
- 1【DevOps】Linux 安全:iptables 组成、命令及应用场景详解_iptables phydev
- 2ROS 发布和订阅压缩图像消息 sensor_msgs/Image 和 sensor_msgs/CompressedImage_ros发布和订阅压缩消息
- 3将jar或aar包发布到JitPack.io_jitpack 上传包含jar
- 4Python酷库之旅-第三方库Pandas(021)
- 5探索 dotnetCampus.Ipc:跨进程通信的新选择
- 6PCIe总线的序
- 7mysql表约束基础 【default | 主键 | 外键 | 唯一键】_mysql default
- 8Ubuntu安装Java并且配置JAVA_HOME_乌班图安装java环境
- 9An Improved Blockchain Consensus Algorithm Based on Raft(Raft算法改进区块链效率_raft共识算法改进
- 10智能安全与隐私:数据驱动的安全与隐私保护
博文推荐 | 详解 Kafka-on-Pulsar 原理设计与技术进展
赞
踩
本文整理自《Kafka-on-Pulsar Meetup》上 StreamNative 软件工程师、Apache Pulsar Committer、KoP Maintainer 徐昀泽的《2022 Kafka-on-Pulsar 技术动态》的分享,重点介绍 KoP 项目在 2022 年的最新动向和技术演进趋势。

点击进入小程序,查看 KoP Meetup 回顾视频
走近 KoP
要了解 KoP,首先要从 Kafka 和 Pulsar 谈起。同为消息队列,它们的模型很相似。两者都通过 Broker 将数据上下游分为生产者、消费者,基于 Topic 进行生产和消费。同时,Pulsar 和 Kafka 都支持 Topic 分区化从而增加处理的并行度。
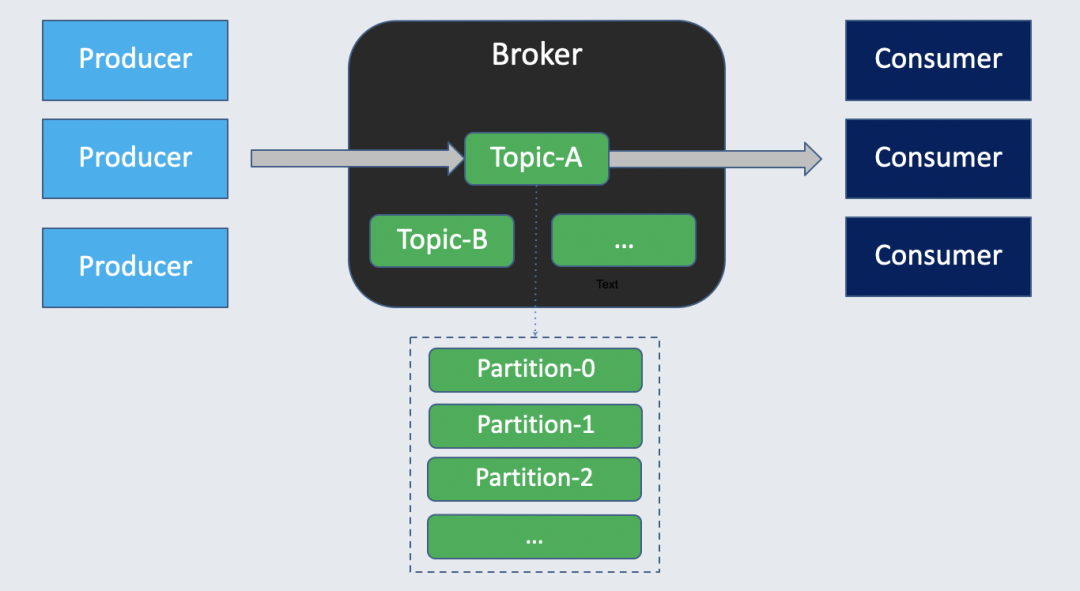
但在存储层,Apache Pulsar 会有一定优势:
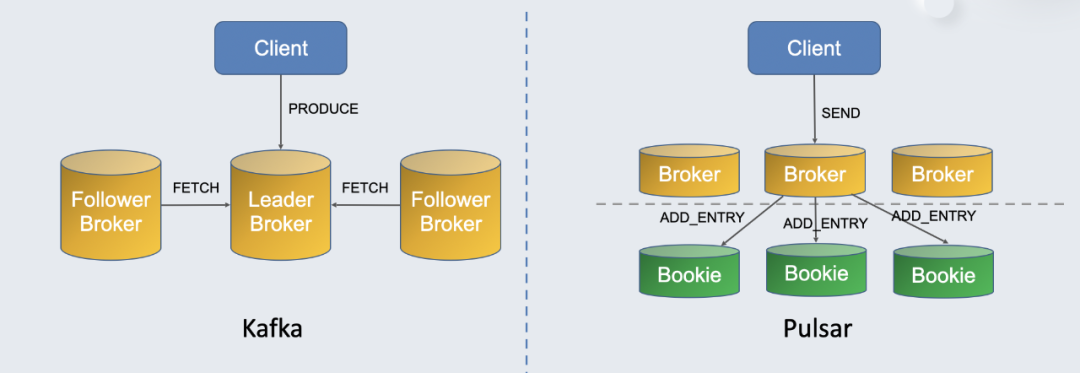
如上图所示,Kafka 生产时通过 PRODUCE 请求将消息释放给 leader broker,leader broker 将消息存储到本地磁盘。与此同时,从节点(follower)会向 leader broker 发送 FETCH 请求拉取最新的消息。Kafka 是主从复制的存储模型,每个 Broker 同时负责计算和存储。
而 Pulsar 计算存储分离,通过 BookKeeper 服务节点 Bookie 处理存储。在 Pulsar 中,客户端将消息发送给 Broker,Broker 处理后再通过 ADD_ENTRY 将消息发送给各个 Bookie。这种模型的运维要更方便,具备强一致、扩缩容简单等优势,可以解决 Kafka 存在的很多痛点。于是很多用户就有了从 Kafka 迁移到 Pulsar 的需求。
要迁移到 Pulsar,常见的方案包括:
1.推动用户更新客户端。缺点包括:
• 用户重写代码,投入较大、成本较大:难点在于用户更换的意愿与参数调优;
• 当前 Pulsar 生态与 Kafka 存在一定差距,Kafka 拥有先发优势,比如多语言客户端以及与第三方组件的集成,因此更新客户端会有一些问题。
