
- 1华为OD算法题汇总_华为od 算法题库
- 2C语言实现单向链表_c语言单向链表
- 3Python爬虫教程,从入门到成神
- 4DecSoft HTML编译器2020版更便捷
- 5【AI工具】openai-translator 可使用谷歌Generative Language API 翻译工具
- 6网络安全最新Hvv面试题(2024)_2024hvv_奇安信2024hvv初筛题库
- 7网络安全系统教程+渗透测试+学习路线(自学笔记)_渗透学习笔记
- 8用python对文心一言进行交互_python调用文心一言
- 9Gradle 插件练习-动态移除权限,腾讯安卓面经_gradle 移除清单文件里权限
- 10挑战性能极限小显卡大作为,教你如何在有限资源下运行大型深度学习模型,GPU显存估算并高效利用全攻略!_大模型微调 显存评估
Elasticsearch(二)——Es 数据存储细节(动态映射、静态映射、类型推断)、核心类型、二十三种映射参数、官方文档地址_es静态映射
赞
踩
Elasticsearch(二)——Es 数据存储细节(动态映射、静态映射、类型推断)、核心类型、二十三种映射参数、官方文档地址
一、Es 数据存储细节
虽然 Es 是 NoSQL ,但是底层也是有数据类型的。
1、动态映射
底层会自动的根据存入的数据判断数据类型,这种自动分析就叫动态映射。
我们可以先创建一个索引,在创建好的索引信息中,可以看到,mappings 为空,这个 mappings 中保存的就是映射信息。
接着存入下面这么个数据:
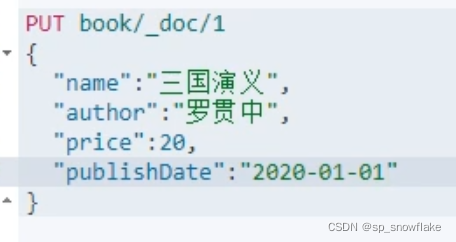
然后查看索引信息:
然后查看 mappings,mappings 里面就是定义数据的详细信息:
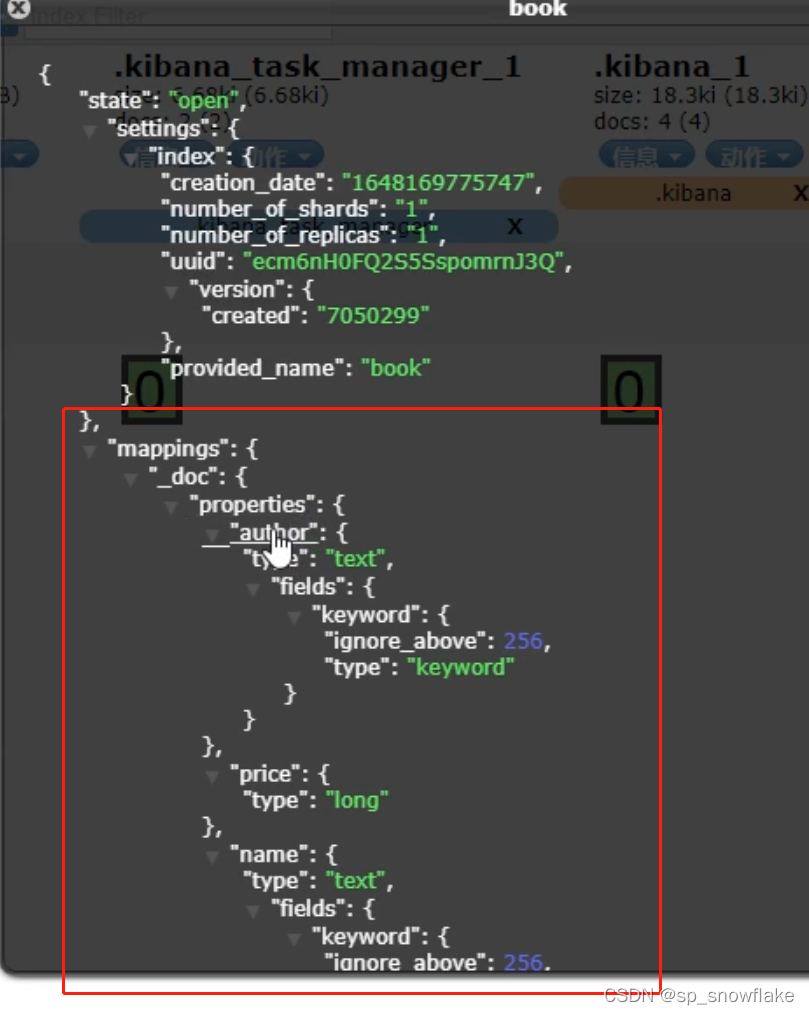
再往里面细看,可以发现有个 “keywork”,里面还有 type:keyword。text 和 keyword 都是存字符串,但是 keyword 存的是像 邮箱地址和电话号码 这种不需要分词的,是什么就直接是什么,一整个去存。
所以:
text:字符串,存储需要分词的。
keyword:字符串,存储不需要分词的。
当然,同一个字段可以有多种类型去存。
动态映射还有一个日期检测的问题。可以看到 publishDate 的数据类型会被推断是日期类型。如果这个时候再存一本书,publishDate 不是日期,而是其他数据类型,那么存储一定会报错;如果是要存字符串类型,我们存数字类型,都一样可以,因为字符串跟数字可以转换,但是日期类型不能转换。
要解决这个问题,可以使用静态映射,即在索引定义时,将 remark 指定为 text 类型。也可以关闭日期检测:

此时日期类型就回当成文本来处理。
默认情况下,文档中如果新增了字段,mappings 中也会自动新增进来。
有的时候,如果希望新增字段时,能够抛出异常来提醒开发者,这个可以通过 mappings 中 dynamic属性来配置。但是这么设置,其实也就是变成静态映射了。
2、静态映射
如果希望新增字段时,能够抛出异常来提醒开发者,这个可以通过 mappings 中 dynamic属性来配置。
dynamic 属性有三种取值:
- true:默认即此。自动添加新字段。
- false:忽略新字段。
- strict:严格模式,发现新字段会抛出异常。
比如下图(严格模式):

静态映射的意思就是在定义索引时,就把索引中的所有字段类型,统统提前定义枚举好,那么以后往索引中加数据和字段时,就只能按照规定好的加。

如果加了类型不对等的数据,会报 400 错误。
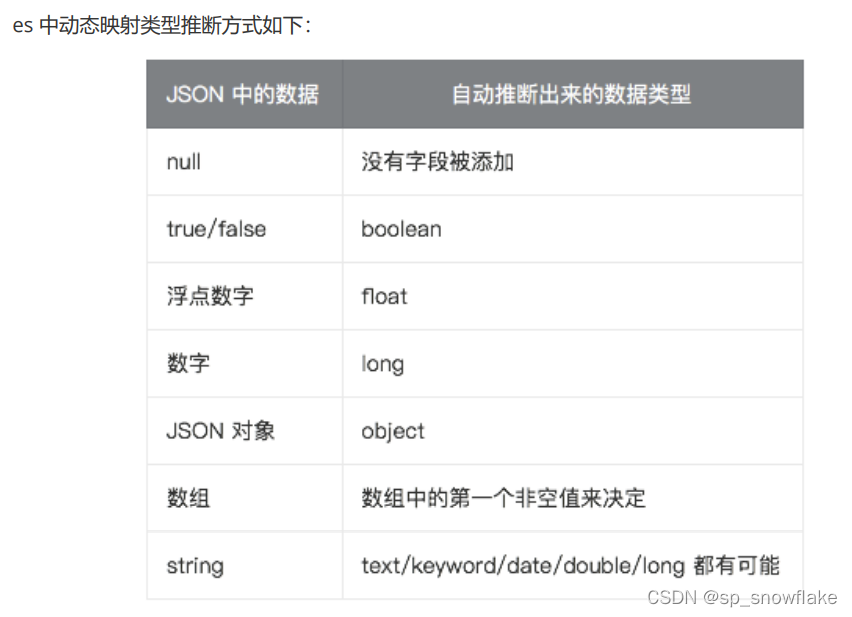
3、类型推断
二、核心类型
1、字符串类型
- string:这是一个已经过期的字符串类型。在 es5 之前,用这个来描述字符串,现在的话,它已经被 text 和 keyword
替代了。 - text:如果一个字段是要被全文检索的,比如说博客内容、新闻内容、产品描述,那么可以使用text。用了 text
之后,字段内容会被分析,在生成倒排索引之前,字符串会被分词器分成一个个词项。text类型的字段不用于排序,很少用于聚合。这种字符串也被称为 analyzed 字段。 - keyword:这种类型适用于结构化的字段,例如标签、email地址、手机号码等等,这种类型的字段可以用作过滤、排序、聚合等。这种字符串也称之为 not-analyzed 字段。
2、数字类型
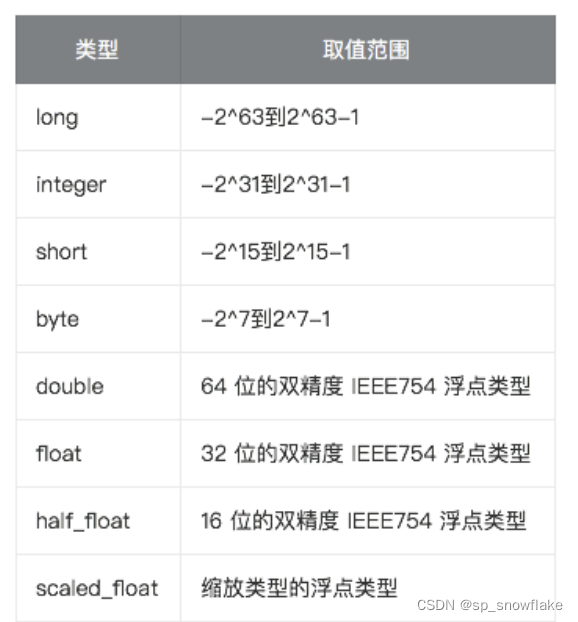
- 在满足需求的情况下,优先使用范围小的字段。字段长度越短,索引和搜索的效率越高。
- 浮点数,优先考虑使用 scaled_float。
scaled_float 举例:

3、日期类型
由于 JSON 中没有日期类型,所以 es 中的日期类型形式就比较多样:
- 2020-11-11 或者 2020-11-11 11:11:11
- 一个从 1970.1.1 零点到现在的一个秒数或者毫秒数。
es 内部将时间转为 UTC,然后将时间按照 millseconds-since-the-epoch 的长整型来存储。
自定义日期类型:

这个能够解析出来的时间格式比较多。

上面三个文档中的日期都可以被解析,内部存储的是毫秒计时的长整型数。
4、布尔类型(boolean)
JSON 中的 “true”、“false”、true、false 都可以。
5、二进制类型(binary)
二进制接受的是 base64 编码的字符串,默认不存储,也不可以搜索。
6、范围类型
- integer_range
- float_range
- long_range
- double_range
- date_range
- ip_range
定义的时候,指定范围类型即可:

插入文档的时候,需要指定范围的界限:

指定范围的时候,可以使用 gt、gte、lt、lte。
7、 复合类型
a、数组类型
es 中没有专门的数组类型。默认情况下,任何字段都可以有一个或者多个值。需要注意的是,数组中的元素必须是同一种类型。
添加数组时,数组中的第一个元素决定了整个数组的类型。
b、对象类型(object)
由于 JSON 本身具有层级关系,所以文档包含内部对象。内部对象中,还可以再包含内部对象。

c、嵌套类型(nested)
nested 是 object 中的一个特例。
如果使用 object 类型,假如有如下一个文档:

由于 Lucene 没有内部对象的概念,所以 es 会将对象层次扁平化,将一个对象转为字段名和值构成的简单列表。即上面的文档,最终存储形式如下:

扁平化之后,用户名之间的关系没了。这样会导致如果搜索 Zhang si 这个人,会搜索到。
此时可以 nested 类型来解决问题,nested 对象类型可以保持数组中每个对象的独立性。nested 类型将数组中的每一饿对象作为独立隐藏文档来索引,这样每一个嵌套对象都可以独立被索引。

