
- 1Eureka 服务注册与消费(超详细)_eureka 收费吗
- 2基于springboot实现的新生宿舍管理系统_springboot学生管理系统
- 3最全面的外包公司的解释_联众科技是外包吗知乎
- 4Perl 入门学习_perl入门学习
- 5AIGC全面介绍 超级详细_aigc介绍
- 6ChatTTS 升级版:支持音色抽卡、长音频生成和分角色朗读_chattts 音色
- 7python-KNN分类(1):调用KNeighborsClassifier()实现_knn分类调用
- 8使用Python爬取小红书笔记与评论(仅供参考与学习上交流)_python爬取小红书关键词所有笔记评论
- 9Tomcat URL重定向漏洞修复
- 10终于有人把云计算、大数据和 AI 讲明白了【深度好文】_ai替代云计算(2)_al能不能代替云计算
目标检测算法之YOLO(YOLOv7)
赞
踩
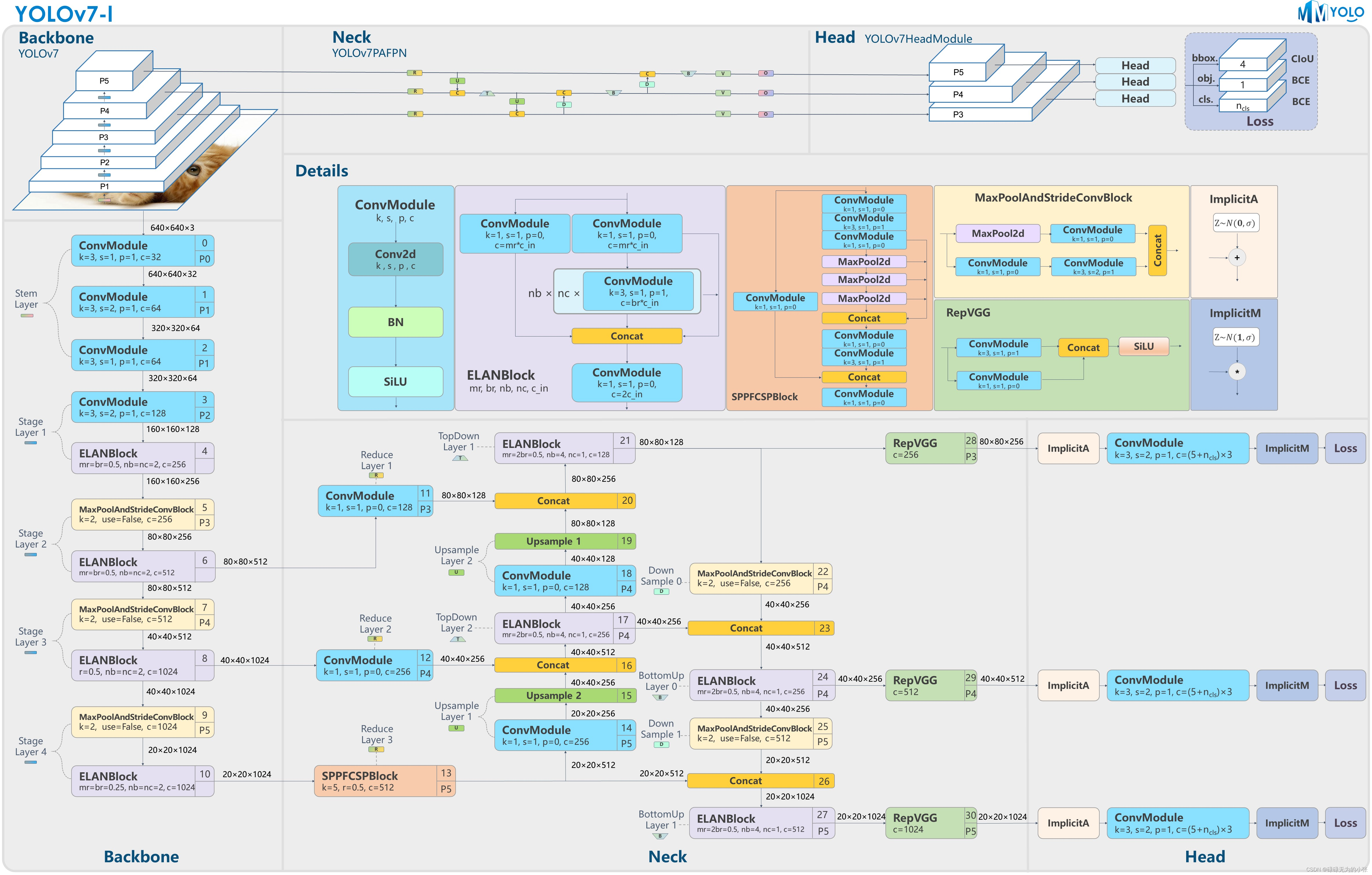
YOLOv7
YOLOv7是2022年发布的,在yolov6发布不久就出了。yolov7是在v5的基础上改进了网络结构,使网络更加高效。其仍然是anchor-based的预测形式,没有做大改。yolov7的主要创新点有三个,分别是E-ELAN网络、Planned re-parameterized convolution和标签分配方式。
yolov7结构图如下
ELAN和E-ELAN
ELAN网络是在CSPnet的基础上改进的一个网络,它的网络结构具备更多的分支以及更少的卷积核,论文作者通过实验证明了这种方式是有效的。
接下来仔细分析ELAN网络,论文中给出的ELAN网络图如下
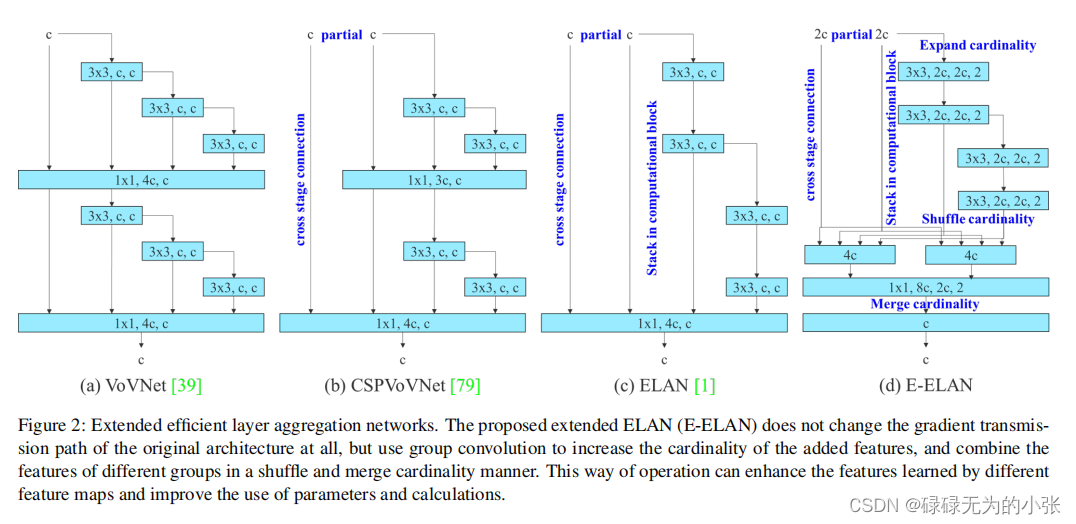
其中图
(
c
)
(c)
(c)为ELAN网络的具体结构,它与CSP网络一样,采用了梯度截流的方式。但ELAN它消除了网络中的1x1卷积concat的操作,转换成了3x3卷积直接输出,在最后再进行concat的方式,从直观上看来,它保留了残差连接,但卷积数减少了。且论文作者提出这种方式会带来更少更长的梯度路径,更容易收敛。
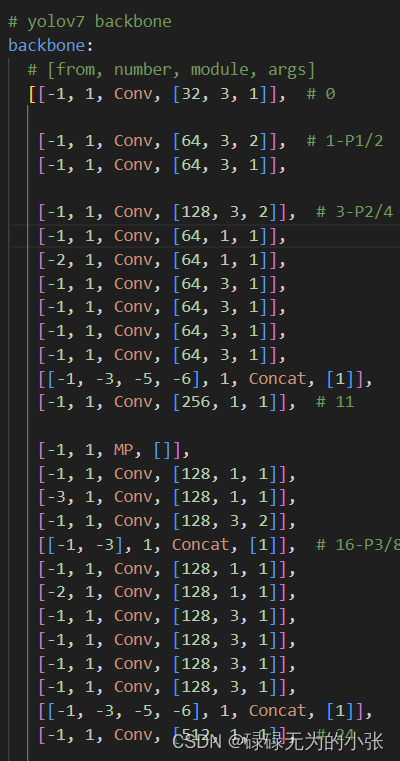
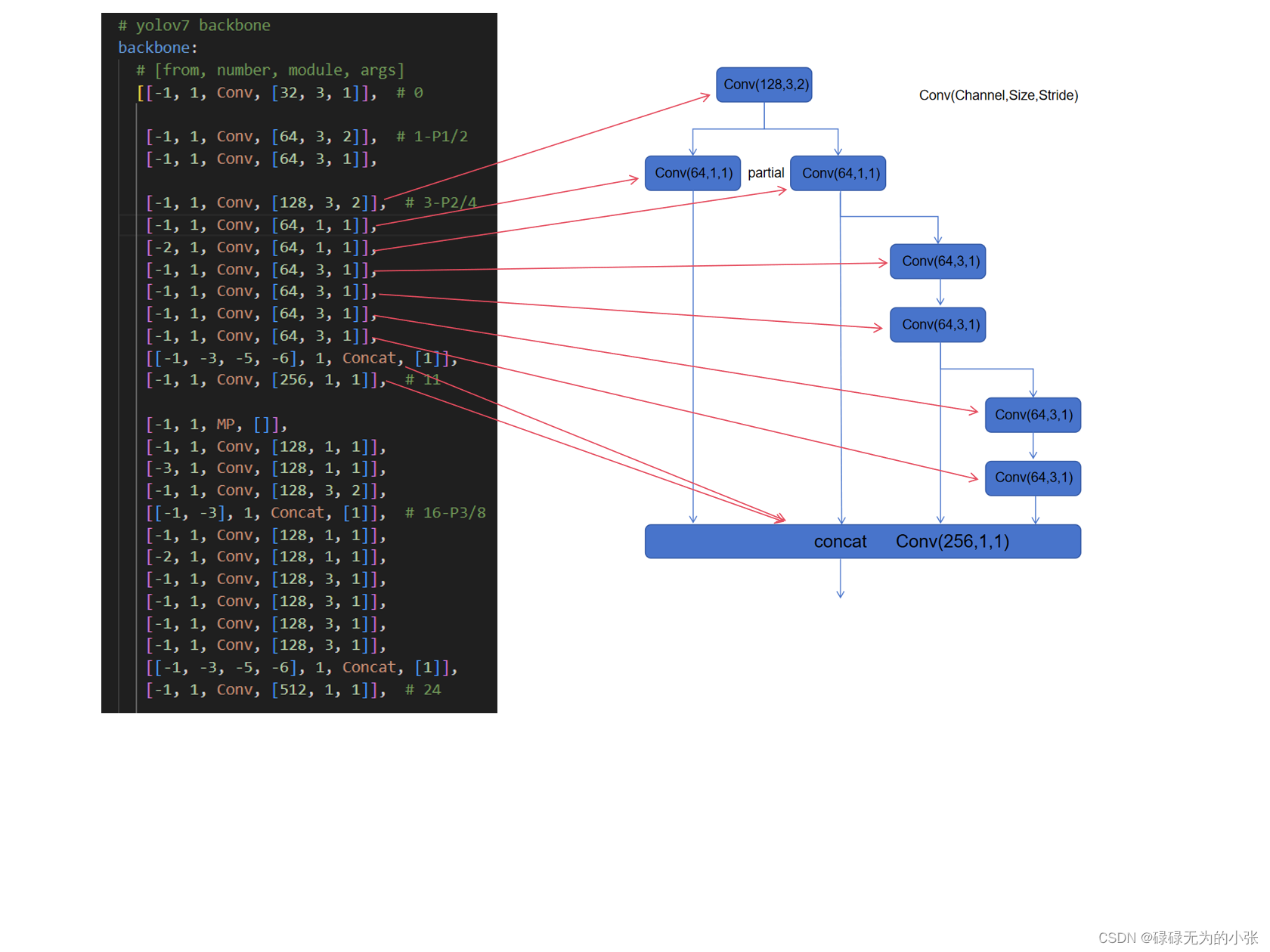
结合在代码中的结构,具体分析一下它的结构,上图是yolov7backbone的部分结构,第3层-第11层就是ELAN网络。可以发现,其是使用了1x1的卷积网路进行partial的操作,然后经过了4层的卷积网络,最后将第4层、第5层、第7层和第9层concat在一起。最后用1x1的卷积变换channel输出。这样的描述可能比较模糊,下面用结构图和代码结构对应来展示整个过程。
作者还提出了E-ELAN,是ELAN的扩展版本。它的结构如图
(
d
)
(d)
(d)所示。从图上可以发现,这个结构十分复杂,让人一头雾水。从图上可以看出partial的维度是
2
c
2c
