
- 1深度学习中的超参管理方法:argparse模块
- 2【论文阅读】A Survey of Challenges and Opportunities in Sensing and Analytics for Risk Factors of Cardiova_a survey of digital twin: integration, challenges
- 3案例23 图书管理系统的设计与实现_图书管理系统设计
- 4Gradle kts配置_android kts中,lint配置
- 5计算机SCI/EI期刊投稿经验_acm tomm期刊属于几区
- 6【JavaScript】深入理解Promise:从基础概念到进阶用法、手写promise_js promise 用法
- 7二叉树画图与求时间复杂度_二叉树插入的空间复杂度和时间复杂度计算
- 8OpenWrt 防火墙配置 /etc/config/firewall_openwrt firewall
- 9git官方文档中文版
- 10Python 文件操作详解_python写文件的操作方法
NLP论文阅读记录 - | 使用GPT对大型文档集合进行抽象总结_abstractivesummarization oflargedocumentcollection
赞
踩
前言

ABSTRACTIVE SUMMARIZATION OF LARGE DOCUMENT COLLECTIONS USING GPT(2306)
- 1
no code
paper
0、论文摘要
本文提出了一种抽象摘要方法,旨在扩展到文档集合而不是单个文档。我们的方法结合了语义聚类、主题集群内的文档大小缩减、集群文档的语义分块、基于 GPT 的摘要和串联以及每个主题的组合情感和文本可视化,以支持探索性数据分析。
使用 ROGUE 汇总分数将我们的结果与现有最先进系统 BART、BRIO、PEGASUS 和 MoCa 进行统计比较,结果显示,BART 和 PEGASUS 在 CNN/Daily Mail 测试数据集上以及 BART 在 Gigaword 上的性能在统计上相当测试数据集。
这一发现很有希望,因为我们认为文档集合摘要比单个文档摘要更具挑战性。最后,我们讨论了如何在 GPT 大语言模型中解决规模问题,然后提出未来工作的潜在领域。
一、Introduction
对变压器注意力机制和大语言模型(LLM)的研究已经产生了令人印象深刻的成果,特别是在自然语言处理(NLP)和文本分析方面。法学硕士,如 BERT Kenton 等人。 [2019],BART Lewis 等人。 [2020],GPT Radford 等人。 [2018]、Bard Manyaka [2023] 和 LLaMA Meta AI [2023] 已经产生了重要的研究和公众影响。尽管它们具有最先进的性能,但广泛、通用用途的目标使得某些任务仅得到部分解决。本文重点研究多文档集合的抽象概括。像 GPT 这样的系统可以执行抽象摘要,但目前仅限于 512 到 4,096 个术语的最大输入。文档集合可以轻松地由数百个包含数千个术语的文档组成。需要一种智能方法来管理规模,以利用法学硕士的抽象总结能力。我们还建议应用情感分析和可视化来增强摘要,并以交互式且易于理解的视觉格式呈现附加属性。我们的方法执行以下步骤,将 GPT 的抽象摘要方法扩展到大型文档集合。
- 应用 Facebook AI 相似性搜索 Johnson 等人。 [2021](FAISS)基于文档对的语义相似性来估计文档相似性。
- 使用 Noise Malzer 和 Baum [2020] (HDBSCAN) 执行基于分层密度的空间聚类和应用,使用 FAISS 结果生成语义主题聚类。
- 识别主题代表性术语并为每个集群构建代表性术语集的集合,其中每个集合包含一个代表性术语以及父集群中所有语义相似的术语 Nagwani [2015]。
- 通过根据语义内容中的变化点将包含代表性术语的簇中的句子组合成语义块,使用代表性术语集进一步减小主题簇大小。
5.使用 GPT 的摘要 API 来摘要每个语义块,然后使用其串联 API 将语义块摘要组合成原始文档集合的抽象摘要。 - 对每个语义块执行基于术语的情感分析,以生成效价(愉悦)和唤醒分数。
