
热门标签
热门文章
- 1Linux——超超讲解SSH的原理与SSH的实现!建议收藏❤_sshd: root [priv]
- 2让表单设计更简单,一个全开源的表单设计神器_自定义表单开源
- 3M1芯片苹果电脑关闭SIP详细教程_m1 芯片 关闭sip
- 4Springboot+druid+多数据源_springboot druid 多数据源
- 5Github 2024-07-13 开源项目日报 Top10_github top
- 6AIGC大时代背景,20美金都付了,一文看看GPT4对Apollo的认知和想法_红外热成像 百度apollo
- 7大数据开发:消息队列如何确保消息不丢失?_消息队列保证消息不丢失
- 8计算机网络1-6合集_网络接口怎么数1-6
- 9【burpsuite安全练兵场-客户端12】跨站点请求伪造CSRF-12个实验(全)_csrf漏洞burp利用
- 10iVox (Faster-Lio): 智行者高博团队开源的增量式稀疏体素结构_ivox3d体素地图
当前位置: article > 正文
C/C++中的移位运算你真的搞懂了吗?一文看懂移位运算_c++ 移位
作者:木道寻08 | 2024-07-17 13:24:00
赞
踩
c++ 移位
移位运算,很多人都是知道,但是又没有完全懂。这是因为移位运算的规则还是稍微有点复杂。因为移位运算分有左移、右移,同时还得区分逻辑移位和算术移位,并且还需要考虑移位超出数据长度的情况。
1 概念区分
首先,左移、右移和算术移位、逻辑移位是交叉的关系,并不是四个并列关系。可以这么讲,左移和右移都可以分为算术移位、逻辑移位,也可以反过来将,算术移位、逻辑移位里面都可以分为左移、右移。所以这几个概念没有办法分开讲。
左移与右移:就是将数据整体左移,然后最左边的位(最低位)被丢弃,最右边的位(最高位)空出来,称为缺位。右移恰好相反。如下图所示(为了方便,以4bit数据为例):
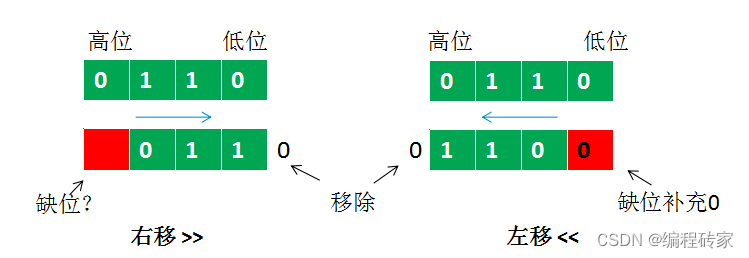
左移(无论是算术左移还是逻辑左移),缺位一律填充为0。因此,对左移运算来讲,算术移位和逻辑移位的结果是一样的,不需要区分。
算术移位与逻辑移位:这个两个的本质区别在于移位(右移)之后如何填充缺位。
- 对于逻辑移位,缺位一律填充0。
- 对于算术移位,缺位填充符号位,即非负数填0,负数填1
对于非负数来讲,符号位为0,因此算术右移之后,缺位填充0,与逻辑右移一样,因此,非负数的逻辑右移与算术右移结果一样。
通过以上的分析,可以得出如下结论:
- 左移 ,算术左移和逻辑左移结果一样,不用区分。
- 右移,如果是非负数,算术右移和逻辑右移结果一样,不用区分。
- 右移,如果是负数,算术右移和逻辑右移结果不一样。
2 编译器如何选择是逻辑移位还是算术移位
我们在编码的时候,可以用<< 以及 >> 分别表示左移和右移,但是编译器是如何区分这是算术移位还是逻辑移位呢?
- 如果是左移,不用区分逻辑移位还是算术移位,因为结果一样。
- 如果是右移,编译器需要根据数据的类型选择,如果是unsigned 类型(无符号),选择逻辑右移,如果是signed类型,选择算术右移。
因此,如果是signed类型数据,想要进行逻辑移位,可以强转为unsigned和类型后进行移位。unsigned类型要想进行算术移位,可以强转为signed类型后进行移位。
3 移位位数超过数据长度了编译器如何处理?
首先,我们编码时,无论是移位运算还是其它计算,都需要尽可能避免数据溢出,或者需要注意这点。一般,当移位的长度大于等于数据的长度时,编译器一般都会产生告警提示。如果真的移位长度m超过了数据长度len,编译器是怎么处理的呢?
- 如果是左移,常量和变量处理不同:
常量,移位长度超过数据长度,直接变为0
变量,实际移位长度为m %len,以32为int数据为例,如果左移40位,实际上移位 40 % 32 = 8位 - 右移的话,按照规则补位即可。
一个例子
下面通过一个例子,直观感受不同情况下移位的结果:
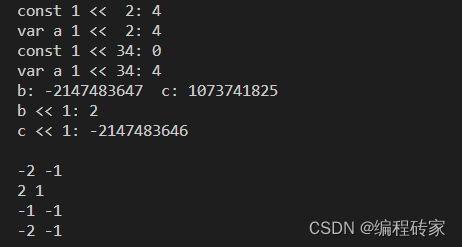
#include <bits/stdc++.h> using namespace std; int main() { /* 左移: 1.不区分逻辑移位和算术移位,一律低位补0,高位丢弃 2.当移位长度大于数据类型长度时,如果是常量,结果为0,若是变量,移位长度对数据长度取余 */ int a = 1; cout << "const 1 << 2: " << (1 << 2) << endl; cout << "var a 1 << 2: " << (a << 2) << endl; cout << "const 1 << 34: " << (1 << 34) << endl; // 常量移位长度超过数据长度,结果为0 cout << "var a 1 << 34: " << (a << 34) << endl; // 变量移位长度超过数据长度,34 % 32 = 2,左移2位 // 由于左移丢弃最高位,对于signed类型数,最高位为符号位,因此符号位变化,可能正数变负数,负数变正数 int b = 0x80000001; // 最高位bit为1000,符号为1,负数 int c = 0x40000001; // 最高位bit为0111,符号为0,正数 cout <<"b: " << b << " c: " << c << endl; cout << "b << 1: " << (b << 1) << endl; // b最高位1被移除,最高位变为0,负数变正数 cout << "c << 1: " << (c << 1) << endl; // c最高位0被移除,最高位变为1,正数变负数 cout << endl; /* 右移: 有符号数 编译器采取算术右移,最高位补符号位,即非负数补0,负数补1 无符号数 编译器采取逻辑右移,最高位补0 所以,非负数 和 无符号数 不断右移的最终结果为0, 负数 不断右移的结果为 -1 另外,从结果看,右移从结果都是变为原来数的1/2(奇数要取整),但是-1除外, 因为-1右移结果还是-1 !,这是因为-1的二进制补码已经全是1了,即:111...111,共32个1 右移之后,右边丢弃一个1,左边最高位在补充一个1,结果一样嘛,这也是为上面所有的负数一直右移 最终结果都是-1 */ int d = -2; unsigned int e = 2; int f = -1; cout << d << " " << (d >> 1) << endl; cout << e << " " << (e >> 1) << endl; cout << f << " " << (f >> 1) << endl; cout << d << " " << (d >> 33) << endl; return 0; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
运行结果如下:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/木道寻08/article/detail/840143
推荐阅读
相关标签