2.早期方案是使用 Pulsar Adaptor for Apache Kafka,使用户无需替换现有代码,只需替换 JAR 包即可完成迁移。本质上是使用基于 Pulsar 客户端的依赖来实现和 Kafka client 一样的 API。缺点包括:
• 这种方案只适用于 Java 客户端;
• 对 Kafka Offset 的处理存在缺陷;
• 用户仍需学习一些 Pulsar 客户端的配置来调优,无法复用 Kafka 侧的经验。
3.最新方案:使用 KoP(Kafka-on-Pulsar)。优势包括:
• 用户无需修改现有 Kafka 应用的任何代码,包括不同语言客户端、应用本身、第三方组件等;
• 兼容绝大多数 Kafka 生态(目前 KoP 支持 Kafka 0.9 以上客户端,对 Kafka Transaction 支持暂不完善);
• 直接访问 Pulsar Broker 的资源:在 KoP 之前,很多用户的兼容逻辑是在 Pulsar 前设置代理层来处理 Kafka client 的请求,这样会增加额外的路由与处理。而 KoP 直接调动 Pulsar Broker 资源,减少其他方案中存在的额外性能开销。
如何使用 KoP
从 官网 [1]下载 NAR 包或者自行编译;进入 Pulsar 安装目录,新建 protocols 目录,将 NAR 包放入目录;在 broker.conf 或 standalone.conf 中添加以下配置并启动 broker。
- messagingProtocols=kafka
- allowAutoTopicCreationType=partitioned
- listeners=PLAINTEXT://127.0.0.1:9092
- brokerEntryMetadataInterceptors=\
- org.apache.pulsar.common.intercept.AppendlndexMetadatalntercepor
版本选择:
• KoP 有四位版本号,前三位与 Pulsar 的三位版本号一致,直接兼容对应版本;
• 补丁版本即 Pulsar 第三位版本号升级后,KoP 不再维护对应的旧版本。例如 Pulsar 2.9.2 发布后,KoP 不再维护 2.9.1.m,建议升级 Pulsar 防止不兼;
• 不建议使用版本号低于 2.8 的 Pulsar;
• KoP master 分支为开发分支,若自行编译源码需要切换到 Pulsar 版本对应分支,如 branch-2.9.2。
KoP 工作原理
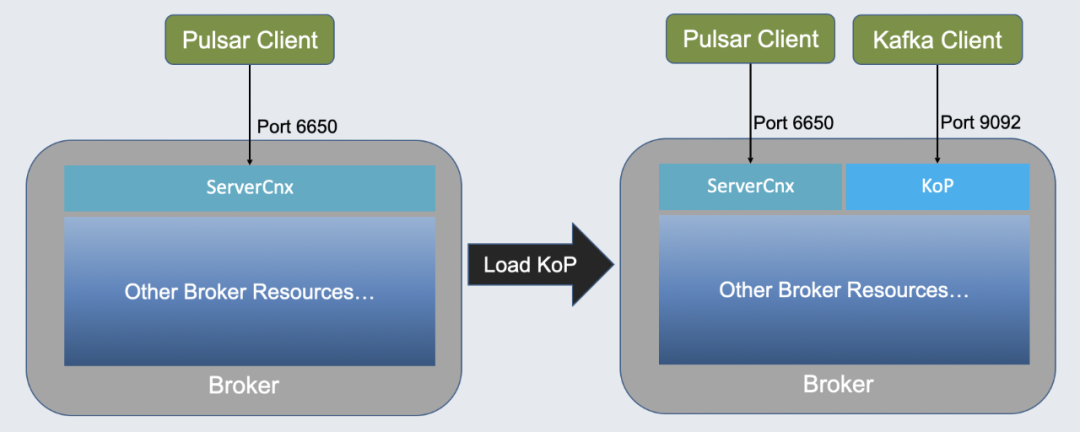
如上图,左侧为没有 KoP 时的 Pulsar。看过 Pulsar 源代码的同学会发现,ServerCnx 类会暴露默认的 6650 端口解析 Pulsar Client 发来的请求,而后调度 Broker 资源。加载 KoP 组件后多了 KoP 组件,Broker 会默认暴露 9092 端口。KoP 组件连接 Kafka Client 并理解请求,而后访问和调度 Broker 所有资源。
KoP 基本设计
Topic 和分区的映射
在 Kafka 中分区是一个独立的整型,而 Pulsar 中分区是 Topic 名字的一部分。
Kafka 分区示例:
- public final class Topicpartition {
- private final int partition;
- private final String topic;
- // ...
