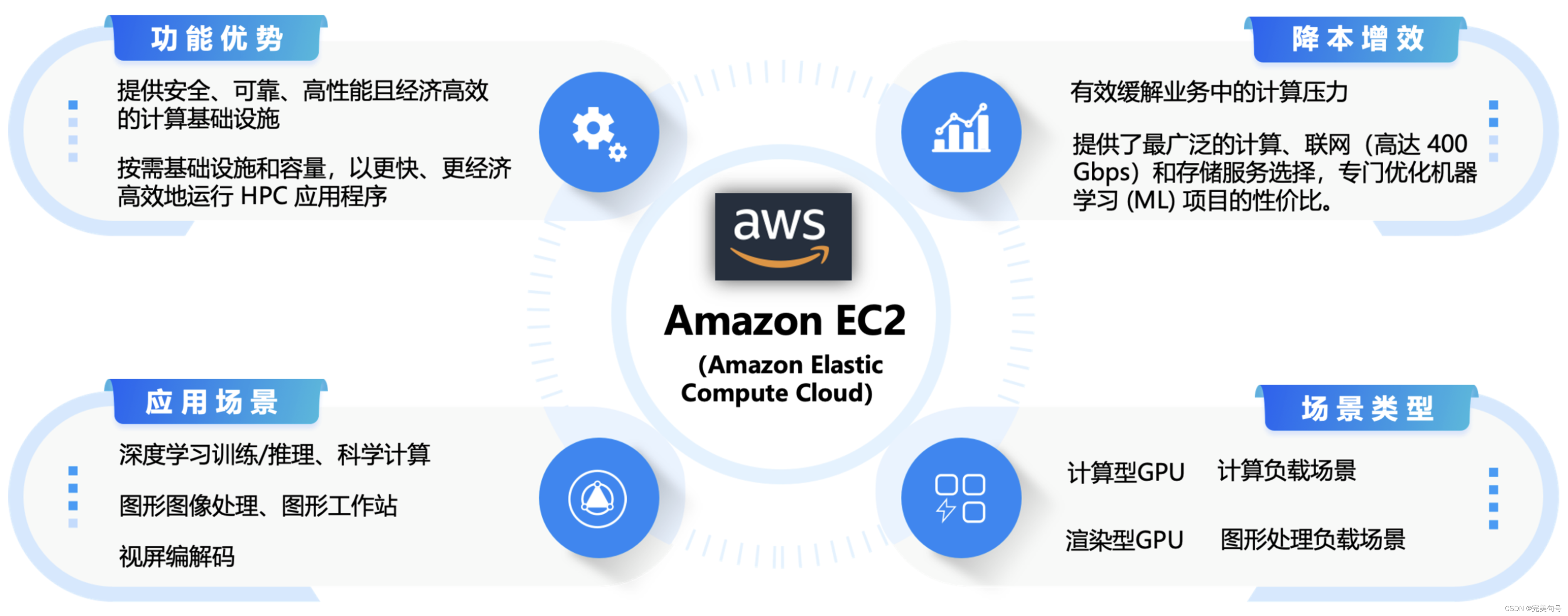
2. Amazon EC2云服务器应用场景:
GPU计算型应用场景:

GPU渲染型应用场景:

三、Amazon Bedrock了解:
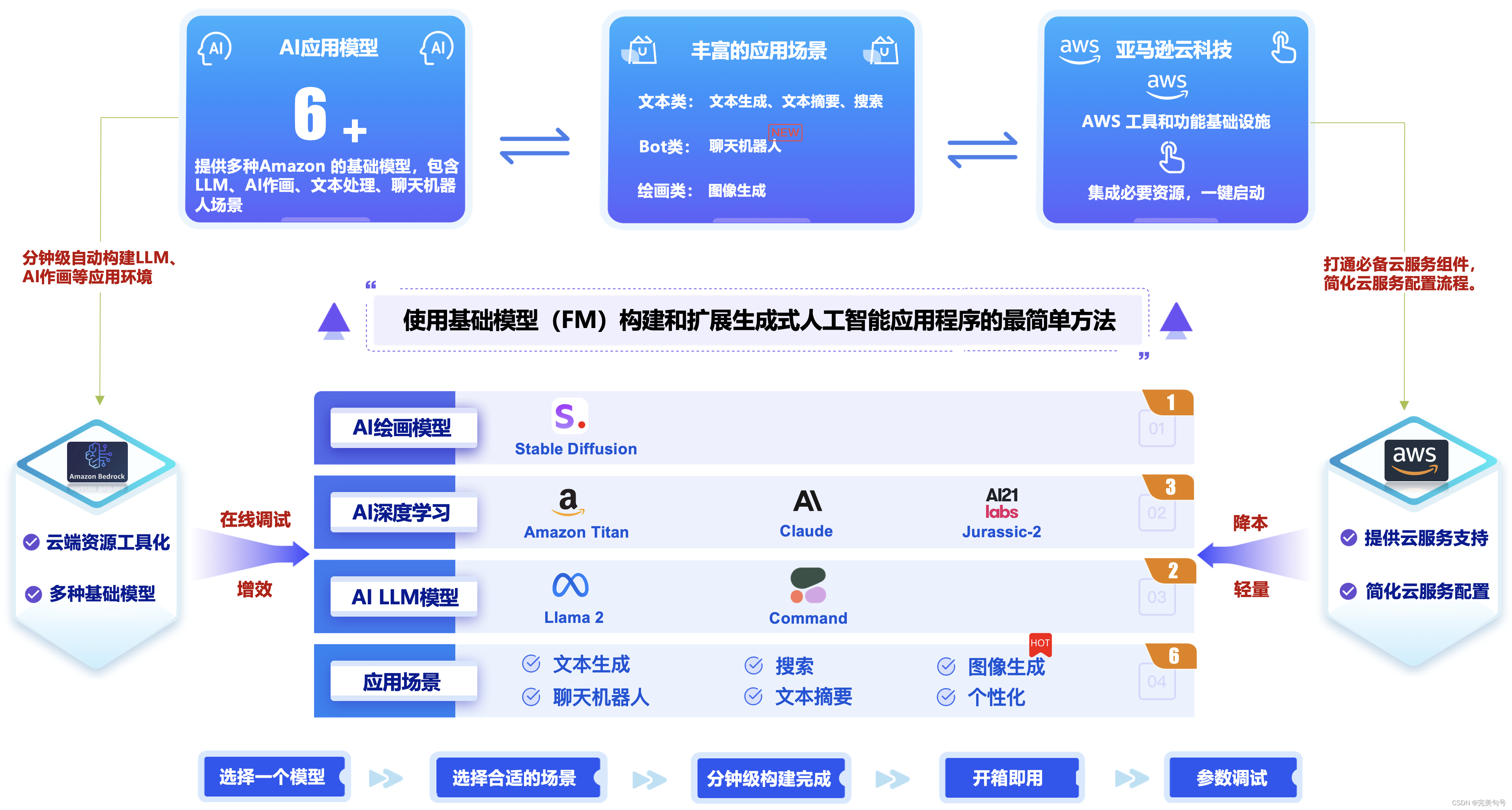
Amazon Bedrock 是一项完全托管的服务,通过单个 API 提供来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon 等领先人工智能公司的高性能基础模型(FM),以及通过安全性、隐私性和负责任的 AI 构建生成式人工智能应用程序所需的一系列广泛功能。
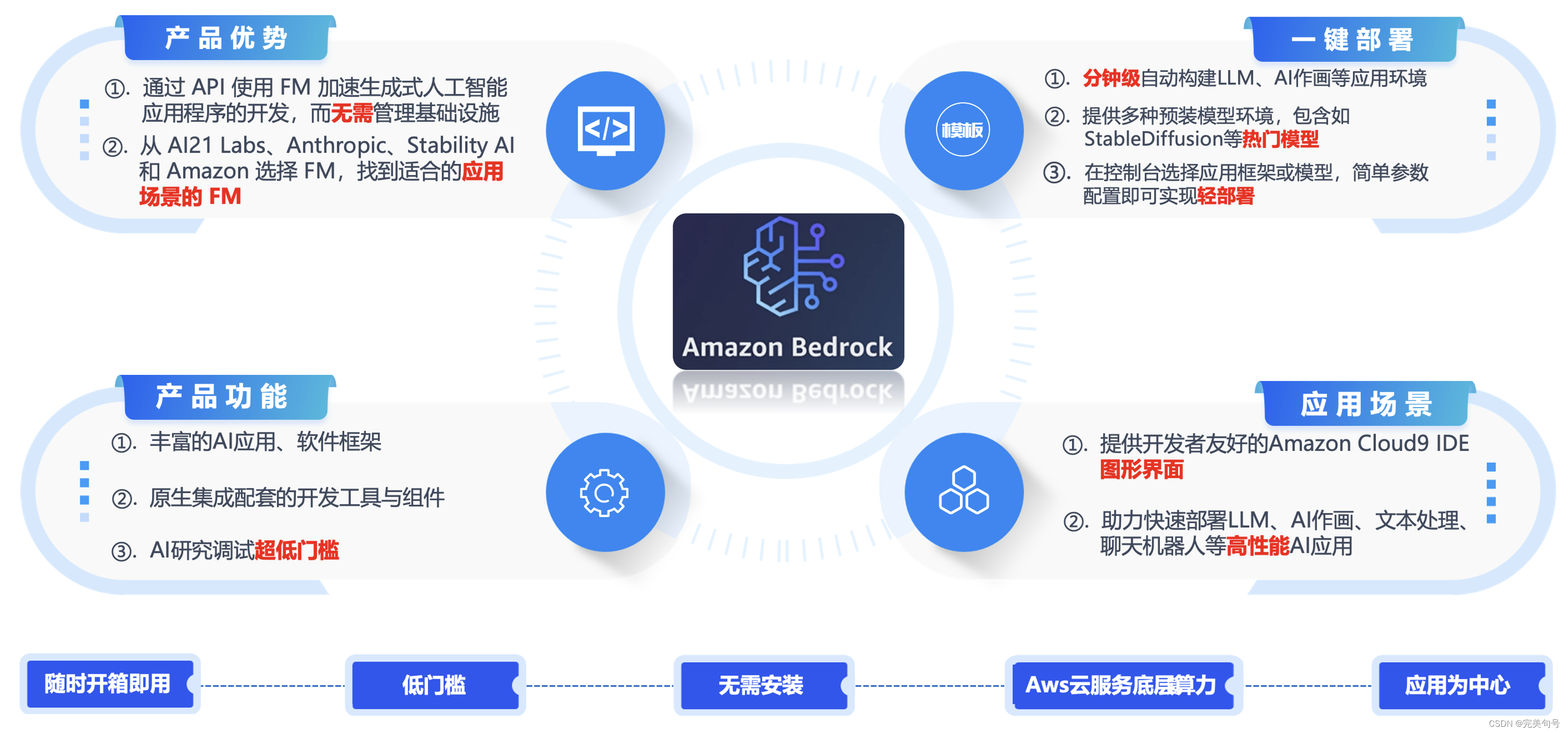
尤其值得一提的是针对开发者,使用可视化的Amazon Cloud9 IDE图形界面大大的降低了调试的复杂度、降低应用使用的门槛,甚至经过简单的培训,让非开发者(运维人员)也可以参与到使用中来。
1. 横向对比,青出于蓝:
在以往都是自己组合搭建大多数搭载GPU云服务器的AI服务器可以覆盖更多的应用场景,如图形渲染、深度学习、天体物理、化学分子计算、云计算和虚拟化、计算密集型行业等应用。
Amazon Bedrock的产品的价值:
借助 Bedrock 的无服务器体验,可以快速入门,使用自己的数据私人定制 FM,并使用 AWS 工具轻松将其集成和部署到您的应用程序中,而无需管理任何基础设施。,低门槛、开箱即用。
2. Amazon Bedrock动手实验:
本次活动是由亚马逊云科技推出的开发者技术实践活动。通过动手实验的形式,带您深入沉浸式体验Amazon Bedrock服务。
- 实验手册一:在Amazon Bedrock上掌握Stable Diffusion AI SDXL 1.0:创造独特艺术风格的图像
- [实验手册二:实验二 在Amazon Bedrock上掌握Meta Llama 2:快速轻松地构建基于⽣成式⼈⼯智能的体验(登陆官网即可查看)]
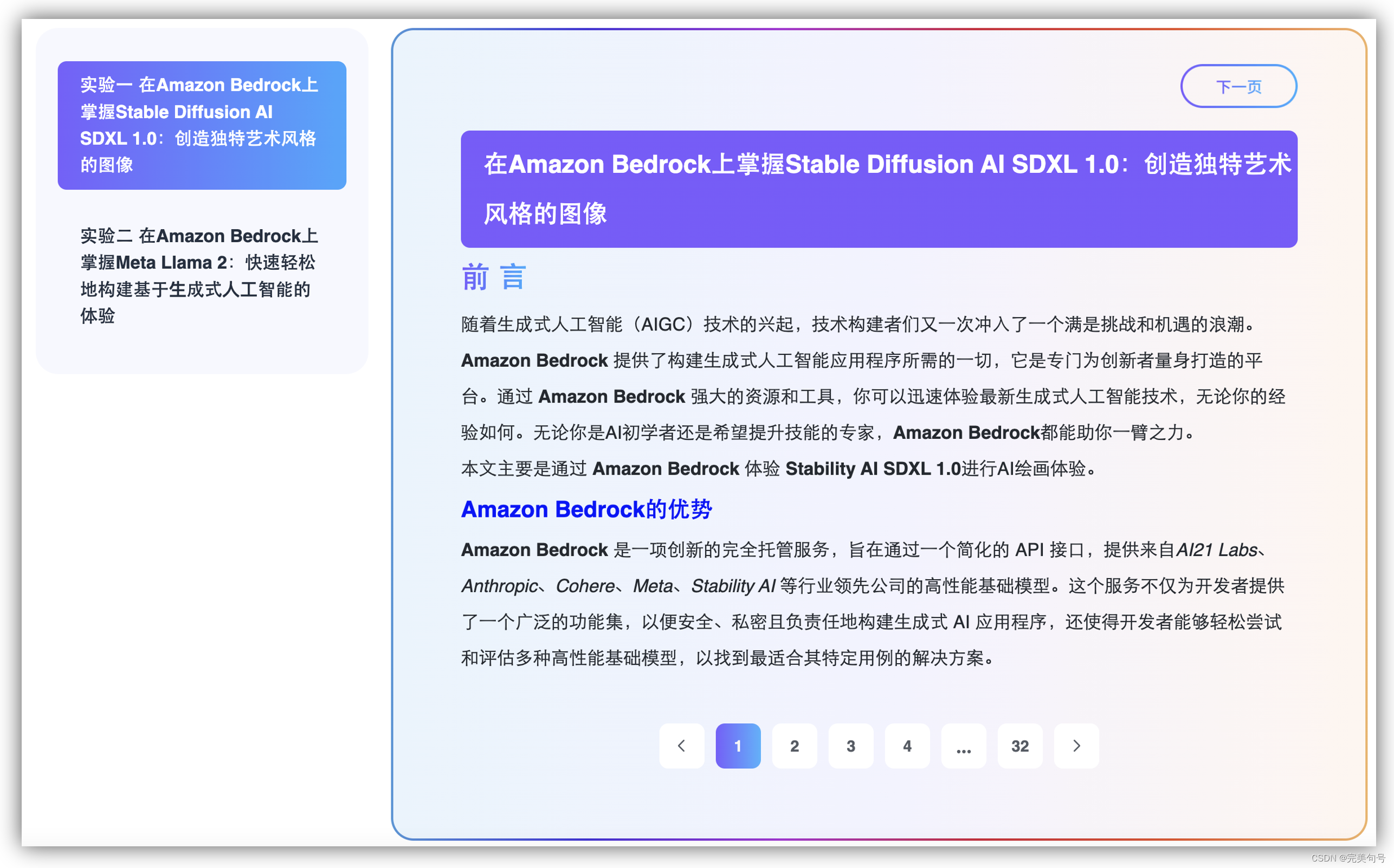
活动提供的手册也是非常的详细,可以快速体验一下Amazon Bedrock服务相关的AI产品,无论您是技术新手还是经验丰富的开发者,都可以从活动中汲取到技术上的精华。
四、Stable Diffusion介绍:
1. Stable Diffusion:
Stable Diffusion是一种基于扩散过程的图像生成模型,可以生成高质量、高分辨率的图像。它通过模拟扩散过程,将噪声图像逐渐转化为目标图像。这种模型具有较强的稳定性和可控性,可以生成具有多样化效果和良好视觉效果的图像。
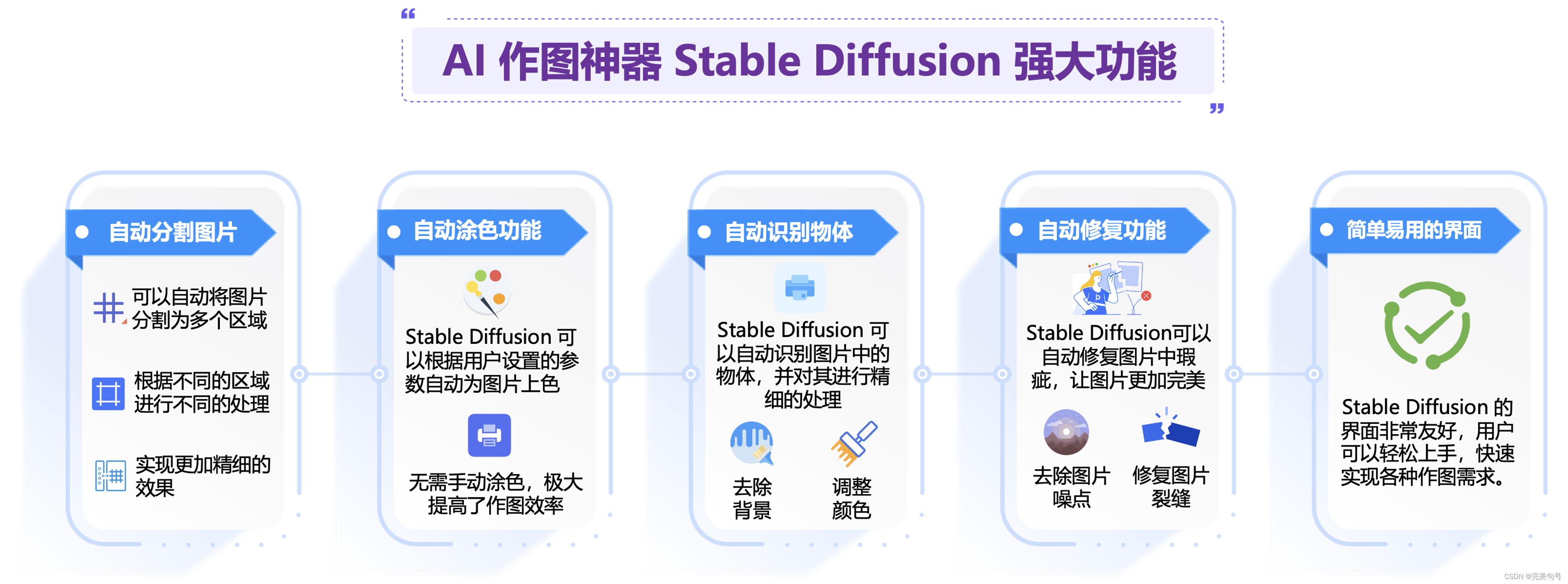
