
R语言一元时间序列建模:ARIMA模型(手动定阶)_arima 基于r语言
赞
踩
传统时间序列主要针对平稳序列进行建模,因为趋势性(如长期趋势,季节趋势)在前期建模过程中已经剔除,我们需要深入挖掘剔除趋势性后的部分之间的线性影响关系。故本案例采用R语言自带的数据集“Nile”:包含了1898年到1958年间,每年尼罗河水位的数据集。
- library (PerformanceAnalytics)
- library(tseries)
- library(forecast)
- library(datasets)
- data("Nile")
- head(Nile)
若数据为其他类型,先将数据转换为时间类型,可以采用lubridate包里dmy函数或PerformanceAnalytics包里的as.Date(data$Years,“%d/%m/%Y”)进行转换,转换完成后用class命令查看数据是否为时间序列类型。
class(Nile)- plot.zoo(Nile, main = "1898年到1958年尼罗河水位", xlab =
- "Time", ylab = "尼罗河水位", lwd = 2, col = "blue")
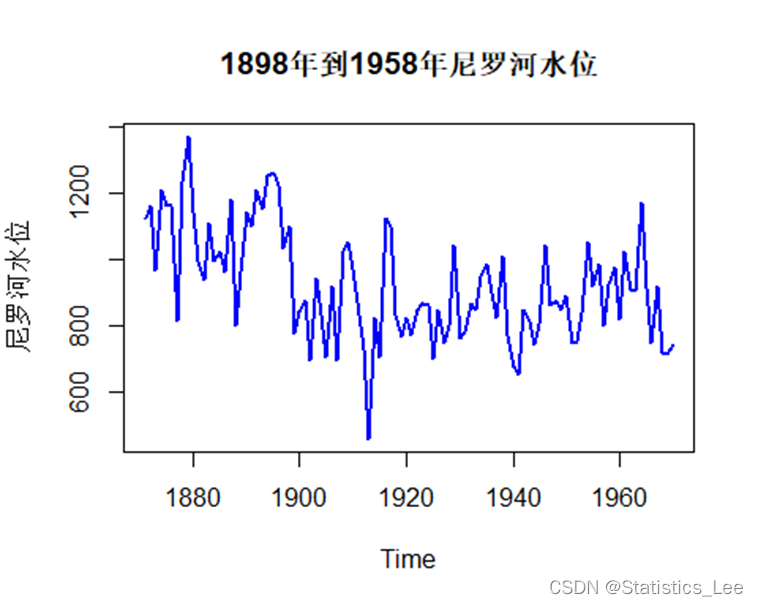
从上图我们发现尼罗河水位明显不平稳,所以该序列不是平稳时间序列。
平稳性检验
即使我们从上图中看出尼罗河水位非平稳,我们仍旧需要通过ADF(Augmented Dicky Fuller)检验或者pp(Phillips-Perron Unit Root)检验,更加客观的检验时间序列是否平稳。
- library(tseries)
- #ADF unit root test
- adf.test(Nile, alternative = c("stationary"))
- ##
- ## Augmented Dickey-Fuller Test
- ##
- ## data: Nile
- ## Dickey-Fuller = -3.3657, Lag order = 4, p-value = 0.0642
- ## alternative hypothesis: stationary
- ##Phillips-Perron Unit Root Test
- #PP.test(Nile)
我们来看上述假设检验的结果,上述ADF检验方法的p-value>0.05,没有拒绝原假设,所以我们认为原时间序列非平稳。
可以考虑差分或取对数方式使得时间序列变平稳。
- Nile1 <- diff(Nile,1)
- plot.zoo(Nile1,lwd = 2, col = "blue")