- 在仪表板中可视化语义块,允许以不同的细节级别交互式探索摘要的情绪及其文本。
将我们的摘要与使用 ROGUE 指标的当前最先进方法进行比较表明,我们在多文档集合和单个文档摘要对上实现了可比的性能。这表明我们的方法可以有效地扩展以总结超出现有系统范围的更大文档或文档集合。
二.相关工作
文本摘要一般分为两大类:抽取式摘要和抽象式摘要。最近的几篇调查论文详细讨论了这一主题 Cao [2022]、Gupta 和 Gupta [2019]、Lin 和 Ng [2019]、Noratanch 和 Chitrakala [2016]、Zhang 等人。 [2022a]。
2.1Summarization
提取式摘要从原始文档中逐字提取代表性文本,并将其组织成连贯的摘要。常见的方法包括关键字提取,使用权重方案根据关键字捕获文档内容的程度(例如,术语频率 - 逆文档频率)对关键字进行排名,或使用权重对句子进行排名和句子之间的相似性度量进行句子提取,以避免包含冗余文本。
抽象摘要尝试构建独特的文本摘要,而不逐字使用文档中的文本。这类似于人类读者构建摘要的方式。 Lin 和 Ng 将其描述为信息提取、内容选择和表面实现的三步过程 Lin 和 Ng [2019]。
• 信息提取。从文档中提取有意义的信息,例如名词和动词短语以及上下文、形成主语-动词-宾语三元组的信息项或不同主题的动词-宾语抽象模式。
• 内容选择。选择要包含在摘要中的候选短语子集。启发式方法和整数线性规划(ILP)已被提出来将摘要任务构造为约束优化问题。 ILP 的优点是短语选择是在所有候选者中联合执行的,而不是按顺序执行的。
• 表面实现。使用语法和句法规则组合候选短语以生成连贯的摘要。
Gupta 和 Gupta Gupta 和 Gupta [2019] 提出将抽象摘要分为结构摘要、语义摘要和基于神经网络的摘要。结构方法识别文本中的相关信息,以创建用于生成抽象摘要的预定义结构。语义方法将文本转换为语义表示,用作自然语言生成 (NLG) 系统的输入以创建抽象摘要。神经网络技术使用深度神经网络来训练使用文本摘要对的模型。然后应用该模型来生成未标记文本的抽象摘要。
基于结构的方法使用树、模板、本体、图形和规则将文本转换为抽象摘要。 Barzilay 和 McKeown Barzilay 和 McKeown [2005] 应用内容主题方法来转换常见短语
进入依赖树。依存树添加了额外的相关信息,以创建一组子树,用作 NLG 系统的输入,将它们组织成新颖的句子并生成抽象摘要。或者,构建词图来表示文档中的术语关系,然后进行分析以构建抽象摘要 Lloret 和 Palomar [2011]。迈赫达德等人。定位词图中的最短路径来识别相关句子并删除冗余信息,然后融合剩余句子以生成抽象摘要 Mehdad 等人。 [2013]。
语义方法构建文档文本的语义表示,例如谓词-论元结构(句子的动词、主语和宾语)或语义图。这些被用作 NLG 系统的输入,该系统将语义表示转换为抽象摘要。 Moawad 和 Aref 构建了丰富的语义图,其中名词和动词代表节点,语义关系代表边 Moawad 和 Aref [2012]。该图使用启发式规则进行简化,然后输入 NLG 系统。在 NLG 解析 Munot 和 Govilkar [2015] 之前,Munot 和 Govilkar 使用领域本体来连接句子之间的概念。类似的方法已用于抽象意义表示图:句子及其语义关系的有向无环图 Liu 等人。 [2015]。
2.2 神经网络抽象概括
最新最先进的抽象摘要器使用深度神经网络来训练基于文本摘要对的模型。最初的工作使用循环神经网络(RNN)来生成 Buys 和 Blunsom [2017] 的摘要。最近的方法使用基于转换的注意力模型。这两种方法都是基于编码器-解码器策略构建的。编码器将术语转换为向量表示,通常是词嵌入。解码器尝试根据迄今为止的先前单词确定输出中的下一个单词。训练编码器-解码器通常称为 seq2seq 学习问题。注意力允许根据在训练过程的当前阶段关注哪里获得最大收益,优先从编码器中提取信息。 RNN 抽象概括器的例子有很多。拉什等人。构建一个由基于注意力的编码器和波束搜索解码器组成的前馈神经网络,用于句子级摘要 Chopra 等人。 [2016],拉什等人。 [2015]。波束搜索在传统的贪婪搜索的基础上进行了扩展,它在每个解码步骤中选择 k 个最佳候选者,并在看到序列结束标记时修剪它们。纳拉帕蒂等人。使用 RNN 处理词嵌入并生成摘要来解决关键字建模和稀有词包含等问题 Nallapati 等人。 [2016]。