Stable Diffusion 可以通过生成多样化、高质量的图像、修复损坏的图像、提高图像的分辨率和应用特定风格到图像上等方式,辅助视觉创意的实现。它为视觉艺术家、设计师等提供更多的创作工具和素材,促进视觉艺术领域的创新和发展。
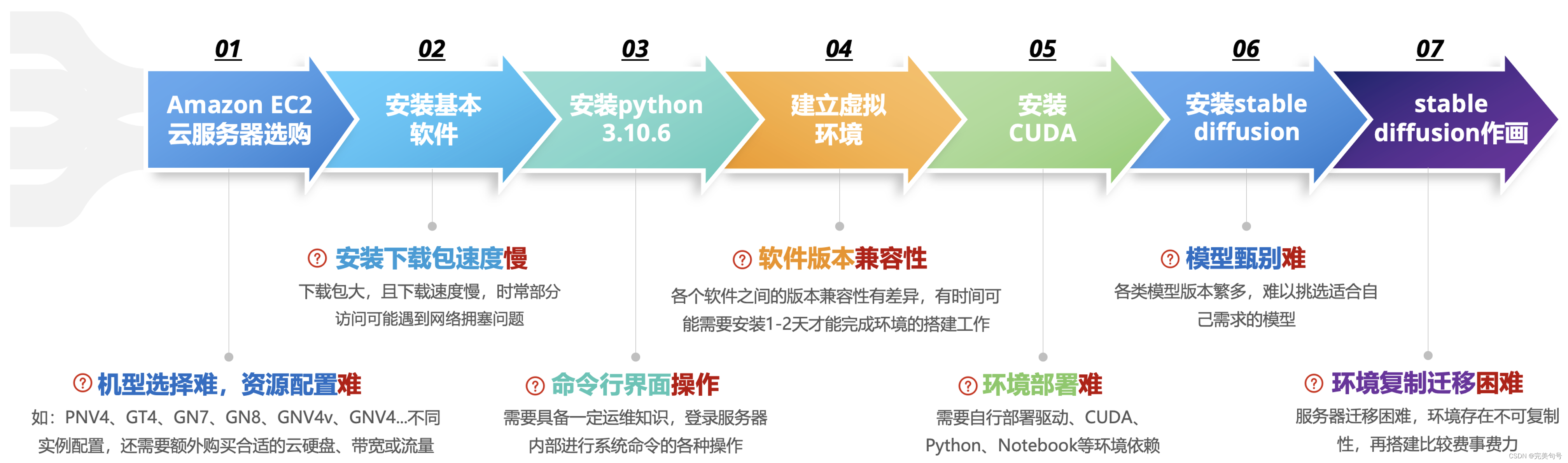
2. 对比一下服务器自行部署Stable Diffusion痛点:
2.1 安装基本软件:
sudo apt install wget git
- 1
2.1 安装python 3.10.6:
# 安装依赖 sudo apt install wget git python3 python3-venv # 删除默认的低版本 which python3 sudo rm /usr/bin/python # 配置软链接 ls -lh /usr/bin | grep python ln -s /usr/bin/python3 /usr/bin/python # 若是GPU环境的用户需要安装与cuda版本对应的torch pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117 # pip换源 pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple # 安装对应依赖 pip install -r requirements_versions.txt # 建立虚拟环境 sudo apt-get install python3.5-venv python3 -m venv_name source venv_name/bin/activate

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2.2 安装CUDA:
# 下载Cuda
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
# 安装cuda
sudo sh cuda_11.8.0_520.61.05_linux.run
# 配置环境变量
# 增加下面两行内容,并保存
vim ~/.bashrc
export PATH=/usr/local/cuda-11.8/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH
# 使配置文件生效
source ~/.bashrc
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.3 安装stable diffusion:
# 拉取stable diffusion 代码:
git clone GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
# 安装stable diffusion:
cd stable-diffusion-webui/
# 启动
./webui.sh