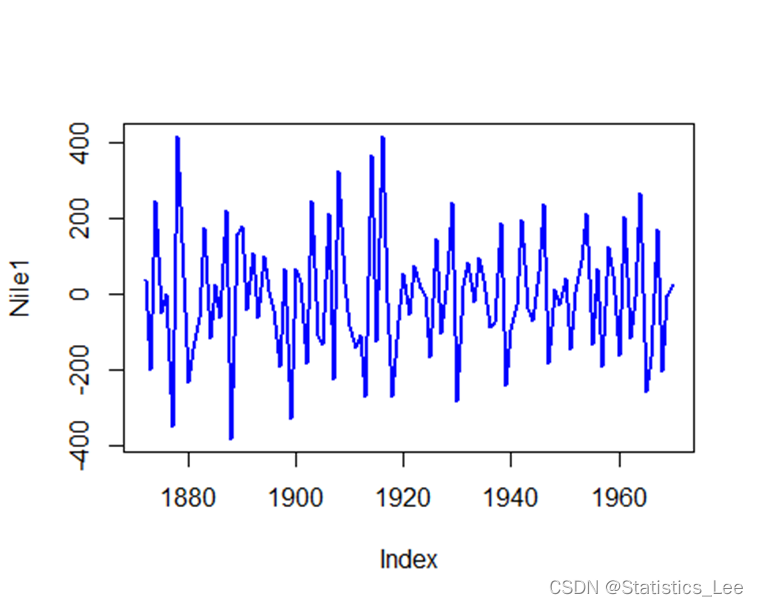
自相关性检验
我们将会通过Ljung Box test来判断序列有无自相关性,若无自相关性,说明线性模型无法挖掘信息,为白噪声过程,停止线性时间序列建模。并且我们会绘制序列的ACF和PACF图来辅助判断序列有无自相关性,判断使用AR还是MA模型并定阶,亦或者使用ARMA模型。
- #acf图
- acf(Nile1, lag.max = 30, main = "ACF of AirPassengers")

- #pacf图
- pacf(Nile1)

- #Ljung Bob 检验
- Box.test(Nile1, lag = 20, type = c("Ljung-Box"), fitdf = 0)
- ##
- ## Box-Ljung test
- ##
- ## data: Nile1
- ## X-squared = 37.208, df = 20, p-value = 0.01105
注:时间序列数据中存在季节性因素时,滞后阶数可能显示是分数.
从acf图中我们可以看出,1阶后截尾
从pacf图中我们可以看出,除了1,2,7,10个偏自相关系数显著外,其余均落在虚线内部(虚线是偏自相关系数95%的置信区间),说明时间序列的pacf存在截尾性质
从Ljung Box test的自相关性检验,我们发现其p-value=0.01105,拒绝原假设,说明时间序列存在自相关性,不是白噪声,可以用线性时间序列模型建模
模型定阶
AR(p):acf 拖尾,pacf p阶截尾
MA(q):acf q阶截尾,pacf 拖尾
ARMA(p,q):acf和pacf一般拖尾,可采用信息准则进行定阶段
从上图中我们可以看出acf截尾,pacf截尾,可以考虑先采用MA(1)模型进行建模
拟合MA(1)
- MA <- arima(Nile1,order = c(0,0,1))
- print(MA)
- ##
- ## Call:
- ## arima(x = Nile1, order = c(0, 0, 1))
- ##
- ## Coefficients:
- ## ma1 intercept
- ## -0.7646 -3.2583
- ## s.e. 0.1205 3.5165
- ##
- ## sigma^2 estimated as 20416: log likelihood = -632.15, aic = 1270.31
残差的白噪声检验
若拟合模型的残差为白噪声,说明模型拟合较好,剩余部分无线性信息继续挖掘
- library(forecast)
- checkresiduals(MA)
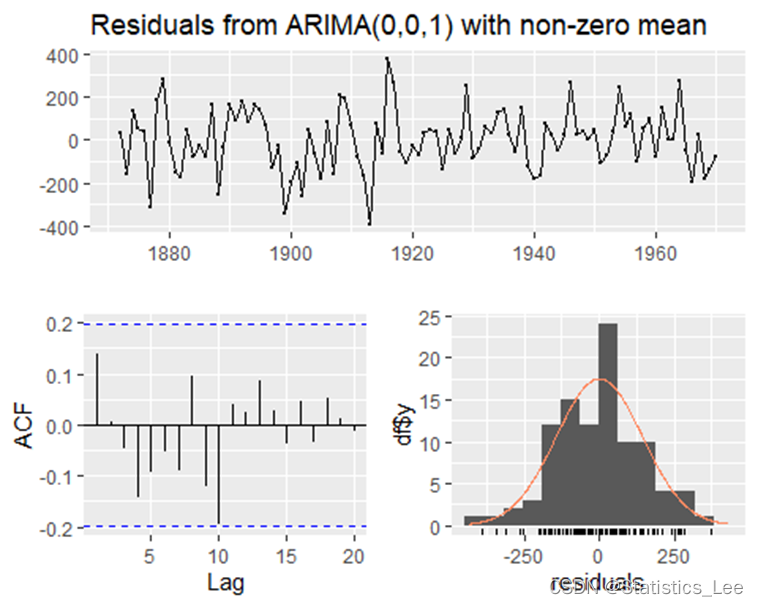