优点:文档存储在一起,读取性能高。
缺点:更新父或者子文档时需要更新更个文档。比如更新 zhang 这个姓,需要连 san 这个名也一起更新。
8、地理类型
使用场景:
- 查找某一个范围内的地理位置
- 通过地理位置或者相对中心点的距离来聚合文档
- 把距离整个到文档的评分中
- 通过距离对文档进行排序
a、 geo_point


注意:使用数组描述,先经度后纬度。
地址位置转 geo_hash:http://www.csxgame.top/#/
b、geo_shape



9、特殊类型
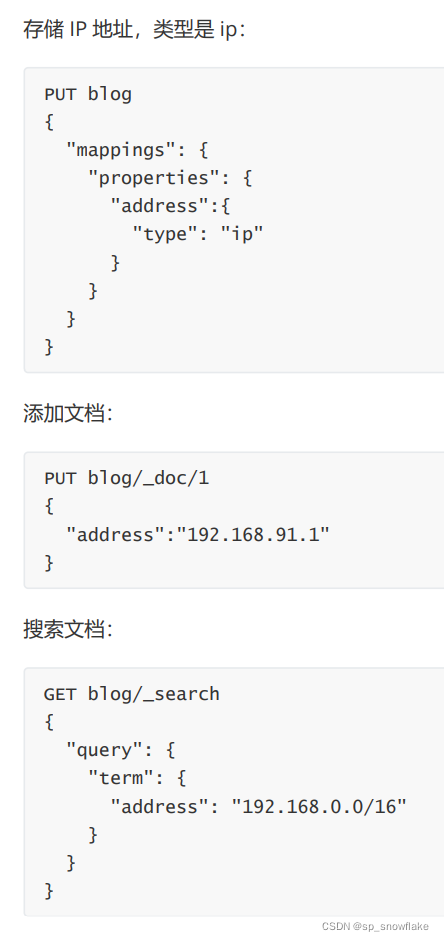
a、IP
b、token_count

三、二十三种映射参数
1、analyzer

这里的结果就不贴图了,可自行尝试。
默认情况下,中文就是一个字一个字的分,这种分词方式没有任何意义。如果这样分词,查询就只能按照一个字一个字来查,像下面这样:


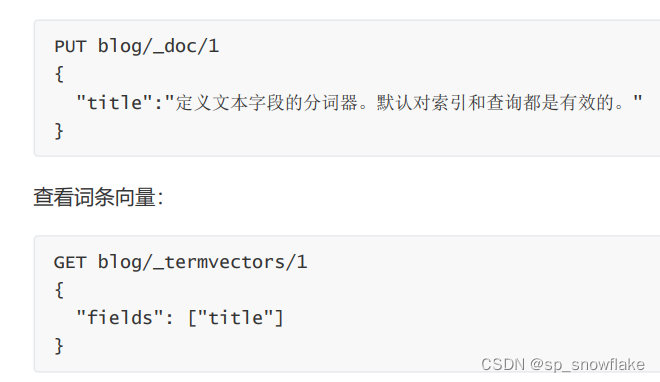
结果就不贴图了。
总之这么分词后,然后就可以通过词去搜索了:

词条向量:存到底层的词是怎么分词的;并不是说简单的存储分词,还有这个词在这句话中具体的位置,以及这个词在这句话中出现了多少次(频率);因为这些将来都要作为搜索评分的标准。
2、search_analyzer
查询时候的分词器。默认情况下,如果没有配置 search_analyzer,则查询时,首先查看有没有search_analyzer,有的话,就用 search_analyzer 来进行分词,如果没有,则看有没有 analyzer,如果有,则用 analyzer 来进行分词,否则使用 es 默认的分词器。
3、normalizer
normalizer 参数用于解析前(索引或者查询)的标准化配置。
比如,在 es 中,对于一些我们不想切分的字符串,我们通常会将其设置为 keyword,搜索时候也是使用整个词进行搜索。如果在索引前没有做好数据清洗,导致大小写不一致,例如 javaboy 和JAVABOY,此时,我们就可以使用 normalizer 在索引之前以及查询之前进行文档的标准化。
先来一个反例,创建一个名为 blog 的索引,设置 author 字段类型为 keyword:


大写关键字可以搜到大写的文档,小写关键字可以搜到小写的文档。
如果使用了 normalizer,可以在索引和查询时,分别对文档进行预处理。
normalizer 定义方式如下:

在 settings 中定义 normalizer,然后在 mappings 中引用。
测试方式和前面一致。此时查询的时候,大写关键字也可以查询到小写文档,因为无论是索引还是查询,都会将大写转为小写。
4、boost
boost 参数可以设置字段的权重。
boost 有两种使用思路,一种就是在定义 mappings 的时候使用,在指定字段类型时使用;另一种就是在查询(搜索)时使用。
实际开发中建议使用后者,前者有问题:如果不重新索引文档,权重无法修改。
mapping 中使用 boost(不推荐):

另一种方式就是在查询(搜索)的时候,指定 boost(推荐):
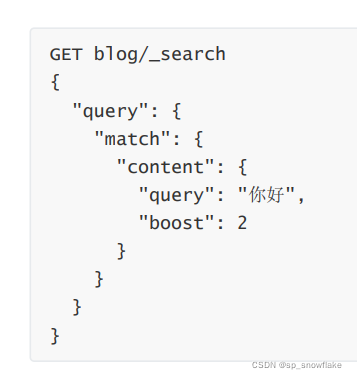
5、coerce



6、copy_to

7、doc_values 和 fielddata
es 中的搜索主要是用到倒排索引,doc_values 参数是为了加快排序、聚合操作而生的。当建立倒排索引的时候,会额外增加列式存储映射。