- 1
- 2
- 3
- 4
- 5
- 6
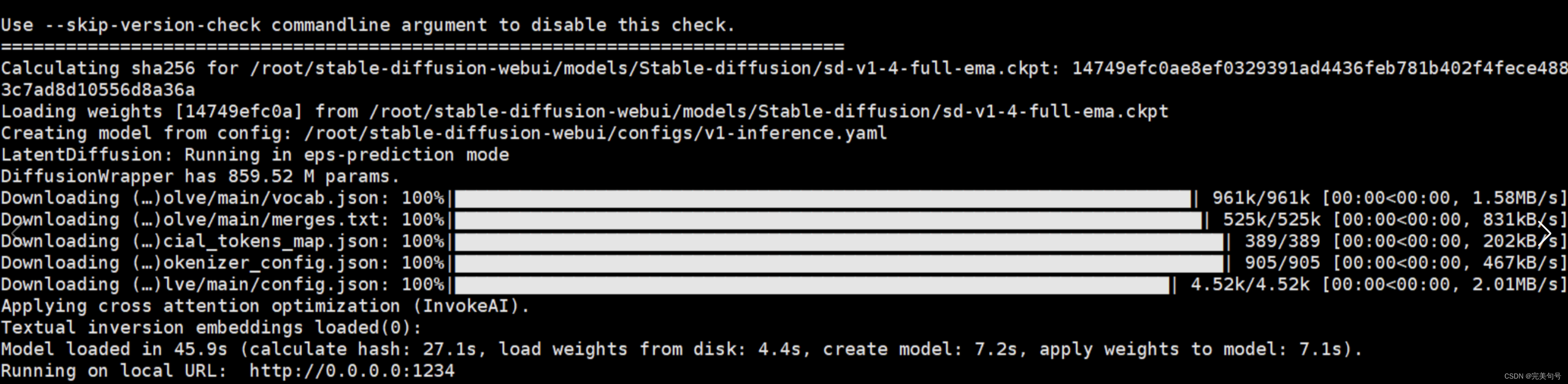
以上是自行尝试购买云服务器,自己手动搭建环境,并运行stable diffusion。大概花费了差不多一个下午的时间,而且这个还是自己以前尝鲜有过经验的前提下。
3. 对比Amazon Bedrock产品的提效:
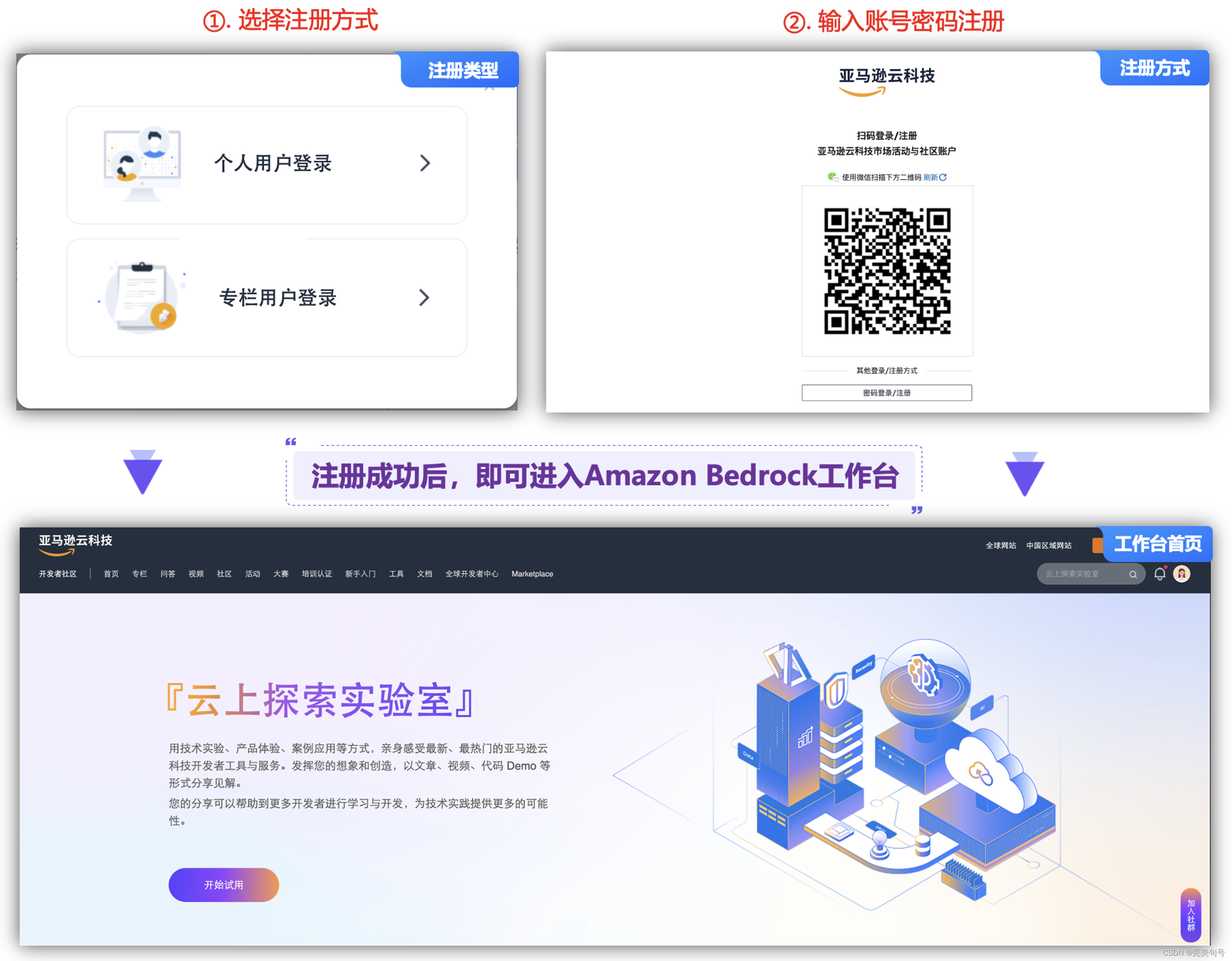
3.1 注册登录:
通过实验手册的相关介绍,我们这里使用个人用户登录方式的模式进行注册与登录,进入工作台首页,点击“开始试用”即可玩转Amazon Bedrock产品。
3.2 功能体验:
在通过完成官方提供的动手实验,我们大概只花了不到几分钟就可以从0到使用stable diffusion开始作画,并且不到20分钟就能完成动手的实验,实验证手册已经有非常详细的描述如何使用,这里就不去“鹦鹉学舌”重复赘述了。
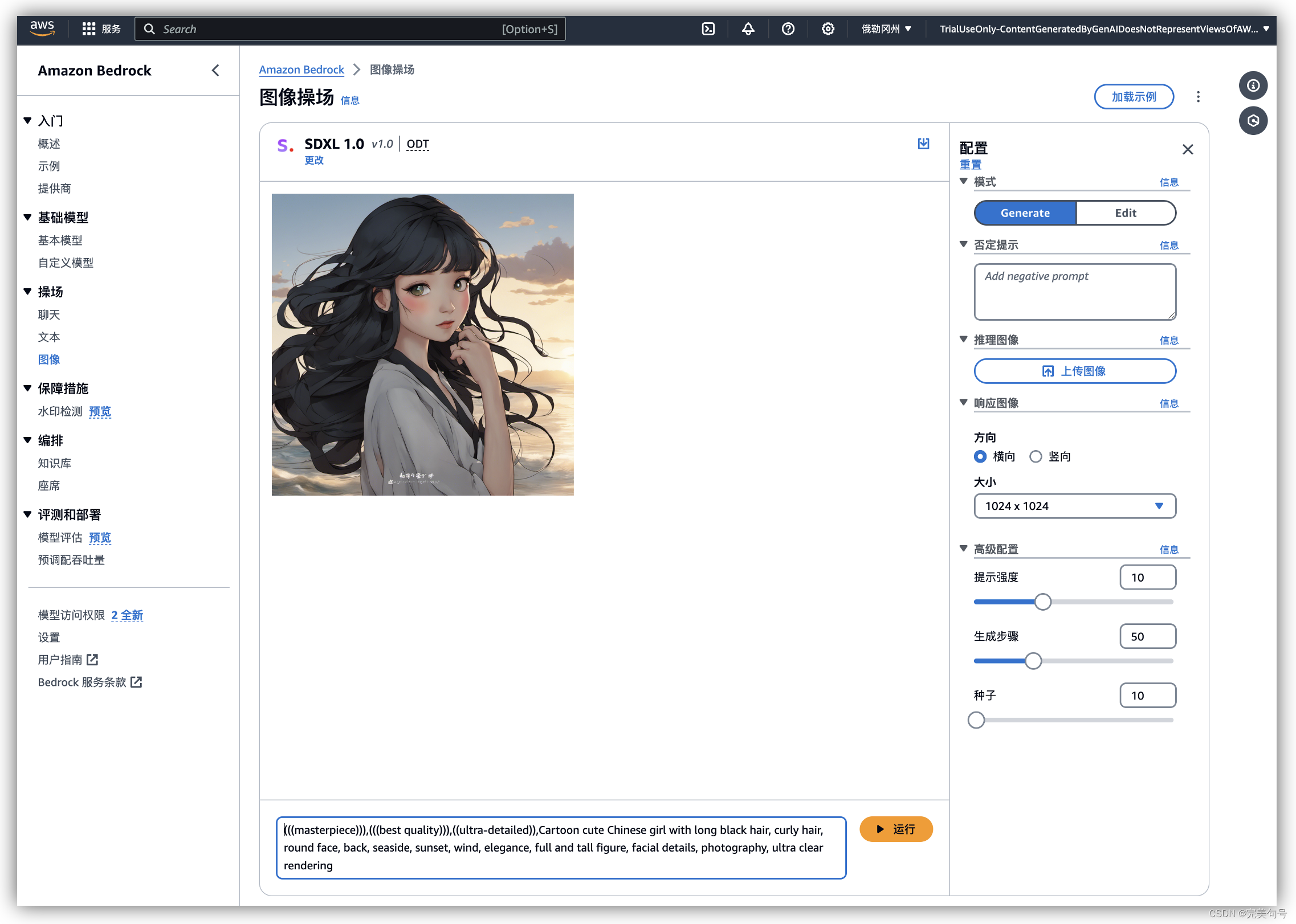
相关提示语:
(((masterpiece))),(((best quality))),((ultra-detailed)),Cartoon cute hinese girl with long black hair, curly hair, round face, back, seaside, sunset, wind, elegance, full and tall fig ure, facial details, photography, ultra clear rendering
- 1
五、“Amazon Bedrock”产品给公司业务提效方案可行性评估:
自从AIGC人工智能生成内容的来临,在过去的一段时间里,以Stable Diffusion 为代表的 AIGC 绘画迎来了爆发式增长,引发了一场生产力的革命。
1. “Amazon Bedrock”产品AI绘画帮助设计师降本增效方案评估:
在传统的设计团队,通常的设计师的工作流程如下:
- 运营提出商业意图与图形的要求
- 设计在“千图网”找一些符合要求的参考图,或者自己手工画一些设计的初稿
- 在与业务确认沟通风格和草图,再跟业务确认,是否符合业务的要求
- 设计进行建模,并且针对一些细化的设计进行调整
- 最终,设计定稿,交付设计图
在这个设计的阶段过程中,交付给业务团队的耗时点如下:
- 设计师往往需要在“千图网”找大量的参考图,这个过程是比较费事也费劲的,一般需要半个工作日的倍数。
- 如果遇到一些比较复杂的交互,设计师还需要自己手画设计草图,也是比较费时间的。
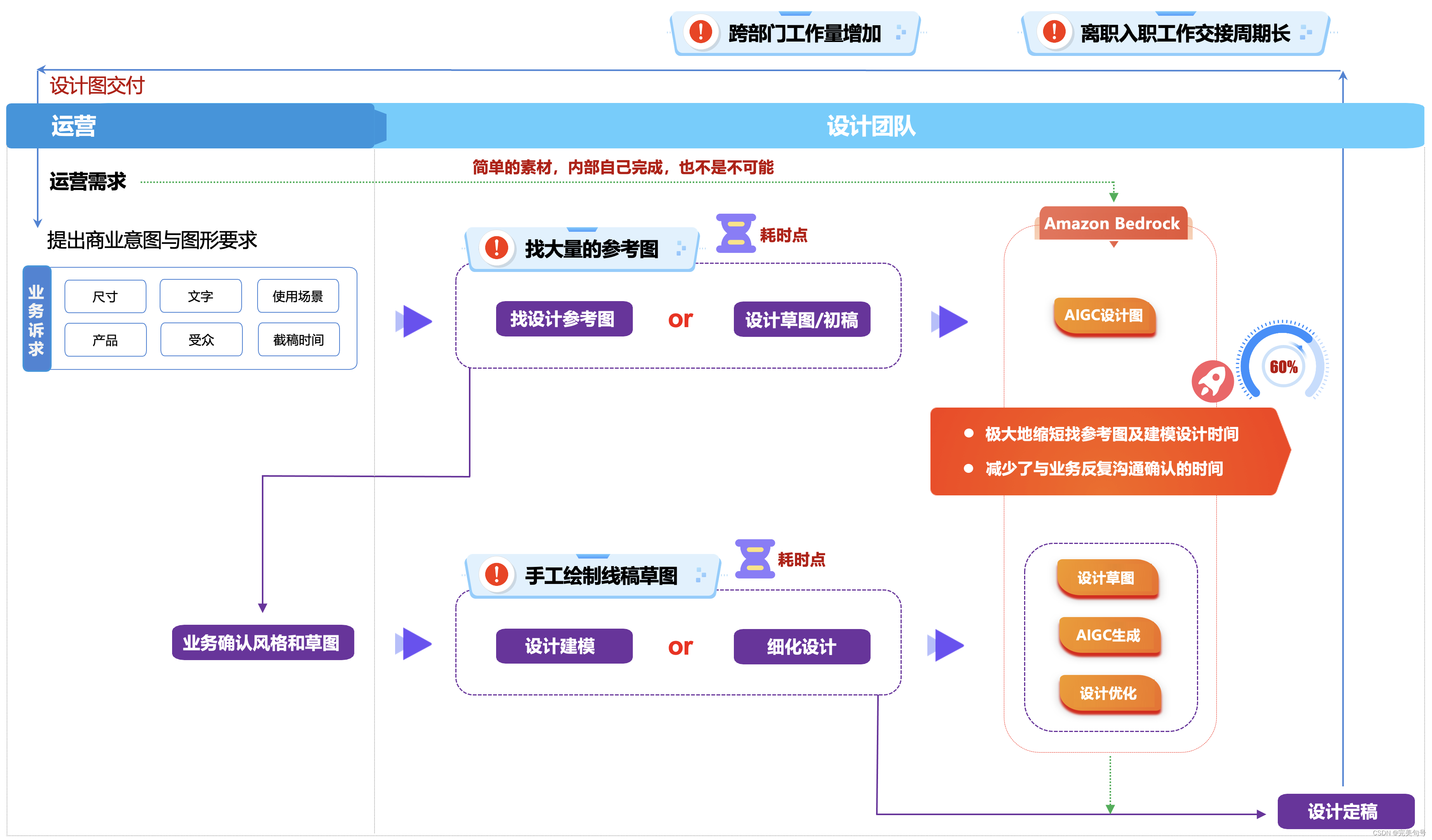
