
- 1机器学习与深度学习:区别与联系(含工作站硬件推荐)_7个pcie插槽 机箱 双路gpu
- 2部署DiffSynth-Studio实现视频风格转换
- 3Leetcode题库(数据库合集)_ 难度:困难_leetcode题库数据集
- 4milvus实战 | docker部署单机版_milvus docker
- 5Graph Embedding_有向图 节点相似度计算
- 6最新最全大数据毕业设计选题推荐_数据科学与大数据毕业论文选题方向
- 7Flutter 应用内调试工具(字节&贝壳)
- 8ctfshow元旦水友赛 easy_web_ctfshow 以假换真
- 9SublimeText3配置UnityShader编辑环境_unity shader 格式化
- 10实现页面分页
小白的大数据入门路——Hive学习笔记_hive with as 用法
赞
踩
文章目录
一、Hive基本概念
1.1、什么是Hive
Hive:最早由Facebook开源用于解决海量结构化日志的数据统计
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成为一张表,并提供类SQL的查询功能
本质:就是将HQL(Hive Query Language)转化为MapReduce程序
简单原理图:
其实整个过程还是要依托Hadoop的组件来完成的。比如MapReduce的运行需要Yarn来进行资源调度管理,计算的数据和结果还是存放在HDFS上,所以现在就很好理解为什么说Hive是Hadoop的数据仓库工具了。
总结:
- Hive的处理数据是存放在HDFS上的
- Hive分析数据底层的默认实现是MapReduce(可以修改)
- 执行程序(底层是MapReduce)是运行在Yarn上的
1.2、Hive的优缺点
优点
- 操作接口采用类SQL的语法,简单容易上手
- 避免了写MapReduce程序,降低了学习成本
- Hive由于采用MR进行数据分析计算,所以执行延迟较高,适用于对实时性要求不高的场景
- Hive善于处理大数据,不适合处理小文件,其实是MR的优势和不足
- Hive支持用户自定义函数,用户可以根据自己的业务需要来定制自己的函数
缺点
- Hive的HQL表达能力有限,主要表现在:
- 对于迭代式算法无法表达(迭代式算法:对计算结果进行迭代处理)
- 数据挖掘方面不擅长(数据挖掘本质就是通过使用迭代式算法)
- Hive的效率较低
- Hive自动生成的MapReduce程序,通常情况下不够智能化(自动生成的没有全手写的来得智能)
- Hive的调优比较困难,粒度较粗(因为是使用MapReduce模板,所以即时调优也不能精确到MapReduce的方法中)
1.3、Hive架构原理
简易架构图
先不看HDFS和MapReduce。整个Hive组成核心就是解析器、编译器、优化器、执行器以及元数据存储
- CLI、JDBC、Driver都是Hive对外开放的用户操作接口
- 元数据MateData:存放Hive通过映射HDFS中文件生成表的一些数据,包括表名、所属数据库、字段属性、字段名以及表数据的路径等。默认存储在自带的derby数据库中,但是推荐使用MySQL进行存储元数据