2c,像是直接维度翻倍了。但实际它的结构应该如下图所示
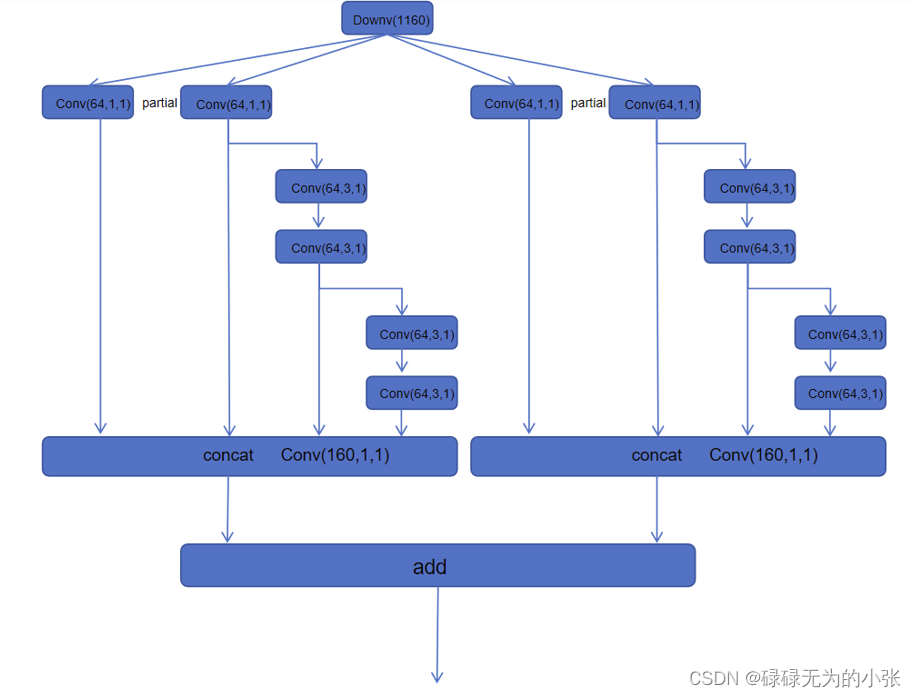
它是将俩个ELAN网络合并了,通过俩个一样的ELAN网络最后用add的方式合并输出。在官方代码中的yolov7e6的参数中实现了这个网络,所以可以结和它的参数具体分析一下。

从上图可以发现,第2层至第23层为E-ELAN网络,其中第3层-第11层为第一个ELAN网络,第13层-第22层为第2个ELAN网络,最后用add(shorcut实现的也是add)方式叠加输出。ELAN网咯中,3x3的卷积多了俩个,同时最后concat时变成了5个,这与论文给的图是不一致的,论文图中的E-ELAN只用了4个分支,这里用了5个。具体的对应用下图表示。

结合E-ELAN和ELAN的机构可以看出,论文作者将多分支concat的方式作为一种增精降参的方式。
Planned re-parameterized convolution
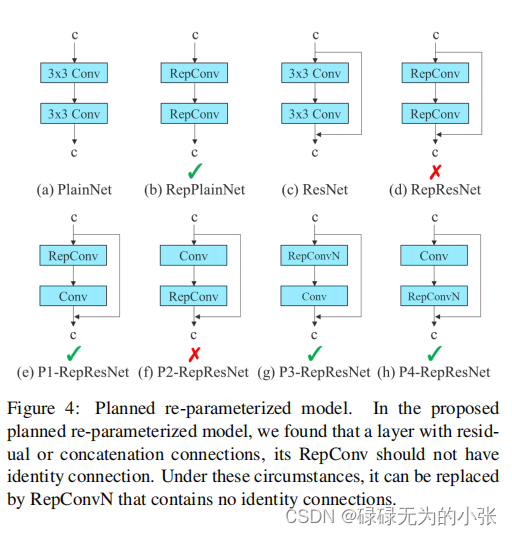
上图是Planned re-parameterized模型,它是re-parameterized的一种改进方式。论文中指出repconv的方式直接应用于网络中时会出现网路下降,并分析给出了原因。从图
(
a
)
(a)
(a)和图
(
b
)
(b)
(b),可以看出俩个卷积网络直接更换成repconv是可以的。根据图
(
c
)
(c)
(c)和图
(
d
)
(d)
(d),说明发现当网络中使用残差连接时,引用俩个连续的repconv层效果不好。根据图
(
e
)
(e)
(e)和图
(
f
)
(f)
(f),可以发现残差连接时,repconv层直接和残差连接相加的效果不好。根据图
(
g
)
(g)
(g)和图
(
h
)
(h)
(h),可以发现,将repconv改变成repconvN就可以改进图
e
e
e和图
f
f
f的效果。
总的来说,论文作者分析了Repconv的适用情况,认为残差连接不能直接和Repconv相加。但提出了RepConvN来改进这种情况。
标签分配
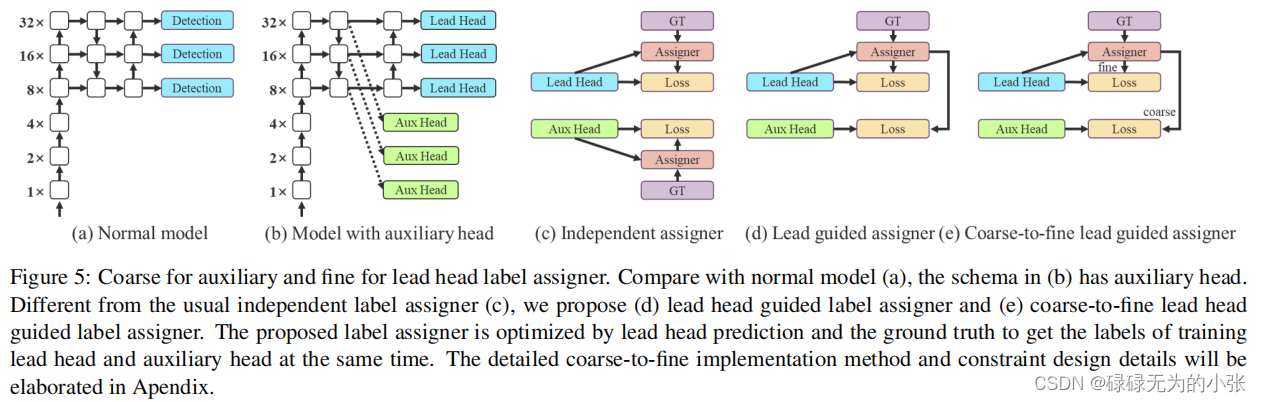
yolov7提出了lead guided assigner的方法。以前的辅助损失头一般用解耦的方式,各自分别分配标签,但是这样aux head的损失和lead head的就难以对齐了。所以这里提出了lead head guided label assigner。即通过lead头来控制lead和aux的标签分配。并在这个基础上提出了aux head学习coarse label,lead head学习fine label的方式,使aux head学习更多标签,具备更好地召回,而lead head学习细标签,更关注于精准度。
在yolov7中的代码中,标签分配采用了simOTA的方式,对aux head分配更多的正样本,而lead head分配较少的正样本。simOTA是yolox中提出的方法,能够使真实标签更好地分配给grid,减少真实标签分配过多给不正确的grid从而导致检测效果降低的情况。而yolox是采用anchor-free的方式,yolov7仍然是anchor-based的模型。