- }
Pulsar 分区示例:
persistent://public/default/my-topic-partition-0Pulsar 的 Topic 名称还有三部分。第一部分决定是否持久化消息,由于 Kafka 会将所有消息持久化,所以 KoP 会将所有 Topic 作为持久化 Topic。其次 Pulsar 支持多租户,所以提供了三层 Topic,前两层是租户和命名空间。
KoP 通过以下配置来兼容短 Topic 名称,比如传入 Topic 时会默认设置 Tenant 和 Namespace。同时支持直接访问其他命名空间:

以下为默认配置:
- #默认短 Topic 所在租户和命名空间
- kafkaTenant=public
- kafkaNamespace=default
认证
在生产中启用 KoP 时,可能出现一部分 Namespace 给 Pulsar 客户端使用,另一部分给 Kafka 客户端使用的情况。如果认证出问题,会导致 Kafka 客户端影响其他 Namespace 的错误。所以 KoP 支持认证,只需在 Pulsar 端开启认证的基础上增加配置:
saslAllowedMechanisms=<mechanism>其中 mechanism 支持:
• PLAIN:基于 JWT 的认证
• OAUTHBEARER:基于第三方 OAuth 2 服务的认证
细节详见 KoP 文档[2]。
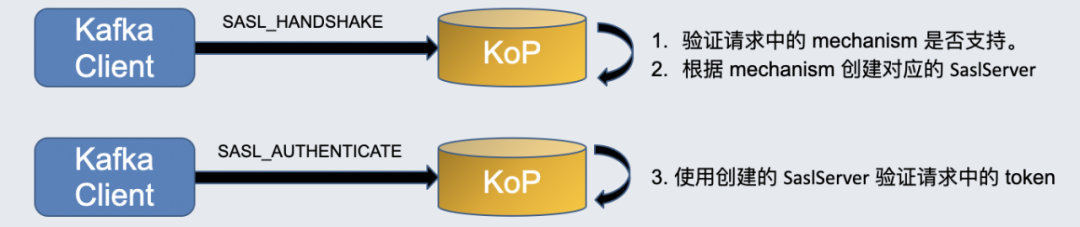
配置验证参数后,Kafka 客户端会首先向 KoP 发送一个 SASL_HANDSHAKE 请求,该请求会携带 Kafka 客户端配置的 mechanism。KoP 会验证请求中的 mechanism 是否支持,并根据 mechanism 创建对应的 SaslServer。
KoP 响应 Kafka 客户端后,后者会发送携带 token 的 SASL_AUTHENTICATE 认证请求。KoP 会使用刚才创建的 SaslServer 验证请求中的 token。目前 KoP 只支持 Kafka 中的这两种认证方式。
鉴权

在认证的基础上,我们要进行鉴权,因为对于 Topic 而言可能只支持某些客户端进行生产、某些客户端进行消费。如图,Kafka 的鉴权比 Pulsar 复杂一些,有 ACL 操作和资源类型。在 Kafka 中资源类型很多,在 KoP 中支持的是 Topic 资源类型,比如 Read 映射到了可以消费处理。
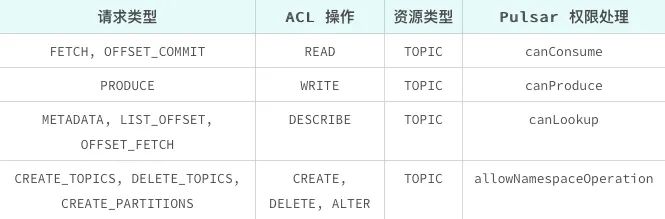
其原理是在认证完成后会生成 Authorization ID,对应 Pulsar Roller,并传递给 Authorization Service。由于复用 Authorization Service,KoP 将 Kafka 定义的请求类型、ACL 操作和资源类型交由 AuthorizationService 处理,因我们可以定制 Authorization Provider。KoP 也支持 SSL 传输,避免暴露信息。
Group Coordinator
Group Coordinator 是很重要的概念,它主要负责两大部分:
• Rebalance:将多个 Partition 分配给同一个 Group 内的多个 Consumer Consumer 可以加入 Group,这个时候会把一个 Topic 的 Partition 分配给不同的 Consumer,这就是所谓的 Rebalance。
