
- 1前端在WebSocket中加入Token_websocket token
- 2程序员真是个悲哀的职业!_程序员的性格通病
- 3【论文翻译】Learning from Few Samples: A Survey 小样本学习综述_小样本图像分类英语论文
- 4docker的安装,以及通过docker拉取nacos镜像和启动_nacos docker镜像
- 54种 MySQL 同步 ES 方案_es 同步
- 6Django连接SQL Server配置指引_django.db.backend.odbc isnt an availablr
- 7互联网没有下半场
- 8程序员面试 10 大潜规则,千万不要踩坑!
- 92022最新Macbookpro M1芯片 搭建RocketMQ_mac pro 电脑安装rocketmq
- 10屠杀机器人和无处不在的监控:AI是我们最大的生存威胁?
仓颉编程语言 -- 初识(二)_仓颉语法
赞
踩
4、卓越性能
仓颉语言通过值类型、多层级静态分析优化和超轻量运行时,在计算机语言基准测试Benchmarks Game上,相比业界同类语言取得了较为明显的性能优势。
4.1 静态编译优化
仓颉编译采用模块化编译,编译流程间通过IR作为载体,不同编译优化之间,做到互相不影响。对于编译优化的适配,编译流程的调整,拥有更高的自由度。
仓颉语言使用静态编译手段,将仓颉程序、核心库代码等编译成机器代码,加速程序运行速度。
4.1.1 GC相关优化
仓颉静态编译中,添加了许多运行时联合优化。例如对于堆上对象读写的优化、堆对象创建的优化、以及堆内存管理信号机制的优化等。静态分析和运行时的联合优化,加快了仓颉程序在对象的创建、读写、成员函数调用等方面的运行速度。
仓颉静态后端同时对于堆对象的访问时,使能了向量化优化,保证数据读写、运算速率,尽量减少GC Barrier对性能的影响。对堆对象的活跃作用域的分析,也保证了静态后端能够对堆对象的分配地址拥有决定权,无论在堆、栈或常量区,静态后端能根据对象特性来进行分配优化。
仓颉对于栈上引用的精确记录,能够加快GC 信息采集速度。精确栈对象的记录,减少了垃圾回收根集合的数量,避免了对象指针的冗余地址判断。在扫描和fix阶段,保证了GC程序高效运行。
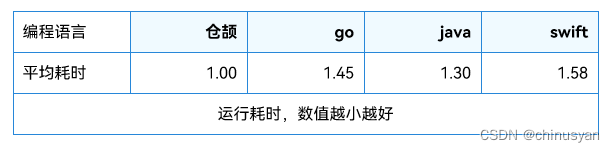
结合GC功能,仓颉语言对于对象的创建、读写上进行了fastPath优化。如下图所示,在编译访存操作时,生成快速路径和高效判断快速路径的指令,减少性能开销。
4.1.2 逃逸分析
仓颉语言在做全局分析优化时,增加了引用的逃逸分析。对于引用的类型,仓颉语言分析该引用的生命周期,对于未逃逸出其所在函数的引用,可以采用栈上分配优化。如下代码所示,其中包含了部分逃逸分析结果。
class B {} class A { var a : Int64 = 0 var b : B = B() } var ga : A = A() func test1(var a : A) { a.a = 10 } func test2(var a : A) { ga = a // escape to global } func test3(var a : A, var b : B) { a.b = b } main() { var instance : A = A() // alloca on stack, not escape out this func instance.a = 10 var instance1 : A = A() // alloca on stack, test1 not escape param a test1(instance1) var instance2 : A = A() // gc malloc in heap, test2 escapa param a test2(instance2) var instance3 : B = B() // alloca on stack, instance3 store into instance1, but instance1 not escaped. test3(instance1, instance3) var instance4 : B = B() // gc malloc in heap, instance4 store int instance2 and instance2 escaped to global. test3(instance2, instance4) }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
通过栈上分配优化,可以直接缩减自动管理内存的GC压力,减少堆上分配内存和频率,降低垃圾回收频率。对于堆上内存的读写屏障,也会因为栈上分配从而变成直接的数据存取,加快了内存访问速度。对象栈上分配后,对于栈上内存,又可以额外采用例如SROA,DSE等优化措施,减少内存读写次数。
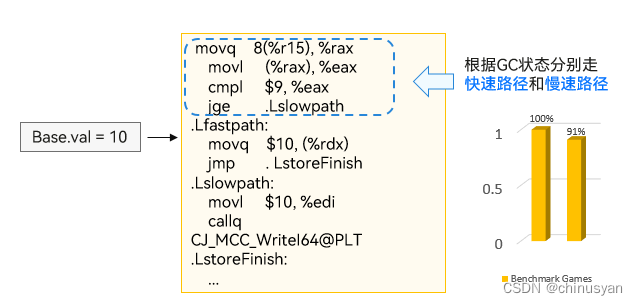
4.1.3 类型分析/去虚化