现在有了AIGC绘画的工具辅助后,可以极大地缩短找参考图及建模设计草图时间,同时也减少了与业务反复沟通确认的时间。使用Stable Diffusion模型/Amazon Titan模型(更推荐)生成设计参考图,可以快速与业务确认设计风格,绘制线稿草图后,再通过Stable Diffusion模型/Amazon Titan模型直接生成设计图,设计师再做细节优化,大大提升了整个设计流程的效率。甚至,简单的绘图可以直接交付由业务单位来完成。
2. “Amazon Bedrock”产品AI绘画实际案例参考:
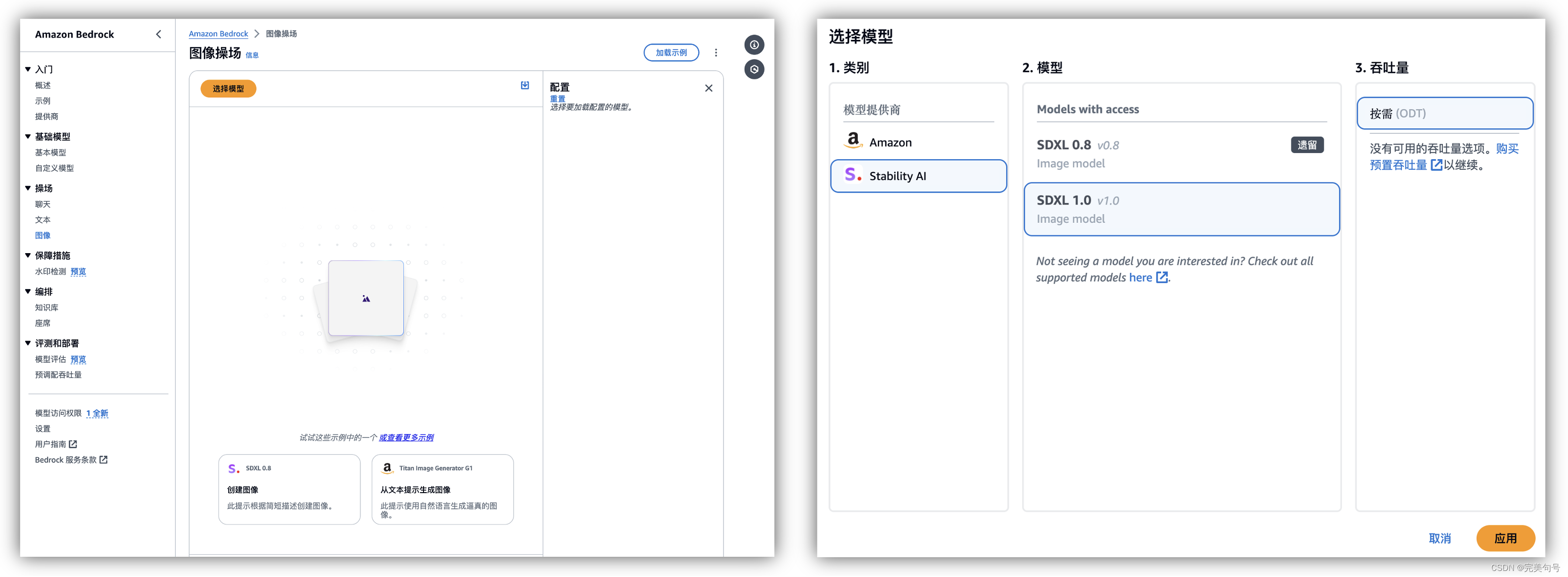
通过以下操作,在“操场 -> 图像”中,可以输入相关提示词,配合右侧相关的参数,可以快速生成需要的图片素材。
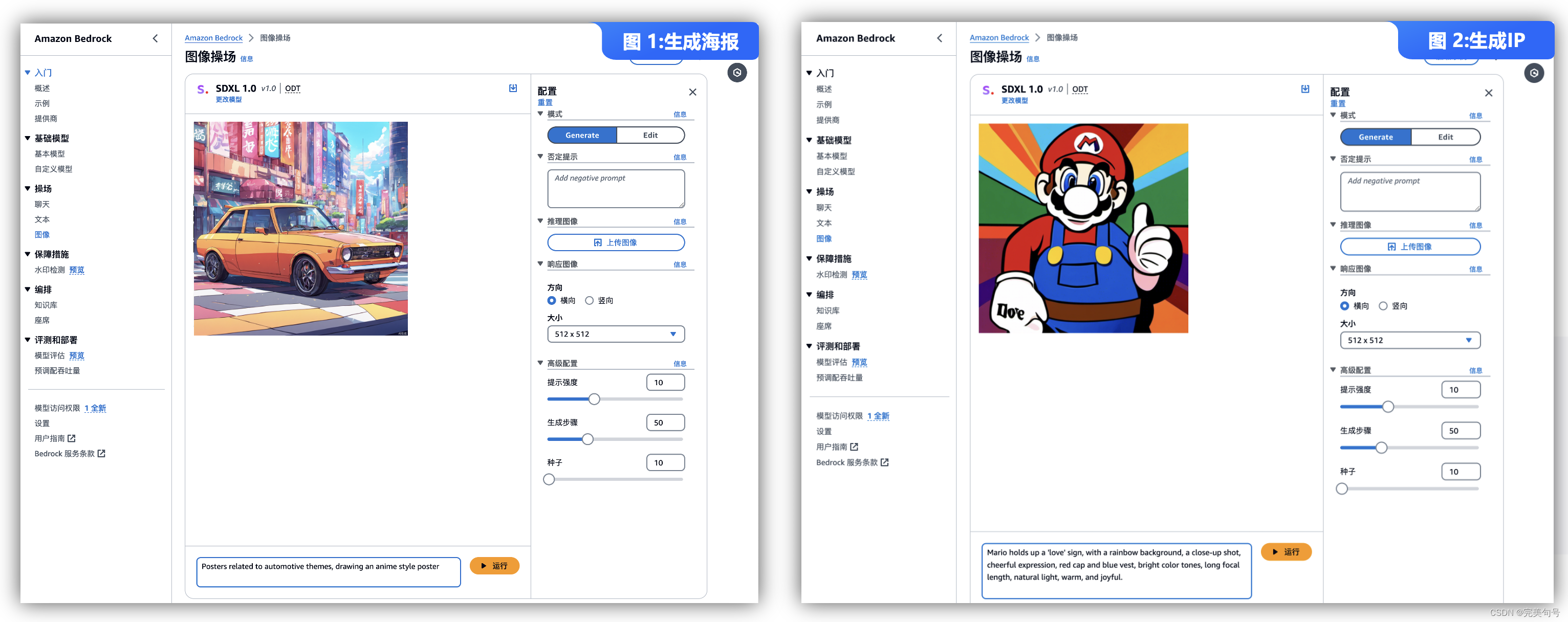
3. “Amazon Bedrock”产品文本处理的实际案例参考:
在公司的运营团队中,经常会与相关的文案、物料话术、相关策化方案打交道,往往这会需要在垂直领域花费大量的时间来整理,通过“Amazon Bedrock”的聊天操场可以自动帮助我们生成大量的文案,帮助快速交付业务。
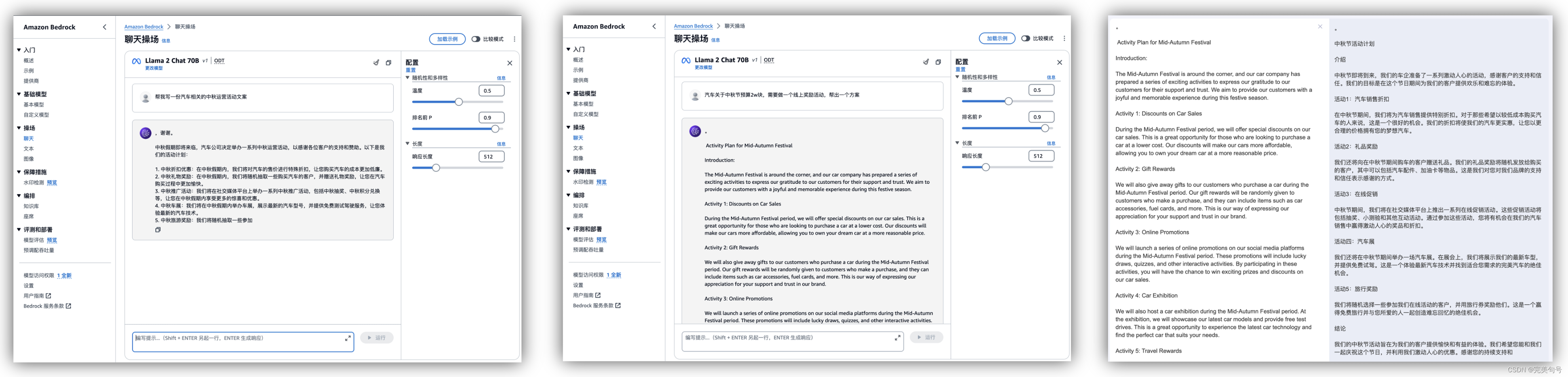
这里有一个特别好的功能就是“比较模式”,开启这个“比较模式”,就可以对多个模型进行比较,通过右侧的“+”号,可以添加多个窗口进行不同模型,对同一个问题的解析。
这种情况很适合,在某个垂直领域的问题搜索,比如,我搜索同一个问题“帮我生成一段gin框架的web初始化代码”,可以对3个模型进行比较一下,Llama 2 Chat 70B这个模型生成的回答更为精确,对于文本相关的操作,这个功能非常的有作用,可以针对性的看一下哪个模型在这个知识领域是否满足要求,在其它的AI产品还不具备这个功能。
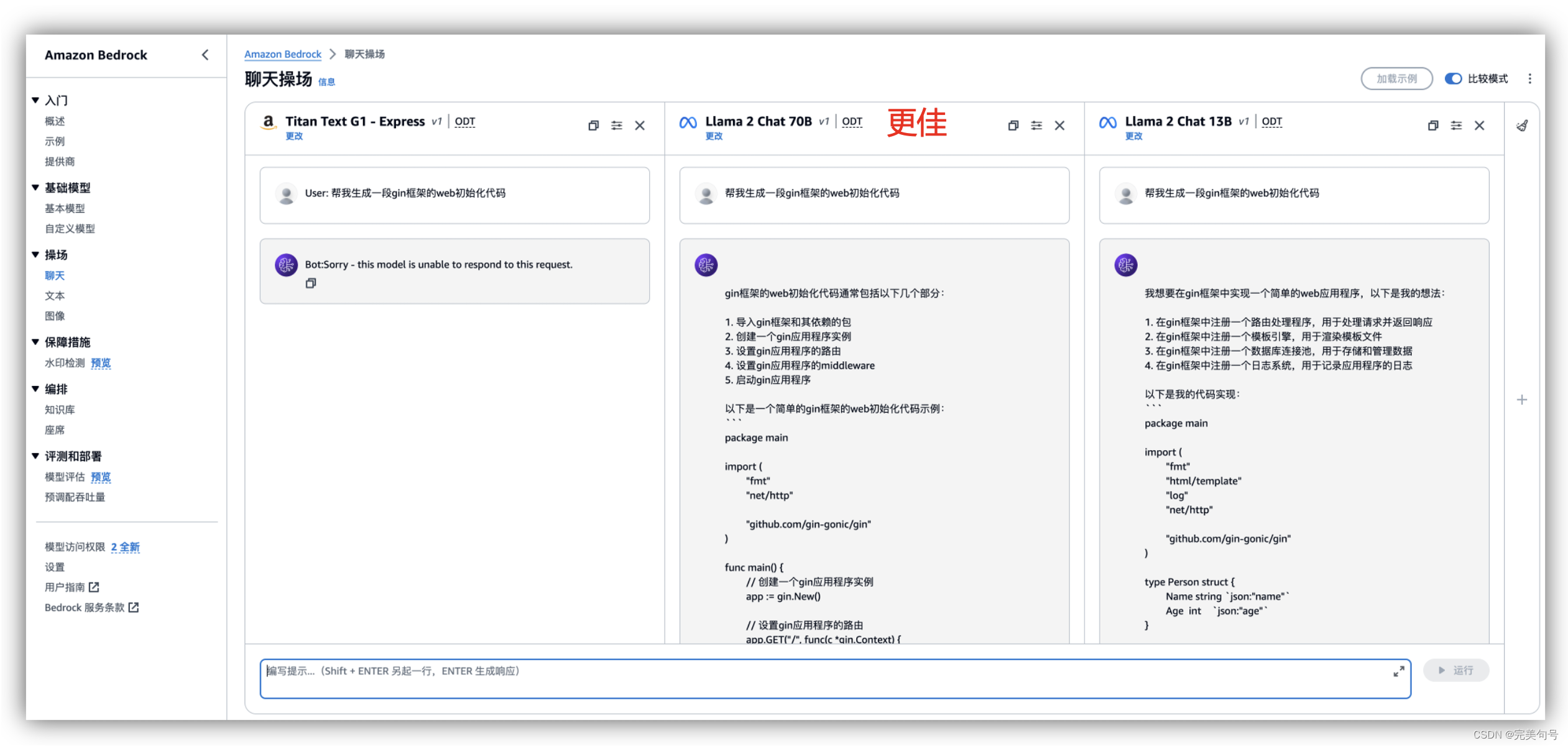
在评估不同的模型的同时,也可以去尝试各种提示词和推理配置参数的修改。提示词(Prompt )描述的越详细、越规范,可以让FM更好地理解并将其应用于模型推测,有效的提示词可以充分利用 FM 并获得正确、精确的响应。
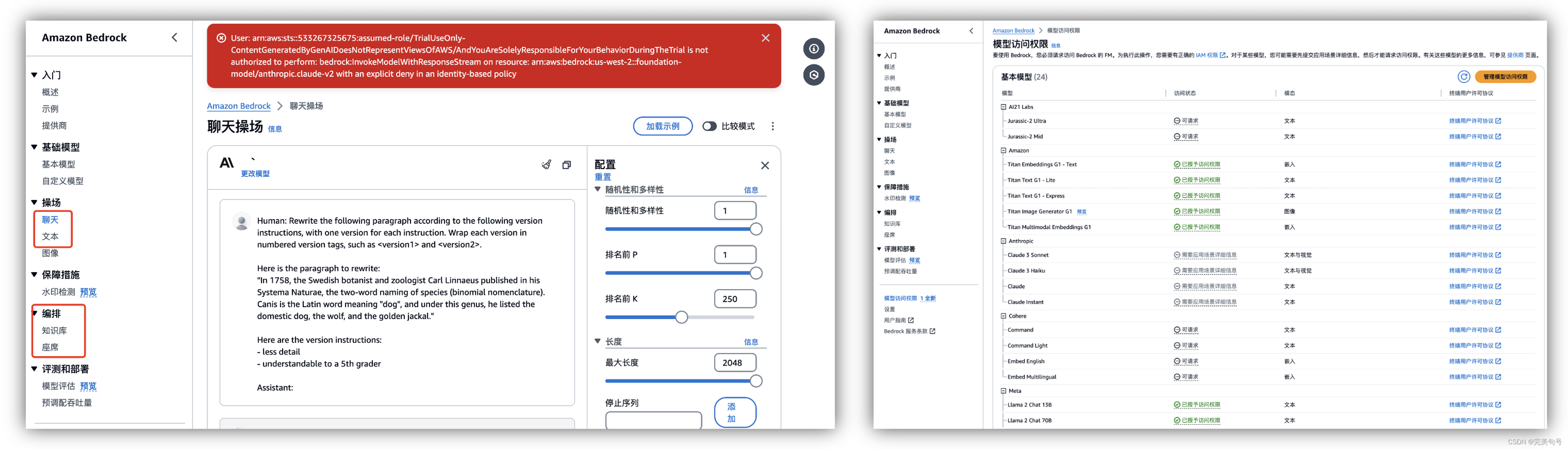
4. “Amazon Bedrock”产品权限处理:
在体验的过程中,有些API的权限是需要通过授权才可以进行访问的,如下图,可以在“模型访问权限”中进行开启相应的权限。
5. “Amazon Bedrock” API接口方式访问:
上面的都是需要登陆到控制台中,使用默认的AI产品,那么如何以API的形式进行提供服务,这样就可以嵌入集成到我们自己的系统中来,更方便业务人员来使用。
通过快速体验Amazon Bedrock Meta Llama 2 聊天、文本功能,基于生成式人工智能的体验,让创意变得触手可及,使用Amazon Cloud 9 快速体验Amazon Bedrock Meta Llama 2 API的调用。
