
- 1RabbitMQ安装UI监控插件
- 2《图像处理的璀璨星空:技术演进与热点聚焦》_图像处理技术现如今的前沿技术有哪些
- 3C++ + QT (不使用QT插件模式)的heic图片显示。_qt heic
- 4欧拉操作系统_欧拉系统
- 5网络资源模板--基于 Android Studio 实现的新闻App_android studio新闻客户端制作
- 6Android数据库高手秘籍_android 数据库密集
- 7【kafka专栏】消息队列通用消息传递模型(带视频)_可以传输图片视频的消息队列
- 8Git工具常用命令详解_git命令工具
- 9深入理解哈希表
- 10【大模型应用篇6】私有化智能体平台,为了数据更安全........_dify和coze
如何编写【C++高性能服务器/程序】_c++高性能服务器开发
赞
踩
总结了一些关于性能方面的知识/经验,跟大家分析下。
欢迎大家在评论进行补充(我会按照补充添加)。
希望大家点赞收藏
1. 避免频繁内存申请(避免频繁系统函数调用)
- 系统调用通常涉及到与操作系统内核的交互
- 操作通常涉及资源调度、复杂的数据结构和算法、异常校验
- 频繁内存分配会造成内存碎片,导致操作系统可能需要耗时寻找足够大的连续内存块
- 系统调用本身是线程安全的,操作系统内核会在内部使用各种技术和算法来确保系统调用的正确性和线程安全性。
建议: 在需要频繁调用场景下,多了解需使用的系统函数调用内部实现原理,选择一些更优的方案替换系统调用,或一些策略减少系统调用.
2. 避免不必要的内存访问
(1) 尽量Cache命中
- 遵循局部性原理,即尽量让数据在物理内存上连续存储,以减少缓存未命中的次数。这可以通过适当的数组和结构体布局来实现。
- 尽量减少跨页或跨块的数据访问,因为这可能导致更高的内存访问延迟
- 常用局部变量加上register关键字
建议编译器尽可能地把变量存放在寄存器中,以加快其访问速度。
(2) 使用数据缓存
-
如果某些数据被频繁访问,考虑将它们缓存在更快的存储介质中,如CPU缓存或寄存器
-
在某些情况下,使用内存池或对象池可以避免频繁的内存分配和释放,从而提高性能
概念1: 存储金字塔
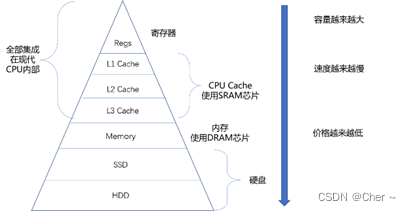
** 越靠近 CPU 速度越快,容量越小,价格越贵
** 每一种存储器设备只和它相邻的存储设备打交道 比如,CPU Cache 是从内存里加载而来的,或者需要写回内存,并不会直接写回数据到硬盘,也不会直接从硬盘加载数据到 CPU Cache 中,而是先加载到内存,再从内存加载到 Cache 中。概念2: 高速缓存-Cache
** CPU和内存之间速度严重不匹配的问题,在CPU和内存之间设计了高速缓存,即Cache。
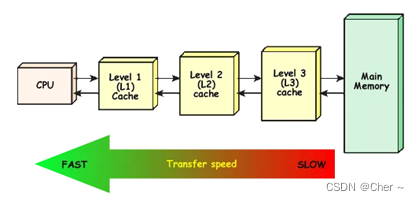
CPU读取数据时,会在L1、L2、L3Cache中逐级查找,如果找到,就从Cache直接读取,找不到再从内存读取,并且把数据存放到Cache中,以便提高下次访问的效率。
在这个过程中,如果在Cache中找到所需数据,称为Cache命中(Cache Hit), 找不到称为Cache未命中(Cache Miss)。
L1 Cache命中的时候,读取数据最快,性能最好,而当L1、L2、L3 Cache全部未命中时,就必须要直接从内存中读取数据,性能最差概念3: 局部性原理
** 时间局部性。如果一个数据在某个时间点被CPU访问了,那么在接下来很短的一段时间内,这个数据很有可能会再次被CPU访问到。
** 空间局部性。如果一个数据在某个时间点被CPU访问了,那么与这个数据临近的其他数据,很有可能也会很快被CPU访问到。概念4: 缓存行-Cache Line
** 根据 局部性原理 如果一个数据被CPU访问了,那么这个数据相邻的其他数据也很快会被访问到。因此,为了提高内存数据的读取效率,并且最大化利用CPU资源,数据在Cache和内存之间传输时,不是一个字节一个字节进行传输的,而是以缓存行(Cache Line)为单位进行传输的。
(3) 数据结构优化
设计/选择 合适的数据结构和算法,避免不必要的数据复制和遍历。选择合适的数据结构可以减少内存访问次数和数据移动操作。
(4) 尽量确保内存对齐
