
- 1oVirt 4.4.10三节点超融合集群安装配置及集群扩容(二)_ovirt超融合
- 2MySQL基础篇——MySQL数据库客户端连接,数据模型,SQL知识_mysql 客户端
- 3软约束和硬约束的轨迹优化_车上面有哪些软约束和硬约束?
- 4Flink消费pubsub问题_flink pubsubsource
- 5记录 mac 错误:zsh: command not found: brew 解决方法_brew install tcptraceroute zsh: command not found:
- 6VMware安装macOS虚拟机_vmware mac
- 7解决MobaXterm中文乱码编码问题.
- 8【Java】浅谈前缀和与差分_java 前缀和 差分
- 9Motion Plan | 软硬约束下的轨迹如何生成,理论&代码详解!
- 10vue3框架搭建+vite+ts+elementplus+axios+vuex_vue3+vite+ts+elementplus的安装和使用教程
自建搜索引擎-基于美丽云_美丽云搜索配置
赞
踩
Meilisearch 是一个搜索引擎,主程序完全开源,除了使用官方提供的美丽云服务(收费)进行对接之外,还可以通过自建搜索引擎来实现完全独立的搜索服务。
由于成本问题,本博客采用自建的方式,本文就讲讲怎么搭建。
本文主要参考:
- meilisearch 全接入指南 | 二丫讲梵:讲了怎么使用官方提供的服务,也讲了怎么自建
- Meilisearch Documentation:官网文档
前置工作
- 博客已配置 sitemap 功能,参考 VuePress 博客之 SEO 优化(一)之 sitemap 与搜索引擎收录 - 知乎
- 自建时要用到自定义的域名,因此额外购买了一个二级域名的 SSL 证书,例如我用的是 search.peterjxl.com
安装和启动美丽云
首先需要在服务器上安装美丽云搜索:
curl -L https://install.meilisearch.com | sh
- 1
我在用 curl 安装的时候,发现有报错,推测是 GFW 的问题,改为用 Docker 安装(有很多安装方式,参考安装指南):
docker pull getmeili/meilisearch:v1.6
- 1
然后启动命令格式为:
docker run -itd --name meilisearch -p 7700:7700 \
-e MEILI_ENV="production" -e MEILI_NO_ANALYTICS=true \
-e MEILI_MASTER_KEY="自定义一个不少于16字节的秘钥" \
-v $(pwd)/meili_data:/meili_data \
getmeili/meilisearch:v1.6
- 1
- 2
- 3
- 4
- 5
注意修改 master-key,该密钥用于爬虫抓取使用(就是爬取你的博客内容并做好分词、索引等)。
启动后可以用 docker ps 查看容器状态,或者用 telnet 检查端口是否被监听。
配置 Nginx
首先去阿里云上配置 DNS 解析记录:

这个结合自身情况添加配置(例如我用的是 Nginx):
server { listen 80; listen 443 ssl; server_name search.peterjxl.com; ssl_certificate /conf/search.peterjxl.com.pem; ssl_certificate_key /conf/search.peterjxl.com.key; ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_prefer_server_ciphers on; location / { proxy_set_header Host $host; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Real-IP $remote_addr; proxy_pass http://127.0.0.1:7700; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
配置后记得重启 Nginx,并且记得开通防火墙,然后尝试访问子域名,可以看到正常转发了请求:

建立索引
接下来,我们通过美丽云提供的爬虫功能,将博客数据创建成索引,相关文档请见:Integrate a relevant search bar to your documentation — Meilisearch documentation。
其中,提供了一个关于 VuePress 的配置文件模板:
If you use VuePress for your documentation, you can check out the configuration file we use in production. In our case, the main container is
theme-default-content and the selector titles and subtitles areh1,h2…
{ "index_uid": "docs", "sitemap_urls": ["https://docs.meilisearch.com/sitemap.xml"], "start_urls": ["https://docs.meilisearch.com"], "selectors": { "lvl0": { "selector": ".sidebar-heading.open", "global": true, "default_value": "Documentation" }, "lvl1": ".theme-default-content h1", "lvl2": ".theme-default-content h2", "lvl3": ".theme-default-content h3", "lvl4": ".theme-default-content h4", "lvl5": ".theme-default-content h5", "text": ".theme-default-content p, .theme-default-content li, .theme-default-content td" }, "strip_chars": " .,;:#", "scrap_start_urls": true, "custom_settings": { "synonyms": { "relevancy": ["relevant", "relevance"], "relevant": ["relevancy", "relevance"], "relevance": ["relevancy", "relevant"] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
注意如上的配置内容很重要,如果你的博客不是常规默认的,那么需要根据自己的情况对元素进行辨别,详细配置项说明,参考官方文档:更多可选字段 。
我用的配置如下:
{ "index_uid": "VuePressBlog", "sitemap_urls": ["https://www.peterjxl.com/sitemap.xml"], "start_urls": ["https://www.peterjxl.com"], "selectors": { "lvl0": { "selector": "h1", "global": true, "default_value": "Documentation" }, "lvl1": ".theme-vdoing-content h2", "lvl2": ".theme-vdoing-content h3", "lvl3": ".theme-vdoing-content h4", "lvl4": ".theme-vdoing-content h5", "lvl5": ".theme-vdoing-content h6", "text": ".theme-vdoing-content p, .theme-vdoing-content li" }, "strip_chars": " .,;:#", "scrap_start_urls": true, "selectors_exclude": ["iframe", ".katex-block", ".md-flowchart", ".md-mermaid", ".md-presentation.reveal.reveal-viewport", ".line-numbers-mode", ".code -group", ".footnotes", "footer.page-meta", ".page-nav", ".comments-wrapper"]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
index_uid :为索引名称,如果服务端没有,则会自动创建。接下来我们将这个配置文件放到服务器上,然后通过如下命令运行爬虫对内容进行抓取(注意修改相关参数):
docker run -t --rm \
--network=host \
-e MEILISEARCH_HOST_URL='二级域名,例如我的是search.peterjxl.com' \
-e MEILISEARCH_API_KEY='刚刚创建的Master Key' \
-v 配置文件完整路径:/docs-scraper/config.json \
getmeili/docs-scraper:v0.12.7 pipenv run ./docs_scraper config.json
- 1
- 2
- 3
- 4
- 5
- 6
执行过程中可以看到每个页面都进行了抓取(爬取过程会比较久,这取决于博客的内容数量):