yolov7延续了yolov5的框分配方式,每个真实标签分配给了不多于3的grid中。将分配后的所有真实框与每个预测框计算iou的值。然后筛选前
m
=
min
(
10
,
n
u
m
(
p
r
e
d
i
c
t
)
)
m = \min(10,num(predict))
m=min(10,num(predict)) 个iou的值。然后根据前
m
m
m个iou值计算动态
k
k
k值,即
D
y
n
a
m
i
c
_
k
=
⌊
∑
i
m
i
o
u
i
⌋
Dynamic\_k = \left \lfloor \sum_i^{m} iou_i\right\rfloor
Dynamic_k=⌊i∑mioui⌋由于smiOTA考虑了分类分数和回归分数,所以smiOTA的cost为
c
o
s
t
=
L
o
s
s
c
l
s
+
3
L
o
s
s
s
i
o
u
cost = Loss_{cls}+3Losss_{iou}
cost=Losscls+3Losssiou其中
L
o
s
s
c
l
s
Loss_{cls}
Losscls为分类损失,
L
o
s
s
s
i
o
u
Losss_{iou}
Losssiou为回归损失
根据cost获取cost最低的
D
y
n
a
m
i
c
_
k
Dynamic\_k
Dynamic_k个预测标签的index。这里的index是指与真实标签匹配的预测标签。
最后需要处理一下当预测值匹配多个真实值的情况,同样的这里也是将cost最低的作为匹配,其他的都去除。
具体可以看下述代码,主要部分用注释标出
def build_targets(self, p, targets, imgs): #indices, anch = self.find_positive(p, targets) #与yolov5类似的真实框分配给grid的方法 indices, anch = self.find_3_positive(p, targets) #indices, anch = self.find_4_positive(p, targets) #indices, anch = self.find_5_positive(p, targets) #indices, anch = self.find_9_positive(p, targets) device = torch.device(targets.device) matching_bs = [[] for pp in p] matching_as = [[] for pp in p] matching_gjs = [[] for pp in p] matching_gis = [[] for pp in p] matching_targets = [[] for pp in p] matching_anchs = [[] for pp in p] # nl = len(p) for batch_idx in range(p[0].shape[0]): b_idx = targets[:, 0]==batch_idx this_target = targets[b_idx] if this_target.shape[0] == 0: continue txywh = this_target[:, 2:6] * imgs[batch_idx].shape[1] txyxy = xywh2xyxy(txywh) pxyxys = [] p_cls = [] p_obj = [] from_which_layer = [] all_b = [] all_a = [] all_gj = [] all_gi = [] all_anch = [] #处理预测值 for i, pi in enumerate(p): b, a, gj, gi = indices[i] idx = (b == batch_idx) b, a, gj, gi = b[idx], a[idx], gj[idx], gi[idx] all_b.append(b) all_a.append(a) all_gj.append(gj) all_gi.append(gi) all_anch.append(anch[i][idx]) from_which_layer.append((torch.ones(size=(len(b),)) * i).to(device)) fg_pred = pi[b, a, gj, gi] p_obj.append(fg_pred[:, 4:5]) p_cls.append(fg_pred[:, 5:]) grid = torch.stack([gi, gj], dim=1) pxy = (fg_pred[:, :2].sigmoid() * 2. - 0.5 + grid) * self.stride[i] #/ 8. #pxy = (fg_pred[:, :2].sigmoid() * 3. - 1. + grid) * self.stride[i] pwh = (fg_pred[:, 2:4].sigmoid() * 2) ** 2 * anch[i][idx] * self.stride[i] #/ 8. pxywh = torch.cat([pxy, pwh], dim=-1) pxyxy = xywh2xyxy(pxywh) pxyxys.append(pxyxy) pxyxys = torch.cat(pxyxys, dim=0) if pxyxys.shape[0] == 0: continue p_obj = torch.cat(p_obj, dim=0) p_cls = torch.cat(p_cls, dim=0) from_which_layer = torch.cat(from_which_layer, dim=0) all_b = torch.cat(all_b, dim=0) all_a = torch.cat(all_a, dim=0) all_gj = torch.cat(all_gj, dim=0) all_gi = torch.cat(all_gi, dim=0) all_anch = torch.cat(all_anch, dim=0) #计算预测值和真实值之间的iou pair_wise_iou = box_iou(txyxy, pxyxys) #对计算的iou进行类似于取反的操作 pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8) #获取前 min(10,num(predict))个iou top_k, _ = torch.topk(pair_wise_iou, min(10, pair_wise_iou.shape[1]), dim=1) #计算动态k值 dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1) #计算分类损失 gt_cls_per_image = ( F.one_hot(this_target[:, 1].to(torch.int64), self.nc) .float() .unsqueeze(1) .repeat(1, pxyxys.shape[0], 1) ) num_gt = this_target.shape[0] cls_preds_ = ( p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() * p_obj.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() ) y = cls_preds_.sqrt_() pair_wise_cls_loss = F.binary_cross_entropy_with_logits( torch.log(y/(1-y)) , gt_cls_per_image, reduction="none" ).sum(-1) del cls_preds_ #计算cost cost = ( pair_wise_cls_loss + 3.0 * pair_wise_iou_loss ) #初始化匹配矩阵 matching_matrix = torch.zeros_like(cost, device=device) #每个真实值分配dynamic_k个预测值 for gt_idx in range(num_gt): _, pos_idx = torch.topk( cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False ) matching_matrix[gt_idx][pos_idx] = 1.0 del top_k, dynamic_ks #将一个预测值匹配多个真实值的情况进行过滤 anchor_matching_gt = matching_matrix.sum(0) if (anchor_matching_gt > 1).sum() > 0: _, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0) matching_matrix[:, anchor_matching_gt > 1] *= 0.0 matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0 fg_mask_inboxes = (matching_matrix.sum(0) > 0.0).to(device) matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0) from_which_layer = from_which_layer[fg_mask_inboxes] all_b = all_b[fg_mask_inboxes] all_a = all_a[fg_mask_inboxes] all_gj = all_gj[fg_mask_inboxes] all_gi = all_gi[fg_mask_inboxes] all_anch = all_anch[fg_mask_inboxes] this_target = this_target[matched_gt_inds] for i in range(nl): layer_idx = from_which_layer == i matching_bs[i].append(all_b[layer_idx]) matching_as[i].append(all_a[layer_idx]) matching_gjs[i].append(all_gj[layer_idx]) matching_gis[i].append(all_gi[layer_idx]) matching_targets[i].append(this_target[layer_idx]) matching_anchs[i].append(all_anch[layer_idx]) for i in range(nl): if matching_targets[i] != []: matching_bs[i] = torch.cat(matching_bs[i], dim=0) matching_as[i] = torch.cat(matching_as[i], dim=0) matching_gjs[i] = torch.cat(matching_gjs[i], dim=0) matching_gis[i] = torch.cat(matching_gis[i], dim=0) matching_targets[i] = torch.cat(matching_targets[i], dim=0) matching_anchs[i] = torch.cat(matching_anchs[i], dim=0) else: matching_bs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64) matching_as[i] = torch.tensor([], device='cuda:0', dtype=torch.int64) matching_gjs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64) matching_gis[i] = torch.tensor([], device='cuda:0', dtype=torch.int64) matching_targets[i] = torch.tensor([], device='cuda:0', dtype=torch.int64) matching_anchs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64) return matching_bs, matching_as, matching_gjs, matching_gis, matching_targets, matching_anchs

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
这里的标签分配理解有三个难点,第一个是 n n n个真实值在分配给grid后会变成 t ( n < t < 3 n ) t(n<t<3n) t(n<t<3n)个真实值;第二个是smiOTA是分配一个真实值分配给多个预测框的问题;第三个是一个预测框只能分配一个真实值。把握这三个点再去分析代码和问题能够更加容易理解,也不会感觉代码太乱。
在yolov7的代码中,coarse标签是指在分配给辅助头时,先将 n n n个真实值分配给 t ( n < t < 5 n ) t(n<t<5n) t(n<t<5n)个grid,那样就会扩大了真实值覆盖的grid。然后在筛选iou时从 min ( 10 , n u m ( p r e d i c t ) ) \min(10,num(predict)) min(10,num(predict))扩大到 min ( 20 , n u m ( p r e d i c t ) ) \min(20,num(predict)) min(20,num(predict))这种方式可以明显的增大后续的 d y n a m i c _ k dynamic\_k dynamic_k,从而使真实标签分配给更多的grid。至于yolov7中这俩部分的代码来自于yolov5和yolox。本文讲解了来自yolox的smiOTA部分,至于来自yolov5的真实值分配grid可以看我在yolov5那篇博客中的描述。
总结
从现在的角度去看yolov7,可以发现其ELAN的方法是有效的,在后续的版本中也多次被用到或者改进。而如今标签分配更多的是使用TAL策略。yolov7的热度明显不如yolov8,很多人在v7上fine-tune自己的数据集的效果甚至不如v5。不过这也是现如今新算法的一个普遍问题,许多算法过度追求SOTA从而导致模型的标签只能在某些数据集上取得较好的效果,所以对于新的算法更多的是去了解新的思想。然后在此基础上去创新或者调参,从而获得更好地模型效果。