大多数现代处理器在访问未对齐的内存时,性能会下降。这是因为处理器通常一次从内存中读取或写入多个字节(例如,4字节、8字节等),如果数据未对齐,处理器可能需要多次访问内存来获取或存储数据,这被称为“未对齐访问”或“跨边界访问”。因此,内存对齐可以显著提高数据访问的性能。
(5) 考虑使用内联函数
将那些短小的、频繁调用的函数声明为内联函数
3. 避免不必要的内存拷贝
(1) 使用引用或指针传递参数 或 做为返回值
- 减少 临时变量创建 构造 析构
(2) 使用零拷贝技术
- 一些函数调用
** std::move使用移动语义和完美转发, C++11引入了右值引用和移动语义,允许对象在不需要时“移动”其资源,而不是拷贝
** std::swap: 交换两个对象的内容。对于支持移动语义的对象,swap可以在不进行数据复制的情况下交换资源
** 容器的emplace方法 (如:emplace_back, emplace, try_emplace): 在容器的指定位置直接构造元素,通常比push_back或insert更高效,因为它们避免了临时对象的创建和复制。
** std::unique_ptr 和 std::shared_ptr: 智能指针通过控制对象的所有权,可以避免对象的复制,并且可以在多个指针之间转移所有权。
** std::string_view 或 std::span (C++20): 这些是非拥有的引用类型,它们提供了对数据的视图,而不是复制。它们可以用来访问字符串或数组的一部分,而不需要进行复制。
** 发送文件sendfile: 它可以在两个文件描述符之间直接传输数据,常用于将数据从文件直接发送到网络套接字。这避免了将数据从内核拷贝到用户空间,然后再从用户空间拷贝回内核的情况。 原理:sendfile直接在内核中操作,将文件内容直接从文件系统缓存拷贝到套接字缓冲区,省去了用户空间的介入。
** 使用“placement new”语法: 允许在已分配的内存上直接构造对象,避免了额外的内存分配和复制。 - 内存映射 (Memory-Mapped Files):
** 内存映射文件通过将磁盘上的文件映射到进程的地址空间来实现零拷贝,直接在内存上操作文件数据,无需通过read/write系统调用。这样可以避免用户空间和内核空间之间的数据拷贝。 原理:使用mmap系统调用将文件映射到进程的虚拟内存空间。对这块内存的读写操作将直接影响到磁盘上的文件内容。 - 共享内存 (Shared Memory)
** 允许多个进程访问同一块内存区域,这样数据就可以在不同的进程之间共享而无需复制。 - 零拷贝数据传输
** 在数据包到达网络适配器后,网络协议栈可以直接将数据包传输到应用程序的内存中,而不是先将数据包复制到内核缓冲区,再从内核缓冲区复制到用户空间。 - 一些策略
** 循环缓冲区 (Circular Buffers): 在生产者-消费者模型中,循环缓冲区可以使生产者和消费者共享缓冲区而无需进行数据拷贝。
** 写时复制 (Copy-On-Write, COW): 当多个进程需要读取同一份数据时,它们可以共享同一份物理内存。只有当其中一个进程需要修改数据时,才会创建这份数据的副本。
** 使用大页内存 (Large Pages): 大页内存可以减少页表项的数量,从而减少TLB(Translation Lookaside Buffer)缓存不命中的情况,提高内存访问效率。
** 避免使用缓冲区: 直接I/O (Direct I/O) 允许数据从磁盘直接传输到应用程序的数据结构中,而不是先复制到操作系统的缓冲区。选择合理的数据结构.
(3) 使用合理的数据结构
合理设计数据结构可以减少内存拷贝。例如,使用连续存储的数组而不是链表,可以减少访问和拷贝的开销。
(4) 避免容器扩容
选择好需使用容器后(如std::vector), 尽量通过resize、reserve来提前分配好内存, 来避免或 减少 扩容次数。 (经实测小数据对象下(如int)reserve后一个个去赋值 快于resize后一个个 push_back, 可能是因为push_back多了很多单次修改std::vector成员属性, 校验等…)
(5) 避免不必要的临时对象
在函数调用或表达式求值过程中,尽量减少临时对象的创建。这可以通过使用const引用参数、返回值优化等技术来实现
4. 避免不必要的计算
(1) 合理进行程序设计 找出最优解决方案
(2) 使用更高效的算法和数据结构
(3) 使用缓存机制
使用变量存储中间结果,避免在循环中重复计算相同的表达式。使用记忆化技术或缓存机制,特别是在递归算法中.
