
- 1【系统架构设计师】二十四、安全架构设计理论与实践③
- 2vmware网卡(网络适配器)桥接、NAT、仅主机3种模式解析_桥接网卡
- 3UE4 VR设备的基本操作1---手柄跟头显的显示_ue4vr识别手柄模型
- 4在Windows上安装Linux的Bash_windows安装bash
- 5常用的数据可视化工具简介_列举三个知识可视化的常用工具并对其进行介绍
- 6微信小程序之appID_后台需要微信小程序applicationid
- 7ACL 2024 | UHGEval: 无约束生成下的中文大模型幻觉评估
- 8Python将两个列表合并成一个列表_python两个列表合并成一个列表
- 9对一维数组进行比较大小及公式的输出!_一维数组比大小
- 10RNN简介_rnn的优点
玳数科技集成 Flink CDC 3.0 的实践
赞
踩
摘要:本文投稿自玳数科技工程师杨槐老师,介绍了 Flink CDC 3.0 与 ChunJun 框架在玳数科技的集成实践。主要分为以下六个内容:
- 背景
- 技术选型
- 架构设计
- 挑战与解决方案
- 上线效果
- 未来规划
1. 背景
玳数科技对内外部用户提供了一站式的数据开发治理平台,其中数据集成是用户使用最为广泛的一个重要功能,底层基于开源项目 ChunJun 完成离线和实时数据采集,支撑平台用户完成异构数据源的迁移和数据入湖入仓作业。
在离线同步场景,随着引擎层不停迭代,ChunJun 基于 Flink 1.10/1.12/1.16 提供了近百个数据源连接器,对引擎团队造成很大的维护压力,从稳定性以及维护成本考虑,研发团队决定离线同步作业固定使用某一个 Flink 版本。
在实时同步场景,用户对 Flink 新功能和特性更为关注,因此我们的实时同步和实时计算作业会根据 Flink 版本进行升级维护。考虑到实时同步场景下的稳定性挑战和上下游表结构同步挑战,我们也在积极参考业界的可靠方案进行实践。
2. 技术选型
在基于Flink架构的实时采集领域中,Flink CDC 的成熟度和社区繁荣度都是名列前茅的,经过了广泛验证。尤其是今年发布了 3.x 版本,功能更为完善,聚焦于数据集成领域,支持了全增量一体化、整库同步、Schema Evolution 等能力。
ChunJun 的 CDC 连接器基于 Canal 或者 logminer 实现实时采集,并提供了 Schema Evolution 等类似功能,和 Flink CDC 3.0 功能有很多的类似。我们在思考是否可以使用 Flink CDC 作为玳数科技实时同步的底层框架支持,这样能避免很多 CDC 相关的功能重复开发,同时考虑 Flink CDC 的发展速度,也能减少后续升级、维护等成本,能让引擎团队将重心集中在核心连接器以及 Flink 拓展上,并开始了接入 Flink CDC 3.0 的实践。
