
- 1Ubuntu安装Web服务器Boa和CGIC_lubuntu2在线入
- 2【笔试】美团2023年秋招第1场笔试(后端&数开&软件方向)_美团后端开发笔试
- 3高通平台 android7.1 蓝牙的可见性设置
- 4mysql基础5 数据类型_unsigined tinyint3
- 5k8s1.19使用ceph15 rbd块存储_rbd watch
- 67-42 实验7_7_连续子序列 (100 分)_本关任务:对于一个浮点数序列a,只包含正数,找到一个连续子序列,使得该子序列中元
- 7win10 家庭版安装 docker(Docker Desktop)_window10 家庭版安装dockerdesktop
- 8c++使用opencv打开相机获取图像_opencv打开摄像头并捕捉图像
- 9Code Runner for VS Code,下载量突破 4000 万!支持超过50种语言
- 10Random 对象、Math.random(转)
Python图书数据可视化分析_seaborn读取csv文件画柱状图
赞
踩
20220615 导师发布第一个任务---图书数据可视化分析
课件下载链接:
https://pan.baidu.com/s/1RjRyk8ZTbxI1z5W7MZLTdQ?pwd=m6eq
提取码: m6eq
数据集链接:
http://idatascience.cn/dataset-detail?table_id=100178
http://idatascience.cn/dataset-detail?table_id=407
爱数课实验链接:
http://idatacourse.cn/case-run?id=6564&token=bcaf2e9d80c0ba1cd114b2b2fc9dabce