- 解析器:主要是检查SQL的语法以及数据合法性的检查
- 编译器:将解析通过的SQL,结合MapReduce的模板翻译成对应的MapReduce程序。
- 优化器:对要执行的程序进行简单的优化处理
- 执行器:提交执行MR
1.4、Hive对比数据库
由于Hive采用的类SQL查询语言,以及表、数据类型、数据库等都和数据库比较相似,所以很容易误以为Hive也是一款数据库软件,其实Hive只是针对Hadoop的一个数据仓库的工具,和数据库相比区别还是比较大的。
查询语言
Hive:HQL(Hive Query Language),MySQL:SQL(Structured Query Language)两者虽然语法大致相同,但是前者针对大数据环境,还提供了一些特殊的功能语法。
数据的存储位置
Hive是建立在Hadoop之上的,所以Hive的数据都是存放在HDFS上的。而数据库则是将数据存放在块设备或者本地文件系统中。
数据更新
Hive是针对数据仓库设计的,而数据仓库中的内容都是多读少写的,所以Hive对数据的操作基本都是查询,不建议对已有的数据进行改写,而数据库则是面向与用户交互对数据进行存放的,所以数据库对数据的更新就包括增删改查。
索引
MySQL中使用数据存储引擎InnoDB是支持索引的,在数据库中建立索引主要是优化SQL的查询速度。而Hive中是不支持创建索引的,即时有索引在海量数据的场景下优化的幅度也不明显。
执行
Hive的本质是将HQL转化为MR程序运行,而数据库一般都有自己的执行引擎。
执行延时
由于Hive是采用MR进行数据分析计算,所以MR慢的特性就提高了Hive的执行延时。而SQL的执行效率相比较来说在数据量瓶颈之前要快得多。
可扩展性
得益于Hadoop的优良扩展性,Hive的扩展性也相应提升,而反观数据库扩展性却不那么理想。
数据规模
Hive能处理的数据都是大规模的数据,而数据库的性能瓶颈的原因2000万条数据是单台数据库所能接收的最大数据量。
二、Hive安装
2.1、安装包准备
-
Hive 1.2.x(可以尝试新版本2.3.x)
-
MySQL的相关安装文件
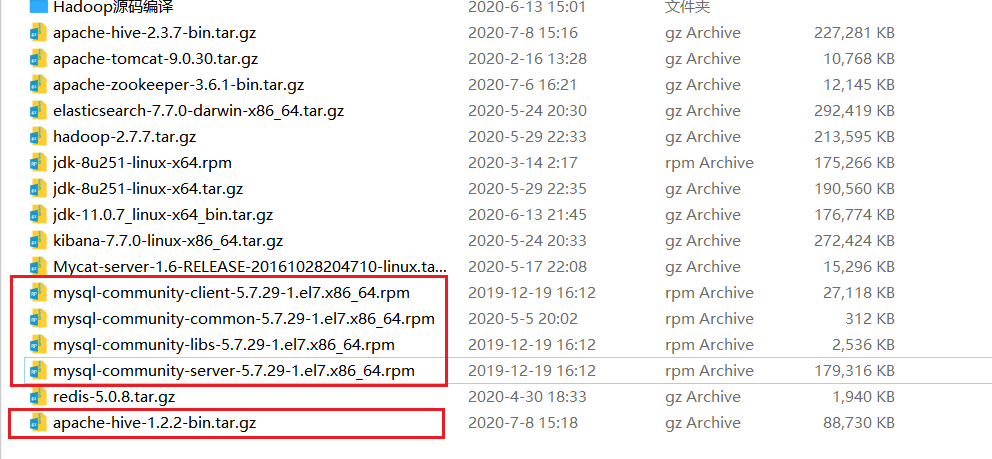
-
到虚拟机上解压Hive:(初始目录结构)
2.2、相关配置和启动
-
首先确保Hadoop的环境配置没有问题
-
hive的conf目录中
hive-env.sh.template文件修改export HADOOP_HOME=/opt/module/hadoop-2.7.7 export HIVE_CONF_DIR=/opt/module/hive-2.3.7/conf- 1
- 2
-
启动Hadoop(NN、DN、RM、NM)
-
使用
bin/hive启动hive即可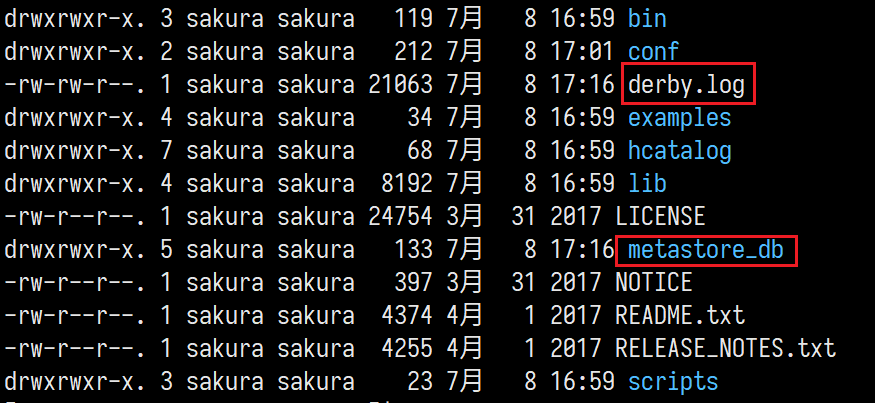
启动后目录中多了
derby.log、metastore_db文件,是和元数据存储相关的文件。 -
执行一些简单命令:
show databases;create table xxx(xx)创建一张表insert插入数据我们做一次数据插入,他居然启动了一个MapReduce Job!!
