
热门标签
热门文章
- 1机器学习与深度学习:区别与联系(含工作站硬件推荐)_7个pcie插槽 机箱 双路gpu
- 2部署DiffSynth-Studio实现视频风格转换
- 3Leetcode题库(数据库合集)_ 难度:困难_leetcode题库数据集
- 4milvus实战 | docker部署单机版_milvus docker
- 5Graph Embedding_有向图 节点相似度计算
- 6最新最全大数据毕业设计选题推荐_数据科学与大数据毕业论文选题方向
- 7Flutter 应用内调试工具(字节&贝壳)
- 8ctfshow元旦水友赛 easy_web_ctfshow 以假换真
- 9SublimeText3配置UnityShader编辑环境_unity shader 格式化
- 10实现页面分页
当前位置: article > 正文
如何用Python获取网页指定内容_python获取网页内容
作者:我家自动化 | 2024-07-17 06:02:12
赞
踩
python获取网页内容
文章目录
Python用做数据处理还是相当不错的,如果你想要做爬虫,Python是很好的选择,它有很多已经写好的类包,只要调用,即可完成很多复杂的功能
在我们开始之前,我们需要安装一些环境依赖包,打开命令行


确保电脑中具有python和pip,如果没有的话则需要自行进行安装
之后我们可使用pip安装必备模块 requests
pip install requests
- 1

requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多,requests 允许你发送 HTTP/1.1 请求。指定 URL并添加查询url字符串即可开始爬取网页信息
1.抓取网页源代码
以该平台为例,抓取网页中的公司名称数据,网页链接:https://www.crrcgo.cc/admin/crr_supplier.html?page=1
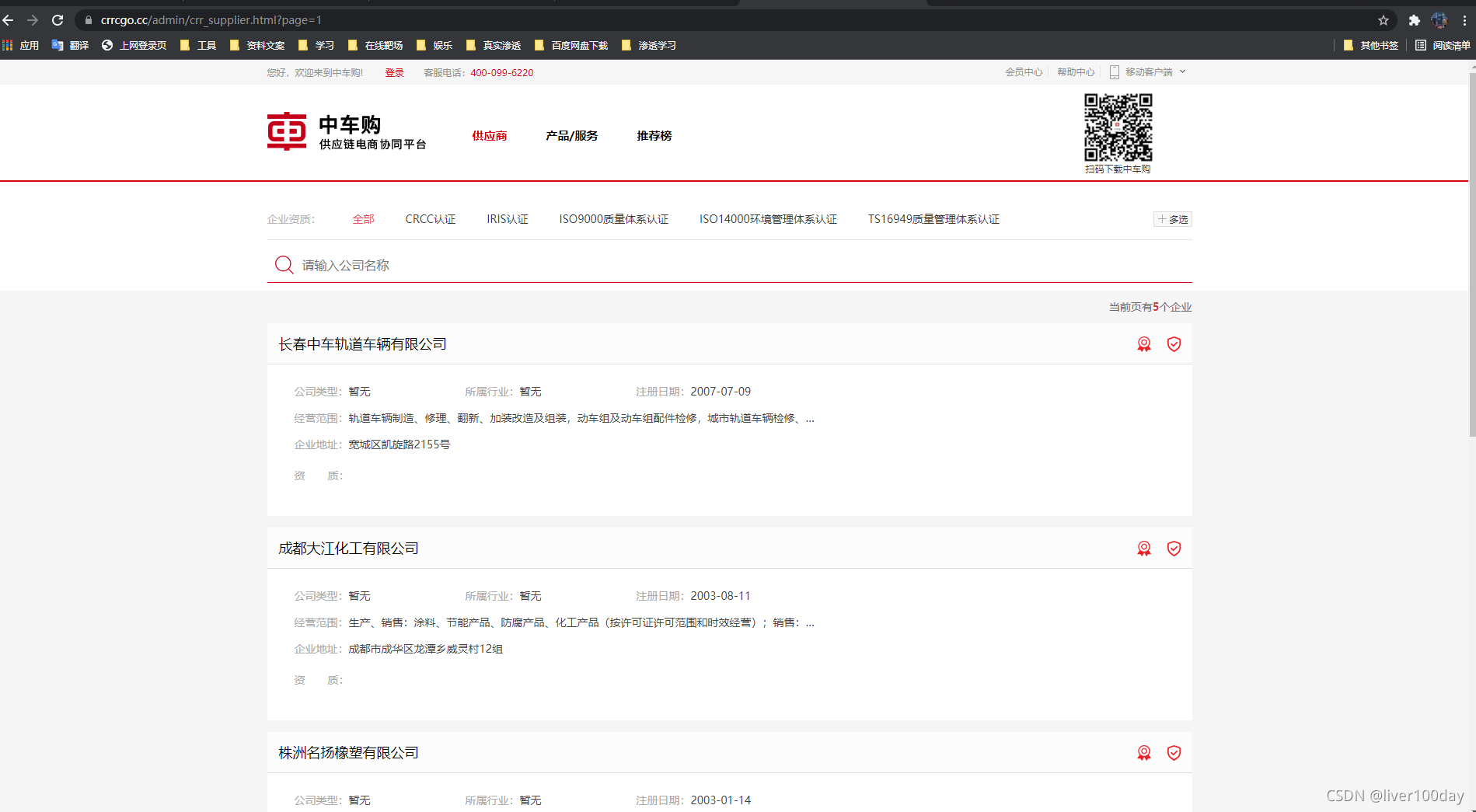
目标网页源代码如下:
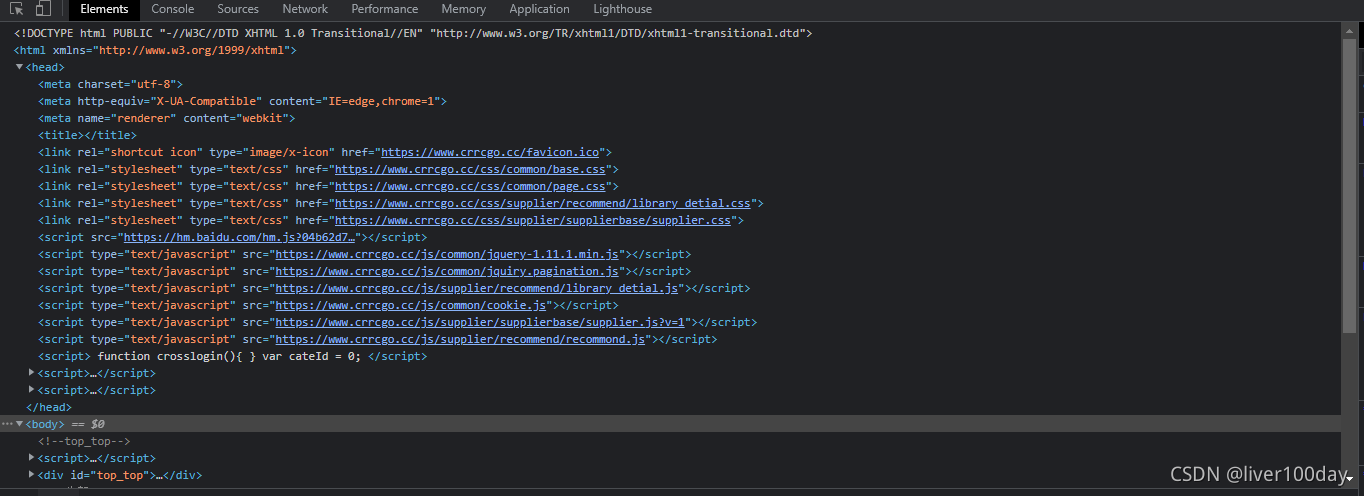
首先明确步骤
1.打开目标站点
2.抓取目标站点代码并输出
import requests
- 1
导入我们需要的requests功能模块
page=requests.g声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/838376
推荐阅读

相关标签

