
- 1统计学和机器学习到底有什么区别?
- 2【路径规划】模糊逻辑算法路径规划【含Matlab源码 3801期】_声源定位 atan2
- 3WEB自动化测试第一讲—selenium中阶操作
- 4机器学习实战——端到端的机器学习项目_机器学习端到端机器学习项目
- 5【经典链表OJ】环形链表
- 6Mysql 开启ssl连接
- 7无公网IP,从公网SSH远程访问家中的树莓派
- 8【Flink】Flink checkpoint expired before completing
- 9基于ART算法和SIRT算法的超声CT反演及MATLAB代码实现_simultaneous iterative reconstruction technique
- 10软件工程常见简答题总结,适用于考研复试_软件工程简答题
NVIDIA AI Enterprise 科普 | Triton 推理服务器 & TensorRT-LLM 两大组件介绍及实践_triton inference server ubuntu
赞
踩
2023年⼤语⾔ AI 模型的蓬勃发展,在⽣产环境中部署应⽤⼤模型的需求也与⽇俱增,然⽽开发⼀个推理解决⽅案来部署这些模型是⼀项艰巨的任务。时延、吞吐量、AI 框架的⽀持度、模型并⾏和负载均衡、GPU优化等因素都是要考虑到的重点,如何进⾏快速部署及管理是⽐较迫切的需求。
NVIDIA作为全球领先的 GPU 芯⽚制造商,为 AI 训练领域提升算⼒赋能⼤模型突破的同时,致⼒于软件⽣态开发,推出了NVIDIA AI Enterprise (NAIE) 的全栈软件套件,其中包含丰富的SDK⼯具库。
本⽂将简单介绍 NAIE 的组件:Triton inference server 和 TensorRT-LLM,并使⽤容器化⽅式部署和测试了 LlaMa2 ⼤模型的推理应⽤。
Triton inference server
Triton 推理服务器是英伟达 NVIDIA AIE 的组成部分,同时也是一个开源的推理服务软件,用于简化 AI 模型的部署和推理过程,并提供高性能的推理服务。
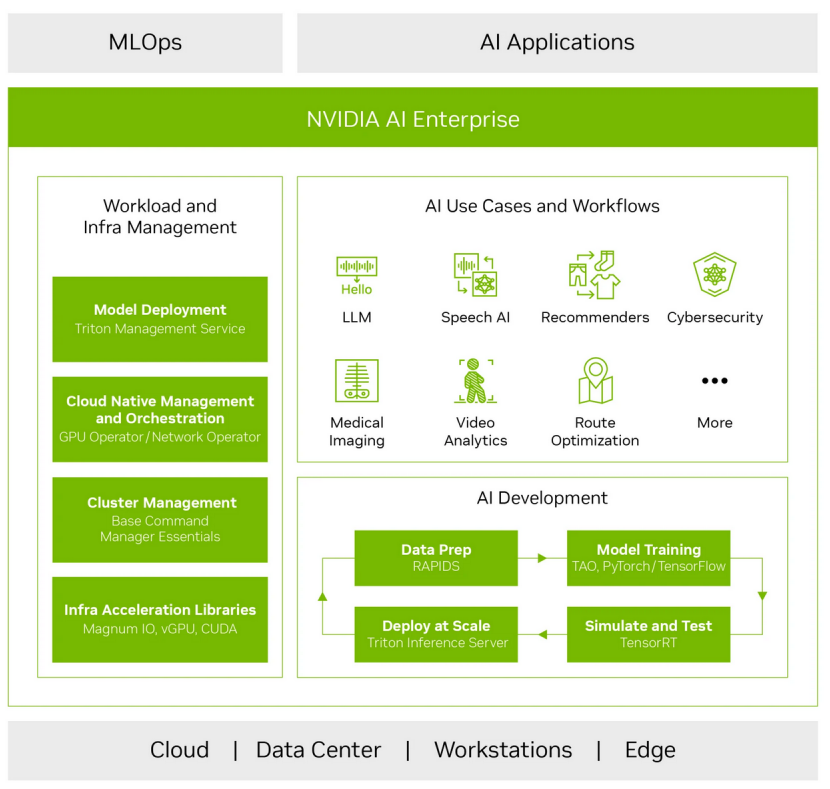
NVIDIA AI Enterprise 平台(图片源于NVIDIA)
Triton 推理服务器提供了标准化的 AI 推理流程,支持部署各种深度学习和机器学习框架的AI模型, 包括 TensorRT、TensorFlow、PyTorch、ONNX、OpenVINO、Python、RAPIDS FIL等 。Triton 推理服务器可以在 NVIDIA GPU、x86 和 ARM CPU 以及 AWS Inferentia 等设备上进行云端、数据中心、边缘和嵌入式设备的推理。
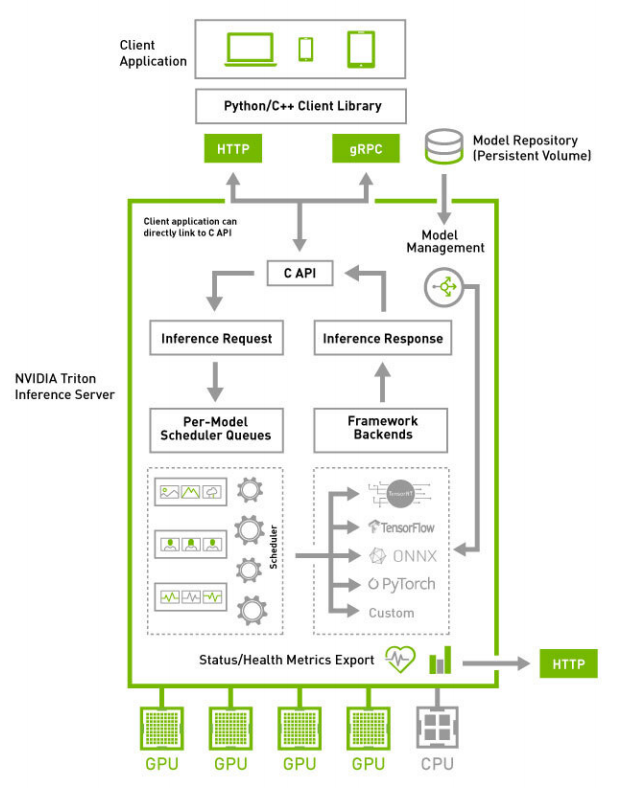
Triton 推理服务器框架(图片源于NVIDIA)
Triton的主要特性包括:
-
支持多种机器学习/深度学习框架
-
并发模型执行
-
动态批处理
-
序列批处理和隐式状态管理用于有状态模型
-
提供后端API,允许添加自定义后端和前/后处理操作
-
使用集成( Ensembles)和业务逻辑脚本( BLS)构建模型Pipeline
-
基于社区开发的KServe协议的HTTP/REST和GRPC推理协议
-
支持C API和Java API直接链接到应用程序
-
指示GPU利用率 、服务器吞吐量 、服务器延迟等指标
Triton 推理服务器对多种查询类型提供高效的推理,支持实时查询、批处理查询、集成模型查询和音视频流查询等。下图示意了使用 Triton 推理服务器在云端、数据中心上部署 AI 生产服务的解决方案。
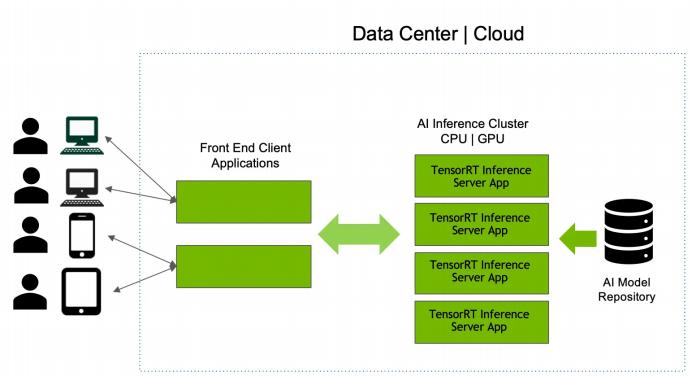
(图片源于NVIDIA)
TensorRT-LLM