3. 架构设计
在对 Flink CDC 3.0 的集成上,我们遵循以下几个前提:
-
尽量避免对开源项目代码的强入侵性,避免后续和开源差异太大,维护成本变高;
-
屏蔽 Flink CDC 和 ChunJun 任务的差异性,减少平台的对接工作;
-
生态融合,ChunJun 和 Flink CDC 连接器能互相使用。
最终决定使用 ChunJun 框架作为统一入口,以 Json 作为任务描述载体,支持 ChunJun pipeline 和 Flink CDC pipeline 算子链的构造,同时将数据源连接器进行融合,ChunJun-connector 或者 Flink CDC-pipeline-connector连接器均可在 ChunJun 或者 Flink CDC 任务中使用。
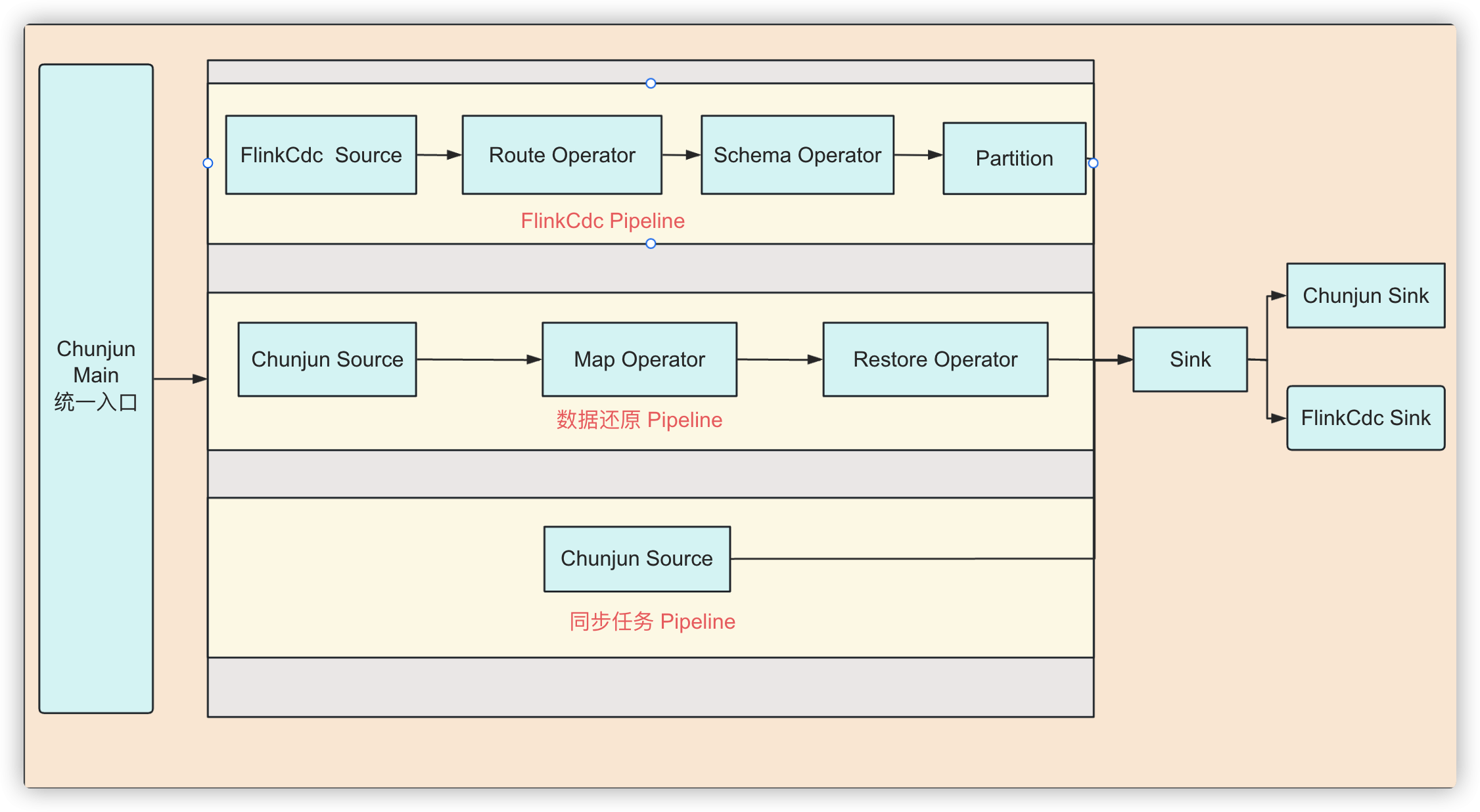
采用这种架构,能带来以下好处:
-
屏蔽 FlinkCDC 和 ChunJun 任务的差异性,减少平台的对接工作;
-
引擎团队只有第一次适配层的工作量,后续 Flink CDC-pipeline-connector 的对接无需开发;
-
ChunJun 和 CDC 连接器分离,无需关心 CDC sink 连接器的具体实现,只需将jar放入对应目录部署即可直接使用;
-
ChunJun 连接器和 CDC pipeline 连接器的复用,丰富更多场景的选择。
4. 挑战和解决方案
4.1 客户端入口统一
4.1.1 挑战
目前内部数据平台通过 Json 统一描述各种同步任务,而 Flink CDC 基于 yaml 格式进行描述,因此为了保证统一性,我们需要 Json 支持描述 Flink CDC yaml 的所有信息,且结构和 ChunJun 任务的结构尽量一致,减少两者差异性。
4.1.2 解决方案
通过对比 Flink CDC Yaml 和 ChunJun Json 结构之后,如下图,我们发现两者需要描述的信息和内部结构也是类似的,因此只需要注意保证连接器参数 key 的一致性,ChunJun 的 Json 结构是完全可以代替 Yaml 的。

在配置文件统一之后,我们将 Flink 任务的构建入口统一为 ChunJun 的 Main 函数而不是 Flink CDC 的 cli 模块。因此 ChunJun 的 Main 函数在内部将 Json 转为 ChunJun 的 SyncConf 对象后,CDC 类型任务会将 SyncConf 转为 Flink CDC 的 PipelineDef 对象,交由 FlinkPipelineComposer 构建任务。
4.2 sink的完善
4.2.1 挑战
