
- 1记一次因敏感信息泄露而导致的越权+存储型XSS_鹰图平台如何搜索学校网站
- 2Flink 必知必会:Flink Runtime Architecture
- 3使用GPU跑包工具
- 4常见的数据结构面试题_常见数据结构面试题
- 5App测试之App日志收集及adb常用命令_android日志收集工具
- 6快速定位线上慢 SQL 问题,掌握这几个性能排查工具可助你一臂之力_检查sql语句慢的工具
- 7mysql signed unsigned zerofill详解_unsigned、signed、zerofill
- 8WPF 路由事件(RoutedEventArgs 路由事件参数、 RoutedEvent 路由事件、RoutedEventHandler路由事件处理程序、RaiseEvent引发路由事件)
- 9windows和mac详细图文安装charles_mac安装charles证书
- 10SpringCloud集成RabbitMQ_spring cloud集成rabbitmq
电商数据分析3_数据分析方法
赞
踩
00. 方法和使用场景
| 分析方法 | 使用场景 |
|---|---|
| 对比法 | 发现问题:只有通过参照物的对比才能了解现状和发现问题,通过横向和纵向的对比找自己所处的位置 |
| 拆分法 | 寻找问题的原因:将大问题和相关的指标拆解成多个小问题和多个相关指标,通过拆解问题和指标可以快速找到问题产生的原因 |
| 排序法 | 找到分析的重点:基于某个度量值进行递增或递减的排列,通过排序后的结果查看所有观测值的情况 |
| 分组法 | 洞察事物特征:将数据依据某些维度进行分组统计,通过观察分组后的结果洞察事物的特征 |
| 交叉法 | 将两个及以上的维度进行比较,并通过交叉的方式分析数据,比如通过产品特征和价格区间两个维度交叉分析,找到更符合企业定位的细分市场。 |
| 降维法 | 解决复杂问题:分析问题时指标的信息量过多,采用业务梳理的方式选择核心指标进行分析。减少过多指标的干扰。主成分分析或因子分析 |
| 增维法 | 解决信息量过少的问题:分析问题时指标的信息量不足,通过计算,派生出新的指标,包含了更多的信息量,比如搜索竞争度=搜索人气-商品数 |
| 指标法 | 基本方法,可支持多字段:在分析时采用指标的方式分析结果,一般通过制成表格来查看分析结果。 |
| 图形法 | 对分析字段有数量限制:在分析时采用图形的方式更加直观地分析结果 |
| SWOT分析法 | 通过该方法了解自己所处的环境,对内外部因素进行分析并制订应对策略 |
| 描述性统计法 | 描述性统计是用来概括、表述事物整体状况以及事物间关联、类属关系的统计方法,基于统计值来表示数据集的集中和离散等情况。 |
| 数据标准化 | 将数值映射在[0,1]的范围上,消除因为值域不同产生的分析难点,一般配合多维分析法或在数据建模时使用。 |
| 熵值法 | |
| 漏斗分析法 | 流程式分析模型,本质上通过数据流程的变化来控制结果。 |
| 矩阵分析法 | 将主要因素放在矩阵的两个维度轴进行定量或者定性的分析,并通过某个点将数据分为四个象限。 |
| 多维分析法 | 将三个及以上的维度在表格、多维平面图或者三维图中进行观测分析。 |