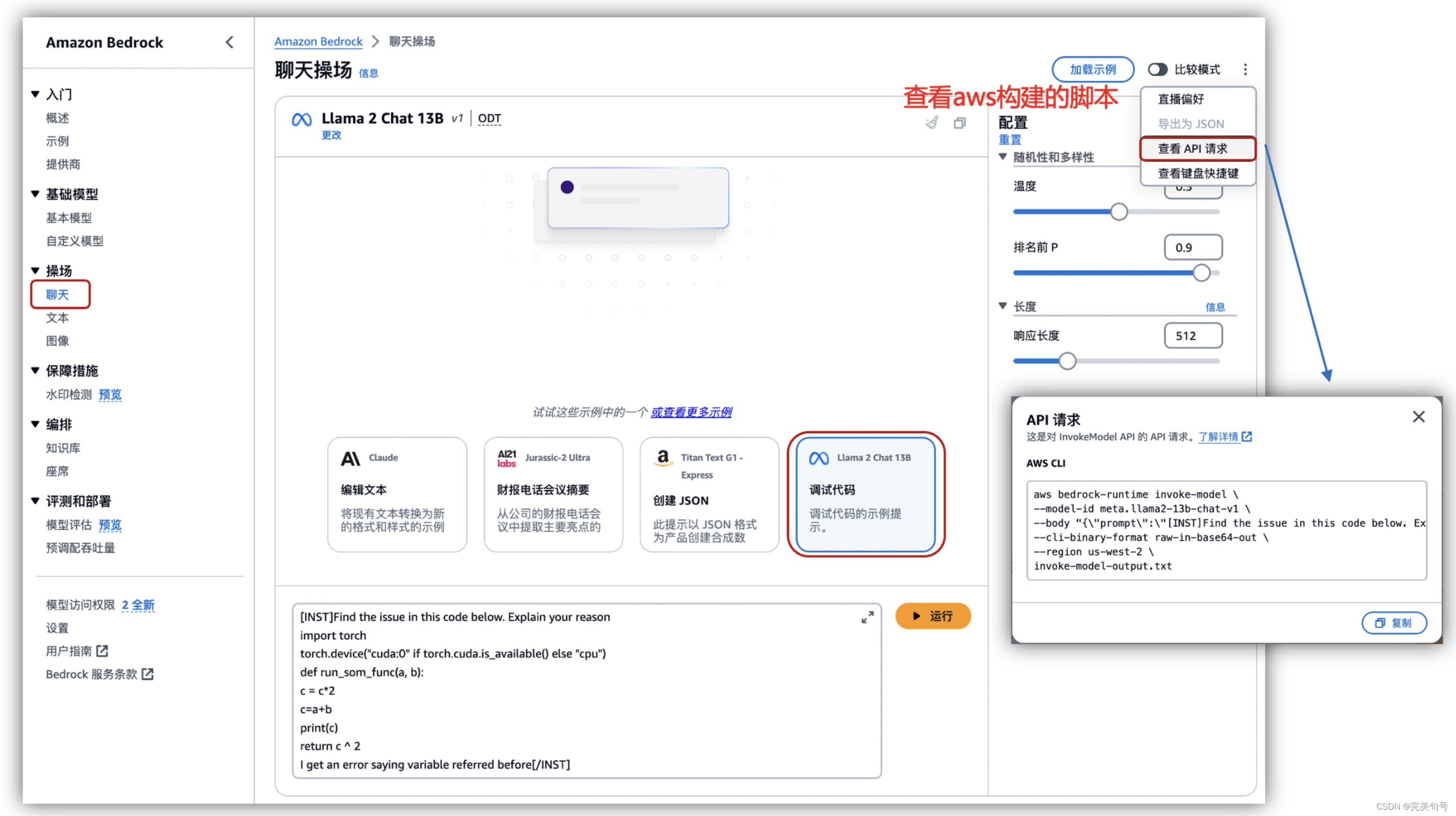
由于 Amazon Bedrock可以作为无服务器组件运行,因此可以与aws的平台可以完美的集成是真正的无服务器。基础模型可通过 REST API 访问以供下游使用,并且 AWS 提供 Bedrock SDK 客户端,任何应用程序都可以利用该客户端连接到 Amazon Bedrock。
aws bedrock-runtime invoke-model \
--model-id meta.llama2-13b-chat-v1 \
--body "{\"prompt\":\"[INST]Find the issue in this code below. Explain your reason\\nimport torch\\ntorch.device(\\\"cuda:0\\\" if torch.cuda.is_available() else \\\"cpu\\\")\\ndef run_som_func(a, b):\\nc = c*2\\nc=a+b\\nprint(c)\\nreturn c ^ 2\\nI get an error saying variable referred before[/INST]\",\"max_gen_len\":512,\"temperature\":0.5,\"top_p\":0.9}" \
--cli-binary-format raw-in-base64-out \
--region us-west-2 \
invoke-model-output.txt
- 1
- 2
- 3
- 4
- 5
- 6
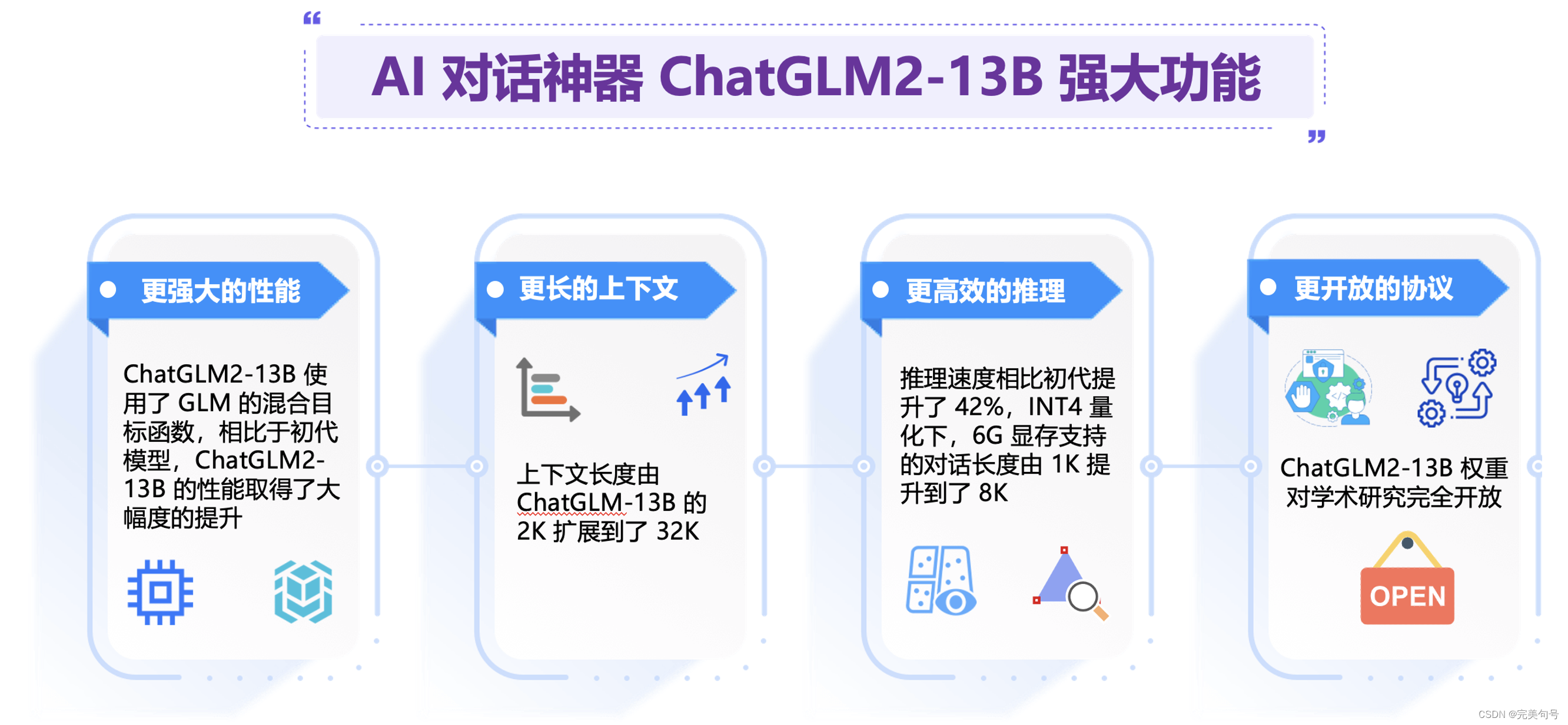
6. ChatGLM2 13B模型AI对话帮助业务单位降本增效方案评估:
目前公司的客服业务,是传统的人工客服和自动配置机械化的文案回复的客服机器人,这种混合工作模式,与商家而言,减少用人成本,同时消费者也能获得更快速的回应与服务。
Llama 是一系列使用公开数据进行训练的大型语言模型。这些模型基于转换程序架构,这使得它能够处理任意长度的输入序列并生成可变长度的输出序列。Llama 模型的关键特征之一是它能够生成连贯且与上下文相关的文本。这是通过使用注意力机制来实现的,注意力机制使模型能够在生成输出时专注于输入序列的不同部分。
此外,Llama 模型还使用一种称为“掩码语言模型”的技术在大型文本语料库上对模型进行预训练,这有助于它学会预测句子中缺失的单词。
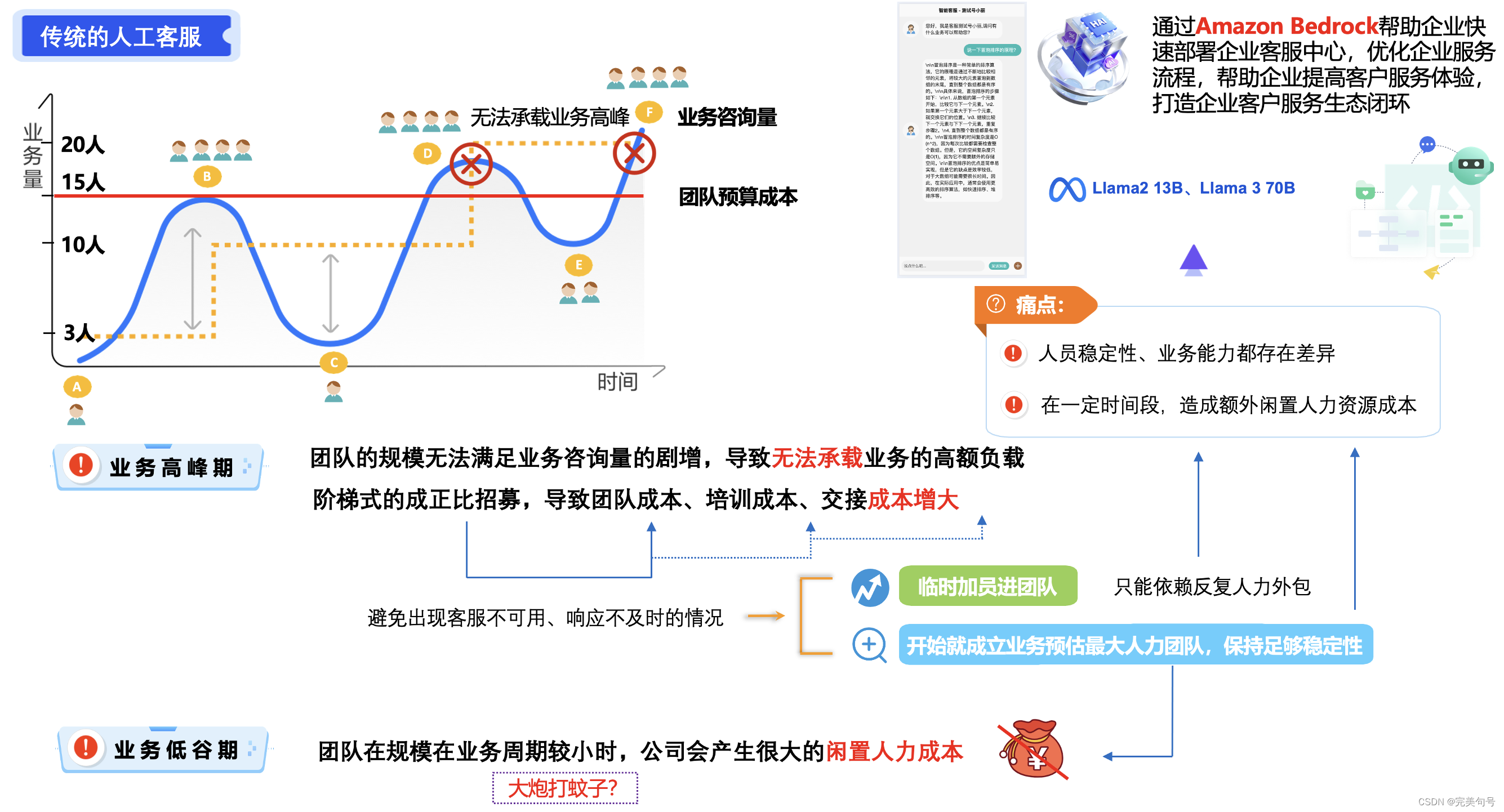
但是目前自动配置机械化的文案回复,也让很多消费者难以读懂,但消费者就算跟智能客服反馈自己看不懂,也不会得到别的回应。“Amazon Bedrock”的AI对话,可以帮助消费者更好地理解自己遇到的问题,这不是更加方便吗?