最近的工作涉及大型语言模型 (LLM),例如 GPT、Bard Manyaka [2023] 和 LLaMA Meta AI [2023]。 GPT-3(生成式预训练 Transformer 3)建立在具有 1750 亿个参数的训练集上 Brown 等人。 [2020]。 GPT-3采用元学习方法:在训练过程中构建一个具有广泛通用技能和模式识别能力的模型,然后在任务完成过程中最多用几个例子来推断结果,而无需调整模型的任何内部权重。 GPT-3 在零样本(无任务示例)、单样本(1 个任务示例)和少样本(10-100 个任务示例)上下文中展示了与微调模型相媲美的性能。任务包括句子完成、故事结局选择、回答问题、语言翻译、代词参考、常识推理、数学推理和阅读理解。 Meta 的 LLaMA(大型语言模型 Meta AI)使用了另一种方法,认为性能不仅取决于参数大小,还取决于执行的训练量。 [2023]。图夫龙等人。提出虽然较大的模型训练成本可能较低,但训练时间较长的较小模型在用于执行 NLP 任务时推理效率会更高。 LLaMA 的评估方法是在不同大小的输入上对其进行训练,执行简短的微调步骤,然后使用 0、1、5 和 64- 对其进行问答、常识推理、数学推理、代码生成和阅读理解进行测试。拍摄上下文。训练集包含 7、13、33 和 650 亿个模型,两个较小模型集使用 1 万亿个令牌进行训练,两个较大模型集使用 1.4 万亿个令牌进行训练。任务性能显示 LLaMA 在大多数基准测试中都优于 GPT-3。
2.2.1训练和测试数据集。
存在许多包含文本和相应摘要的数据集用于训练和测试。最常见的数据集之一是由美国国家标准与技术研究院 (NIST) 管理的文档理解会议 (DUC) 数据集 [2011]。 DUC 数据集分析是 NIST 年度文本分析会议的一个议题。每个 DUC 条目都包含新闻文档和三个真实摘要:(1) 手动生成,(2) 作为基线自动生成,以及 (3) 由现有系统自动生成。 CNN/每日邮报数据集包含报纸文章的文档摘要对和相应的摘要:286,817 个训练对、13,368 个验证对和 11,487 个测试对参见[2023]。 Gigaword 数据集包含大约 380 万个英文新闻文章训练对、189,000 个验证对和 2,000 个测试对 Microsoft [2023]。尽管足以训练神经网络模型,但训练对使用文档的第一句作为其摘要基础事实。最后,NYT 数据集包含来自《纽约时报》的预处理文章:大约 650,000 个手动生成的文章-摘要对,文章限制为 800 个标记,摘要限制为 100 个标记 Sandhaus [2008]。
2.2.2 评估。
一旦构建了候选抽象摘要,就必须将其与参考“基本事实”摘要进行比较,以评估其质量。尽管存在多种评估指标,包括 BLEU、METEOR 和 ROUGE,但 ROUGE(Recall-Oriented Understudy for Gisting Information)的变体是最常见的评估方法:用于一元语法的 ROUGE-1、用于二元语法的 ROUGE-2 以及用于二元语法的 ROUGE-L。最长公共子序列 Lin [2004]。 ROUGE 的评估基于字符重叠,而不是语义内容。 ROUGE返回recall:候选摘要捕获的参考摘要中单词的比例;精度:候选摘要中的单词出现在参考摘要中的比例。
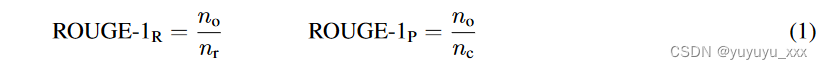