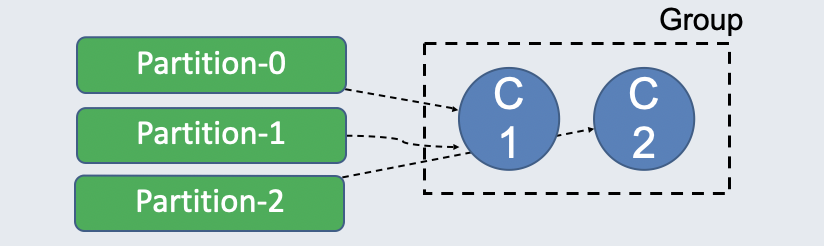
• Commit Offset:将消费者消费的最新消息的 offset 持久化到特殊的 topic。

在 Kafka 中 Broker 之间是非对等的,会有通信,Follower Broker 会向 Leader 告知 ISR 变更;但 Pulsar 中 Broker 之间无法通信,所以使用 Namespace Bundle Listener 组件监听 Bundle 的变化。
消息的读写
因为 Offset Topic 只有一个,所以 Offset Topic 写入直接使用 Pulsar Producer 和 Consumer 进行读写。对于普通消息的读写,KoP 直接利用了 Managed Ledger 和 Managed Cursor 两个 Broker 组件处理:
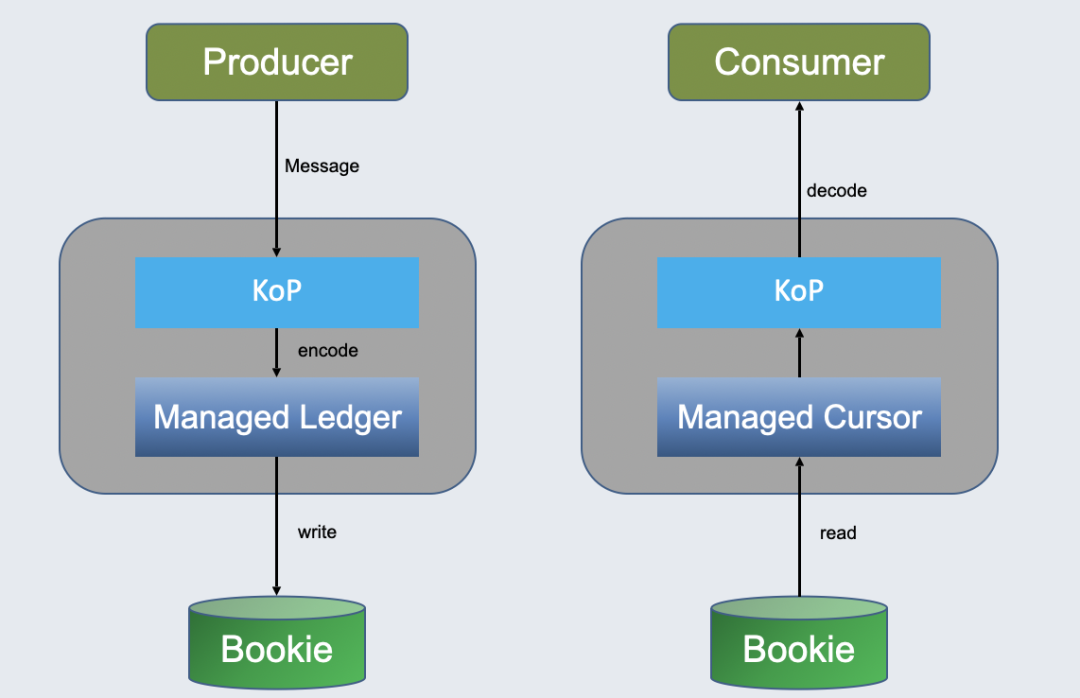
Managed Ledger 对应 Partition,负责把消息写入 BookKeeper。BookKeeper 中数据分为多个分段存储,每个分段对应一个 Ledger,每个 Partition 可以有多个分段,Managed Ledger 就负责管理多个 Ledger。
Managed Cursor 标志每个订阅消费的最新位置。这里 KoP 直接使用 Broker 的资源,无需创建 Pulsar 客户端,所以减少了多余的网络处理层。
Offset 的实现
Pulsar 客户端与 Broker 交互时,消息分为两部分,分别是 payload 和元数据。元数据会在客户端序列化,写入 Broker。Broker 向 Bookie 写入消息时,写入后才能知道消息的序号,Offset 需要另外添加。但消息元数据又不能修改,所以要在头部加上 Broker Entry Metadata:
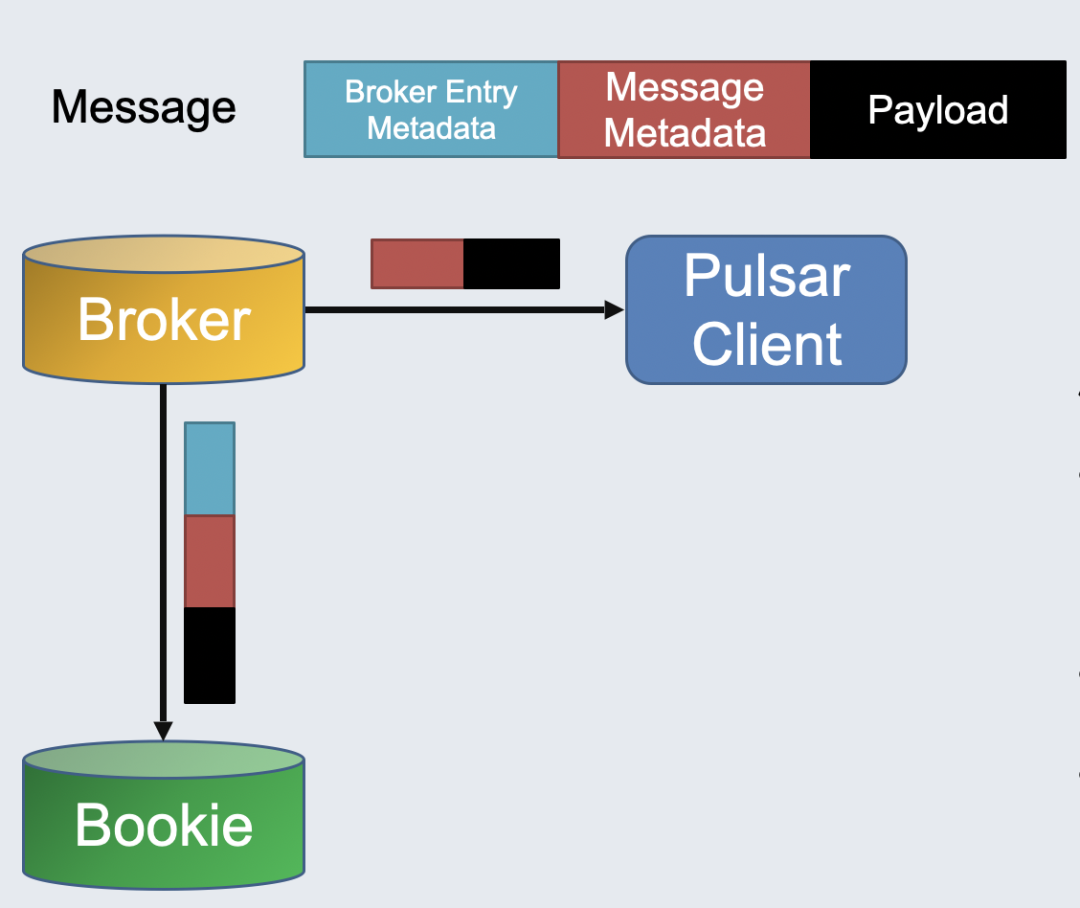
对于 Kafka 客户端,Broker 会动态生成 Offset(即 index),添加到客户端消息的头部,写入 Bookie。Pulsar 客户端会默认跳过这一步骤,从而实现兼容。在 2.10 版本开始,Pulsar Client 也可以取得和 Kafka 一样的信息。
所有涉及到 offset 的请求处理:
• FETCH 请求:对于同一条连接上的第一次请求,进行二分查找找到 Offset 对应的消息。对于后续请求会缓存 Offset 到消息位置的映射。
• PRODUCE 请求:解析出 Index,作为 Offset 返回给 Kafka 客户端。
• LIST_OFFSET 请求:
• Latest:读取 Interceptor 中最新的 Index 并加 1(Log End Offset)
• Earliest of Timestamp:二分查找找到 Offset 对应的消息,解析 Index。
Offset 存储机制和 Kafka 相同,Group Coordinator 会将消息写入 Consumer Offset 这个特殊的 Topic 中。它可以在重启后重新加载回 Offset。
关于设计背景和 KoP 2.8 版本之前所采用方案的缺陷,可以参考《Kafka-on-Pulsar 突破性进展:2.8.0 及更高版本的连续偏移量实现》。