并且还在HDFS中创建了一些文件目录:
/user/hive/warehouse/000000_0,下载这个文件查看,里面放着就是我们插入的数据select查询数据count(*)统计数据数只要是设计数据的变动和计算的都会启动MapReduce进行处理。
2.3、本地文件导入Hive
要知道Hive是应用于大数据场景下的,手动录入数据显然是不可能的,Hive提供了从文件导入数据到Hive的功能。
2.3.1、Linux本地文件导入
-
在Linux文件系统中创建一个stu.txt文件(/opt/module/data/stu.txt)
2 lisi 3 wangwu 4 sonliu- 1
- 2
- 3
字段之间以/t分隔
-
在Hive中使用命令从本地导入
load data local inpath ‘/opt/module/data/stu.txt’ into table student;注意:从Linux本地导入数据要在load data后加上 local !!
-
导入数据后,却意外发现导入的数据无法被正常读取到
这是正常情况,总不能说随便来个数据像导入就导入吧!**必须保证数据的格式和已有的数据文件格式一致!!**我们在创建表的时候,并没有规定数据之间以
\t分割,而默认是<0x01>很明显两个文件的数据格式就不一样!
-
重新建表规定数据格式
create table stu(id int, name string) row format delimited fields terminated by '\t';规定字段之间使用\t作为分隔符。
-
再次导入数据进新表
-
发现HDFS中对应表的数据文件中出现了stu.txt文件
既然就是将文件移动到了HDFS中对应的文件夹里面,那么我们使用hdfs命令手动put文件到这个文件夹中行不行呢?
-
手动put文件到HDFS测试
-
准备文件(/opt/module/data/stu2.txt)
5 xiaoming 6 xiaohong 7 xiaoqiang- 1
- 2
- 3
-
HDFS命令上传文件到/user/hive/warehouse/stu
-
hive查询
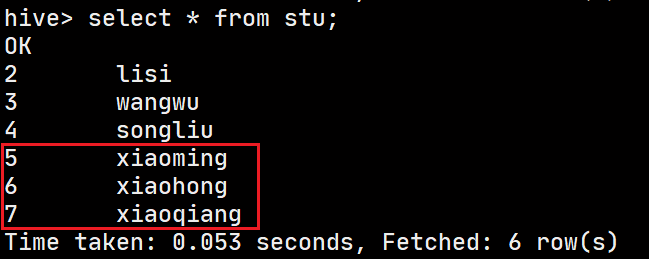
没有毛病!
初步判断本地导入数据,就是将本地的数据拷贝到了HDFS上的数据目录下
-
2.3.2、HDFS文件导入
刚才测试的是从Linux文件系统导入数据,现在我们直接在HDFS上导入数据。
-
准备数据导入到HDFS(hdfs:///stu3.txt)
8 aaa 9 bbb 10 ccc- 1
- 2
- 3
-
Hive导入数据
load data inpath ‘/stu3.txt’ into table stu; -
查询结果
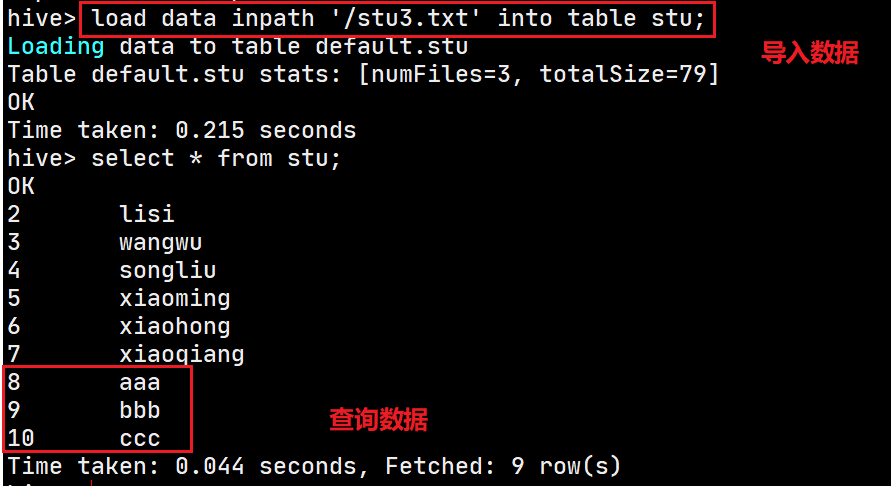
-
但是蹊跷的事情发生了:原数据文件在HDFS中不见了
不出意外数据还是在Hive的表数据目录中
难道真的是发生了数据迁移?
要知道这种移动的效果只是在HDFS这个可视化界面上产生,在Linux的Hadoop中数据的位置并没有发生变化,我们之前说的Hadoop的数据内容与元数据是分离的元数据放在NameNode中,也就是说想要达到视觉上的数据移动,只需要修改NameNode中stu3.txt文件的元数据(中的路径)即可。
真实的数据其实一直都在这里没有动。只是修改其元数据中的路径属性。
2.4、安装MySQL
为什么安装MySQL呢?