doc_values 默认是开启的,如果确定某个字段不需要排序或者不需要聚合,那么可以关闭doc_values。
大部分的字段在索引时都会生成 doc_values,除了 text。text 字段在查询时会生成一个 fielddata 的数据结构,fieldata 在字段首次被聚合、排序的时候生成。
doc_values 默认开启,fielddata 默认关闭。
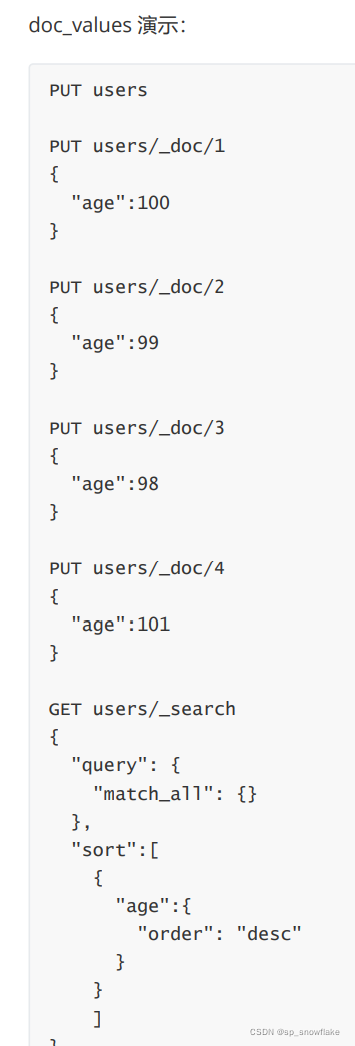
由于 doc_values 默认时开启的,所以可以直接使用该字段排序,如果想关闭 doc_values ,如下:
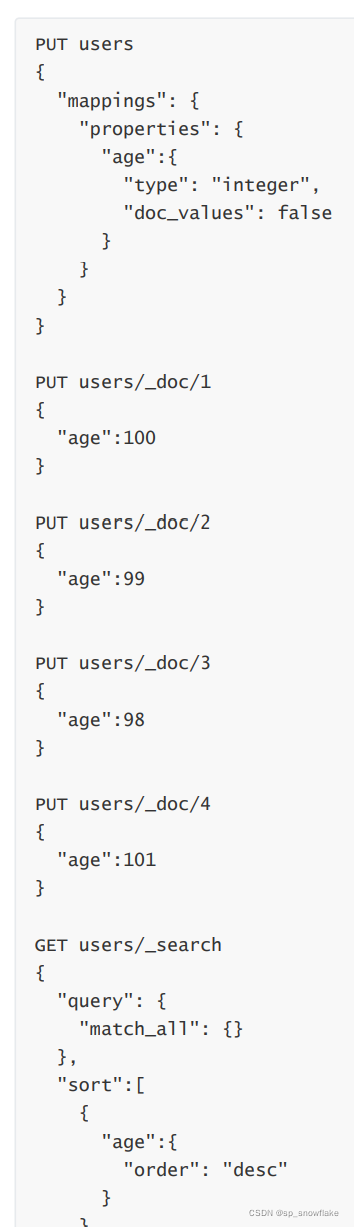
8、dynamic
这个讲动态映射的时候已经说过了,就是严格模式那些。
9、enabled
es 默认会索引所有的字段,但是有的字段可能只需要存储,不需要索引。此时可以通过 enabled 字段来控制:
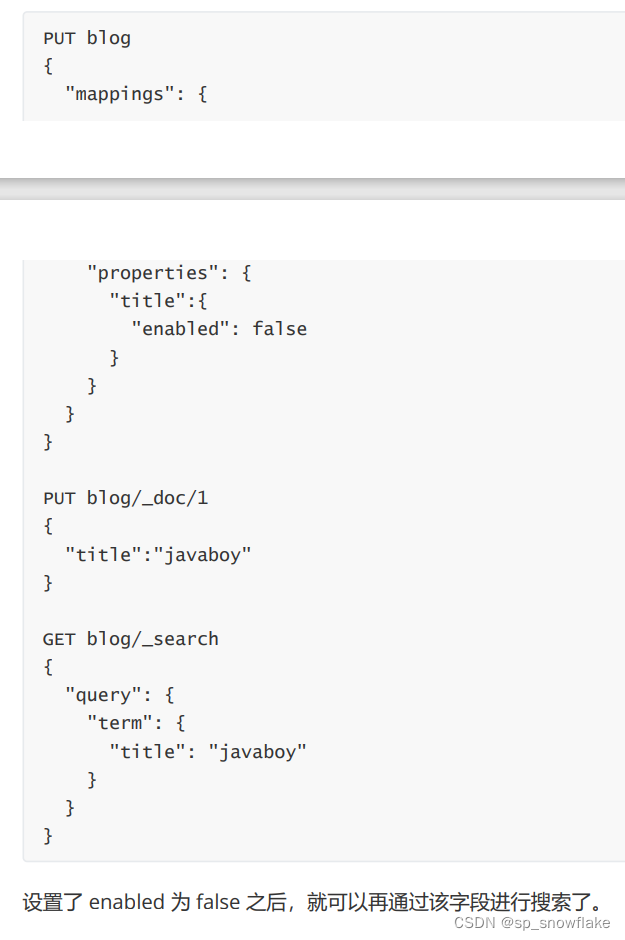
10、format
日期格式。format 可以规范日期格式,而且一次可以定义多个 format。