##
## Ljung-Box test
##
## data: Residuals from ARIMA(0,0,1) with non-zero mean
## Q* = 13.448, df = 9, p-value = 0.1434
##
## Model df: 1. Total lags used: 10
从上述检验可以看出p-value = 0.1434,说明残差序列为白噪声,可以建立MA(1)模型,但这并不代表MA(1)是最适合此时间序列的模型
拟合AR(1)模型
- AR <- arima(Nile1,order = c(1,0,0))
- print(AR)
- ##
- ## Call:
- ## arima(x = Nile1, order = c(1, 0, 0))
- ##
- ## Coefficients:
- ## ar1 intercept
- ## -0.3984 -4.0514
- ## s.e. 0.0915 11.0386
- ##
- ## sigma^2 estimated as 23455: log likelihood = -638.67, aic = 1283.35
- checkresiduals(AR)
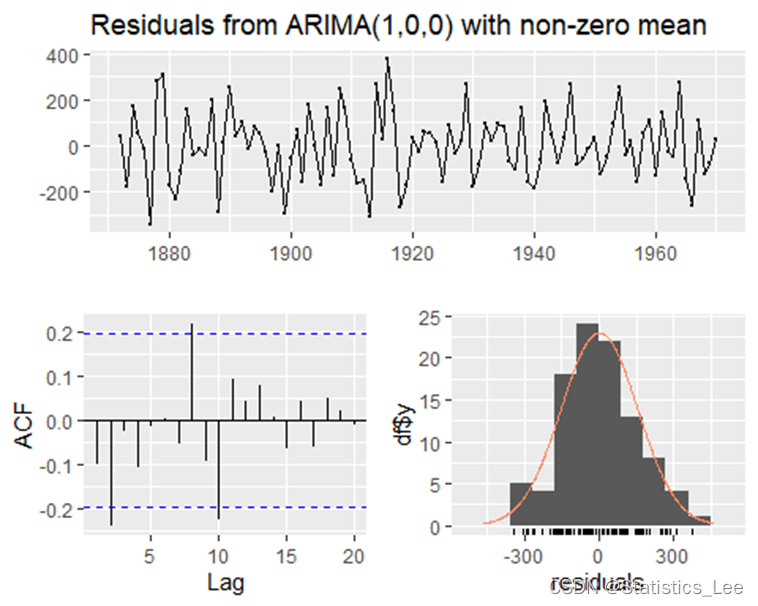
##
## Ljung-Box test
##
## data: Residuals from ARIMA(1,0,0) with non-zero mean
## Q* = 20.54, df = 9, p-value = 0.01486
##
## Model df: 1. Total lags used: 10
从上述检验可以看出p-value < 0.05,说明残差序列不是白噪声,不适合拟合AR(1)模型
拟合AR(2)模型
- AR2 <- arima(Nile1,order = c(2,0,0))
- print(AR2)
- ##
- ## Call:
- ## arima(x = Nile1, order = c(2, 0, 0))
- ##
- ## Coefficients:
- ## ar1 ar2 intercept
- ## -0.4965 -0.243 -3.8844
- ## s.e. 0.0971 0.097 8.6263
- ##
- ## sigma^2 estimated as 22035: log likelihood = -635.64, aic = 1279.28
- checkresiduals(AR2)
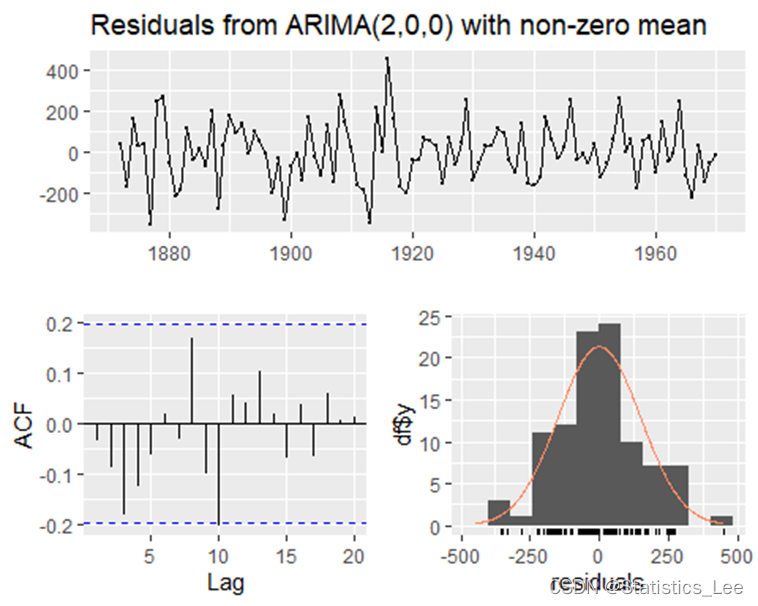