仓颉语言支持全局类型静态分析和结合Profile的类型预测。仓颉语言支持类型继承,支持虚函数、接口函数调用,对于虚函数、接口函数的调用,相比较Direct Call增加了额外的查找、访问开销。
对于全局引用、局部引用、过程间引用等,通过静态分析的方式,仓颉语言将部分虚函数调用改写为Direct Call,加速函数调用,提升函数内联等优化机会。
在PGO模式下,仓颉语言支持虚函数调用的类型、数量统计,通过Profile信息捕捉到的热类型、热调用部分,通过保守去虚化的方式,加速函数调用和程序执行。
4.2 值类型
仓颉语言引入了值类型对象,值类型的局部变量在读写时无需GC相关屏障,在进行内存读写时,能够直接访问,无需考虑引用信息的变化。合理利用值类型语义,能有效加速程序运行。
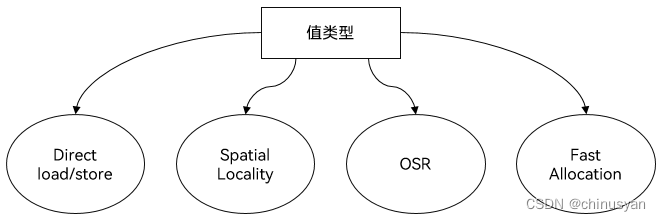
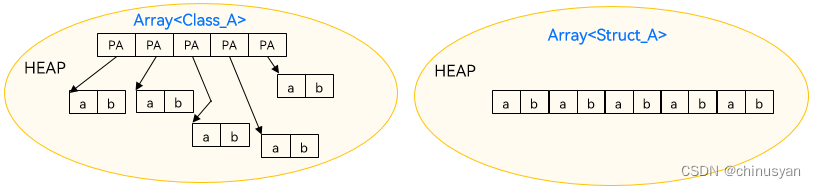
值类型提供了更多数据排布和访问的方式。通过合理的数据结构设计,使得数据在访问上能够拥有优秀的空间/时间局部性,在运算、访问等操作上能够带来更大优势。如下图所示,类A的数组在访问数组内成员的成员变量时,需要进行2次load,而对于值类型的数组,对于A里成员变量的访问时,仅需1次load。
**OSR(On Stack Replacement)**优化对于值类型非常友好,在合理OSR的情况下,部分值类型数据能够直接打散到寄存器中,对于数据访问、运算等带来更大优势。例如下述示例,值类型SA对象,被打散成a和b,而a和b都可以在寄存器中表示,而不用再进行重复的load。后续再通过常量传播可以直接将a和b用常量表示。
struct A { var a : UInt64 = 10 var b : UInt64 = 100 } main() { var SA = A() var sum = 0 for (i in 0..100) { sum += SA.a } return sum + SA.b } => main() { var a = 10 var b = 100 var sum = 0 for (I in 0..100) { sum += a } return sum += b }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
值类型在分配时相比较引用类型更快,在回收时更快速、高效,跟随栈空间的回退,值类型自动回收,无需额外操作。
在引用类型下,会出现深拷贝,引入了额外的访存开销。使用值类型可以改造这类场景,就避免了间接寻址和深拷贝。尤其在处理基础类型时,如数字、布尔值等,将会带来更大优势。
4.3 全并发整理GC
仓颉提供全并发(fully concurrent)的内存标记整理GC算法作为其自动内存管理技术的底座,具有延迟极低、内存碎片率极低、内存利用率高的优势。
4.3.1 消减GC暂停时间
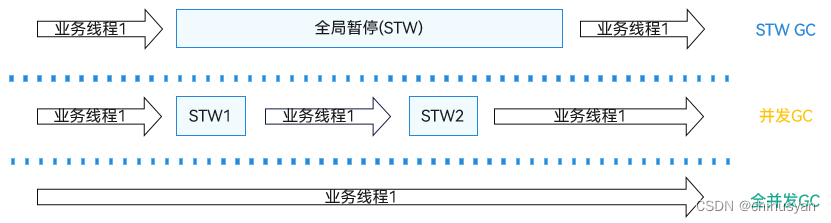
在有些时延敏感的重要场景里,STW GC或近似并发GC难以满足技术规格。比如移动场景高达120Hz的屏幕刷新率(预计后续会更高)要求绘制一帧的总体耗时小于8ms,毫秒级的GC暂停可能成为主要的时延因素。在千级乃至万级的高并发场景里,近似并发算法需要在单次STW里完成上千个调用栈的扫描,这个量级的扫栈操作可能使得STW的时间延长到超过十毫秒。
相比于现有的STW GC以及mostly concurrent GC(参考下图), 仓颉的全并发GC摒弃了STW作为GC同步机制,采用了时延更短的轻量同步机制,其应用线程完成GC同步的平均耗时小于百微妙,典型情况下数十微妙即可完成GC同步。
能实现如此高效的GC同步主要基于以下亮点关键要素:
-
安全点
并发GC需要处理GC线程与应用线程之间的状态同步关系。“安全点”机制是GC线程用于控制应用线程实现GC状态同步的技术手段。“安全点”机制包括两个组成部分:一是由编译器在编译仓颉代码时插入的安全点检查代码,一般插在必经路径上,比如函数头或尾,循环回边等处;二是GC算法中实现的安全点同步逻辑。当GC线程需要把GC状态同步到特定应用线程时,GC线程先激活该应用线程的安全点检查,后续当该应用线程执行到安全点检查代码时,看到自身的安全点处于激活状态,就会响应GC的同步请求,改变自身的GC状态至指定状态。通过安全点机制,GC现成可以控制应用线程的GC状态变更,配合内存屏障,让并发GC得以正确执行。不同的GC状态需要相应的内存屏障配合。 -
内存屏障
仓颉语言实现的全并发GC还需要正确处理三类数据竞争关系:
(1) GC线程与应用线程之间的数据竞争关系。
(2) GC线程之间的数据竞争关系。
(3) 由于应用线程分担了部分GC的工作,应用线程之间也存在由GC引入的数据竞争关系。
“内存屏障”机制用于解决GC线程与仓颉线程的数据竞争。在并发GC中,最广泛存在的数据竞争是GC线程与应用线程的竞争。比如当GC线程想要把某个活对象移动到新地址,而几乎同时业务线程想要访问这个对象。内存屏障用于在应用线程访问内存时,可以跟GC线程采取协调一致的操作。
4.3.2 减少内存碎片和内存峰值