| 时间序列分析法 | 针对连续变化的时间数据的分析方法,主要用于预测连续的未来数据比如分析店铺每天的销售额。 |
| 相关性分析法 | 研究指标间的相关程度,常用于寻找关键影响因素。 |
| 杜邦分析法 | |
| 假设法 | 从结果倒推原因,通过逆向思维进行推导。抽丝剥茧 寻找最佳方案 |
| 聚类分析法 | 将抽象的数据按照类似的对象进行分析 |
按照,方法说明+案例形式归纳汇总
1. 对比法
- 三个维度:过去的自己、同期的对手和同期的行业。对比法还分为横向和纵向:
- 横向对比:跨维度对比,比如分析企业销售业绩的时候,将不同行业的企业销售业绩一起对比,可知企业在整个市场的地位。500强企业排行榜(产值)
- 纵向对比:同一纬度不同阶段对比,比如基于时间维度,将今天的销售业绩和昨天、上个星期同一天对比。
eg:销售A/B/C/D四个品类,通过对比A/B/C/D四个品类销售额的最大值,要做市场规模则选择销售额高的品类,便于生存则选择销售额低的品类。
2. 拆分法
- **分为完全拆分法和重点拆分法。**拆分法是将某个问题拆解成若干个子问题,通过研究若干子问题从而找到问题的症结点并解决问题。
- 完全拆分法:等额拆分,将父问题100%进行拆解。如销售额=访客数x转化率x客单价,等式两边完全相等。
- 重点拆分法:非等额拆分,只拆分出问题的重点,子问题只解释父问题的80%左右。做好网点=点击率+转化率+退款率。
eg: 研究销售业绩下降问题,可以将销售业绩问题拆分为转化率、客单价和访客数这三个子问题。
3. 排序法
基于某个指标或度量值的大小,将观测值进行递增或递减排列。
eg: 百度搜索风云榜、阿里排行榜等
4. 分组法
可以按照类型、结构、时间阶段等维度进行分组,观察分组后的数据特征,从特征中洞察信息。
5. 交叉法
交叉法是对比法和拆分法的结合。将有一定关联的两个或两个以上的维度或度量排列在统计表内进行对比分析。
6. 降维法
数据集指标过多,或者干扰因素太多,通过找到并分析核心指标提高分析精度。主成分分析法、因子分析等。
eg: 评估店铺综合情况。将指标按照产品运营能力、店铺获客能力和店铺服务能力拆分:
- 产品运营能力:动销率、连带率、上新率
- 店铺获客能力:转化率、销售额、客单价、访客数
- 店铺服务能力:好评率、纠纷率
7. 增维法
在数据集的字段过少或信息量不足的时候,通过计算衍生出更加直观的指标
eg: 计算关键词的竞争度
竞争度 = 搜索人气X点击率X支付转化率÷在线产品数
- 1
该指标为正指标,数值越大越好。
8. 指标法
通过汇总值、平均值、标准差等统计指标研究分析数据。
9. 图形法
eg: 直方图,可以直观观察各个价格区间包含商品的个数,售价集中区域
10. SWOT分析法
SWOT分析,态势分析法,基于市场营销方法论,研究内部优势劣势 外部机会或威胁。
- 内部因素: 对企业内部的管理、团队、产品和市场营销情况进行分析
- 外部因素:对企业外部的环境、政策和竞争对手进行分析
eg:
| 优势(Strengths) | 劣势(Weaknesses) |
|---|---|
| 1.店铺开发能力强 | 1.公司管理方面不是很完善 |
| 2.服务消费者的能力强 | 2. 库存能力不强,常断货 |