其中 nc 是候选标记的数量,nr 是参考标记的数量,no 是参考摘要中包含(即重叠)的候选标记的数量。考虑参考摘要“约翰真的很喜欢数据科学”和候选摘要“约翰喜欢数据科学”。这里 nr = 5,nc = 4,no = 4,因此召回率是 ROUGE-1R = 4 5 = 0.8,精度是 ROUGE-1P = 4 4 = 1.0。 ROUGE-2 使用相同的召回率和精确率公式,但适用于二元组而不是一元组。对于相同的候选和参考句子nr = 4:{(John,really),(really,loves),(loves,data),(data,science)}; nc = 3:{(John,loves),(loves,data),(data,science)} and no = 2:{(loves,data),(data,science)},产生ROUGE-2R的召回率和精度= 2 4 = 0.5 和 ROUGE-2P = 2 3 = 0.67。 ROUGE-L 以相同顺序标识令牌的最长公共子序列 nL,但不一定是连续的。例如,候选句子“John 真的很喜欢数据科学并且广泛研究它”和参考句子“John 非常喜欢数据科学并且喜欢它很多”产生 nL = 6,生成的召回率和精度为 ROUGE-LR = 6 11 = 0.55 和 ROUGE-LP = 6 9 = 0.67。
2.3 最先进的抽象摘要器
Papers With Code 维护着一份在 CNN/Daily Mail 数据集1上测试过的最先进的抽象摘要器列表。目前,排名前四的系统分别是 BART、BRIO、PEGASUS 和 MoCa 版本。由于我们针对这些方法测试了我们的方法,因此我们提供了每个系统的简要概述。 BART 是一种“去噪”转换器模型,经过训练,可以使用目标句子的各种排列(例如术语屏蔽、删除或排列)将噪声或损坏的文本转换为去噪、未损坏的文本。 [2020]。然后,BART 的初始语言理解模型经过微调,可以执行抽象摘要等 NLP 任务。 BRIO 将摘要生成过程分为两个阶段:使用交叉熵损失生成和使用对比损失评估 Liu et al. [2022]。结合这些指标可以平衡训练期间最新摘要的概率,即使最大似然估计(摘要生成期间的标准评分方法)不会推荐它们,也能生成高质量的摘要。 PEGASUS 的扩展称为序列似然校准 (SLiC),它使用模型潜在空间中的参考序列来校准模型生成的序列。校准是指比较不同潜在摘要的质量的能力。作者建议在 seq2seq 过程的解码阶段使用模型的潜在状态将候选序列似然与目标序列对齐,而不是应用启发式方法来执行此操作。 MoCa 解决了推理过程中的暴露偏差问题(即训练者在搜索过程中只能访问之前预测的标记,而不能访问真实标记)。 [2022b]。为了纠正这个问题,MoCa 使用生成器模型和在线模型的组合来缓慢演化样本,使用排名损失将生成器模型分数与在线模型分数对齐。这是通过使用基于反向传播期间排名损失的动量系数修改生成器的参数来完成的。
三.本文方法
尽管像 GPT 这样的 LLM 可以执行少样本抽象摘要,但它们支持的输入大小受到限制。 GPT 目前的最大令牌数为 4,096,对于中等大小的文档或文档集合来说这也太小了。因此,问题就变成了:我们如何扩展法学硕士来执行抽象总结?一个明显的方法是智能地将集合压缩到法学硕士的大小限制。这将我们的目标从抽象摘要转变为摘要之前的智能文档压缩。理想情况下,我们希望从集合中识别、提取和压缩最具语义意义的信息。这解释了对大型文档集合进行提取摘要和抽象摘要的标准建议。尽管现有的提取摘要技术可以产生可接受的结果,但这将抽象摘要器简化为语言重写器。断断续续且经常不连续的提取句子被转换为语法和句法正确的摘要,更像是人类作家会产生的内容。然而,要点是,如果一个概念未包含在提取摘要中,则它永远不会出现在摘要摘要中。因此,生产最好的提取成分或总结成分至关重要。
总的来说,我们提出的模型的主要目标是:
(1)克服抽象摘要任务的 GPT 术语限制;
(2)为大型文档集合创建端到端的抽象摘要生成和可视化管道。
与产生一组句子的传统提取摘要方法不同,我们提出将文档集合细分为语义主题簇,从每个簇中提取代表术语,将句子细分为语义块,抽象总结每个语义块,然后连接这些块以生成最终的抽象摘要。
这种方法具有许多新颖的优点:
(1)通过将文档集合细分为语义相似的集群来提高扩展性;
(2)在语义块级别而不是句子级别进行操作;
(3) 尝试识别集合中语义上最有意义的信息。
一旦生成抽象摘要,情感分析就可以通过估计的情感影响来增强它,并通过可视化呈现。情感分析提出了独特的挑战,特别是如何在多句子文本块上聚合情感并以最佳方式直观地表示情感及其相关属性。
我们的方法概述如下。
给定一个文档集合,我们首先对该集合执行文本聚类和主题建模。