##
## Ljung-Box test
##
## data: Residuals from ARIMA(2,0,0) with non-zero mean
## Q* = 15.203, df = 8, p-value = 0.05531
##
## Model df: 2. Total lags used: 10
从上述检验可以看出p-value 勉强> 0.05,说明残差序列是白噪声,也可以拟合AR(2)模型
拟合ARMA(1,1)模型
- ARMA <- arima(Nile1,order = c(1,0,1))
- print(ARMA)
- ##
- ## Call:
- ## arima(x = Nile1, order = c(1, 0, 1))
- ##
- ## Coefficients:
- ## ar1 ma1 intercept
- ## 0.2707 -0.9054 -2.8827
- ## s.e. 0.1176 0.0577 2.0167
- ##
- ## sigma^2 estimated as 19406: log likelihood = -629.82, aic = 1267.64
- checkresiduals(ARMA)
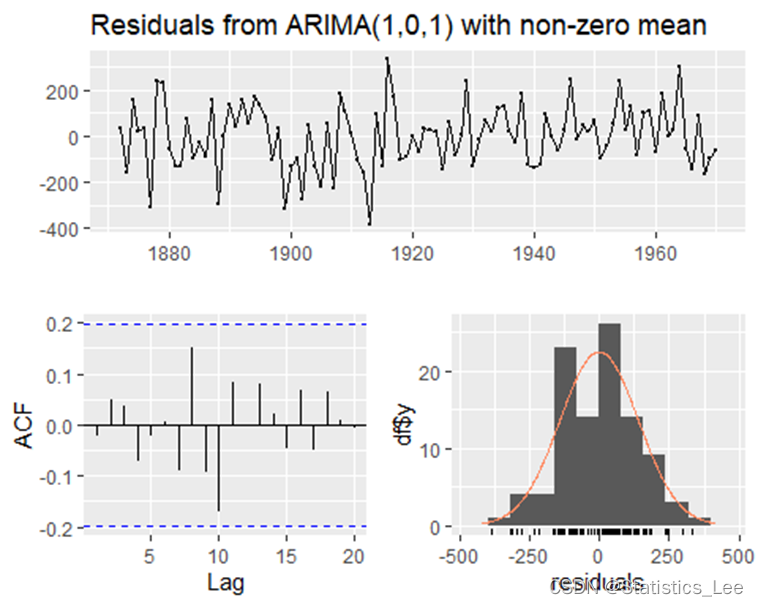
##
## Ljung-Box test
##
## data: Residuals from ARIMA(1,0,1) with non-zero mean
## Q* = 8.7102, df = 8, p-value = 0.3673
##
## Model df: 2. Total lags used: 10
从上述检验可以看出p-value > 0.05,说明残差序列是白噪声,也可以拟合ARMA(1,1)模型
模型选择
最后可通过AIC,BIC,HQIC等信息准则选择模型
- models<-list(MA,AR2,ARMA)
- aicbic<-cbind(lapply(models,AIC),lapply(models,BIC))
- rownames(aicbic) <- c("MA", "AR", "ARMA")
- colnames(aicbic) <- c("AIC", "BIC")
- aicbic
- ## AIC BIC
- ## MA 1270.309 1278.095
- ## AR 1279.282 1289.663
- ## ARMA 1267.637 1278.018
ARMA模型拥有最小的AIC和BIC,因为建模前我们已经对nile数据进行了一阶差分,所以在本实验中选择ARIMA(1,1,1)模型。
- 相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