仓颉GC采用的内存整理技术是当前流行的用于内存回收最前沿的技术之一(当然其算法实现的复杂度也相对增加)。相比于现有的Mark-Sweep算法,内存整理技术可以把分散的活对象搬移到更紧凑的内存布局里,大幅地减少了内存碎片。相比于复制算法把from-space中的活对象全部复制到to-space后,才能释放from-space的内存,内存整理技术可以一边搬移活对象、一边释放已经完成整理的内存块,消除复制GC带来的内存尖峰。
在仓颉的全并发标记整理GC中,仓颉堆内存被划分为小块连续内存,称为region. from-region是from-space中的一个 region,to-region是to-space中的一个 region. 在堆内存整理过程中,from-region中的活对象都被搬移到合适的to-region里,构成更紧凑的内存布局。搬移完成后,这个from-region即可被释放用于分配新对象。在内存压力大的情况下,from-region和to-region在内存空间上可以重叠,进一步降低内存峰值。
4.3.3 极快的对象分配速度
得益于仓颉GC采用的对象搬移技术回收内存,仓颉运行时实现了基于指针跳动(bumping-pointer)技术的对象分配方式,这是现有先进的内存分配技术,平均约10个时钟周期就可以完成一次内存分配。
4.3.4 优化GC开销
仓颉的全并发内存整理算法采用指针标记来加速识别访存操作中的快速路径。指针标记把仓颉对象中的引用成员分为三种状态:(1) 未标记;(2) 已标记且是在当前GC过程中被标记,称为”current pointer”;(3) 已标记且是在上一次GC过程中被标记,称为”old pointer。未被标记的指针就是仓颉对象的真实地址,可以直接用于访存,这是访存的快速路径。old pointer是来自于上一次GC,还未修复的旧指针,需要在enum和trace阶段由GC线程或内存屏障查询转发表后更新。current pointer是在当前GC的enum和trace阶段被标记,用于指示哪些对象可能别移动。当内存屏障访问到被标记的old pointer时,需要查询转发表获取新地址。当内存屏障访问到被标记的current pointer时,需要根据当前的GC状态进一步判断该对象是否已经被转移,如果已经被转移,则查询转发表获取新地址,否则,内存屏障需要把该对象转移到相应的to-region,并且更新被标记的指针。
在仓颉的全并发内存整理算法里,被标记的指针是按需用lazy的方式被更新,只有在被内存屏障访问时,被标记的指针才会被更新。如果未被访问到,被标记的指针会被保留到下一次GC的enum和trace阶段更新。这个策略可以显著减少GC过程的持续时间。
4.3.5 适配值类型
如前述,在仓颉语言中引入值类型赋予开发者更优越的内存和性能开发选择,但也使GC的实现更加复杂。对于纯引用的编程语言(如Java、JavaScript、Kotlin),除基础类型外,其它类型都是引用类型,这个模型对于GC算法更加友好。值类型在两个方面使GC算法变得更加复杂:(1) 值类型的数据可能是其它数据的成员,也可能是独立的全局或局部变量,两种情况下的数据处于不同的内存区域,但是对于值类型的成员方法而言,二者必须具有统一的行为定义。(2) 值类型的数据是以内嵌的形式从属于其它值类型或者引用类型,内嵌改变了内存布局。在支持对象搬移的仓颉GC实现过程中,结合值类型特性,GC的工程复杂度大幅增加了。考虑到值类型带给开发者更强大更便利的表达能力、更优越的应用性能和内存表现,在仓颉语言实现上的内部复杂度增加是物有所值的。
4.4 轻量化运行时
仓颉语言提供了超轻量化的运行时,不但自身的分发开销低,也帮助应用以极低的开销部署和运行。
通过软件工程的优化手段,仓颉运行时库剔除了不必要的冗余代码,移除了对c++运行库的依赖,减少了外部可见符号的定义,其二进制体积达到了1MB量级。针对嵌入式的定制优化后的运行时共享库的体积更小,可以达到约500KB这个量级。
仓颉轻量化运行时支持用户态线程以极低的开销创建、运行和调度。用户态线程的创建耗时只需数百纳秒,用户代码执行栈内存仅有数KB,单次调度耗时只需数百纳秒。
仓颉轻量化运行时实现了仓颉语言与C语言互调的开销接近零成本。在底层实现上,仓颉语言的ABI定义与C语言高度兼容。仓颉语言支持的C兼容类型(通过“@C”关键字修饰)具有和C语言一致的内存布局,在典型场景里,仓颉语言与C语言数据可以实现无转换地共享。
仓颉轻量化运行时为开发者提供了灵活的应用剪裁技术,帮助开发者优化应用的包体积。仓颉语言的反射机制支持按需使能,可以在不需要时关闭反射能力。对于仓颉包内的私有方法可以通过函数粒度的按需链接清除冗余代码。
在轻量化运行时的帮助下,仓颉应用的部署和启动开销极低,应用启动时长在十毫秒级别,空载应用内存在1MB量级,在嵌入式场景里空载内存小于1MB。
5、敏捷扩展
现代软件开发中,领域特定语言DSL由于其贴近领域问题,可以降低软件开发和维护的复杂度,因而承担了重要的作用。从DSL实现角度,内部DSL(embedded DSL,简称eDSL)是将一种现有的通用编程语言作为宿主语言,使用宿主语言提供的语言特性来扩展面向领域的语法,其相比完全独立构建DSL的实现方式(专门的语法解析、编译优化及配套工具等)具备以下优势:
- 可复用宿主语言的语言特性,表达力强。