默认使用derby存储元数据,但是存在缺陷:只允许同时一个客户端窗口连接,开多窗口的连接hive时报错,无法连接:
所以改用MySQL来存储元数据。
MySQL的安装步骤参考:MySQL学习笔记
仅仅安装配置MySQL还不够,还需要一个MySQL的连接驱动,稍后会将其解压文件中的驱动jar包加入到Hive的lib目录下
修改Hive的配置文件(hive-site.xml(首次新建))
hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!--MySQL连接的URL,存放元数据的库:metastore--> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=true</value> </property> <!--连接驱动的完整类名--> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <!--连接用户名--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>Username to use against metastore database</description> </property> <!--连接的密码--> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> <description>password to use against metastore database</description> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
在hive-default.xml中默认使用的连接驱动是derby
重启测试
配置完成后,重启hive,此时会发现之前的所有数据没有了,表示元数据已经成功迁移到了MySQL上!
此时再回到Hive中,尝试多窗口启动hive也不会报错了!!
来看看Hive存放再MySQL中的元数据
里面空空如也,也就很好解释为什么我们的Hive中没有数据了。
2.5、Hive的JDBC访问(了解)
有助于我们后期学习第三方框架,来替换默认的MapReduce
先向Hive中添加一些数据。
hive> select * from aaa;
OK
1
2
3
4
5
6
7
Time taken: 0.03 seconds, Fetched: 7 row(s)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
启动hiveserver2服务
bin/hiveserver2(这是一个阻塞进程,当我们连接上进行操作时会输出相应的提示信息) -
启动beeline
bin/beeline -
连接hiveserver2
beeline>
!connect jdbc:hive2://hadoop102:10000输入用户名:sakura,密码:没有不输入
-
连接成功
一边执行,hiveserver2的阻塞进程也在不停的输出命令的执行情况:
2.6、Hive常用交互命令
当前我们使用Hive存在一些局限,Hive的命令行都是在hive的命令行去完成,可是我们处理数据一般在凌晨使用脚本去自动完成,那能不能不进入hive在Linux命令行中就完成Hive的命令执行呢?
Hive给出了两种方案:执行命令行中的查询语句、执行文件中的查询语句
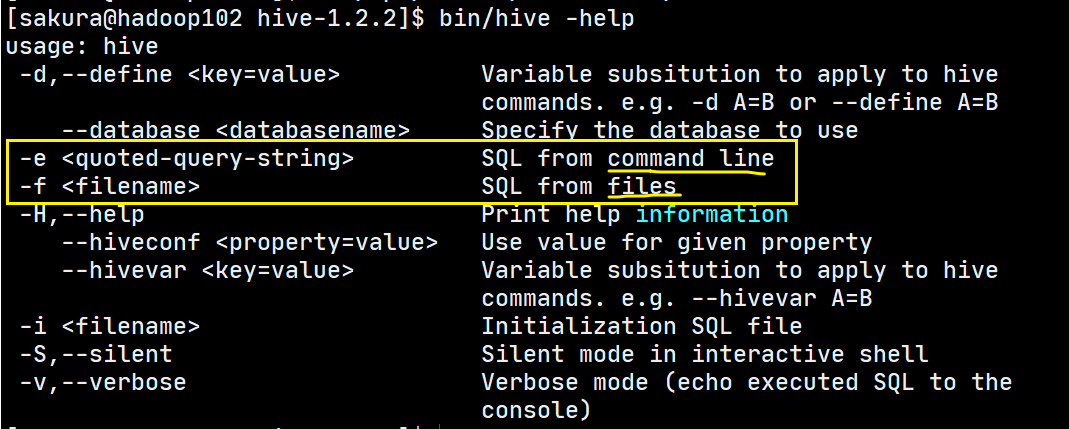
从命令行读取HQL执行
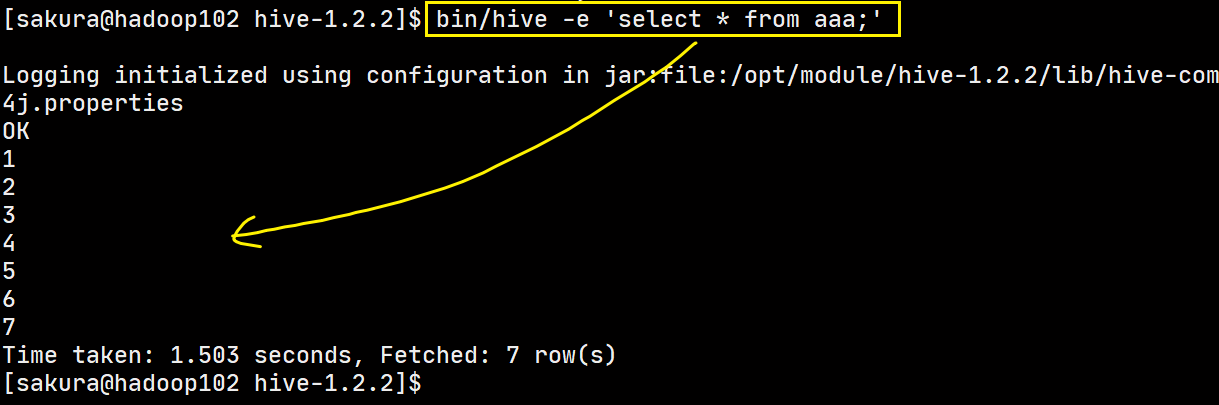
虽然说是有点慢,但是不必进入Hive再去执行查询了。
从文件读取HQL执行
在文件中先写好要执行的查询语句,使用-f选项加上文件路径执行即可
有了以上两种方法,就可以方便我们使用定时任务和脚本来自动完成一些事情。以上的两个命令都可以使用>将结果追加写入到文件中。
其他命令
-
在Hive客户端中操作HDFS
dfs -ls /xx/xx(dfs -xx)hive> dfs -ls /; Found 2 items drwx-wx-wx - sakura supergroup 0 2020-07-08 17:33 /tmp drwxr-xr-x - sakura supergroup 0 2020-07-08 23:11 /user hive> dfs -ls /user; Found 2 items drwxr-xr-x - sakura supergroup 0 2020-07-08 17:31 /user/hive drwx------ - sakura supergroup 0 2020-07-08 23:11 /user/sakura- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