| 3.能够把控品质 | 3. 公司内部人员竞争 |
| 4.公司的财务状况非常好 | 4.店铺定位不明确 |
| 5.开发消费者能力弱 |
| 机会(Opportunities) | 威胁(Threats) |
|---|---|
| 1. 市场杠杆很少,明确定位的店铺很少 | 1.竞争 |
| 2. 市场需求大幅增长 | 2. 同质化严重 |
| 3. 普遍不重视用户体验 | 3. 盗图 |
| 4.个性化 | 4. 大商家新入驻 |
基于内外因素的应对策略:当优势遇到机会 采取发展策略;当优势遇到威胁 财务拓展策略;当劣势遇到机会 采取争取的策略;当劣势遇到威胁 采取保守的策略。
eg:
| 优势(Strengths) | 劣势(Weaknesses) | |
|---|---|---|
| SO(发展) | WO(争取) | |
| 机会 | 1.结合市场情况,在自身开发能力的基础上,找到明确的定位,增加消费者粘性,提高复购率 | 1. 提升管理能力,让指令可以上行下效 |
| – | 2.提升消费者体验 | 2. 合理使用ERP系统进行管理,严格把控库存仓位 |
| – | 3.开发更多新品迎合市场需求 | 3.设定良性竞争机制 |
| – | 4. 精准定位消费人群 | |
| – | 5.制定推广方案,吸引更多消费者 | |
| ST(拓展) | WT(保守) | |
| 威胁 | 1. 提升店铺形象(口碑) | 1.保持店铺的独特风格,不被外界影响 |
| – | 2. 开发团队把控市场需求走向,避免同质化 | 2.加强CRM管控 |
| – | 3.结合公司的自主研发,提升公司版权保护意识 | |
| – | 4.精准定位消费者 |
11. 描述性统计法
了解数据集的字段、数据分布等。
-
五数概况法:最小值、1/4位数、中位数、3/4位数和最大值
-
计数、汇总和平均
-
标准差
标准差 = √((Σ(xi - x̄)²) / N)
Σ 表示求和符号;
xi 表示第 i 个数据点;
x̄ 表示数据集的平均值;
N 表示数据集中的总数据点数。标准差的值越大,数据集中的数据分散程度就越高;标准差的值越小,数据集中的数据分散程度就越低。
-
变异系数
CV = (标准差 / 平均值) * 100%
CV表示变异系数,标准差是数据的离散程度的度量,平均值是数据的集中趋势的度量。
变异系数的值越小,表示数据的离散程度越低,反之,值越大表示数据的离散程度越高。因为变异系数使用了相对度量,所以可以用来比较不同单位或量级的数据的离散程度。
12. 数据标准化
-
min-max标准化(离差标准化)
MinMax标准化是一种数据预处理方法,用于将数据缩放到一个指定的范围(通常是0到1之间)
z = (x - min) / (max - min) -
Z-score标准化
适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据。
Z-score标准化是一种常用的数据标准化方法,也称为标准差标准化。它通过将数据转化为其标准正态分布的值,使得数据的均值为0,标准差为1。
具体步骤如下:-
计算数据的均值和标准差。
-
对每个数据点,将其减去均值,再除以标准差,得到标准化的值。