- 可复用宿主语言配套设施(库生态,编译工具,开发环境等),构建门槛低。
- 无缝嵌入到宿主语言工程中,可以高效的穿越“领域”进行数据交互。
因而eDSL被广泛应用于各个领域,比如UI布局、数据库访问、云基础设施部署、编译脚本等场景。相应的,仓颉编程语言通过提供丰富的语言扩展能力,来支持面向领域的eDSL构建。
本章以下内容首先着重介绍仓颉提供语言扩展能力,包括基于原生语法的扩展能力,以及允许开发者构建新语法的元编程能力,最后以声明式UI为例介绍如何使用以上能力以及带来的效果。
5.1 原生语法扩展能力
本节主要介绍一些仓颉原生语法特性在构建eDSL上的应用。使用这些语法来编写的代码,既是eDSL的程序,符合领域习惯,具有领域特定含义,又“天然”是合法的仓颉程序。这些语法大多在高效编程章节给出了介绍,这里我们重点介绍它们在构建eDSL中的作用。
5.1.1 类型扩展和属性
类型扩展允许我们在不侵入式修改原类型的前提下,为其添加新的功能,尤其是针对语言的原生类型,以及一些外部库定义的类型,这种扩展可以提高类型的易用性。属性机制可以为字段访问提供getter和setter支持,隐藏对数据访问的细节,但我们还可以像直接访问字段那样的语法来隐式调用getter和setter。这两种特性结合,就能写出一些能够自然表达领域含义的程序。例如在图书馆借书的场景,我们想把还书的时间设置为2周后的日期,构造一种类似自然语言的表达,那么期望写成:
var bookReturnDate: DateTime = 2.weeks.later
- 1
这里可以使用属性重新实现对Int64的扩展:
extend Int64 {
prop weeks: Int64 {
get() {
this * 7
}
}
prop later: DateTime {
get() {
DateTime.now() + Duration.day * this
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
5.1.2 命名参数和参数默认值
在构建eDSL时,需要针对一些对象进行参数配置,通常会遇到两类问题:
- 配置参数较多,容易弄错顺序。
- 不希望每次把所有参数配置都写一遍,大多数情况下应该使用默认值。
针对这种场景,可以结合命名参数和参数默认值的特性来解决,比如我们要设置在平面上所占的矩形区域的大小,需要确定其上下左右的位置,通常其上边和左边默认为0坐标,可以实现如下:
class Rect {
static func zone(top!: Int64 = 0, left!: Int64 = 0, bottom!: Int64, right!: Int64): Rect {
//
}
}
- 1
- 2
- 3
- 4
- 5
那么在使用时可以更清晰的进行矩形区域的配置,比如允许以下调用方式
Rect.zone(bottom: 10, right: 10) // top和left采用默认值
Rect.zone(top: 5, bottom: 10, right: 10) // left采用默认值
Rect.zone(right: 10, bottom: 10) // 无需记住参数顺序
- 1
- 2
- 3
5.1.3 操作符重载
操作符重载可以使一些非数值类型的对象,实现算数运算符的语法,比如在图书馆的例子中,之所以能写出
DateTime.now() + Duration.day * this
- 1
实际上是在仓颉标准库中,分别对DateTime的“+”操作和Duration的“*”操作进行重载,比如:
//DateTime
public operator func +(r: Duration): DateTime
//Duration
public operator func *(r: Int64): Duration
- 1
- 2
- 3
- 4
- 5
5.1.4 尾随lambda
前文介绍了尾随lambda的概念,并从构建DSL的视角介绍了它的用途。这里我们再给出一个声明式UI中的例子,人们可以用尾随lambda表达组件间的分层关系,构造一种类似HTML的表达范式:
Column {
Image()
Row {
Text()
Text()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
其中Column其实是对名为Column函数的调用,而后面的花括号其实是仓颉的lambda表达式,是Column函数调用的参数,以尾随lambda的方式提供。Row中采用的也是同样的语法。
5.1.5 关键字省略
eDSL的语法噪音是指由宿主语言引入,但又与领域实际的业务抽象无关的语法。语法噪音会影响eDSL的可读性。仓颉支持构造对象时省略new,允许行尾省略“;”,以及函数返回值省略return的能力,可以进一步简化eDSL表达,降低语法噪音。
5.2 宏
宏可以看作是一种“代码缩写”,也可以看做是一种扩展语言语法的方式。在编译或者程序运行过程中,看到这种代码缩写,会将其替换为实际对应的代码(即所谓的宏展开)。如果有些功能可以用统一且简单的代码来表达,那么就可以使用宏来处理。仓颉提供了在词法分析阶段做宏展开的过程宏,未来还将进一步提供更多简单易用且表达力丰富的宏定义方式,包括late-stage宏和模板宏等。