在Hive客户端操作本地文件系统
!ls /xx/xx(!mkdir等)hive> !ls .; bin conf derby.log examples hcatalog lib LICENSE metastore_db NOTICE README.txt RELEASE_NOTES.txt scripts- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
-
查看你hive的历史执行命令
在当前用户的家目录中有一个
.hivehistory隐藏文件可以查看[sakura@hadoop102 ~]$ cat .hivehistory show databases; show database; show tables;- 1
- 2
- 3
- 4
2.7、Hive常见属性配置
2.7.1、常用配置参数
以下配置均可以在hive-default.xml.template中找到,但是需要在hive-site.xml中进行修改!
Default数据库表数据的存放路径(默认:hdfs://hadoop102:9000/user/hive/warehouse)
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
- 1
- 2
- 3
- 4
- 5
Hive命令行显示当前所在库、查询输出表头(默认都是关闭(false))
<!--显示当前所在库-->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
<!--开启表头输出-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
日志文件的输出位置
-
首先将conf目录下的hive-log4j.properties.template改为
hive-log4j.properties -
默认配置
hive.log.dir=${java.io.tmpdir}/${user.name} hive.log.file=hive.log- 1
- 2
默认是在
/tmp/sakura(用户名)目录下,文件名是hive.log并且日志文件是按天滚动的。
-
修改配置
将日志文件位置改到
/opt/module/hive-1.2.2/logs/
以上配置完成,重启hive查看变化。
2.7.2、修改配置的方式
注意:所有用户自定义的配置都会覆盖原有的默认配置,并且Hive会读取Hadoop的配置,所以Hive上对Hadoop的参数配置也会覆盖原有的Hadoop配置。
Hive命令行查看,修改参数
set
只有set,不赋值就是查看
hive (default)> set hadoop.tmp.dir;
hadoop.tmp.dir=/opt/module/hadoop-2.7.7/data/tmp
hive (default)> set mapred.reduce.tasks;
mapred.reduce.tasks=-1
- 1
- 2
- 3
- 4
set赋值只是临时修改,仅在本客户端有效
hive (default)> set mapred.reduce.tasks=10;
hive (default)> set mapred.reduce.tasks;
mapred.reduce.tasks=10
- 1
- 2
- 3
Linux命令行修改(启动时配置)
--hiveconf property=value
[sakura@hadoop102 hive-1.2.2]$ bin/hive --hiveconf mapred.reduce.tasks=2
Logging initialized using configuration in file:/opt/module/hive-1.2.2/conf/hive-log4j.properties
hive (default)> set mapred.reduce.tasks;
mapred.reduce.tasks=2
- 1
- 2
- 3
- 4
- 5
同样这种也是临时修改,仅本次启动有效
配置文件覆盖
创建的hive-site.xml中配置信息会覆盖Hive原有的hive-default.xml中的对应配置!!