ChunJun连接器包含了丰富的经过生产验证的 connector 连接器,将 ChunJun 连接器集成到 Flink CDC 3.0,能极大地丰富 CDC pipeline 的使用场景。Flink CDC 提供了对 Flink Sinkv2 实现的连接器对接,对 SinkFunction 连接器未提供对接实现,引擎团队需要实现基于 SinkFunction 对接实现,支持 Schema Evolution 等功能,以及 ChunJun 连接器和 Flink CDC 连接器流转数据的转换。
4.2.2 解决方案
Flink CDC 为了下游支持 Schema Evolution 功能,需要 Sink 端支持 DataChangeEvent 数据写入之外,还需要支持 Flush Event 以及 SchemaChangeEvent 等事件的处理。在接收 Flush Event 事件时,需要刷写出当前 Subtask的缓存数据并提交到数据源并通知 SchemaRegistry 当前 Subtask 完成了数据刷写过程。
Flink CDC 提供了 DataSinkWriterOperator 对 Flink Sink 接口进行代理,以完成上述 Flush Event 事件处理逻辑,因此提供一个对 SinkFunction 的代理类是 ChunJun 连接器集成到FlinkCDC融合的关键。
借鉴 DataSinkWriterOperator,我们基于 Flink 的StreamSink自定一个 SinkFunctionOperator 类,对 SinkFunction 做代理。其主要改动点在于 Flush Event 处理以及 SchemaRegistry 的交互,主要两个改动点如下:
-
SInkV2接口提供了Flush 方法,所以 Flink CDC 的 DataSinkWriterOperator 可以直接调用 Flush 方法进行数据刷新,而 SinkFunction 接口并没有相关实现,不过 ChunJun 连接器内部已经有 ddl 处理的业务实现。在 ChunJun 的 OutputFormat#writeRecord 逻辑里,如果接收到了 DdlRowData 就会执行 Flush 类似操作,将缓存的数据写入数据源,因此 Flush Event 只需要转成一个特殊的 EmptyDdlRowData 传给 OutputFormat 即可。
-
ChunJun 将 dml 和 ddl 数据分别对应 ColumnRowData 和 DDlRowdata,和 Flink CDC 的 DataChangeEvent 和 SchemaChangeEvent 一一对应,因此我们提供了一个 serialize 接口解决 ChunJun 和 Flink CDC 数据的转换。