5.2.1 过程宏
仓颉的过程宏接受一个token序列作为输入,对齐进行处理和变换后,输出另一个token序列。输入的token序列由词法分析器产生,因此必须满足仓颉的词法规则,但无需满足仓颉的语法规则。输出的token序列必须满足仓颉的语法语义,是合法的仓颉程序。我们可以通过下面的例子来展示过程宏的工作原理。这里我们调用一个以expensiveComputation()作为参数的DebugLog 宏。这个宏在编译时会判断程序是配置在开发模式下运行还是在生产模式下运行。在开发模式下,会运行expensiveComputation()这样一个昂贵的诊断计算,并打印调试输出,以帮助发现和定位问题。在生产模式下,为了降低性能开销,我们不希望运行这个函数,也不会产生调试输出。
@DebugLog( expensiveComputation() )
上述的宏DebugLog 可以这样实现:
public macro DebugLog(input: Tokens) {
if (globalConfig.mode == Mode.development) {
return quote( println( ${input} ) )
}
else {
return quote()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
仓颉的宏定义语法与函数定义类似,其参数只能是token序列(即Tokens类型),其返回值是经过变换后的token序列。这个返回值就是宏调用(宏展开)后实际生成的代码。在上面的例子中,如果是在development模式下,返回值会在输入的token序列外面,加上println调用,因此除了执行input部分,还会把执行结果打印出来。如果不是development模式,则返回空序列,也就是完全忽略了input部分,不会生成任何代码。
5.2.2 Late-stage宏和模板宏
下面我们介绍两种正在开发中的宏定义,即Late-stage宏和模板宏,它们将在仓颉未来的版本中发布。
上述过程宏的输入token序列不包含程序的语义信息,但在某些情况下,我们希望在宏定义中根据有关变量的类型或类和接口声明的信息做出相应的处理,这种能力很难通过过程宏来实现。以下面的程序为例:
@FindType
var x1: Employee = Employee("Fred Johnson")
// getting the type info of `x1`: easy, it's right there
@FindType
var x2 = Employee("Bob Houston")
// getting the type info of `x2`: hard, requires type inference
- 1
- 2
- 3
- 4
- 5
- 6
- 7
假设宏FindType希望得到下面变量声明中变量的类型,并将其打印或加入日志。对于x1来说,它的类型(Employee)在语法中已经明确给出了,我们可以在输入的token序列中将其提取出来。然而,变量x2的类型在声明中并没有明确给出来,因此无法从输入token序列中直接得到。其类型信息需要靠类型推断计算出来,但宏展开是发生在语法分析阶段,类型推断还没有进行,因此我们还不具备相关信息。Late-stage宏通过将宏展开延迟到类型推断之后,能够获取并利用程序的各种语义信息,包括这种推断的类型信息。
Late-stage宏允许基于类型信息和代码中的非局部定义生成代码。这是一个强大的功能,它扩展了宏定义的处理能力。但它同时也是一个表达力更受限制的特性,因为在类型已知之后,对现有代码的根本更改不再是可能的。
如果我们希望对一些具有非常固定语法模式的代码做一些重写,那么模板宏会是比普通的过程宏更易用的选择。
public template macro unless {
template (cond: Expr, block: Block) {
@unless (cond) block
=>
if (! cond) block
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
上面的模板宏定义将允许用户写出如下的程序:
@unless (x > 0) {
print("x not greater than 0")
}
- 1
- 2
- 3
宏展开时将会根据上面模板宏的定义,匹配上面的模板,提取出cond和block,然后将其转换为:
if (! x > 0) {
print("x not greater than 0")
}
- 1
- 2
- 3
模板宏的优点在于,它直接描述预期的源代码和目标代码,将重点放在关键代码段的转换上。虽然过程宏可以做同样的事情,但过程宏的定义会更加冗长且易出错。
5.2.3 敏捷扩展案例:声明式UI
声明式UI是一种面向UI编程的开发范式,它使开发者只需要描述UI组件间的布局关系、以及UI组件与状态(即渲染所需要的数据)间的绑定关系,而不需要关心UI界面实际渲染刷新的实现细节,因而提高了开发者的开发效率。近几年业界UI框架开始采用eDSL的方式构建声明式UI,本节以声明式UI为例,介绍如何使用仓颉的领域扩展能力来构建UI eDSL。