2023年10月中旬 NVIDIA 发布了第一版的 TensorRT-LLM,目前更新频繁已经发布了三个版本。它是针对大型语言模型构建最优化的 TensorRT 引擎,以在 NVIDIA GPU 上高效执行推理 。
TensorRT-LLM 包含用于创建执行这些 TensorRT 引擎的 Python 和 C++ 运行时的组件,还包括与 NVIDIA Triton 推理服务器集成的后端,用于提供大模型服务的生产级系统。TensorRT-LLM 支持单个 GPU 到多节点多 GPU 的各种配置环境的使用,同时支持近30余种国内外流行大模型的优化。
TensorRT-LLM 的具体性能可以查看官方性能页面,其优势在一些测试和报道中也已经得到体现:NVIDIA TensorRT-LLM 在 NVIDIA H*GPU (80GB)上大幅提升大型语言模型的推理速度。
TensorRT-LLM 优化特性覆盖了以下几个方面:
1. 注意力优化(Attention Optimizations)
-
Multi-head Attention (MHA):将注意力计算分解为多个头,提高并行性,并允许模型关注输入的不同维度语义空间的信息,然后再进行拼接。
-
Multi-query Attention (MQA):与MHA不同的,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量,提高吞吐量并降低延迟。
-
Group-query Attention (GQA):介于MHA和MQA,将查询分组以减少内存访问和计算,提高效率。
-
In-flight Batching:重叠计算和数据传输以隐藏延迟并提高性能。
-
Paged KV Cache for the Attention :在注意力层中缓存键值对,减少内存访问并加快计算速度。
2. 并行性( Parallelism)
-
Tensor Parallelism :将模型层分布在多个 GPU 上,使其能够扩展到大型模型。
-
Pipeline Parallelism :重叠不同层的计算,降低整体延迟。
3. 量化( Quantization)
-
INT4/INT8 weight-only (W4A16 和 W8A16):将权重存储为 4 位或 8 位整型减少模型大小和内存占用,同时保持激活在 16 位浮点精度。
-
SmoothQuant:为注意力层提供平滑量化,保留准确性。
-
GPTQ:一次性权重量化方法,针对 GPT 类似模型架构量身定制的量化技术,同时保持精度。
-
AWQ:自适应权重量化,动态调整不同部分模型的量化精度,确保高精度和效率。
-
FP8:在支持的 GPU( 如 NVIDIA Hopper)上利用 8 位浮点精度进行计算,进一步减少内存占用并加速处理。
4. 解码优化( Decoding Optimizations)
-
Greedy-search:贪婪搜索,一次生成一个文本令牌,通过选择最可能的下一个令牌,快速但可能不太准确。
-
Beam-search:束搜索,跟踪多个可能的令牌序列,提高准确性但增加计算成本。
5. 其他
-
RoPE (相对位置编码):高效地嵌入令牌的相对位置信息,增强模型对上下文的理解。
能否使用特定优化取决于模型架构、硬件配置和所需的性能权衡,目前最新版本中,并非所有模型都支持上述优化。TensorRT-LLM 提供了一个灵活的框架,可用于尝试不同的优化策略,以实现特定用例的最佳结果。通过一系列的优化技术,能显著提高大语言模型在 NVIDIA GPU 上的性能和效率。
部署实践
1、系统环境
-
CPU: Intel® Xeon® Gold 6326 CPU @ 2.90GHz
-
GPU: NVIDIA GPU (80GB PCIe)
-
Memory: 512GB
-
Host OS:Rocky Linux 8.9