修改hive-default.xml.template是毫无意义的!!
三、Hive数据类型
3.1、基本数据类型
| Hive数据类型 | Java数据类型 | 长度 |
|---|---|---|
| tinyint | byte | 1个字节有符号整数 |
| smallint | short | 2个字节有符号整数 |
| int | int | 4个字节有符号整数 |
| bigint | long | 8个字节有符号整数 |
| boolean | boolean | 布尔类型,true or false |
| float | float | 单精度浮点数 |
| double | double | 双精度浮点数 |
| string | String | 字符串类型,使用双引号或单引号表示,可以指定字符集 |
| timestamp | 时间戳 | |
| binary | 字节数组 |
Hive的数据类型是大小写不敏感的,string类型相当于MySQL的varchar,是不可变的,不能指定存储长度,最多可以存储2G的字符数。
3.2、集合数据类型
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
| struct | 结构体类型,类似于C语言中的结构体 | structName.fieldNmae |
| map | 集合Map类型,以KV形式存放数据 | mapName[‘keyName’] |
| array | 数组类型,按顺序存储数据 | arrayName[index] |
3.3、数据类型转换
和Java一样,Hive中的数据类型也支持隐式转换和显示转换,总体来说转换规则可以总结为:
表示范围小的的数据类型可以向表示范围大的数据类型转换
- tinyint、smallint可以转换为int,反之则不行。(不过可以使用cast()进行强转)
- int、float、string在数值正确的情况下可以转换为double
- boolean类型不支持数据转换
在hive客户端可以使用select cast(xx as xx)来尝试做数据类型转换
hive (default)> select cast('1' as int);
OK
_c0
1
Time taken: 0.189 seconds, Fetched: 1 row(s)
hive (default)> select cast('1.23' as double);
OK
_c0
1.23
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.4、集合数据类型实操
上面介绍了集合数据类型,那么我们如何在表中进行使用呢?
数据格式化问题
在Java开发中使用JSON传递数据,JSON对于数据格式要求严格,只有符合数据格式的数据才能被正确解析。这里也是相同的道理,要想Hive能从文件中正确解析出数据存储要做好两件事情:
- 规定好表数据格式
- 按照规定好的格式编写数据
建表并规定数据格式
create table student(
name string,
friends array<string>,
score map<string,int>,
address struct<street:string, city:string>
)
--数据格式规定--
row format delimited
fields terminated by ',' --字段使用 ',' 分隔--
collection items terminated by '_' --集合元素之间使用 '_' 分隔--
map keys terminated by ':' --map中kv之间使用 ':' 分隔--
lines terminated by '\n'; --行数据以 '\n' 分隔--
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
规定好了表中数据的格式后,就要按照要求写数据了。
按规定对数据格式化
我们先来看看对应的数据的JSON表达
{
"name": "sakura",
"friends": ["zhangsan","lisi"],
"score": [
"math": 78,
"computer": 80,
"english": 71
],
"address": {
"street": "danyangdadao",
"city": "yichang"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
按照我们规定的格式对数据进行格式化后:
sakura,zhangsan_lisi,math:78_computer:80_english:71,danyangdadao_yichang
- 1
将格式化的数据写到文件中,在hive中从文件中加载数据测试:
hive (default)> select * from student;
OK
student.name student.friends student.score student.address
sakura ["zhangsan","lisi"] {
"math":78,"computer":80,"english":71} {
"street":"danyangdadao","city":"yichang"}
- 1
- 2
- 3
- 4
- 5
- 6
问题来了,数据插入成功了,我要怎么取出对应的这些集合中的数据呢?
集合数据查询
-
array数据查询
arrayName[index]hive (default)> select friends[0],friends[1] from student; OK _c0 _c1 zhangsan lisi- 1
- 2
- 3
- 4
直接使用数组名和下标就能取到数据。
-
map数据查询
mapName[keyName]hive (default)> select score['math'],score['english'] from student; OK _c0 _c1 78 71- 1
- 2
- 3
- 4
使用map名加上key就能取到对应的value值。
-
struct取值
structName.fieldNamehive (default