然后,我们识别主题代表性术语并为每个集群构建代表性术语集,其中包含代表性术语和父集群中所有语义相似的术语。
为了进一步减少主题簇的大小,我们根据内容的变化点将每个簇中包含代表性术语的句子划分为语义块。
我们利用 GPT 的摘要 API 来摘要每个语义块,并使用其串联 API 将语义块摘要组合成原始文档集合的抽象摘要。最后,我们估计情绪并使用交互式可视化仪表板呈现摘要及其情绪。
我们使用从 CNN/Daily Mail 和 Gigaword 数据集收集的 5 个包含 100 个文档的集合来演示我们的框架。这些藏品涵盖巴拉克·奥巴马、大学研究、野生动物保护、股票市场和篮球等主题。我们将我们的结果与当前最先进的抽象概括器进行比较,以测试我们的框架。
3.1 查询支持
如果需要,可以在我们的抽象摘要管道之前执行查询支持。在这里,我们检索文档集合 D 中与用户查询 q 相似度最高的文档 di,1 ≤ i ≤ nD。我们采用文本编码器 E,将其输入映射到 LLM 中的最终隐藏层。 E 应用于 D 和 q 中的所有文档,产生 Edi 、 1 ≤ i ≤ nD 和 Eq。我们使用 Facebook 的 FAISS 库来索引所有 di。这使我们能够以计算有效的方式查询与 q 的 u 最近匹配,生成原始 D 的子集 D′,D′ = {d′1,d′2,…。 。 。 d′u}。 D’ 取代 D 作为文档聚类阶段的输入。
3.2 文档聚类
我们对 D(原始文档集合或用户查询的结果)应用文档聚类,将 D 细分为更细粒度的主题集。我们使用文本编码器 E 的输出以及 UMAP(统一流形逼近和投影)来执行投影,使我们能够在较低维度(如平面 (2D) 或体积 (3D))中进行聚类 McInnes 等人。 [2018]。有多种降维方法可供使用,包括 PCA(主成分分析)和 t-SNE(t 分布随机邻域嵌入)Hervé 和 Williams [2010]、van der Maaten 和 Hinton [2008]。我们选择 UMAP 是因为它的非线性和无监督性质以及有效管理大型文本数据集、保留其局部和全局结构的能力。投影之后,我们应用 HDBSCAN 生成主题集群 Campello 等人。 [2013]。 HDBSCAN根据局部邻居距离将点转换为低密度和高密度空间区域,在得到的距离加权图上构建最小生成树,根据最小簇大小构造和压缩簇层次结构,然后从其中提取稳定簇浓缩树。结果是一组 C,由 nC 个簇 Cj ∈ C,1 ≤ j ≤ nC 组成,它们不受特定形状或大小的限制,以及不属于任何簇的“离群值”或噪声文档。
3.3主题句提取
为了识别基于概念的主题关键字,潜在狄利克雷分配(LDA)被应用于每个集群中的文档集 Blei 等人。 [2003]。 LDA 将基于词袋的术语文档矩阵转换为概念文档矩阵,其中每个文档 di ∈ Cj 从加权术语频率向量转换为概念向量,表示 di 包含的集群 Cj 中每个潜在概念的数量。 LDA 的第一步是将 nCj 概念识别为 Cj 中包含的独特术语的加权组合。 nCj 必须在运行 LDA 之前定义,并且它本身就是一个悬而未决的问题。给定 nCj ,假设狄利克雷分布形成文档概念混合和术语主题分配的条件概率。这用于生成文档概念矩阵和概念术语矩阵。概念术语矩阵定义了每个 nCj 概念的 Cj 中所有唯一术语的权重。该术语列表通常被截断以包含顶部 tCj 术语或权重超过预定义阈值 εCj 的术语。现在,每个 di ∈ Cj 都由每个 nCj 概念的数量来表示di 包含。这允许通过概念重叠来定义相似性,这是一种比加权术语重叠更具语义的方法。我们使用概念术语矩阵来构建主题术语 TCj 的集合。 TCj 是 Cj 概念的一组术语,这些术语在所有概念中出现频率高于阈值。 TCj 使用 WordNet 进行扩展,为每个主题术语添加同义词。我们从每个 di ∈ Cj 中提取包含一个或多个主题术语的所有句子,生成主题句子列表 SenCj = {sen1,j, sen2,j, …。 。 .}。
3.4 语义分块