- 多个日期格式之间,使用 || 符号连接,注意没有空格。
- 如果用户没有指定日期的 format,默认的日期格式是 strict_date_optional_time||epoch_mills
另外,所有的日期格式,可以在 https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-date-format.html网址查看。
11、ignore_above
igbore_above 用于指定分词和索引的字符串最大长度,超过最大长度的话,该字段将不会被索引,这个字段只适用于 keyword 类型。
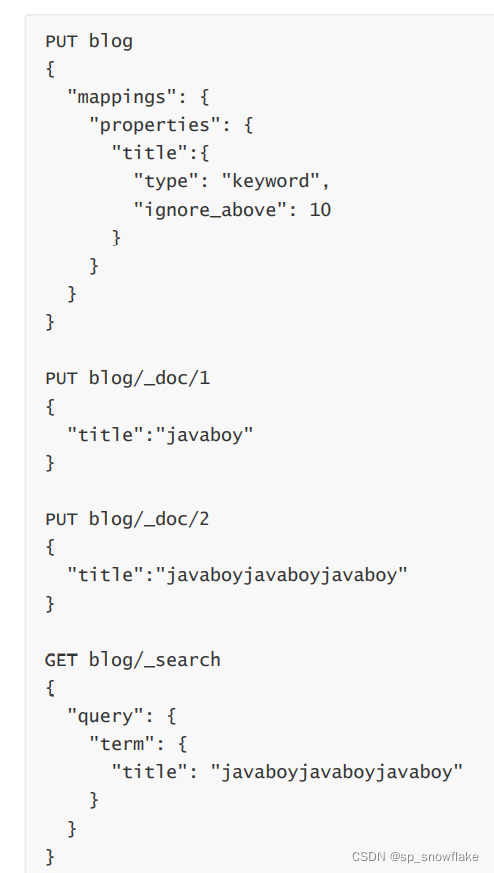
12、ignore_malformed
ignore_malformed 可以忽略不规则的数据,该参数默认为 false。