5. 使用第三方工具协助找到性能评价,并进行调优
(1) Valgrind
主要用于内存泄漏检测,但它的工具集中的Callgrind可以用于性能分析。
(2) gprof
GNU Profiler 是一个标准的UNIX/Linux命令行性能分析工具,输出程序的调用图和执行时间统计。
(3) perf
Linux性能计数器工具,可以分析CPU性能计数器和程序事件,如缓存未命中、分支预测错误等。
(4) Intel VTune Profiler
一款功能强大的性能分析工具,适用于Intel处理器,提供了详细的硬件级别性能数据。
(5) Visual Studio Profiler
Visual Studio集成了性能分析工具,可以在Windows平台上进行性能分析和调试。
(6) Very Sleepy
一个Windows平台上的C/C++ CPU性能分析工具,可以分析函数调用次数和时间消耗。
(7) AQtime
一款商业性能分析工具,支持多种编程语言和开发环境,提供详细的性能报告。
(8) AMD uProf
AMD uProf是AMD的性能分析工具,提供了对CPU性能事件的分析。
(9) Google’s CPU Profiler
部分Google性能工具套件(gperftools),可以用来记录和分析程序的CPU使用情况
6. 使用编译器优化:
(1) GCC和Clang
-O0:不进行优化,编译速度最快,适用于调试。
-O1:开启基本优化,编译器会尝试减少代码大小和执行时间,而不会显著增加编译时间。
-O2:开启进一步优化,比-O1更激进,包括所有不涉及空间-时间权衡的优化。
-O3:启用-O2中的所有优化,并添加更多优化,如更积极的循环优化和内联函数。
-Os:优化代码大小,可能会牺牲一些执行速度。
-Ofast:启用所有-O3优化,并启用一些可能不遵守严格标准兼容性的优化策略。
-flto:启用链接时优化,允许在链接时进行更多的优化。
(2) Microsoft Visual C++(MSVC):
/Od:禁用优化,适合调试。
/O1, /O2:对应于GCC和Clang中的-O1和-O2。
/Ox:使用最大优化(相当于-O2或-O3)。
/Ot:优先优化速度。
/Os:优先优化大小。
/Oy:省略帧指针。
/GL:启用全程序优化。
(4) Intel C++ Compiler
类似于GCC和Clang的优化选项,但还提供一些特定于Intel处理器的优化选项。
7. NUMA(Non-Uniform Memory Access)架构
用于多处理器系统,其中每个处理器都有自己的本地内存。处理器可以访问本地内存比访问远程内存(属于其他处理器的本地内存)更快
(1) 改进的内存访问性能:
通过将线程和内存分配给特定的NUMA节点,可以减少对远程内存的访问,从而减少访问延迟,提高内存访问速度。
(2) 高度并行性:
NUMA架构允许多个处理器同时访问多个内存节点,增加了系统的并行处理能力,这对于并行计算和多线程应用程序来说是非常重要的。
(3) 提高大型多核系统的效率:
对于拥有大量核心的系统,NUMA架构有助于减少每个核心在内存访问时的争用,因为每个核心能够更频繁地访问本地内存。
8. 多线程合理使用锁
(1) 最小化锁的使用:
只在绝对必要的时候使用锁。尽量减少锁的粒度,只保护临界区,即实际需要同步的最小代码块。
(2) 避免锁竞争:
尽量设计无锁的数据结构或算法。
使用局部变量代替共享变量,减少需要锁定的资源。
将数据分解为更小的块,以减少不同线程之间的竞争。
(3) 使用自旋锁:
对于持锁时间非常短的场景,使用自旋锁可能比互斥锁(mutex)效率更高,因为自旋锁避免了线程上下文切换的开销。
(4) 读写锁(共享-独占锁):
当读操作远多于写操作时,使用读写锁可以提高性能。读写锁允许多个读线程同时访问资源,但写线程会独占锁。
(5) 分离互斥:
如果可能,将数据结构分离,使不同的线程操作不同的锁,从而减少锁的争用。
(6) 锁分级:
使用分级锁来减少死锁的可能性,并提高锁的性能。
(7) 条件变量:
结合互斥锁使用条件变量,只在必要时挂起和唤醒线程,减少不必要的锁争用。
(8) 锁粗化:
如果频繁地锁定同一资源,考虑将多个操作合并为一个大的锁定区域(锁粗化),以减少锁的开销。
(9) 避免长时间持锁:
尽量不要在持有锁的时候进行I/O操作、计算密集型任务或者可能导致线程挂起的操作。
9. 减少线程切换