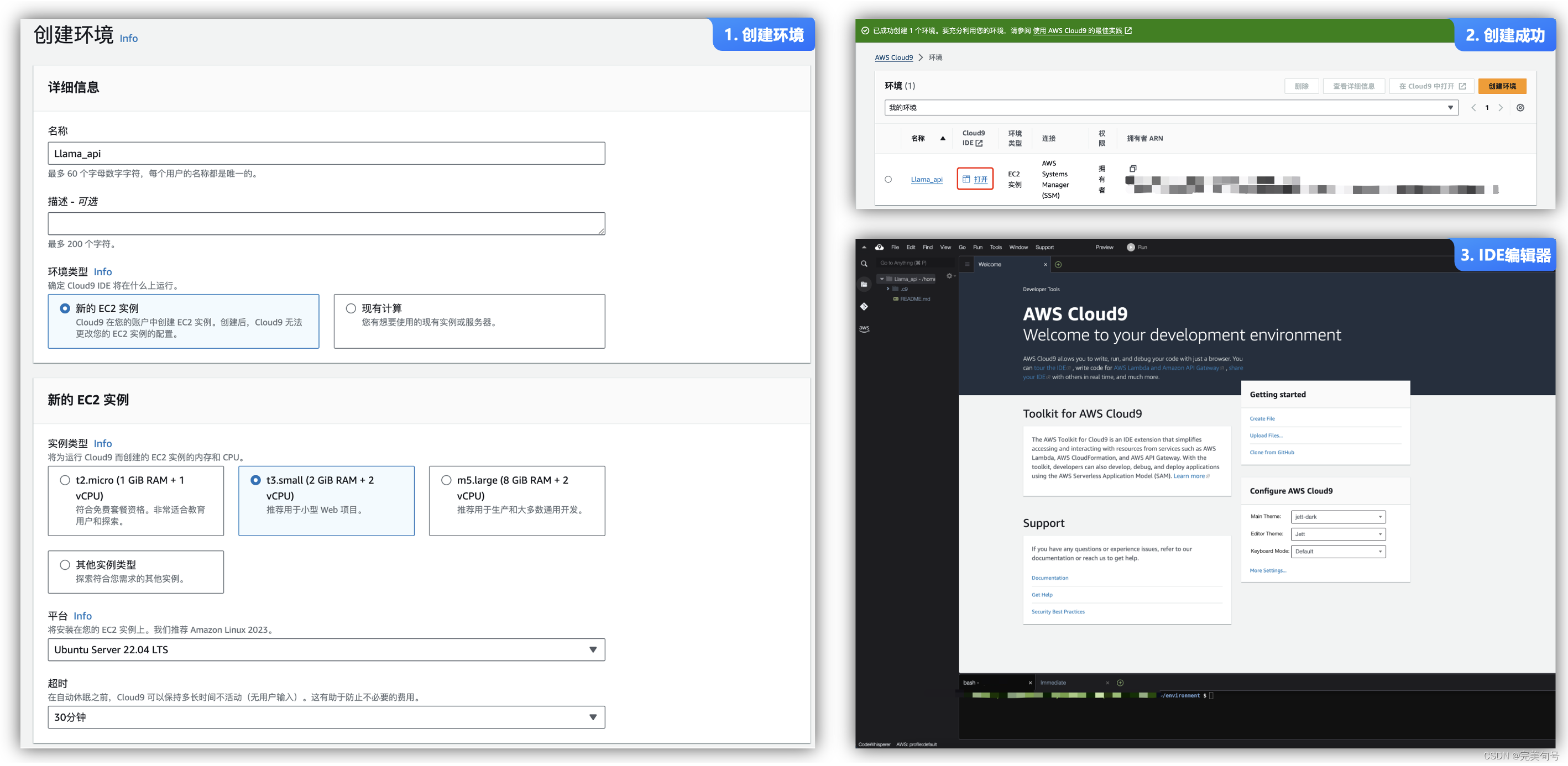
6.1 AWS Cloud9用于编写、运行和调试代码的云 IDE:
AWS Cloud9 允许仅使用浏览器编写、运行和调试代码,使用 AWS Cloud9,可以立即访问丰富的代码编辑器、集成调试器和带有预配置 AWS CLI 的内置终端,可以在几分钟内开始使用,而不必再花时间安装本地应用程序或配置开发计算机。
- 只用浏览器编码:AWS Cloud9 允许使用浏览器编写、运行和调试应用程序,无需安装或维护桌面 IDE。
- 实时一起编码:AWS Cloud9 简化协作编码,只需点击几下即可与团队共享开发环境,并将程序配对在一起。
- 快速启动新项目:AWS Cloud9 EC2 环境预先打包了适用于 40 多种编程语言的工具,能够在几分钟内开始为常用的应用程序堆栈编写代码。
- 轻松构建无服务器应用程序:AWS Cloud9 为开发无服务器应用程序提供了无缝体验,能够轻松定义资源、调试以及在本地和远程执行代码之间切换。
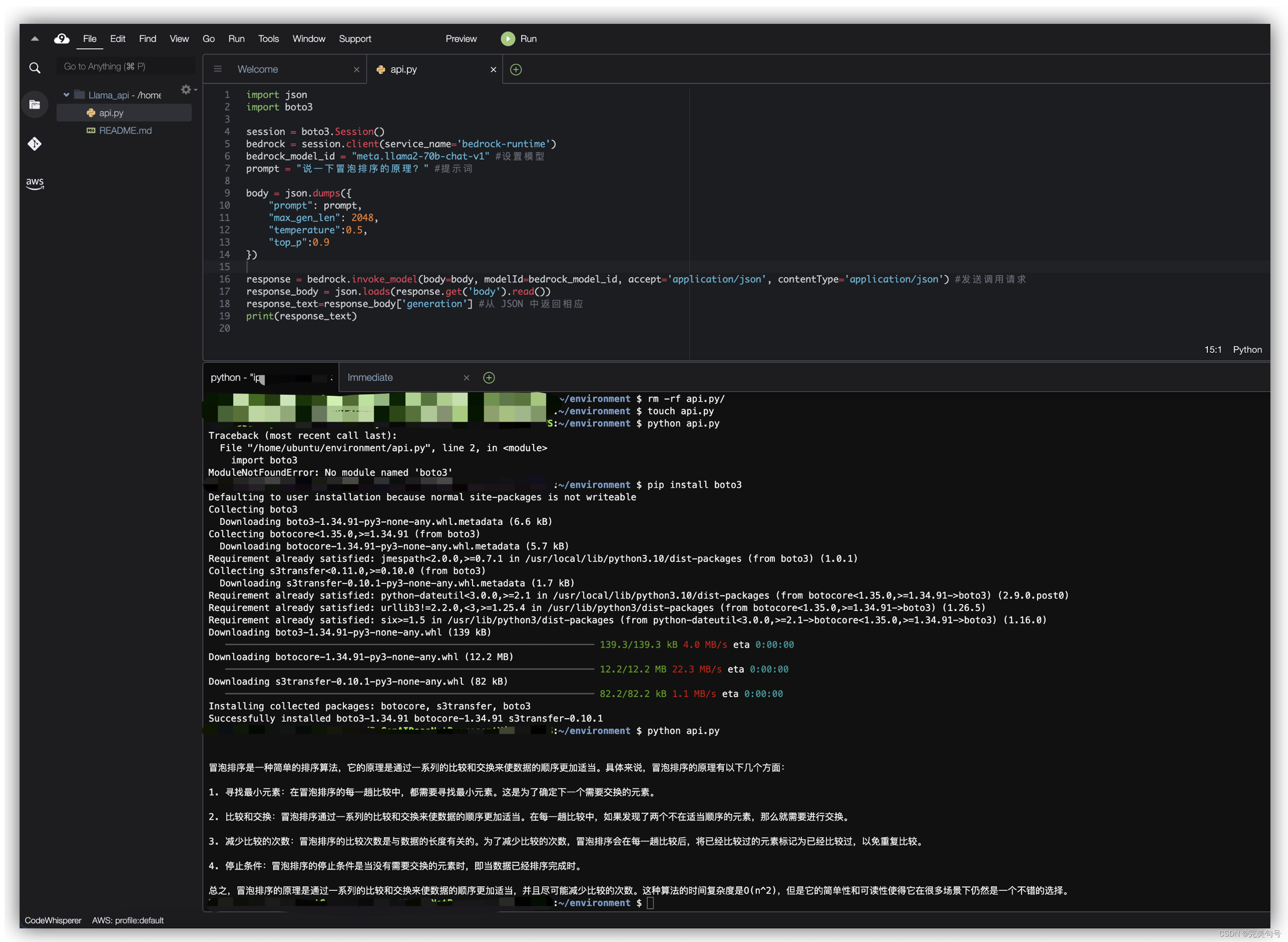
6.2 编写调用 Meta Llama 2 API 应用:
从官网手册上,我们可以了解到以下的代码可以在aws服务器上直接无脑构建一个Amazon Bedrock服务,根据以下代码确认也可以执行成功。
// 添加导入依赖语句允许使用Amazon boto3库来调用Amazon Bedrock import json import boto3 // 初始化Bedrock客户端库,创建一个Bedrock客户端 session = boto3.Session() bedrock = session.client(service_name='bedrock-runtime') bedrock_model_id = "meta.llama2-70b-chat-v1" #设置模型 prompt = "说一下冒泡排序的原理?" #提示词 // 使用的模型、提示和指定模型的推理参数 body = json.dumps({ "prompt": prompt, "max_gen_len": 2048, "temperature":0.5, "top_p":0.9 }) // 使用Amazon Bedrock的invoke_model函数进行调用 response = bedrock.invoke_model(body=body, modelId=bedrock_model_id, accept='application/json', contentType='application/json') #发送调用请求 response_body = json.loads(response.get('body').read()) // 从模型的响应JSON中提取并打印返回的文本 response_text=response_body['generation'] #从 JSON 中返回相应 print(response_text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
6.3 编写Python的一个简单的Web应用:
近年来异步web服务器比较火热,如falcon/bottle/sanic/aiohttp,Sanic是一个支持Python 3.7+的web服务器和web框架,速度很快,允许使用Python 3.5中添加的async/await语法,无阻塞且快,Sanic也符合ASGI,目标是提供一种简单的方法来建立和运行一个高性能的HTTP服务器,该服务器易于构建、扩展。