常见问题答疑
entryFormat 配置
社区有人反应在性能测试时发现 KoP 性能差,因为默认情况下 KoP 要保证 Kafka 客户端和 Pulsar 客户端能互相消费生产,但其代价是很大的:
1. 生产时要将 Kafka 格式的消息拆包和解压缩,重新构造 Pulsar 格式的消息;
2. 消费时需要将 Pulsar 格式的消息拆包和解压缩,重新构造 Kafka 格式的消息。
对于绝大多数生产应用来说,建议配置 entryFormat=kafka,其原理是在生产时将消息直接写入 Bookie,顺便在元数据中添加一个 Pulsar Metadata 键值,标记消息来自 Kafka 客户端;消费时对每个 Entry 进行预处理,将实际的 Offset 填充到每个 Entry 对应的数据块中,将多个 Entry 拼接后返回客户端。这里主要的开销来自拼接,比之前小很多。但这种方式的缺陷在于默认不支持 Kafka 生产和 Pulsar 消费,因为 Pulsar 客户端看不到 Kafka 原格式的消息。
针对这一点,KoP 2.9 版本开始引入了和 Pulsar 同版本对应的 Kafka Payload Processor。只要在 Pulsar 客户端引入该依赖,按如下配置即可让 Pulsar 客户端处理 KoP 的 Kafka 格式的消息。对于 Pulsar 2.9 开始的 Pulsar 客户端,可以配置 Payload Processor 消费 Kafka 格式的消息。
- <dependency>
- <groupld>io.streamnative.pulsar.handlers</groupld>
- <artifactld>kafka-payload-processor</artifactld>
- <version>2.9.I.2</version>
- </dependency>
- final Consumer<byte[]> consumer = client.newConsumer()
- .topic("my-topic")
- .subscript ionName("my-sub")
- .subscriptionlnitialPosition(SubscriptionlnitialPosition.Earliest)
- .messagePayloadProcessor(new KafkaPayloadProcessor())
- .subscribe();
消费性能调优
在压测时很多用户反馈消费跟不上生产,可以根据情况增大以下配置:
maxreadEntriesNum=5该配置代表 KoP 每次处理 FETCH 请求最多读取的 Entry 数量,每个 Entry 对应一个 Kafka 生产者发送的 Record Batch。因为 ManagedCursor 目前不支持基于字节的读取,所以会有上述配置。可以增大上述参数来减少网络往返。但参数过大会增加内存压力(Pulsar 使用堆外内存存储读取的消息)。
没有消费指标
2.8 版本开始 KoP 不再支持查看消费指标。因为 KoP 在生产时复用了 Broker 资源的生产者,因此能复用生产端指标;但是 KoP 的 group 并没有复用 Broker 资源的 Subscription,其原因为:
1. 从提交的 Offset 得到待 ACK 的消息 ID 比较耗时;