-
标准化后的数据的均值为0,标准差为1。
数学公式如下:z = (x - μ) / σ
其中,z为标准化后的值,x为原始数据,μ为数据的均值,σ为数据的标准差。
Z-score标准化可以使得不同指标的数据具有可比性,方便进行数据分析和处理。它常用于机器学习算法中,例如K-means聚类、支持向量机等。
-
- 按小数定标标准化
12. 熵值法
在信息论中,熵是对不确定性的一种度量。信息量越大,不确定性越小。
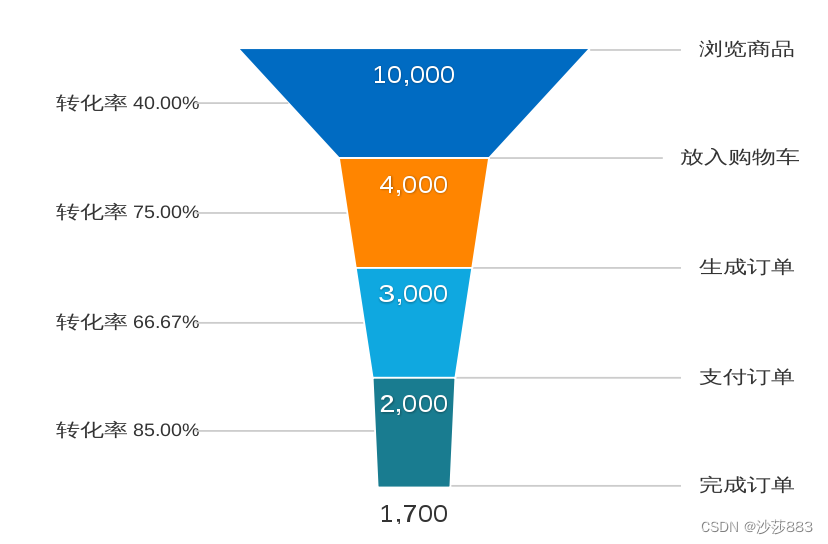
13. 漏斗分析法
漏斗分析法是结合了流程分析的方法,更强调时间的发展过程。广泛应用于网站用户行为分析和App用户行为分析的流量监控、产品目标转化等
步骤:
① 确定业务流程,各个环节的量纲必须一致
②确定数据
③画图
- 1
- 2
- 3
- 4
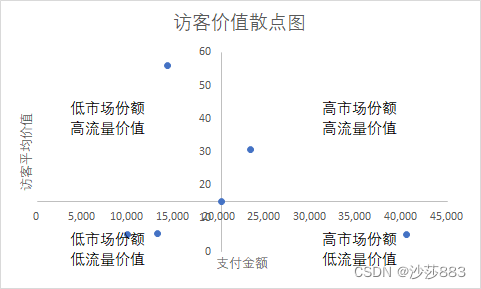
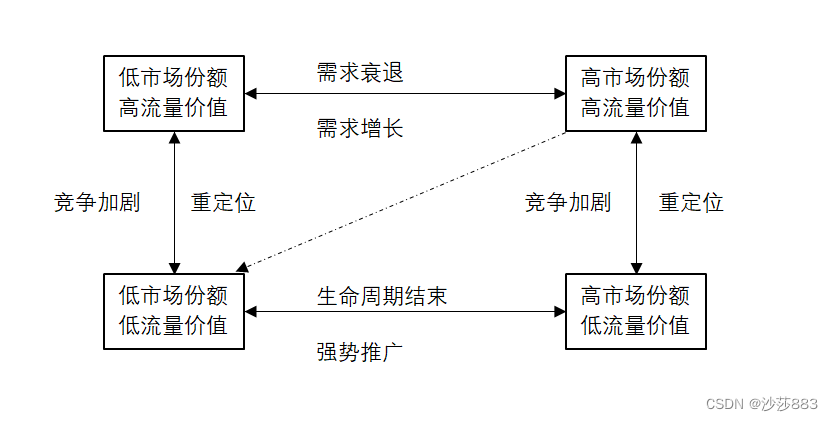
14. 矩阵分析法
15. 多维分析法
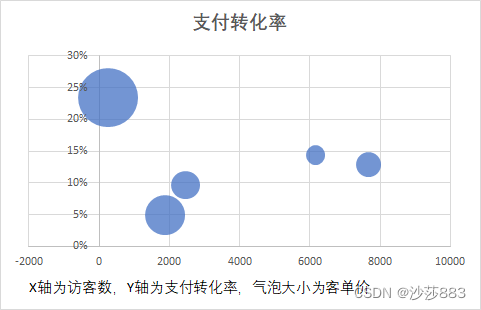
多维分析法是分析多个指标的方法。再许多复杂的业务场景下,降维后仍存在多个指标,对多个维度进行分析的方法,就是多维分析法。
-
三维气泡图
三维气泡图是在二维平面图上展示三个维度
-
雷达图
以同一点开始的轴上表示的三个或更多个定量变量的二维图标的形式展示多变量。

16. 时间序列分析法
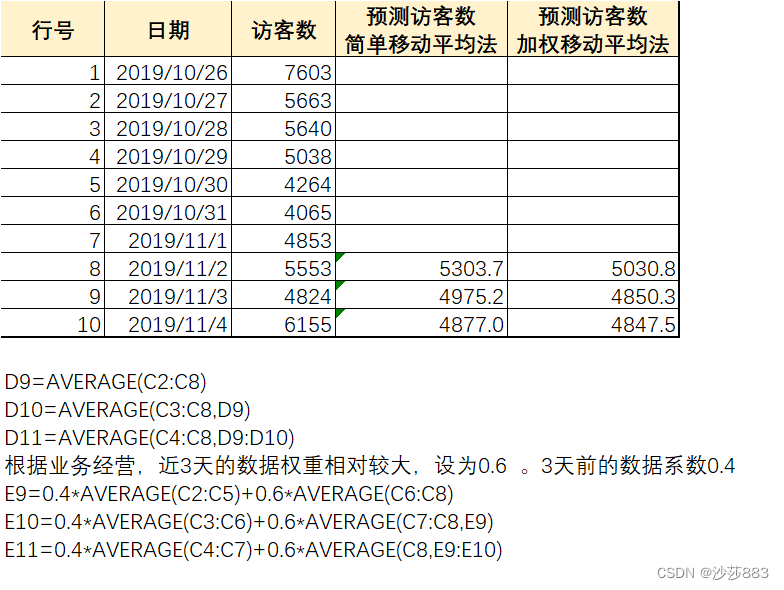
-
移动平均法
移动平均法是用一组最近的实际数据值来预测未来一期或几期内公司产品的需求量、公司产能等的常用方法。移动平均法适用近期预测。-
简单移动平均法
简单移动平均法的各园区的权重都相等。计算公式:Ft = [(At-1)+(At-2)+(At-3)+…+(At-n) ]/n
Ft :对下一期的预测值 n:移动平均的时期个数 At-1:前期实际值 At-2、At-3和At-n分别表示前两期、前三期直至前n期的实际值。- 1
- 2
- 3
- 4
-
加权移动平均法
加权移动平均法给固定跨越期限内的每个变量值以不同的权重。其原理是:历史各期产品需求的数据信息对预测未来期内需求量的作用是不一样的。除了以n为周期的周期性变化外,原理目标期的变量值的影响力相对较小,给予较低的权重。[ X t = ∑ i = 1 n w i ⋅ X t − i + 1 ] [ X_t = \sum_{i=1}^{n} w_i \cdot X_{t-i+1} ] [Xt=∑i=1nwi⋅Xt−i+1]
其中,(X_t)是时刻t的加权移动平均值,(X_{t-i+1})是时刻t-i+1的观测值,(w_i)是权重,n是移动平均的窗口大小
-
-
指数平滑
-
一次指数平滑
当时间数列无明显的趋势变化时,可用一次指数平滑法,其公式:
y t + 1 = a Y t + ( 1 + a ) y t y^{t+1} = aY_t + (1+a)y^{t} yt+1=aYt+(1+a)yty t + 1 y^{t+1} yt+1 :t+1期的预测值,即本期(t期)的平滑值