-
GPU Driver:535.129.03
-
Docker:25.0.0
-
Docker Image:nvcr.io/nvidia/tritonserver:23.12-trtllm-python-py3
本次部署主机使⽤NVIDIA 80G GPU单卡,系统为Rocky Linux 8.9,是类似CentOS, RHEL下游的⼀个新发⾏版本,系统的docker容器环境可以参考此链接(Install Docker Engine on CentOS | Docker Docs)配置,使⽤当前最新的NVIDIA官⽅提供的镜像tritonserver:23.12-trtllm-python-py3,此版本镜像部分配置如下,⼏乎包含了运⾏TensorRT-LLM的所有环境,详情请参考此链接:(Release Notes :: NVIDIA Deep Learning Triton Inference Server Documentation)
-
Image Version: 23.12
-
Triton Inference Server: 2.41
-
Ubuntu: 22.04
-
Python: 3.10
-
CUDA Toolkit: 12.3.2
-
TensorRT: 8.6.1.6
-
TensorRT-LLM: release/0.7.0
2、拉取镜像
# host 主机上拉取镜像docker pull nvcr.io/nvidia/tritonserver:23.12-trtllm-python-py3
3、启动容器
# host 主机上启动容器docker run -it -d --cap-add=SYS_PTRACE --cap-add=SYS_ADMIN --security-optseccomp=unconfined --gpus=all --shm-size=16g --privileged -- ulimitmemlock=-1 --name= test -v /home/docker/mnt:/homenvcr.io/nvidia/tritonserver:23.12-trtllm-python-py3
注意:
-
容器挂载模型⽂件所在的主机⽬录
-
先安装NVIDIA Container Toolkit,容器才能使⽤NVIDIA GPU(安装地址:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html)
4、模型准备
本⽂使⽤ Meta 的 llama2-7b-hf ⼤模型作为测试,TensorRT-LLM 对于 LlaMA 的⽀持详情可以查看链接:https://github.com/NVIDIA/TensorRT-LLM/tree/main/examples/llama。
镜像容器中只有运⾏依赖库,类似地TensorRT使⽤时将模型转为 tensorrt 引擎,需要⾃⾏构建不同⼤模型的引擎。我们可以使⽤TensorRT-LLM仓库的LLaMA示例,代码位于:https://github.com/NVIDIA/TensorRT-LLM/tree/main/examples/llama,以模型HF权重作为输⼊,并构建相应的TensorRT引擎,TensorRT引擎的数量取决于⽤于推理的GPU数量。