2. 无法保证 Subscription 所在的 Broker 能够进行 ACK 操作(Kafka 协议中 Coordinator Broker 不一定是 Leader Broker;Pulsar 只有 Topic Owner Broker 才能进行 ACK 操作)。
这里的替代方案是使用 Prometheus。KoP 提供了包括消费端在内的大量 Prometheus 监控指标,可直接用 Grafana 查看,详情参考 文档 [3]。
关闭 Topic 自动删除
Pulsar 默认开启 Topic 自动删除。但 partitioned topic 被自动删除后,KoP 将无法访问它:
Error: NOT_LEADER_OR_FOLLOWER (org.apache.kafka.clients.producer.internals.Sender)原因如下:
• Pulsar 在自动删除 partitioned topic 时,不会删除分区数量这个元数据。
• Kafka 协议在 METADATA 请求获取分区的 Leader Broker 后,直接向其发送 PRODUCE 请求。(而 Pulsar 协议则多了一个对分区创建 Producer 的请求)
解决方法 1:禁止 Topic 自动删除
brokerDeleteInactiveTopicsEnabled=false解决方法 2:启用分区数量自动删除
brokerDeleteInactivePartitionedTopicMetadataEnabled=true如果生产环境中比较依赖 Topic 自动删除,可以选择第二种方法。
KoP 最新技术进展(2022 上半年)
OpenMessaging Benchmark 支持 KoP
OpenMessaging Benchmark 是一个广泛用于衡量不同 MQ 性能的工具。它为每个消息系统提供了:
• Terraform 脚本,自动化向云厂商申请机器。
• Ansible 脚本,自动化部署 MQ、监控、Benchmark 服务以及监控到远程机器。
• Java 编写的 Driver,一键运行 MQ 客户端,可结合 YAML 配置文件灵活定制客户端配置和工作负载。
更多细节可以参考文档[4]。
基于 OpenMessaging Benchmark 测试 KoP,要做两点工作:
• 修改 Pulsar 的 Ansible 部署脚本,添加部署 KoP 的逻辑。
• 使用 Kafka 的 Driver 和配置文件,启动 Kafka 生产者和消费者。
这里的缺点是部署比较麻烦,需要熟悉 Ansible 脚本编写;而且它只支持 Kafka 生产者到 Kafka 消费者的场景。
针对上述问题,KoP 团队新增了针对 KoP 的 Driver[5]。相比直接使用 Kafka Driver,它的优势在于:
• 支持部署 Kafka 和 Pulsar 混合生产消费。
• 配置 Payload Processor 以支持
entryFormat=kafka模式下 Pulsar 客户端消费 Kafka 格式的消息。
- ./bin/benchmark -d driver-kop/kafka_to_pulsar.yaml -o kop.json workloads/1-topic-1-partition-100b.yaml
- ./bin/benchmark -d driver-kop/kafka_to_kafka.yaml -o kop.json workloads/1-topic-1-partition-100b.yaml