由于 SenCj 中的句子数量可能仍然很大,因此我们将句子 seni,j ∈ SenCj 分割为语义块 KCj = {k1,j, k2,j,…。 。 .}。为此,我们获得每个 seni,j 的 SentenceBERT Reimers 和 Gurevych [2019] 嵌入,并使用它们构建相似性矩阵 ∼ SenCj 。为了自动识别句子之间的分块点,我们将 ∼ SenCj 中的两个相邻对角线直接放在主对角线的右侧,并构建一个两列矩阵 Polovinkin [2022]。这些列表示所有相邻句子对之间的相似性得分。为了更好地捕捉相似性的差异,我们使用基于反向 sigmoid 函数的激活权重 w 放大某些句子的相似性分数并抑制其他句子的相似性分数。
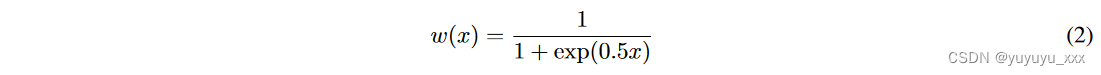
其中 x 是每个矩阵单元中的相似度得分。将每行中的加权相似度相加,以计算相邻句子对之间的相似度。接下来,识别相对最小值:加权和列表中相似性分数先减小后增加的位置。相对最小值表示语义块之间的划分。
3.5 GPT 零样本总结
给定每个块 ki,j ∈ KCj ,我们通过 GPT 的完成 API 运行摘要管道

这会生成每个块的摘要。虽然我们在分析和测试过程中没有遇到这种情况,但 ki,j 有可能超过 GPT 的最大令牌数。如果发生这种情况,ki,j 会进一步细分为两部分。这是在 ki,j 中的内部句子中完成的,该内部句子根据加权语义句子相似度 simi,j 与其邻居产生最大的绝对差异。假设 ki,j 跨越句子 ki,j = (seni,u, Seni,u+1, . . .seni,v),则分割点 sp 出现如下。

生成跨越原始 ki 的两个语义块 k′ i,sp = (seni,u, . . .seni,sp) 和 k′ i,sp+1 = (seni,sp+1, . . .seni,v) ,j。根据需要,可以对 k’ sp 和 k’ sp+1 进行相同的细分。一旦每个语义块满足最大术语限制约束,则 sumi,j 被组合并总结。

这产生了集群 Cj 的最终抽象摘要。我们对 D 中的所有簇重复相同的过程,为文档集合中的每个簇构建摘要。最后,我们再次使用 GPT 组合集群摘要。
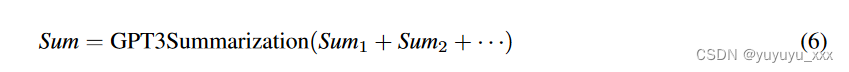
四 实验效果
我们通过将我们提出的抽象概括框架与现有的最先进技术进行比较来评估它:BART、BRIO、PEGASUS 和 MoCa。我们的目的是研究我们提出的框架是否可以保持与竞争系统相当的零样本性能,同时处理大型多文档集合。我们使用 ROGUE-1、ROGUE-2 和 ROGUE-L 分数来衡量摘要质量。
4.1数据集
我们使用 CNN/Daily Mail 和 Hugging Face 库中的 Gigaword 数据集进行了实验。 CNN/每日邮报数据集中的每个条目都包含文档 ID、报纸文章的文本和相应的摘要(或亮点,如数据集中所引用的那样)。 Gigaword 数据集包括英文新闻文章的文本和相应的摘要。 CNN/每日邮报数据集包含 286,817 个训练对、13,368 个验证对和 11,487 个测试对。 Gigaword 数据集包含大约 380 万个训练对、189,000 个验证对和 2,000 个文本对。
我们通过评估其在没有任何事先训练的情况下在测试集上执行摘要任务的能力来评估抽象摘要框架的零样本性能。考虑到每篇文章的长度较短,我们将文档集合 D 的大小增加到 nD = 100 个文档。对于我们的系统,我们必须预先定义 HDBSCAN 创建的主题集群 nC 的数量。我们选择 nC = 10 以确保语义块满足 GPT-3 的最大令牌限制。我们还选择 GPT 超参数温度 = 0.3 设置输出中的随机性以支持出现概率较高的术语,topp = 0.9 选择累积概率超过 0.9 的最小术语集合,频率和存在惩罚为 0 以降低可能性重复文本,并使用 davinici-003 模型“与 davinici-0022 相比,通过更好的长格式生成来生成更高质量的写作。”
4.2 对比模型
我们将我们的结果与四个最先进的摘要摘要器进行了比较:BART、BRIO、PEGASUS 和 MoCa。所有四个系统都旨在总结满足 GPT-3 代币最大值限制的单个文档。这些系统都不是专门为总结文档集合而构建的。因此,我们确保选择长度等于或低于 GPT-3 限制的文档。这些文档平均约有 500 个术语。