UI组件布局
UI eDSL首先需要具备描述各种组件在二维平面如何排布的能力,能够清晰的表达组件的长、宽等配置信息,以及组件间的层次关系;同时期望UI eDSL能使代码结构与UI界面具备一定的相似性,达到“所见即所得”的效果;另外UI eDSL应该非常简洁,尽量减少UI描述以外的“噪音”。
假设要实现如下所示的UI界面,它由一段文本和一个按钮组成,文本和按钮需要纵向居中排列;同时需要为按钮设置点击事件处理逻辑:
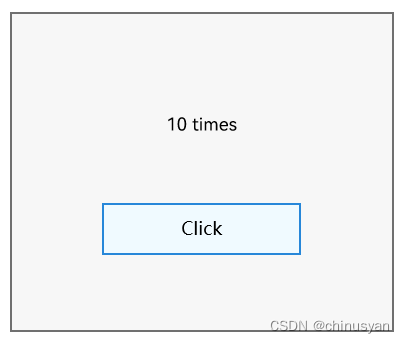
我们使用仓颉定义的UI eDSL,可以通过如下代码来描述期望的UI界面,其中Text组件显示一段文本,Button组件实现按钮功能,为了使它们纵向排列,把这两个组件嵌在一个Column布局组件中。
class CustomView { ... func build() { Column { Text("${count} times") .align( Center ) .margin(top: 50.vp, bottom: 50.vp) Button("Click") .align( Center ) .onClick { evt => count++ } }.width(100.percent) .height(100.percent) } ... }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
作为对比,假如仓颉不提供相应的扩展能力,可能需要开发者写出如下代码。从可读性上,前者更为清晰简洁;从字符数统计上,后者相比前者需要开发者多写近70%的代码,这在更为复杂的页面上,将是非常可观的开销。
class CustomView { ... func build() { new Column ({ => new Text("${count} times") .align(Alignment.Center) .margin(Length(50, Unit.vp), Length(0, Unit.vp), Length(50, Unit.vp), Length(0, Unit.vp)) new Button("Click") .align(Alignment.Center) .onClick ({ evt => count++ }) }).width(Length(100, Unit.percent)) .height(Length(100, Unit.percent)) } ... }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
那么在使用仓颉语言定义如上的eDSL时,我们采用了以下特性:
-
使用尾随Lambda来描述组件间的分层关系,比如Column作为Text和button的父组件,决定了子组件的排列方式;同时尾随Lambda也可以省略“()”,使语法更简洁。
-
使用命名参数和参数默认值的特性,使传参更清晰简洁,比如在设置margin时,只需要设置top和bottom,未设置的参数选择默认值;同时命名参数使得开发者清晰的知道设置的是哪个参数,不用专门去记参数顺序,提高了代码可读性,不易犯错。
-
通过类型扩展能力,为整数类型扩展出带有长度单位的表达能力,比如100.percent等价于“100%”,而50.vp等价于“50 vp”,其相比只用整数,提供了类型校验的保障;而相比使用Length类,语法更简洁,可读性更高。
-
仓颉支持类实例化时省略“new”关键字,通过类型推断实现省略枚举前缀(比如直接用Center而不是Alignment.Center),进一步增强了表达的简洁性。
UI组件与状态绑定关系
状态是一组与界面关联的数据,在声明式UI下,通常使用view = f(state)来表达UI界面(view)与状态(state)的关系,其中f作为view与state之间的纽带,由框架实现,并向UI开发者隐藏。通常f被实现为一套响应式的机制,即:
- 建立state到view中组件的绑定关系。
- 捕获state修改,触发相应组件的刷新。
我们修改上面的例子实现一个计数器。我们为组件增加一个状态count,同时为Button增加点击事件处理,每点击一次按钮,就使count自增1。另外组件Text会显示当前的点击次数,即count值。
class CustomView { @State var count: Int64 = 0 ... func build() { Column { Text("${count} times") .align( Center ) .margin(top: 50.vp, bottom: 50.vp) Button("Click") .align( Center ) .onClick { evt => count++ } }.width(100.percent) .height(100.percent) } ... }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
