
热门标签
热门文章
- 1头歌:Spark的安装与使用_spark的安装与使用头歌
- 2程序员如何轻松搞副业?完整攻略及注意事项都在这里|TodayAI_程序员 副业
- 3Android休眠唤醒和wakeup_source机制的使用(2)_android wakeup
- 4文心一言降重效果 快码论文_文心一言降重诀窍
- 5python-分享篇-自定义词云图颜色_词云图多种颜色
- 6【爬虫】爬取当当网的图书信息_爬虫获取当当网近七日新书热卖前100图书信息
- 7三面(技术+HR面试)网易,分享我的面试经验!(已拿offer)
- 8WINDOWS系统服务详解
- 9爱星物联——设备运行情况和故障排查初探
- 10OFDM系统信道估计误码率matlab仿真,对比LS,LMMSE,LR-LMMSE三种信道估计算法_lmmse信道估计
当前位置: article > 正文
如何通俗地理解Hive的工作原理?_hive基本原理通俗解释 博客
作者:我家自动化 | 2024-07-16 10:34:29
赞
踩
hive基本原理通俗解释 博客
Hive是基于Hadoop的一个数据仓库工具,主要用来对数据进行抽取、转换、加载操作。HiveQL可以将结构化的数据文件映射为一张数据表,允许熟悉SQL的用户查询数据,也允许熟悉MapReduce的开发者开发自定义的mapper和reducer来处理内建的mapper和 reducer无法完成的复杂的分析工作,相对于Java代码编写的MapReduce来说,Hive的优势更加明显。Hive利用Hadoop的HDFS存储数据,利用Hadoop的MapReduce执行查询。
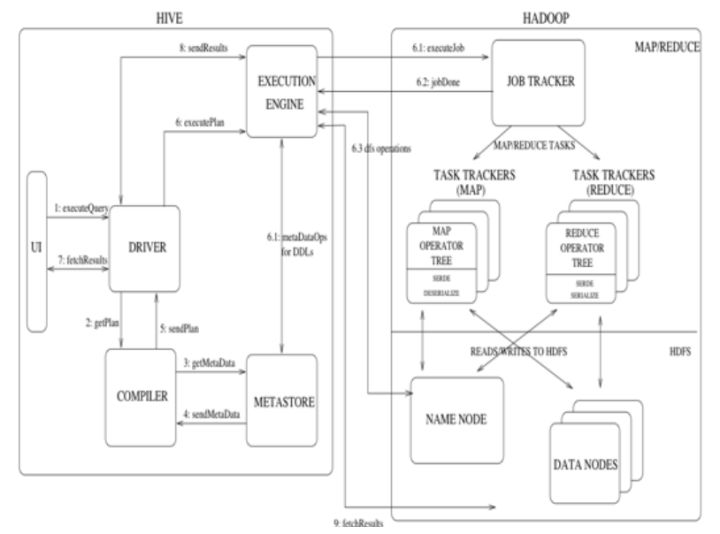
编辑切换为居中
添加图片注释,不超过 140 字(可选)
Hive和Hadoop协作执行任务的工作原理 (1) 用户通过用户接口向Driver提交executeQuery。 (2) Driver向Compiler发送获取计划的请求。 (3) Compiler根据用户提交的executeQuery去MetaStore获取需要的元数据信息。 (4) MetaStore向Compiler发送元数据信息。 (5) Compiler得到元数据信息,并向Driver发送计划。 (6) Driver 向EXECUTION ENGINE提交executePlan。 (7) 用户接口向Driver发起获取结果集(fetchResults)的请求。 (8)Driver向EXECUTION ENGINE发起获取结果集的请求。 (9)EXECUTION ENGINE向Driver发送结果集,Driver获取到结果集后返回用户接口。 文 / 黑马程序员 Python自学必备教程,打包送给你:
零基础学Python篇:
计算机就业、面试篇:
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