- ./bin/benchmark -d driver-kop/pulsar_to_kafka.yaml -o kop.json workloads/1-topic-1-partition-100b.yaml
其中,-d 指定 Driver 配置文件,可定制 MQ 客户端的配置;-o 指定测试结果的输出文件;必选参数为工作负载配置文件。
简化的 Protocol Handler 部署脚本
新脚本[6]基于 Ansible Extra Variables 特性,支持更灵活地定制启用的 Protocol Handler 的版本、配置文件及下载地址;Pulsar 使用的最大堆内存和堆外内存;从本地上传 Pulsar 还是从远程下载 Pulsar 等等。只需加上 -e @extra_vars.yaml 选项指定 Extra Vars 配置文件即可(如 extra_vars.yaml),不需要对 Ansible 脚本做额外修改。
用于监控指标的 ZNode 自动删除
Kafka 消费者加入的 Group 信息位于单独的连接中,Broker 处理 FETCH 请求时无法拿到 Group。KoP 使用 ZK 临时记录 Group 信息,从而能拿到 Group 信息,用于更新消费端监控指标。
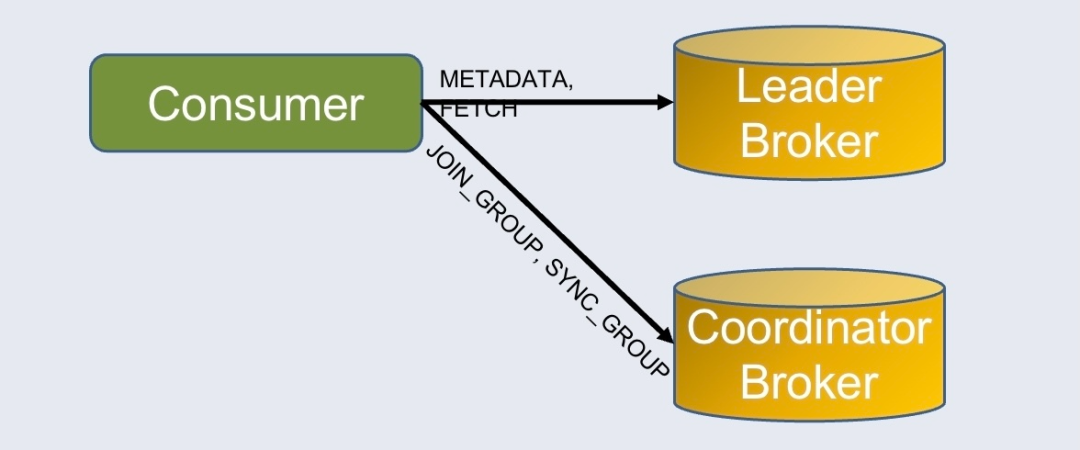
该新特性[7]可以在连接断开时清理所有记录的 ZNode,避免大量 ZNode 手动清理的麻烦。
完善 OAuth 2.0 插件
Kafka 对 OAuth2 认证的支持依赖于单独实现的插件,KoP 和 Pulsar 一样采用了 Client Credentials 的方式:
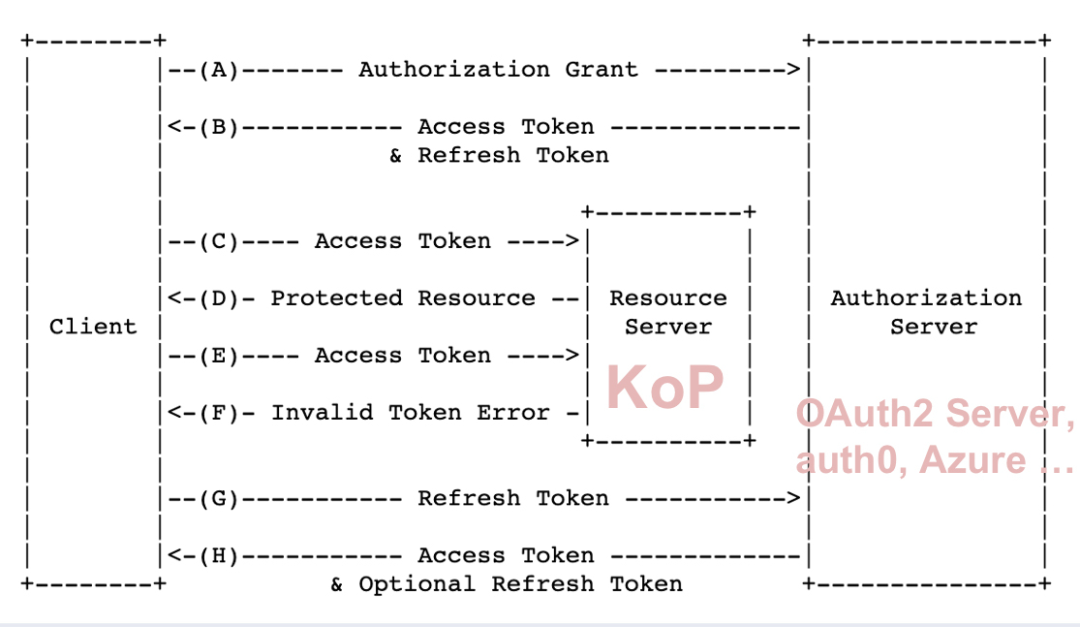
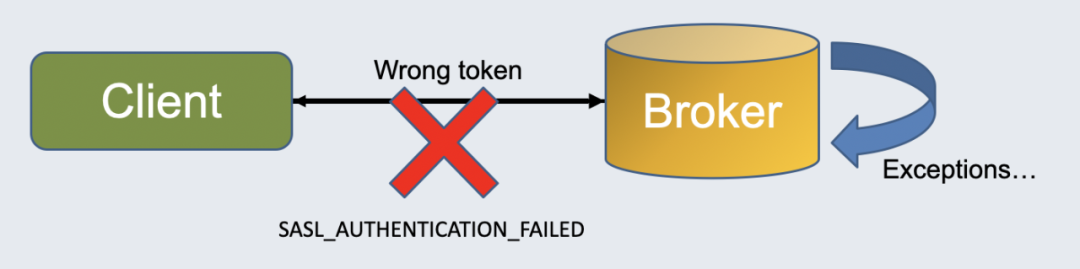
之前的 OAuth2 插件存在很多问题,包括复用 Pulsar 客户端的类,引入了大量 Pulsar 依赖;未验证较复杂场景,如 token 过期等;测试使用了一个真实的 auth0 服务,其对 OAuth 2.0 协议实现不够完善等。
为此引入了 Ory Hydra[8] 这个第三方组件作为 OAuth 2.0 服务器用于测试。它支持 audience、scope 等配置,支持设置 token 过期时间。在此基础上团队重写了 OAuth2 插件,移除了对 Pulsar 客户端的依赖。在服务端也做了一些修复,修复了 OAuth2 认证下授权失败的问题[9],以及异常场景下客户端 token 不刷新的问题[10]。
其他重要进展
Bug 修复
• KoP 2.9 以上版本没有返回正确的 advertised listener:PR 1038[11]
• 空轮询下多分区消费的 race condition 导致问题,导致 PR 复归:PR 973[12]
• 修复开启消息去重后普通消息生产失败问题:PR 1125[13]
新的功能
• 支持启动 KoP 时不初始化元数据,避免一些无谓操作和奇特问题。
• 复用 Pulsar 的消息去重以支持更大的 inflight 消息数量:PR 1006[14]
• Transaction 改为使用 system topic 生成独特的生产者 ID,减轻对 ZooKeeper 的依赖:PR 1125[15]