以下为自己实验过程
一、导包
1、pandas需要安装 才能使用
cmd打开窗口,输入代码安装pandas:pip install pandas
如果报错,需要检查pip版本,实验性更新:python -m pip install --upgrade pip
2、seaborn,jieba等等同上述用一种方法
- import pandas as pd
- import seaborn as sns
- import matplotlib.pyplot as plt
- import jieba
- from wordcloud import WordCloud,STOPWORDS
- # 设置中文字体
- plt.rcParams['font.sans-serif']='SimHei'
二、得到数据集
- # 得到数据集
- data = pd.read_csv('D:/newStudent/data/test1/data1.csv',sep=',',encoding='utf-8')
- # 输出到终端查看前五行
- print(data.head(5))
1、字段基本统计信息
使用DataFrame对象的describe()方法可以查看各个列的基本统计信息,统计并生成数据集中各个字段的样本数、均值、标准差、最小值、四分位数等基本信息。
describe()方法的主要参数:
- percentiles:自定义分位数,默认是25%,50%,75%
- include:指定统计的数据类型,默认只统计数值型,当为all时数值和离散型都统计
- exclude:意排除哪些字段,默认统计所有列
-
print(data.describe(include='all'))
运行结果
三 可视化探索分析
在前面的任务中,我们读取并了解了数据的基本信息。下面将通过Python中的绘图库如Matplotlib、Seaborn等,利用一系列可视化的手段,以绘图的方式展示数据字段的取值分布以及数据字段间的相关关系等。
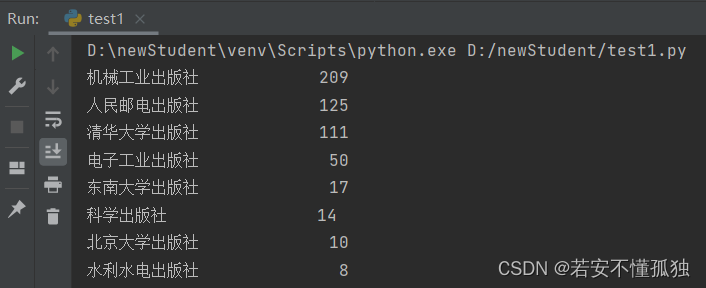
1、各出版社图书数量
Series对象的value_counts()方法可以对某列的取值数量分布进行统计,其主要参数为:
- normallize:默认为False,若为True,则以百分比的形式显示
- sort:是否对结果进行排序,默认为True
- ascending: 默认对值降序排列(False)
- dropna:是否删除空值,默认删除(True)
print(data['出版社'].value_counts(ascending=False))运行结果(降序)
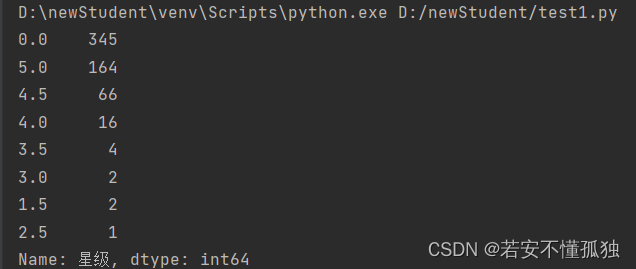
2、各星级图书柱状图
柱状图的主要作用是将多个或者2个以上的类别变量在同一条件下,进行数值之间的比较以此来判断哪些数据值相对较大或相对较小。
利用Seaborn中的barplot函数绘制柱状图,其中主要参数有:
- x:x坐标传入的值
- y:y坐标传入的值
- data:传入的数据集
打印星级数量
print(data['星级'].value_counts())
运行结果
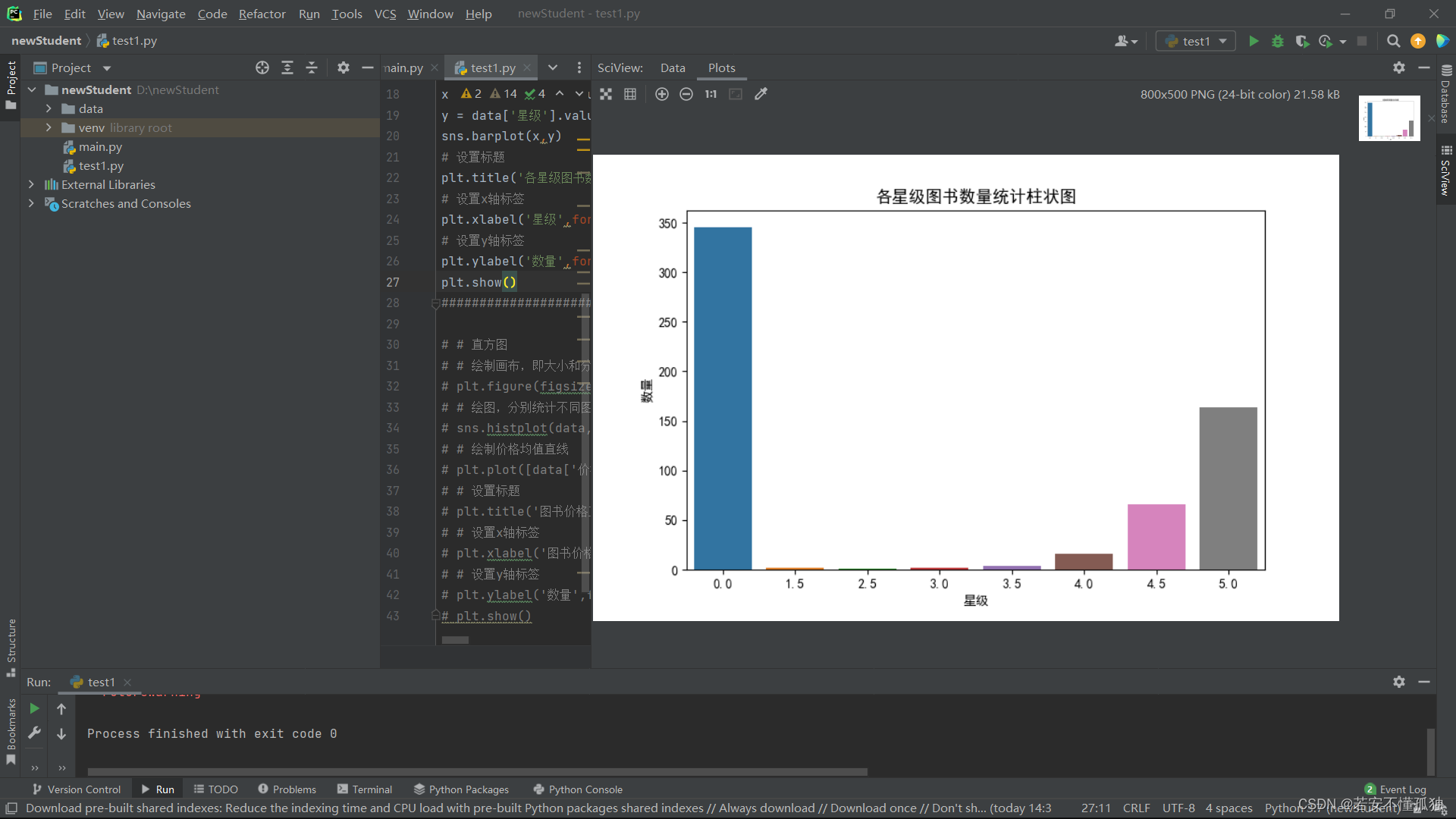
绘图,对照
- #绘图柱状图
- plt.figure(figsize=(8,5), dpi=100)
- # 星级
- x = data['星级'].value_counts().index
- # 数量