下图是 Flink CDC 采集 Mysql 写入 ChunJun Mysql Sink 连接器的一个任务示例:

4.3 route 配置增强
4.3.1 挑战
Flink CDC 在实时同步中还提供了 Route 模块,进行上下游表的映射关系处理。如下述配置为上游 dt 下的所有表同步到下游 sync 一张表中。
route:
- source-table: dt.\.*
sink-table: dt.sync
description: sync all sharding tables to one
- 1
- 2
- 3
- 4
但是在使用中,发现 route 算子在某些场景下的支持不够全面,比如我希望同步过程中,下游表会加上 sync 后缀代表是 CDC 任务同步的表,是比较难配置的。因为 Flink CDC 3.0 的 route 算子的映射关系配置中,下游必须是完整的 ‘schemaName’.‘tableName’ 表达方式,而不支持占位符,这样会导致上游表的数量和 route 配置的数量一致。
4.3.2 解决方案
我们在 route 算子做了部分改造,支持配置 ${schemaName} ${tableName} 作为占位符,下述脚本逻辑代表上游表写入上游表名加上 _CDC 后缀,如上游 dt.t1 的数据写入下游 dt.t1_CDC 表。
route:
- source-table: dt.\.*
sink-table: dt.${tableName}_CDC
- 1
- 2
- 3
4.4 SchemaChange 异常优化
4.4.1 挑战
Flink CDC 提供了多种策略处理 SchemaChange 事件,如忽略直接抛弃,抛出异常,自动执行策略。Flink CDC 3.0 版本在 EVOLVE 场景做了比较完善支持,而 EXCEPTION 场景下的处理比较粗暴,上游产生 SchemaChangeEvent 数据后直接抛出异常,让任务失败退出。
当配置抛出异常策略处理 schemaChange 事件后,客户在下游手动操作 Schema 变更完成后,任务上一次 checkpoint 和当前 SchemaChangeEvent 之间的数据较难恢复。因为 Flink CDC 在抛出异常前,并没有将 sink 端缓存的数据进行 Flush,即 Sink 没有接受到 Flush Event 进行处理。
4.4.2 解决方案
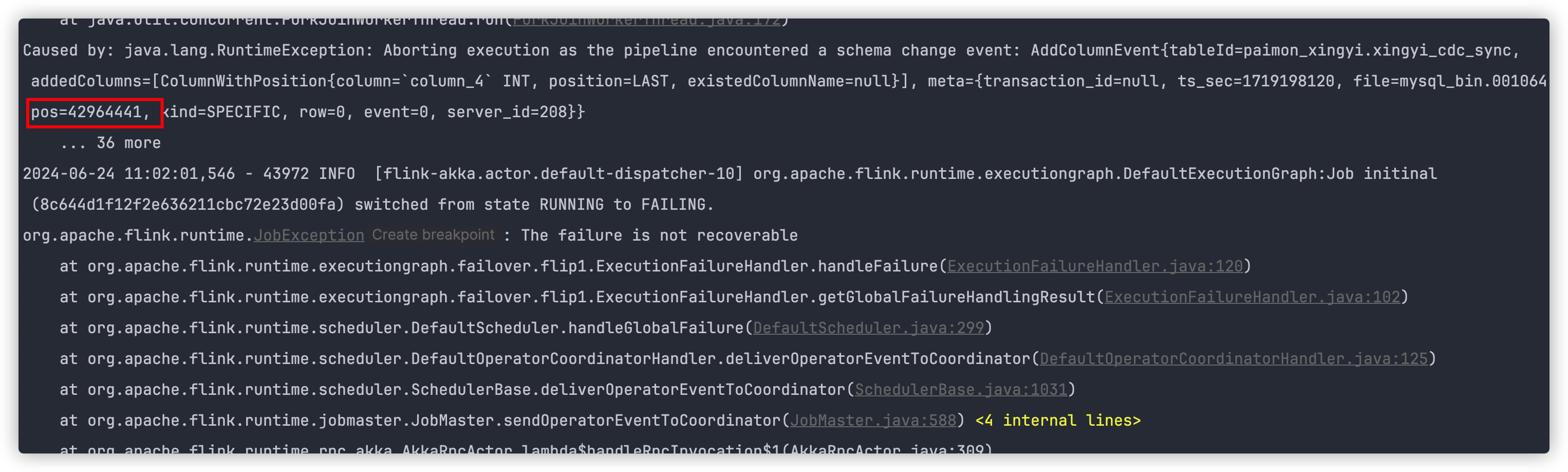