13、include_in_all
这个是针对 _all 字段的,但是在 es7 中,该字段已经被废弃了。
14、index
index 属性指定一个字段是否被索引,该属性为 true 表示字段被索引,false 表示字段不被索引。
如果 index 为 false,则不能通过对应的字段搜索。
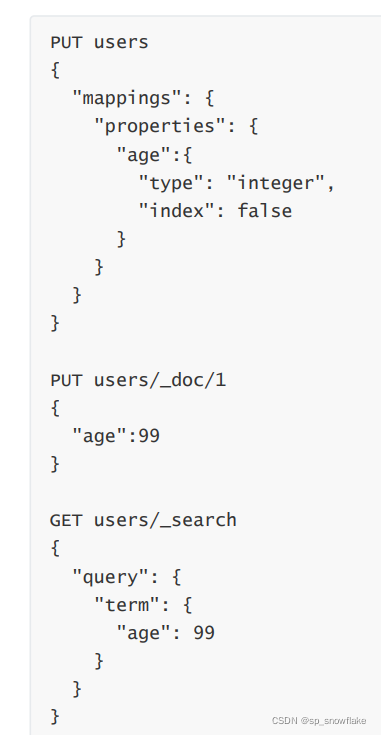
15、index_options
index_options 控制索引时哪些信息被存储到倒排索引中(用在 text 字段中),有四种取值:

16、norms
norms 对字段评分有用,text 默认开启 norms,如果不是特别需要,不要开启 norms。
17、null_value
在 es 中,值为 null 的字段不索引也不可以被搜索,null_value 可以让值为 null 的字段显式的可索引、可搜索:
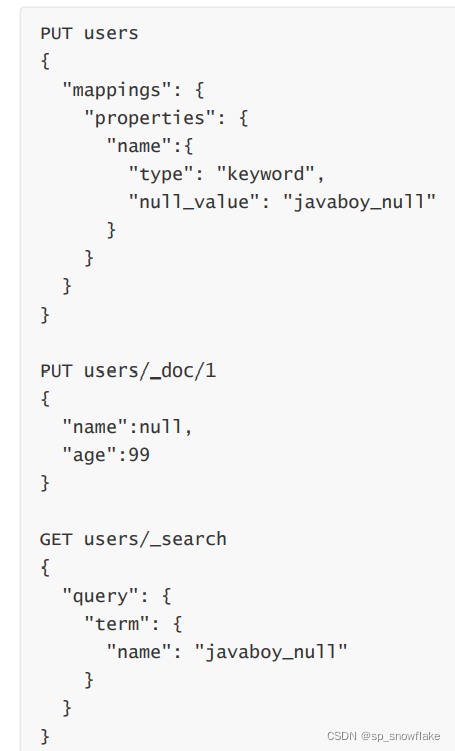
18、position_increment_gap
被解析的 text 字段会将 term 的位置考虑进去,目的是为了支持近似查询和短语查询,当我们去索引一个含有多个值的 text 字段时,会在各个值之间添加一个假想的空间,将值隔开,这样就可以有效避免一些无意义的短语匹配,间隙大小通过 position_increment_gap 来控制,默认是 100。