- y = data['星级'].value_counts().values
-
- sns.barplot(x,y)
- # 设置标题
- plt.title('各星级图书数量统计柱状图',fontsize=13)
- # 设置x轴标签
- plt.xlabel('星级',fontsize=10)
- # 设置y轴标签
- plt.ylabel('数量',fontsize=10)
运行结果
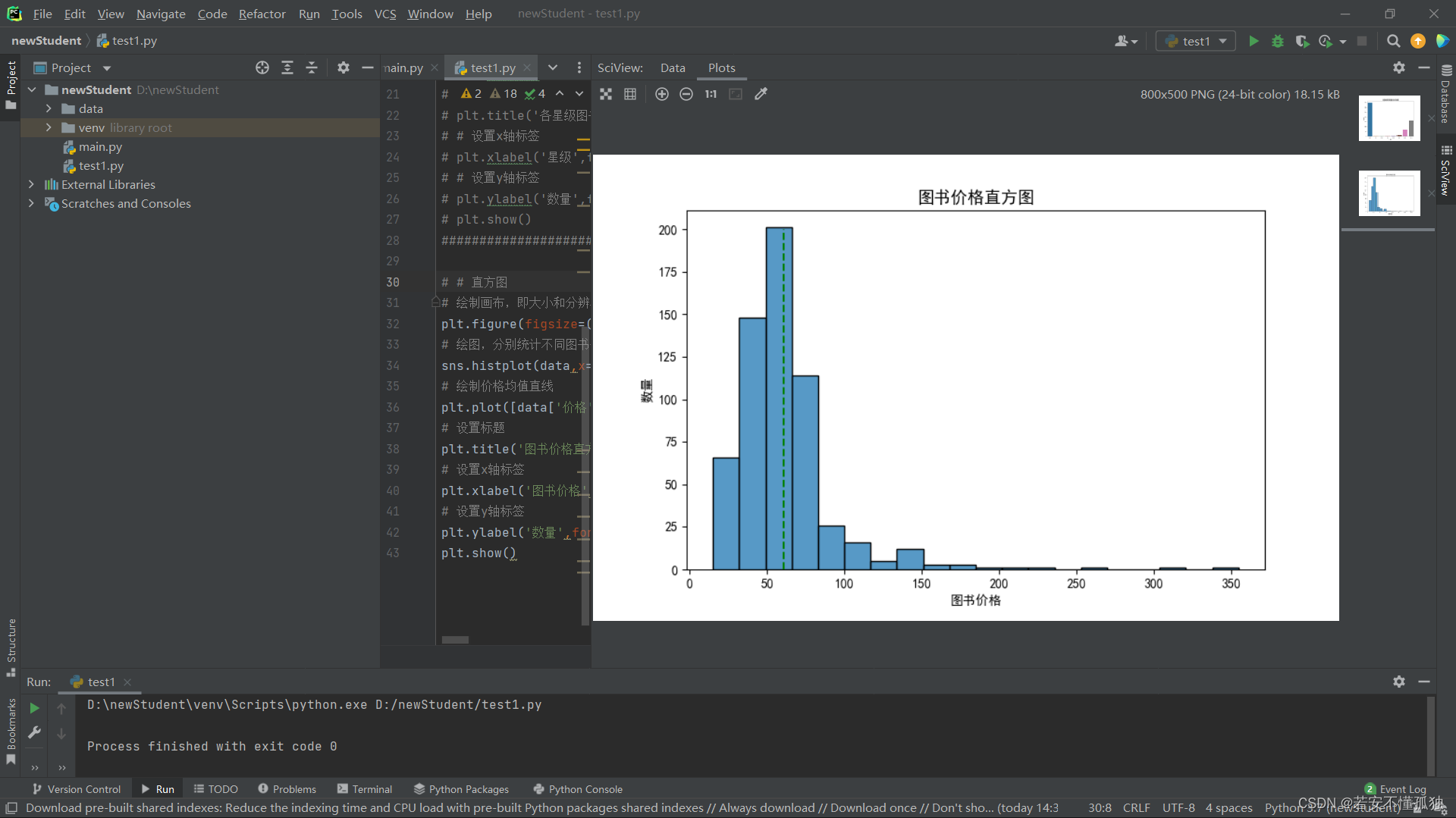
3、图书价格直方图
利用Seaborn里的histplot函数来绘制直方图,主要参数有:
- data:传入的数据
- x:做直方图所用的数据,必须是一维数组
- bins:分组数量
- # # 直方图
- # 绘制画布,即大小和分辨率
- plt.figure(figsize=(8,5),dpi=100)
- # 绘图,分别统计不同图书价格的数量
- sns.histplot(data,x='价格',bins=20)
- # 绘制价格均值直线
- plt.plot([data['价格'].mean(),data['价格'].mean()],[0,200],'g--')
- # 设置标题
- plt.title('图书价格直方图',fontsize=13)
- # 设置x轴标签
- plt.xlabel('图书价格',fontsize=10)
- # 设置y轴标签
- plt.ylabel('数量',fontsize=10)
- plt.show()
运行结果
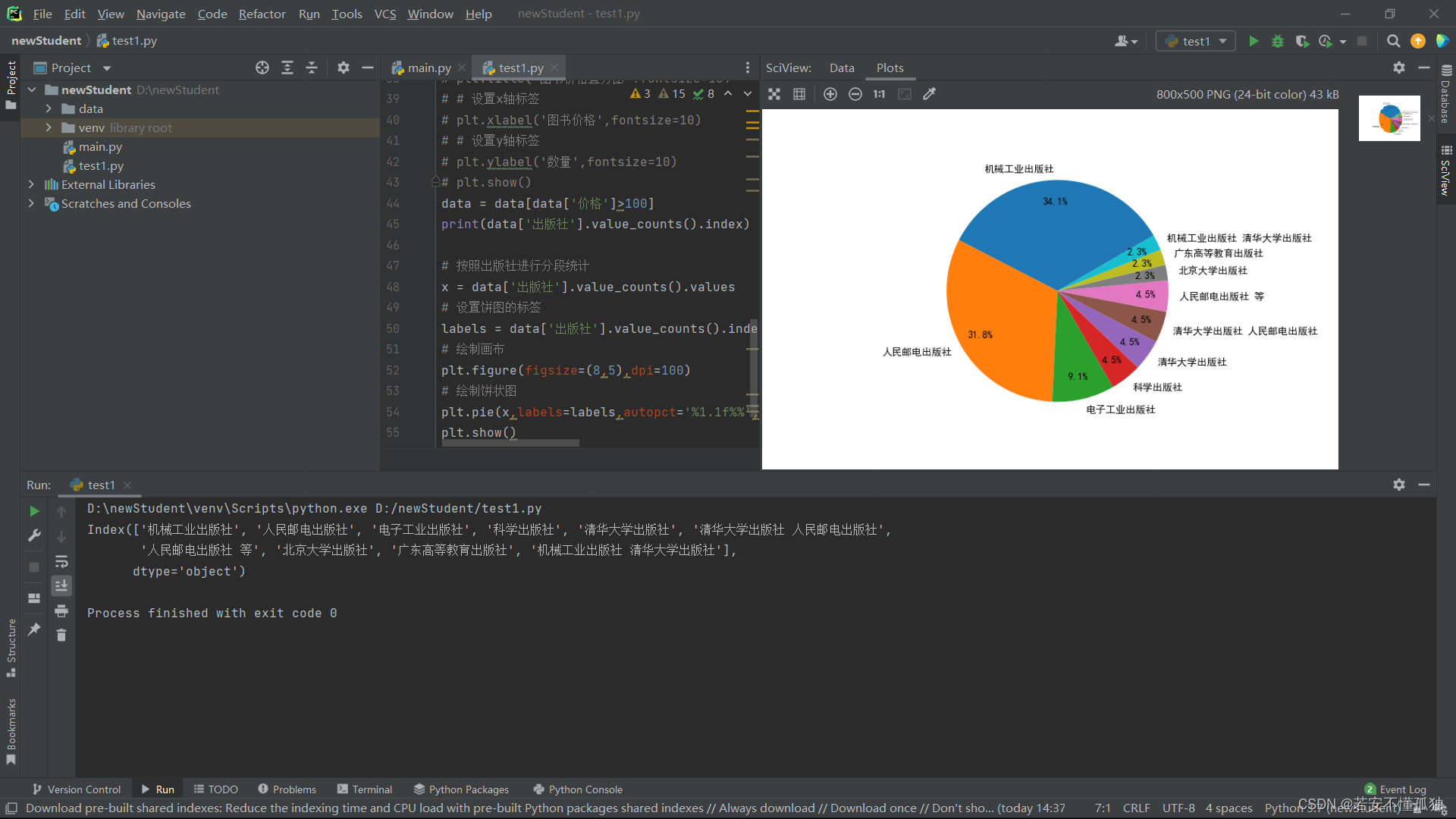
4,高价图书分析
- data = data[data['价格']>100]