a a a :阻尼系数
Y t Y_t Yt :t 期的实际值
y t y^{t} yt :t 期的预测值,即上期的平滑值若时间序列的观察期n大于15时,初始值对预测结果的影响很小,可以方便地以第一次观测值作为初始值;若观察期n小于15,初始值对预测结果影响较大,可以取最初几期的平均值作为初始值,通常取前三期。
一次指数平滑法的局限性:只适用于水平型历史数据的预测,不适用于呈斜坡型线性趋势历史数据的预测。 -
二次指数平滑法
二次指数平滑是在一次指数平滑的基础上再平滑。
F t + T = a t + b t T F_{t+T} = a_t + b_t^{T} Ft+T=at+btT
F t + T F_{t+T} Ft+T: t+T期的预测值
T T T: 预测步长即需要预测的期数与当前期数的间隔
a t 、 b t a_t 、b_t at、bt: 参数
a t = 2 S t ( 1 ) − S t ( 2 ) a_t = 2S_t^{(1)} -S_t^{(2)} at=2St(1)−St(2):
b t = a / ( 1 − a ) ( 2 S t ( 1 ) − S t ( 2 ) ) b_t = a/(1-a)(2S_t^{(1)} -S_t^{(2)}) bt=a/(1−a)(2St(1)−St(2)):
S t ( 1 ) S_t^{(1)} St(1): 第一次平滑的预测值
S t ( 2 ) S_t^{(2)} St(2): 第二次平滑的预测值
很好,看迷糊了,会的也不会了,这部分后续更新
-
高次指数平滑预测法
pass
-
17. 相关性分析法
相关性可以研究数值和数值之间的关系,可以研究数值和分类之间的关系,可以研究分类和分类之间的关系
| 研究类型 | 指标 | 值的范围 | 计算公式 |
|---|---|---|---|
| 数值和数值 | 相关系数 | -1~1 | CORREL |
| 数值和分类 | 相关比 | 0~1 | |
| 分类和分类 | 克莱姆关系数 | 0~1 |
-
相关系数
r = Cov(X, Y) / (σX * σY)
其中,Cov(X, Y)表示变量X和Y的协方差,σX和σY分别表示变量X和Y的标准差。通过计算协方差和标准差,我们可以得到两个变量之间的相关系数。
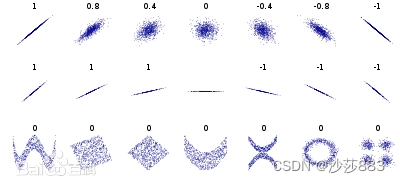
| 相关系数的绝对值 | 定义 |
|---|---|
| 0.9~1 | 强相关 |
| 0.7~0.9 | 中相关 |
| 0.5~0.7 | 弱相关 |
| 0~0.5 | 不相关 |
https://zhuanlan.zhihu.com/p/676392044
-
相关矩阵
相关矩阵也叫做相关系数矩阵,是由矩阵各列间的相关系数构成。也就是说,相关矩阵第i行第j列的元素是原矩阵第i列和第j列的相关系数。
18. 杜邦分析法
杜邦分析法原理:利用集中主要财务比率之间的关系来综合分析企业的财务状况。基本思想是将企业净资产收益率逐级分解为多项财务比率的乘机。
eg:
树状图的替代画法:
参考文献:
[1]陈海城.Excel电商数据分析与应用.图书目录[M].北京:人民邮电出版社,2021:26-53