由于我们正在为我们的系统生成多文档摘要,因此我们首先需要定义一个用于比较的真实摘要。这是通过从测试数据集中获取集群中每个文档的单独真实摘要并将它们连接起来来完成的。将主题簇的抽象摘要与串联的真实摘要进行比较。对每个主题簇的 ROGUE 分数进行平均,以生成我们方法的总体 ROGUE 分数。
4.3实施细节
我们对 CNN/Daily Mail 和 Gigaword 数据集进行了五个查询(Barack Obama、大学研究、野生动物保护、股票市场和篮球),每个查询提取 100 个文档。我们将我们的系统应用于每个查询的 100 个文档:HDBSCAN 用于生成主题簇,LDA 识别每个簇的 10 个概念,构建主题集来识别包含主题术语的句子,相邻句子相似度用于定位分隔语义块的相对最小值,每个语义块使用 GPT-3 进行总结,块摘要与 GPT-3 连接起来生成主题摘要,主题摘要本身连接起来生成原始 100 个文档的最终抽象摘要。查询示例、从查询返回的文档生成的 LDA 主题以及我们根据各个主题摘要构建的最终抽象摘要如表 2 所示。将主题摘要与我们构建的真实摘要进行比较以计算 ROGUE 分数。然后对主题簇 ROGUE 分数进行平均,为我们的抽象概括方法生成最终 ROGUE 分数。
4.4评估指标
我们将我们的系统生成的五个抽象摘要的 ROUGE-1、ROUGE-2 和 ROUGE-L 指标与竞争方法的 ROGUE 结果进行了比较。表 3 中竞争系统的分数直接取自其论文报告的结果。我们的系统为 CNN/Daily Mail 数据集生成了最高的 ROGUE 分数,MoCa 报告了 Gigaword 数据集的最高 ROGUE 分数。然而,我们的 Gigaword 分数与所有四个系统相当。这是有希望的,因为我们正在生成多文档摘要,而其他系统则生成单文档摘要。我们还想与 GPT 进行比较,因为它能够进行多文档抽象摘要。不幸的是,我们无法找到报告的 ROGUE 分数进行抽象总结。我们考虑直接测试 GPT,但 GPT-3 和 GPT-4 的输入项限制分别为 4,096 和 8,192,小于我们最小集群的大小。 GPT-4 的 Beta 版本声称将此限制增加到 32,767 个术语,但根据我们的测试,GPT-4 和 GPT-4 Beta API 在特殊情况使用之外均不可用,我们无法确保特殊情况的使用。
4.5 实验结果
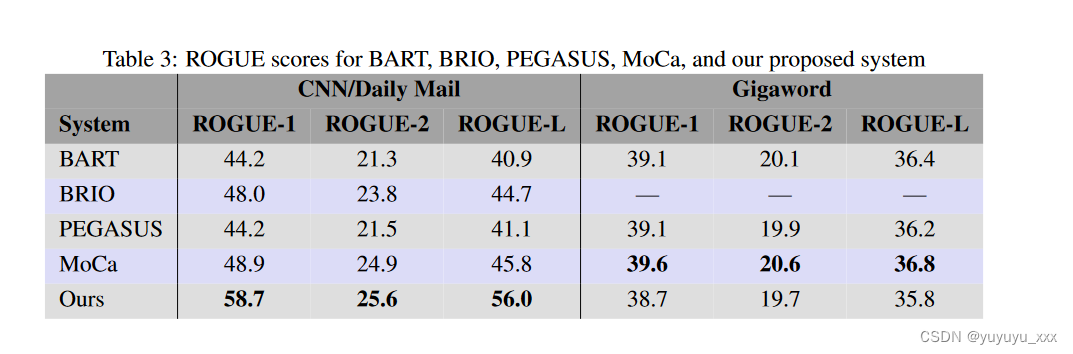
为了寻找统计性能差异,我们在五个查询生成的文档集上运行竞争系统和我们的系统,然后对每个 ROGUE 类型和摘要系统的各个 ROGUE 分数进行方差分析 (ANOVA)。对每个系统执行以下步骤来计算总体 ROGUE 分数。
- 要求给定系统(例如 BART)为输入文档提供抽象摘要 SumBART。
- 与测试数据集中提供的真实摘要相比,计算 SumBART 的 ROGUE-1、ROGUE-2 和 ROGUE-L 分数。
- 对 ROGUE-1、ROGUE-2 和 ROGUE-L 分数进行平均,以生成给定系统的总体 ROGUE 分数。
由于汇总系统之间的方差并不相等,因此我们应用了非参数 Kruskal-Wallis 方差分析。除 MoCa 之外的所有系统都在 Hugging Face 变压器模型存储库中提供实现3。因此,MoCa 被排除在我们的统计分析之外。此外,BRIO 的实现并未针对 Gigaword 数据集中的短文档进行调整,因此它没有包含在任何涉及 Gigaword 比较的方差分析中。对于 α = 95% 的显着性率,CNN/Daily Mail 和 Gigaword ROGUE-1、ROGUE-2 和 ROGUE-L 分数的 F 结果如表 4 所示。