- print(data['出版社'].value_counts().index)
-
- # 按照出版社进行分段统计
- x = data['出版社'].value_counts().values
- # 设置饼图的标签
- labels = data['出版社'].value_counts().index
- # 绘制画布
- plt.figure(figsize=(8,5),dpi=100)
- # 绘制饼状图
- plt.pie(x,labels=labels,autopct='%1.1f%%',startangle=30,pctdistance=0.8,radius=1)
- plt.show()
运行结果
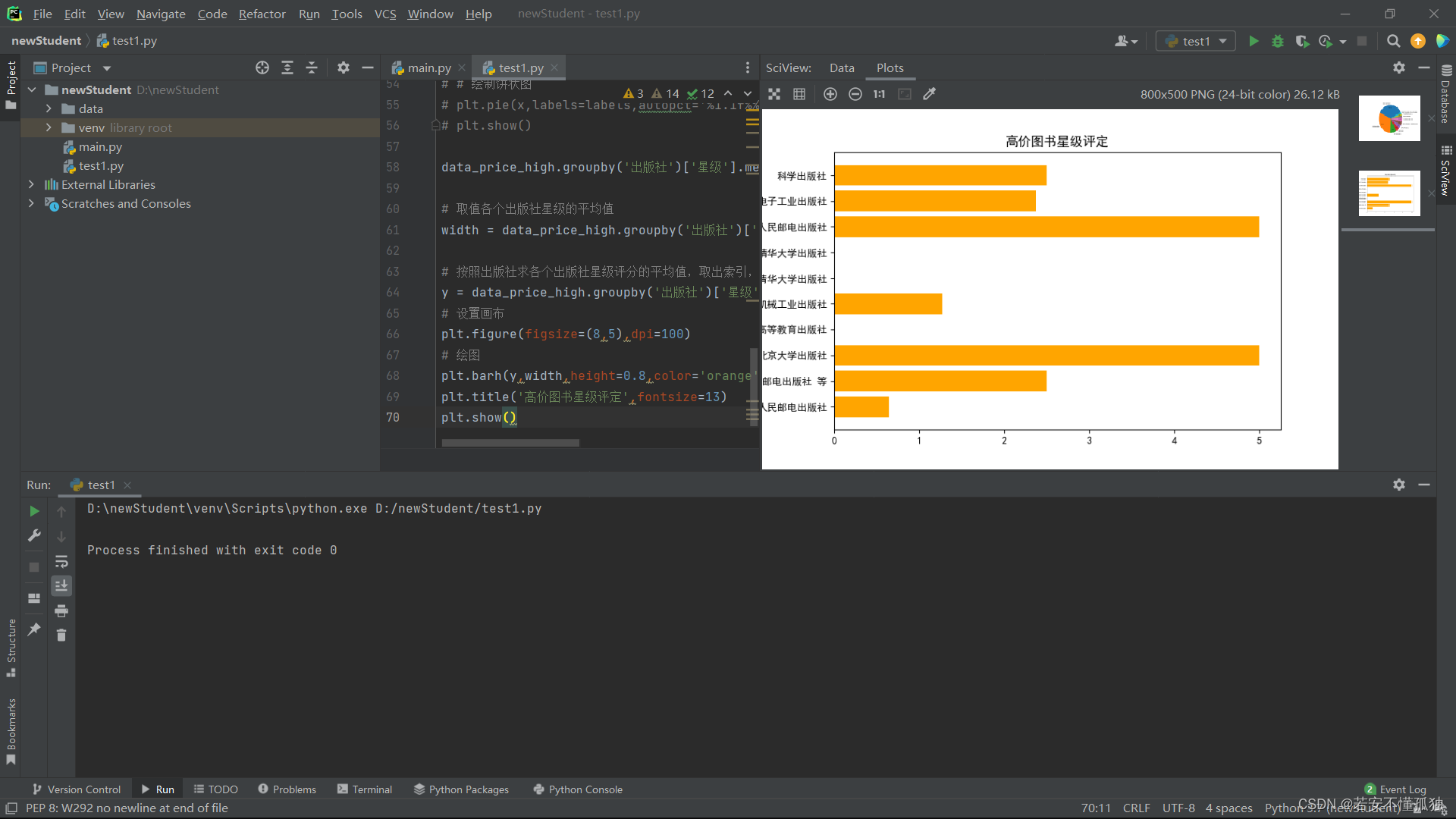
5,高价图书星级评定
利用饼状图分析了高价图书出版社占比情况,接下来对高价图书中各个出版社的星级评定进行分析,利用条形图查看哪些出版社的星级评分好。
利用Matplotlib子模块pyplot中的barh()函数绘制柱状图,其中,主要参数有:
- y:y坐标
- width:柱子的宽度,即统计的数值大小
- height:柱子的高度,默认为0.8
- # 取值各个出版社星级的平均值
- width = data_price_high.groupby('出版社')['星级'].mean().values
-
- # 按照出版社求各个出版社星级评分的平均值,取出索引,即出版社
- y = data_price_high.groupby('出版社')['星级'].mean().index
- # 设置画布
- plt.figure(figsize=(8,5),dpi=100)
- # 绘图