(1) 使用亲和性绑定:
(线程核心绑定) 将线程绑定到特定的处理器核心上,这样可以减少线程在不同核心间迁移,从而减少缓存失效和上下文切换。
(2) 减少线程数量:
尽量使用不多于处理器核心数的线程。过多的线程会导致频繁的上下文切换,增加开销。
(3) 使用线程池:
线程池可以复用一组线程来执行多个任务,减少线程创建和销毁的开销。
(4) 避免过度同步:
多线程合理使用锁,尽量避免不必要的同步,以减少因等待锁而导致的线程挂起和切换。
(5) 合理分配任务:
尽量将任务合理分配给线程,使线程可以持续工作一段时间,避免频繁的任务切换。
(6) 使用工作窃取策略:
对于任务并行库,可以减少线程间的同步,从而减少切换。
(7) 避免长时间的阻塞操作:
尽量减少线程执行I/O操作或其他可能导致线程阻塞的操作。可以使用异步I/O或将I/O操作分离到特定的I/O线程。
(8) 合理设置线程优先级:
谨慎设置线程优先级,以防止优先级倒置或饿死问题。
(9) 减少虚假唤醒:
使用条件变量时,减少不必要的唤醒操作。
(10) 使用并发数据结构:
使用无锁或者低锁的并发数据结构,如C++11中的std::atomic和std::concurrent_queue。
(11) 避免昂贵的操作:
在锁定资源时,避免在临界区内进行昂贵的操作,如内存分配或复杂的计算。
10. 减少流水线停顿 增加指令级并行率
冲突包含
(1)数据冲突(Data Hazard) 数据间依赖
(2)控制冲突(Control Hazard) 遇到分支跳转 无法预测
(3)结构冲突(Structure Hazard) 多条指令同时竞争同一个硬件资源
需要你做的(编译器也会帮你做)
- 避免数据冲突
- 循环展开(Loop Unrolling): 减少循环中的控制逻辑,可以降低分支预测错误的影响,从而减少流水线停顿。
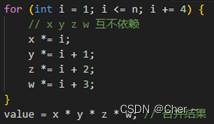 如图避免依赖(数据冲突) 和循环展开
如图避免依赖(数据冲突) 和循环展开 - 软件流水线(Software Pipelining): 手动重新组织代码,使得每个CPU周期都有多个操作在不同的执行阶段,以减少资源冲突和等待时间。
- 指令调度(Instruction Scheduling): 编译器通常会尝试重新排列指令的顺序来避免执行单元的闲置和减少数据相关性导致的停顿。手动调整代码语句的顺序也可以达到相似的效果。
- 分支预测优化(Branch Prediction Optimization): 尽量减少代码中的分支,尤其是在循环和频繁执行的路径中。如果不可避免,则通过排序操作或使用分支预测提示来帮助编译器优化。
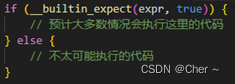
- 多线程(Multithreading): 在软件层面使用多线程可以让多个处理器核心并行工作
不需要你做的, 但需要你了解贴合 (由系统、CPU架构、硬件支持)
- 超标量架构: CPU架构 可以在一个时钟周期内发射 和执行多条指令,从而提高并行度。
- 指令向量化: 或称为单指令多数据(SIMD),是一种并行计算架构,它允许一条指令同时对多个数据元素执行相同的操作(如SSE、AVX2、AES…)。
- 乱序执行: CPU架构 允许指令在不违反数据依赖性的情况下乱序执行,以利用所有可用的执行单元。
- 指令重排: CPU架构 编译器或处理器可以重排指令顺序,以减少流水线停顿
- 分支预测: CPU架构 通过高效的分支预测算法,处理器可以猜测分支指令的结果,以减少由于控制冒险引起的停顿。
- 分支目标缓冲区: CPU架构 使用BTB存储分支目标地址,这样当分支被预测为“跳转”时可以快速获取跳转地址。
- 投机执行: CPU架构 在分支预测的基础上进行投机执行,以填充那些因分支预测而闲置的流水线阶段。
- 数据前推: CPU架构 在数据生产和消费之间提供一条直接路径,使得后续指令可以直接使用前一条指令的结果,而不必等待其写回寄存器。
- 延迟加载: CPU架构 编译器或处理器推迟加载操作,将计算指令插入到加载和使用该数据的指令之间,减少数据冒险。
- 多线程支持: CPU架构 支持多线程,当一个线程遇到长时间的停顿时,处理器可以快速切换到另一个线程,减少流水线空闲时间。
- 硬件预取: 使用硬件预取逻辑来提前加载可能很快会被访问的数据,减少因缓存未命中引起的停顿。