# 进⼊容器交互式 bashdocker exec -it test bash# 以下命令在容器内操作# 安装 git 和 git-lfsapt-get update && apt-get -y install cmake git git-lfs# 拉取 TensorRT-LLM git 仓库cd /home/git clone https://github.com/NVIDIA/TensorRT-LLM.gitcd TensorRT-LLMgit submodule update --init --recursivegit lfs installgit lfs pull# 下载 Huggingface 上的 LlaMA2-7b-hf 模型GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/meta-llama/Llama-2-7b-hfcd Llama-2-7b-hfgit lfs installgit lfs pull# 编译⽣成 TensorRT-LLM python wheelcd TensorRT-LLM/python ./scripts/build_wheel.py --trt_root /usr/local/tensorrt# 安装 TensorRT-LLM python wheelpip install build/tensorrt_llm-0.7.0-cp310-cp310-linux_x86_64.whl# 安装 Python libs 依赖pip3 install torch torchvision torchaudio# 以下编译构建 enginemkdir trt_engines# 单卡 + INT8 weight-only 量化python TensorRT-LLM/examples/llama/build.py \--model_dir ./models/Llama-2-7b-hf/ \ --dtype float16 \--use_gpt_attention_plugin float16 \--use_weight_only \--output_dir ./trt_engines/Llama-2-7b-hf-WINT8-1gpu/# trt engines ⽂件列表tree trt_engines/ -lh[ 116] trt_engines/|-- [ 98] Llama-2-7b-hf-WINT8-1gpu| |-- [2.1K] config.json| |-- [6.5G] llama_float16_tp1_rank0.engine| `-- [213K] model.cache
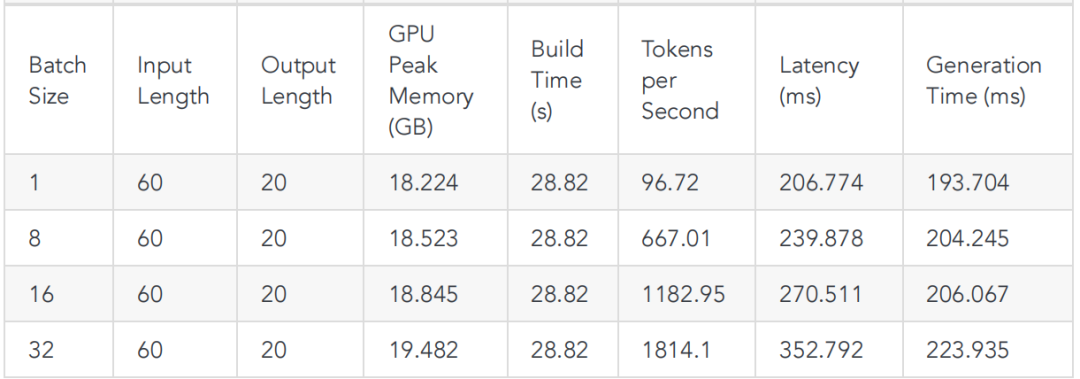
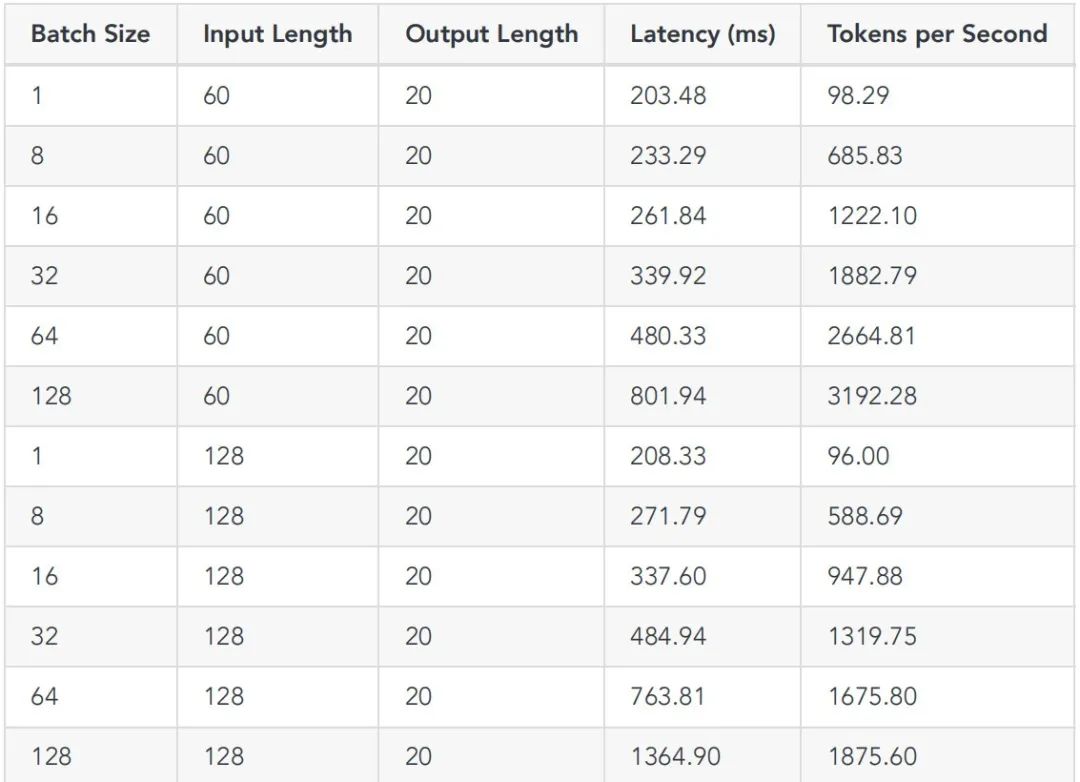
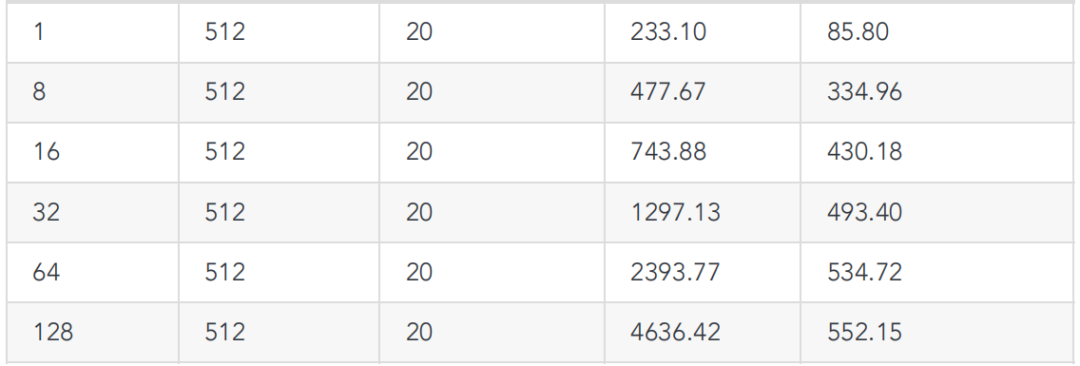
5、Benchmark结果
这⾥顺便跑了 TensorRT-LLM 的 llama2-7b benchmark(python和cpp),结果请看下⾯表格。
# python benchmarkpython3 TensorRT-LLM/benchmarks/python/benchmark.py \-m llama_7b \--mode plugin \--output_dir "./trt_engines/benchmark/" \--batch_size "1;8;16;32;64;128" \--input_output_len "60,20;128,20;512,20"# cpp benchmark./TensorRT-LLM/cpp/build/benchmarks/gptSessionBenchmark \--model llama_7b \--engine_dir "trt_engines/benchmark/" \--batch_size "1;8;16;32;64;128" \--input_output_len "60,20;128,20;512,20"
-
python


-
cpp
我们构建了⼀种 Llama-2-7b-hf 模型的针对单卡GPU和仅权重INT8量化的优化引擎。接下来根据 tensorrtllm_backend 模型库模板⽂件夹配置模型:
git clone https://github.com/triton-inference-server/tensorrtllm_backendmkdir triton_model_repo/Llama-2-7b-hf-WINT8-1gpucp -r tensorrtllm_backend/all_models/inflight_batcher_llm/*triton_model_repo/Llama-2-7b-hf-WINT8-1gpu# 以 Llama-2-7b-hf-WINT8-1gpu 为例# 拷⻉ engine ⽂件到 triton_model_repocp ./trt_engines/Llama-2-7b-hf-WINT8-1gpu/* triton_model_repo/Llama-2-7b-hfWINT8-1gpu/tensorrt_llm/1
模型库中的每个模型都必须包含⼀个模型配置,该配置提供有关模型的必需和可选信息。通常,这个配置以ModelConfig protobuf指定的config.pbtxt⽂件形式提供。在某些情况下,可以通过Triton⾃动⽣成模型配置,不需要显式提供。不同的配置参数可能会对模型的性能有较⼤差异,可以借助https://github.com/triton-inference-server/model_analyzer搜索到最佳的参数,有兴趣的可以⾃⾏深⼊学习。
此外 triton server 部署中还有很多可调的细节设置来优化性能和便利性,⽐如:全局或模型的响应缓存(global or model specific response cache),模型轮询间隔(model poll interval),模型预热(model warmup),模型实例(model instances)等。
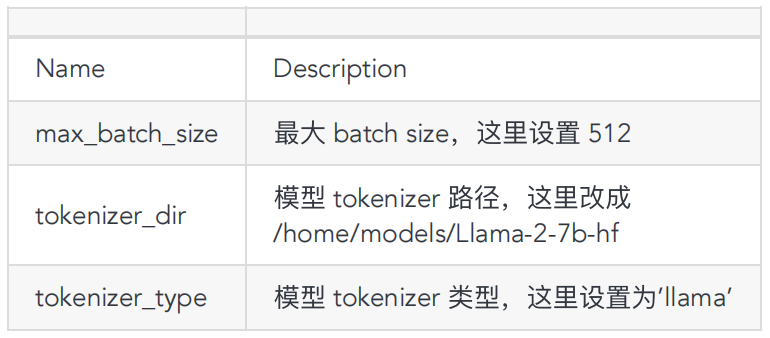
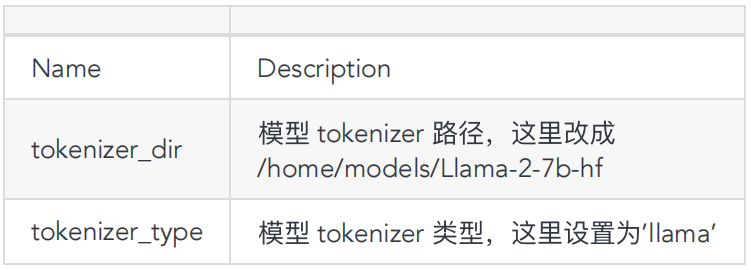
编辑相关的 config.pbtxt ,主要参数保持默认,参数调整请参考⽂档(https://github.com/triton-inference-server/tensorrtllm_backend):
-
triton_model_repo/Llama-2-7b-hf- WINT8-1gpu/preprocessing/config.pbtxt
-
triton_model_repo/Llama-2-7b-hf-WINT8-1gpu/tensorrt_llm/config.pbtxt

-
triton_model_repo/Llama-2-7b-hf-WINT8-1gpu/postprocessing/config.pbtxt
6、启动 tritonserver
tritonserver --model_repo /home/triton_model_repo/Llama-2-7b-hf-WINT8-1gpu --allow-metrics true --allow-grpc true --allow-http true &# 开启服务后,命令⾏会显示相关后端、模型、配置和硬件信息I0125 09:01:53.748648 73097 server.cc:633]+-------------+----------------------------------------------------------------+----------------------------------------------------------------+| Backend | Path| Config |+-------------+----------------------------------------------------------------+----------------------------------------------------------------+| python | /opt/tritonserver/backends/python/libtriton_python.so| { "cmdline" :{ "auto-complete-config" : "true" , "backend-directory" : || || "/opt/tritonserver/backends" , "min-compute-capability" : "6.00000 || || 0" , "default-max-batch-size" : "4" }} || tensorrtllm |/opt/tritonserver/backends/tensorrtllm/libtriton_tensorrtllm.s | { "cmdline" :{ "auto-complete-config" : "true" , "backend-directory" : || | o| "/opt/tritonserver/backends" , "min-compute-capability" : "6.00000 || || 0" , "default-max-batch-size" : "4" }} || || | +-------------+----------------------------------------------------------------+----------------------------------------------------------------+I0125 09:01:53.748679 73097 server.cc:676]+------------------+---------+--------+| Model | Version | Status |+------------------+---------+--------+| ensemble | 1 | READY || postprocessing | 1 | READY || preprocessing | 1 | READY || tensorrt_llm | 1 | READY || tensorrt_llm_bls | 1 | READY |+------------------+---------+--------+I0125 09:01:53.949752 73097 metrics.cc:817] Collecting metrics for GPU 0:NVIDIA A100 80GB PCIeI0125 09:01:54.000065 73097 metrics.cc:710] Collecting CPU metricsI0125 09:01:54.000192 73097 tritonserver.cc:2483]+----------------------------------+------------------------------------------------------------------------------------------------------------+| Option | Value|+----------------------------------+------------------------------------------------------------------------------------------------------------+| server_id | triton|| server_version | 2.41.0|| server_extensions | classification sequencemodel_repository model_repository(unload_dependents) schedule_policymodel_configu || | ration system_shared_memorycuda_shared_memory binary_tensor_data parameters statistics trace logging|| model_repository_path[0] | /home/triton_model_repo/Llama-2-7b-hfWINT8-1gpu|| model_control_mode | MODE_NONE|| strict_model_config | 0|| rate_limit | OFF| | pinned_memory_pool_byte_size | 268435456|| cuda_memory_pool_byte_size{5} | 67108864| min_supported_compute_capability | 6.0|| strict_readiness | 1|| exit_timeout | 30|| cache_enabled | 0|+----------------------------------+------------------------------------------------------------------------------------------------------------+I0125 09:01:54.001568 73097 grpc_server.cc:2495] StartedGRPCInferenceService at 0.0.0.0:8001I0125 09:01:54.001754 73097 http_server.cc:4619] Started HTTPService at0.0.0.0:8000I0125 09:01:54.042876 73097 http_server.cc:282] Started Metrics Service at0.0.0.0:8002# 显存加载情况nvidia-smi+---------------------------------------------------------------------------------------+| NVIDIA-SMI 535.129.03 Driver Version: 535.129.03 CUDAVersion: 12.2 ||-----------------------------------------+----------------------+----------------------+| GPU Name Persistence-M | Bus-Id Disp.A | VolatileUncorr. ECC || Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-UtilCompute M. || | |MIG M. ||=========================================+======================+======================|| 0 NVIDIA A100 80GB PCIe Off | 00000000:4F:00.0 Off |0 || N/A 30C P0 63W / 300W | 18739MiB / 81920MiB | 0%Default || | |Disabled | +-----------------------------------------+----------------------+----------------------++---------------------------------------------------------------------------------------+| Processes:|| GPU GI CI PID Type Process nameGPU Memory || ID IDUsage ||=======================================================================================|| 0 N/A N/A 1446460 C tritonserver18726MiB |+---------------------------------------------------------------------------------------+
注意:
构建引擎时使⽤的TensorRT-LLM版本必须与tritonserver的TensorRT-LLM版本保持⼀致。
7、客户端测试
-
HTTP客户端测试:
curl -X POST localhost:8000/v2/models/ensemble/generate -d '{"text_input":"What is machine learning?", "max_tokens": 20, "bad_words": "","stop_words": "", "pad_id": 2, "end_id": 2}'{ "cum_log_probs" :0.0, "model_name" : "ensemble" , "model_version" : "1" , "output_log_probs" :[0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0], "sequence_end" : false , "sequence_id" :0, "sequence_start" : false , "text_output" : "What is machine learning? | Machine Learning\nMachine learning is atype of artificial intelligence that involves training algorithms on datain" }
-
GRPC 客户端测试:
如果使⽤客户端的Streaming选项,则必须先更改模型 tensorrt_llm/config.pbtxt 设置将“Decoupled” 设置为 “True”,然后重启tritonserver服务。
cd /home/tensorrtllm_backend/inflight_batcher_llm/clientpython3 end_to_end_grpc_client.py --streaming --output-len 10 --prompt "Whatis machine learning?" "What is machine learning? | Machine Learning\nMachine learning is a type ofartificial intelligence that involves training algorithms on data in"
另外对于语⾔⼤模型的推理官⽅也推出了⼀个集成了vllm的triton server镜像,⼤家有兴趣可以尝试⽐较。
到这⾥完成了使⽤ triton server 以及 tensorRT-LLM 作为推理后端的服务部署和客户端利⽤ LlaMA2⼤语⾔模型的推理应⽤,这类推理应⽤可以扩展到其他领域的模型⽐如⽬标检测、图像识别等。