我们通过为count变量增加@State宏修饰,使其具有响应式的能力,即可以捕获在点击事件中的改动,并触发Text组件的刷新,而这种实现机制都隐藏在@State的宏实现中。以下是一种示意的宏展开代码逻辑(实际上如前所述,宏展开发生在编译阶段,展开逻辑以AST形式存在):
class CustomView { private var count_ = State<Int64>(0) mut prop count: Int64 { get(): Int64 { count_.bindToComponent() count_.get() } set(newValue: Int64) { count_.set(newVaue) count_.notifyComponentChanges() } } ... func build() { Column { Text("${count} times") .align( Center ) .margin(top: 50.vp, bottom: 50.vp) Button("Click") .align( Center ) .onClick { evt => count++ } }.width(100.percent) .height(100.percent) } ... }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
实现以上效果,我们采用了以下特性:
- 定义用于状态管理的宏
@State,其展开生成相应的状态处理代码,从而减少开发者编写一些模板化和重复性的代码,简化了状态声明和管理的复杂度。 - 采用属性机制,实现对实际状态数据的代理,对外保持读写count的形式,但在其内部实现中,通过get方法来捕获“读”操作,建立状态与组件的绑定关系;通过set方法捕获“写”操作,并通知其绑定的组件进行刷新。
以上通过声明式UI这个案例,展示了通过灵活使用仓颉的扩展能力,可以提高代码的可读性、简洁性和正确性,简化开发者负担,降低框架或者库的使用门槛,有利于生态推广。
6、工具支持
仓颉开发者工具聚焦用户开发体验,围绕编译构建、调试、性能分析与LLT验证等开发流程,提供包管理器、调试器、原生测试框架、IDE等常用的开发工具,帮助开发者提升开发与问题定位效率。开发者工具从以下几方面显著提升开发效率,降低开发负担:
- 包管理器:支持自动依赖管理和用户自定义构建,提供一站式编译构建能力;
- 调试器:支持跨语言调试和多线程调试,提升调试体验;
- 测试框架:包括单元测试框架、Mocking测试框架和基准测试框架;
- IDE:开发者在VSCode底座以及Huawei DevEco Studio底座安装仓颉插件后,实现开箱即用。
6.1 包管理器
通过包管理器cjpm提供项目级编译构建能力,自动依赖管理实现对引入的多版本三方依赖软件进行分析合并,无需开发者担心多版本依赖冲突问题,大大减轻开发者负担;同时提供基于仓颉语言原生的自定义构建机制,允许开发者在构建的不同阶段增加预处理和后处理流程,实现构建流程可灵活定制,能够满足开发者不同业务场景下的编译构建诉求。
6.1.1 自动依赖管理
对于项目中引入的多版本依赖模块,cjpm会对它进行依赖分析,计算出最终依赖,实现对依赖管理的自动化,开发者无需手动去管理项目中的依赖冲突问题,实现自动依赖管理后,包管理器在编译构建时,会扫描工程的所有依赖关系,对相同模块依赖的不同版本进行同类项合并,不会因为导入多版本的依赖产生编译构建错误,开发者只需要执行 cjpm build 就可以实现项目级构建,极大减轻开发者负担。
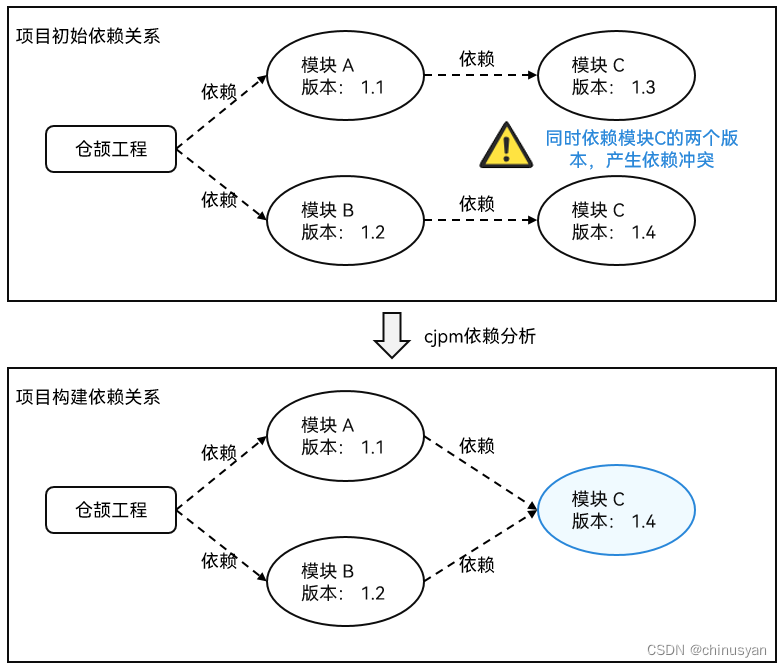
以上图为例:项目的直接依赖模块A和模块B,其中模块A依赖模块C的1.3版本,模块B依赖模块C的1.4版本,如果不做依赖分析和管理,编译时会由于多版本依赖产生依赖冲突,导致编译错误。通过cjpm的依赖管理,将模块C进行依赖分析后,合并到同一个版本依赖。
6.1.2 用户自定义构建
在仓颉项目构建时,开发者会有若干与编译仓颉代码有一定关联性的其他自定义行为诉求,如环境变量配置、外部依赖库的拷贝、CFFI源码依赖时需要先编译C文件的前置操作等,如 Rust语言通过cargo工具提供build前置构建的开发者自定义配置。
cjpm 允许开发者在任意构建阶段增加前置/后置自定义构建行为,帮助开发者解决复杂项目构建问题,无需切换其他构建工具,实现项目的一站式构建管理。

以上图为例:开发者自定义了编译cffi模块的stagePreBuild任务和删除cffi源码的stagePostBuild任务,当执行build命令时,cjpm会先执行stagePreBuild任务,build完成后再执行stagePostBuild任务。
6.2 调试器
通过调试器cjdb提供源码级调试能力,支持仓颉跨语言调试,比如单步进入/退出跨语言函数代码、跨语言下的完整调用栈查看,一个调试器完成多种语言的调试,同时支持对仓颉线程进行调试,进一步提升用户调试体验。
6.2.1 跨语言调试
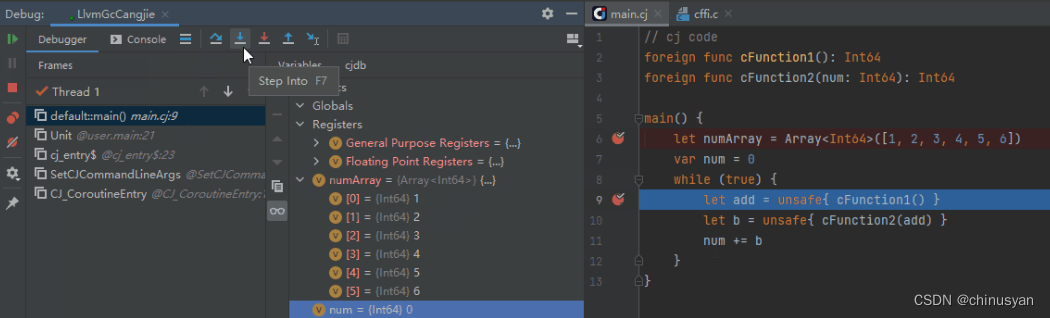