- plt.barh(y,width,height=0.8,color='orange')
- plt.title('高价图书星级评定',fontsize=13)
- plt.show()
运行结果
6,图书简介文本分词
上面我们对各个出版社的价格、星级等方面进行了分析,接下来我们对图书的简介进行分析,最终形成一个词云图,词云图又叫文字图,是对文本数据中出现频率较高的关键词予以视觉上的突出。首先数据中简介1这一列是文本类型,因此我们要先进行分词,分词的目的是将文本按一定的规则进行分词处理。在这里我们使用jieba库里面的cut函数进行分词,jieba库是专门使用Python语言开发的分词库,占用资源较少,常识类文档的分词精度较高。
cut函数的主要参数如下:
- sentence:要进行的分词的句子样本
- cut_all:分词的模式,有全模式和精准模式,默认false,精准模式
- HMM:隐马尔科夫链,即HMM模型,默认开启,这个是在分词的理论模型中用到的
- # 对数据集的每个样本的文本进行中文分词
- #记录分词后的结果
- cutted = []
-
- for item in data['简介1'].values:
- raw_words = (" ".join(jieba.cut(str(item))))
- cutted.append(raw_words)
- # 创建一个新的DataFrame,将没分词和分词后的句子添加到里面
- data_cutted = pd.DataFrame({
- '简介1': data['简介1'],
- '简介1_cut': cutted
- })
-
- print(data_cutted.head())
运行结果

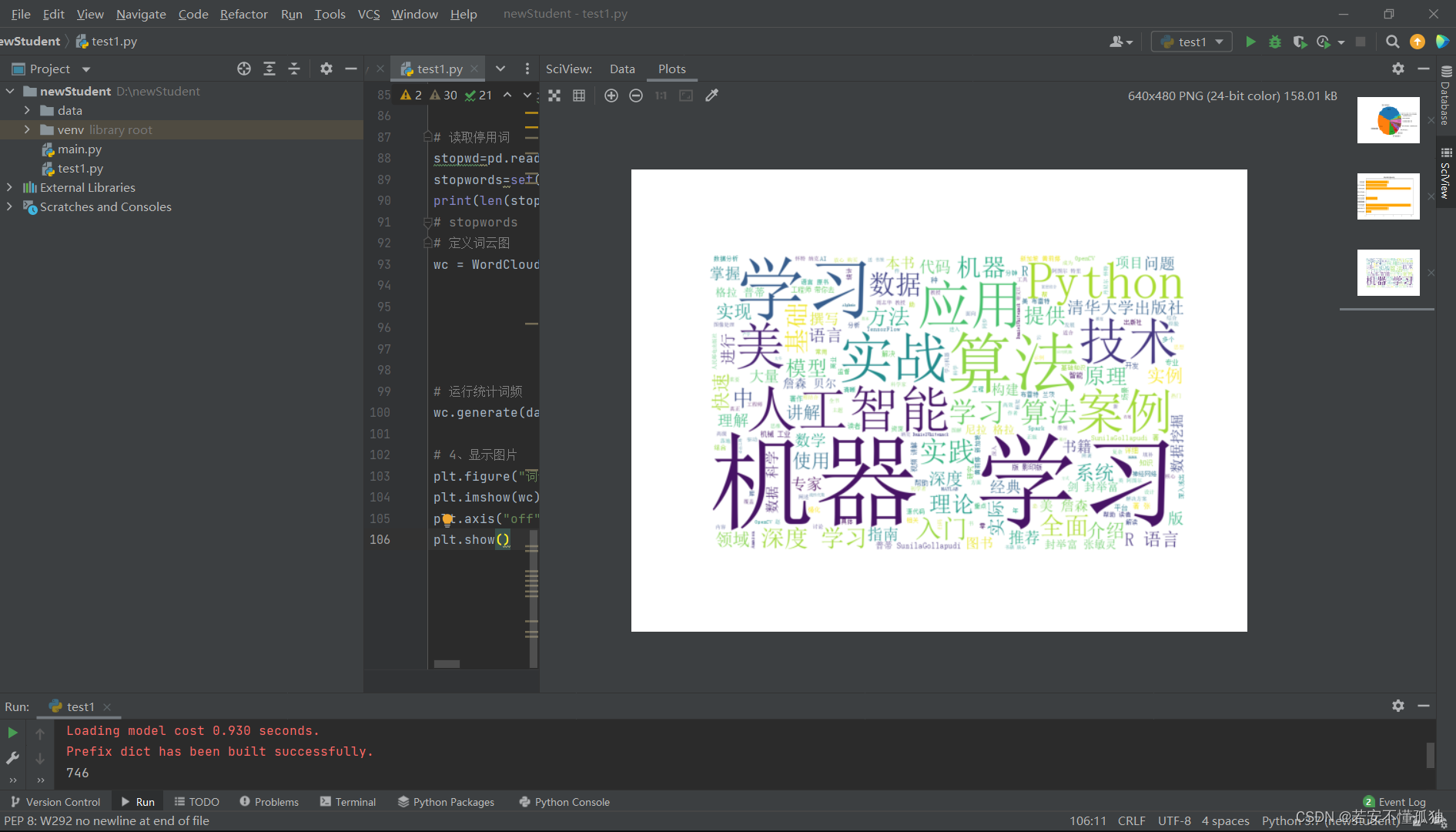
7,词云图
分词处理完毕后,再处理停用词,最后形成词云图。利用wordcloud中的WordColoud()函数绘制词云图,其中主要参数为:
- font_path:字体路径
- stopword:将被忽略或者是删除的单词表
- width:词云图的宽度,默认400
- height:词云图的高度,默认200
- max_font_size:最大字体的大小
- # 读取停用词
- stopwd=pd.read_csv('D:/newStudent/data/test1//中文停用词表数据集.csv')
- stopwords=set([i for i in stopwd['cn_stopwords']])
- print(len(stopwords))
- # stopwords
- # 定义词云图
- wc = WordCloud(font_path = "./dataset/simsun.ttc",#设置字体
- stopwords = stopwords, #设置停用词
- background_color = 'white',
- width = 1000,
- height = 618,
- max_font_size = 400)
- # 运行统计词频
- wc.generate(data_cutted['简介1_cut'].sum())
-
- # 4、显示图片
- plt.figure("词云图") #指定所绘图名称
- plt.imshow(wc) # 以图片的形式显示词云
- plt.axis("off") #关闭图像坐标系
- plt.show()

运行结果
四,结论
feeling:可视化分析是what???=>让庞大的数据通过科学有效的手段以一种更为直观的方式(图)展现出来。