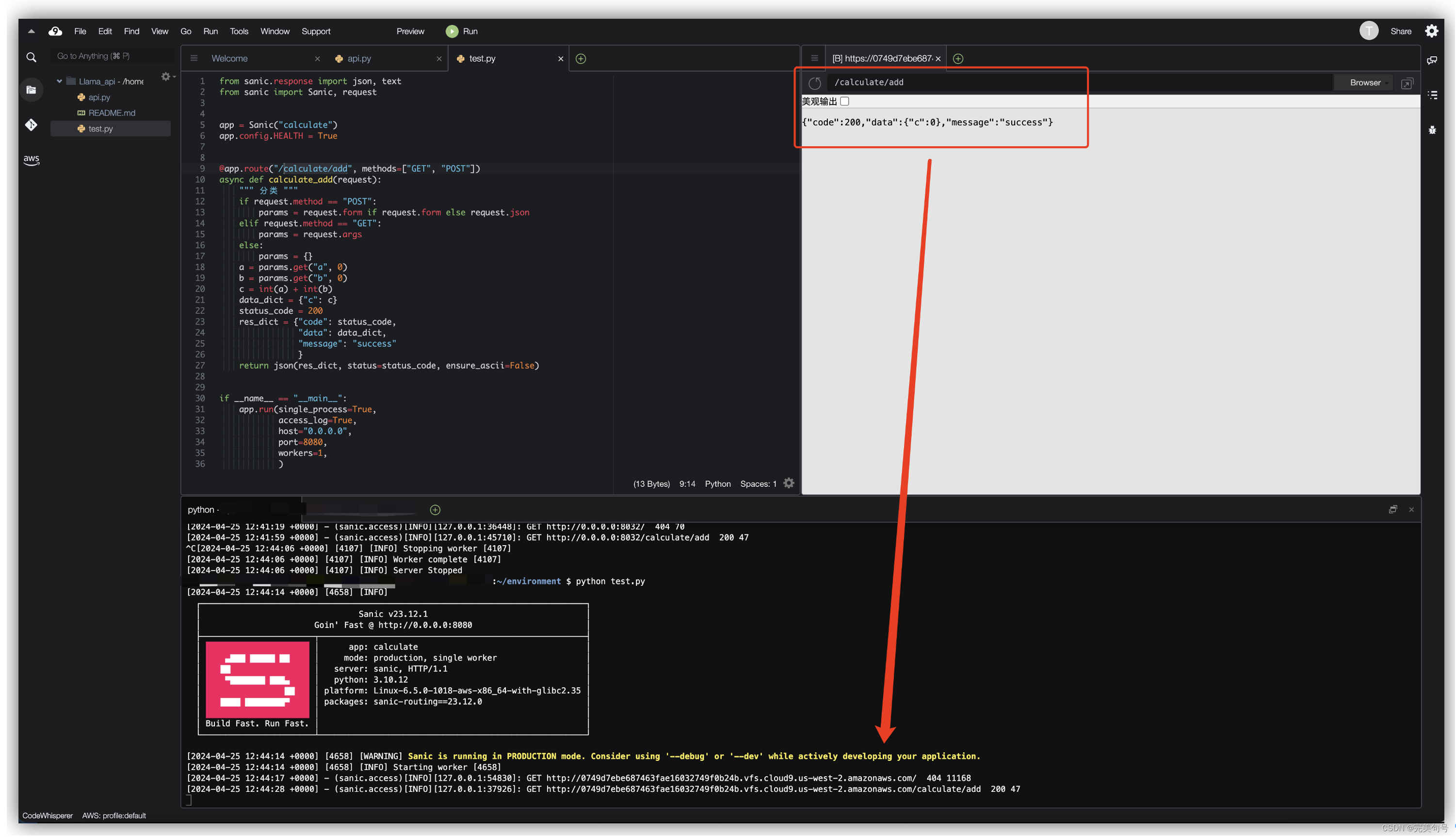
可以看到我们快速的通过一个简单Sanic代码构建出一个Web服务器,通过内置的浏览器进行访问,可以看到get请求是成功的,那接下来就好办了,模型能解析成功,web服务器的get请求也成功了,将两者进行结合就可以得到一个API的服务器请求了。
6.4 编写Python的Web应用提供模型解析服务:
from sanic.response import json, text from sanic import Sanic, request import json as json2 import boto3 app = Sanic("calculate") app.config.HEALTH = True session = boto3.Session() bedrock = session.client(service_name='bedrock-runtime') bedrock_model_id = "meta.llama2-70b-chat-v1" @app.route("/calculate/add", methods=["GET"]) async def calculate_add(request): if request.method == "GET": params = request.args else: params = {} prompt = params.get("prompt", "") body = json.dumps({ "prompt": prompt, "max_gen_len": 2048, "temperature":0.5, "top_p":0.9 }) response = bedrock.invoke_model(body=body, modelId=bedrock_model_id, accept='application/json', contentType='application/json') #发送调用请求 response_body = json2.loads(response.get('body').read()) response_text=response_body['generation'] data_dict = {"result": response_text} status_code = 200 res_dict = {"code": status_code, "data": data_dict, "message": "success" } return json(res_dict, status=status_code, ensure_ascii=False) if __name__ == "__main__": app.run(single_process=True, access_log=True, host="0.0.0.0", port=8080, workers=1, )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
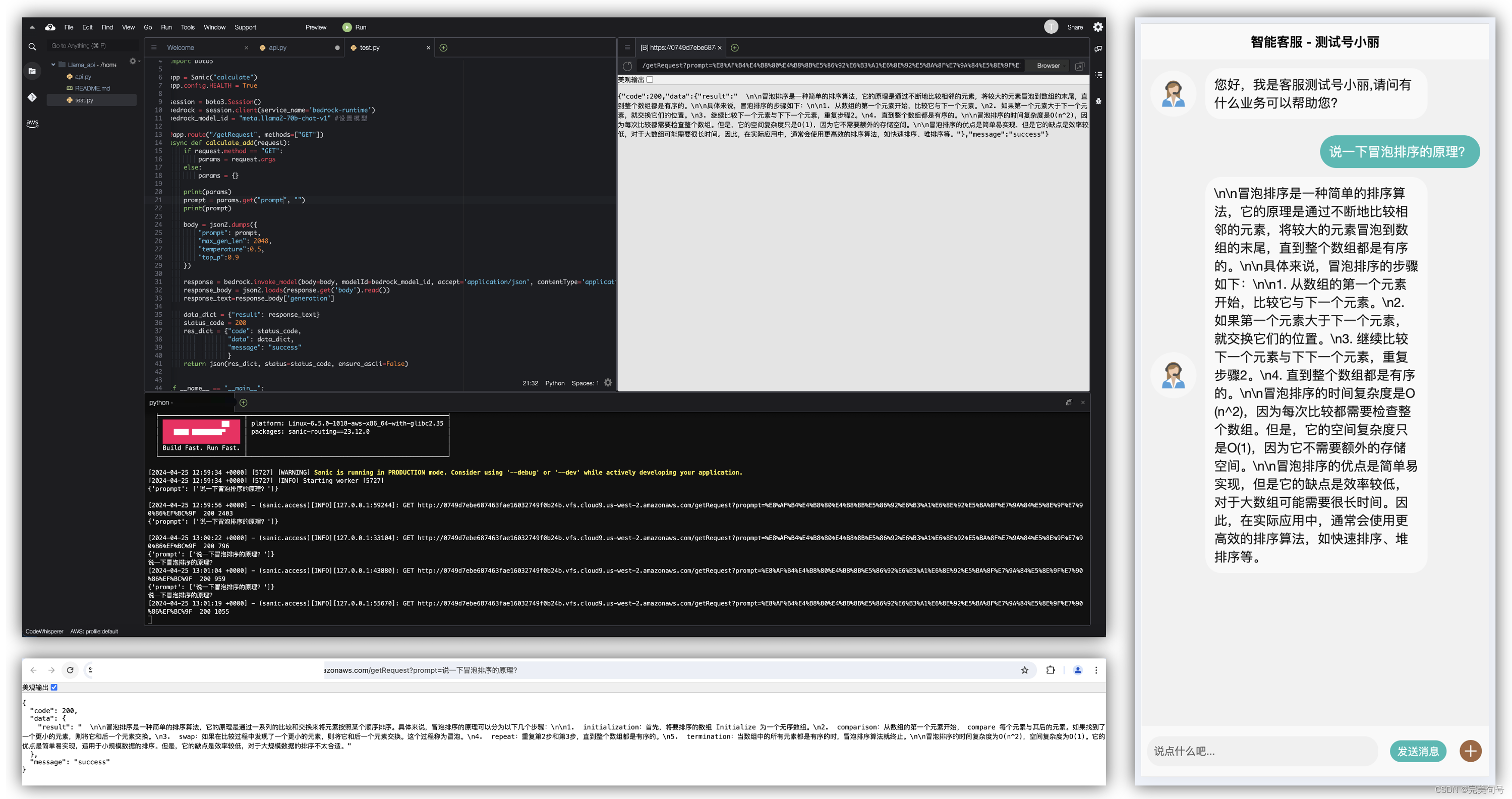
通过上面的例子改造,我们将这个接口请求放到我们的客服代码请求中,可以看到输入提示词prompt参数即可返回信息,把返回的信息进行渲染即可。
六、比较团队中已有的AI方案:
GPT-4.0相较于GPT-3.5在综合能力方面的确更出色,尤其是逻辑、推理等方面,能力更出色、更强大。