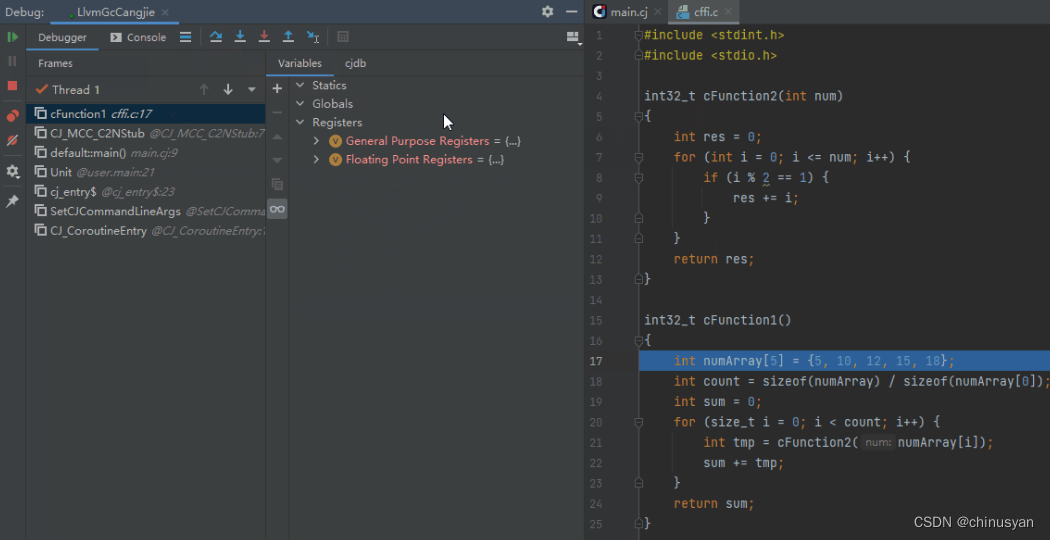
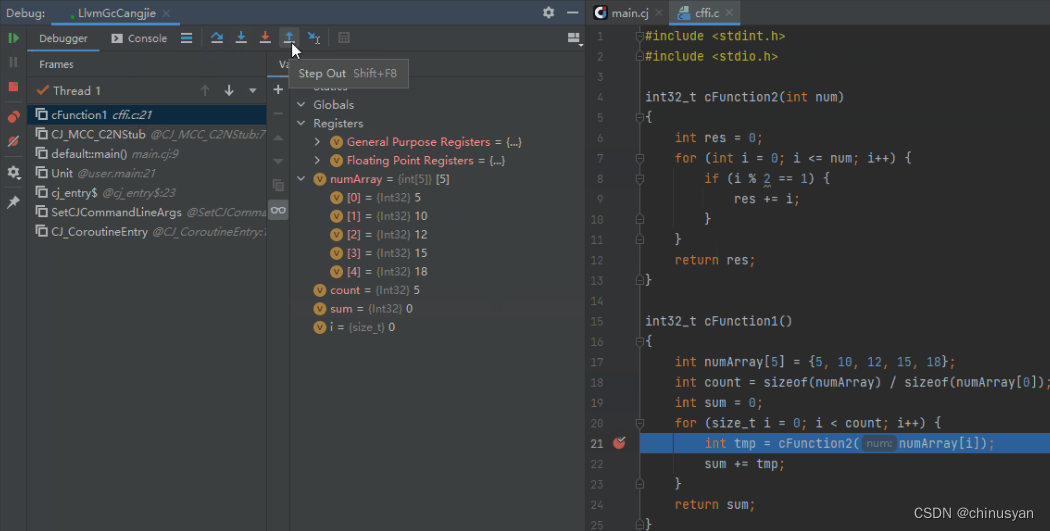
调试器在单步过程中识别跨语言互操作胶水代码层,自动计算目标函数地址,过滤用户不关心的胶水代码,使得跨语言函数调用的单步进入/退出与普通函数调用无异,多种语言调用栈能够自动拼接展示,带给开发者的调试体验更佳。在下面的图中,展示了IDE中仓颉调用C函数的跨语言调试。
图示1:仓颉->C 跨语言调用
图示2:仓颉->C 跨语言单步进入
图示3:仓颉->C 跨语言调用栈,FFI-C函数内单步调试
6.2.2 仓颉线程调试
仓颉支持基于仓颉线程的多线程并发编程,仓颉程序执行时仓颉线程与系统线程是M:N的关系,仓颉线程数量往往非常庞大。由于仓颉线程之间的调用是异步的,如果出现异常,无法像普通程序那样进行捕获和处理。仓颉调试器支持对仓颉线程设置断点,查看仓颉线程的调用栈。

6.3 原生测试框架
仓颉的原生测试框架构建在仓颉的标准库中,为用户提供了先进的测试体验,既允许传统和简单的测试技术,也允许更先进的技术用于更高级的测试场景。测试框架包括三个主要部分:单元测试框架、Mocking测试框架和基准测试框架。
6.3.1 单元测试框架
单元测试框架,顾名思义,允许用户在他们的仓颉项目中创建单元测试。除了能够像实现单个仓颉函数一样创建简单的单元测试之外,它还提供了各种更高级的技术:
- 参数化测试:基于多种输入参数运行被测试代码;
- 数据驱动测试:从文件中读取多组测试数据,作为入参,运行同一份测试代码;
- 随机化参数测试:支持结构化构造的不同随机数据作为入参,运行同一份测试代码。相较于业界仅可生成基础类型和字符数组类型的随机值,仓颉提供了更为强大的随机化参数测试能力;
- 泛型类型参数化测试:对于泛型库开发者,框架可基于同一测试代码,通过传入不同类型参数,测试泛型函数在不同类型上的实现;
- 死亡测试:对于底层库开发者,框架支持捕获不符合预期的信号,段错误和其他发生在底层库中的错误。
此外,为了进一步改善用户体验,测试框架引入了对power assertions和difference assertions的原生实现,提供对测试数据和故障背后原因的详尽说明。
上述这些特性都是灵活可配置的,并可以按需组合使用。例如,测试泛型函数时,使用类型参数化一次生成多种类型实例化实现,传入对应类型下随机生成的测试数据,同时使用 power assertions 和 difference assertions 获取更为清晰的信息。
6.3.2 Mocking框架
Mocking框架允许用户使用 mock 和 spy 来改变在测试中的仓颉类的行为:这些 mock 或 spy 对象可以通过捕获和修改被处理对象的行为,来测试程序的其余部分如何与该对象交互。Mocking 是一种高级技术,主要用于测试由大量交互组件组成的大型应用程序。
我们的Mocking DSL的设计尽量遵照现有语言mocking框架的风格,让用户的切换过程更加简单。DSL允许指定、验证和修改在测试代码中的对象的行为,并产生可读的错误提示。但与其他Mocking框架不同,仓颉的Mocking框架基于独特的编译器插桩技术实现,用户不仅可以 mock 接口和开发类型,还可以mock final 类。
仓颉的Mocking框架与单元测试框架能够无缝结合,两者的任何功能都可以一起使用,使框架的测试能力更加强大。
6.3.3 基准测试框架
仓颉测试框架提供了先进的基准测试体验,包括基于线性回归的统计值计算,预热和精确测量。值得一提的是,单元测试框架提供的大多数功能也可用于基准测试,允许参数化测试,参数随机化生成和泛型类型对泛型代码的基准测试。
除此之外,基准测试框架还具有自己的一套功能,例如相对于给定基线的计算,访问原始基准测试数据(以便在需要时进行用户自己的计算)以及分别针对 micro 和 macro 基准测试的精确误差估计。
6.4 IDE插件
仓颉支持在VSCode底座以及Huawei DevEco Studio底座开发,在VSCode底座以及Huawei DevEco Studio底座安装仓颉插件后,实现开箱即用,支持以下特性:
- 工程管理,支持创建、打开仓颉工程(在DevEco Studio支持创建、打开仓颉HarmonyOS工程);
- 代码高亮、代码补全、语法诊断、悬浮提示、定义跳转、引用查找、格式化等编码辅助能力,包括元编程相关的编码辅助能力;
- 编译构建,在HarmonyOS DevEco Studio底座支持推送仓颉HAP包至手机运行能力;
- 代码调试,包括断点能力、单步调试、调试信息可视化查看能力,在HarmonyOS DevEco Studio底座支持仓颉APP手机调试能力。
7、未来工作规划
仓颉将始终坚持高效编程、安全可靠、轻松并发、卓越性能的设计理念,给开发者带来友好的编程体验以及高性能的运行体验。同时思考在大模型浪潮下AI for PL、PL for AI的形态。以下介绍一些已经在我们规划中的、令人兴奋的语言能力。
- 原生智能(AI Native)应用开发
- DSL KIT
- Actor和分布式编程
- IDE AI赋能
- 可视化并行并发程序调优