我们的解决方案是复用了 EVOLVE 所有流程,仅仅在 MetadataApplier#applySchemaChange 自动执行 Schema 变更前判断是否支持执行即可:SchemaChangeBehavior 为 EXCEPTION 时,执行 MetadataApplier#applySchemaChange 前抛出异常,这样由于复用了 EVOLVE 流程, MetadataApplier#applySchemaChange 执行之前,Sink 端一定会将所有数据刷新到数据源,客户只需要将任务的位点选择 SchemaChangeEvent的position,然后重新运行即可保证数据的一致性。
我们在 SchemaChangeEvent 里加上了 meta 信息,如 binlog 的点位信息,在抛出异常的时候会显示出相关位点信息,客户重跑任务,重新选择位点就很方便,直接选择日志里显示的位点信息即可。
5. 上线效果
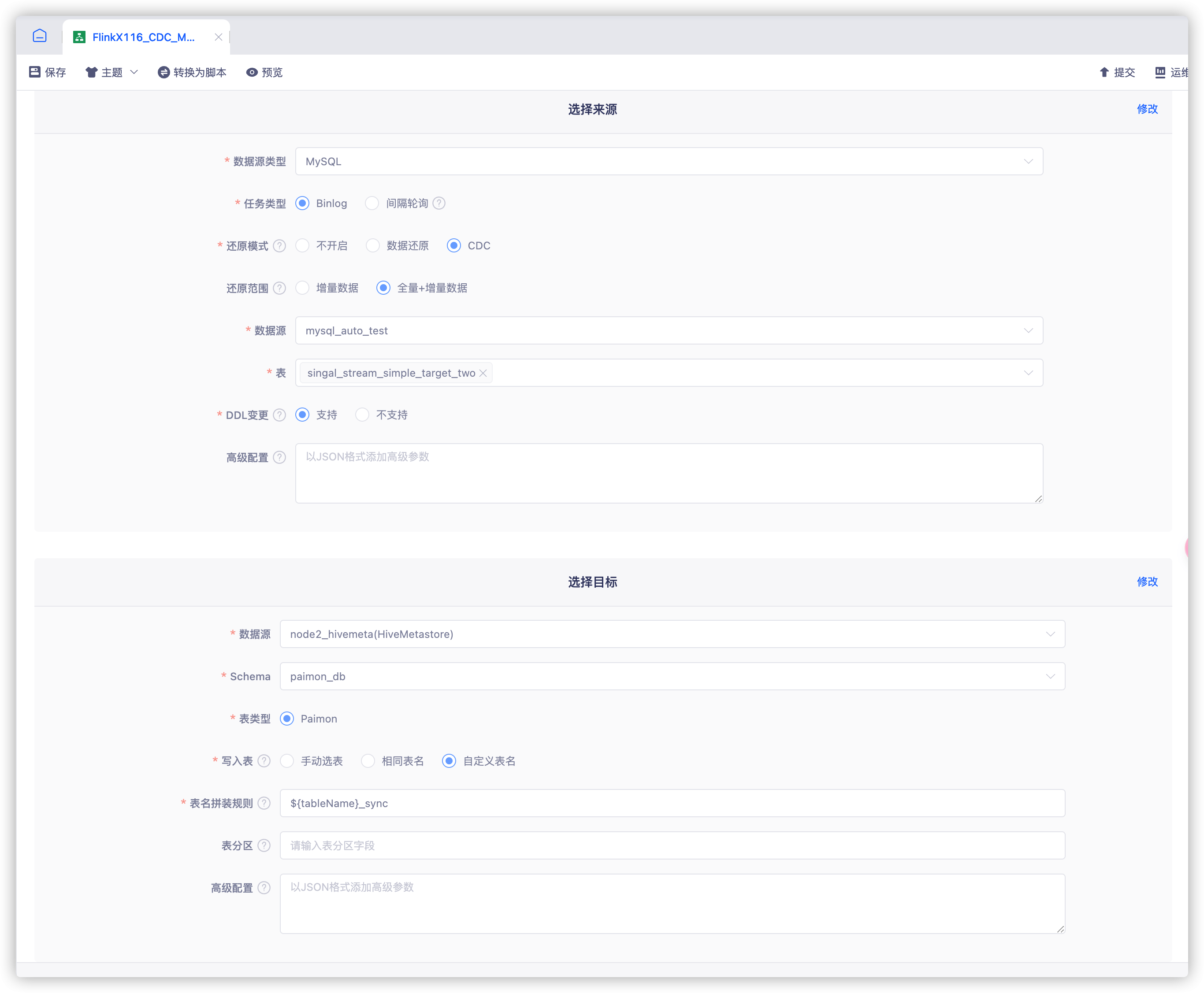
引擎层基于上述方案对 ChunJun 和 Flink CDC 整合之后,节约了连接器层大量对接时间。以 mysql CDC->paimon 入湖为例,引擎研发团队只需要和平台研发团队进行简单的联调,不需要额外的连接器层的开发就可以快速上线,有效降低了开发运维成本。
同时使用 Flink CDC 也为玳数科技产品提供了全增量一体化、多表同步、SchemaEvolution 等强大功能。
6. 未来规划
目前以 Flink CDC 为基础的 mysql->paimon 入湖链路已在玳数科技产品上线,正在规划 Doris、StartRocks 等组件快速上线。同时我们密切关注 Flink CDC 社区的发展,将内部对 Flink CDC 的改动贡献到社区,减少两者差异性。玳数科技集成 Flink CDC 的未来规划主要如下:
-
持续更新版本:Flink CDC 版本更新到 3.1+,将 transform 能力融入产品以及稳定性提升
-
持续丰富连接器:数据同步组件增加 Doris/StarRocks 连接器作为下游
-
metric 增强:增加全量阶段和增量阶段,每个表的同步信息以及 ddl 数据监控和报警策略
欢迎大家多多关注 Flink CDC,从钉钉用户交流群[1]、微信公众号[2]、Slack 频道[3]、邮件列表[4]加入 CDC 用户社区,以及在 Flink CDC GitHub 仓库[5]上参与代码贡献!
[1] “ Flink CDC 社区 ② 群”群的钉钉群号:80655011780

[2] ” Flink CDC 公众号“的微信号:ApacheFlinkCDC

[3] https://flink.apache.org/what-is-flink/community/#slack
[4] https://flink.apache.org/what-is-flink/community/#mailing-lists