团队中也有人在使用GPT-4,想要技术整个团队的普及,是比较困难的。需要接收海外的短信、海外的银行卡、访问OpenAI网站(在外面),而且使用不当还容易封号,ChatGPT 4.0是收费的,必须开通plus会员才可以用。

而现在让你用一个 API 就能接入来自 AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和 Amazon等领先人工智能公司的高性能 AI 基础模型(FM),就可以不用科学上网、不用银行卡、不用短信、不用收费限制,即可在团队或企业、个人中免费无缝体验上AI应用,使工作和生活效率事半功倍,还在犹豫啥?
以下是公司手动搭建AI应用环境环境,并运行Stable diffusion,时间周期还是比较长的,而且还比较消耗硬件的资源。
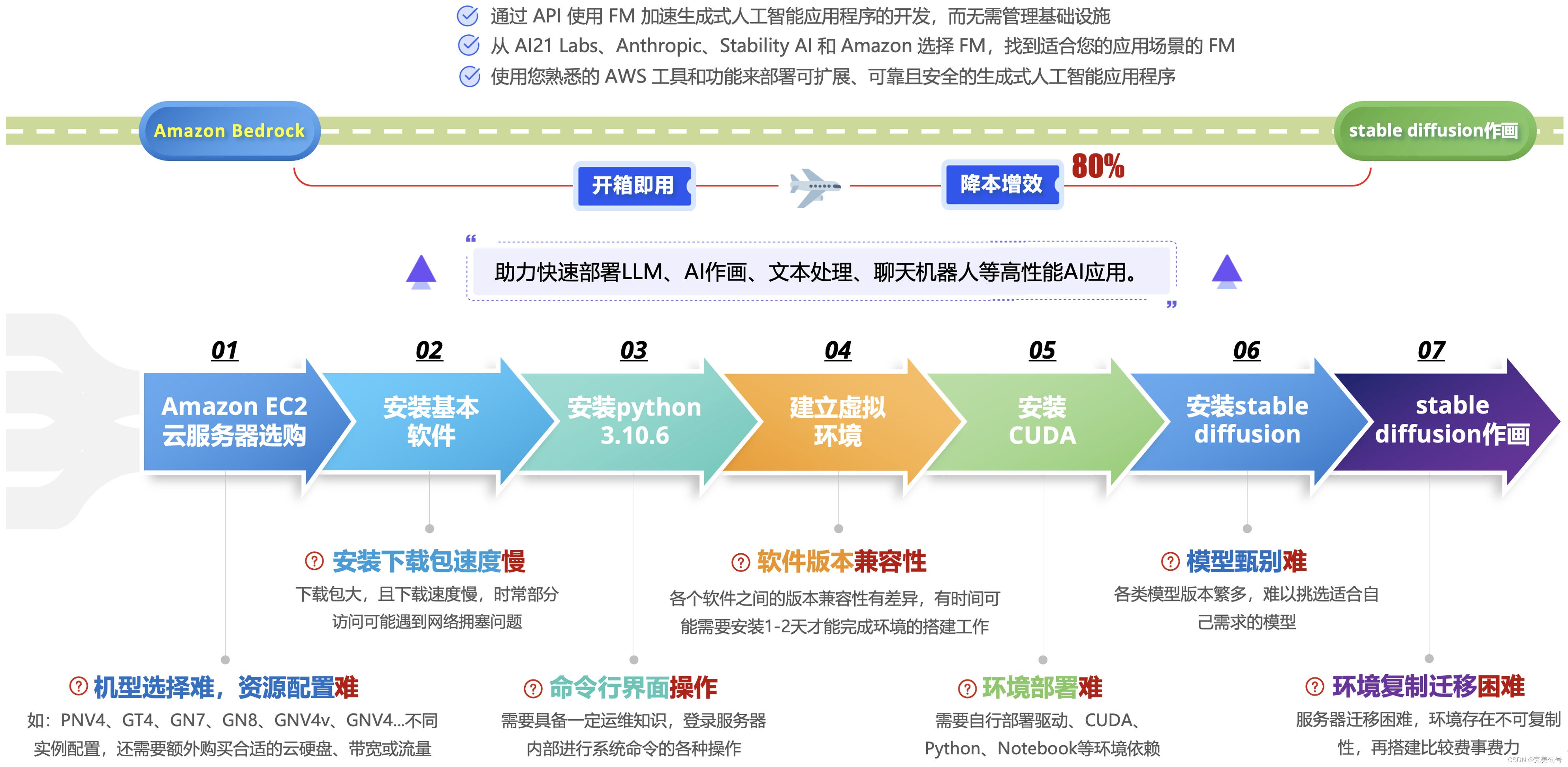
在体验完Amazon Bedrock后对比可以看出,同样来实现一个AI人工智能对话的需求,一站式全托管Amazon Bedrock服务大大的降低了使用的门槛、降低了学习的成本,让更多的企业、开发者能够加入到AI应用的行业中来。
通过“Amazon Bedrock”的实践了AI作画、AI LLM模型、AI智能机器人的案例,可以体验到简易部署、便捷维护,减少工作量、步骤繁琐、效率低和时间成本的问题,同时提升系统整体性能和用户体验。
以下为在体验过程中,个人觉得非常提效的几个点:
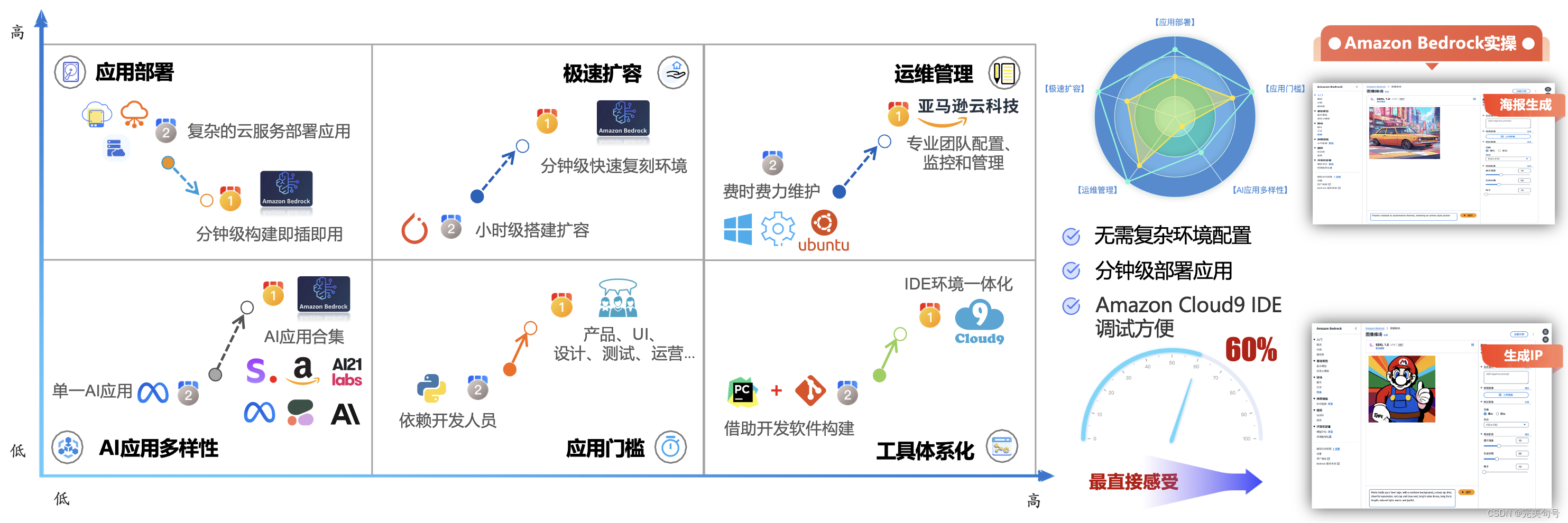
同时,在体验AIGC的应用中,可以通过Aws的“Amazon Bedrock”的应用大幅提高内容生成的速度,节省时间和资源,“Amazon Bedrock”可以轻松应对大规模的内容生成需求。
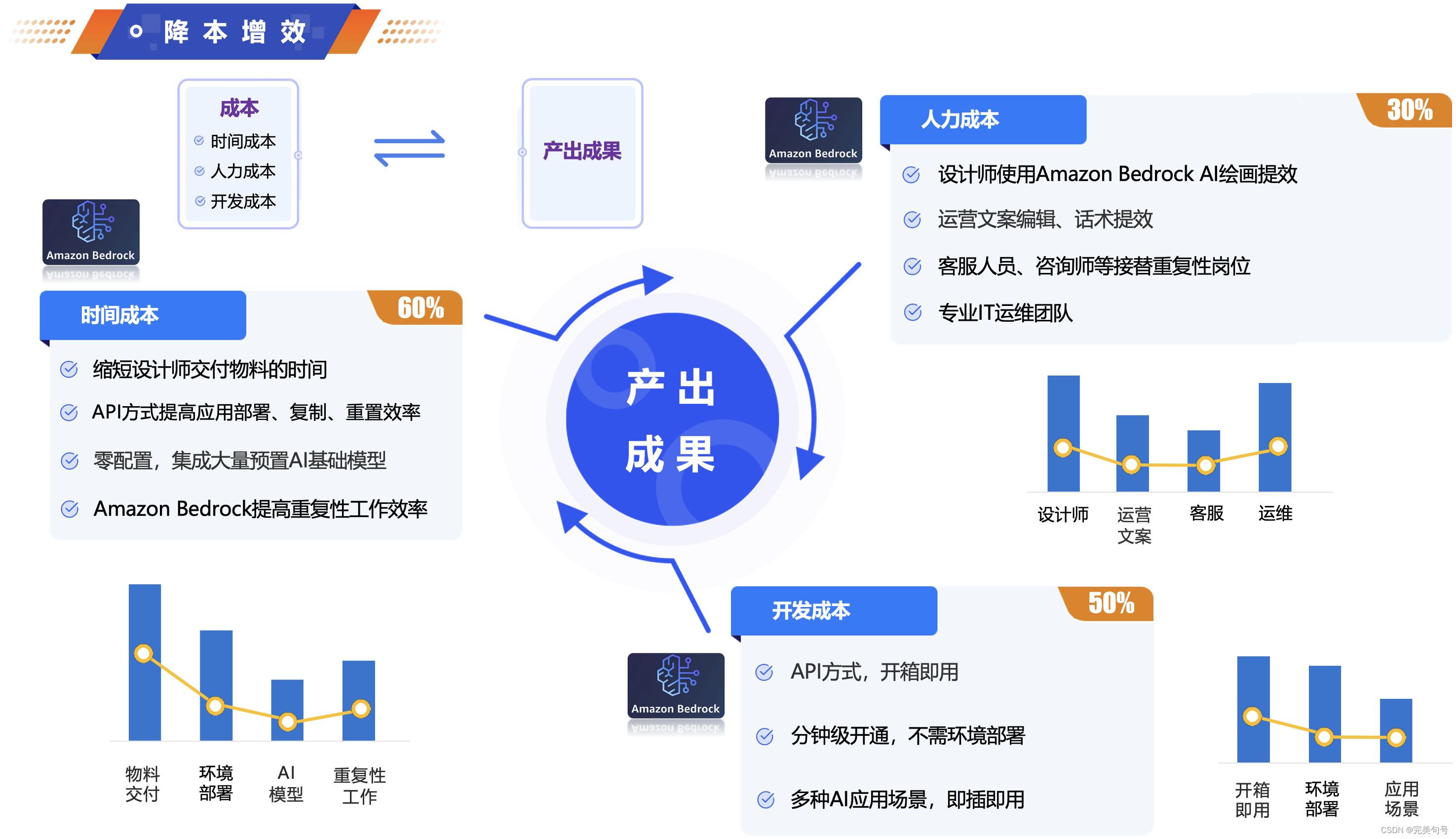
当然,并非是AI取代了人,而是会用AI对话模型、AI绘画工具的人,替换掉不会驾驭AI工具,传统的作业方式的人,让使用“Amazon Bedrock”可以在企业中,实现“一个人顶一个组”、“支撑以前2-3倍的业务体量”。

总结:
随着⽣成式⼈⼯智能(AIGC)技术的兴起,技术构建者们⼜⼀次冲⼊了⼀个满是挑战和机遇的浪潮。Amazon Bedrock 提供了构建⽣成式⼈⼯智能应⽤程序所需的⼀切,它是专⻔为创新者量身打造的平台。通过 Amazon Bedrock 强⼤的资源和⼯具,你可以迅速体验最新⽣成式⼈⼯智能技术,⽆论你的经验如何。⽆论你是AI初学者还是希望提升技能的专家,Amazon Bedrock都能助你⼀臂之⼒。 本⽂主要是通过 Amazon Bedrock 体验 Meta Llama 2构建基于⽣成式⼈⼯智能的体验。
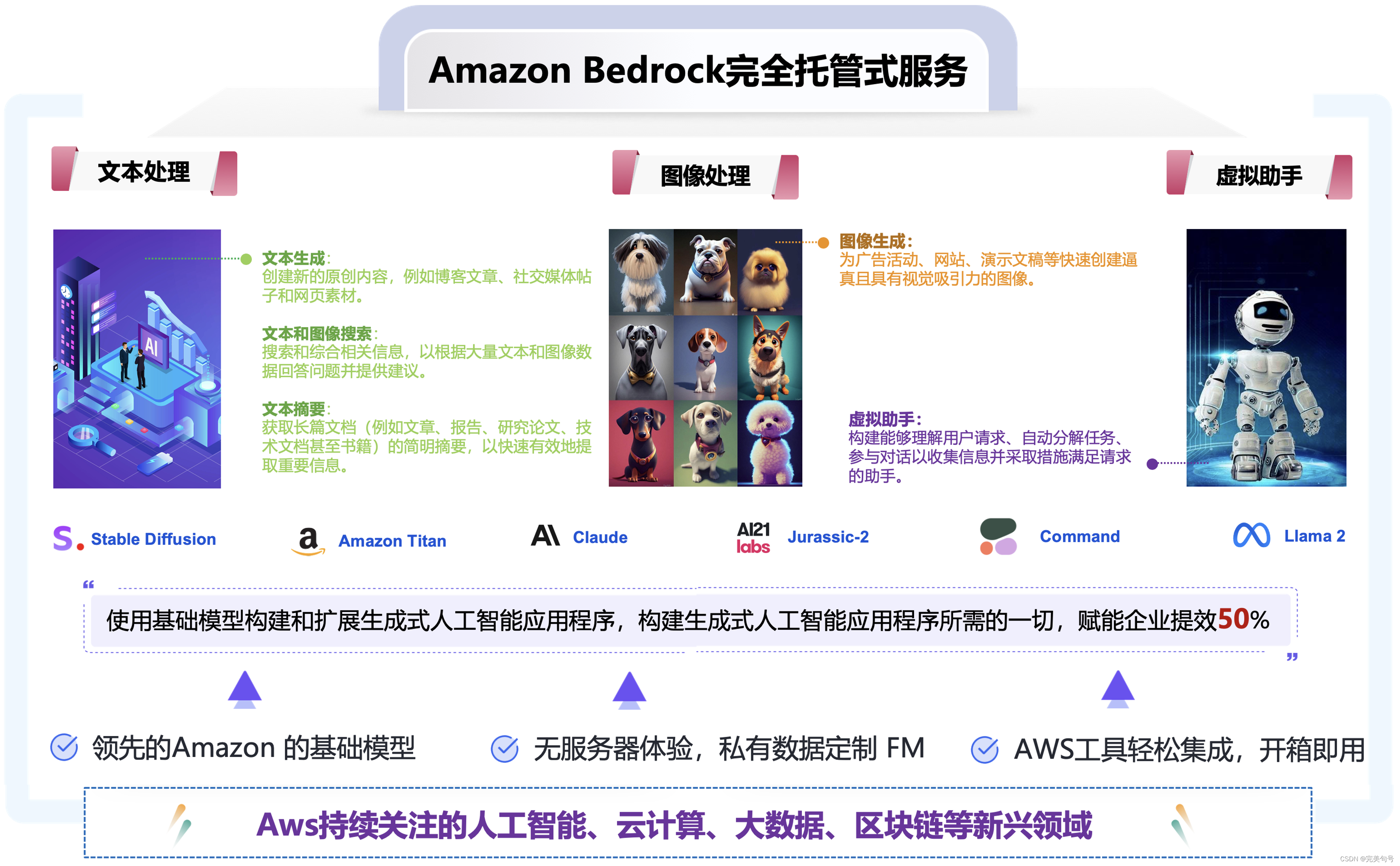
Amazon Bedrock 是一项创新的完全托管服务,旨在通过一个简化的 API 接口,提供来自AI21 Labs、Anthropic、Cohere、Meta、Stability AI 等行业领先公司的高性能基础模型。这个服务不仅为开发者提供了一个广泛的功能集,以便安全、私密且负责任地构建生成式 AI 应用程序,还使得开发者能够轻松尝试和评估多种高性能基础模型,以找到最适合其特定用例的解决方案。
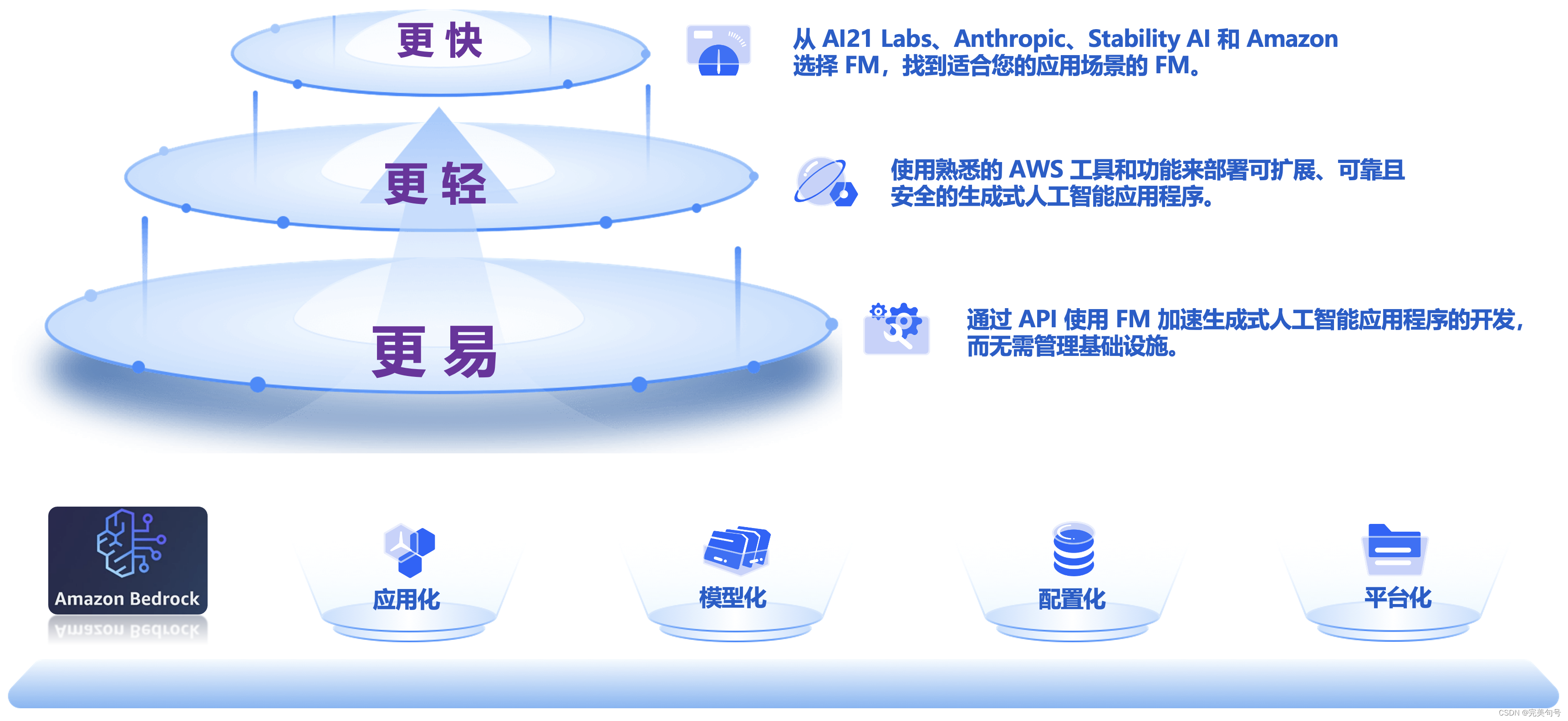
亚马逊云科技Amazon Bedrock作为一项完全托管的服务,用户只需要通过API的调用就可以完成基于LLM的推理工作,大大地降低了用户涉足AI的门槛,同时Serverless的方式也极大的降低了入门成本。