方差分析结果证实,所有 ROGUE 分数在数据集和技术上均存在显着差异。邓恩的事后分析是为了寻找绩效上的成对差异。以下对被确定为没有显着差异。 • CNN/《每日邮报》,ROGUE-1,我们的–PEGASUS,p = 0.12 • CNN/《每日邮报》,ROGUE-2,我们的–BART,p = 0.31 • CNN/每日邮报,ROGUE-2,我们的–PEGASUS,p = 0.31 0.14 • CNN/每日邮报,ROGUE-L,我们的 – BART,p = 0.11 • CNN/每日邮报,ROGUE-L,我们的 – PEGASUS,p = 0.11 • Gigaword,ROGUE-2,我们的 – BART,p = 0.10 Dunn成对结果表明,对于 CNN/Daily Mail 数据集上除其中一个 ROGUE 分数之外的所有 ROGUE 分数,我们的方法在统计上与 PEGASUS 和 BART 等效,并且对于 Gigaword 数据集上的 ROGUE-2 分数与 BART 等效。这是一个积极的迹象,表明我们的技术可扩展到多文档集合,现有系统要么难以处理,要么由于最大输入项限制而无法处理。最后,我们注意到表 3 和表 4 中 Gigaword 数据集的结果主要归因于 Gigaword 提供的摘要类型以及我们对 GPT 的使用。 GPT 旨在返回包含完整、语法正确的句子的摘要。 Gigaword 的摘要通常是文本片段,因此与 GPT 的摘要的对应程度不如 CNN/每日邮报数据集中包含的摘要。例如,Gigaword 的测试数据集包含文本摘要条目,例如“UNK – 俄罗斯自由党赢得辞职”或“兰特兑美元汇率在周三开盘时上涨,至 #.#### ## 兑美元汇率从 # .#### ## 周二收盘时,兰特上涨”。第一个示例不包含原始文本,将其报告为 UNK 或未知。第二个示例使用占位符表示数值,并使用简短的文本片段而不是完整的句子作为基本事实摘要。在这两种情况下,GPT 以及我们的系统都很难生成可比较的摘要。我们避免在正文或摘要中包含 UNK 条目。我们没有删除摘要不完整或语法不正确的对,因为我们想诚实地表示我们的系统在这些类型的数据集上的执行情况。
五 总结
我们在本文中的目标是一种可以扩展以对多文档集合执行抽象摘要的技术。我们使用 FAISS 和 HDBSCAN 将文档划分为语义主题簇。为每个簇生成代表性术语集,然后用于将簇大小缩小为语义块。应用 GPT 来总结每个块,然后将这些摘要连接成每个主题的抽象摘要。相同的串联操作将主题摘要组合成总体文档集合摘要。对句子、语义块和主题摘要进行情感分析,然后使用交互式仪表板进行可视化,使用户能够在多个细节级别探索效价、唤醒度以及原始和摘要文本。
对我们的系统和竞争方法(包括 BART、BRIO 和 PEGASUS)的 ROGUE 分数进行统计分析,证实了我们的多文档摘要与现有方法的单个文档结果的性能相当。与现有系统相比,我们具有以下优势。 1. 与单个文档相比,能够扩展到多文档集合。
2. 使用语义聚类来识别主题,以提供文档集合内容的多个详细级别。
3. 基于感知的交互式可视化仪表板,旨在以不同的细节级别呈现文本情感、文本摘要和原始文本。
4. 利用和扩展大型语言模型的能力进行抽象概括。
5. 新技术的未来集成,例如,新的大型语言模型、抽象摘要算法或评估方法,因为我们的方法可以快速推广到任何这些变化,因此它们变得可用。
在未来的工作方面,我们目前正在研究对我们系统的三项潜在改进。
- 流媒体。扩展我们的系统以支持实时流,使其能够动态添加或删除文档集合中的文档。这会影响主题聚类,因为我们假设主题会随着时间的推移而变化。存在实时聚类算法,例如实时指数过滤聚类(RTEFC)和实时移动平均聚类(RTMAC)。一种可能更相关的方法是针对实时流数据的基于密度的聚类 Chen 和 Tu [2007]。另一种可能性是跟踪当前聚类结果中的估计误差,并在超过阈值误差时执行更新的聚类,类似于我们在流文档环境 Venkatesh [2010] 中维护准确的 TF-IDF 分数的方式。一旦定义了集群,后续的语义分块、块、主题和文档集合摘要以及可视化将像在当前系统中一样执行。
- 可视化。改进可视化仪表板以支持更复杂的可视化分析。扩展可视化仪表板以支持额外的探索性分析,特别是在不同的细节级别,是一个潜在的兴趣领域。我们当前的重点是一个类似于我们为在客户聊天会话期间探索主题及其相关情绪模式而构建的系统。 [2021]。该系统专门设计用于以多个详细程度呈现相关信息。
- 替代法学硕士。探索 Bard、BLOOM Le Scao 等其他法学硕士的优势和局限性。 [2023] 和 LLaMA 提供抽象摘要和文本连接功能。我们计划调查这些和类似的法学硕士,以确定它们对于我们的总结流程是否有任何特定的优势或局限性。