创建搜索用的 key
在美丽云中,有两种密钥:
- master-key:权限很大,例如创建,更新,删除索引。
- API Key:权限很小,一般只用于搜索,可以有多个
更多说明可以参考官网文档:Master key and API keys — Meilisearch documentation。
由于 master-key 权限很大,不宜暴露,因此我们可以创建一个只有搜索权限的 API Key(用来搜索),命令格式:
curl \
-X POST 'http://localhost:7700/keys' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer 刚刚自定义的master-key' \
--data-binary '{
"description": "peterjxl.com search_key",
"actions": ["search"],
"indexes": ["刚刚创建的index_id"],
"expiresAt": "2099-01-01T00:00:00Z"
}'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
然后会返回一串 JSON,其中的 key 就是我们需要的(已脱敏):
{
"name": null,
"description": "peterjxl.com search_key",
"key": "xxxx",
"uid": "xxxx",
"actions": [
"search"
],
"indexes": [
"wiki"
],
"expiresAt": "2099-01-01T00:00:00Z",
"createdAt": "2024-01-17T12:54:42.357819802Z",
"updatedAt": "2024-01-17T12:54:42.357819802Z"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
测试搜索
我们可以使用 Postman 来测试搜索效果(如果使用了美丽云的服务,可以在其官网进行搜索测试)
相关文档:Postman collection for Meilisearch — Meilisearch documentation (图片需科学上网后看到)
配置好后,可以进行搜索,效果如下:

配置 VuePress
接下来就是在 VuePress 中集成美丽云了。
客户端的配置相对简单,因为 meilisearch 的官方文档用的也是 Vuepress,因此官方也维护了一个 Vuepress 的插件,安装:
npm install vuepress-plugin-meilisearch
- 1
然后在配置插件的部分添加相关配置:
// 全文搜索插件 meilisearch
[
'vuepress-plugin-meilisearch',
{
hostUrl: 'https://search.peterjxl.com', // meilisearch 服务端域名
apiKey: "刚刚创建的搜索key", // 只有搜索权限的 key
indexUid: 'VuePressBlog',
placeholder: '支持全文搜索', // 在搜索栏中显示的占位符
maxSuggestions: 9, // 最多显示几个搜索结果
cropLength: 30, // 每个搜索结果最多显示多少个字符
},
],
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
然后本地运行,试试效果:

配置 GitHub Action
如果每次更新了博客,都重新运行建立索引的命令,也太麻烦了。我们可以脚本化,或者使用 GitHub Action。例如,添加如下配置:
scrape-docs: needs: test_website runs-on: ubuntu-20.04 steps: - uses: actions/checkout@v2 - uses: actions/setup-node@v2 with: node-version: 14 registry-url: https://registry.npmjs.org/ - name: Run docs-scraper env: API_KEY: ${{ secrets.MEILISEARCH_API_KEY }} CONFIG_FILE_PATH: ${{ github.workspace }}/docs/.vuepress/public/data/docs-scraper-config.json run: | docker run -t --rm \ -e MEILISEARCH_HOST_URL="https://search.peterjxl.com" \ -e MEILISEARCH_API_KEY=$API_KEY \ -v $CONFIG_FILE_PATH:/docs-scraper/config.json \ getmeili/docs-scraper:v0.12.7 pipenv run ./docs_scraper config.json
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
注意这 3 个配置:
secrets.MEILISEARCH_API_KEY:就是 Master keyCONFIG_FILE_PATH:爬虫抓取时的配置文件,可以选择放在项目源码的某个指定目录(例如我的是docs/.vuepress/config/)MEILISEARCH_HOST_URL:美丽云的域名,例如我的是https://search.peterjxl.com
配置完后,当我们提交了新的代码,就会自动爬取博客数据并更新索引了,GitHub Action 执行情况:
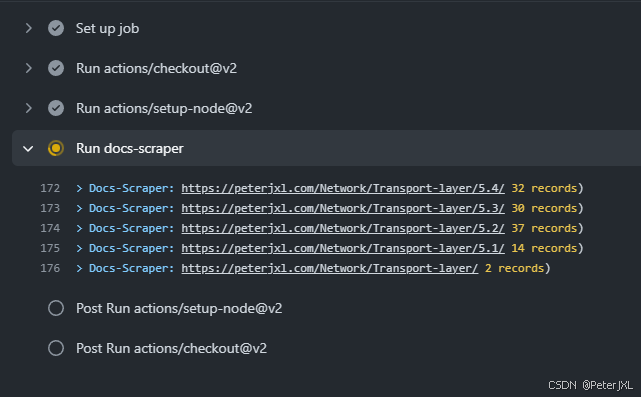
(完)