未来计划
• 对 Schema 的支持
• Kafka 本身不提供 schema 支持,然而 Confluent Schema Registry API 提供了 Kafka Schema 的标准,我们将其视为 Kafka 生态并兼容,目前已合并到分支[16]。由于其依赖于 JDK 11,暂时还未将其添加到过往版本。
• 提供与 Pulsar Schema 兼容的序列化/反序列化器[17],这样 Kafka 客户端可以与 Pulsar Schema 进行交互。
• 从 2022 下半年开始逐步完善 Transaction 功能。
• 针对其他语言(C/C++/Golang/Python)的 OAuth2 认证插件做调研。
• 完成 KoP 性能测试报告。
引用链接
[1] 官网 : https://github.com/streamnative/kop/releases[2] 文档: https://github.com/streamnative/kop/blob/master/docs/security.md[3] 文档 : https://github.com/streamnative/kop/blob/master/docs/reference-metrics.md[4] 文档: https://github.com/openmessaging/benchmark[5] 新增了针对 KoP 的 Driver: https://github.com/openmessaging/benchmark/pull/245[6] 新脚本: https://github.com/streamnative/kop/pull/251[7] 新特性: https://github.com/streamnative/kop/pull/1256[8] Ory Hydra: https://www.ory.sh/docs/hydra[9] 修复了 OAuth2 认证下授权失败的问题: https://github.com/streamnative/kop/pull/1230[10] 异常场景下客户端 token 不刷新的问题: https://github.com/streamnative/kop/pull/1276[11] PR 1038: https://github.com/streamnative/kop/pull/1038[12] PR 973: https://github.com/streamnative/kop/pull/973[13] PR 1125: https://github.com/streamnative/kop/pull/1125[14] PR 1006: https://github.com/streamnative/kop/pull/1006[15] PR 1125: https://github.com/streamnative/kop/pull/1125[16] 分支: https://github.com/streamnative/kop/pull/1313[17] Pulsar Schema 兼容的序列化/反序列化器: https://github.com/streamnative/kop/pull/1290
▼ 关注「Apache Pulsar」,获取干货与动态 ▼
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