sanli 搜索不到,因为两个短语之间有一个假想的空隙,为 100。

可以通过 slop 指定空隙大小。
也可以在定义索引的时候,指定空隙:
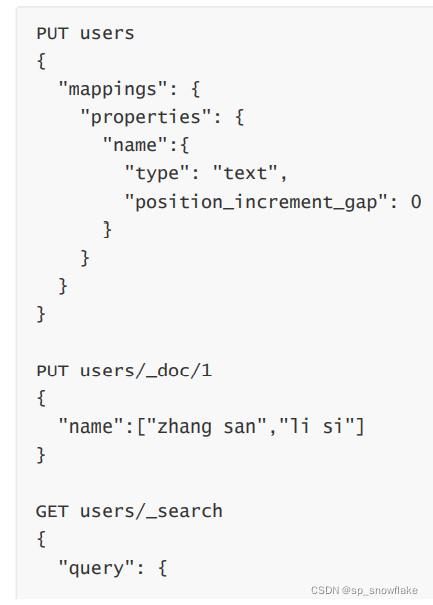

近似查询:比如查询 java,但实际输入了 jaav 或者 jvaa 这种,但是近似查询依然能搜索出 java,;近似查询解决的就是这种问题。
19、properties
这个就不说了,用了很多次了。
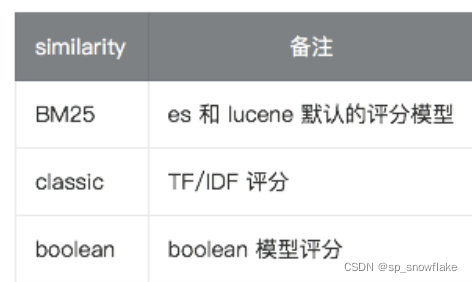
20、similarity
similarity 指定文档的评分模型,默认有三种:
21、store
默认情况下,字段会被索引,也可以搜索,但是不会存储,虽然不会被存储的,但是 _source 中有一个字段的备份。如果想将字段存储下来,可以通过配置 store 来实现。
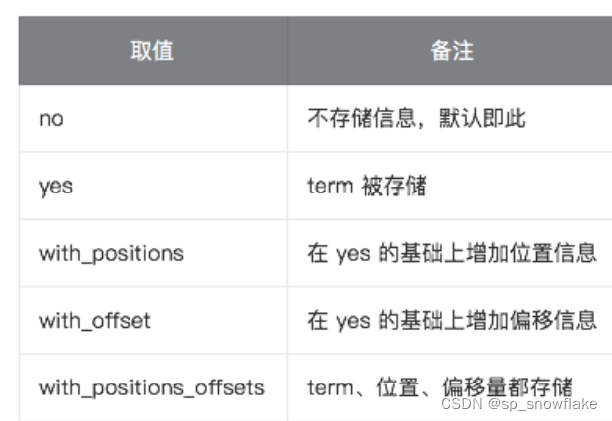
22、term_vectors
term_vectors 是通过分词器产生的信息,包括:
- 一组 terms
- 每个 term 的位置
- term 的首字符/尾字符与原始字符串原点的偏移量
term_vectors 取值:
23、fields
fields 参数可以让同一字段有多种不同的索引方式。例如:
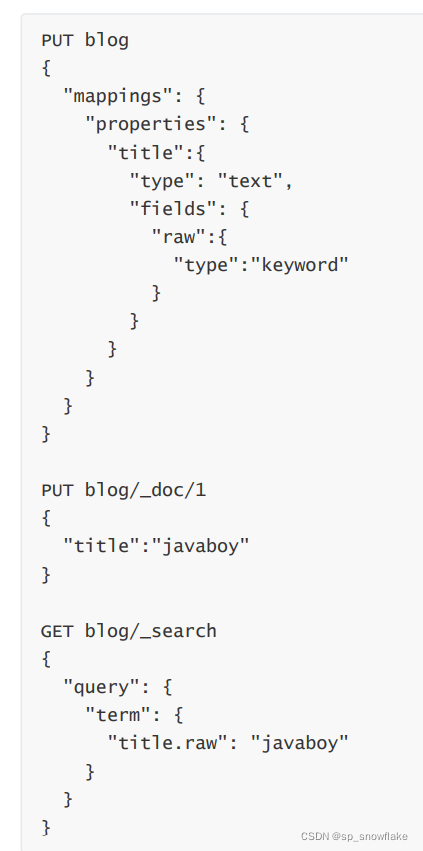
24、官方文档
二十三种映射参数官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-params.html

